SpringCloud
微服务
1、微服务架构概述
微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务。服务之间互相协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务与服务间采用轻量级的通信机制互相协作(通常是基于HTTP协议的RESTful API)。每个服务都围绕着具体业务进行构建,并且能够被独立的部署到生产环境、类生产环境等。另外,应当尽量避免统一的、集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建。
2、微服务架构编码构建
Rest微服务工程搭建:
约定>配置>编码
IDEA新建project工作空间
- 微服务cloud整体聚合工程
- 父工程步骤
- New Project
- 聚合总父工程名字
- Maven选版本
- 工程名字
- 字符编码
- 注解生效激活
- java编译版本选8
- File Type过滤
- 父工程POM
- DependencyManagement(版本统一管理)
- maven中跳过单元测试
- 父工程创建完成执行mvn:insall将父工程发布到仓库方便子工程继承
- 父工程步骤
- 微服务cloud整体聚合工程
Rest微服务工程搭建
创建公共的模块
- 实体类emtities
- 主实体
- Json封装体
- 常量类
- 枚举类
- 创建步骤
- 建module
- 改pom
- 编写
- 执行mvn:insall将公共工程发布到仓库方便需要的工程继承
- 实体类emtities
微服务提供者Module模块
- 建module
- 改POM
- 写YML
- 主启动
- 业务类
- 建表sql
- dao
- 接口
- mybatis的映射文件(src\main\resources\mapper\XxxxxMapper.xml)
- service
- 接口
- 实现类
- controller
- 测试(postman)
热部署Devtools
微服务消费者订单Module模块
- 建module
- 改POM
- 写YML
- 主启动
- 业务类
- config配置类
- controller
- 测试
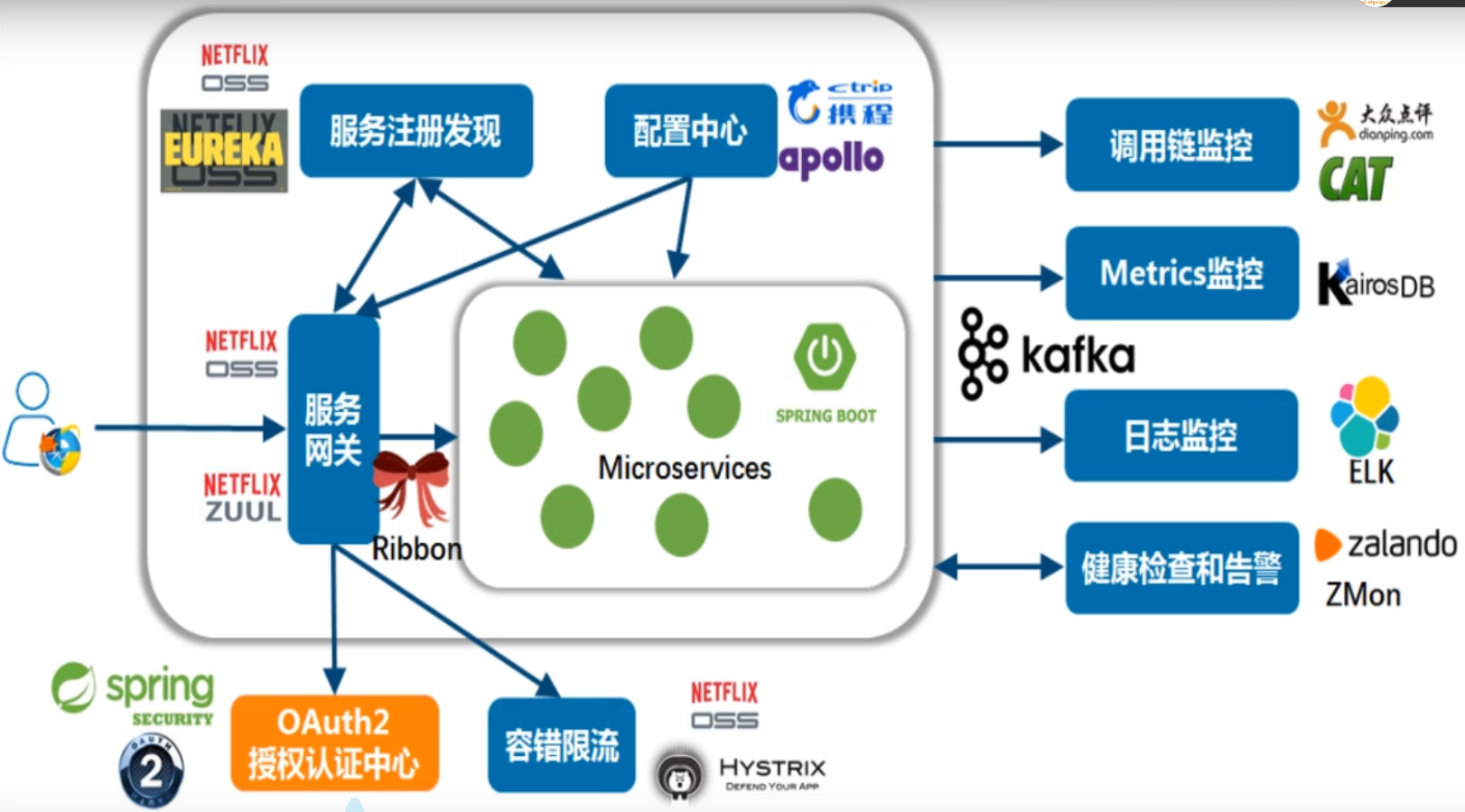
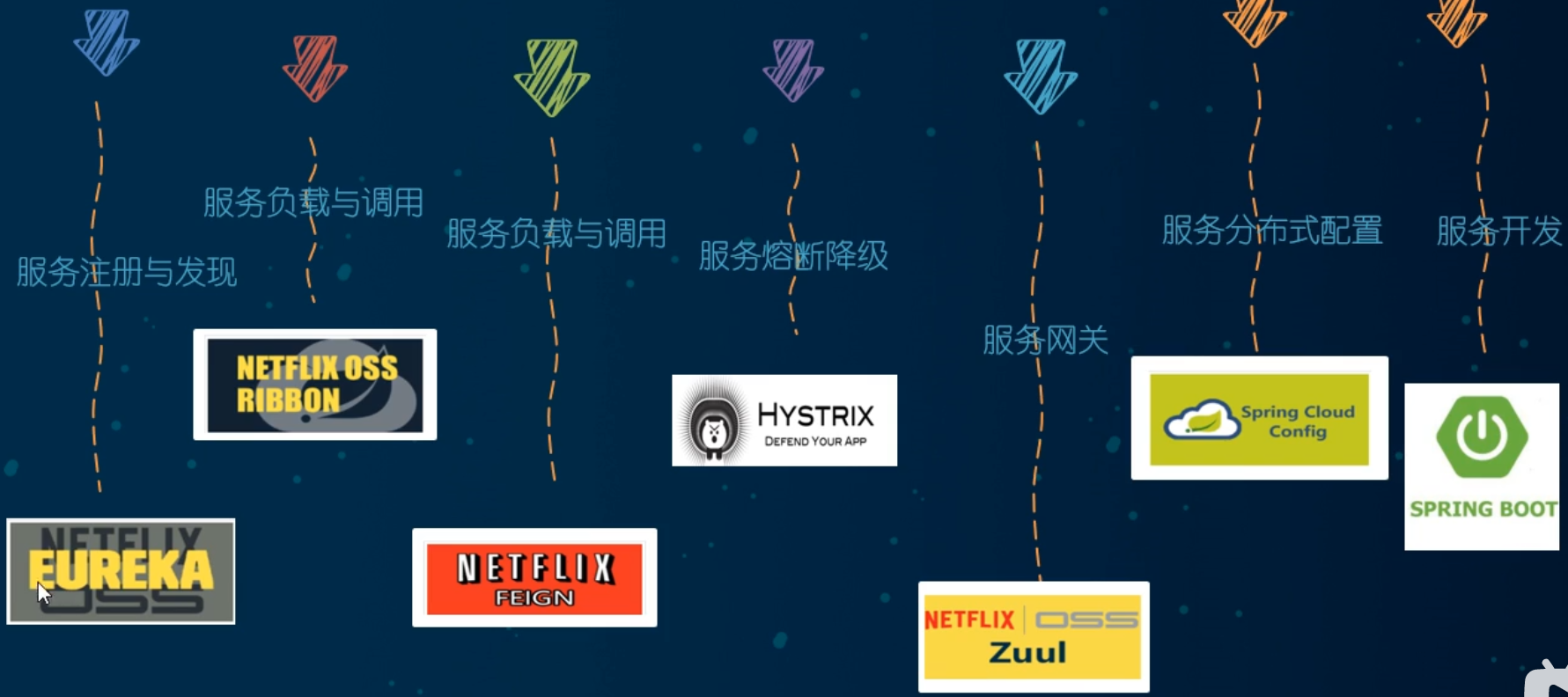
3、SpringCloud简介
SpringCloud:分布式微服务架构的一站式解决方案,是多种微服务架构落
地技术的集合体,俗称微服务全家桶。


4、SpringCloud技术栈
5、版本选择
springboot:2.2.RELEASE
springcloud:Hoxton.SR1
springcloud Alibaba:2.1.0.RELEASE
java:8
Maven:3.5及以上
Mysql:5.7及以上
6、访问方式
- 网页
- postman
- dos窗口 + crul
注册中心
7、Eureka注册中心
7.1、Eureka基础知识:
服务治理:SpringCloud封装了Netflix公司开发的Eureka模块来实现服
务治理。
在传统的rpc远程调用框架中,管理每个服务与服务之间的依赖关系比
较复杂,管理比较复杂,所以需要使用服务治理,管理服务与服务之间
的依赖关系,可以实现服务调用、负载均衡、容错等,实现服务的发现
与注册。
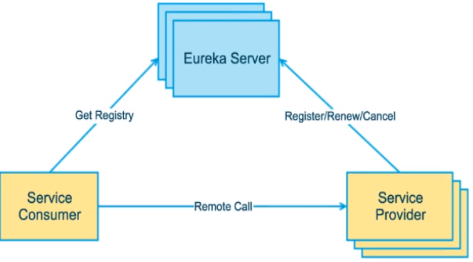
服务发现与注册:Eureka采用了CS的设计架构,Eureka Server作为服
务注册功能的服务器,它是服务注册中心。而系统中的其他微服务,使
用Eureka的客户端连接到Eureka Server并维持心跳连接。这样系统的
维护人员就可以通过Eureka Server来监控系统中各个微服务是否正常
运行。
在服务注册与发现中,有一个注册中心。但服务器启动的时候,会把当
前自己的服务的信息。比如:服务地址、通讯地址等以别名方式注册到
注册中心上。另一方(消费者|服务提供者),以该别名的方式去注册
中心上获取到实际的服务通讯地址,然后在实现本地的RPC调用。远程
RPC调用的框架核心设计思想:在于注册中心,因为使用注册中心管理
每个服务与服务之间的一个依赖关系(服务治理概念)。在任何远程
RPC框架中,都会有一个注册中心(存放服务地址相关信息(接口地
址))
Eureka系统架构与Dubbo架构的对比
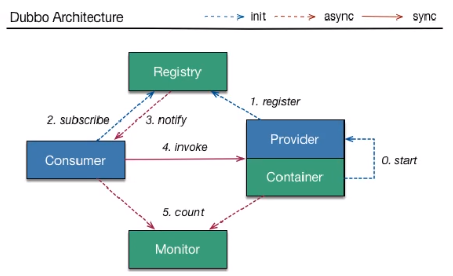
Eureka的两大组件
Eureka Server:提供服务注册服务
各个微服务结点通过配置启动后,会在Eureka Server中进行注
册,这样Eureka Server中的服务注册表中将会存储所有可用服务
注册节点的信息,服务节点的信息可以在界面中直观看到。
主启动加注解:@EnableEurekaServer
pom:
1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>Eureka Client:通过注册中心进行访问
是一个java客户端,用于简化Eureka Server的交互,客户端同时也
具备一个内置的,使用轮询(round-robin)负载算法的负载均衡
器。在启动应用后,将会向Eureka Server发送心跳(默认周期
30s)。如果Eureka Server在多个心跳周期内没有接收到某个节点
的心跳,Eureka Server将会从访问注册表中把这个服务节点移除
(默认90s)
主启动加注解:@EnableEurekaClient
pom:
1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
7.2、工作流程:

解决办法: 搭建Eureka注册中心集群,实现负载均衡+故障容错
7.3、集群搭建
相互依赖,相互守望(在application.yml中配置文件互相配置)
7.4、eureka自我保护
概述:保护模式主要用于一组客户端和Eureka Server之间存在网络分区场
景下的保护。一旦进入保护模式,Eureka Server将会尝试保护其服务注册
表中的信息,不在删除服务注册表中的数据,也就是不会注销任何微服务。

导致原因:




一句话总结:某时刻 一个微服务不可用了,Eureka不会立刻清理,依旧会对该
服务的信息进行保存。属于CAP里面的AP分支
如何禁用Eureka的保护模式:
在Eureka服务端(Eureka Server):
使用eureka.server.enable-self-preservation=false 可以禁用自我保护模式
在Eureka客户端(Eureka Client)(修改时间):
eureka.instance.lease-renewal-interval-in-seconds=1
Eureka客户端向服务端发送心跳的时间间隔,单位为秒。默认是30秒
eureka.instance.lease-expiration-duration-in-seconds=90
Eureka服务端在收到最后一次心跳后等待时间上限 ,单位为秒(默认是90
秒),超时删除服务
8、Zookeeper注册中心
Zookeeper是一个分布式协调工具,可以实现注册中心功能。
依赖导入:
pom:
1 | <dependency> |
思考:
服务节点是临时节点还是持久节点?
临时节点。所以Zookeeper属于CAP中里的CP分支。

9、Consul注册中心
9.1、什么是consul
Consul是一套开源的分布式服务发现和配置管理系统,由HashiCorp公司用
Go语言开发。Consul提供了微服务系统中的服务治理、配置中心、控制总
线等功能。这些功能中的每一个都可以根据需要单独使用,也可以一起使用
以构建全方位的服务网络,总之Consul提供了一种完整服务网络解决方
案。
优点:
- 基于raft协议,比较简洁
- 支持健康检查,同时支持HTTP和DNS协议支持跨数据中心的WAN集群
- 提供图形界面
- 跨平台
- 支持Linux、Mac、Windows
9.2、功能
- 服务发现:提供HTTP/DNS两种发现方式
- 健康检测:支持多种方式,HTTP、TCP、Docker、shell脚本定制化
- KV存储:Key、Value的存储方式
- 多数据中心:Consul支持多数据中心
- 可视化界面
9.3、依赖导入
pom:
1 | <dependency> |
10、三个注册中心异同点
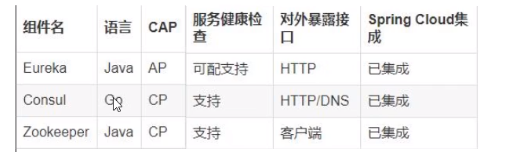
CP(Zookeeper/Consul):
当网络分区出现后,为了保证一致性,就必须拒绝请求,否则无法保证一致性
结论:违背了可用性A的要求,只满足一致性和分区容错,即CP。
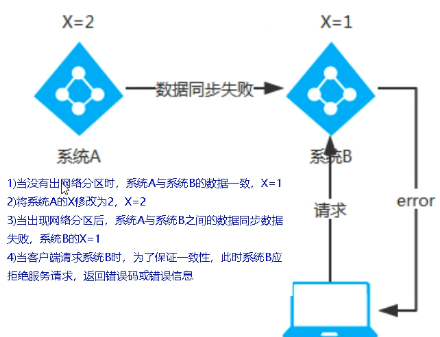
AP(Eureka):
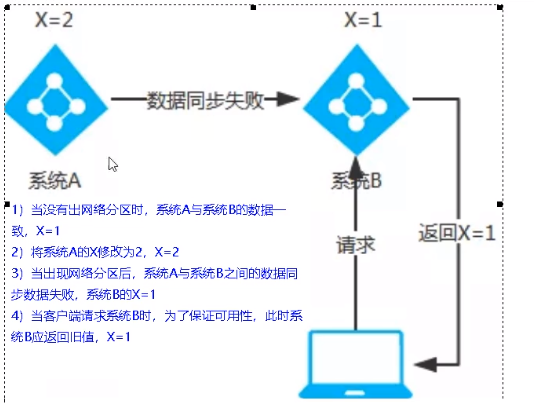
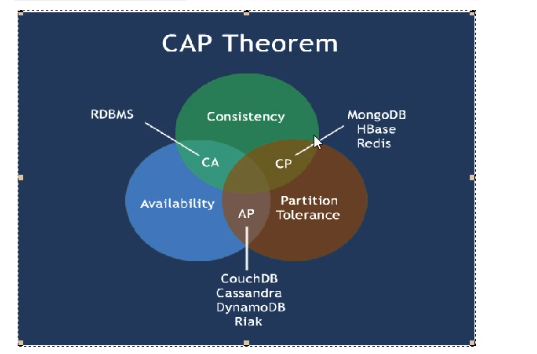
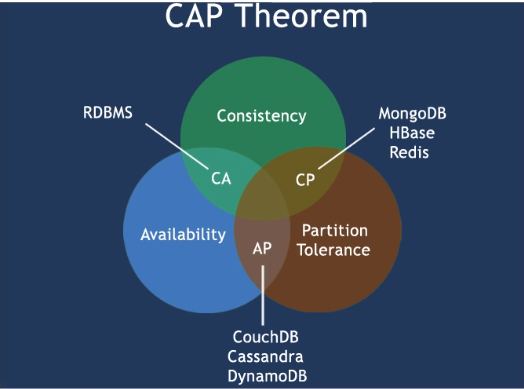
CAP(分区容错性要保证,所以要么是CP,要么是AP):
- C: Consistency(强一致性)
- A: Availability(可用性)
- P: Parttition tolerance(分区容错性)
CAP理论关注粒度是否是数据,而不是整体系统设计的策略
经典CAP图:

负载均衡
11、Ribbon负载均衡调用
11.1、是什么
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的
工具。
简单的说,Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软
件负载均衡算法和服务调用。Ribbon客户端组件提供一系列完善的配置项
如连接超时,重试等。简单的说,就是在配置文件中列出Load
Balancer(LB)后面所有机器,Ribbon会自动的帮助你基于某种规则(如简
单轮询,随机连接等)去连接这些机器。我们很容易使用Ribbon实现自定义
的负载均衡算法。
总结: Ribbon其实就是一个软负载均衡的客户端组件, 他可以和其他所需请
求的客户端结合使用,和eureka结合只是其中一个实例.
11.2、作用(负载均衡+RestTemplate调用)
LB(负载均衡):
简单的说就是将用户的请求平摊的分配到多个服务上,从而达到系统的
HA(高可用)。
常见的负载均衡有软件Nginx,LVS,硬件F5等。
Ribbon本地负载均衡客户端 VS Nginx服务端负载均衡的区别:
Nginx是服务器负载均衡,客户端所有请求都会交给nginx,然后由
nginx实现转发请求。即负载均衡是由服务端实的。
Ribbon本地负载均衡,在调用微服务接口的时候,会在注册中心上获
取注册信息服务列表之后缓存到JVM本地,从而在本地实现RPC远程服务调用技术。
LB(负载均衡)可分为:
集中式LB
即在服务的消费方和提供方之间提供独立的LB设施(可以是硬件如F5,
也可以是软件,如nginx),由该设施负责把访问请求通过某种策略转发
至服务的提供方。
进程内LB
将LB逻辑集成到消费方,消费方从服务注册中心获知有哪些地址可用,
然后自己再从这些地址中选择出一台合适的服务器。Ribbon就属于进
程内LB,它只是一个类库,集成与消费方进程,消费方通过它来获取服
务提供方的地址。
11.3、框架说明
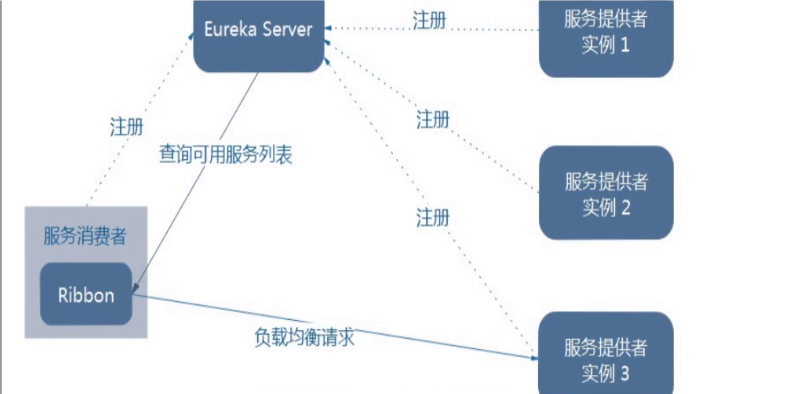
Ribbon在工作时分成两步:
第一步:
先选择Eureka Server,它优先选择在同一区域内负载较少的server
第二步:
再根据用户指定的策略,再从server取到的服务注册列表中选择一个地
址。其中Ribbon提供了多种策略:比如轮询、随机和根据响应时间加
权。
RestTemplate的使用:
getForObject(String url,class)方法:返回对象为响应体中数据转化成的
对象,基本上可以理解成Json
getForEntity(String url,class)方法:返回对象为ResponseEntity对象,
包含响应中的一些重要信息,比如响应头、响应状态码、响应体等。
11.4、Ribbon核心组件IRule
11.4.1、IRule是什么
IRule:根据特定算法从服务列表中选取一个要访问的服务
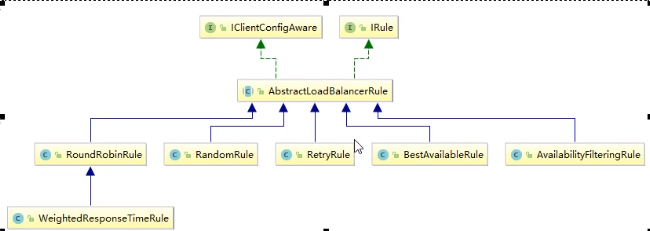
com.netflix.loadbalancer.RoundRobinRule:轮询(默认)
com.netflix.loadbalancer.RandomRule:随机
com.netflix.loadbalancer.RetryRule:先按照RoundRobinRule的策略
获取服务,如果获取服务失败则在指定时间内进行重试,获取可用的服务
WeightedResponseTimeRule:对RoundRobinRule的扩展,响应速度
越快的实例选择权重越多大,越容易被选择
BestAvailableRule:会先过滤掉由于多次访问故障而处于断路器跳闸
状态的服务,然后选择一个并发量最小的服务
AvailabilityFilteringRule:先过滤掉故障实例,再选择并发较小的实例
ZoneAvoidanceRule:默认规则,复合判断server所在区域的性能和
server的可用性选择服务器
11.4.2、替换:
注意配置细节
官方文档明确给出了警告:
这个自定义配置类不能放在@ComponentScan所扫描的当前包以及子包
下,否则我们自定义的这个配置类就会被所有的Ribbon客户端所共享,达
不到特殊化定制的目的了。

@ComponentScan所扫描的当前包以及子包:因为
@SpringBootApplication注解包含了@ComponentScan注解,所以该自定
义配置类不能放在当前包(springcloud)下。
新建package:com.atguigu.myrule
上面包下新建MySelfRule规则类
主启动类添加@RibbonClient
11.4.3、Ribbon负载均衡算法
RoundRobinRule:轮询的算法思想
12、OenFeign
12.1、是什么?
官方解释:https://cloud.spring.io/spring-cloud-static/Hoxton.SR1/reference/htmlsingle/#spring-cloud-openfeign
Feign是一个声明式WebService客户端。使用Feign能让编写Web Service客
户端更加简单。它的使用方法是定义一个服务接口然后在上面添加注解。
Feign也支持可拔插式的编码器和解码器。Spring Cloud对Feign进行了封
装,使其支持了Spring MVC标准注解和HTTPMessageConverters。Feign
可以与Eureka和Ribbon组合使用以支持负载均衡。
12.2、作用:
Feign旨在使编写Java Http客户端变得更容易。
前面在使用Ribbon+RestTemplate时,利用RestTemplate对http请求的封装处
理,形成了一套模版化的调用方法。但是在实际开发中,由于对服务依赖的调用
可能不止一处,往往一个接口会被多处调用,所以通常都会针对每个微服务自行
封装一些客户端类来包装这些依赖服务的调用。所以,Feign在此基础上做了进
一步封装,由他来帮助我们定义和实现依赖服务接口的定义。在Feign的实现下
我们只需创建一个接口并使用注解的方式来配置它(以前是Dao接口上面标
注Mapper注解,现在是一个微服务接口上面标注一个Feign注解即可),即可完
成对服务提供方的接口绑定,简化了使用Spring cloud Ribbon时,自动封装服
务调用客户端的开发量。
Feign集成了Ribbon
利用Ribbon维护了Payment的服务列表信息,并且通过轮询实现了客户端的负
载均衡。而与Ribbon不同的是,通过feign只需要定义服务绑定接口且以声明式
的方法,优雅而简单的实现了服务调用。
12.3、Feign和OpenFeign两者区别

12.4、使用步骤
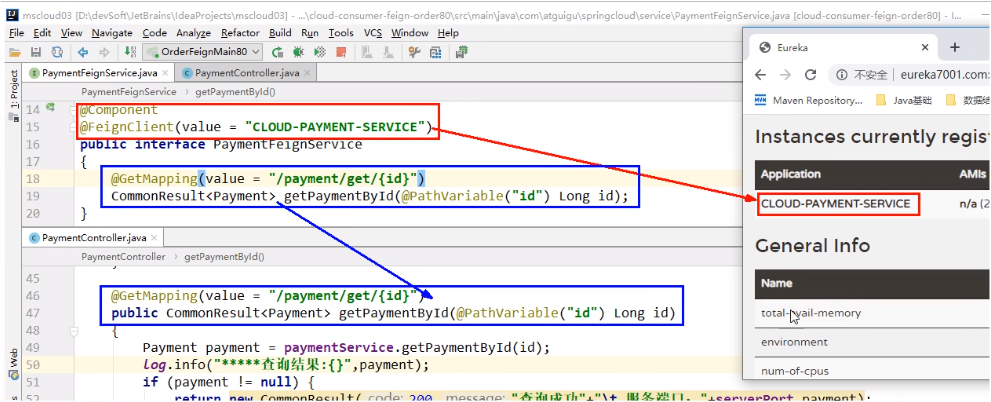
接口+注解:微服务调用接口+@FeignClient
Feign在消费端使用
pom:
1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>主启动加上@EnableFeignClients注解开启Feign
业务逻辑接口+@FeignClient配置调用provider服务
@FeignClient(value = “xxx-xxx-xxx”)value的值要写服务提供方在Eureka注册的名称
控制层Controller
12.5、OpenFeign超时控制
12.5.1、是什么?
默认Feign客户端只等待1秒钟,但是服务端处理需要超过1秒钟,导致Feign客
户端不想等待了,直接返回报错。
12.5.2、解决方法(OpenFeign默认支持Ribbon)
为了避免这样的情况,有时候我们需要设置Feign客户端的超时控制。
yml文件中开启配置
1 | #设置feign客户端超时时间(OpenFeign默认支持ribbon) |
12.6、OpenFeign日志打印功能
12.6.1、是什么?
Feign提供了日志打印功能,我们可以通过配置来调整日志级别,从而了解
Feign中Http请求的细节。说白了就是对Feign接口的调用情况进行监控和
输出。
熔断器
13、Hystrix熔断器(豪猪哥)
13.1、分布式系统面临的问题
复杂分布式体系结构中的应用程序 ,有数10个依赖关系,每个依赖关系在某些时候将不可避免地失败。

服务雪崩:
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和
微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微
服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系
统资源,进而引起系统崩溃,所谓的“雪崩效应”。
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都
在几秒钟内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟
增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故
障。这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,
不能取消整个应用程序或系统。所以,通常当你发现一个模块下的某个实例失败
后,这时候这个模块依然还会接收流量,然后这个有问题的模块还调用了其他的
模块,这样就会发生级联故障,或者叫雪崩。
13.2、Hystrix是什么
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,
许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个
依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系
统的弹性。
“断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故
障监控(类似熔断保险丝),向调用方返回一个符合预期的、可处理的备选响应
(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证
了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系
统中的蔓延,乃至雪崩。
官网:https://github.com/Netflix/hystrix/wiki
13.3、作用
- 服务降级
- 服务熔断
- 接近实时的监控
13.4、HyStrix重要概念
13.4.1、服务降级
服务器忙,请稍后再试,不让客户端等待并立刻返回一个友好提示,fallback
哪些情况会发出降级:
- 程序运行异常
- 超时
- 服务熔断触发服务降级
- 线程池/信号量也会导致服务降级
13.4.2、服务熔断
类比保险丝达到最大服务访问后,直接拒绝访问,拉闸限电,然后调用服务降级的方
法并返回友好提示
服务熔断的过程:
服务的降级->进而熔断->恢复调用链路
12.4.3、服务限流
秒杀高并发等操作,严禁一窝蜂的过来拥挤,大家排队,一秒钟N个,有序进行
13.5、依赖
pom:
1 | <dependency> |
13.6、高压访问的解决方法
超时导致服务器变慢(转圈):超时不再等待
出错(宕机或程序运行出错):出错要有兜底
13.7、访问降级
降级配置@HystrixCommand
13.7.1、对于服务提供方:
设置自身调用超时时间的峰值,峰值内可以正常运行, 超过了需要有兜底的方法处
理,做服务降级fallback
一旦调用服务方法失败并抛出了错误信息后,会自动调用@HystrixCommand标‘
注好的fallbckMethod调用类中的指定方法
主启动类激活@EnableCircuitBreaker
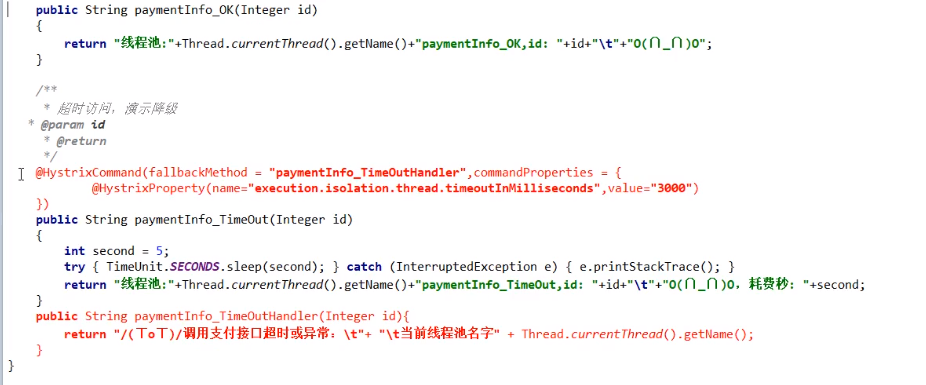
下图故意制造两个异常:
- int age = 10/0;计算异常
- 我们能接受3秒钟,它运行5秒钟,超时异常。
当前服务不可用了,做服务降级,兜底的方案都是paymentInfo_TimeOutHandler
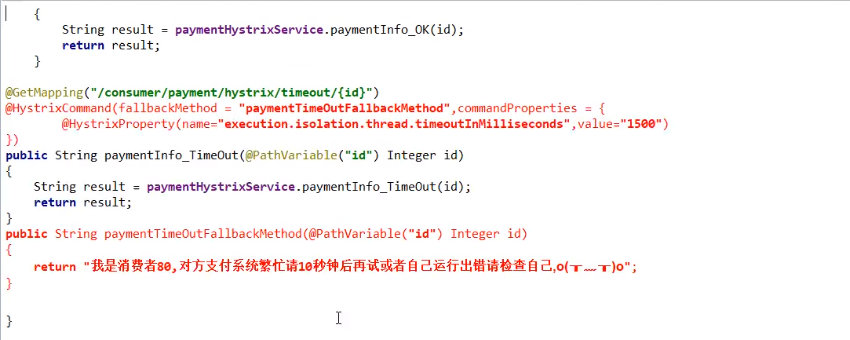
13.7.2、对于服务消费方:
主启动类激活@EnableHystrix
业务类
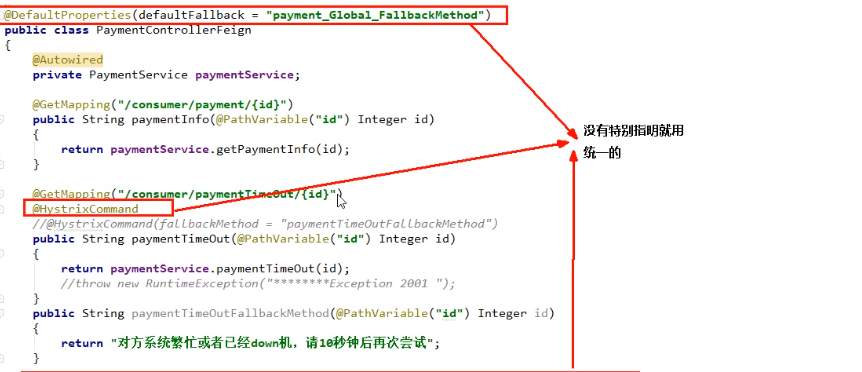
13.7.3、目前问题
- 每个业务方法对应一个兜底的方法,代码膨胀
- 统一和自定义的分开
解决方法:
解决第一个问题:代码膨胀
feign接口系列
@DefaultProperties(defaultFallback=””)
每个方法配置一个服务降级方法,技术上可以,实际上导致代码膨胀。
除了个别重要核心业务有专属,其它普通的可以通过
@DefaultProperties(defaultFallback =”)统一跳转到统一处理结果页面
通用的和独享的各自分开,避免了代码膨胀,合理减少了代码量。

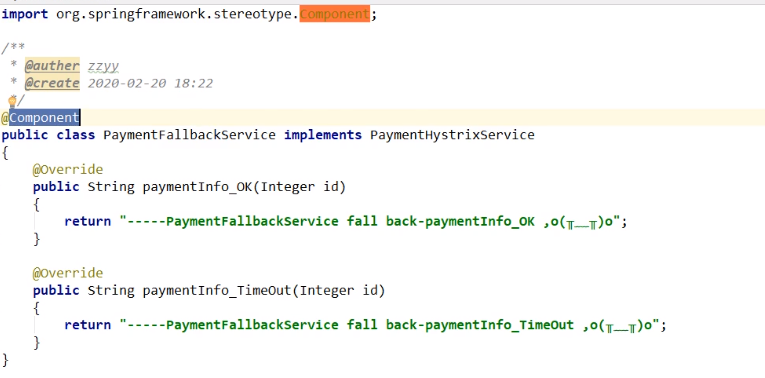
解决第二个问题:和业务逻辑混在一起
服务降级,客户端去调用服务端,碰上服务端宕机或关闭。只需要为Feign客户
端定义的接口添加一个服务降级处理的实现类即可实现解耦。
我们可能面临的异常:
- 运行
- 超时
- 宕机
重新新建一个类(PaymentFallbackService)实现PaymentHystrixService接
口(OpenFeign的服务接口),统一为接口里面的方法进行异常处理
PaymentHystrixService接口:

13.8、服务熔断
13.8.1、是什么?
https://martinfowler.com/bliki/CircuitBreaker.html
熔断机制概述
熔断机制是应对雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务
出错不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的
调用,快速返回错误的响应信息。
当检测到该节点微服务调用响应正常后,恢复调用链路。
在Spring Cloud框架里,熔断机制通过Hystrix实现。Hystrix会监控微服务间调
用的状况,当失败的调用到一定國值,缺省是5秒内20次调用失败,就会启动熔
断机制。熔断机制的注解是@HystrixCommand。
12.8.2、服务熔断的注解@HystrixCommand(Service层)
1 |
12.8.3、大神结论
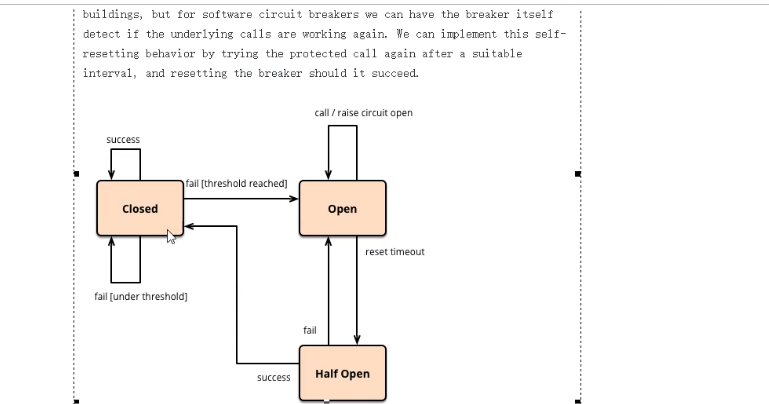
熔断类型:
熔断打开(Open):
请求不再调用当前服务,内部设置一般为MTTR(平均故障处理时间),当打开长达导所设时钟则进入半熔断状态
熔断关闭(Closed):
熔断关闭后不会对服务进行熔断
熔断半开(Half Open):
部分请求根据规则调用当前服务,如果请求成功且符合规则则认为当前服务恢复正常,关闭熔断
12.8.4、断路流程图
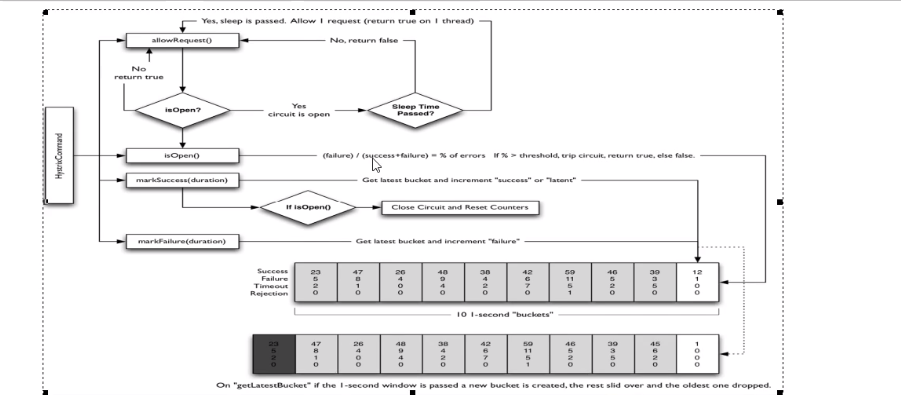
步骤:

断路器在什么情况下开始起作用

涉及到断路器的三个重要参数:快照时间窗、请求总数阀值、错误百分比
阀值
快照时间窗:断路器确定是否打开需要统计一些请求和错误数据,而统
计的时间范围就是快照时间窗,默认为最近的10秒。
请求总数阀值:在快照时间窗内,必须满足请求总数阀值才有资格熔
断。默认为20,意味着在10秒内,如果该hystrix命令的调用次数不足
20次,即使所有的请求都超时或其他原因失败,断路器都不会打开。
错误百分比阀值:当请求总数在快照时间窗内超过了阀值,比如发生了
30次调用,如果在这30次调用中,有15次发生了超时异常,也就是超
过50%的错误百分比,在默认设定50%阀值情况下,这时候就会将断路
器打开。
断路器开启或者关闭的条件:
当满足一定的阈值的时候(默认10秒钟超过20个请求次数)
当失败率达到一定的时候(默认10秒内超过50%的请求次数)
到达以上阈值,断路器将会开启
当开启的时候,所有请求都不会进行转发
一段时间之后(默认5秒),这个时候断路器是半开状态,会让其他一个请求
进行转发. 如果成功,断路器会关闭,若失败,继续开启.重复4和5
断路器打开之后:
再有请求调用的时候,将不会调用主逻辑,而是直接调用降级
fallback。通过断路器,实现了自动地发现错误并将降级逻辑切换为主
逻辑,减少响应延迟的效果。
原来的主逻辑要如何恢复呢?
对于这一问题,hystrix也为我们实现了自动恢复功能。
当断路器打开,对主逻辑进行熔断之后,hystrix会启动一个休眠时间
窗,在这个时间窗内,降级逻辑是临时的成为主逻辑,当休眠时间窗到
期,断路器将进入半开状态,释放一次请求到原来的主逻辑上,如果此
次请求正常返回,那么断路器将继续闭合,主逻辑恢复,如果这次请求
依然有问题,断路器继续进入打开状态,休眠时间窗重新计时。
ALL配置:




13.9、服务限流
alibaba的Sentinel说明
13.10、Hystrix的工作流程
https://github.com/Netflix/Hystrix/wiki/How-it-Works
官网图例
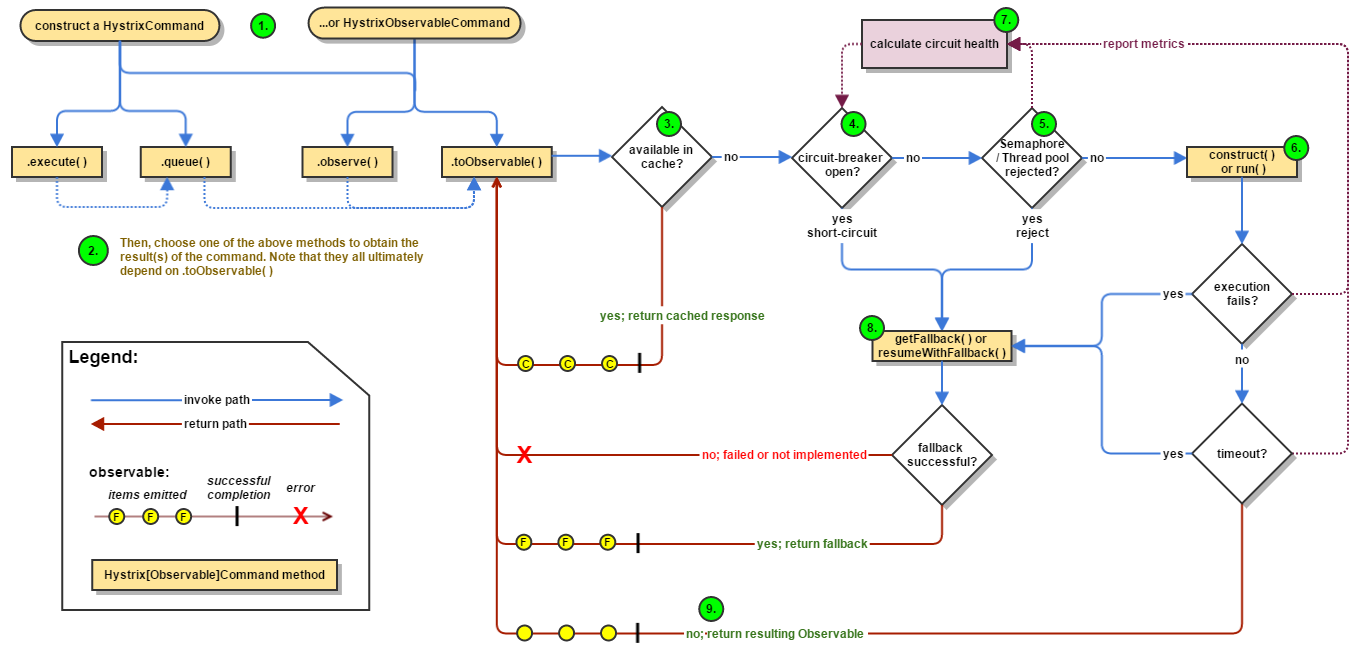
步骤说明

13.11、服务监控hystrixDashboard
13.11.1、概述
除了隔离依赖服务的调用以外,Hystrix还提供了准实时的调用监控
**(Hystrix Dashboard)**,Hystrix会持续地记录所有通过Hystrix发起的请求
的执行信息,并以统计报表和图形的形式展示给用户,包括每秒执行多少
请求多少成功,多少失败等。Netflix通过hystrix-metrics-event-stream项
目实现了对以上指标的监控。Spring Cloud也提供了Hystrix Dashboard的
整合,对监控内容转化成可视化界面。
13.11.2、依赖
pom:
1 | <dependency> |
13.11.3、步骤
主启动类加注解激活@EnableHystrixDashboard
所有Provider微服务提供类都需要监控依赖部署
1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
13.11.4、断路器演示(服务监控hystrixDashboard)
新版本Hystrix需要在主启动MainAppHystrix8001(微服务提供方)中指
定监控路径
1 |
|
启动一个eureka或者3个eureka集群进行监控测试
填写监控地址http://localhost:8001/hystrix.stream
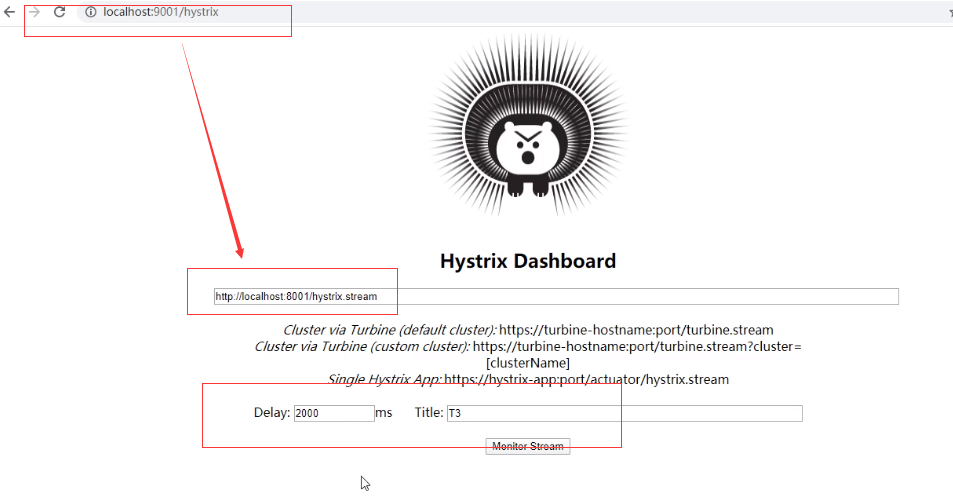
13.11.5、如何看hystrixDashboard服务监控图
七色
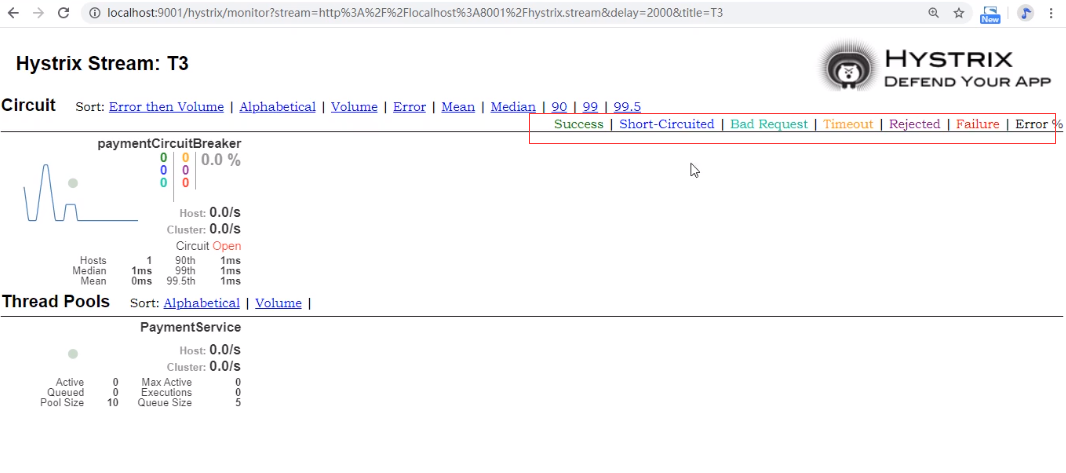
一圈:
实心圆:共有两种含义。它通过颜色的变化代表了实例的健康程度,它
的健康度从绿色<黄色<橙色<红色递减。
该实心圆除了颜色的变化之外,它的大小也会根据实例的请求流量发生
变化,流量越大该实心圆就越大。所以通过该实心圆的展示,就可以在
大量的实例中快速的发现故障实例和高压力实例。
一线:
曲线:用来记录2分钟内流量的相对变化,可以通过它来观察到流量的上升与下降趋势
整图说明:


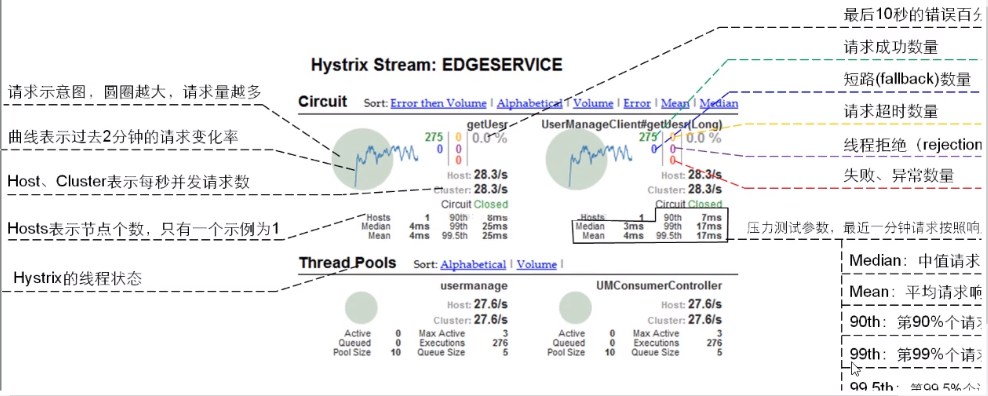
搞懂一个才能看懂复杂的

路由网关
14、Gateway新一代网关
14.1、是什么?
一句话:
SpringCloud Gateway使用的是Webflux中的reactor-netty响应式编程组
件,底层使用了Netty通讯框架。
https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.1.RELEASE/reference/html/
Cloud全家桶中有个很重要的组件就是网关,在1.x版本中都是采用的Zuul
网关;但在2.x版本中,zuul的升级一直跳票,SpringCloud最后自己研发
了一个网关替代Zuul,那就是SpringCloud Gateway一句话:
gateway是原zuul1.x版的替代
Gateway是在Spring生态系统之上构建的API网关服务,基于Spring
5,Spring Boot 2和Project Reactor等技术。
Gateway旨在提供一种简单而有效的方式来对API进行路由,以及提供一些
强大的过滤器功能,例如:熔断、限流、重试等
SpringCloud Gateway 是 Spring Cloud 的一个全新项目,基于 Spring
5.0+Spring Boot 2.0 和 Project Reactor 等技术开发的网关,它旨在为微
服务架构提供一种简单有效的统一的API路由管理方式。
SpringCloud Gateway 作为 Spring Cloud 生态系统中的网关,目标是替代
Zuul,在Spring Cloud 2.0以上版本中,没有对新版本的Zuul 2.0以上最新
高性能版本进行集成,仍然还是使用的Zuul 1.x非Reactor模式的老版本。
而为了提升网关的性能,SpringCloud Gateway是基于WebFlux框架实现
的,而WebFlux框架底层则使用了高性能的Reactor模式通信框架Netty。
Spring Cloud Gateway的目标提供统一的路由方式且基于 Filter 链的方式
提供了网关基本的功能,例如:安全,监控/指标,和限流。
源码架构:
14.2、作用
- 反向代理
- 鉴权
- 流量控制
- 熔断
- 日志监控
- ……
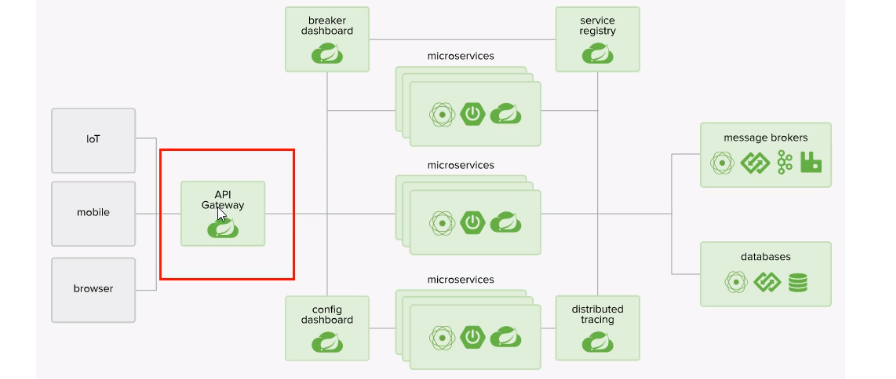
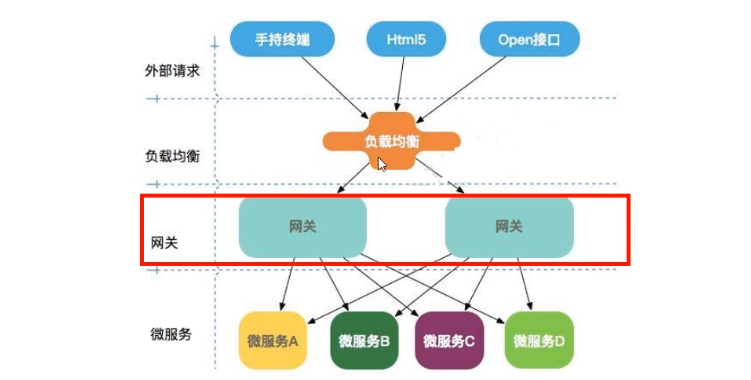
14.3、微服务架构中网关在哪里
14.4、Zool与Gateway
一方面因为Zuul1.0已经进入了维护阶段,而且Gateway是
Spring Cloud团队研发的,是亲儿子产品,值得信赖。而且很多功能
Zuul都没有用起来也非常的简单便捷。
Gateway是基于异步非阻塞模型上进行开发的,性能方面不需要担
心。虽然Netfix早就发布了最新的Zuul 2.x,但 Spring Cloud貌似没有
整合计划。而且Netflix相关组件都宣布进入维护期;不知前景如何?
多方面综合考虑Gateway是很理想的网关选择。
Spring Cloud Gateway 具有如下特性:
基于Spring Framework 5,Project Reactor和 Spring Boot 2.0 进行构建;
- 动态路由:能够匹配任何请求属性;
- 可以对路由指定 Predicate (断言)和 Filter (过滤器);
- 集成Hystrix的断路器功能;
- 集成 Spring Cloud 服务发现功能;
- 易于编写的Predicate (断言)和Filter (过滤器);
- 请求限流功能;
- 支持路径重写。
Spring Cloud Gateway 与 Zuul的区别:
在SpringCloud Finchley正式版之前,Spring Cloud 推荐的网关是
Netflix 提供的Zuul:
Zuul 1.x,是一个基于阻塞I/O的API Gateway
Zuul 1.x 基于Servlet 2.5使用阻塞架构,它不支持任何长连接(如
WebSocket)。 Zuul 的设计模式和Nginx较像,每次I/ O 操作都
是从工作线程中选择一个执行,请求线程被阻塞到工作线程完成,
但是差别是:Nginx 用C++ 实现,Zuul 用 Java 实现,而 JVM 本身
会有第一次加载较慢的情况,使得Zuul的性能相对较差。
Zuul 2.x理念更先进,想基于Netty非阻塞和支持长连接,但
SpringCloud目前还没有整合。Zuul 2.x的性能较 Zuul 1.x有较大提升。在性能方面,根据官方提供的基准测试,Spring Cloud Gateway的RPS(每秒请求数)是Zuul的1.6倍。
Spring Cloud Gateway 建立在 Spring Framework 5、Project
Reactor和 Spring Boot 2之上,使用非阻塞API。
Spring Cloud Gateway 还支持WebSocket,并且与Spring紧密集
成拥有更好的开发体验。
springcloud中所集成的Zuul版本,采用的是Tomcat容器,使用的是传
统的Servlet IO处理模型。
Servlet的生命周期:servlet由servlet container进行生命周期管理。
container启动时构造servlet对象并调用servlet init()进行初始化;
container运行时接受请求,并为每个请求分配一个线程(一般从线
程池中获取空闲线程)然后调用service();
container关闭时调用servlet destory()销毁servlet;
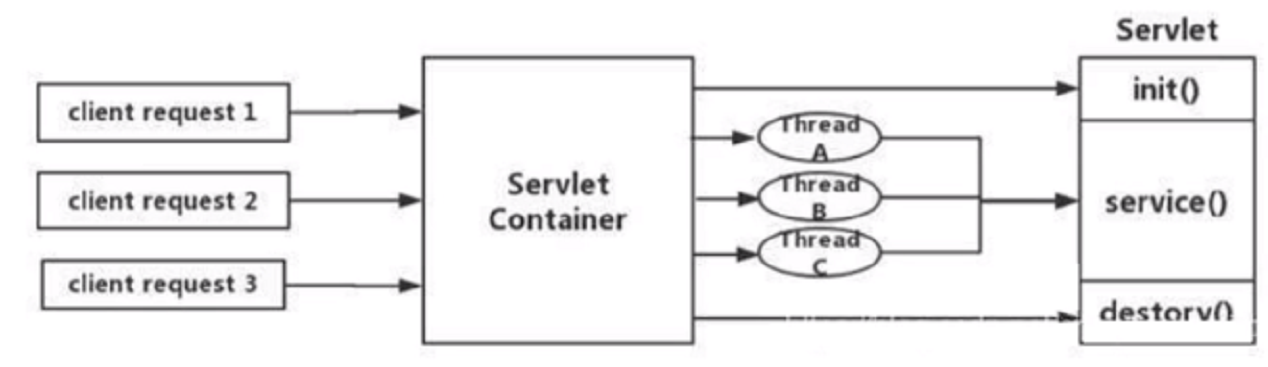
上述模式的缺点:
servlet是一个简单的网络IO模型,当请求进入servlet container时,
servlet container就会为其绑定一个线程,在并发不高的场景下这种模
型是适用的。但是一旦高并发(比如抽风用jemeter压),线程数量就会
上涨,而线程资源代价是昂贵的(上线文切换,内存消耗大)严重影响请
求的处理时间。在一些简单业务场景下,不希望为每个request分配一
个线程,只需要1个或几个线程就能应对极大并发的请求,这种业务场
景下servlet模型没有优势。
而Zuul 1.X是基于servlet之上的一个阻塞式处理模型,即spring实现
了处理所有request请求的一个servlet(DispatcherServlet)并由该
servlet阻塞式处理处理。所以Springcloud Zuul无法摆脱servlet模型
的弊端。
WebFlux:


传统的Web框架,此如说:struts2,springmvc等都是基于Servlet
API与Servlet容器基础之上运行的。
但是,在Servlet3.1之后有了异步非阻赛的支持。而WebFlux是一个典
型非阻塞异步的框架,它的核心是基于Reactor的相关API实现的。相
对于传统的web框架来说,它可以运行在诸如Netty,Undertow及支
持Servlet3.1的容器上。非阻塞式+函数式编程(Spring5必须让你使用
java8)
Spring WebFlux 是Spring 5.0 引入的新的响应式框架,区别于 Spring
MVC,它不需要依赖Servlet API,它是完全异步非阻塞的,并且基于
Reactor 来实现响应式流规范。
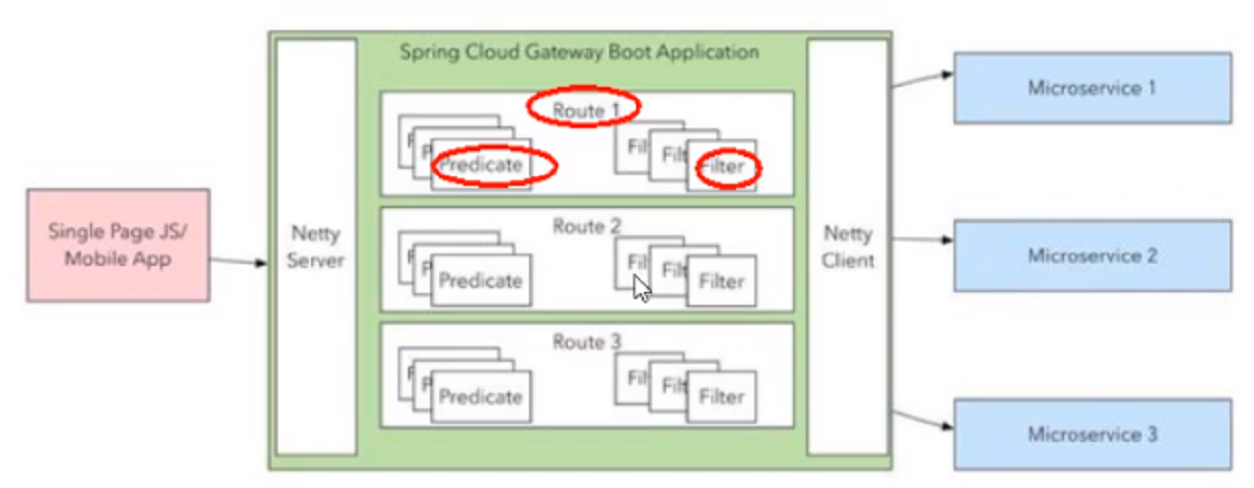
14.5、三大核心概念
Route(路由):
路由是构建网关的基本模块,它由ID,目标URI,一系列的断言和过滤器组
成,如断言为true则匹配该路由。
Predicate(断言):
参考的是Java8的java.util.function.Predicate
开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),如
果请求与断言相匹配则进行路由。
Filter(过滤):
指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路
由前或者之后对请求进行修改。
web请求,通过一些匹配条件,定位到真正的服务节点。并在这个转发过
程的前后,进行一些精细化控制。
predicate就是我们的匹配条件;而filter,就可以理解为一个无所不能的拦截器。有了这两个元素,再加上目标uri,就可以实现一个具体的路由了。
14.6、Gateway工作流程(路由转发+执行过滤器链)
官网总结
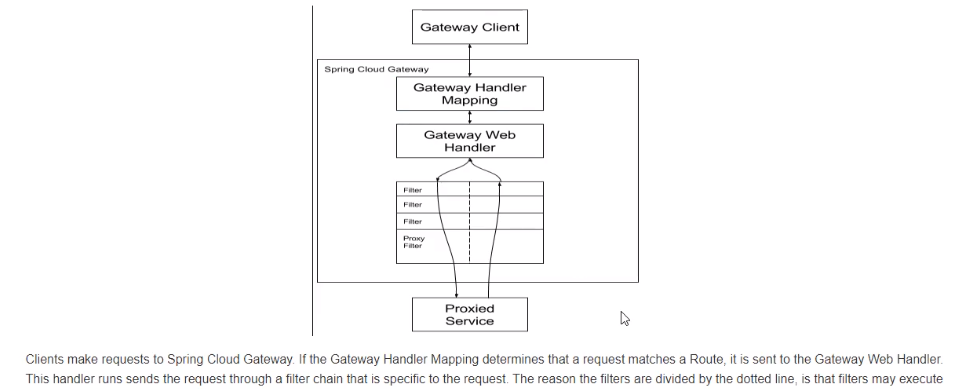

客户端向Spring Cloud Gateway发出请求。然后在Gateway Handler
Mapping中找到与请求相匹配的路由,将其发送到Gateway Web
Handler。
Handler 再通过指定的过滤器链来将请求发送到我们实际的服务执行业务
逻辑,然后返回。
过滤器之间用虚线分开是因为过滤器可能会在发送代理请求之前(“pre”)或之
后(“post”)执行业务逻辑。
Filter在“pre”类型的过滤器可以做参数校验、权限校验、流量监控、日志输
出、协议转换等,
在“post”类型的过滤器中可以做响应内容、响应头的修改,日志的输出,流
量监控等有着非常重要的作用。
14.7、依赖
pom:
1 | <dependency> |
application.yml配置:

访问:
添加网关前:http://localhost:8001/payment/get/31
添加网关后:http://localhost:9527/payment/get/31
14.8、Gateway网关路由有两种配置方式
1、在配置文件yml中配置
2、代码中注入RouteLocator的Bean
示例:
百度国内新闻网站,需要外网https://news.baidu.com/guonei
业务需求:通过9527网关访问到外网的百度新闻网址
实现:在cloud-gateway-gateway9527编写配置类


14.9、通过服务名实现动态
默认情况下Gatway会根据注册中心注册的服务列表, 以注册中心上微服务
名为路径创建动态路由进行转发,从而实现动态路由的功能。
启动:一个eureka+两个服务提供者
application.yml配置:
需要注意的是uri的协议lb,表示启用Gateway的负载均衡功能。
lb://serverName是spring cloud gatway在微服务中自动为我们创建的负载均衡uri

14.10、Predicate(断言)
说白了,Predicate就是为了实现一组匹配规则, 让请求过来找到对应的
Route进行处理。
Spring Cloud Gateway将路由匹配作为Spring WebFlux HandlerMapping
基础架构的一部分。
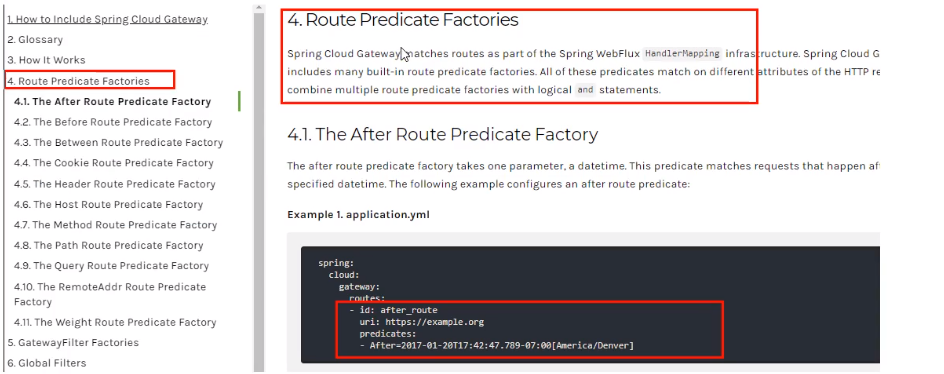
Spring Cloud Gateway包括许多内置的Route PredicateI工厂。所有这些
Predicate都与HTTP请求的不同属性匹配。多个RoutePredicate工厂可以
进行组合。
Spring Cloud Gateway 创建 Route 对象时,使用 RoutePredicateFactory
创建 Predicate 对象,Predicate 对象可以赋值给Route。Spring Cloud
Gateway 包含许多内置的Route Predicate Factories。
所有这些谓词都匹配HTTP请求的不同属性。多种谓词工厂可以组合,并通
过逻辑and。
常用的Route Predicate
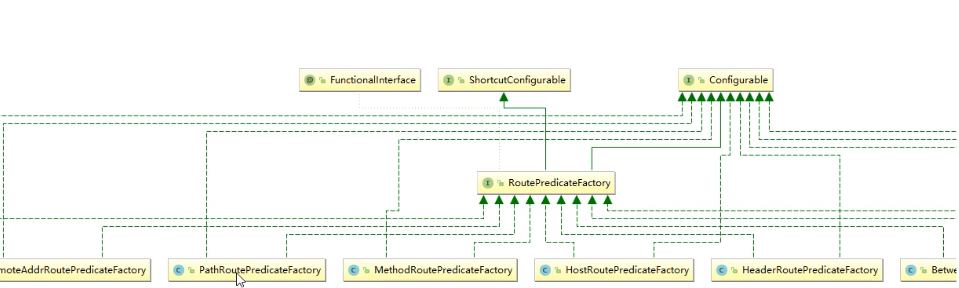
After Route Predicate:在设置时间之后
Before Route Predicate:在设置时间之前
Between Route Predicate:在设置时间中间
Cookie Route Predicate:请求要带有cookie
Header Route Predicate:请求要带有请求头,且请求头的值要符合要求
Host Route Predicate:要使用符合要求的主机进行访问
Method Route Predicate:请求方式要是符合要求
Path Route Predicate:路径相匹配的进行路由
Query Route Predicate:要有参数名并且值还要是符合要求的才能路由
RemoteAddr Route Predicate:通过无类别域间路由(IPv4 or IPv6)列
表匹配路由(- RemoteAddr=192.168.1.1/24)(不常用)
Weight Route Predicate:接收一个[组名,权重], 然后对于同一个组内
的路由按照权重转发(-Weight= group3, 9)(不常用)
application.yml配置:
1 | server: |
14.11、Filter(过滤器)
14.11.1、是什么?
路由过滤器可用于修改进入的HTTP请求和返回的HTTP响应,路由过滤器
只能指定路由进行使用。
Spring Cloud Gateway内置了多种路由过滤器,他们都由GatewayFilter的
工厂类来产生。

14.11.2、生命周期
- post
- pre
14.11.3、种类
- GatewayFilter(31种):https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.1.RELEASE/reference/html/#gatewayfilter-factories
- GlobalFilter(10种):https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.1.RELEASE/reference/html/#global-filters
常用的GatewayFilter:
在yml里面配置:

自定义过滤器:
自定义全局GlobalFilter
两个主要接口
GlobalFilter
Ordered
作用:
- 全局日志记录
- 统一网关鉴权
代码:
1 |
|
分布式配置中心
15、SpringCloud config
15.1、分布式系统面临的问题
配置问题:
到目前为止,我们对 Eureka、Robbin、OpenFeign、Hystrix、Gateway
等有了相应的了解,每个微服务都是单独一个模块,微服务彼此还支持集群
环境。
但是在微服务项目的开发中,还面临着一个严重的配置问题。每一个微服务
都需要一个配置文件,如果有几个微服务需要连接数据库,name就需要进
行 4 次数据库的配置。当数据库发生改变,那么就需要同时修改 4 个微服
务的配置文件才可以。那么如果有40台呢?如果是集群模式呢??
如果能够做到:一处修改、处处生效,这样就可以减轻修改配置压力,从而
增强配置管理方面的功能,此时就需要 Spring Cloud Config 和 Spring
Cloud Bus 上场了。
使用 Config + Bus,可以实现 :
一处修改、处处生效
灵活的对版本(dev/test/prod)进行切换,这样就足够方便了
15.2、是什么:
https://cloud.spring.io/spring-cloud-static/spring-cloud-config/2.2.1.RELEASE/reference/html/
Springcloud config为微服务架构中的微服务提供集中化的外部配置支持,
配置服务器为各个不同微服务应用的所有环境提供一个中心化的外部配
置。各个不同微服务应用 Springcloud config为微服务架构中的微服务提
供集中化的外部配置支持,配置服务器为各个不同微服务应用的所有环境
提供一个中心化的外部配置。中心化的外部配置。
15.3、怎么用:
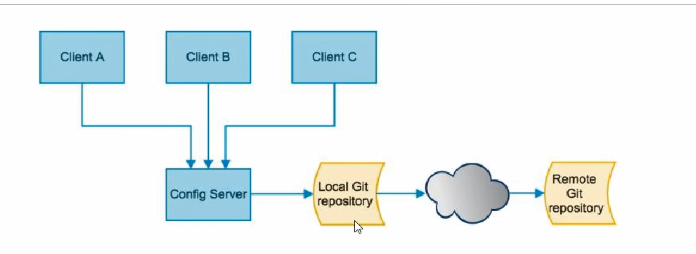
Springcloud Config分为服务端和客户端两部分。
服务端(Config Server):也称分布式配置中心,它是一个独立的微服
务应用,用来连接配置服务器并未客户端提供获取配置信息,加密、解
密信息等访问接口。
客户端:通过指定的 配置中心(Config Server) 来管理应用资源,以及与业务相关的配置内容,并在启动的时候从 配置中心 获取和加载配置信息。
15.4、作用
集中管理配置文件
不同环境不同配置,动态化的配置更新,分环境部署比如
dev/test/prod/beta/release
运行期间动态调整配置,不再需要字啊每个服务器的机器上编写配置文
件,服务会向配置中心同意拉去配置自己的信息
当配置发生变动时,服务不需要重启即可感知到配置的变化并应用新的
配置
将配置信息以REST接口的形式暴露
- post,curl访问刷新均可
15.5、与GitHub整合配置
由于SpringCloud Config默认使用Git来存储配置文件(也有其他方式,比
如注册SVN和本地文件),但最推荐的还是Git,而且使用的是http/https服
务的形式。
步骤:
创建存储 Config 的新 Repository
将新建的GitHub远程仓库克隆到本地
Repository 创建成功,即可获取自己的仓库地址,将项目克隆到本
地,方便对数据的修改。(GitHub 也支持直接修改,你也可以不克
隆,此处克隆只是为了更方便处理数据。)
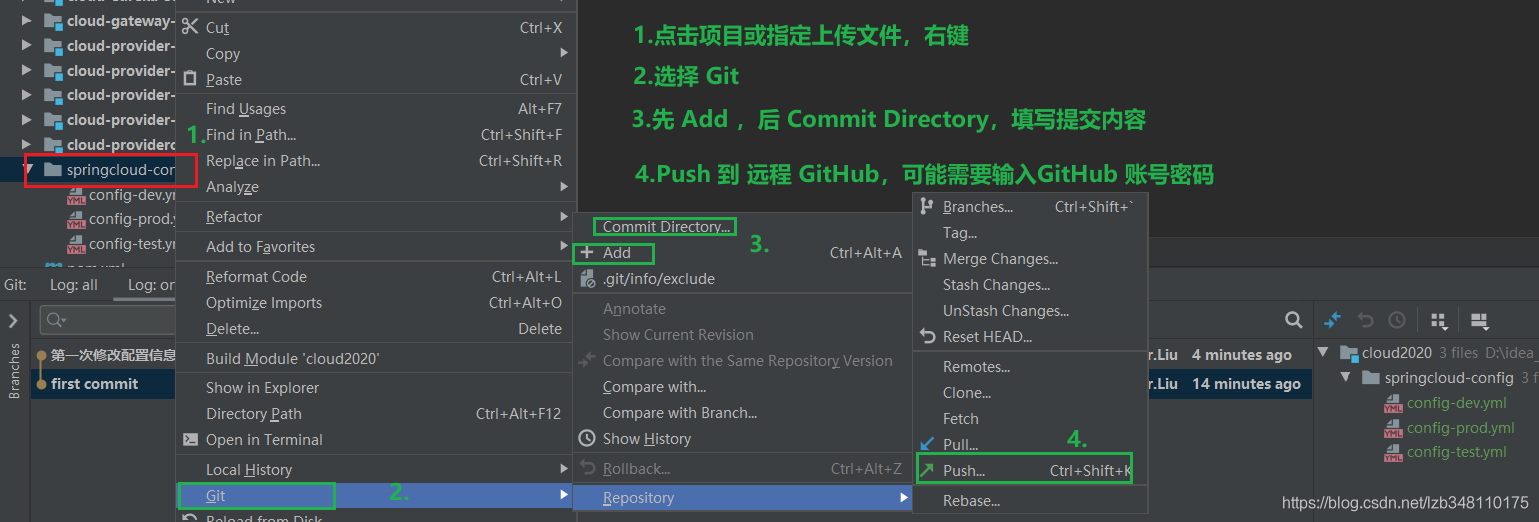
进入克隆目录,新建三个配置文件,分别是
config-dev.yml**、config-test.yml、config-prod.yml**。然后通过命令将其推送到远程GitHub仓库。1
2
3git add *.yml(将提交的文件加入暂存区,为git commit做准备)
git commit -m “first commit” (完成对文件内容提交至Git版本库)
git push -u origin master(将本地仓库内容,推送至GitHub远程仓库)对配置修改后,通过以上三个命令,便可以再次将修改后的内容推送至 GitHub。你也可以使用 IDEA 等工具进行
Github 远程仓库内容
服务端配置测试 (Config 结构图中的 Config Server)
pom:
1
2
3
4
5<!--引入spring-cloud-config-server依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>配置文件 application.yml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22server:
port: 3344 #端口号
spring:
application:
name: cloud-config-center #注册进Eureka 服务器的微服务名
cloud:
config:
server:
git:
uri: https://github.com/Liuzebiao/springcloud-config.git #GitHub远程仓库地址
# 搜索目录
search-paths:
- springcloud-config
#读取分支
label: master
#服务注册到eureka
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka主启动类 配置**@EnableConfigServer**注解
GitHub配置文件读取规则:
远程 GitHub 仓库,配置文件的命名也是有具体规则的。Spring Cloud
Config 官方共支持 5 种方式的配置(https://cloud.spring.io/spring-cloud-static/spring-cloud-config/2.2.1.RELEASE/reference/html/#_quick_start
参数说明:
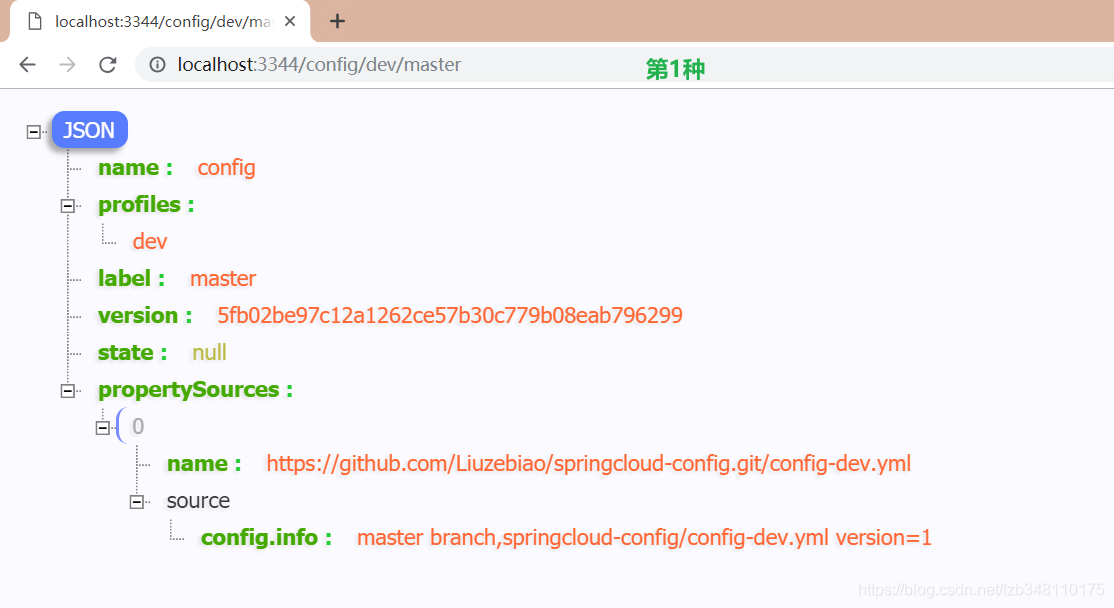
label:GitHub 分支(branch)名称application:服务名profile:环境(dev/test/prod)
/{application}/{profile}/{label}:
返回的是 Json 对象,需要自己解析所要的内容
/{application}-{profile}.yml:
(这种不带label方式,默认使用application.yml 配置)因为
applicaiton.yml 文件已经有配置过 label,不带label 方式,默认走
的就是 yml 配置的 label,返回的是配置内容

/{label}/{application}-{profile}.yml:
(推荐使用第三种)这种方式简明扼要,条理清晰,返回的是配置内
容

/{application}-{profile}.properties:
同第2种
/{label}/{application}-{profile}.properties:
同第3种
客户端配置测试 (Config 结构图中的 Client A、Client B、Client C)
依赖pom:
1
2
3
4
5<!--引入spring-cloud-starter-config依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>配置文件 bootstrap.yml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19server:
port: 3355 #端口
spring:
application: #名称
name: config-client
cloud:
#config客户端配置
config:
label: master #分支名称
name: config #配置文件名称
profile: dev # 读取后缀名称 上述3个综合:master分支上config-dev.yml 的配置文件被读取(http://config-3344.com:3344/master/fongig-dev.yml)
uri: http://localhost:3344 #配置中心地址
#服务注册到eureka地址
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka主启动类 配置**@EnableConfigServer**注解
controller业务类:
1
2
3
4
5
6
7
8
9
10
11
public class ConfigClientController {
//通过这种方式,可以直接读取ConfigServer中的配置信息
private String configInfo;
public String getConfigInfo(){
return configInfo;
}
}启动测试:http://localhost:3355/configInfo
15.6、bootstrap.yml与application.yml
applicaiton.yml是用户级的资源配置项
bootstrap.yml是系统级的,优先级更加高
Spring Cloud会创建一个“Bootstrap Context”,作为Spring应用
的Application Context的父上下文。初始化的时候,
BootstrapContext负责从外部源加载配置属性并解析配置。这两个上下
文共享一个从外部获取的Environment。
“Bootstrap”属性有高优先级,默认情况下,它们不会被本地配置覆
盖。Bootstrap context和Application Context有着不同的约定,所
以新增了一个bootstrap.yml’文件,保证Bootstrap Context和
Application Context配置的分离。
要将Client模块下的application.yml文件改为bootstrap.yml,这是很关
键的,因为bootstrap.yml是比application.yml先加载的。bootstrap.yml
优先级高于application.yml。
15.7、分布式配置的动态刷新问题
POM引入actuator监控
1
2
3
4
5<!--引入actuator监控-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>修改YML,暴露监控接口
1
2
3
4
5management:
endpoints:
web:
exposure:
include: "*"@RefreshScope业务类Controller修改
需要运维人员发送Post请求刷新3355客户端
- 必须是POST请求
- curl -X POST “http://localhost:3355/actuator/refresh"
15.8、残留问题
假如有 N 多个台,就需要 N 多次的curl的手动刷新
解决想法:
大规模
微服务/集群模式**,我们可以采用广播的方式,一次通知,处处生效。类似于 **消息队列的 Topic,**微信公众号** 的概念,一次订阅,所有订阅者都能接收到新消息。无法实现精确通知,只通知集群中的某些服务(精确通知,比如有100台机器,只通知前98台)
解决以上两个问题的方法:bus消息总线
消息总线
16、SpringCloud Bus
16.1、是什么
https://cloud.spring.io/spring-cloud-static/spring-cloud-bus/2.2.1.RELEASE/reference/html/
在微服务架构的系统中,通常会使用轻量级的消息代理来构建一个共用的消
息主题,并让系统中所有的微服务实例都连接上来。由于该主题中产生的消
息会被所有实例监听和消费,所以称它为消息总线在总线上的各个实例,都
可以方便的广播一些需要让其他链接在该主题上的实例都知道的消息。
Spring Cloud Bus 是用来将 分布式系统的节点与 轻量级消息系统连接起来
的框架,它整合了 Java 的事件处理机制和消息中间件的功能。Spring
Cloud Bus 目前仅支持RabbitMQ和Kafka。
16.2、作用
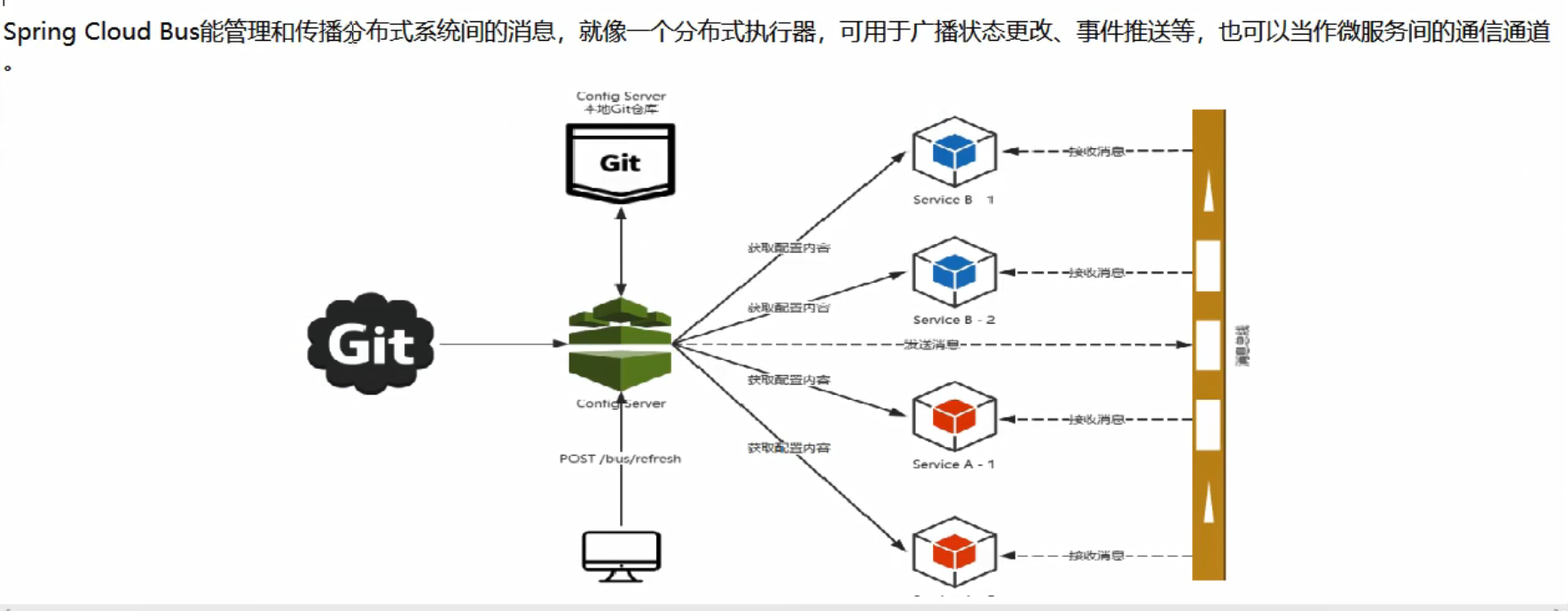
Spring Cloud Bus能管理和传播分布式系统间的消息,就像一个分布式执行
器,可用于广播状态更改,事件推送等,也可以作为微服务的通信通道。
16.3、基本原理与执行流程
ConfigClient实例都监听MQ中的同一个topic(默认是SpringcloudBus)。
当一个服务刷新数据的时候,它会把这个信息放入到topic中,这样其它监
听同一个topic的服务就能得到通知,然后去更新自身的配置。其实就是通
过 MQ 消息队列的 Topic 机制,达到广播的效果。
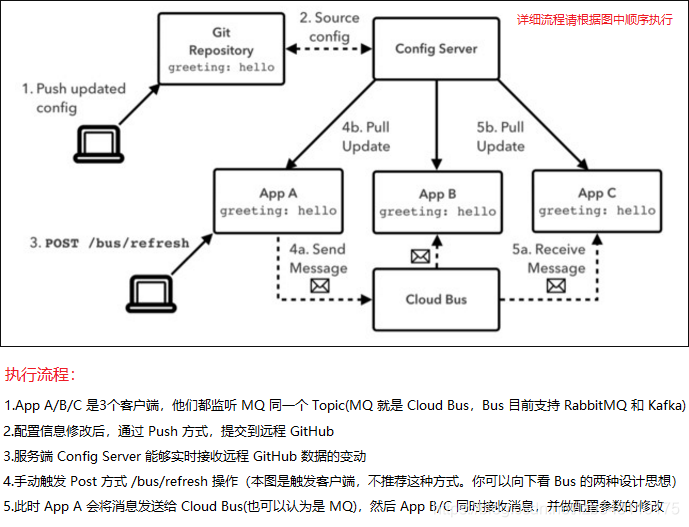
16.4、Bus的两种设计思想
触发客户端:
利用消息总线触发一个客户端的
/bus/refresh,而刷新所有客户端的配置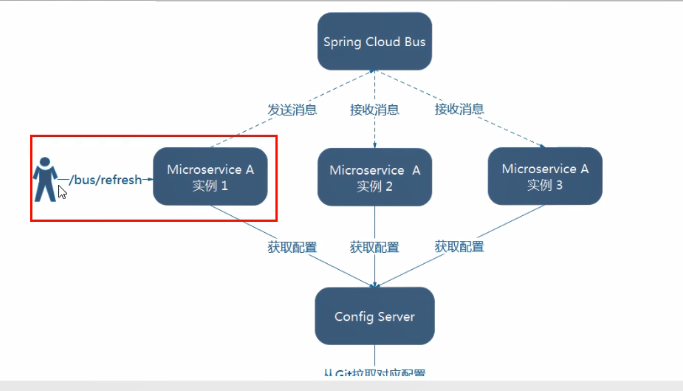
触发服务端:
利用消息总线触发一个服务端ConfigServer的
/bus/refresh端点,而刷新所有客户端的配置
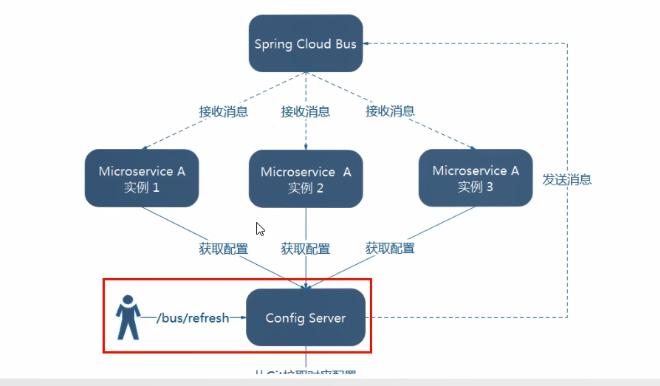
如何选型:
根据架构图显然第二种更加合适,所以推荐使用触发服务端 Config Server
的方式。第一种触发客户端方式 不适合的原因如下:
利用消息总线触发客户端方式,打破了微服务的职责单一性,因为微服
务本身是业务模块,它本不应该承担配置刷新的职责;
触发客户端方式,破坏了微服务各个节点之间的对等性(比如说:
3355/3366/3377 集群方式提供服务,此时 3355 还需要消息通知,影
响节点的对等性)
有一定的局限性。当微服务迁移时,网络地址会经常发生变化,如果此
时需要做到自动刷新,则会增加更多的修改。
16.5、Bus 动态刷新全局广播配置
集群版客户端组建(搭建两个或多个客户端)
服务端配置中心/客户端 pom 引入Bus总线依赖
1
2
3
4
5<!--添加消息总线支持-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-amqp</artifactId>
</dependency>服务端配置中心 application.yml 修改 (添加 rabbitmq 相关配置)
1
2
3
4
5
6
7
8
9
10
11
12
13
14#添加rabbitmq相关支持(新加)
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
#rabbitmq相关配置,暴露bus舒心配置的端点
management:
endpoints:
web:
exposure:
include: 'bus-refresh' #为什么配置 bus-refresh,看传染病那张图客户端 application.yml 修改 (同样添加 rabbitmq 相关配置)
1
2
3
4
5
6
7
8
9
10
11
12
13
14#添加rabbitmq相关支持
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
#暴露监控端点
management:
endpoints:
web:
exposure:
include: "*" #此处有很多选项可以配置,为了省事 ,直接配置 *启动模块,开始测试
启动:服务端配置中心 Config Server (3344)、客户端集群
(3355/3366)、Eureka Server(7001)。修改 GitHub 参数配置,然后向
服务端 发送 Post 请求,命令:
curl -X POST "http://localhost:3344/actuator/bus-refresh",当向 Config Server 发送 Post 请求后,总线上的各个实例(客户端
3355/3366 )都能够及时
监听和消费配置的变更。使用广播的方式,真正的实现 **
一处通知,处处生效**。使用 MQ 广播的方式,实现
一处通知,处处生效的效果。此时我们登陆Rabbit MQ 客户端,在
Exchanges模块,就能够看到一个叫做springCloudBus的Topic。与本文 2.2 Bus 原理 中介绍吻合:Config 客户端示例,都去监听 MQ
中的同一个 topic(默认是 springCloudBus)。当一个服务刷新数据
**的时候,它会把这个消息放入到 Topic 中,这样其他监听同一 Topic **
的服务就能够得到通知,然后去更新自身的配置。
16.6、Bus 动态刷新定点通知配置
如果需要差异化通知,并不想进行全局广播,此时就用到了 Bus 的定点通
知功能。
此次我们通过客户端集群(3344/3355)演示。GitHub 远程配置修改后 ,进
行差异化定点通知,只通知 3355,不通知 3366。此处命令和全局广播有点
不同,命令为:http://配置中心IP:配置中心的端口号/actuator/bus-
refresh/{destination}
通过指定 /bus/refresh请求不再发送到具体的服务实例上,而是发给
Config Server 并通过 {destination} 参数来指定需要更新配置的服务或实
例。
{destination} 参数 = 微服务名 :端口号。3355 微服务名为:config-
client。此处最终发送的 Post 请求命令为:curl -X POST http://localhost:3
344/actuator/bus-refresh/config-client:3355,真正的实现精确通知功
能。
消息驱动
17、Spring Cloud Stream消息驱动
17.1、目前微服务面临的问题
在项目开发中,常用的四种消息中间件:ActiveMQ、RabbitMQ、
RocketMQ、Kafka。由于每个项目需求的不同,在消息中间件的选型
上也就会不同。
在项目开发中,你会遇到以下一些问题:
自己学的是 RabbitMQ,公司用的却是 Kafka 。再学 Kafka?学习成本
太高,负担太重;
多部门配合,MQ差异化带来的联调问题。A部门使用 RabbitMQ 进行
消息发送,大数据部门却用 Kafka, MQ 选型的不同,MQ 切换、维
护、开发等困难随之而来。
有没有一种技术,可以让我们不再关注 MQ 的细节,只需要用一种适配绑
定的方式,就可以帮助我们自动的在各种 MQ 之间切换呢?答案就是
Spring Cloud Stream 消息驱动。
Spring Cloud Stream 消息驱动,它可以屏蔽底层 MQ 之间的细节差异。我
们只需要操作Spring Cloud Stream 就可以操作底层多种多样的MQ。从而
解决我们在 MQ 切换、维护、开发方面的难度问题。
17.2、是什么
https://spring.io/projects/spring-cloud-stream#overview
Spring Cloud Stream 是一个构建消息驱动微服务的框架。应用程序通过
inputs或者outputs来与 Spring Cloud Stream 中的 binder 对象交互。通
过我们的配置来进行 binding(绑定), 然后 Spring Cloud Stream 通过
binder 对象与消息中间件交互。所以,我们只需要搞清楚如何与 Spring
Cloud Stream 交互,就可以方便使用消息驱动的方式。
Spring Cloud Stream 通过使用 Spring Integration 来连接消息代理中间
件,以实现消息时间驱动。Spring Cloud Stream 为一些供应商的消息中间
件产品提供了个性化的自动配置发现,引用了发布-订阅、消费组、分区 三
个核心概念。目前仅支持RabbitMQ、Kafka。
一句话总结: Spring Cloud Stream 屏蔽了底层消息中间件的差异,降低
MQ 切换成本,统一消息的编程模型。开发中使用的就是各种xxxBinder
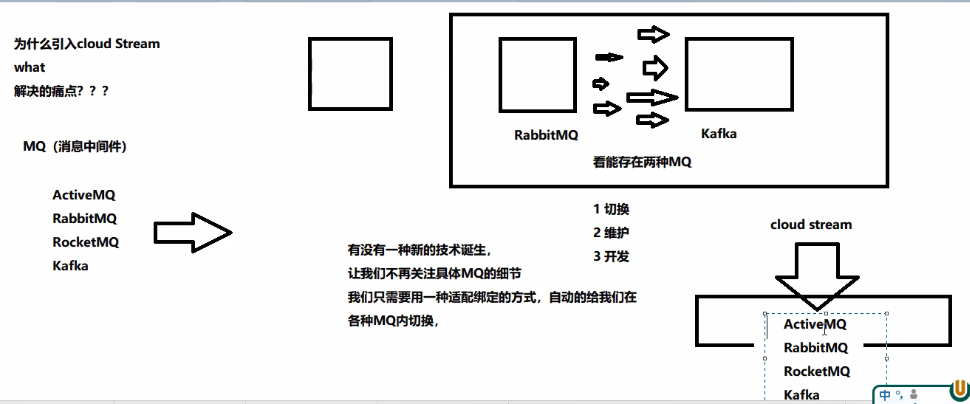
17.3、设计思想
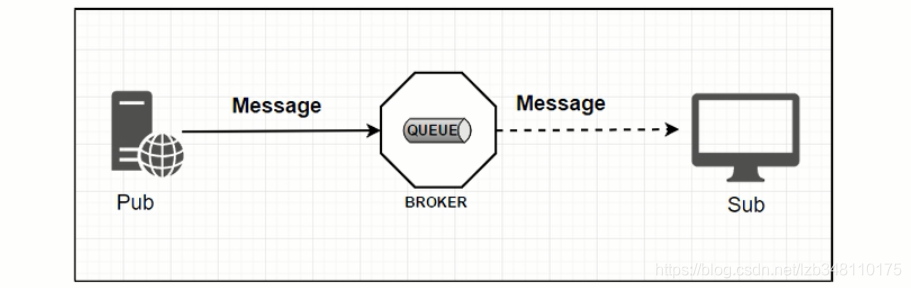
17.3.1、标志MQ
生产者/消费者 之间通过 消息媒介 传递消息内容
生产者/消费者之间靠消息媒介传递信息内容:Message
消息必须走特定的通道:MessageChannel
消息通道MessageChannel的子接口SubscribeChannel,由
MessageHandler消息处理器所订阅
结构图:
17.3.2、Spring Cloud Stream
比如说我们用到了RabbitMQ和 Kafka,由于这两个消息中间件的架构上的
不同。像RabbitMQ 有exchange、Kafka有Topic和Partions分区的概念。
这些中间件的差异性,给我们实际项目的开发造成了一定的困扰。我们如果
用了两个消息队列中的其中一个,后面的业务需求如果向往另外一种消息队
列进行迁移,这需求简直是灾难性的。因为它们之间的耦合性过高,导致一
大堆东西都要重新推到来做,这时候 Spring Cloud Stream 无疑是一个好的
选择,它为我们提供了一种解耦合的方式。
结构图:
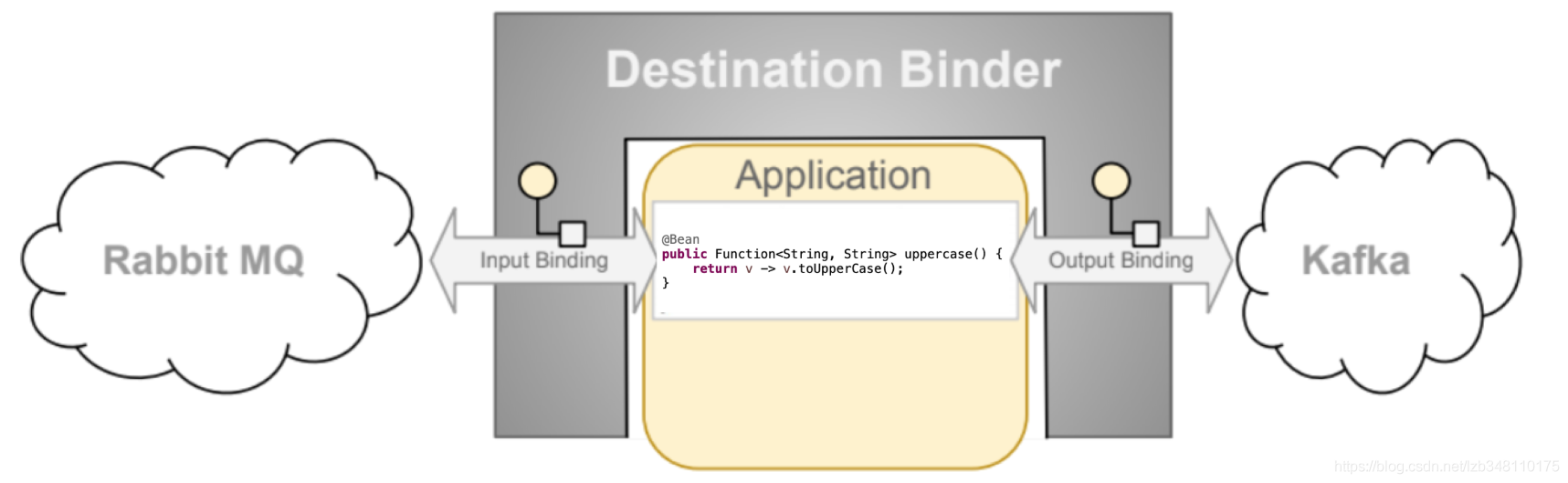
17.4、Spring Cloud Stream如何统一底层差异
在没有绑定器这个概念的情况下,我们的 Spring Boot 应用直接与消息中间
件进行信息交互时,由于个消息中间件构建的初衷不同,它们的实现细节上
会有较大的差异性。
通过定义绑定器(Binder)作为中间层,就可以完美的实现应用程序与消息中
间件细节的隔离。 通过向应用程序暴露统一的 Channel 通道,使得应用程
序不需要在考虑各种不同的消息中间件的实现。
17.5、Binder
在没有绑定器这个概念的情况下,我们的SpringBoot应用要直接与消息中
间件进行信息交互的时候,由于各消息中间件构建的初衷不同,它们的实现
细节上会有较大的差异性,通过定义绑定器作为中间层,完美地实现了应用
程序与消息中间件细节之间的隔离。Stream对消息中间件的进一步封装,
可以做到代码层面对中间件的无感知,甚至于动态的切换中间件(rabbitmq
切换为kafka),使得微服务开发的高度解耦,服务可以关注更多自己的业务
流程。
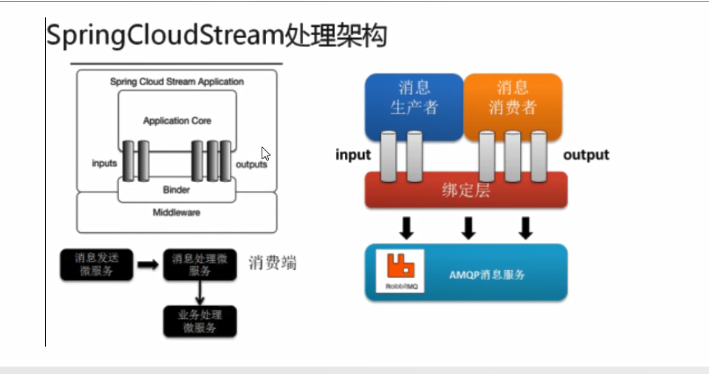
- INPUT:适用于消费者
- OUTPUT:适用于生产者
默认情况下,RabbitMQ Binder实现将每个目标映射到TopicExchange。
对于每个使用者组,队列都绑定到该 TopicExchange。 每个使用者实例在
其组的队列中都有一个对应的 RabbitMQ使用者实例。 对于分区的生产者
和使用者,队列以分区索引为后缀,并使用分区索引作为路由键。 对于匿
名使用者(没有组属性的使用者),将使用自动删除队列(具有随机的唯一
名称)。
17.6、Spring Cloud Stream 执行流程
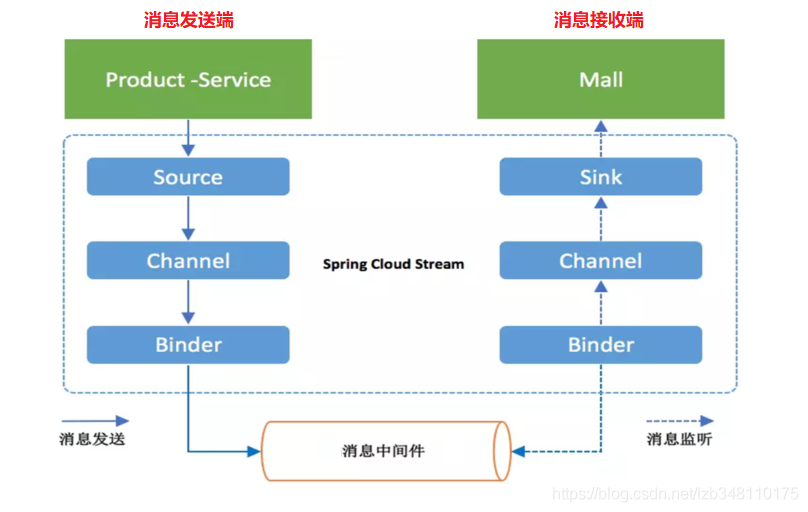
说明:
Source/Sink:Source 输入消息,Sink 输出消息Channel:通道,是队列 Queue 的一种抽象,在消息通讯系统中就是实现存储和转发的媒介,通过Channel 对队列进行配置;Binder:很方便的 **连接中间件**,屏蔽 MQ 之间的差异
17.7、编码API和常用注解

17.8、详细配置与代码
选用 RabbitMQ,在不需要任何 RabbitMQ 包依赖的基础上,使用 Spring
Cloud Stream 消息驱动来实现消息的发送&接收。
步骤:
生产者配置
依赖pom:
1
2
3
4
5<!--引入stream-rabbit依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>applicaiton.yml 配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34server:
port: 8801
spring:
application:
name: cloud-stream-provider
cloud:
stream:
binders: # 在此处配置要绑定的rabbitmq的服务信息;
defaultRabbit: # 表示定义的名称,用于binding整合(可以自定义名称)
type: rabbit # 消息组件类型
environment: # 设置rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
bindings: # 服务的整合处理
output: # 这个名字是一个通道的名称
destination: studyExchange # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
default-binder: defaultRabbit
binder: defaultRabbit # 设置要绑定的消息服务的具体设置(需与自定义名称一致)(飘红:Settings->Editor->Inspections->Spring->Spring Boot->Spring Boot application.yml 对勾去掉)
eureka:
client: # 客户端进行Eureka注册的配置
service-url:
defaultZone: http://localhost:7001/eureka
instance:
lease-renewal-interval-in-seconds: 2 # 设置心跳的时间间隔(默认是30秒)
lease-expiration-duration-in-seconds: 5 # 如果现在超过了5秒的间隔(默认是90秒)
instance-id: send-8801.com # 在信息列表时显示主机名称
prefer-ip-address: true # 访问的路径变为IP地址业务类:
controller
1
2
3
4
5
6
7
8
9
10
public class SendMessageController {
private IMessageProvider messageProvider;
public String sendMessage() {
return messageProvider.send();
}
}interface 接口
1
2
3public interface IMessageProvider {
public String send();
}service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//@EnableBinding 指信道channel和exchange绑定在一起
//@EnableBinding(Source.class) 就是将 Source(源) 放到 Channel 的意思
//定义消息的推送管道
public class MessageProviderImpl implements IMessageProvider {
private MessageChannel output; // 消息发送管道
public String send() {
String serial = UUID.randomUUID().toString();
output.send(MessageBuilder.withPayload(serial).build());
System.out.println("发送消息: "+serial);
return null;
}
}
测试启动:http://localhost:8801/sendMessage
可以看到后台有显示发送消息,进入 RabbitMQ 可视化界面,可以看到
有发送消息波峰出现。
消费者配置
依赖pom:
1
2
3
4
5<!--引入stream-rabbit依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>applicaiton.yml 配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32server:
port: 8802
spring:
application:
name: cloud-stream-consumer
cloud:
stream:
binders: # 在此处配置要绑定的rabbitmq的服务信息;
defaultRabbit: # 表示定义的名称,用于于binding整合(可以自定义名称)
type: rabbit # 消息组件类型
environment: # 设置rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
bindings: # 服务的整合处理
input: # 这个名字是一个通道的名称
destination: studyExchange # 表示要使用的Exchange名称定义
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: defaultRabbit # 设置要绑定的消息服务的具体设置(需与自定义名称一致)(飘红:Settings->Editor->Inspections->Spring->Spring Boot->Spring Boot application.yml 对勾去掉)
eureka:
client: # 客户端进行Eureka注册的配置
service-url:
defaultZone: http://localhost:7001/eureka
instance:
lease-renewal-interval-in-seconds: 2 # 设置心跳的时间间隔(默认是30秒)
lease-expiration-duration-in-seconds: 5 # 如果现在超过了5秒的间隔(默认是90秒)
instance-id: receive-8802.com # 在信息列表时显示主机名称
prefer-ip-address: true # 访问的路径变为IP地址业务类:
1
2
3
4
5
6
7
8
9
10
11
public class ReceiveMessageListenerController {
private String serverPort;
public void input(Message<String> message) {
System.out.println("1号消费者,接收:"+message.getPayload()+"\t port:"+serverPort);
}
}启动测试:启动 RabbitMQ,调用http://localhost:880/sendMessage
进行消息发送,可以看到消费者后台在实时接收消息。
这样,我们并没有引入任何相关 RabbitMQ 包,也并不了解 Rabbit MQ。
便能够使用 Rabbit MQ 进行 **消息发送 & 接收**。这就是Spring Cloud
Stream 消息驱动的优越之处。
17.9、Stream 重复消费/持久化问题
17.9.1、重复消费问题
当集群方式进行消息消费时,就会存在消息的重复消费问题。比如支付微服
务,购物支付完成后,消息重复消费就会导致支付多次的问题出现,这显然
是不能接受的。
这是因为没有进行分组的原因,不同组就会出现重复消费;同一组内会发生
竞争关系,只有一个可以消费。 如果我们不指定(8802、8803)集群分组信
息,它会默认将其当做两个分组来对待。这个时候,如果发送一条消息到
MQ,不同的组就都会收到消息,就会造成消息的重复消费。
解决方法:
只需要用到 Stream 当中 group 属性对消息进行分组即可。将8802、8803
分到一个组即可。(项目中,是否分组就视业务情况而定吧)
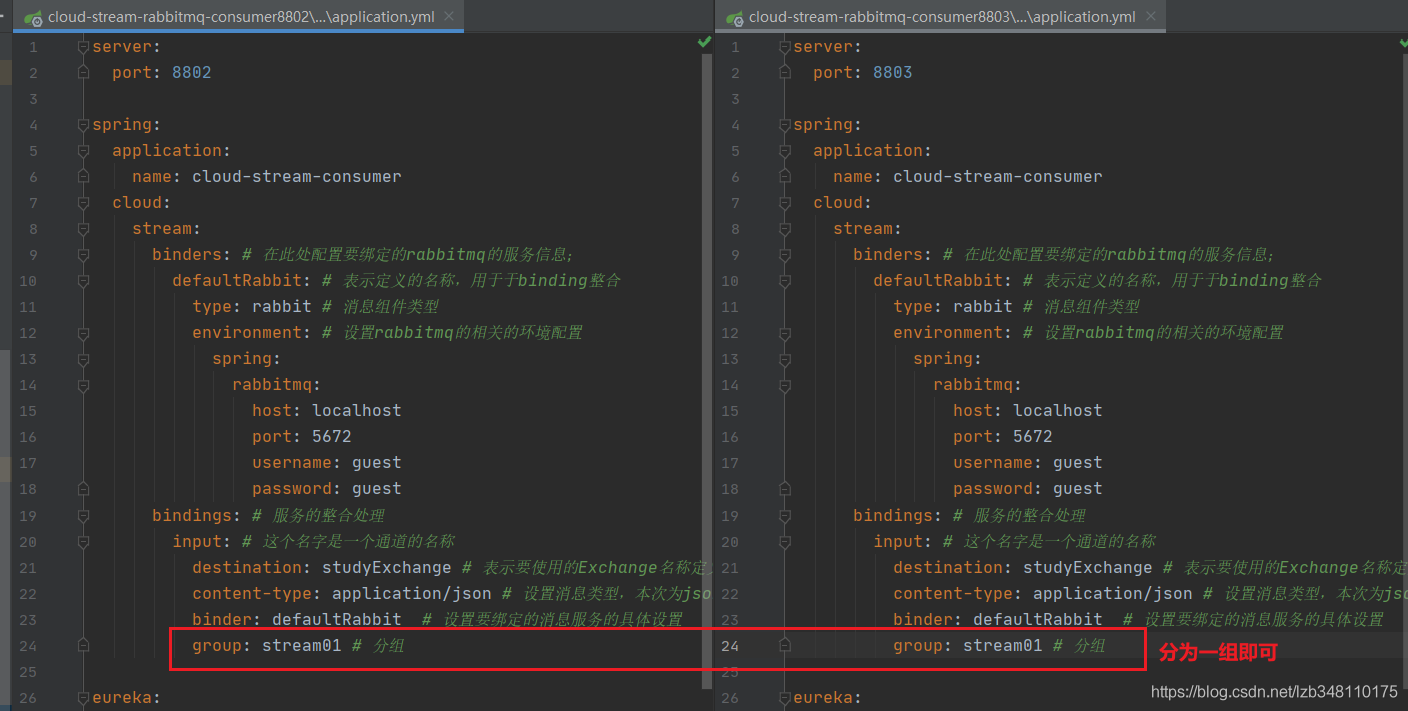
17.9.2、持久化问题
服务端发送消息时,此时客户端断开服务(宕机):若客户端没有分组,此
时客户端不会接收到服务端发送的消息,导致消息丢失。
解决方法:
加一个 group 分组属性就行了。如果有客户端有进行分组,重启之后则可
以消费待消费的消息。特别的,但多个客户端都为同一组时,既使其中有一
个客户端宕机,其同组的一个客户端也可以接收到消息,不会导致消息丢失
(无需重启)。
分布式链路追踪
18、Spring Cloud Sleuth + Zipkin 分布式链路追踪
18.1、目前微服务面临的问题
在微服务框架中,一个由客户端发起的请求,在后端系统中会经过多个不同
的微服务节点调用,协同操作产生最后的请求结果。每一个前端请求都会形
成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或者错
误,都会引起整个请求最后的失败。
18.2、是什么?
https://spring.io/projects/spring-cloud-sleuth#overview
Spring Cloud Sleuth 提供了分布式系统中一套完整的服务跟踪的解决方
案,并且兼容支持了zipkin,完美的解决了多个微服务之间链路调用的问
题。
一句话总结: 就是用来处理服务之间调用关系的。
18.3、调用结构图
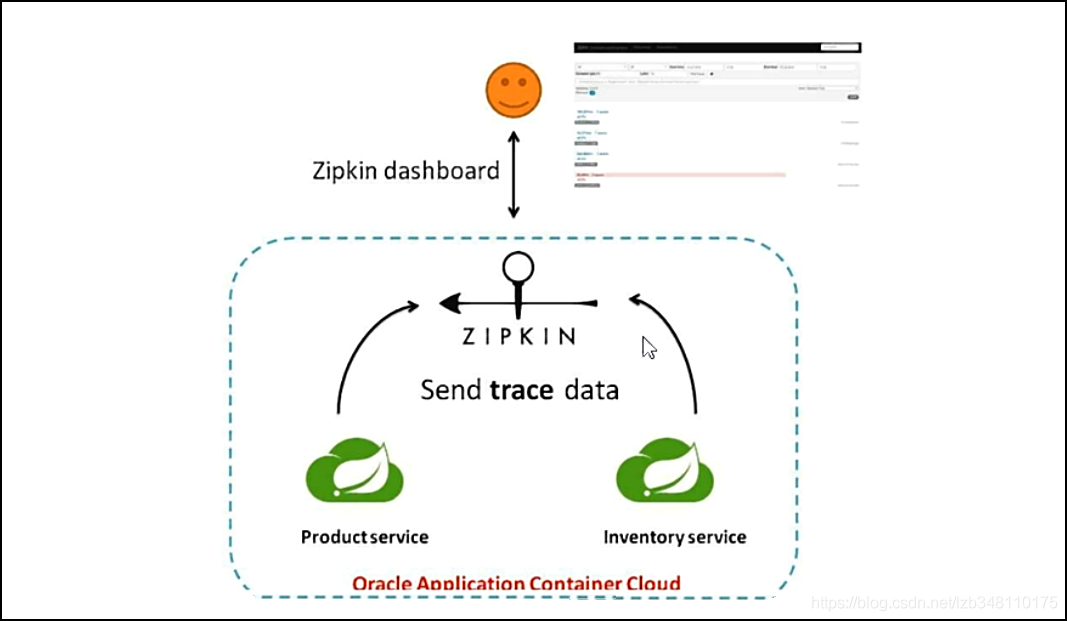
18.4、搭建链路监控步骤
18.4.1、环境准备
Zipkin 是 Twitter 的一个开源项目,允许开发者收集 Twitter 各个服务上的
监控数据,并提供查询接口。
我们需要先准备一个 Zipkin 环境。Spring Cloud 从F版起已不需要自己构
建Zipkin server了,只需要调用jar包即可。当前使用版本为 H版。我们只
需要下载 Zipkin jar包,在安装目录的路径下使用 java -jar xxx的方式启动
即可。点击链接:https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server ,下载 zipkin-server-2.12.9-exec.jar 。启动就OK了,如
图所示。
通过 http://loclahost:9411 就能进入到 Zipkin 为我们提供的可视化界面(中文)
一次请求完整的调用链路:
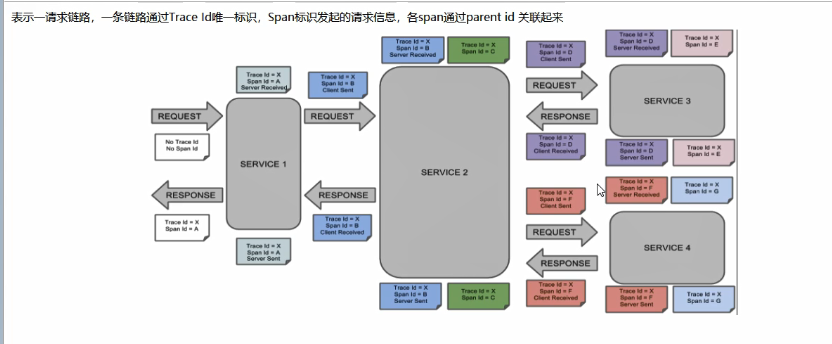
简单概述上图:
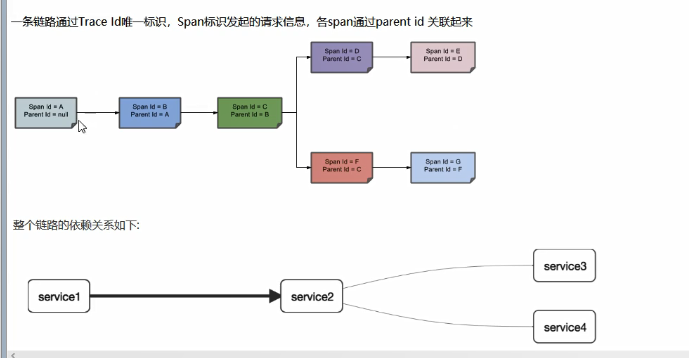
术词:
- Trace:类似于树结构的Span集合,表示一条调用链路,存在唯一标识
- span:表示调用链路来源,通俗的理解span就是一次请求信息
18.4.2、Sleuth测试环境搭建
服务端/客户端 进行相同配置
引入 zipkin + sleuth pom 依赖:
1
2
3
4
5<!--引入sleuth+zipkin依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>在 applicaiton.yml 添加 zipkin、sleuth 相同配置:
1
2
3
4
5
6
7
8
9spring:
# 应用名
application:
name: cloud-payment-service
zipkin:
base-url: http://localhost:9411 #监控数据要打到9411zipkin上
sleuth:
sampler:
probability: 1 #采样率值介于0到1,1则表示全部采集调用测试:
通过
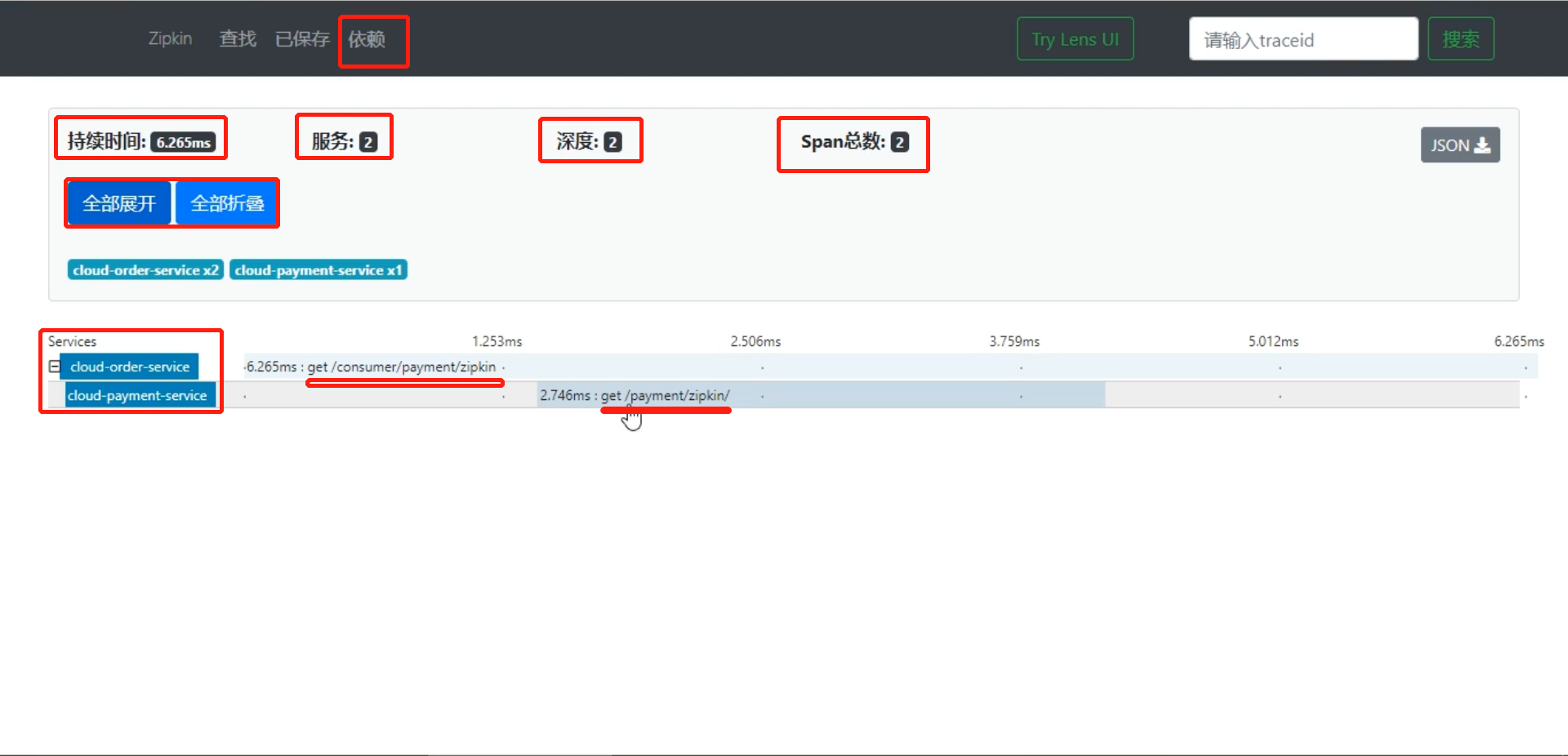
http://localhost/consumer/payment/get/31进行服务调用,调用成功后,我们打开
http://localhost:9411Zipkin 控制台就可以看到具体服务调用情况。
点击相对应请求,还可以看到
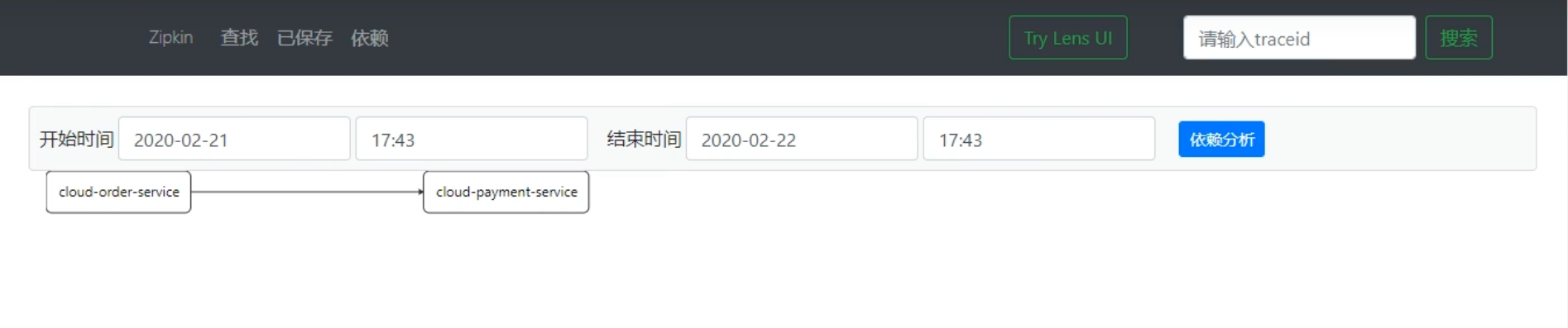
模块间调用情况**、调用耗时** 等更详细的信息。点击导航栏中的
依赖项,还可以查看模块(调用、被调用)的依赖关系等,链路调用关系一目了然。

点进每个具体的请求:
点进依赖:(查看微服务间的依赖关系)
Spring Cloud Alibaba
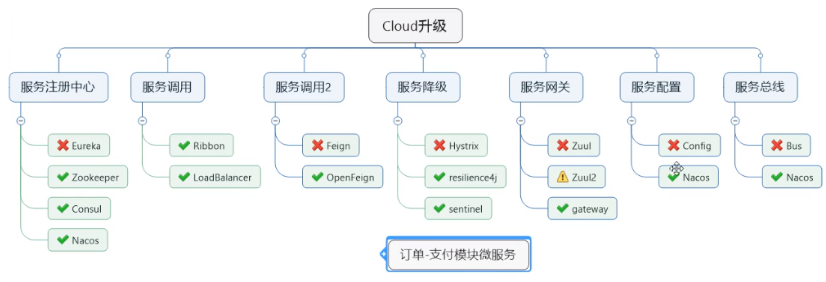
1、什么是维护模式
随着 Spring Cloud Netflix 项目进入维护模式(Maintenance Mode),Eureka、Hystrix、Ribbon、Zuul 等项目都进入了维护模式。
将模块置于维护模式意味着 Spring Cloud 团队将不再向该模块添加新功能。我们将修复block级别的bug和安全性问题,还将考虑并审查社区中的小请求。自 Spring Cloud Greenwich 版本发行(2018.12.12)以来,Spring Cloud 打算继续为这些模块提供至少一年的支持。(摘自:官网)
现在针对 Spring Cloud Netflix 相关模块已经不再提供支持。我们都知道 Spring Cloud 版本迭代算是比较快的,因而出现了很多重大ISSUE都还来不及Fix就又推出另一个 Release 版本了。进入维护模式意味着:以后一段时间 Spring Cloud Netflix 提供的服务和功能就这么多了,不再开发新的组件和功能了,这显然无法满足接下来微服务的开发要求。
伴随着 Spring Cloud Netflix 倒下,停更的组件自然就需要寻找替代者来继续下去。Alibaba 为了能够在微服务领域占据一定的话语权,此时便趁虚而入,将其代替,于2018.10.31 Spring Cloud Alibaba 正式入驻 Spring Cloud 官方孵化器,并在 Maven Spring Cloud for Alibaba 0.2.0 released。(附:Spring Cloud Alibaba 官方介绍)
2、Spring Cloud Alibaba
Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案。此项目包含开发分布式应用微服务的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发分布式应用服务。
依托 Spring Cloud Alibaba,您只需要添加一些注解和少量配置,就可以将 Spring Cloud 应用接入阿里微服务解决方案,通过阿里中间件来迅速搭建分布式应用系统。
2.1、Spring Cloud Alibaba包含的组件
- **
Sentinel**:阿里巴巴开源产品,把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。 - **
Nacos**:阿里巴巴开源产品,一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。 - **
RocketMQ**:Apache RocketMQ™ 基于 Java 的高性能、高吞吐量的分布式消息和流计算平台。 - **
Dubbo**:Apache Dubbo™ 是一款高性能 Java RPC 框架。 - **
Seata**:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。 - **
Alibaba Cloud OSS**:阿里云对象存储服务(Object Storage Service,简称 OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。 - **
Alibaba Cloud SchedulerX**:阿里中间件团队开发的一款分布式任务调度产品,支持周期性的任务与固定时间点触发任务。 - **
Alibaba Cloud SMS**:覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
2.2、主要功能
- **
服务限流降级**: 默认支持 WebServlet、WebFlux, OpenFeign、RestTemplate、Spring Cloud Gateway, Zuul, Dubbo 和 RocketMQ 限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级 Metrics 监控。 - **
服务注册与发现**: 适配 Spring Cloud 服务注册与发现标准,默认集成了 Ribbon 的支持。 - **
分布式配置管理**: 支持分布式系统中的外部化配置,配置更改时自动刷新。 - **
消息驱动能力**: 基于 Spring Cloud Stream 为微服务应用构建消息驱动能力。 - **
分布式事务**: 使用 @GlobalTransactional 注解, 高效并且对业务零侵入地解决分布式事务问题。。 - **
阿里云对象存储**: 阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据。 - **
分布式任务调度**: 提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有 Worker(schedulerx-client)上执行。 - **
阿里云短信服务**: 覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
3、学习组件
Alibaba Cloud OSS**、Alibaba Cloud SchedulerX、Alibaba Cloud SMS** 是阿里云相关的付费业务。接下来,我们主要介绍 Nacos、Sentinel、Seata 这三个模块。
4、官网资料
19、Spring Cloud Alibaba Nacos服务注册中心与配置中心
19.1、什么是 Nacos
Nacos(Dynamic Naming and Configuration Service):一个更易于构建云原生应用的动态服务发现,配置管理和服务管理中心。
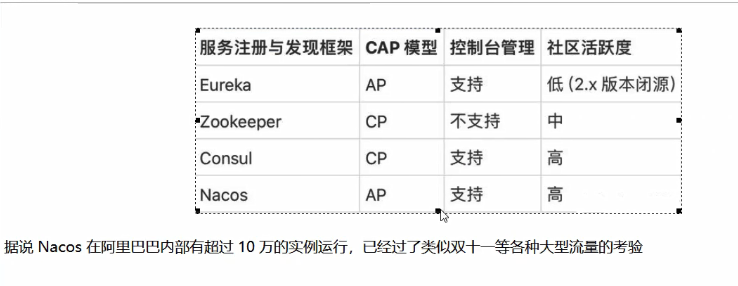
我们可以理解为:Nacos = 服务注册中心 + 配置中心;等价于 Nacos = Eureka + Spring Cloud Config + Spring Cloud Bus。
19.2、能干嘛
Nacos 可以替代 Eureka 来实现服务注册中心、可以替代 Spring Cloud Config 来实现服务配置中心、可以替代 Spring Cloud Bus 来实现配置的全局广播。Nacos 是更强调云原生时代支持 “服务治理、服务沉淀、共享、持续发展” 理念的注册中心和配置中心。(附:Nacos 官网与官方文档)
与各种注册中心比较(粗劣):
19.3、Nacos 安装运行
本地环境:java8+maven环境
从官网下载,你也可以选择指定版本下载:选择指定版本下载。此处以 window 版进行演示,后续 Nacos 集群环境会在 Linux 环境配置。
下载完成后,解压缩,直接运行 bin 目录下的startup.cmd,此处需注意:若你下载的nacos为较新版本,nacos默认是集群方式开启,会出现:nacos is starting with cluster,无法正常启动(此时nacos并未集群)。
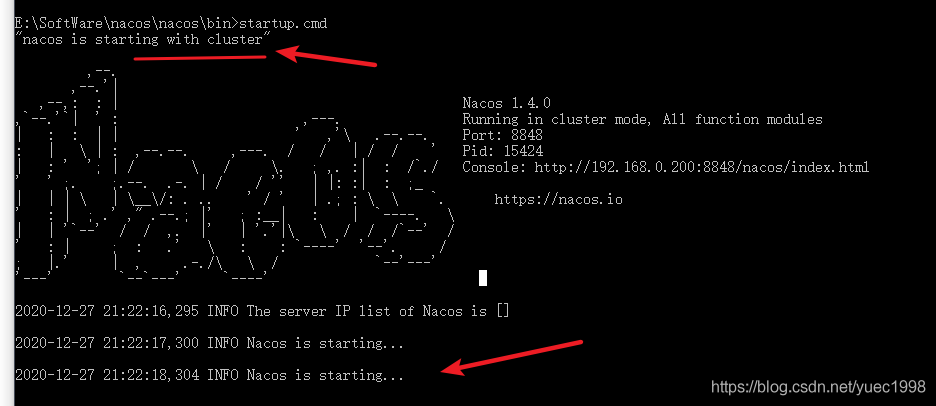
此时需以单机方式启动,执行以下命令startup.cmd -m standalone即可启动Nacos服务,我们可以看到它使用的是 8848 端口,启动结果如图所示:
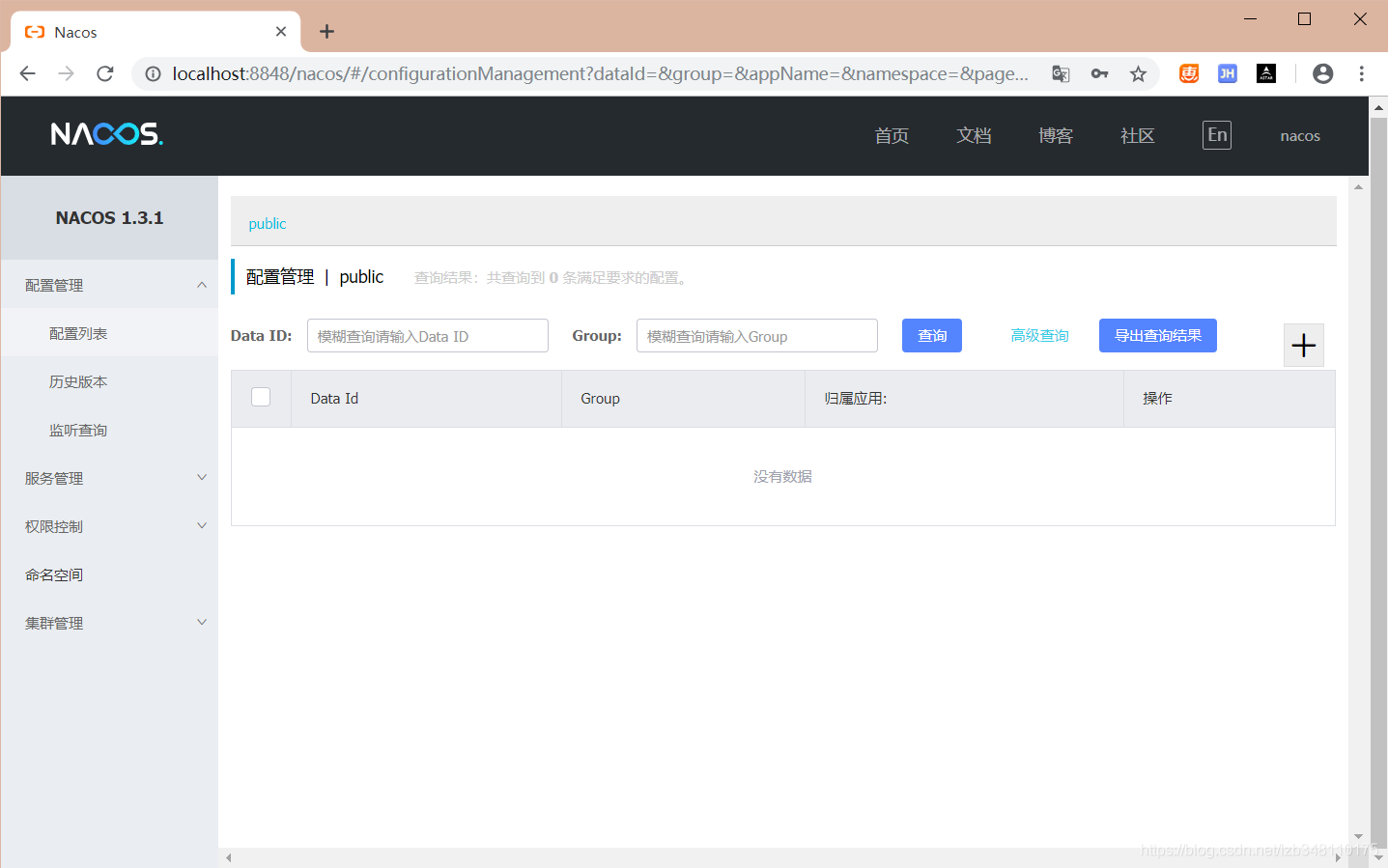
运行成功后,直接访问 http://localhost:8848/nacos 就可以进入 Nacos 的为我们提供的 web 控制台。**用户名、密码默认为 nacos**(1.2.0 版本不需要输入密码),控制台还是挺清新的哈,还提供中文支持。
19.4、Nacos与其他注册中心对比
Nacos和CAP:
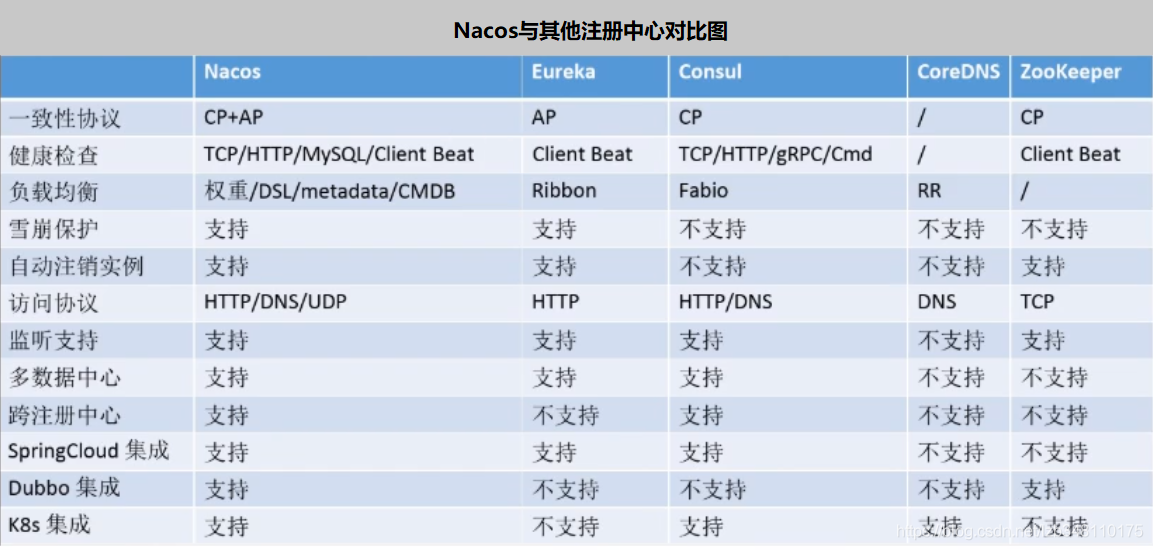
CAP:
C一致性A高可用P容错性。参考:CAP原则,主流选用的都是 AP 模式,保证系统的高可用。
何时选择使用何种模式?
一般来说,如果不需要存储服务级别的信息,且服务实例是通过Nacos-client注册,并能够保证心跳上报,那么就可以选择 AP 模式。当前主流的服务如 Spring Cloud 和 Dubbo 服务,都适用于 AP 模式,**AP模式为了服务的可用行而减弱了一致性,因此 AP 模式下只支持注册临时实例**。
如果需要在服务级别编辑或者存储配置信息,那么 CP 是必须的,K8S服务和DNS服务则适用于 CP 模式。CP模式下则支持注册**持久化实例,此时则是以Raft协议为集群运行模式,该模式下注册实例之前必须先注册服务,如果服务不存在,则会返回错误。**
而Nacos支持AP和CP模式的切换:
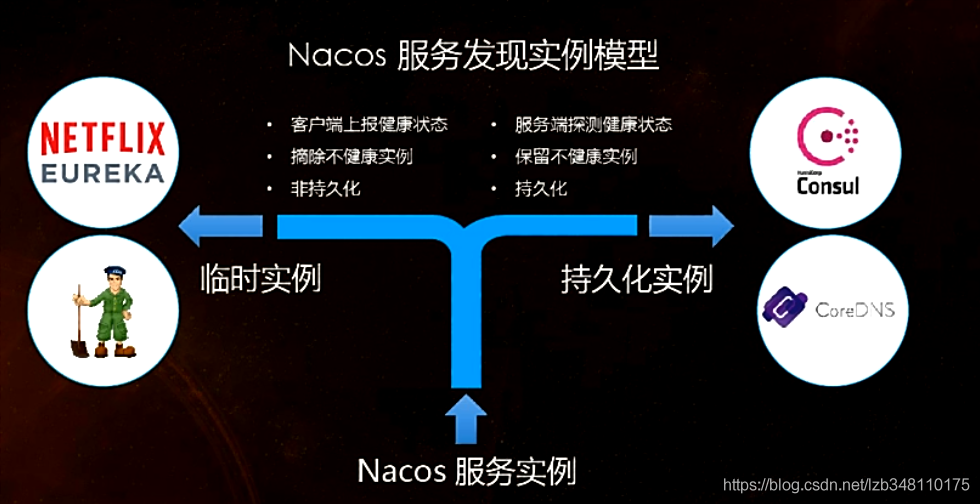
Nacos的全景图:
Nacos AP/CP模式切换:
Nacos 集群默认支持的是CAP原则中的 AP原则,但是也可切换为CP原则,切换命令如下:
1 | curl -X PUT '$NACOS_SERVER:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=CP' |
同时微服务的 bootstrap.yml需配置如下选项指明注册为临时/永久实例,AP模式不支持数据一致性,所以只支持服务注册的临时实例,CP模式支持服务注册的永久实例,满足配置文件的一致性。
1 | #false为永久实例,true表示临时实例开启,注册为临时实例 |
19.5、Nacos用作服务注册中心
Nacos 可以替代 Eureka 来作为 **服务注册中心**。附:Nacos 服务注册中心官方文档
基于Nacos的服务提供者(provider)
父pom引入spring-cloud-alibaba 依赖:
1
2
3
4
5
6
7
8<!--spring cloud alibaba 2.1.0.RELEASE-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.1.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>当前模块pom引入 nacos-discovery 依赖:
1
2
3
4
5<!--引入 nacos-discovery 依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>applicaiton.yml 文件配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14server:
port: 9021
spring:
application:
name: nacos-payment-provider
cloud:
nacos:
discovery:
server-addr: localhost:8848
management:
endpoints:
web:
exposure:
include: "*"主启动加上@EnableDiscoveryClient
业务类:
1
2
3
4
5
6
7
8
9
10
11
12
13
public class PaymentController {
private String serverPort;
public String getPayment( Integer id){
return "Alibaba Nacos registry,server "+ serverPort+"----- id:"+id;
}
}启动服务模块,查看服务是否注册到 Nacos
启动服务模块,进入 Nacos 控制台,在
服务管理 → 服务列表中可以看到,我们定义的服务名nacos-payment-provider已经成功注册到 Nacos 注册中心。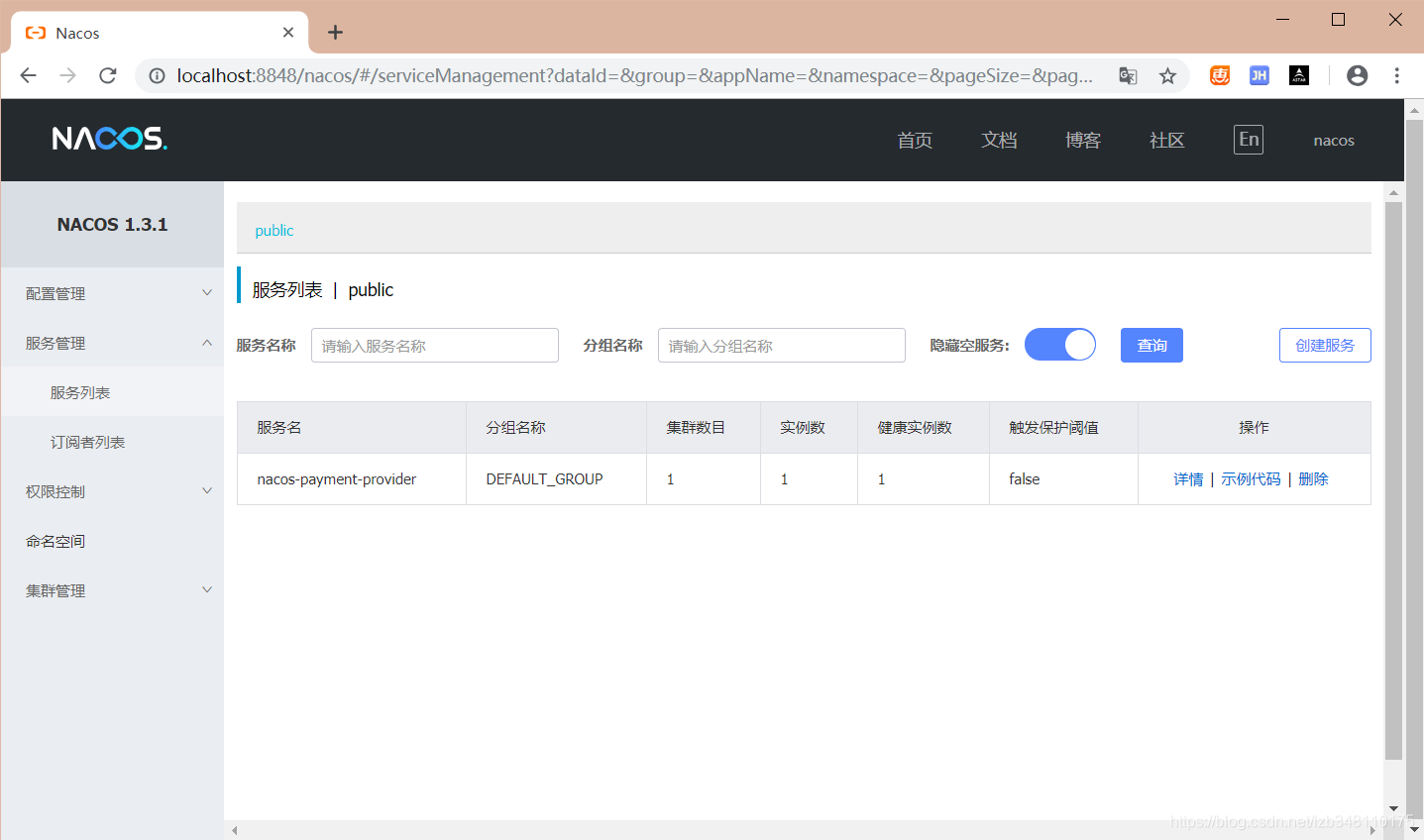
可以多来个服务端,与 9021 组成集群(9022、9023等等,做法与上一致)
提示:9022 和 9023 除端口外,其他配置都相同。在测试环境(只能在测试环境里用,可能出现未知的bug)使用时,此处还有个取巧的方法,**
可以通过直接拷贝虚拟端口映射,来创建 9002 模块**。我们使用 9021 来创建9022/9023,(实质端口为9021)如下图所示: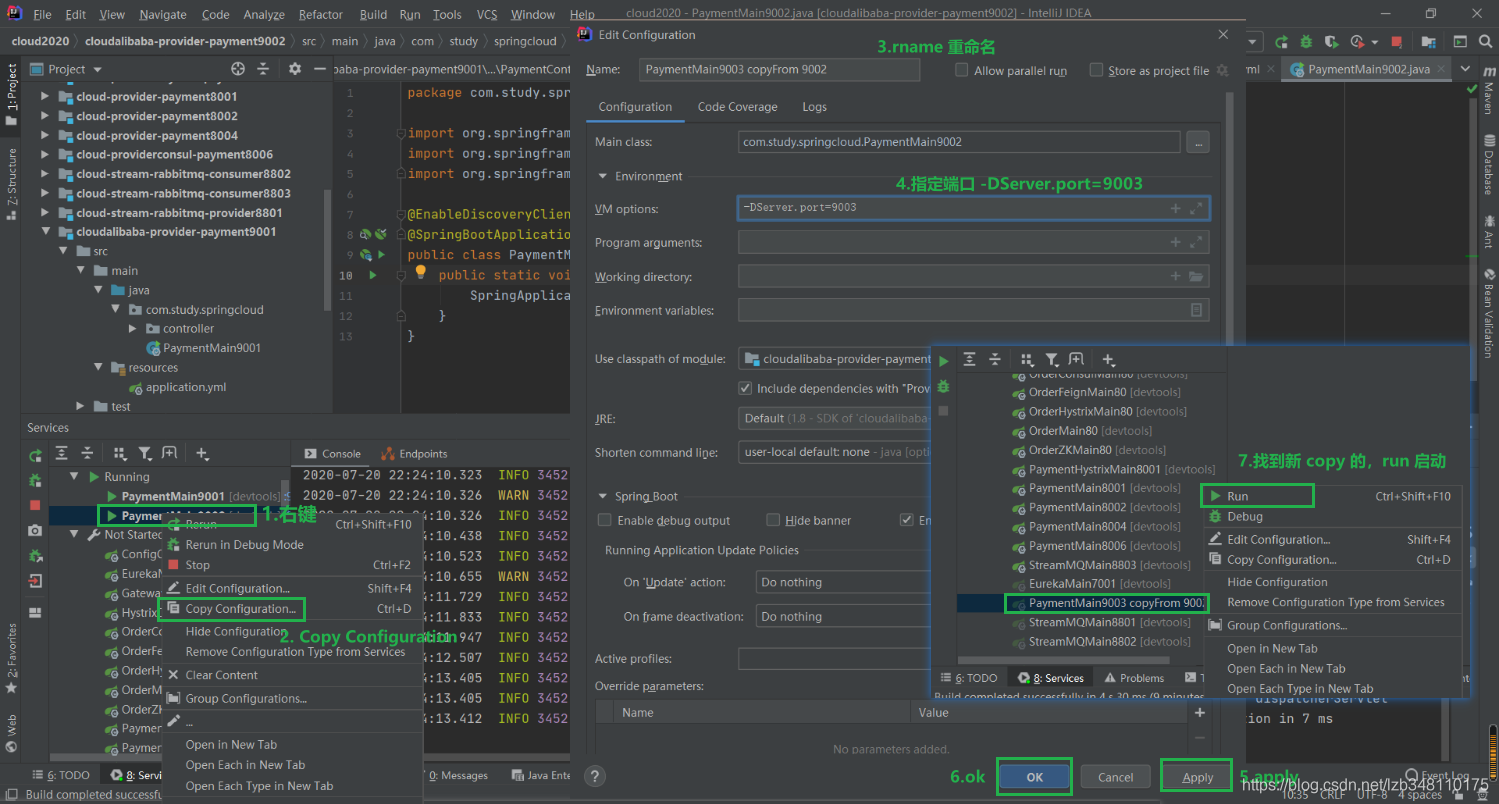
基于Nacos的服务消费者(consumer)
当前模块pom引入 nacos-discovery 依赖:
1
2
3
4
5<!--SpringCloud ailibaba nacos -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>Nacos 默认支持负载均衡
spring-cloud-starter-alibaba-nacos-discovery包里就整合有ribbon
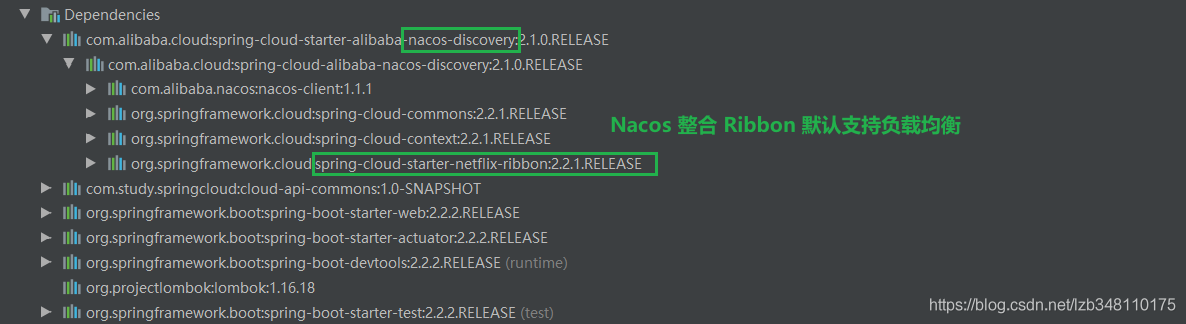
也就是说:我们可以使用ribbon的负载均衡与RestTemplate
applicaiton.yml 文件配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14server:
port: 83
spring:
application:
name: cloud-nacos-order
cloud:
nacos:
discovery:
server-addr: localhost:8848
#消费者将要去访问的微服务名称
server-url:
nacos-user-service: http://nacos-payment-provider主启动加注解@EnableDiscoveryClient
业务类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class OrderNacosController {
private RestTemplate restTemplate;
private String serverURL;
public String paymentInfo( Long id) {
return restTemplate.getForObject(serverURL+"/payment/nacos/"+id,String.class);
}
}RestTemplate配置类(注意加上@LoadBalanced实现负载均衡):
1
2
3
4
5
6
7
8
9
public class ApplicationContextConfig {
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
}启动服务消费者,查看服务是否注册到 Nacos
服务调用测试,是否实现负载均衡。通过服务端对客户端服务进行调用:http://localhost:83/consumer/payment/nacos/31。采用轮询的方式,实现了负载均衡。
也可以用OpenFeign+Nacos实现服务消费者(consumer)
引入 spring-cloud-openfeign 依赖:
1
2
3
4
5<!-- 引入 spring-cloud-openfeign 依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>application.yml配置同上(改端口也行)
主启动类加上@EnableDiscoveryClient与@EnableFeignClients两个注解。
编写OpenFeign的服务接口:
1
2
3
4
5
6
7
public interface OrderNacosService {
public String getPayment( Long id);
}此处注意:注解@FeignClient里的服务名”nacos-payment-provider”必须和服务提供端的yml配置一致,大小写敏感(Eureka 大小写不敏感,Nacos 不同,大小写会导致调用失败)
具体可参考ISSUE
业务类
1
2
3
4
5
6
7
8
9
10
11
12
public class OrderNacosController {
private OrderNacosService service;
public String paymentInfo( Long id){
return service.getPayment(id);
}
}启动测试
19.6、Nacos用作服务配置中心
19.6.1、Nacos作为配置中心–基础配置
当前模块 pom 引入 nacos-config 依赖:
1
2
3
4
5
6
7
8
9
10
11<!--引入nacos-config配置-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--注册到 Nacos,需引入nacos-discovery配置-->
<!--引入nacos-discovery配置-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>进行yml配置:
此处需要配置
bootstrap.yml和application.yml两个文件bootstrap.yml用作系统级资源配置项,application.yml用作用户级的资源配置项。在项目中两者配合共同生效,bootstrap.yml优先级更高。
bootstrap.yml:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
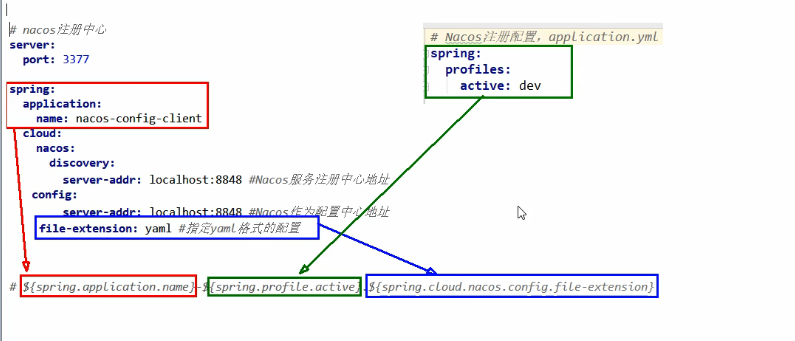
20# nacos配置
server:
port: 3377
spring:
application:
name: nacos-config-client
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
config:
server-addr: localhost:8848 #Nacos作为配置中心地址
file-extension: yaml #指定yaml格式的配置
# ${spring.application.name}-${spring.profile.active}.${spring.cloud.nacos.config.file-extension}
# nacos-config-client-dev.yaml
# nacos-config-client-test.yaml ----> config.infoapplication.yml:
1
2
3
4
5spring:
profiles:
active: dev # 表示开发环境
#active: test # 表示测试环境
#active: info主启动类添加 @EnableDiscoveryClient 注解
业务类:(添加 @RefreshScope 实现配置自动更新)
1
2
3
4
5
6
7
8
9
10
11
12
//支持Nacos的动态刷新功能
public class ConfigClientController {
private String configInfo;
public String getConfigInfo() {
return configInfo;
}
}Nacos中添加配置项:
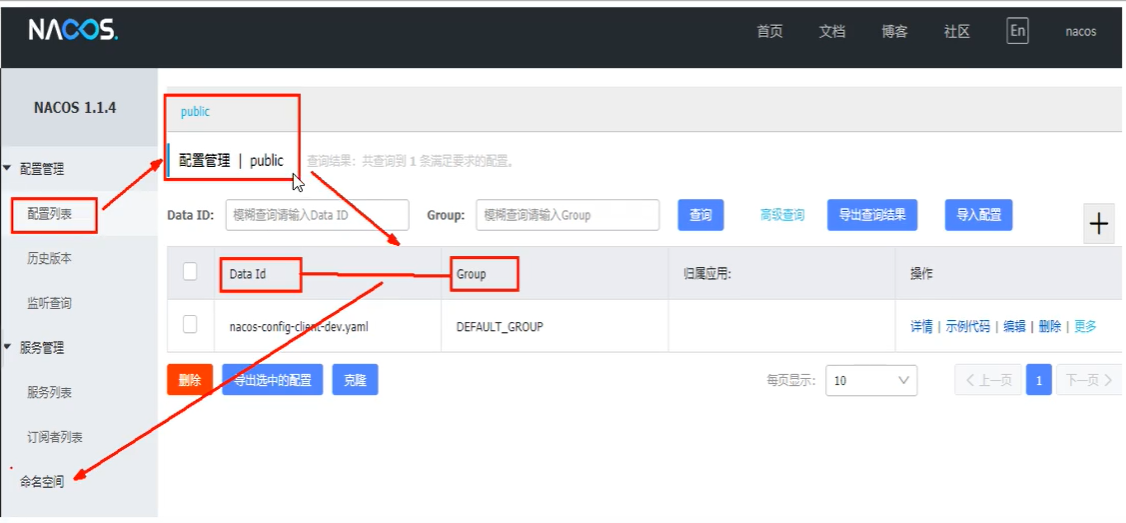
进入
Nacos → 配置管理 → 配置列表 → + 号添加配置项。Data ID 按规则编写,Group 在接下来的分类配置会有介绍。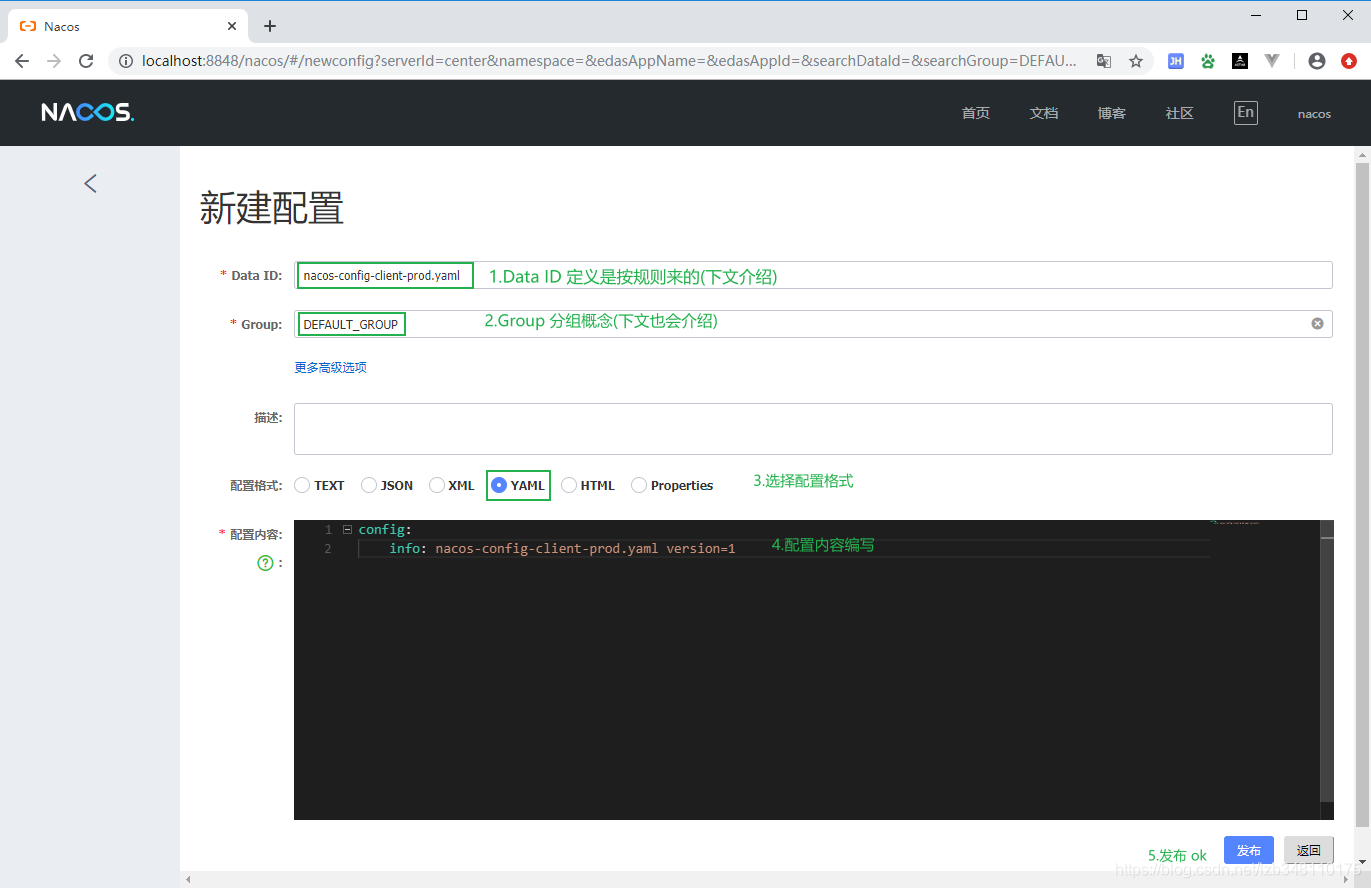
启动测试,是否能够获取Nacos配置:
通过 http://localhost:3377/config/info 测试,发现可以正确获取 Nacos 配置中心的配置信息

Nacos 自带动态刷新:
在使用 Spring Cloud Config 时,需要配合 Spring Cloud Bus + RabbitMQ 中间件,用
curl进行广播方式才能实现动态刷新**。Nacos则自带动态刷新,修改下Nacos中的yaml配置文件,再次调用查看配置的接口,就会发现配置已经刷新。**
19.6.2、dataId 命名规则
在 Nacos Spring Cloud 中, dataId 有明确的配置规则,官方也有说明。进入链接查看:官网链接。
dataId 的完整格式如下:
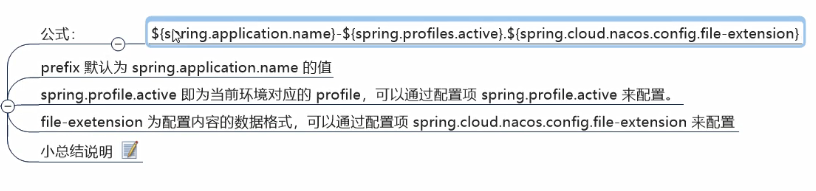
1 | ${prefix}-${spring.profile.active}.${file-extension} |
- prefix 默认为 spring.application.name 的值,也可以通过配置项 spring.cloud.nacos.config.prefix来配置。
- spring.profile.active 即为当前环境对应的 profile。注意:当 spring.profile.active 为空时,对应的连接符 - 也将不存在,dataId 的拼接格式变成 ${prefix}.${file-extension}(建议:不要让 spring.profile.active 为空,或许会有一些意外的问题,未知的bug)
- file-exetension 为配置内容的数据格式,可以通过配置项 spring.cloud.nacos.config.file-extension 来配置。目前只支持 properties 和 yaml 类型。
此处注意:在Nacos网页中进行添加配置项时,在填写Data ID需要注意,若你采用的是yaml格式的话,如nacos-config-dev.yaml中的yaml不能省略成yml,即nacos-config-dev.yml。若省略,程序启动会报错(找不到配置项config.info)。这是Nacos的一个小坑(bug)。
19.6.3、Nacos作为配置中心–分类配置
项目开发中,一定会遇到多环境、多项目管理问题。遇到下面问题时,Nacos 基础配置显然无法解决这些问题,接下来就对Nacos 命名空间及Group相关概念的了解。
- 问题1: 实际开发中,通常一个系统会准备
dev开发环境、test测试环境、prod生产环境,如何保证指定环境启动时服务能够正确读取到 Nacos 上相应环境的配置文件? - 问题2: 一个大型的分布式微服务系统会有很多个微服务
子项目,每个微服务项目又都会有相应的dev开发环境、test测试环境、prod生产环境等,那怎么对这些微服务配置进行管理呢?
这是就可以用到Nacos的分类功能了。
19.6.3.1、Nacos的命名规则说明
Nacos 命名由Namespace(命名空间) + Group(分组) + Data ID(实例ID) 三部分组成,类似于 Java 中的 package(报名) + class(类名) 方式。最外层 Namespace 用于区分部署环境;Group 和 Data ID 逻辑上用于区分两个目标对象。
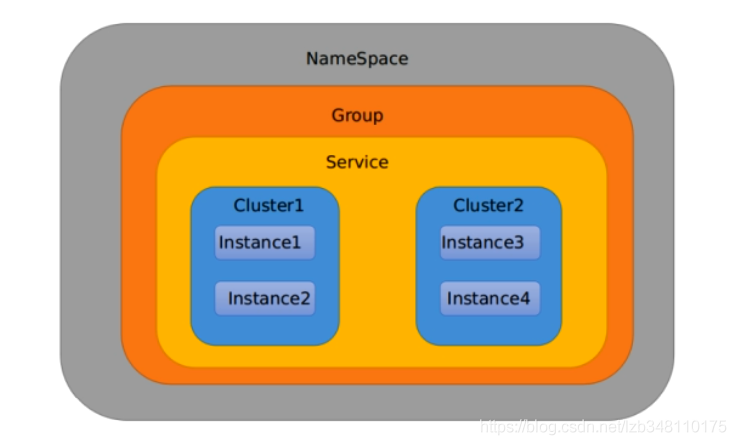
默认情况下:
Namespace = public,Group = DEFAULT_GROUP,Cluster=DEFAULT
Namespace**主要用来实现隔离**,Nacos 默认的命名空间是public。比方说我们现在有三个环境:开发、测试、生产环境,我们就可以创建三个 Namespace,不同的 Namespace 之间是隔离的;
Group**是一组配置集,是组织配置的维度之一。默认是DEFAULT_GROUP。通过一个有意义的名称对配置集进行分组,从而区分 Data ID 相同的配置集。配置分组的常见场景:不同的应用或组件使用了相同的配置类型,就可以把不同的微服务划分到同一个分组里面去,从而解决问题2;如 database_url 配置和 MQ_topic 配置。**
Service**微服务;一个 Service 可以包含多个Cluster(集群),Nacos 默认 Cluster 是DEFAULT,Cluster 是对指定微服务的一个虚拟划分。比方说为了容灾,将 Service 微服务分别部署在了杭州机房和广州机房,这是就可以给杭州机房的 Service 微服务起一个集群名称(HZ),给广州机房的 Service 微服务起一个集群名称(GZ),还可以尽量让同一个机房的微服务互相调用,以提升性能。**
Instance**,就是一个个微服务实例**。
保留空间public是不能被删除的。。
19.6.3.2、新建Namespace
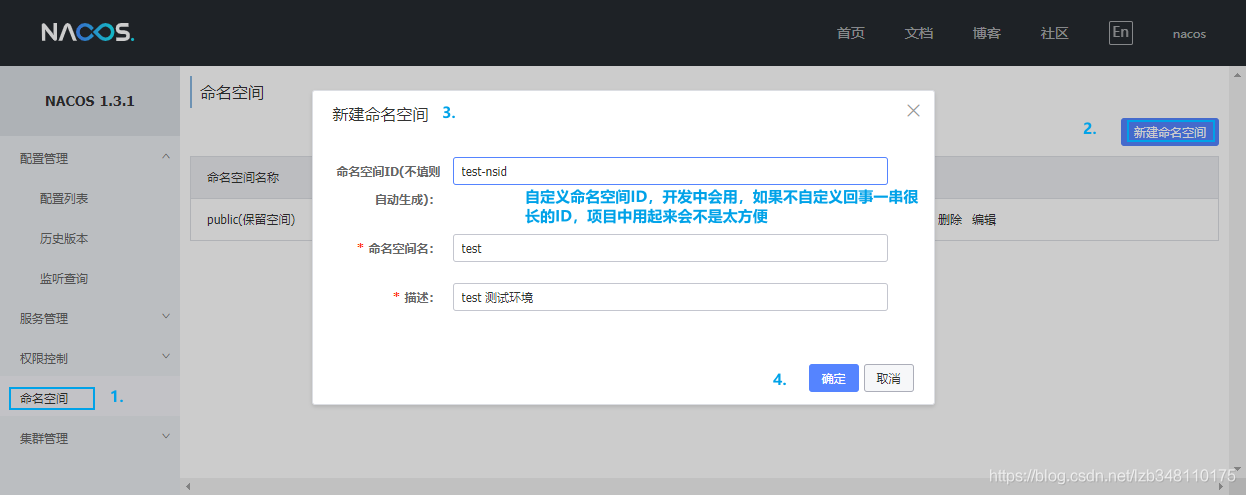
选择 命名空间 → 新建命名空间**,进行命名空间的设置。在 Nacos 1.1.4 版本,还不支持自定义命名空间ID,Nacos 1.2.0 版本后开始支持自定义命名空间ID 了。更推荐你使用自定义命名空间**。
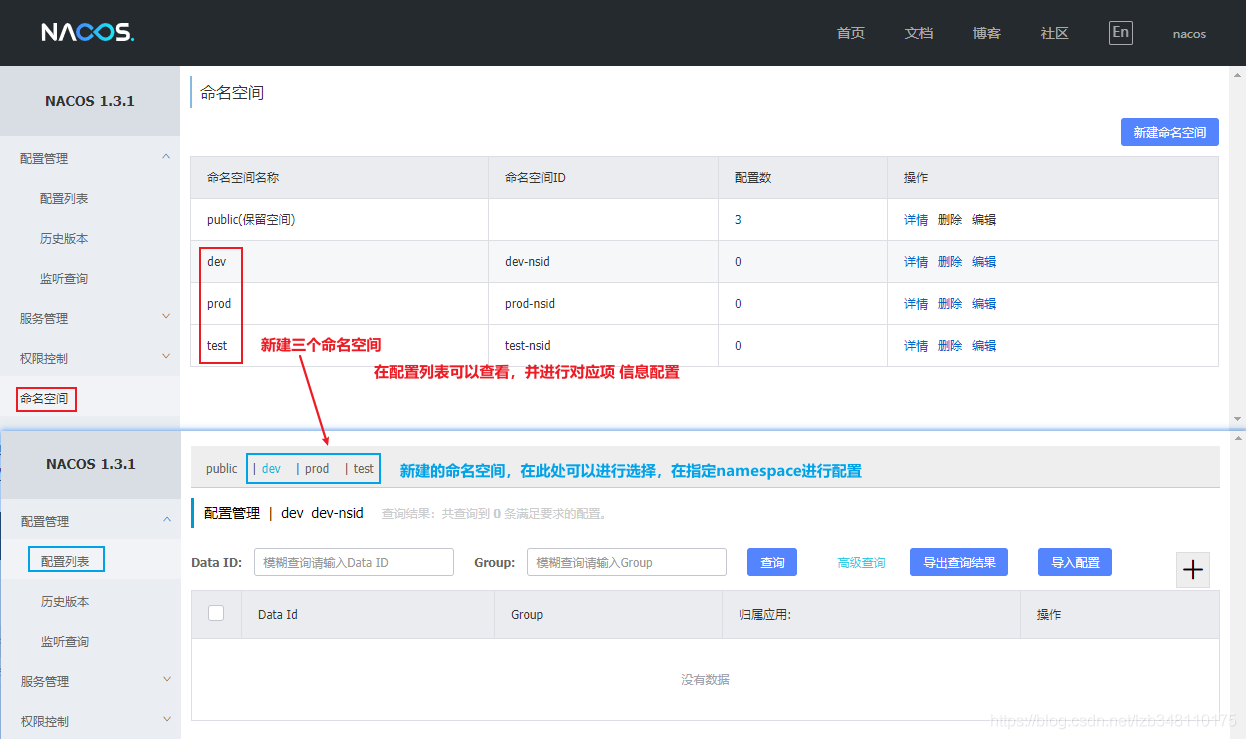
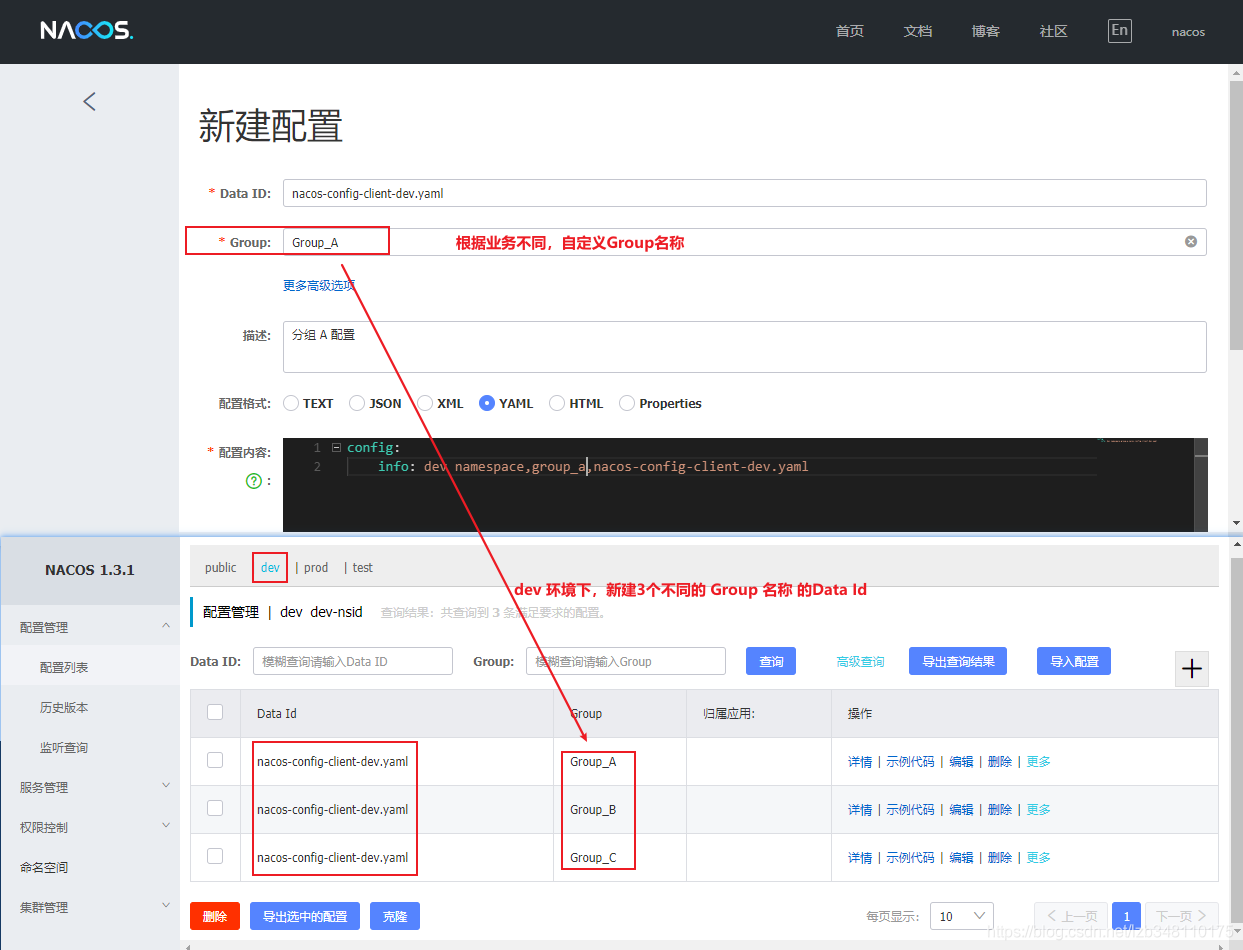
19.6.3.3、新建 Group
新建配置自定义Group名称。Group 就是根据需求的不同,将微服务划分到同一个分组里面去,来解决问题2
19.6.3.4、将 namespace 和 Group 应用到项目中
只需要在bootstrap.yml中添加 namespace 和 group 两个属性即可。**namespace** 属性:此处配置为 namespace **命名空间 ID**,自定义namespace时,推荐还是自定义名称,否则就是一串很长的字符串流水号,而且还语意不明。
1 | server: |
19.6.3.5、指定 namespace 和 group 后,读取的便是对应配置内容
19.7、Nacos 集群搭建和持久化配置(Linux + Mysql)
19.7.1、Nacos集群官方架构图
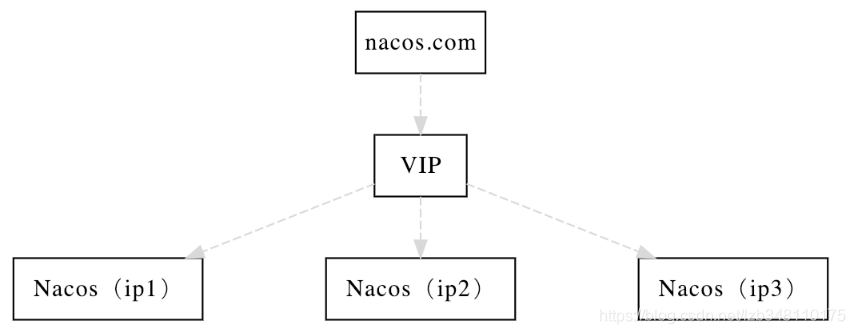
VIP:此处的 VIP 指代的是 Virtual IP(虚拟IP)的意思,通常情况下指代的是Nginx。
说明: 开源时,推荐用户把所有服务列表放到一个vip下面,然后挂到一个域名下面:
http://ip1:port/openAPI 直连ip模式,机器挂则需要修改ip才可以使用。
http://VIP:port/openAPI 挂载VIP模式,直连vip即可,下面挂server真实ip,可读性不好。
http://nacos.com:port/openAPI 域名 + VIP模式,可读性好,而且换ip方便,推荐模式。
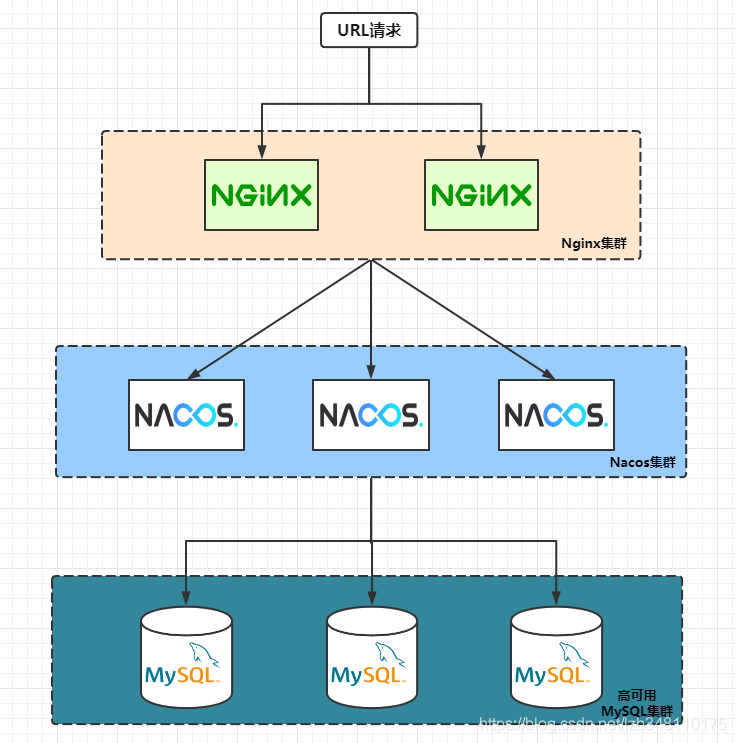
19.7.2、Nacos集群真实架构图
19.7.3、Nacos在linux下安装下载
1、在官网下载xxx.tar.gz文件,并转移进Linux服务器。
2、nacos 安装目录:/usr/local/nacos/
3、使用tar -zxvf 命令解压
19.7.4、Nacos数据库支持(derby )
手动将Nacos服务关闭再启动。存储在Nacos中的配置信息并不会丢失。这是因为 Nacos 默认内置DerBy数据库。 嵌入式数据库,nacos pom.xml 有引入derby依赖。以下摘自Nacos的github源码
1 | <dependency> |
Nacos的derby数据库记录的数据放在nacos安装目录下的/conf/nacos-mysql.sql的sql文件里。
在Nacos 0.7版本之前,在单机模式时nacos使用嵌入式数据库(derby)实现数据的存储,不方便观察数据存储的基本情况。0.7 版本增加了支持 mysql 数据源能力。 具体的操作步骤:
- 安装数据库,版本要求:5.6.5+
- 初始化mysql数据库,数据库初始化文件:
nacos-mysql.sql - 修改
conf/application.properties文件,增加支持mysql数据源配置(目前只支持mysql),添加mysql数据源的url、用户名和密码。 - 再启动nacos,nacos所有写嵌入式数据库的数据都写到了mysql。
19.7.5、Nacos 集群部署搭建
Nacos支持三种部署模式
- 单机模式 - 用于测试和单机试用。
集群模式 - 用于生产环境,确保高可用。- 多集群模式 - 用于多数据中心场景。
此处附:Nacos集群模式部署官方文档
若单机要集群Nacos的话要删除其中的data文件夹。资料
19.7.5.1、节点部署情况
| 服务器IP | 部署服务 | 端口 | 备注 |
|---|---|---|---|
| 192.168.204.202 | MySQL 5.7.28 | 3306 | 测试,使用单机 MySQL,高可用参考:MySQL 5.7.28 主从复制实现 |
| 192.168.204.202 | Nginx 1.4.1 | 8807 | 测试,使用单机 Nginx,Nginx集群搭建请自行了解(Nginx默认端口为80,此处负载均衡使用8087端口) |
| 192.168.204.202 | nacos | 8848 | 集群节点01:nacos 01 |
| 192.168.204.203 | nacos | 8848 | 集群节点02:nacos 02 |
| 192.168.204.204 | nacos | 8848 | 集群节点03:nacos 03 |
提示: 三台机器配置相同,此处对一台进行配置。使用命令 scp 发送到其他两台机器即可,此处以192.168.204.202为例说明。
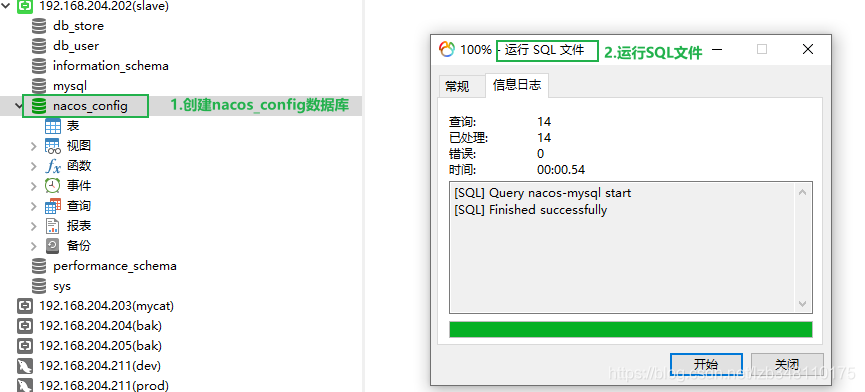
19.7.5.2、derby 切换 mysql 数据库配置
执行nacos-mysql.sql脚本:
进入 nacos 安装目录 conf 文件下,找到
nacos-mysql.sql 脚本。创建 nacos_config 数据库,并执行 nacos-mysql.sql 脚本。

修改application.properties,添加mysql支持:
进入nacos安装目录 conf 文件下,
application.properties配置文件添加 mysql 支持。其中:
在修改所有文件之前建议保存副本
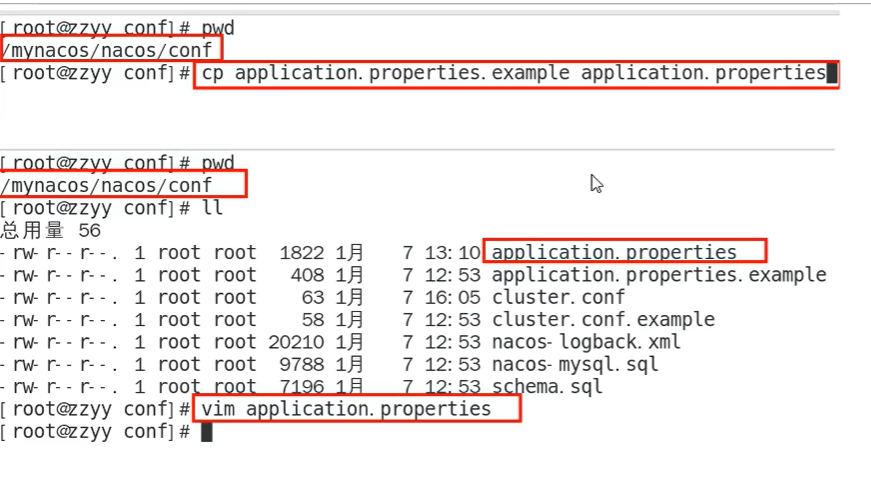
db.user与db.password填写本机的用户名与密码
1
2
3
4
5
6=mysql
=1
=jdbc:mysql://192.168.204.202:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
=root
=root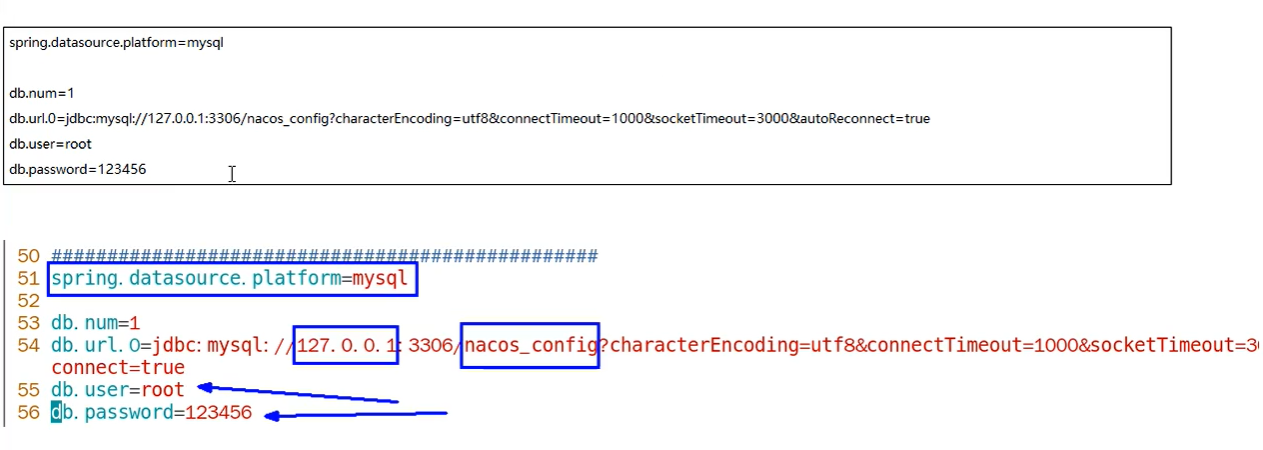
cluster.conf 配置:
进入 conf 目录,使用命令:
cp cluster.conf.example cluster.conf拷贝一份,重命名为cluster.conf,在 cluster.conf 中进行配置,说明哪几台机器组成集群(填写的是 nacos 集群3个节点所在 IP:端口号,不要写127.0.0.1,必须是Linux的真实IP),可以通过命令hostname -i查看Linux的真实IP。1
2
3192.168.204.202:8848
192.168.204.203:8848
192.168.204.204:8848修改 nacos 启动堆栈大小:
(nacos 启动时,默认
-Xms2g -Xmx2g。如果你是在多台虚拟机测试,配置紧张,这一步就比较重要了。如果服务器配置很优秀,这一步可以绕过。)配置紧张会导致以下情况的出现:
- nacos 服务启动很慢很慢的情况;
- nacos 服务注册中心,有3个提供服务,你可能只能看到 2个、1个、0个服务节点,还会来回跳动的问题。
- 反正还是会出现一些意想不到的问题,视情况而配置。
Xms 是指设定程序启动时占用内存大小。一般来讲,大点,程序会启动的快一点,但是也可能会导致机器暂时间变慢。Xmx 是指设定程序运行期间最大可占用的内存大小。如果程序运行需要占用更多的内存,超出了这个设置值,就会抛出OutOfMemory异常。我们进入 bin 目录,使用
vim startup.sh对其进行修改,将其按照配置修改到指定大小即可。(好像可以通过启动时添加 Xms 参数方式修改,我忘了怎么搞了,此处就直接修改.sh启动脚本了)(建议修改之前进行备份)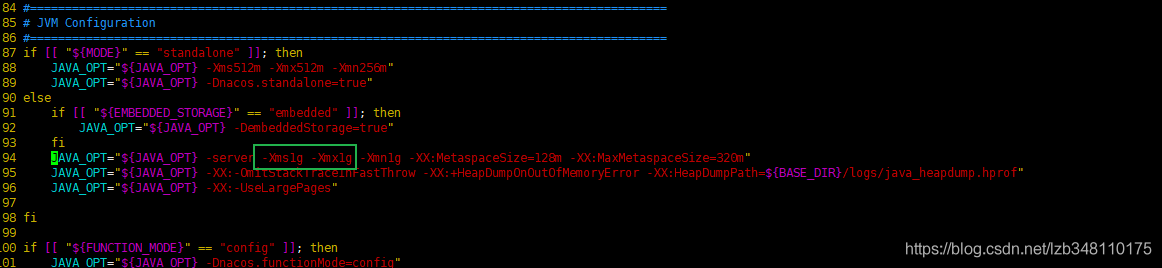
使用scp命令,进行nacos配置分发:
192.168.204.202 一台 nacos 集群环境配置完成,使用 scp 命令,将 nacos 目录分发到 203/204两台机器。scp 命令的使用如下:(scp命令使用介绍,请参考:Linux命令—scp),不使用 scp 命令,你也可以 rz、sz 以打包的方式进行上传。
scp -r /usr/local/env/nacos root@192.168.204.203:/usr/local/nacos/
scp -r /usr/local/env/nacos root@192.168.204.204:/usr/local/nacos/以上第5步也可以通过编辑Nacos的启动脚本
startup.sh,使他能够接受不同的启动端口(建议备份):
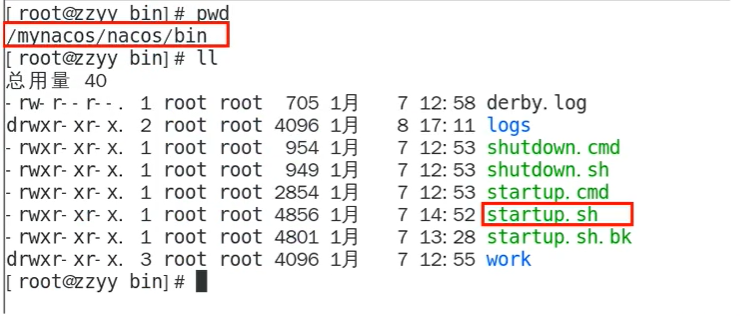


之后就可以通过
./startup.sh -p 端口号执行:
19.7.5.2、Nginx的配置,由他作为负载均衡器
在此处,已经默认 Nginx 服务已经OK,Nginx 服务跑在192.168.204.202。如需 Nginx 的搭建过程,请自行。
进入nginx/conf 目录,对 nginx.conf添加 nacos 集群配置,配置如下图所示:
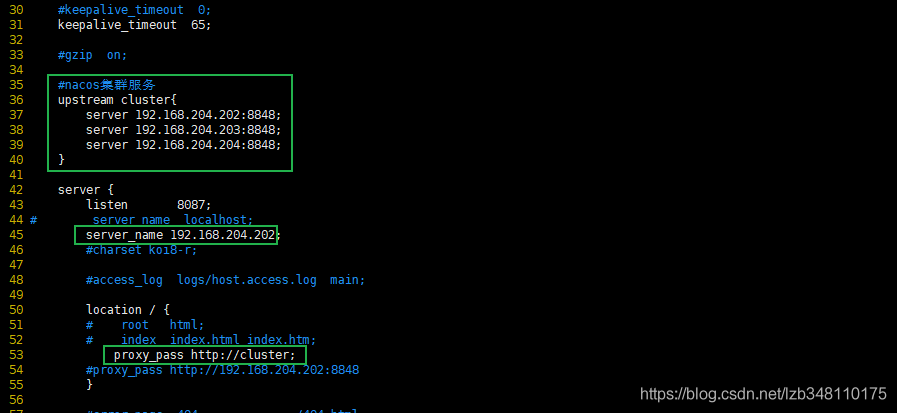
配置完成,进入 sbin 目录,使用./nginx -c /usr/local/nginx/nginx-1.16.0/conf/nginx.conf启动 nginx,使用-c加载指定配置文件,路径为 nginx.conf 所在路径。启动完成,通过命令:ps aux | grep nginx查看 nginx 是否启动。如图已经启动成功。

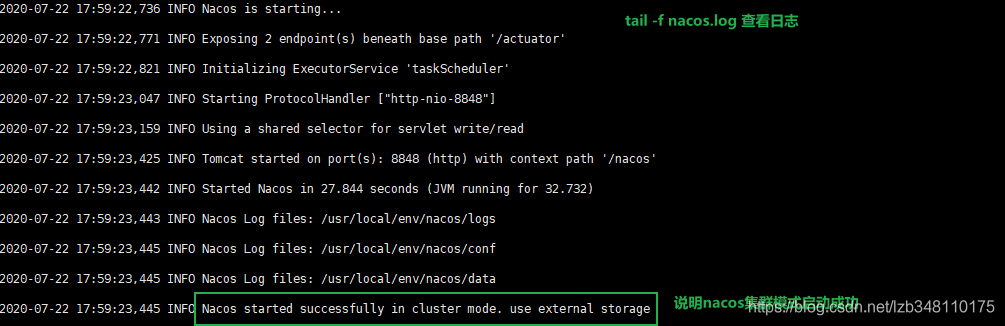
19.7.5.3、启动nacos集群
启动集群中的3台nacos。可以通过命令ps -ef|grep nacos|grep -v grep grep |wc -l查看nacos集群启用的端口数量,也可以通过nacos安装路径logs目录,使用 tail -f nacos.log 查看日志。
启动成功提示:
如果虚拟机资源紧张,此处会一直很长时间在 nacos is starting... 状态,一定注意自己服务器的配置。
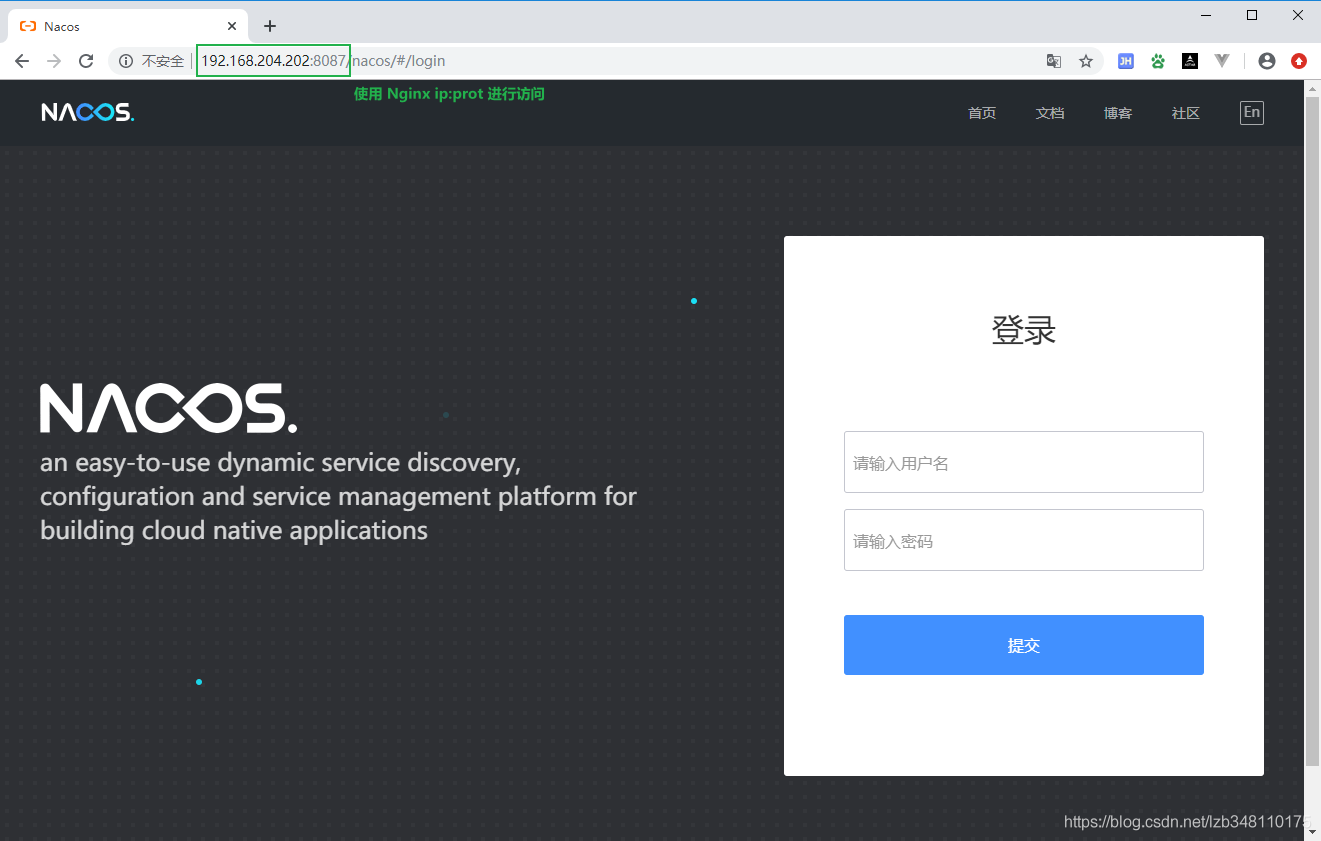
19.7.5.4、进入Nacos控制台
已经配置 Nginx 负载均衡,所以我们使用 Nginx 8087 端口进入Nacos 控制台:**http://192.168.204.202:8087/nacos/**
19.7.5.5、查看集群节点启动情况
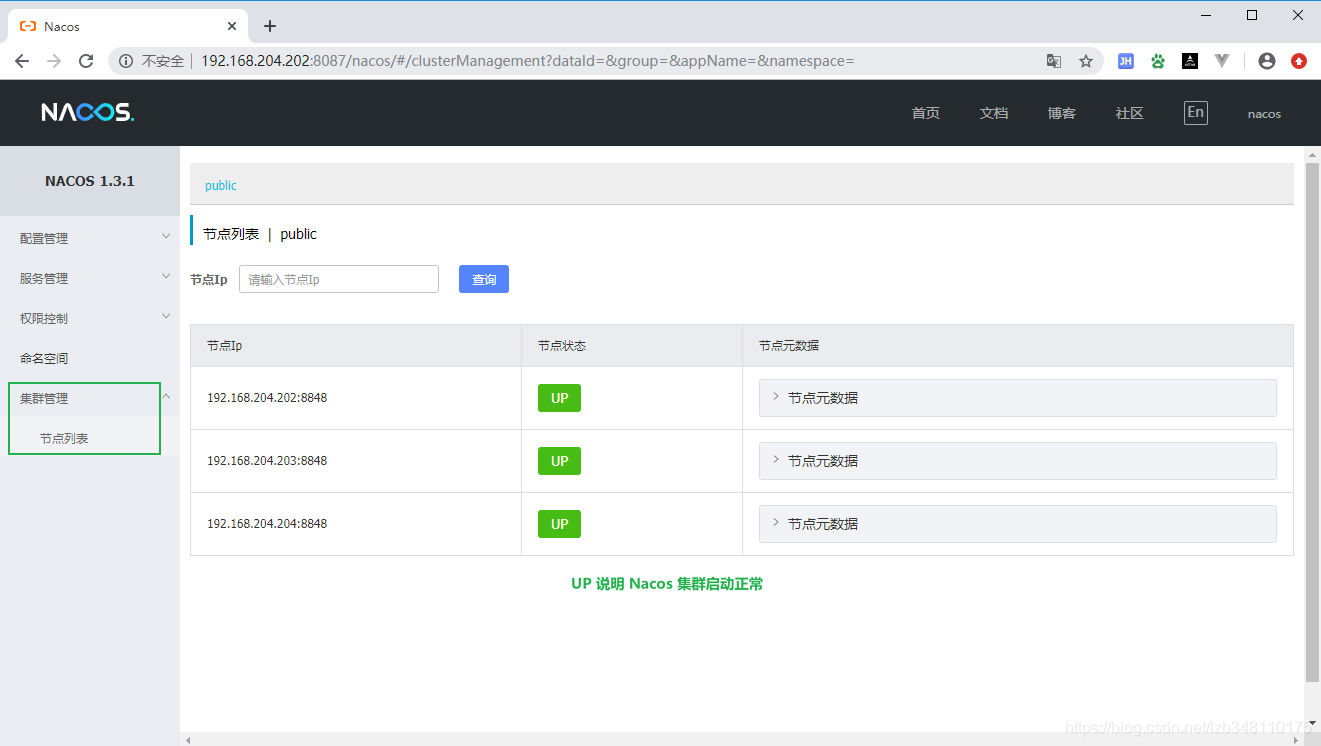
19.7.5.6、Nacos集群环境,项目application.yml中nacos地址需写 Nginx 地址
1 | spring: |
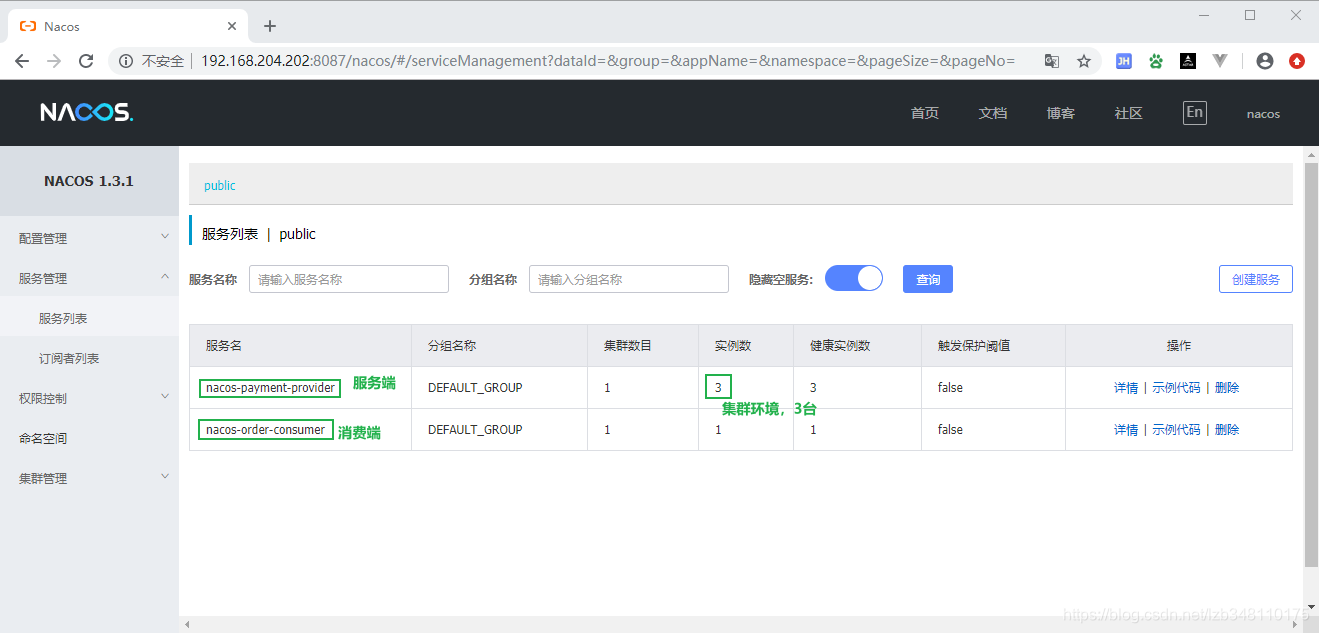
通过访问8087端口(Ngnix)来实际访问三个nacos端口。
20、Sentinel实现服务降级、服务熔断、服务限流
资料查询:
中文介绍文档:Sentinel Wiki中文介绍文档
Sentinel 使用介绍:Spring Cloud 关于 Sentinel 使用文档
20.1、是什么
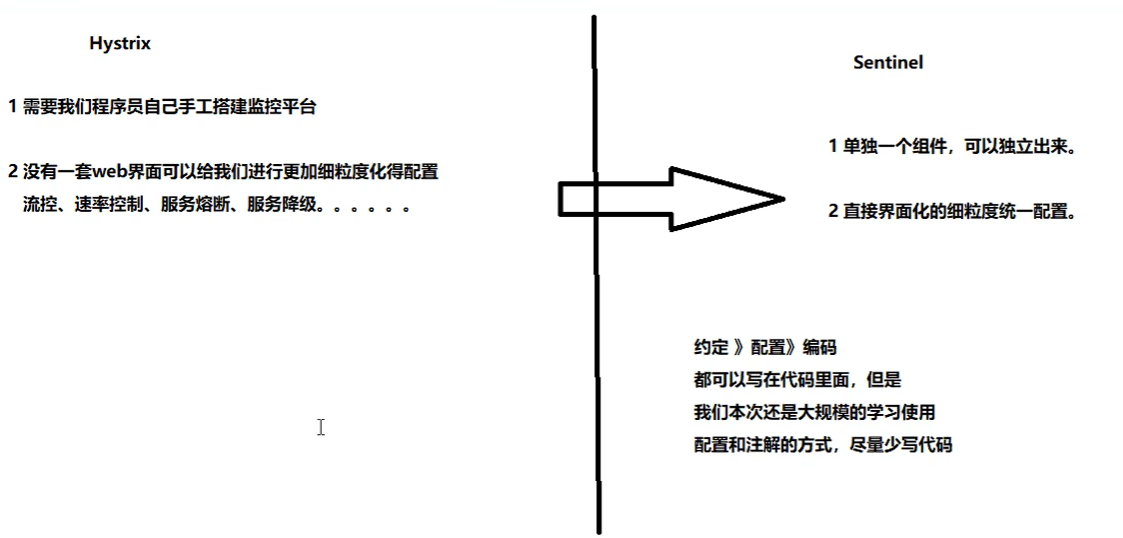
(本段内容摘自:Sentinel Wiki 中文文档,一句话解释Sentinel,就是之前介绍过的:Hystrix 实现服务降级、服务熔断、服务限流,Sentinel 后起之秀,更优秀)
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
20.2、Sentinel的特征
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
- 完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
- 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
- 完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
20.3、Sentinel的作用
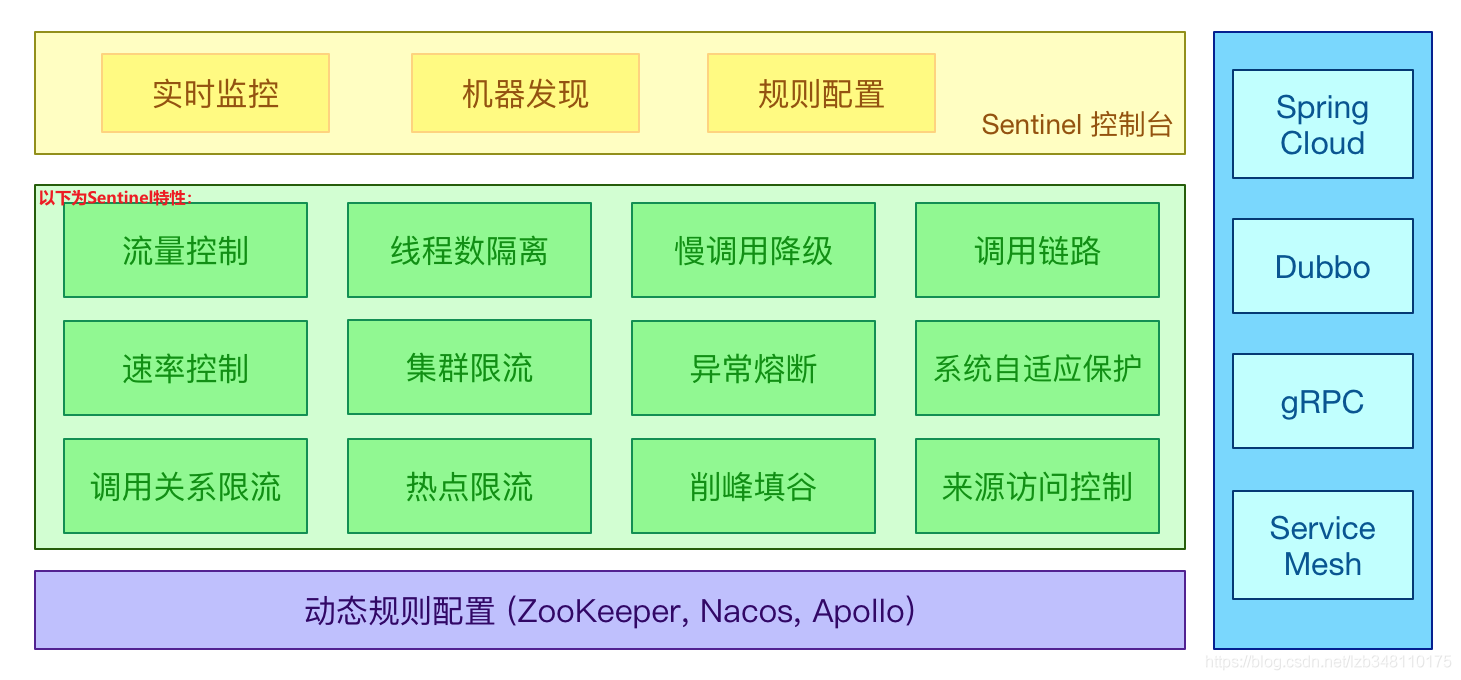
Sentinel 的开源生态:
Sentinel 分为两个部分:
- 核心库(Java 客户端):不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
- 控制台(Dashboard):基于 Spring Boot 开发,打包后使用 java -jar xxx.jar 方式可以直接运行,不需要额外的 Tomcat 等应用容器。
20.4、安装Sentinel控制台(Dashboard)
Sentinel Dashboard 下载地址:Sentinel Dashboard 下载地址
环境:JDK 8,端口:8080 不被占用。
在安装目录进入 cmd 控制台,使用
java -jar sentinel-dashboard-1.7.2.jar方式直接运行。
使用 http://localhost:8080 访问 Sentinel 图形管理界面。
登陆账号、密码均为:**
sentinel**
至此,Sentinel控制台(Dashboard)安装成功。
20.5、微服务项目整合Sentinel
使用 Sentinel 最好配好 Nacos 一起使用。
启动Sentinel与Nacos的微服务,并通过http://localhost:8080与http://localhost:8848/nacos/#/login进行访问。
新建微服务模块:
添加pom依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<!--引入 sentinel 依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
<!--nacos服务注册依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--sentinel持久化需要的依赖(后续持久化会用到,此处可有可无)-->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>application.yml 配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22server:
port: 8401
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
# 添加sentinel相关配置
sentinel:
transport:
dashboard: localhost:8080 #配置sentinel dashboard地址
port: 8719 #sentinel默认8719,假如被占用了会自动从8719开始依次+1扫描。直至找到未被占用的端口
#暴露,用于监控等
management:
endpoints:
web:
exposure:
include: '*'主启动类添加 @EnableDiscoveryClient 注解
业务类:
1
2
3
4
5
6
7
8
9
10
11
12
13
public class FlowLimitController {
public String testA() {
return "-----testA";
}
public String testB(){
return "-----testB";
}
}启动项目,查看Sentinel是否成功监控:
此时进入 Sentinel 图形管理界面,并没有看到关于微服务任何信息。这是因为 Sentinel 采用的
懒加载机制,只有执行一次方法调用,才能被Sentinel监控到。 然后多次调用 /testA 接口,在实时监控便能够看到接口 调用时间、QPS、响应时间 等内容。 说明:Sentinel 8080 已经在监控微服务 8401,监控会有一丁点的延迟。服务一段时间不调用,实时监控会消失。
20.6、Spring Cloud Alibaba Sentinel 流控、降级、热点、系统规则
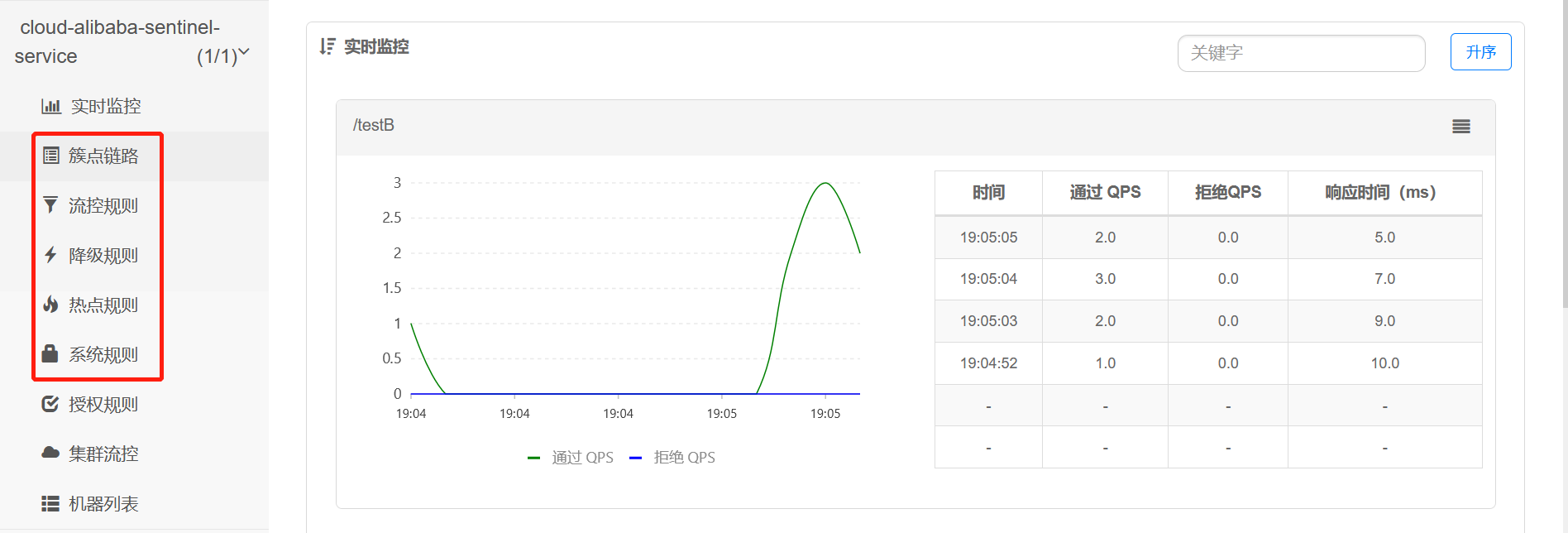
20.6.1、流控规则
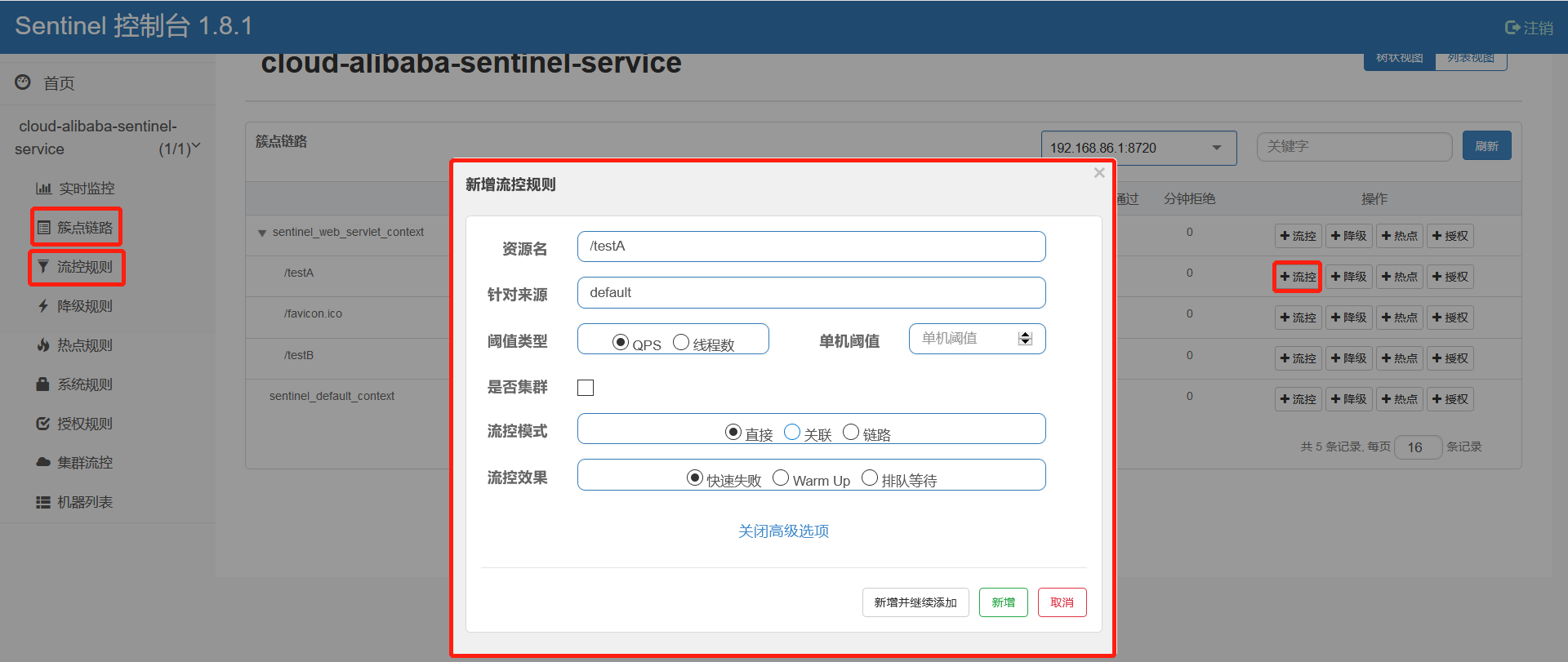
流控规则,即:流量控制规则。可自行参考官网介绍:GitHub 流量控制。具体配置有 资源名**、针对来源、阈值类型、是否集群、流控模式、单机阈值、流控效果** 这几项,它们配合进行使用。
可以通过簇点链路的方式添加,也可以通过流控规则方式添加。
**
资源名**:唯一路径,默认为请求路径(也可以是后续介绍的 @SentinelResource 注解的 value 属性值)
**针对来源**:Sentinel 可以针对调用者进行限流,填写微服务名。默认为 default(不区分来源)
**是否集群**:本文为单机测试,是否集群不选
20.6.1.1、阈值类型:QPS
QPS(每秒钟的请求数量):当调用该 API 的 QPS 达到阈值的时候,进行限流。
配置(默认流控模式为直接,流控效果为快速失败):
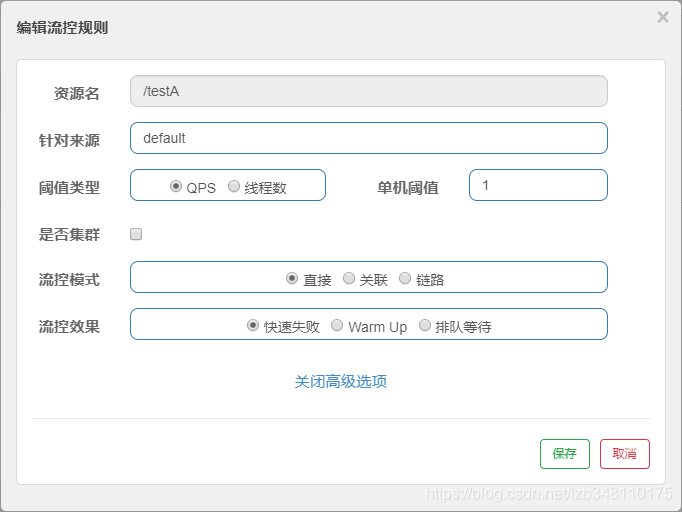
效果:/testA 服务,每秒只允许调用 1 次,超出阈值后,直接失败(流控 Sentinel 默认提示:**Blocked by Sentinel(flow limiting)**)
20.6.1.2、阈值类型:线程数
线程数:当调用该 API 的 线程数 达到阈值的时候,进行限流。
配置:
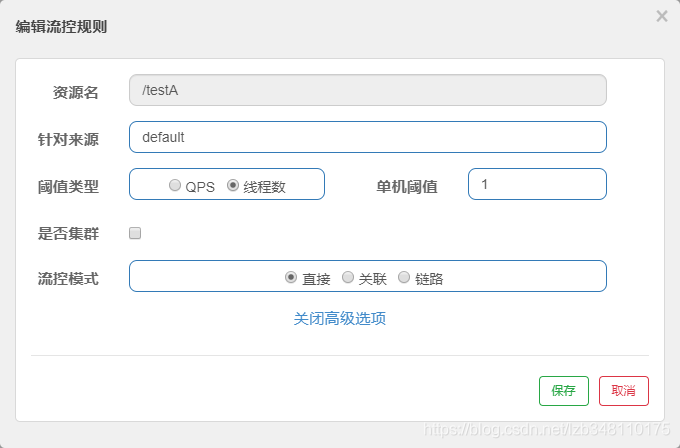
效果:
/testA 服务,单个线程只允许调用 1 次,超出阈值后,直接失败(流控 Sentinel 默认提示:**Blocked by Sentinel(flow limiting)**)
20.6.1.3、流控模式:直接
效果:超出阈值后,直接失败。
20.6.1.4、流控模式:关联
关联:当关联的资源达到阈值时,就限流自己。**当与 A 资源关联的 B 资源达到阈值时,就限流自己(A)**,即:B惹事,A挂了
应用场景:
双十一,支付接口和下单接口关联。当支付接口达到阈值,就限流下单接口。
配置:
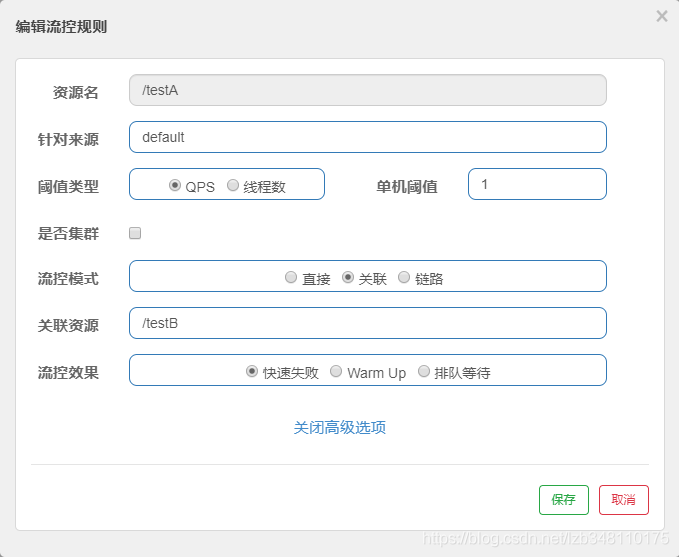
效果:
/testA 服务关联/testB 服务,1s 调用 1次,服务正常。当狂点刷新调用 /testB 服务,超出阈值 QPS = 1 后,此时 /testA 被限流了,这就是 **B惹事,A挂了**。
20.6.1.5、流控模式:链路
链路:当链路中的资源达到阈值时,就会对使用到该资源的链路进行流控。当A01 资源达到设定阈值时,所有调用该服务的链路,都会被限流,即:A01 挂了,用到我的链路都得挂。
此处会用到 @SentinelResource 注解 value 属性值 作为资源名。此处只是使用一下。
模拟两条请求链路:
A链路: A → A01 → A04 → A05
B链路: B → A01 → A02 → A03
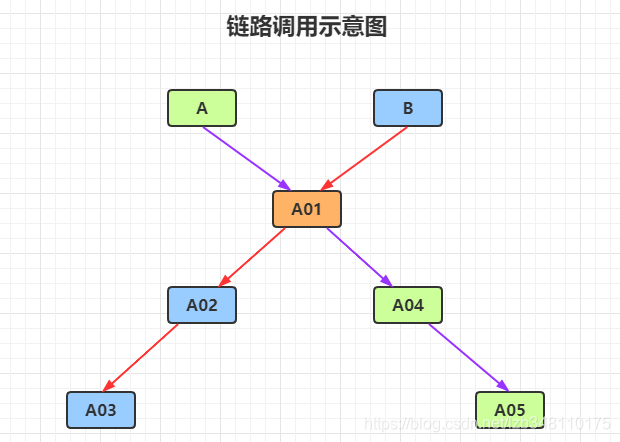
配置:
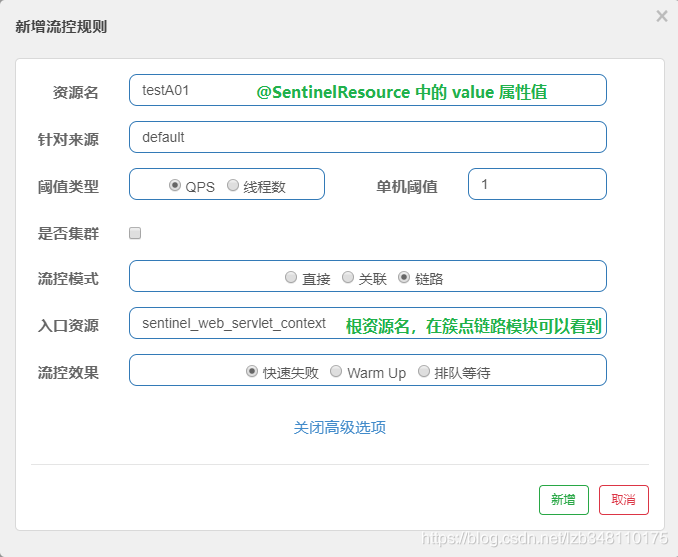
效果:
对 testA01 服务进行 链路 流控,该服务关联有 A 和 B 两条链路。当 A 链路1s 调用 1次,服务正常。当该链路调用 **超出阈值 QPS = 1 后,此时A链路都会被限流,同时因为B链路也调用 testA01,所以B链路也会同时被限流调用**。
20.6.1.6、用postman进行循环访问
postman里新建多线程集合组:

访问地址添加进新线程组:
run:
20.6.1.7、流控效果:快速失败
效果:
直接失败。(流控 Sentinel 默认提示:**Blocked by Sentinel(flow limiting)**)
20.6.1.8、流控效果:Warm Up
Warm Up:某个服务,日常访问量很少,基本为 0,突然1s访问量 10w,这种极端情况,会直接将服务击垮。所以通过配置 流控效果:Warm Up**,允许系统慢慢呼呼的进行预热**,经预热时长逐渐升至设定的QPS阈值。以下图片来自官网。
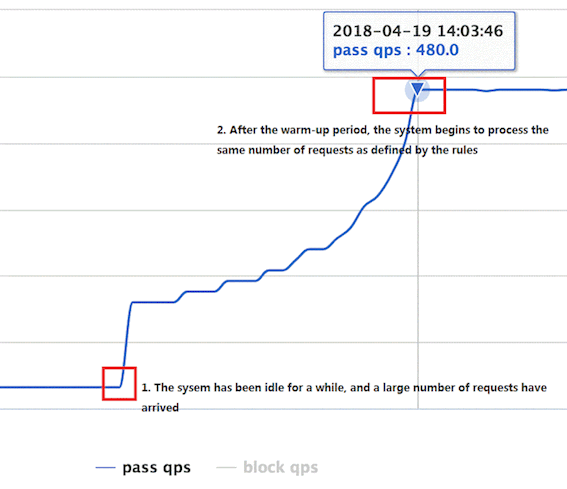 限限流 冷启动:(以下来自官网)
限限流 冷启动:(以下来自官网)
当流量突然增大的时候,我们常常会希望系统从空闲状态到繁忙状态的切换的时间长一些。即如果系统在此之前长期处于空闲的状态,我们希望处理请求的数量是缓步的增多,经过预期的时间以后,到达系统处理请求个数的最大值。Warm Up(冷启动,预热)模式就是为了实现这个目的的。
这个场景主要用于启动需要额外开销的场景,例如建立数据库连接等。
它的实现是在 Guava 的算法的基础上实现的。然而,和 Guava 的场景不同,Guava 的场景主要用于调节请求的间隔,即 Leaky Bucket,而 Sentinel 则主要用于控制每秒的 QPS,即我们满足每秒通过的 QPS 即可,我们不需要关注每个请求的间隔,换言之,我们更像一个 Token Bucket。
默认 coldFactor 为 3,即请求 QPS 从 threshold / 3 开始,经预热时长逐渐升至设定的 QPS 阈值。
公式:阈值/coldFactor(默认值为3)
源码:

应用场景:
秒杀系统。秒杀系统在开启的瞬间,会有很多的流量上来,很有可能将系统打死。预热方式就是为了保护系统,可以慢慢的将流量放进来,最终将阈值增长到指定的数值。
配置:
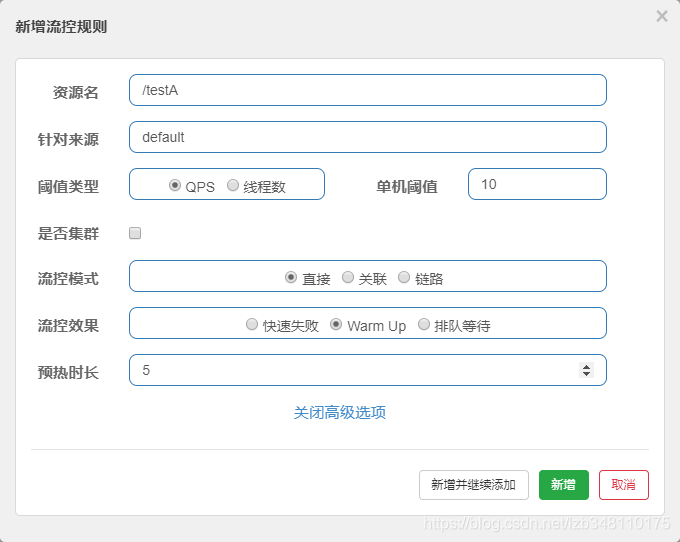
效果:
/testA 服务,设置 QPS 单机阈值为 10,采用 Warm Up 预热的方式,预热时长为 5s。根据计算公式 **10 / 3 = 3**,前 5s 的阈值为 3,预热 5s 后阈值增长到 10。
即:前5s内,访问超过 3 次便会被限流;5s 后,阈值增长到 10,此时访问超过 3 次也不会被限流,这就是 Warm Up 预热效果。
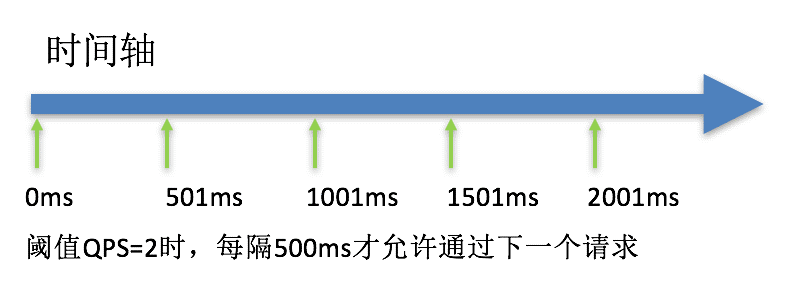
20.6.1.9、流控效果:排队等待
排队等待:让请求以均匀的速度通过,对应的是漏桶算法。这种方式主要用于处理间隔性突发的流量,例如消息队列。
应用场景:
在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态。我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。**官网**
注意:匀速排队模式暂时不支持 QPS > 1000 的场景。
配置:
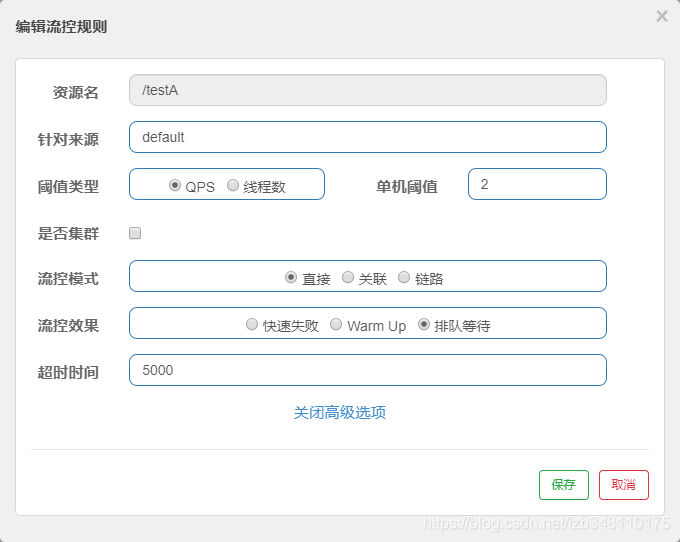
效果:
/testA 服务,设置 QPS 单机阈值为 2,每秒只接收 2 个请求。设置超时时间 5s。采用漏斗算法,让后台匀速的处理请求,而不是直接拒绝更多的请求。超时的请求则被抛弃,返回错误信息。(流控 Sentinel 默认提示:**Blocked by Sentinel(flow limiting)**)
20.6.2、降级规则
降级规则。可自行参考官网介绍:GitHub 熔断降级。降级策略有 慢调用比例**、异常比例、异常数** 三种。
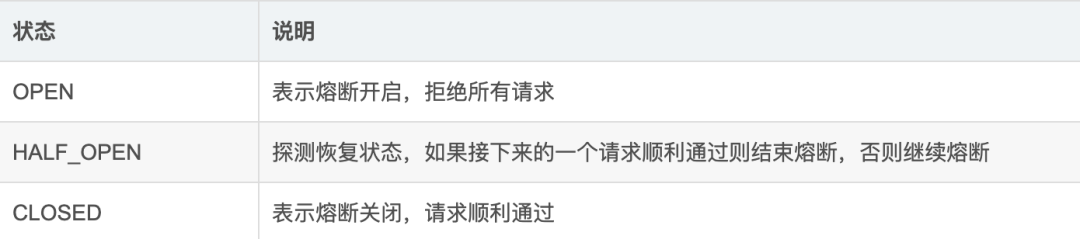
熔断状态:
熔断有三种状态,分别为OPEN、HALF_OPEN、CLOSED
**
资源名**:唯一路径,默认为请求路径(也可以是后续介绍的 @SentinelResource 注解的 value 属性值)
20.6.2.1、慢调用比例
慢调用比例 (SLOW_REQUEST_RATIO):选择以慢调用比例作为阈值,需要设置允许的慢调用RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。(以上来自官网)

执行逻辑:
熔断(OPEN):请求数大于最小请求数并且慢调用的比率大于比例阈值则发生熔断,熔断时长为用户自定义设置。
探测(HALFOPEN):当熔断过了定义的熔断时长,状态由熔断(OPEN)变为探测(HALFOPEN)。
如果接下来的一个请求小于最大RT,说明慢调用已经恢复,结束熔断,状态由探测(HALF_OPEN)变更为关闭(CLOSED)
如果接下来的一个请求大于最大RT,说明慢调用未恢复,继续熔断,熔断时长保持一致
注意Sentinel默认统计的RT上限是4900ms,超出此阈值的都会算作4900ms,若需要变更此上限可以通过启动配置项-Dcsp.sentinel.statistic.max.rt=xxx来配置。
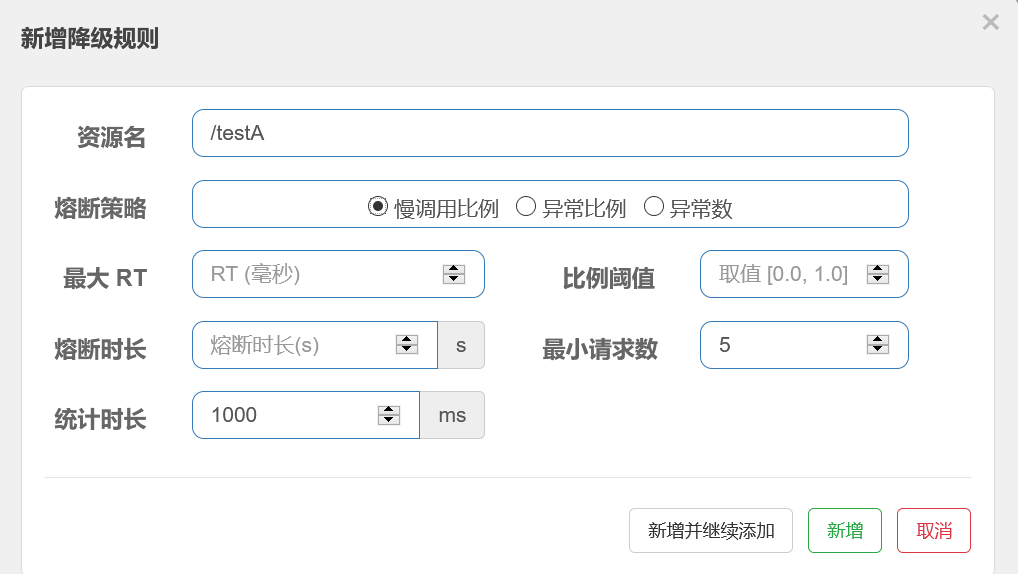
20.6.2.2、异常比例
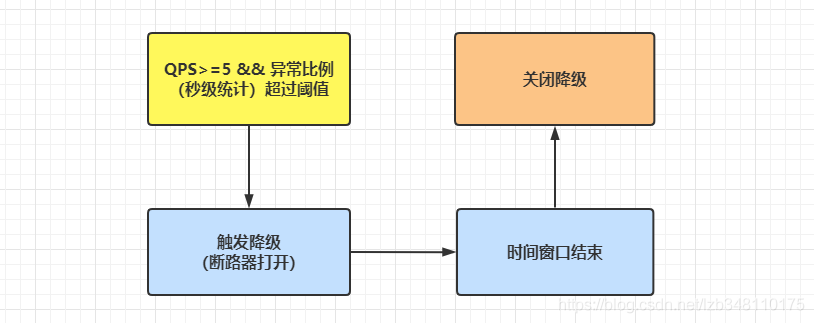
异常比例:QPS >= 5 && 异常比例超过设定的阈值,便会发生服务降级 。
异常比例为 0.0~1.0 范围内值。**时间窗口就是断路器开启时间长短(降级时间)** 。要看官网介绍来这里:异常比例介绍
图示:
配置:
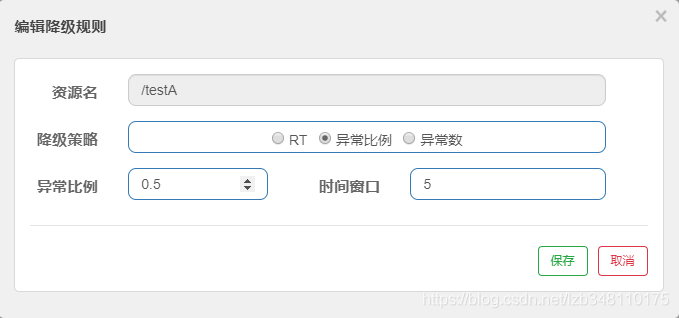
效果:
/testA 服务,设置 降级策略为 **异常比例**,异常比例设为 **0.5**,时间窗口为 **5s**。即:1s 发送6个请求,异常比例超过 50%,就会被熔断,断路器打开5s,5s后自动关闭,继续提供服务。
如果1s发送6次请求,前3次网页报错,因为第4次访问后,异常比例 > 50%,第4次便会被熔断,报 **Blocked by Sentinel(flow limiting)**。5s后继续提供服务哦。
20.6.2.3、异常数
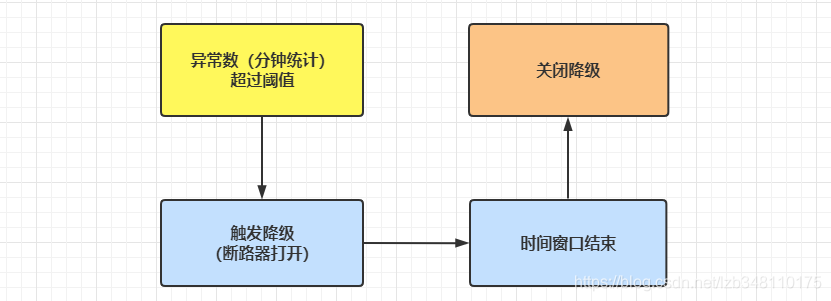
异常数:指的是资源 近1分钟 的异常数目,超过阈值之后会进行熔断。官网
重点注意:异常数,统计时间窗口是分钟级别,若 timeWindow 小于 60s,则结束熔断状态后仍可能再次进入熔断状态。推荐 时间窗口一定要>=60s
图示:
配置:
效果:
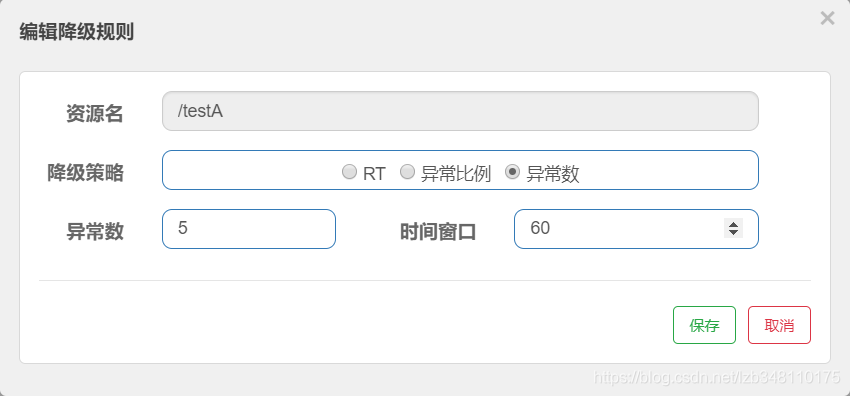
/testA 服务,设置 降级策略为 **异常数**,异常数设为 **5**,时间窗口为 **60s**。即:调用服务,当异常数超过5个时,开启断路器,执行熔断操作。60s 后,断路器关闭,服务恢复正常。
执行 /testA 服务请求,因为每个请求都是异常,前5次调用正常返回,只是报异常到前台(错误页面);第6次服务调用时,便会被降级熔断。报 **Blocked by Sentinel(flow limiting)**。60s后继续提供服务哦。
20.6.3、热点规则
(本段内容摘自:Github 热点规则官方介绍)
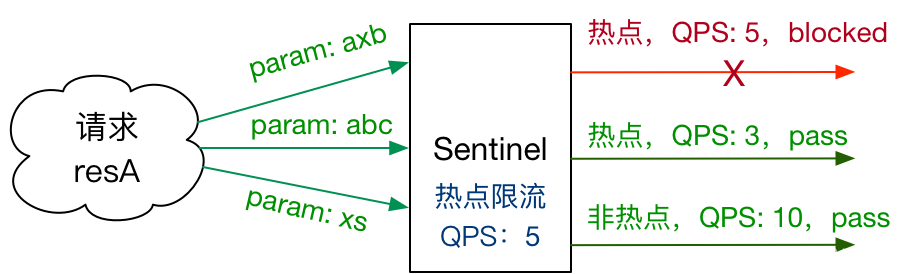
20.6.3.1、何为热点?
热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制。比如:
商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制
用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。 热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
Sentinel 利用LRU 策略统计最近最常访问的热点参数,结合令牌桶算法来进行参数级别的流控。热点参数限流支持集群模式。
20.6.3.2、何为热点限流
一句话解释:根据 url 传递进来的参数进行限流。带这个参数就限流,不带就不限流。
20.6.3.3、热点规则
共有 资源名**、限流模式(只支持QPS模式)、参数索引、单机阈值、统计窗口时长、是否集群** 六种参数;高级选项还有额外一些参数。
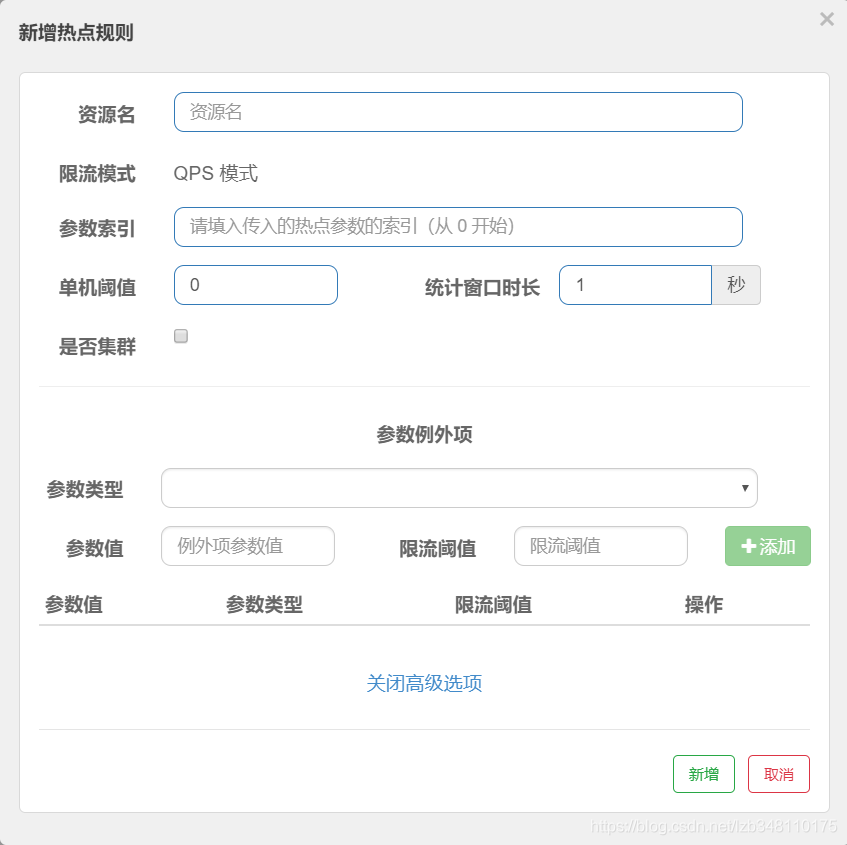
资源名**:唯一路径,默认为请求路径。此处必须是 @SentinelResource 注解的 value 属性值,配置@GetMapping 的请求路径无效)**参数索引**:参数索引(从0**开始,0表示第一个参数、1表示第二个参数)
配置:
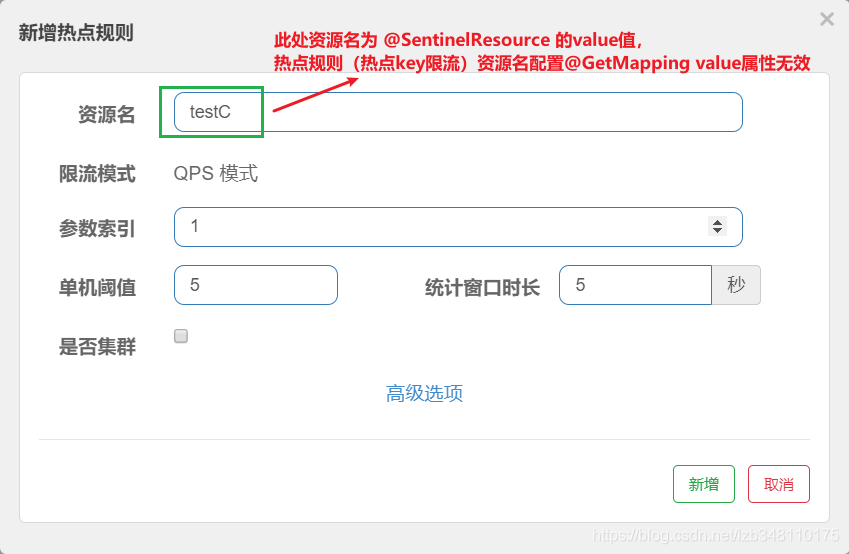
效果:
对 /testC 服务,配置热点key限流。当 1.第二个参数存在 2.一秒内调用 /testC 服务 > 5次,满足限流规则。服务将被熔断。断路器打开,5s 后服务恢复正常。
参数例外项配置:
需求(当请求参数name的值为Wade时,改变其限流阈值):
当 name 参数值为 Wade 时,限流阈值变更为 100。此时就需要对 参数例外项 进行配置了。
参数类型支持:int、double、String、long、float、char、byte 7种类型,参数值 指 name 参数的值,限流阈值指该参数值允许的阈值。
配置:
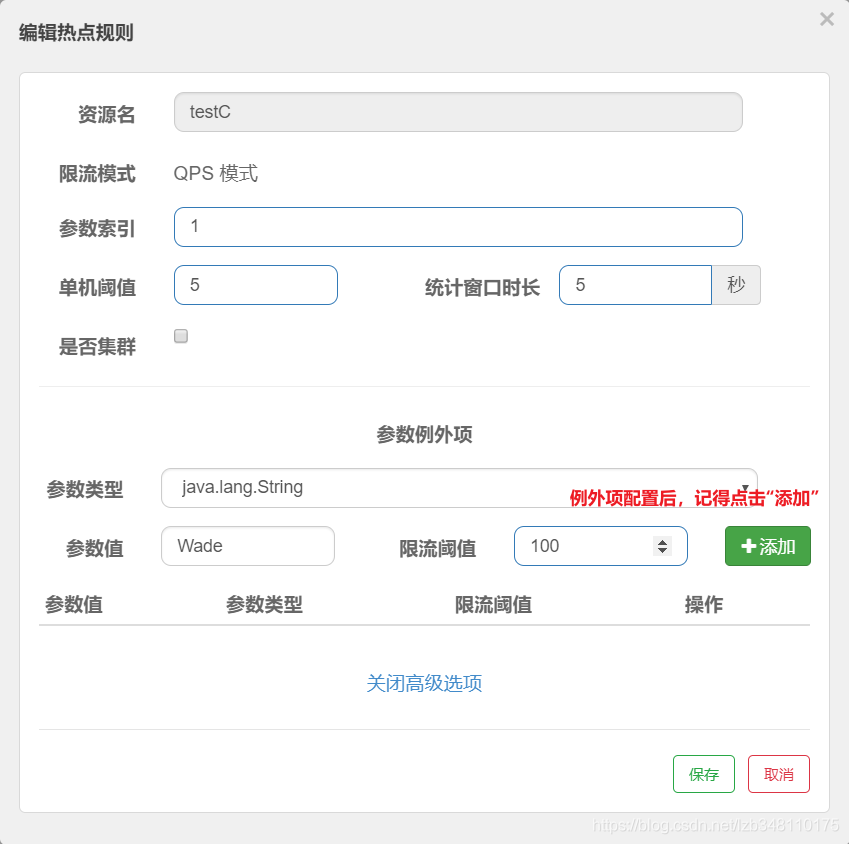
测试:
调用 URL:
http://localhost:8401/testC?id=1&name=Wade,阈值为200;
http://localhost:8401/testC?id=1&name=Jhon,阈值为200;
20.6.4、系统规则(不常用)
20.6.4.1、是什么
系统保护规则是从应用级别的入口流量进行控制,从单台机器的load、CPU 使用率、平均 RT、入口 QPS和并发线程数等几个维度监控应用指标,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效。入口流量指的是进入应用的流量(EntryType.IN),比如 Web 服务或 Dubbo 服务端接收的请求,都属于入口流量。
Sentinel 系统自适应限流从整体维度对应用入口流量进行控制,结合应用的 Load、CPU 使用率、总体平均 RT、入口 QPS 和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
20.6.4.2、系统规则支持的模式
- Load 自适应(仅对 Linux/Unix-like 机器生效):系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的 maxQps * minRt 估算得出。设定参考值一般是 CPU cores * 2.5。
- CPU usage(1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。
- 平均 RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
- 并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
20.6.4.3、入口QPS配置
入口QPS,实用性还是比较危险的。 如果 sentinel 密码被修改,将你的整个系统 入口QPS 配置很小,那么整个系统就瘫痪了。
但是 入口QPS 有总控的功能。最终选择是否使用,还是视情况而定吧
配置:
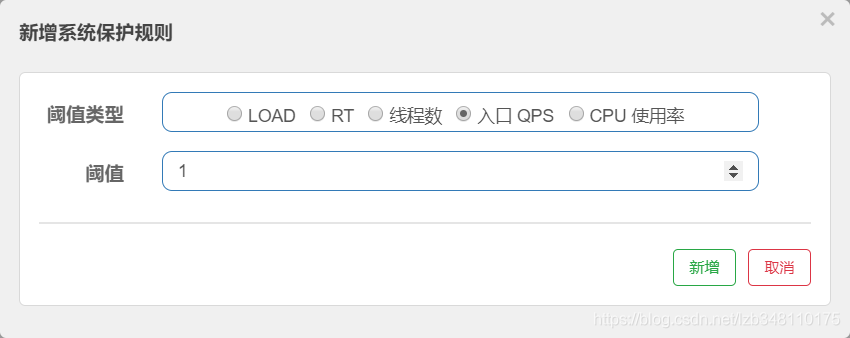
效果:
整个系统,每个请求 QPS = 1 正常访问,当该请求 QPS >1 就会被限流。
20.6.5、@SentinelResource
@SentinelResource可以说是 Sentinel 学习的突破口,搞懂了这个注解的应用,基本上就搞清楚了 Sentinel 的大部分应用场景。Sentinel 提供了 @SentinelResource 注解用于定义资源,并提供了AspectJ的扩展用于自动定义资源、处理BlockException等。
20.6.5.1、@SentinelResource 属性介绍
| 属性名 | 是否必填 | 说明 |
|---|---|---|
| value | 是 | 资源名称(必填项,需要通过 value 值找到对应的规则进行配置) |
| entryType | 否 | entry类型,标记流量的方向,取值IN/OUT,默认是OUT |
| blockHandler | 否 | **处理BlockException的函数名称(可以理解为对Sentinel的配置进行方法兜底)**。函数要求:1.必须是 public修饰2. 返回类型与原方法一致3. 参数类型需要和原方法相匹配,并在最后加 BlockException类型的参数。4. 默认需和原方法在同一个类中(耦合度高)。若希望使用其他类的函数,可配置 blockHandlerClass,并指定blockHandlerClass里面的方法。 |
| blockHandlerClass | 否 | 存放blockHandler的类。 对应的处理函数必须 public static修饰,否则无法解析,其他要求:同blockHandler。 |
| fallback | 否 | **用于在抛出异常的时候提供fallback处理逻辑(可以理解为对java异常情况方法兜底)**。fallback函数可以针对所有类型的异常(除了 exceptionsToIgnore里面排除掉的异常类型)进行处理。函数要求:1. 返回类型与原方法一致2. 参数类型需要和原方法相匹配,Sentinel 1.6开始,也可在方法最后加Throwable类型的参数。3.默认需和原方法在同一个类中(耦合度高)。若希望使用其他类的函数,可配置 fallbackClass ,并指定fallbackClass里面的方法。 |
| fallbackClass | 否 | 存放fallback的类。 对应的处理函数必须 static修饰,否则无法解析,其他要求:同fallback。 |
| defaultFallback | 否 | 用于通用的 fallback 逻辑。 默认 fallback 函数可以针对所有类型的异常(除了 exceptionsToIgnore里面排除掉的异常类型)进行处理。若同时配置了 fallback 和 defaultFallback,以fallback为准。函数要求:1. 返回类型与原方法一致2.方法参数列表为 空,或者有一个Throwable 类型的参数。3.默认需要和原方法在同一个类中(耦合度高)。若希望使用其他类的函数,可配置 fallbackClass ,并指定fallbackClass 里面的方法。 |
| exceptionsToIgnore | 否 | 指定排除掉哪些异常。 排除的异常不会计入异常统计,也不会进入fallback逻辑,而是原样抛出。 |
| exceptionsToTrace | 否 | 需要trace的异常 |
(加深标注属性为常用属性)

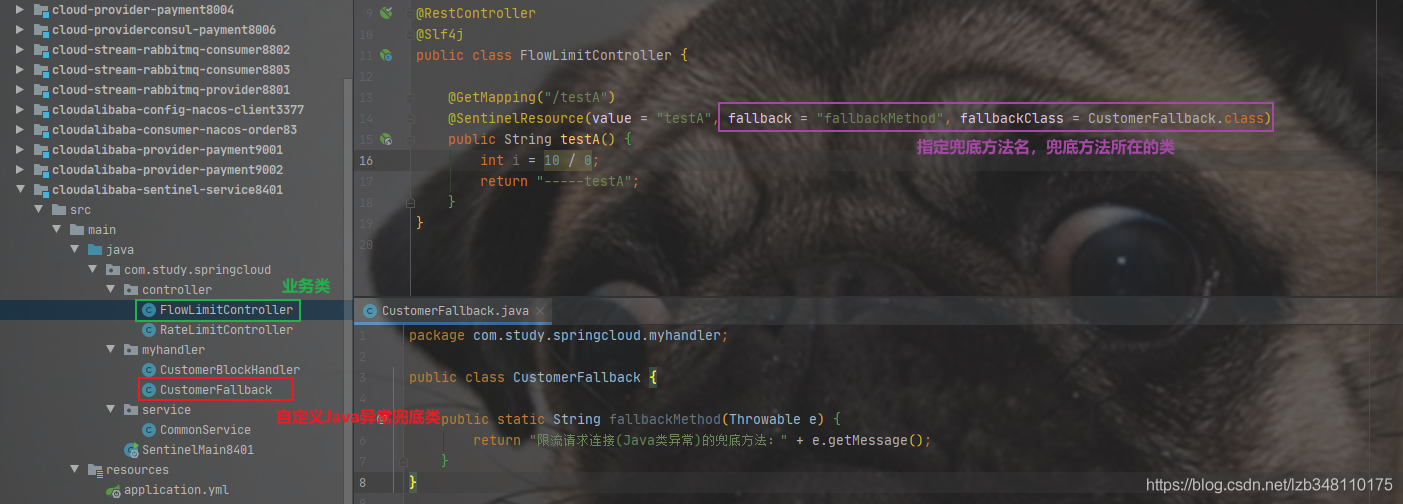
20.6.5.2、fallback 指定java异常兜底方法
**fallback只用来处理与Java逻辑异常相关的兜底**。比如:NullPointerException、ArrayIndexOutOfBoundsException 等java代码中的异常,fallback 指定的兜底方法便会生效。
兜底方法与业务方法耦合:
1 |
|
使用 fallbackClass 将兜底方法与业务解耦合:
20.6.5.3、blockHandler 指定 Sentinel 配置兜底方法
**blockHandler 只用来处理 与 Sentinel 配置有关的兜底**。比如:配置某资源 QPS =1,当 QPS >1 时,blockHandler 指定的兜底方法便会生效。
1 | /** |
使用 fallbackClass 将兜底方法与业务解耦合
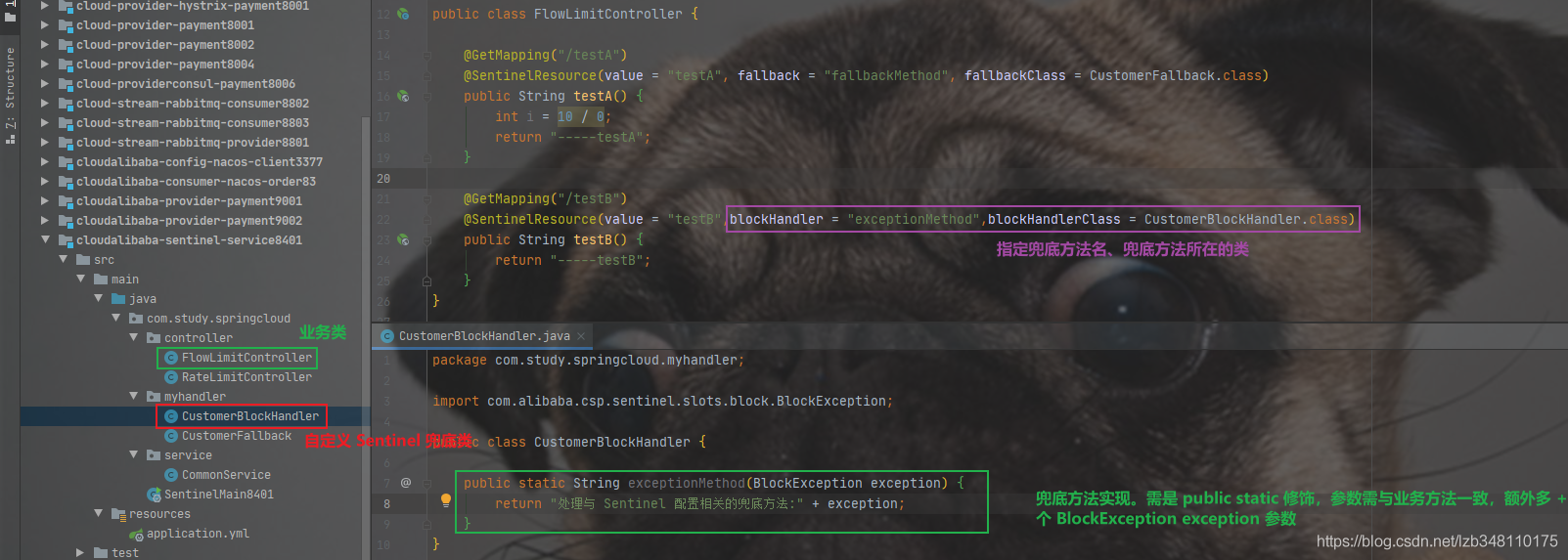
20.6.5.4、exceptionsToIgnore 用于指定异常不走兜底方法
使用exceptionsTolgnore属性,来指定某些异常不执行兜底方法,直接显示错误信息。配置 ArithmeticException 异常不走兜底方法。java.lang.ArithmeticException: / by zero ,便不会再执行兜底方法,直接显示错误信息给前台页面。
1 |
|
20.6.5.5、defaultFallback 用于指定通用的 fallback 兜底方法
使用 defaultFallback 来指定通用的 fallback 兜底方法。
- 如果当前业务配置有 defaultFallback 和 fallback 两个属性,则优先执行 fallback 指定的方法。
- 如果 fallback 指定的方法不存在,还会执行 defaultFallback 指定的方法。
1 | /** |
上面兜底方案面临的问题:
- 系统默认的,没有体现我们自己的业务要求。
- 依照现有条件,我们自定义的处理方法又和业务代码耦合在一块,不直观。
- 每个业务方法都添加一个兜底的,那代码膨胀加剧。
- 全局统一的处理方法没有体现。
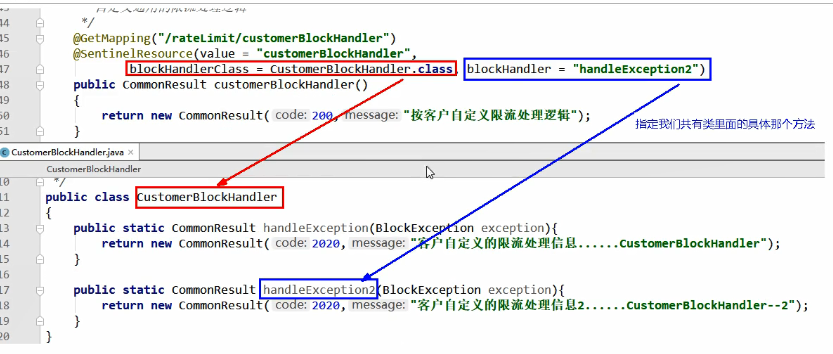
客户自定义限流处理逻辑:
创建CustomerBlockHandler类用于自定义限流处理逻辑:
自定义限流处理类
1
2
3
4
5
6
7
8
9
10public class CustomerBlockHandler{
public static CommonResult handlerException(BlockException exception)
{
return new CommonResult(4444,"按客戶自定义,global handlerException----1");
}
public static CommonResult handlerException2(BlockException exception)
{
return new CommonResult(4444,"按客戶自定义,global handlerException----2");
}
}RateLimitController:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
public class RateLimitController
{
public CommonResult byResource()
{
return new CommonResult(200,"按资源名称限流测试OK",new Payment(2020L,"serial001"));
}
public CommonResult handleException(BlockException exception)
{
return new CommonResult(444,exception.getClass().getCanonicalName()+"\t 服务不可用");
}
public CommonResult byUrl()
{
return new CommonResult(200,"按url限流测试OK",new Payment(2020L,"serial002"));
}
public CommonResult customerBlockHandler()
{
return new CommonResult(200,"按客戶自定义",new Payment(2020L,"serial003"));
}
}
Sentinel的三个核心API:

注意异常降级仅针对业务异常,对 Sentinel 限流降级本身的异常(BlockException)不生效。为了统计异常比例或异常数,需要通过 Tracer.trace(ex) 记录业务异常。示例:
1 | Entry entry = null; |
20.7、服务熔断
sentinel整合ribbon+openFeign+fallback
公共:
启动nacos和启动sentinel服务
新建两个服务提供端(实现负载均衡)(详情看上面微服务项目整合Sentinel)
服务提供端的业务类PaymentController:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class PaymentController
{
private String serverPort;
public static HashMap<Long,Payment> hashMap = new HashMap<>();
// 模拟数据库
static
{
hashMap.put(1L,new Payment(1L,"28a8c1e3bc2742d8848569891fb42181"));
hashMap.put(2L,new Payment(2L,"bba8c1e3bc2742d8848569891ac32182"));
hashMap.put(3L,new Payment(3L,"6ua8c1e3bc2742d8848569891xt92183"));
}
// 输入1、2、3得到数据,输入4报空指针异常
public CommonResult<Payment> paymentSQL( Long id)
{
Payment payment = hashMap.get(id);
CommonResult<Payment> result = new CommonResult(200,"from mysql,serverPort: "+serverPort,payment);
return result;
}
}新建服务消费端
业务类CircleBreakerController
20.7.1、Ribbon系列
添加sentinel依赖pom:
1
2
3
4
5
6
7
8
9
10<!--SpringCloud ailibaba nacos -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--SpringCloud ailibaba sentinel -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>application.yml配置文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21server:
port: 84
spring:
application:
name: nacos-order-consumer
cloud:
nacos:
discovery:
server-addr: localhost:8848
sentinel:
transport:
#配置Sentinel dashboard地址
dashboard: localhost:8080
#默认8719端口,假如被占用会自动从8719开始依次+1扫描,直至找到未被占用的端口
port: 8719
#消费者将要去访问的微服务名称(注册成功进nacos的微服务提供者)
service-url:
nacos-user-service: http://nacos-payment-provider主启动添加@EnableDiscoveryClient
添加RestTemplate配置类ApplicationContextConfig(添加@LoadBalanced):
1
2
3
4
5
6
7
8
9
10
public class ApplicationContextConfig
{
public RestTemplate getRestTemplate()
{
return new RestTemplate();
}
}
20.7.2、OpenFeign系列(Feign组件一般是在消费者侧)
添加OpenFeign依赖pom:
1
2
3
4
5<!--SpringCloud openfeign -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>application.yml配置文件(激活Sentinel对Feign的支持):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26server:
port: 84
spring:
application:
name: nacos-order-consumer
cloud:
nacos:
discovery:
server-addr: localhost:8848
sentinel:
transport:
#配置Sentinel dashboard地址
dashboard: localhost:8080
#默认8719端口,假如被占用会自动从8719开始依次+1扫描,直至找到未被占用的端口
port: 8719
#消费者将要去访问的微服务名称(注册成功进nacos的微服务提供者)
service-url:
nacos-user-service: http://nacos-payment-provider
# 激活Sentinel对Feign的支持
feign:
sentinel:
enabled: true主启动类添加注解:@EnableFeignClients
service接口:
1
2
3
4
5
6
public interface PaymentService
{
public CommonResult<Payment> paymentSQL( Long id);
}全局fallback实现service接口:
1
2
3
4
5
6
7
8
9
public class PaymentFallbackService implements PaymentService
{
public CommonResult<Payment> paymentSQL(Long id)
{
return new CommonResult<>(44444,"服务降级返回,---PaymentFallbackService",new Payment(id,"errorSerial"));
}
}
业务类CircleBreakerController:
1 |
|
没有配置:@SentinelResource(value = “fallback”) (不友好)
只配置fallback(只负责运行异常):@SentinelResource(value = “fallback”,fallback = “handlerFallback”)
只配置blockHandler(只负责sentinel控制台配置违规):@SentinelResource(value = “fallback”,blockHandler = “blockHandler”)
配置sentinel控制台:
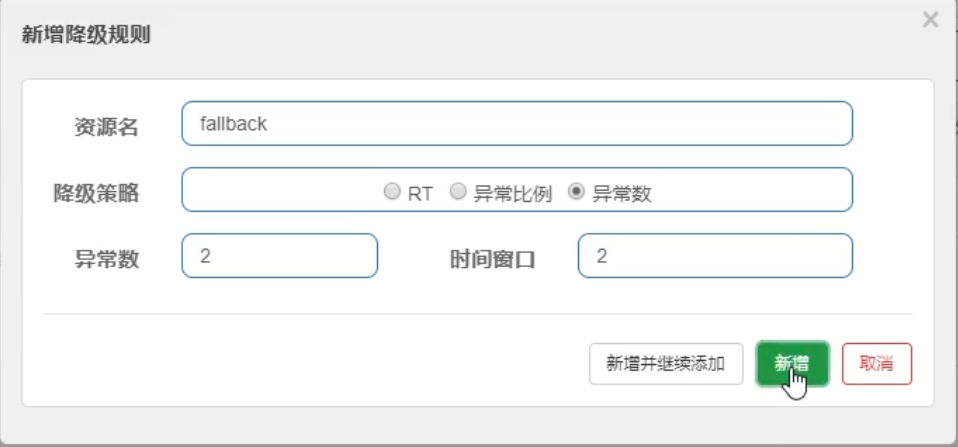
fallback和blockHandler都配置:
若blockHandler和fallback都进行了配置,则被限流降级而抛出BlockException时只会进入blockHandler处理逻辑。

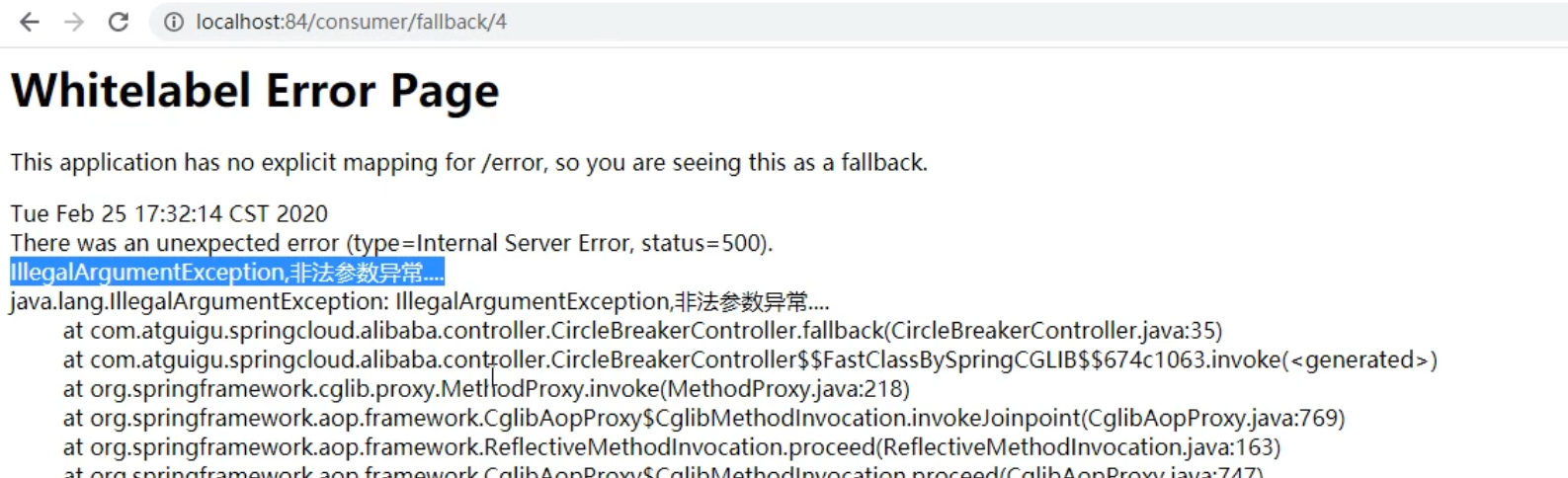
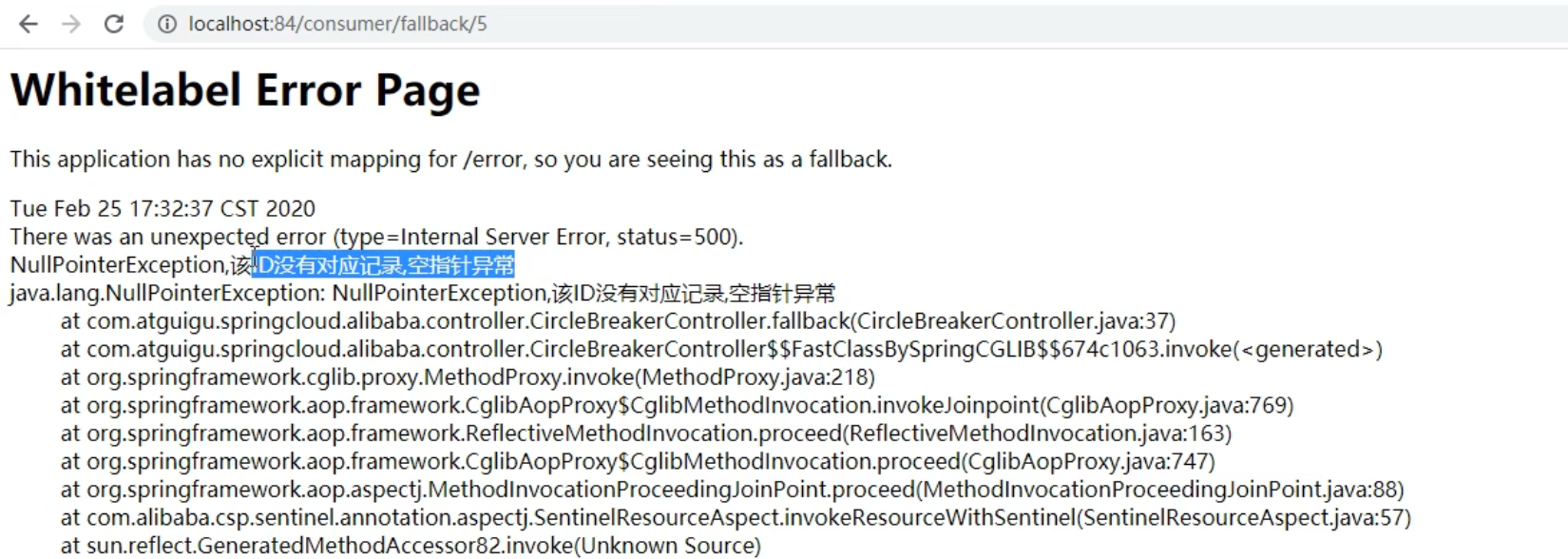



20.7.3、熔断框架比较
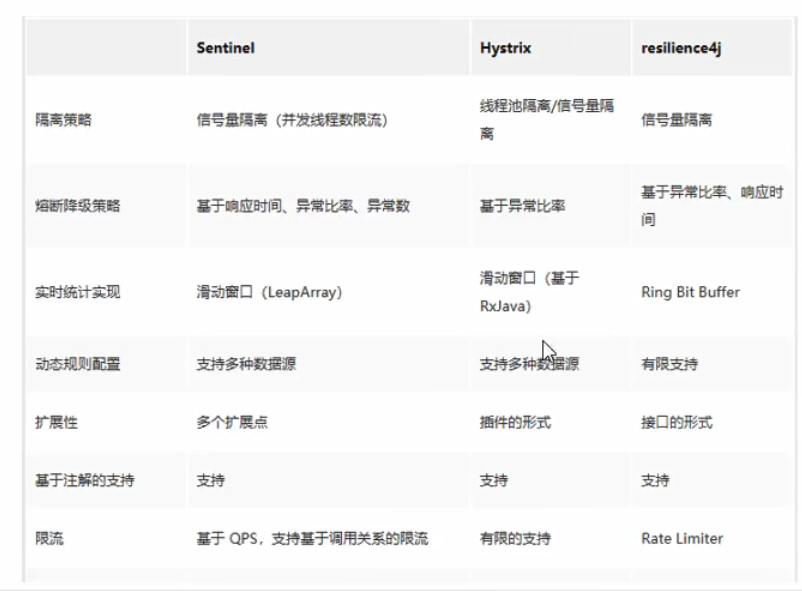

20.8、Sentinel 控制台规则持久化(持久化到Nacos比较鸡肋)
Sentinel 控制台规则持久化问题:
在 Sentinel 中,我们会为多个服务进行 流控、限流、热点 等规则 的配置,但是当服务重启后再进入 Sentinel 后,发现之前配置过的规则都不在了,这样子的体验显然不友好,此时就需要我们对 Sentinel 中配置的规则规则进行持久化操作。
目前控制台的规则推送也是通过规则查询更改 HTTP API来更改规则。这也意味着这些规则 仅在内存态生效,应用重启之后,该规则会丢失。
以上是原始模式。当了解了原始模式之后,我们非常鼓励您通过动态规则 并结合各种外部存储来定制自己的规则源。我们推荐通过动态配置源的控制台来进行规则写入和推送,而不是通过 Sentinel 客户端直接写入到动态配置源中。在生产环境中,我们推荐 push 模式,具体可以参考:在生产环境使用 Sentinel。也可以参考博客
规则管理及推送:
20.8.1、持久化配置(鸡肋)
将限流配置规则持久化进Nacos保存,只要刷新8401某个rest地址,sentinel控制台的流控规则就能看到,只要Nacos里面的配置不删除,针对8401上sentinel上的流控规则持续有效。
步骤:
添加依赖pom:
1
2
3
4
5<!--SpringCloud ailibaba sentinel-datasource-nacos 后续做持久化用到-->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>修改添加application.yml(主要是datasource):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33server:
port: 8401
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
sentinel:
transport:
dashboard: localhost:8080 #配置Sentinel dashboard地址
port: 8719
#添加nacos数据源配置
datasource:
ds1:
nacos:
server-addr: localhost:8848
dataId: cloudalibaba-sentinel-service
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow
management:
endpoints:
web:
exposure:
include: '*'
feign:
sentinel:
enabled: true # 激活Sentinel对Feign的支持其中dataId的值为${spring.application.name}。
添加nacos业务配置规则
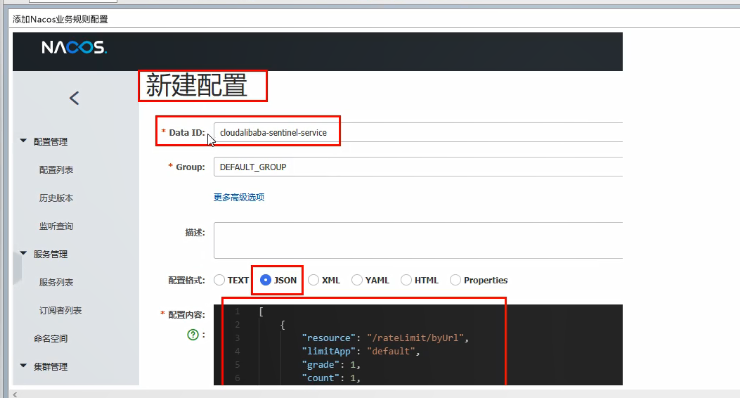
其中Data ID的值为${spring.application.name}的值。
在配置中的选择json,并添加内容:
1
2
3
4
5
6
7
8
9
10
11[
{
"resource":"/rateLimit/byUrl",
"limitApp":"default",
"grade":1,
"count": 1,
"strategy":0,
"controlBehavior":0,
"clusterMode"; false
}
]- resource:资源名称;
- limitApp:来源应用;
- grade:國值类型,0表示线程数,1表示QPS;
- count:单机國值;
- strategy:流控模式,0表示直接,1表示关联,2表示链路;
- controlBehavior:流控效果,0表示快速失败,1表示Warm Up,2表示排队等待;
- clusterMode:是否集群。
重启微服务,刷新sentinel。
发现业务规则有了
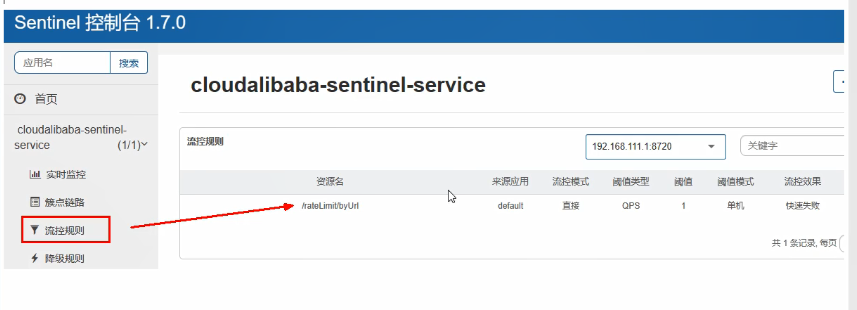
快速访问测试接口:配置成功。
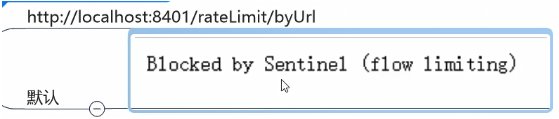
关闭微服务再看sentinel:
重启微服务再看sentinel:(鸡肋)

20.8.2、Alibaba AHAS 与 Alibaba Sentinel
20.8.2.1、AHAS是什么:
应用高可用服务AHAS是一款专注于提高应用高可用能力的SaaS产品,提供应用架构自动探测、故障注入式高可用能力演练、一键应用防护和增加功能开关等功能,可以快速低成本地提升应用可用性。
Alibaba AHAS是商业化的(说白了就是要用钱买)
Alibaba Sentinel是开源的,任何人都能用
Alibaba AHAS完成了对配置信息持久化的更深一层的包装。
更多资料:
Alibaba AHAS 与 Alibaba Sentinel的对比
springcloud(11)Alibaba-AHAS 限流方式
21、SpringCloud Alibaba Seata处理分布式事务
21.1、目前微服务面临的问题
在之前 单机单库 环境下,针对事务的处理还是比较简单的。尤其是结合 Spring 框架,可以说是一个@Transaction 注解走天下。事务 & Spring 事务相关内容,点击链接去了解吧:事务 & Spring 事务内容介绍
在如今 Spring Cloud 分布式微服务架构体系中,按业务模块划分,一个模块使用一个数据库。多个模块配合来完成一个业务,我们就从 官网 的一个微服务实例开始吧。
21.1.1、 用例
用户购买商品的业务逻辑。整个业务逻辑由3个微服务提供支持:
- 仓储服务:对给定的商品扣除仓储数量。
- 订单服务:根据采购需求创建订单。
- 帐户服务:从用户帐户中扣除余额。
21.1.2、架构图
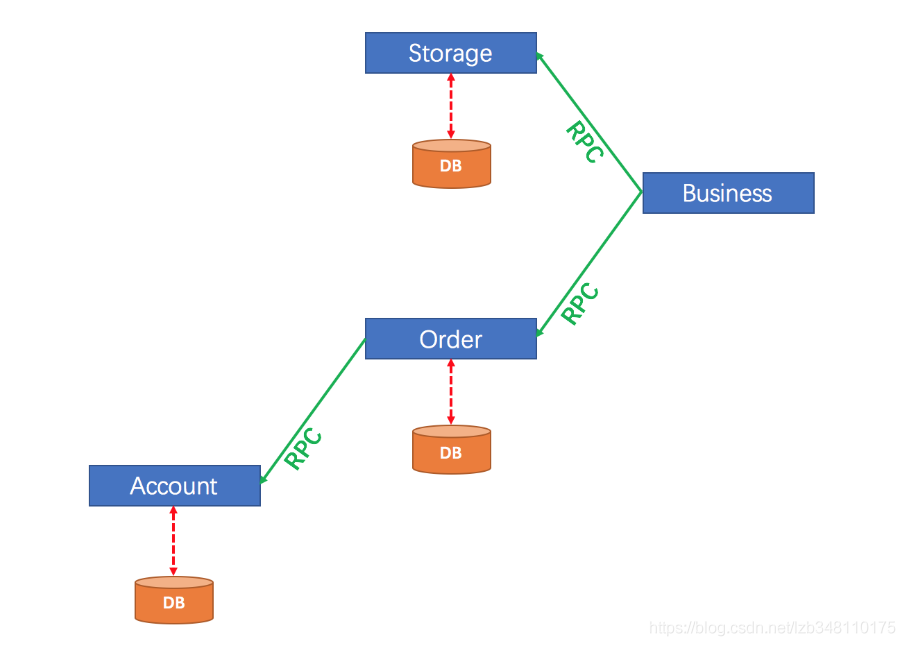
21.1.3、分布式事务解决方案
单体应用被拆分成微服务应用,原来的三个模块被拆分成三个独立的应用,分别使用三个独立的数据源,业务操作需要调用三个服务来完成。此时每个服务内部的数据一致性由本地事务来保证,但是全局数据一致性问题是无法保证的。所以,Alibaba Seata来处理分布式事务
21.2、是什么
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。 Seata 将为用户提供了**AT**、TCC、SAGA和XA事务模式,为用户打造一站式的分布式解决方案。
在 Seata 开源之前,Seata 对应的内部版本在阿里经济体内部一直扮演着分布式一致性中间件的角色,帮助经济体平稳的度过历年的双11,对各部门业务进行了有力的支撑。经过多年沉淀与积累,商业化产品先后在阿里云、金融云进行售卖。2019.1 为了打造更加完善的技术生态和普惠技术成果,Seata 正式宣布对外开源,未来 Seata 将以社区共建的形式帮助其技术更加可靠与完备。
此处重点介绍 **AT模式**,在工作中也最常用,用起来也比较简单。
AT 模式:
提供无侵入自动补偿的事务模式,目前已支持 MySQL、 Oracle 、PostgreSQL和 TiDB的AT模式,H2 开发中
TCC 模式资料:
支持 TCC 模式并可与 AT 混用,灵活度更高
SAGA 模式资料:
为长事务提供有效的解决方案
XA 模式资料:
支持已实现 XA 接口的数据库的 XA 模式
21.3、Seata 术语表
(术语即:名词介绍,以下内容摘自:Seata 官方文档 http://seata.io/zh-cn/docs/overview/terminology.html)
- TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。 - TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。 - RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
其中,TC 为单独部署的 Server 服务端,TM 和 RM 为嵌入到应用中的 Client 客户端。
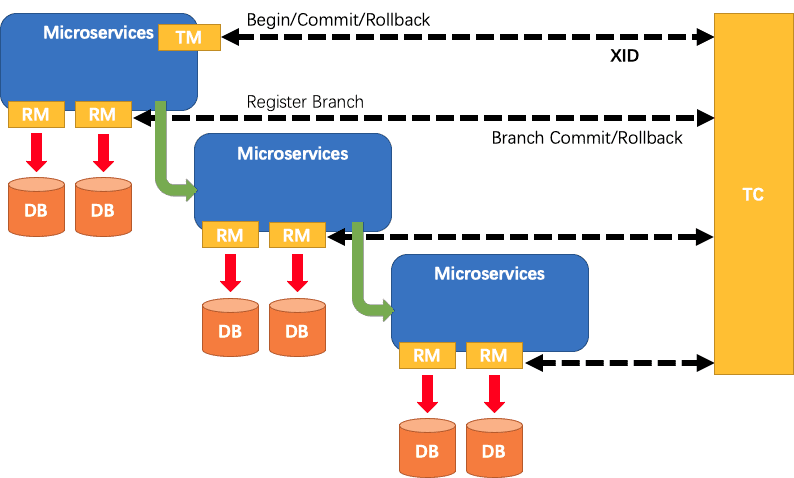
Seata管理的分布式事务的典型生命周期(执行过程):
- TM 向 TC 申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的 XID;
- XID 在微服务调用链路的上下文中传播;
- RM 向 TC 注册分支事务,将其纳入 XID 对应全局事务的管辖;
- TM 向 TC 发起针对 XID 的全局提交或回滚决议;
- TC 调度 XID 下管辖的全局分支事务,完成分支提交或回滚请求。
21.4、AT模式
21.4.1、AT 前提
- 基于支持本地 ACID 事务的关系型数据库。
- Java 应用,通过 JDBC 访问数据库。
21.4.2、AT 整体机制
两阶段提交协议的演变:
- 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
- 二阶段:
- 提交异步化,非常快速地完成。
- 回滚通过一阶段的回滚日志进行
反向补偿。
21.4.3、写隔离
- 一阶段本地事务提交前,需要确保先拿到 全局锁 。
- 拿不到 全局锁 ,不能提交本地事务。
- 拿 全局锁 的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
以一个示例来说明:
两个全局事务 tx1 和 tx2,分别对 a 表的 m 字段进行更新操作,m 的初始值 1000。
tx1 先开始,开启本地事务,拿到本地锁,更新操作 m = 1000 - 100 = 900。本地事务提交前,先拿到该记录的 全局锁 ,本地提交释放本地锁。 tx2 后开始,开启本地事务,拿到本地锁,更新操作 m = 900 - 100 = 800。本地事务提交前,尝试拿该记录的 全局锁 ,tx1 全局提交前,该记录的全局锁被 tx1 持有,tx2 需要重试等待 全局锁 。
tx1 二阶段全局提交,释放 全局锁 。tx2 拿到 全局锁 提交本地事务。
如果 tx1 的二阶段全局回滚,则 tx1 需要重新获取该数据的本地锁,进行反向补偿的更新操作,实现分支的回滚。
此时,如果 tx2 仍在等待该数据的 全局锁,同时持有本地锁,则 tx1 的分支回滚会失败。分支的回滚会一直重试,直到 tx2 的 全局锁 等锁超时,放弃 全局锁 并回滚本地事务释放本地锁,tx1 的分支回滚最终成功。
因为整个过程 全局锁 在 tx1 结束前一直是被 tx1 持有的,所以不会发生 脏写 的问题。
21.4.4、读隔离
在数据库本地事务隔离级别 读已提交(Read Committed) 或以上的基础上,Seata(AT 模式)的默认全局隔离级别是 读未提交(Read Uncommitted) 。
如果应用在特定场景下,必需要求全局的 读已提交 ,目前 Seata 的方式是通过 SELECT FOR UPDATE 语句的代理。
SELECT FOR UPDATE 语句的执行会申请 全局锁 ,如果 全局锁 被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试。这个过程中,查询是被 block 住的,直到 全局锁 拿到,即读取的相关数据是 已提交 的,才返回。
出于总体性能上的考虑,Seata 目前的方案并没有对所有 SELECT 语句都进行代理,仅针对 FOR UPDATE 的 SELECT 语句。
21.4.5、工作机制
以一个示例来说明整个 AT 分支的工作过程。
业务表:product
| Field | Type | Key |
|---|---|---|
| id | bigint(20) | PRI |
| name | varchar(100) | |
| since | varchar(100) |
AT 分支事务的业务逻辑:
1 | update product set name = 'GTS' where name = 'TXC'; |
21.4.5.1、一阶段
过程:
- 解析 SQL:得到 SQL 的类型(UPDATE),表(product),条件(where name = ‘TXC’)等相关的信息。
- 查询前镜像:根据解析得到的条件信息,生成查询语句,定位数据。
1 | select id, name, since from product where name = 'TXC'; |
得到前镜像:
| id | name | since |
|---|---|---|
| 1 | TXC | 2021 |
- 执行业务 SQL:更新这条记录的 name 为 ‘GTS’。
- 查询后镜像:根据前镜像的结果,通过 主键 定位数据。
1 | select id, name, since from product where id = 1`; |
得到后镜像:
| id | name | since |
|---|---|---|
| 1 | GTS | 2021 |
插入回滚日志:把前后镜像数据以及业务 SQL 相关的信息组成一条回滚日志记录,插入到 UNDO_LOG 表中。
1 | { |
- 提交前,向 TC注册分支:申请
product表中,主键值等于 1 的记录的全局锁. - 本地事务提交:业务数据的更新和前面步骤中生成的 UNDO LOG 一并提交。
- 将本地事务提交的结果上报给 TC。
21.4.5.2、二阶段-回滚
收到 TC 的分支回滚请求,开启一个本地事务,执行如下操作。
通过 XID 和 Branch ID 查找到相应的 UNDO LOG 记录。
数据校验:拿 UNDO LOG 中的后镜与当前数据进行比较,如果有不同,说明数据被当前全局事务之外的动作做了修改(脏写)。这种情况,需要根据配置策略来做处理,详细的说明在另外的文档中介绍。
根据 UNDO LOG 中的前镜像和业务 SQL 的相关信息生成并执行回滚的语句:
1
update product set name = 'TXC' where id = 1;
提交本地事务。并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC。
21.4.5.3、二阶段-提交
- 收到 TC 的分支提交请求,把请求放入一个异步任务的队列中,马上返回提交成功的结果给 TC。
- 异步任务阶段的分支提交请求将异步和批量地删除相应
UNDO LOG记录。
回滚事务表:
UNDO_LOG Table:不同数据库在类型上会略有差别。
以 MySQL 为例:
| Field | Type |
|---|---|
| branch_id | bigint PK |
| xid | varchar(100) |
| context | varchar(128) |
| rollback_info | longblob |
| log_status | tinyint |
| log_created | datetime |
| log_modified | datetime |
1 | -- 注意此处0.7.0+ 增加字段 context |
21.4.5.4、总结
- 是什么
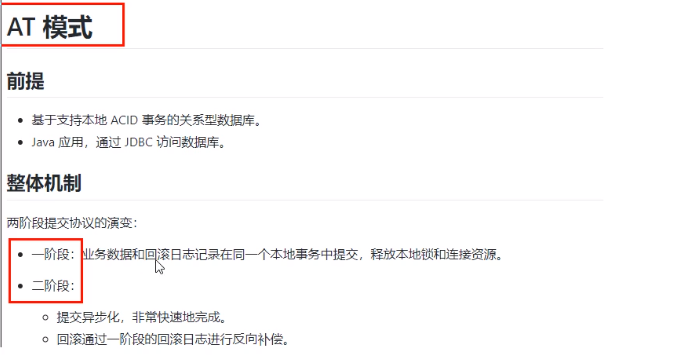
- 一阶段加载:

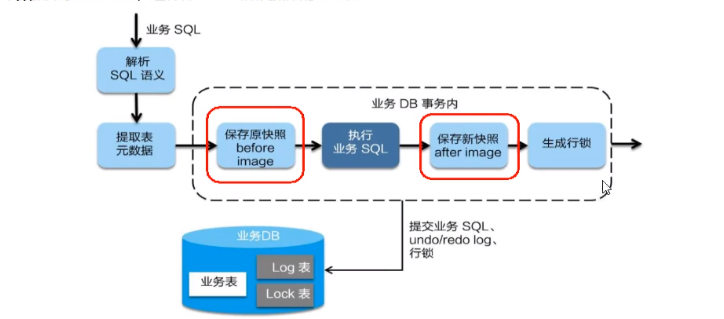
- 二阶段提交:
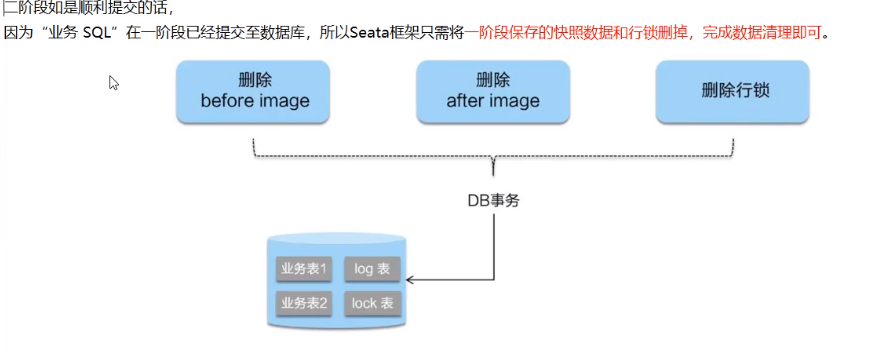
- 二阶段回滚:

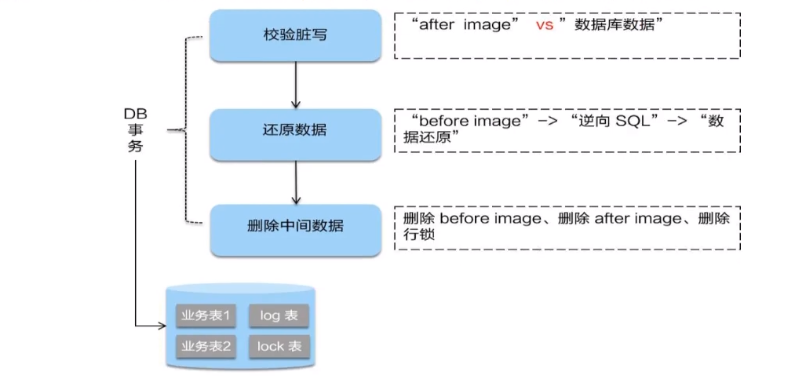
21.5、Spring Cloud 整合 Nacos 1.3.1 + Seata 1.2.0 集群部署(Windows版)
21.5.1、环境说明
部署环境+版本: MySQL 5.7.x + Nacos 1.3.1 + Seata 1.2.0 + **Windows 环境演示**,Linux 部署类似。
21.5.2、Seata 1.2.0 下载
进入 Seata 官网下载地址 或者 Seata Github下载地址,选择 Seata 1.2.0 版本下载。
21.5.3、官网新人文档中的资源目录介绍
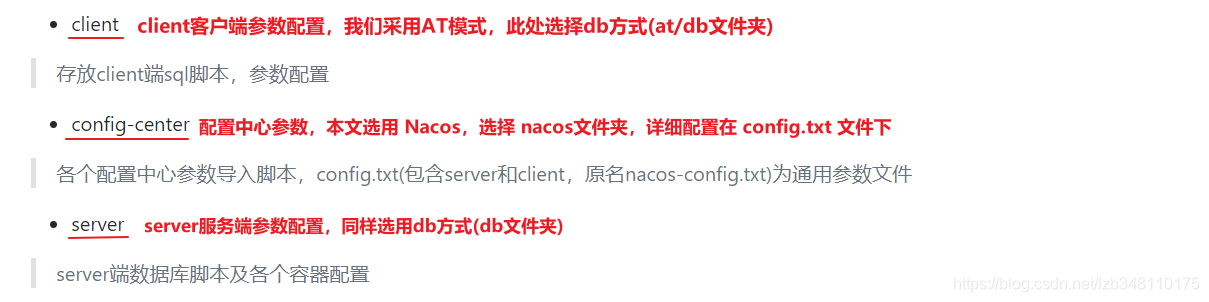
详细说明
21.5.4、Seata Server 端配置
21.5.4.1、解压
将下载的 seata-server-1.2.0.zip 解压到某个路径下(注意该路径不要有中文或空格)。
21.5.4.2、MySQL 数据库配置
1、执行MySQL数据库操作前,需要我们手动创建一个名称为 seata 的数据库,然后在该数据库下建表。建库命令如下:
1 | CREATE DATABASE seata DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci; |
进入 资源目录 seata/script/server/db/mysql.sql ,执行SQL语句。建表语句如下,你也可以点击链接获取。
1 | -- -------------------------------- The script used when storeMode is 'db' -------------------------------- |
21.5.4.3、Server端参数项配置
解压后,进入 conf 目录开始参数的配置。我们修改 file.conf 和 registry.conf 这两个文件。
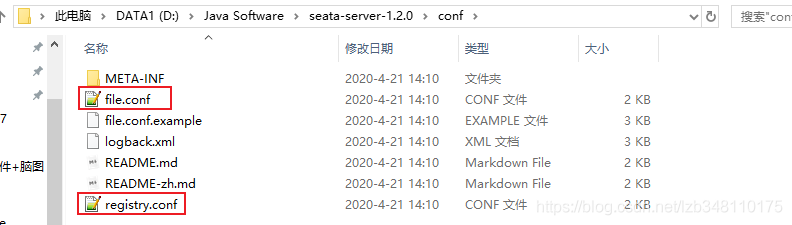
对 file.conf 配置:
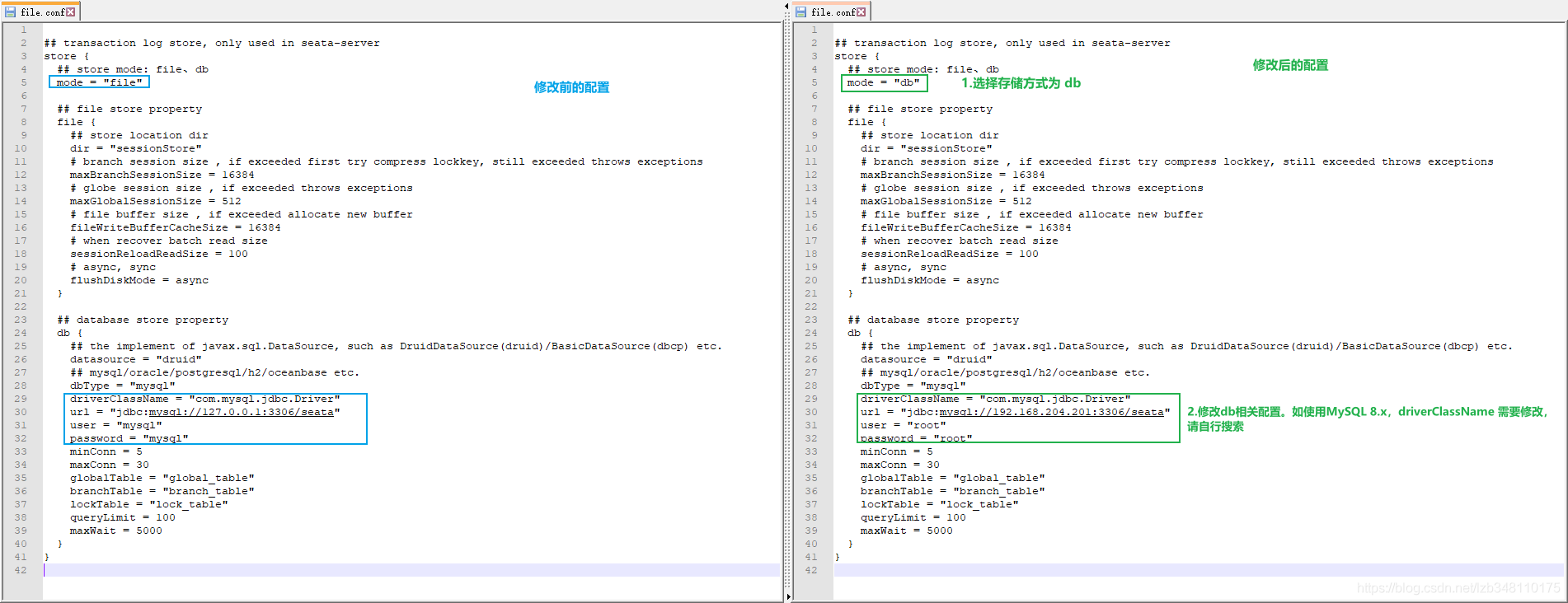
对 registry.conf 配置:
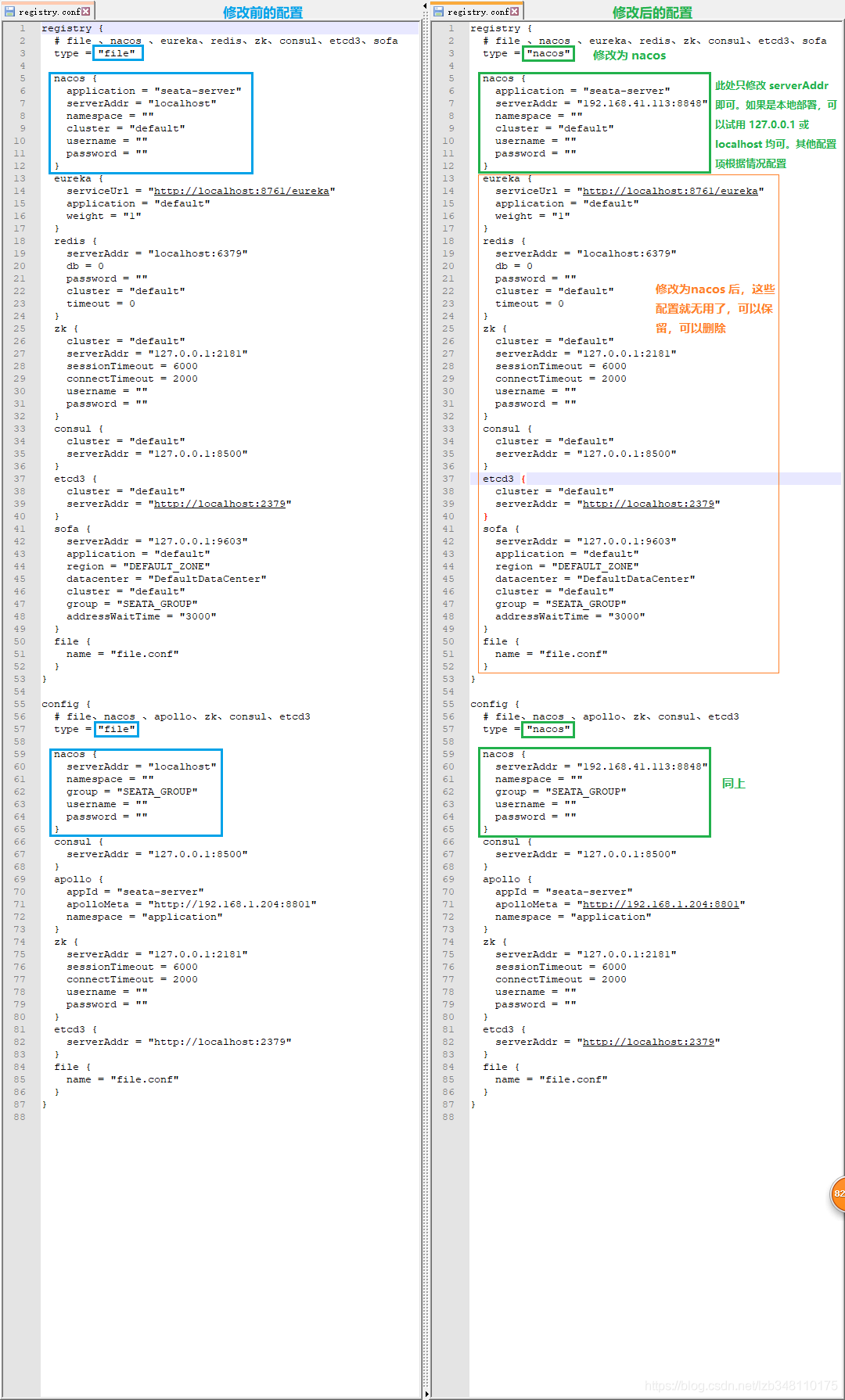
21.5.4.4、启动Seata Server端
进入 bin 目录,双击 seata-server.bat 启动。(Linux环境请选择 seata-server.sh 启动)
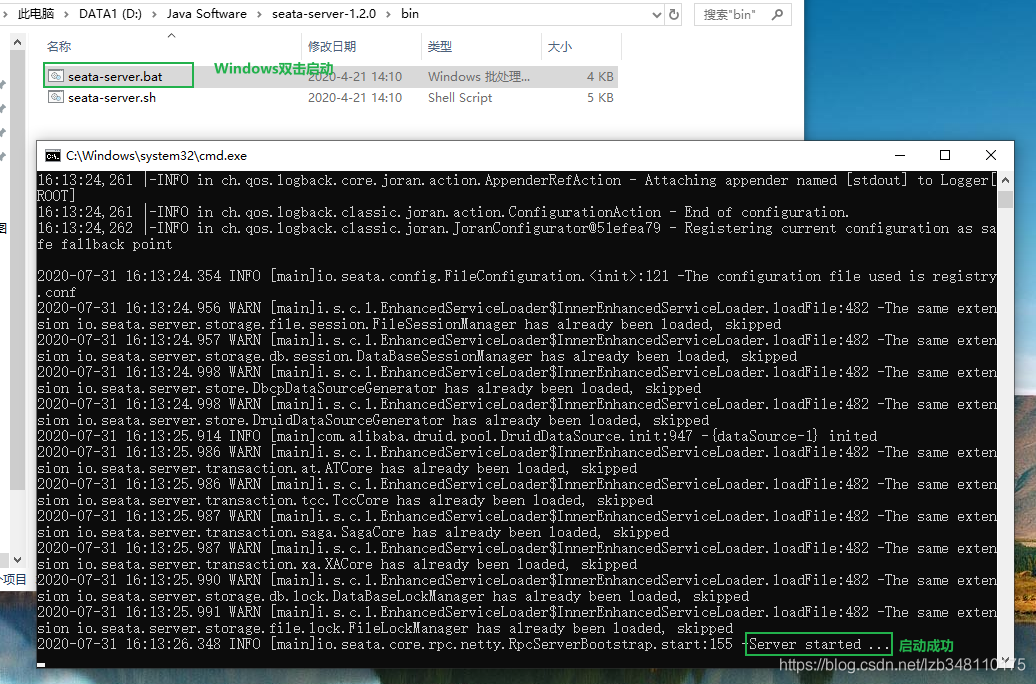
到此为止,Seata Server 端启动完成。
21.5.5、config-center 配置中心配置
配置中心的配置,本文使用 nacos 作为配置中心。
21.5.5.1、获取要配置的参数信息
进入 资源目录 seata/script/config-center/config.txt ,展示的是 Seata 1.2.0 版本所有配置中心的内容,全部配置点击链接查看。本文使用db方式,故选择db相关配置,需要用到的配置如下:
1 | service.vgroupMapping.my_test_tx_group=default |
21.5.5.2、将参数配置到Nacos配置中心
进入 资源目录 seata/script/config-center/nacos/nacos-config.sh ,该配置会将 seata 相关配置批量添加到 nacos 服务器。
该脚本可以随便放在某个位置,只要脚本 nacos-config.sh 能够读取到 config.txt 文件即可。本文放在如下为止
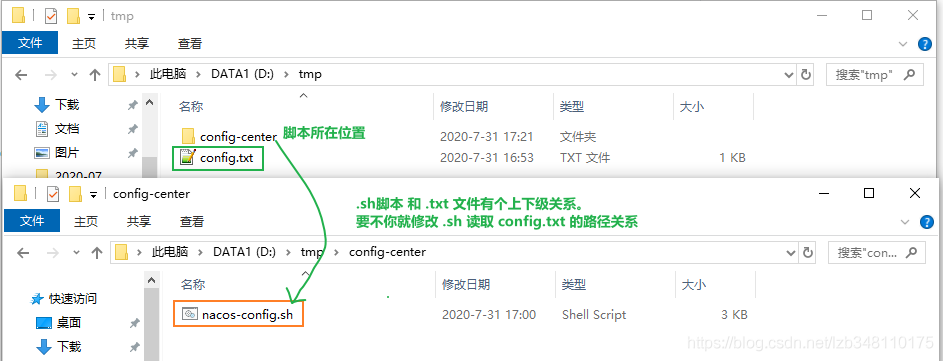
你自己打开nacos-config.sh脚本 看看它查找 config.txt 的逻辑就可以了,只要能够读取到 config.txt 文件即可。nacos-config.sh 脚本支持传入四个参数:
- -h nacos 所在服务器的IP地址,默认为 localhost
- -p nacos 端口号,默认为 8848
- -g nacos 配置所属 group 名称,默认为 SEATA_GROUP
- -t 将 nacos 配置保存到指定的命名空间,默认为 “”,代表 public 命名空间(注意:-t 参数值接收的是 命名空间ID,不是 命名空间名称)
使用 git 命令框 执行 sh nacos-config.sh ,就可以将配置批量保存到 nacos 服务器。如下图所示:
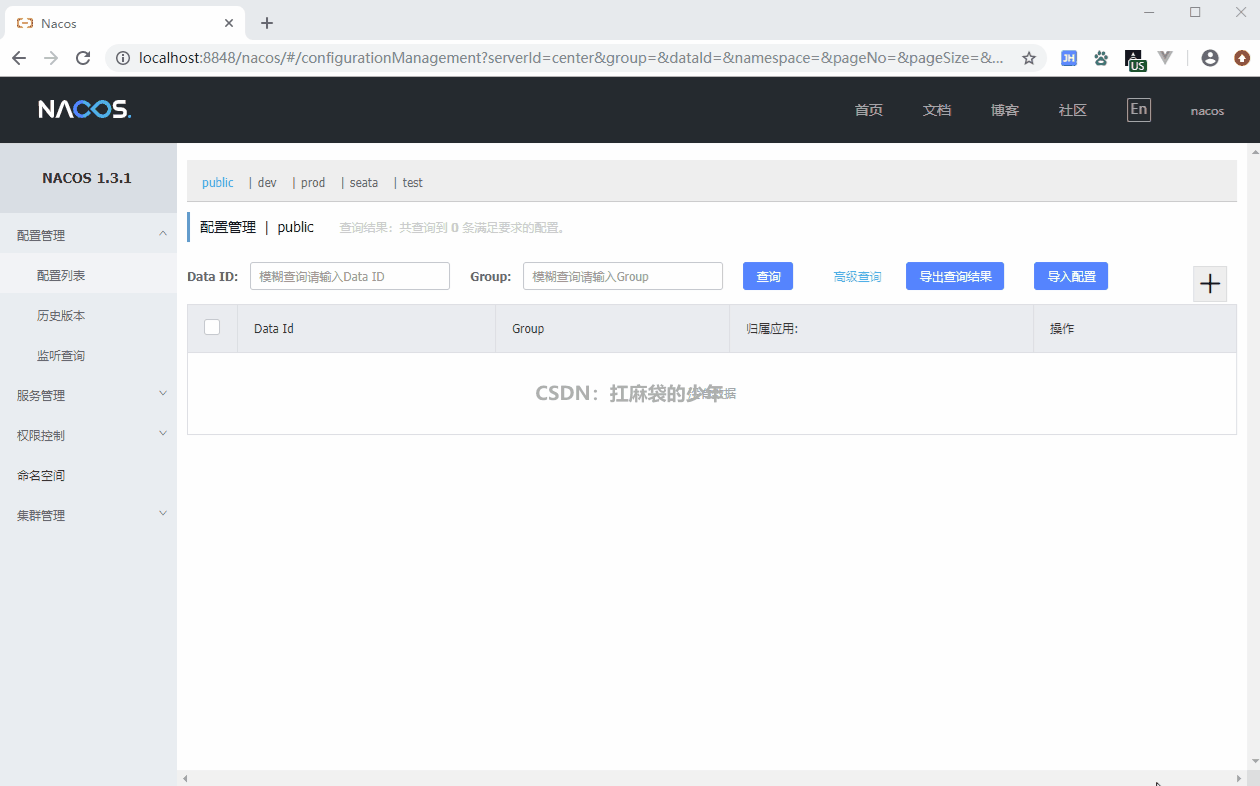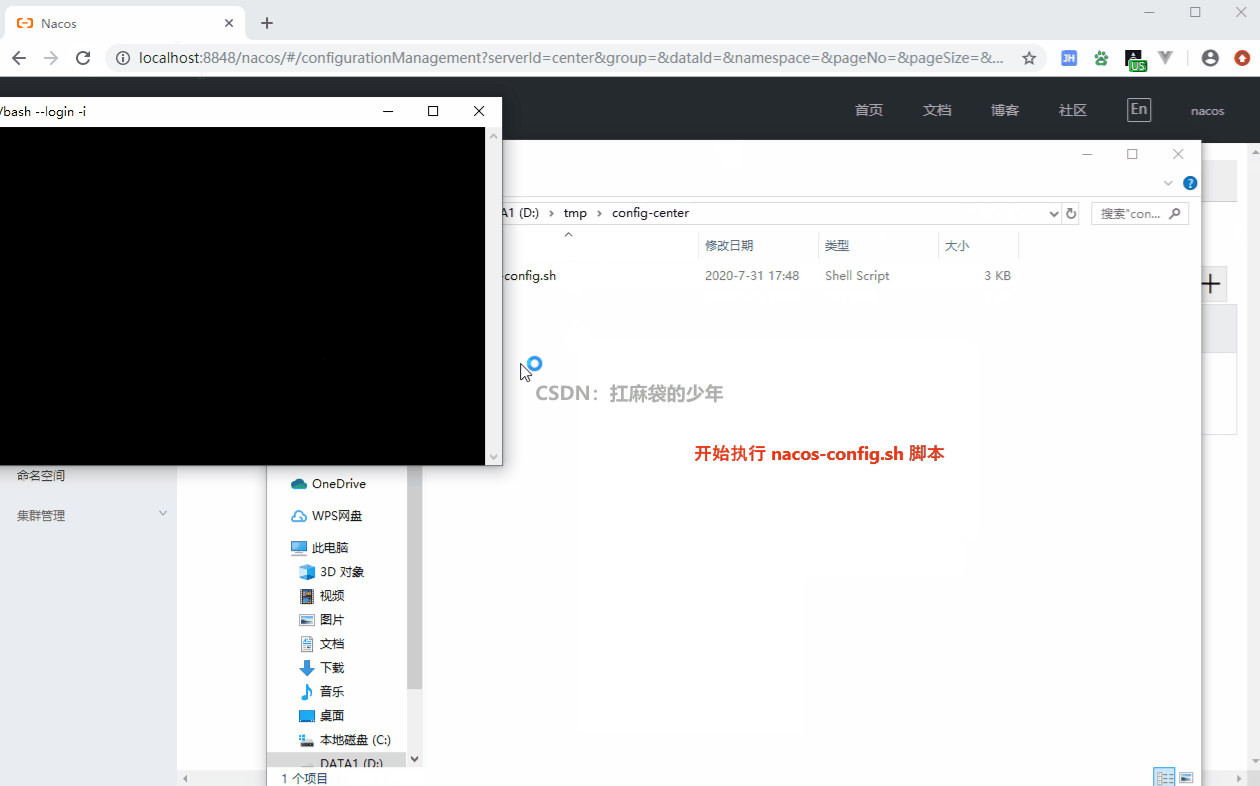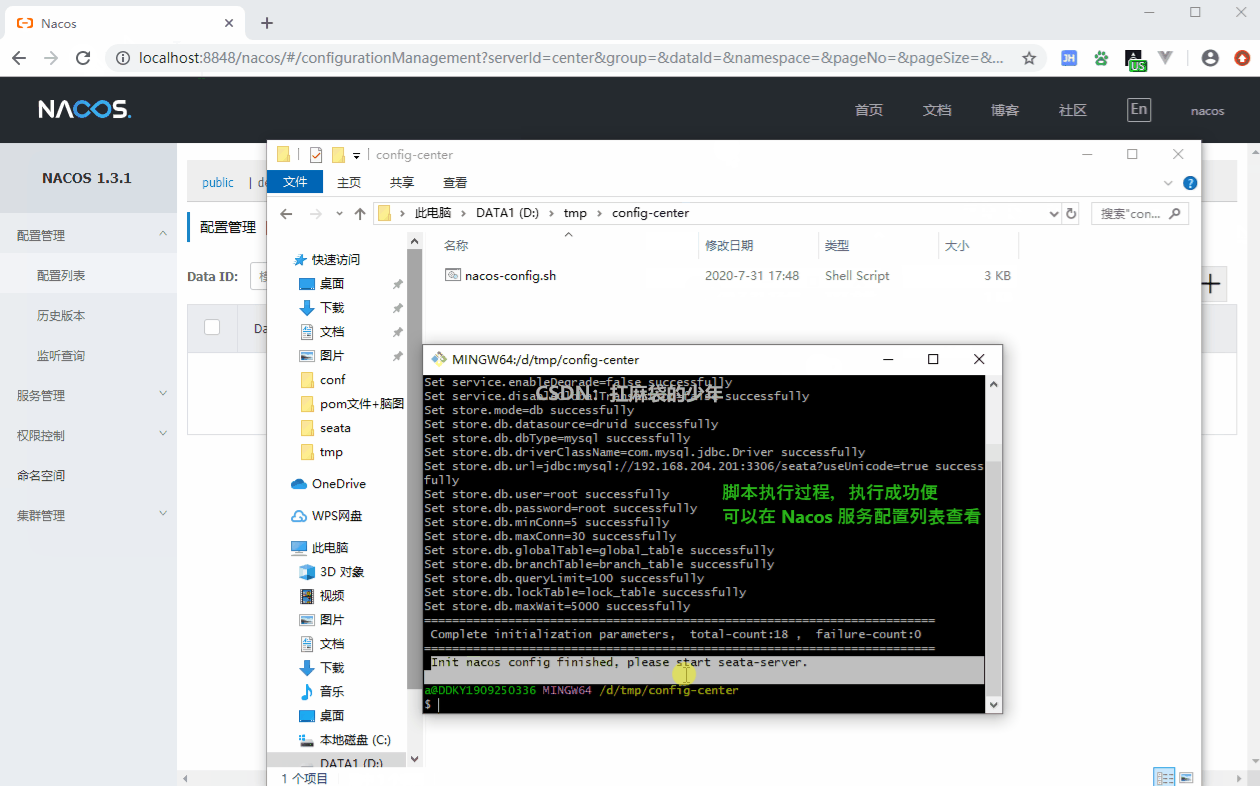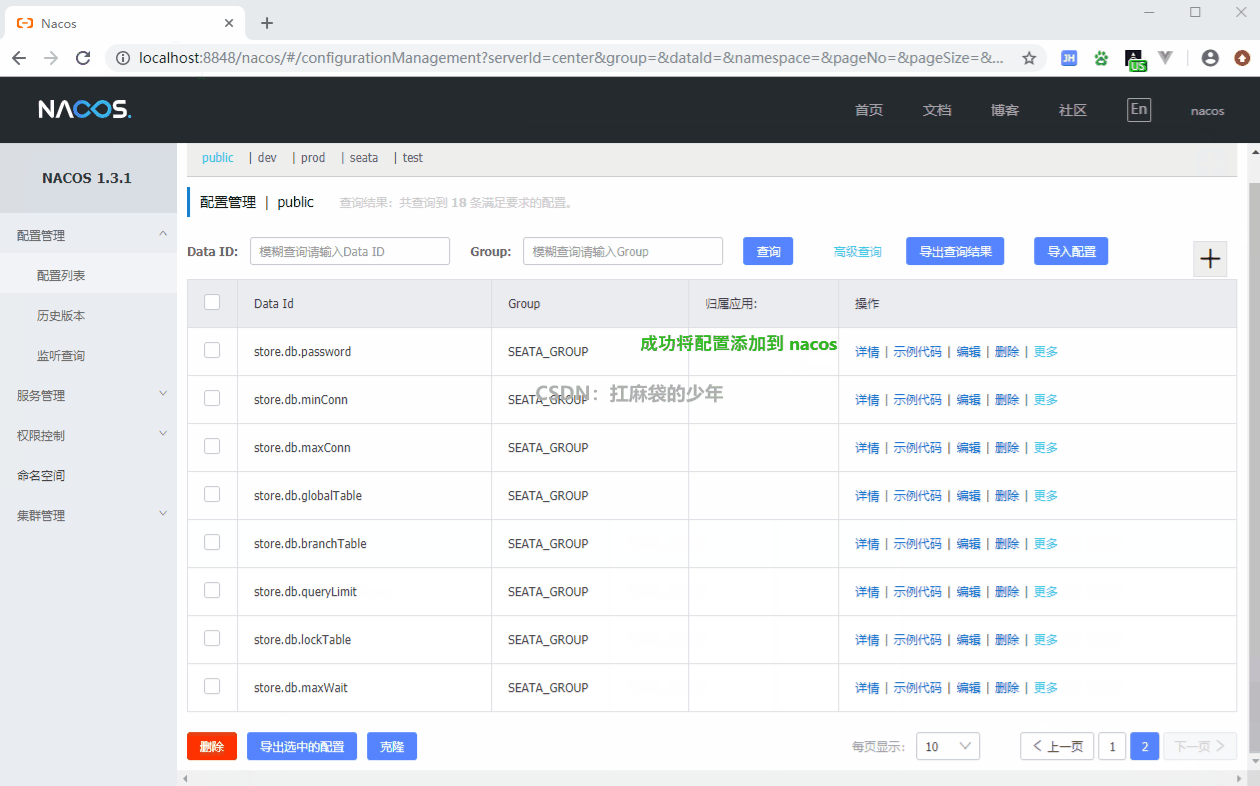
到此为止,Config Center 配置中心参数,配置完成。
21.5.6、client 客户端配置
21.5.6.1、业务场景
用户购买商品的业务逻辑。整个业务逻辑由3个微服务提供支持:
- 订单服务A:根据采购需求创建订单。
- 仓储服务B:对给定的商品扣除仓储数量。
- 帐户服务C:从用户帐户中扣除余额。
用户A购买商品,调用A服务创建订单完成,调用B服务扣减库存,然后调用C服务扣减账户余额。每个服务内部的数据一致性由本地事务来保证,多个服务调用来完成业务,全局事务数据一致性则由 Seata 来保证。
21.5.6.2、业务数据库准备
配置三个业务分别对应各自的数据库。
- A服务 对应数据库:seata_order ;表:t_order
- B服务 对应数据库:seata_storage ;表:t_storage
- C服务 对应数据库:seata_account ;表:t_account
建库,建表语句如下:
1 | # 创建seata_order数据库 |
1 | # 创建seata_storage数据库 |
1 | # 创建seata_account数据库 |
21.5.6.3、创建 undo_log 表
进入 资源目录 seata/script/client/at/db/mysql.sql ,展示的就是 undo_log 表的建表语句,该表需要在涉及到事务处理的每个库中都添加以下。undo_log 表建表语句如下:
1 | -- for AT mode you must to init this sql for you business database. the seata server not need it. |
21.5.6.4、库表创建完成图示
21.5.6.5、添加 pom 依赖
pom.xml 部分的注意事项,可参考:部署指南-注意事项
1 | <!--seata--> |
21.5.6.7、application.yml 针对 seata 进行配置
进入资源目录seata/script/client/spring/,展示的就是 seata 整合 Spring 的全部配置内容,提供了.properties、.yml两种格式的配置。详细的配置项还挺多,此处就不粘贴了,你可以点击 资源目录 查看。此处挑选了本案例需要的部分内容进行配置,配置如下所示:(项目application.yml完整配置,请参考文末项目完整代码)
该配置在每个服务模块都需要配置一份,你也可以通过 nacos 配置中心的方式配置使用。
1 | seata: |
业务代码略
21.5.7、Seata 高可用集群部署
21.5.7.1、集群部署
Seata 集群部署比较简单,只需将已配置好的 seata-server 再启动一个即可。seata 默认使用 8091 端口,此次我在 Windows 部署,所以 seata-server 第二个节点选用 8092 端口,进入 cmd 命令行,使用命令:seata-server.bat -p 8092启动seata-server 第二台节点。(Linux 正式环境,多机器的话,只需要 scp 到另一台机器,启动即可)
通过 nacos 服务列表,seata-server 实例数由 1 变为 2。端口分别为 8091、8092 。集群搭建完成,挺简单的。想要几个节点就来几个节点,so easy。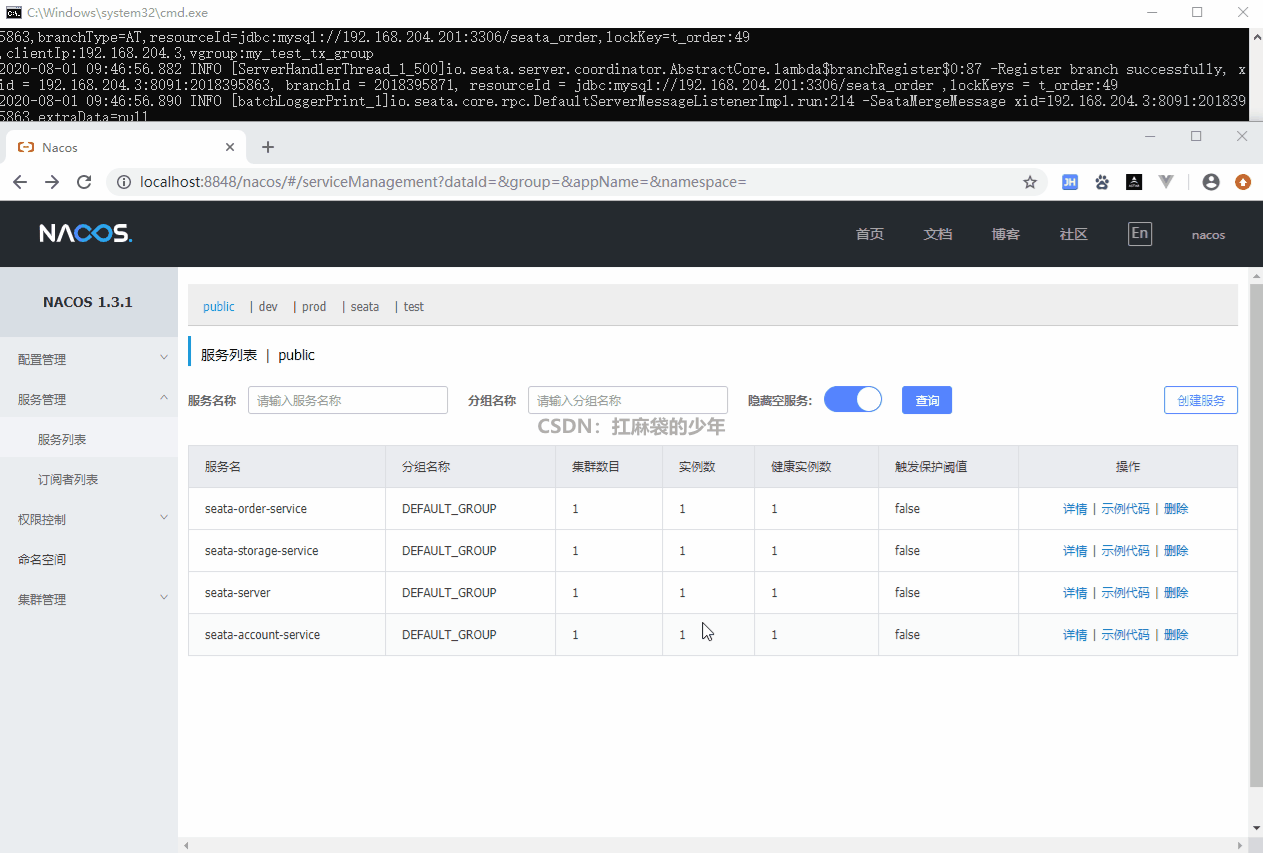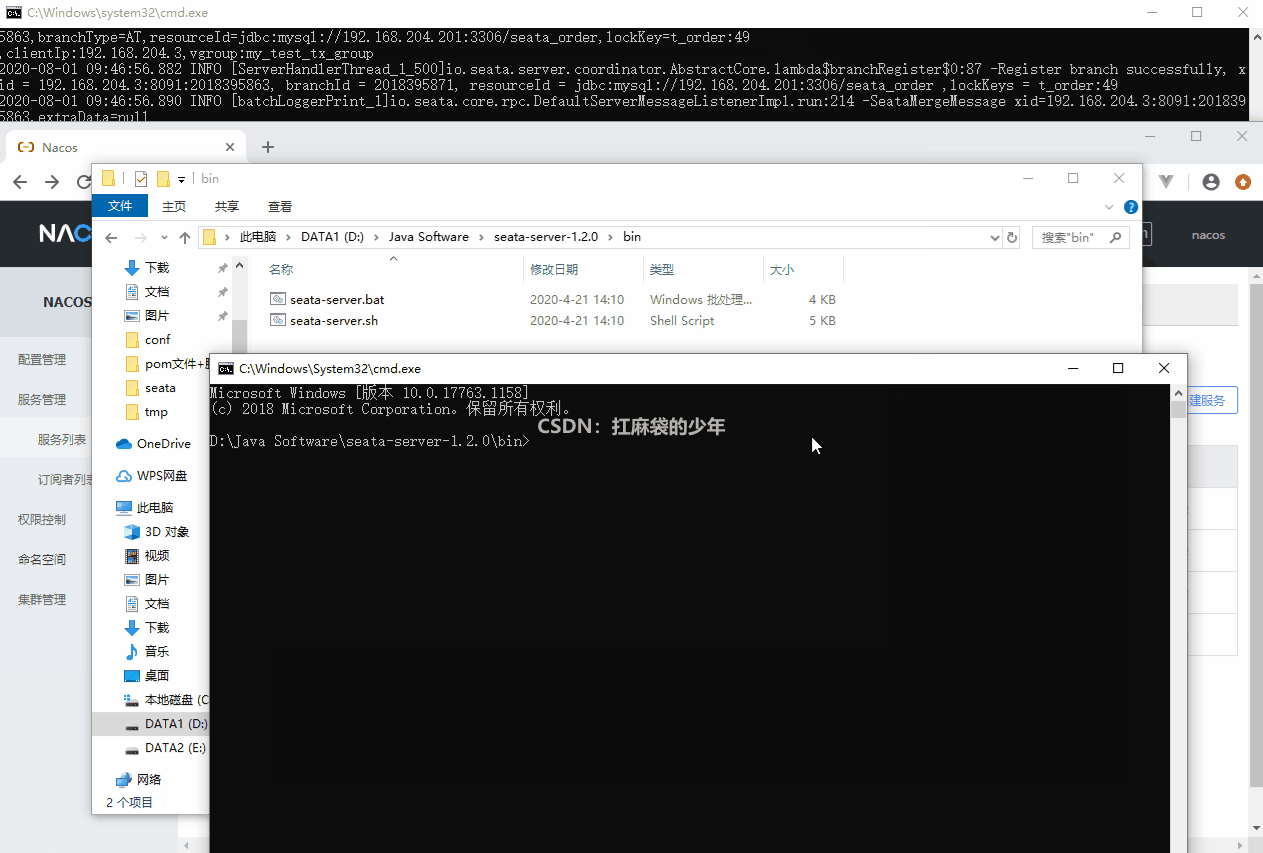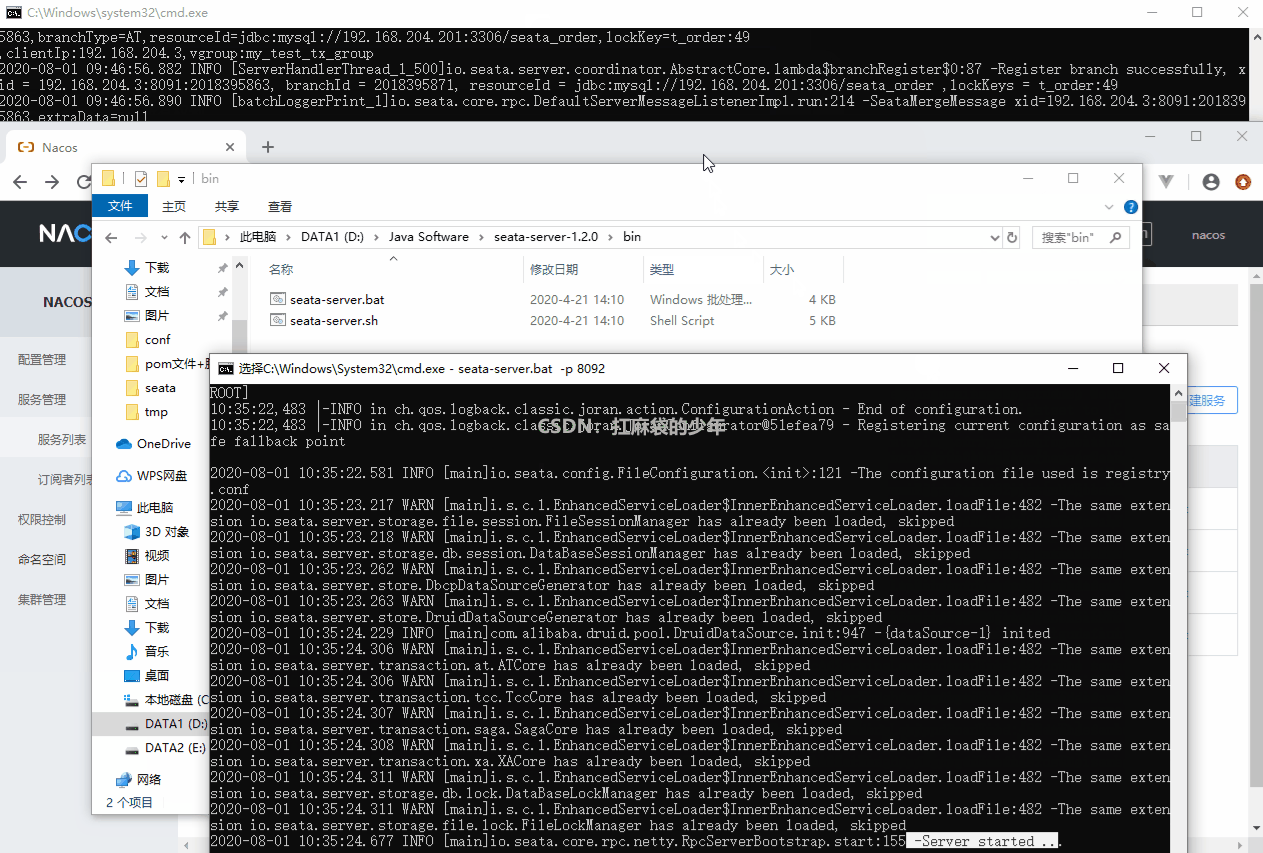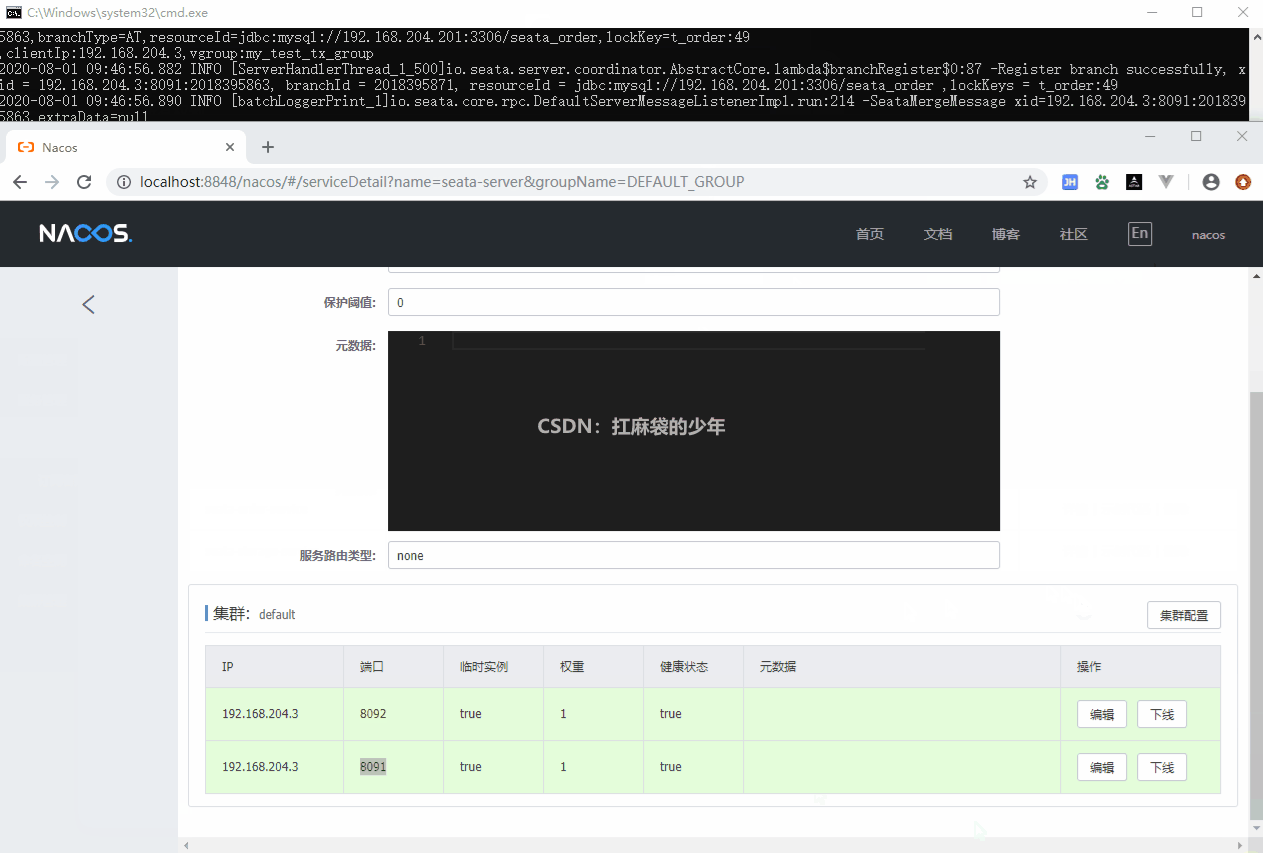
21.5.7.2、服务注册成功
3个服务启动成功后,均会通过 RPC 的方式注册到 Seata 集群的两个节点上来,如下图所示:
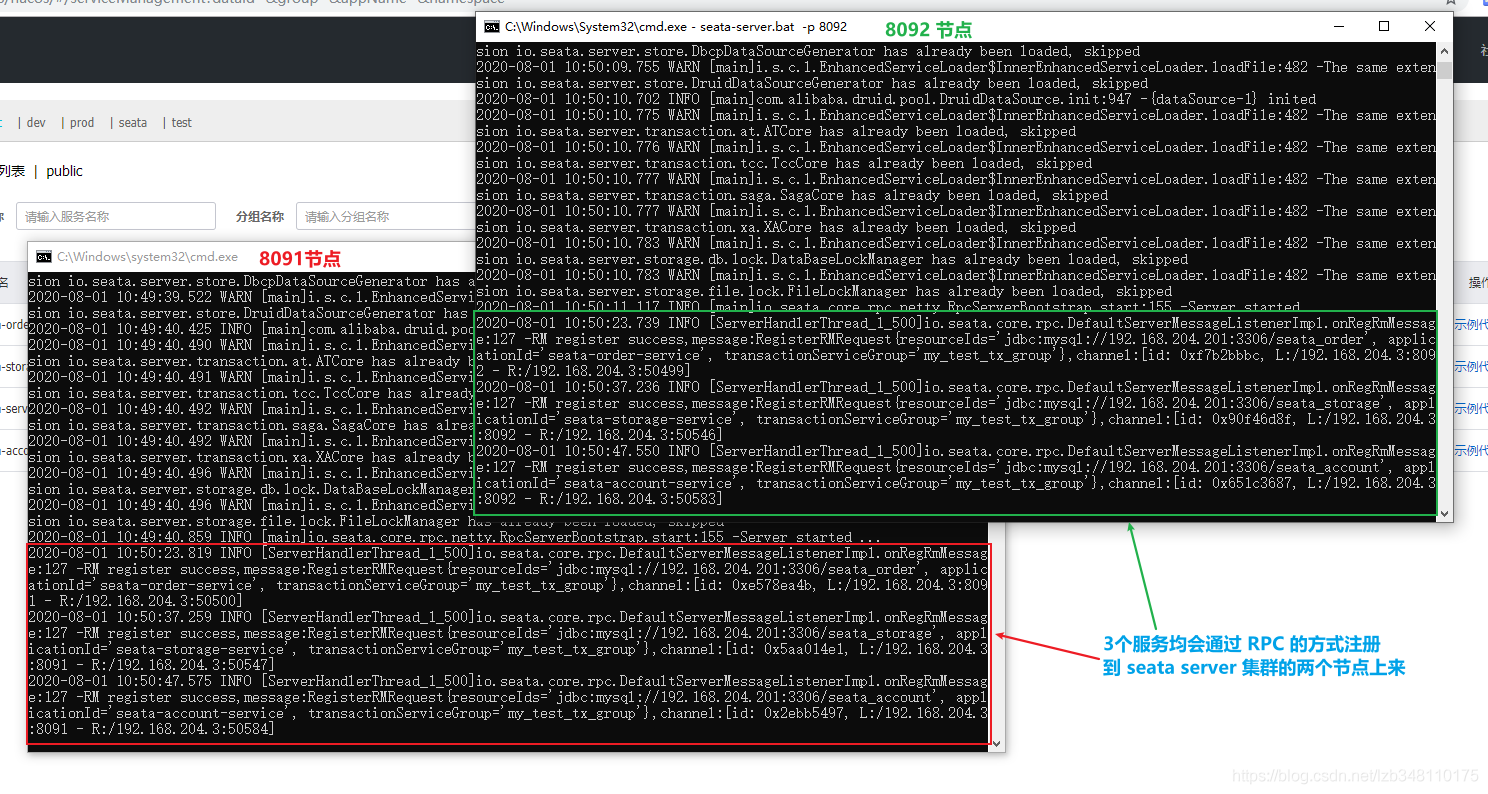
21.5.7.3、Seata集群测试
使用 postman 发送 50 个请求,中途关闭 8091 节点。由于集群之间通过 Nacos 通信原因,一个节点的突然宕机,会导致部分请求失败,但是服务很快便会恢复正常。
当再次将 8091 节点启动后,服务还是能够正常请求,8091 节点也有事务相应的日志显示,说明Seata 集群能够正常提供服务。测试如图所示: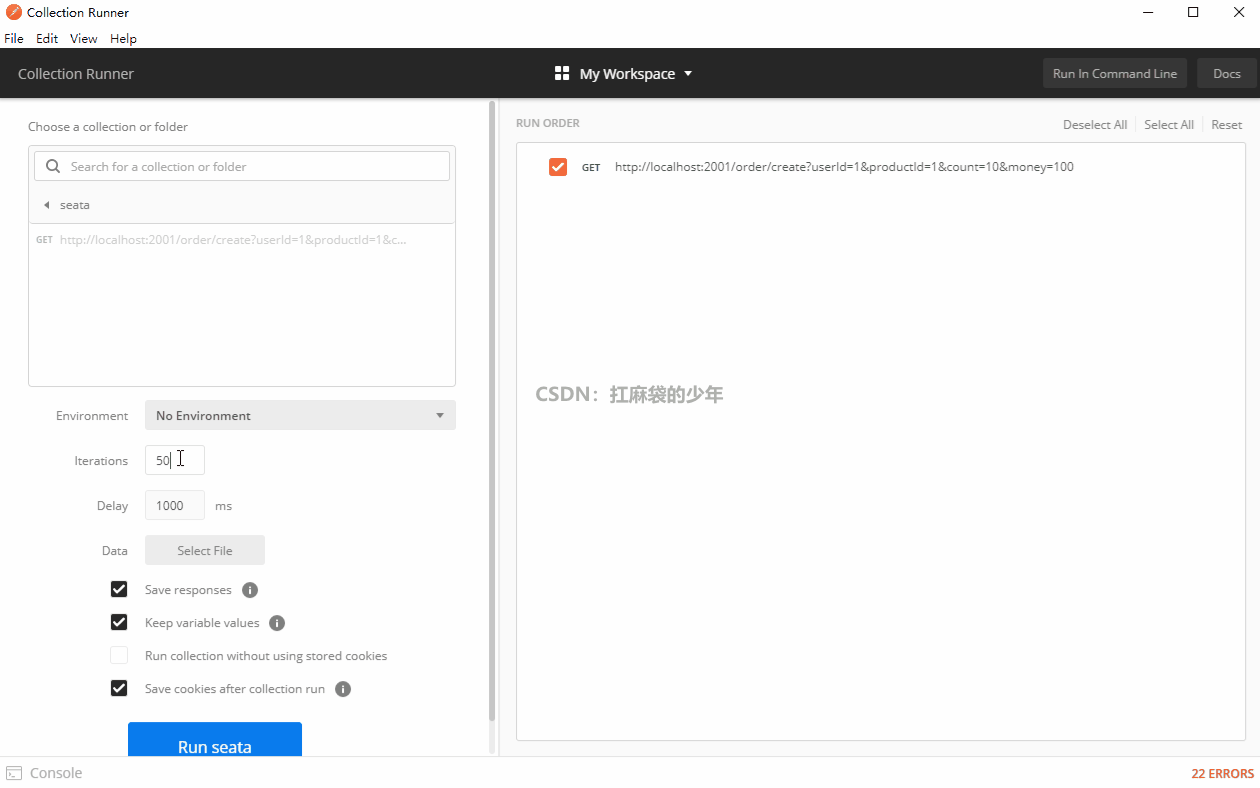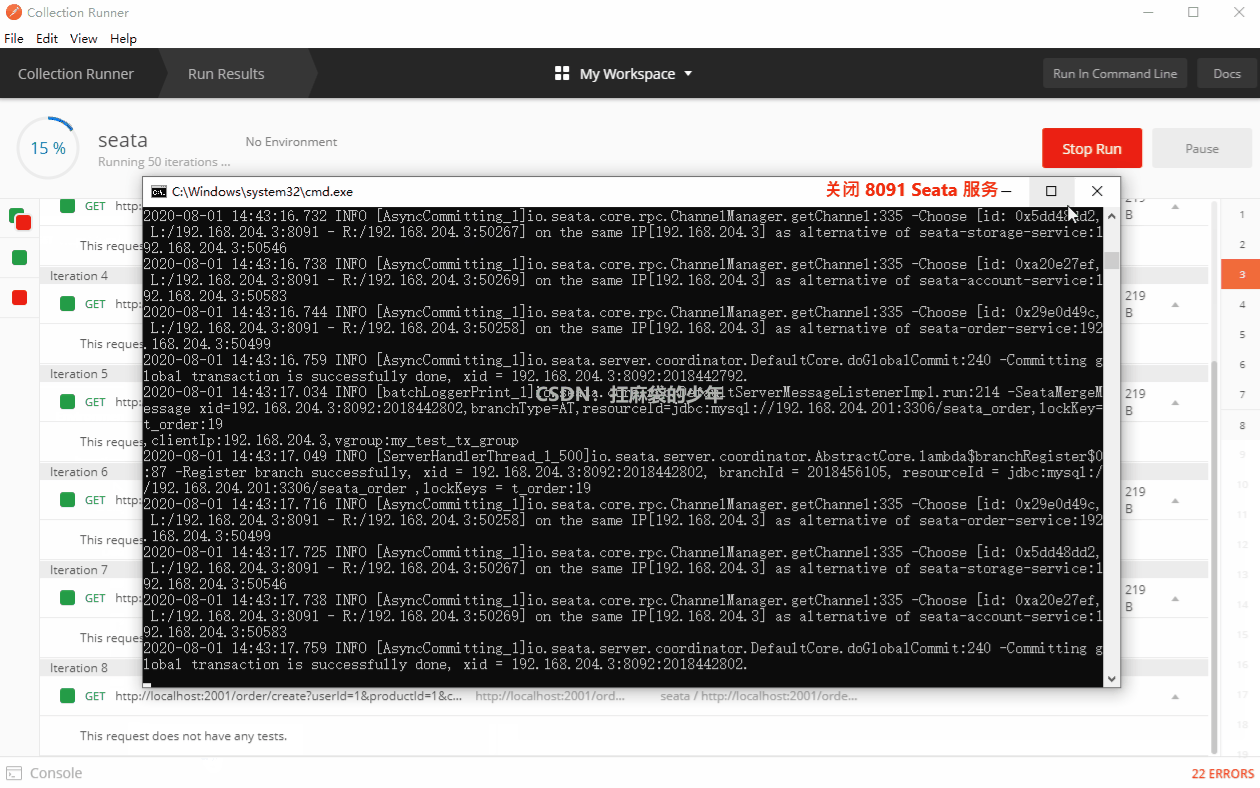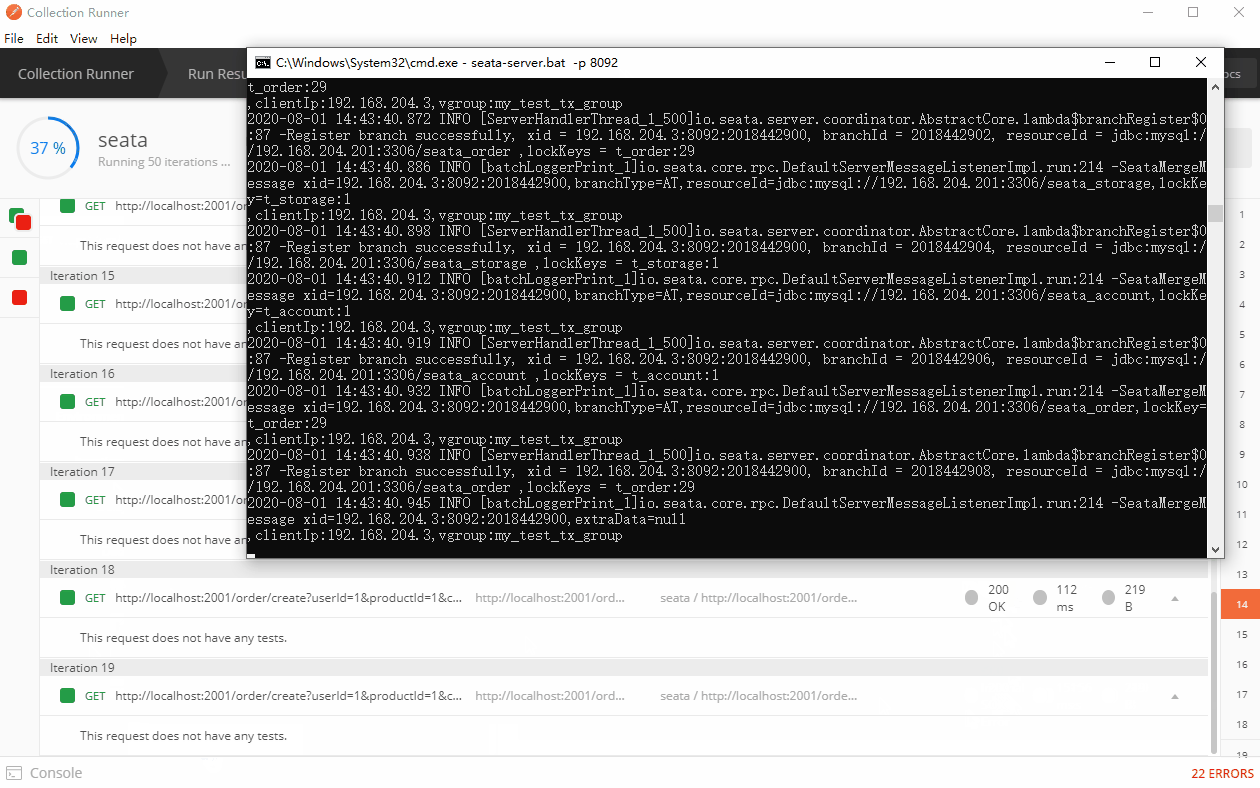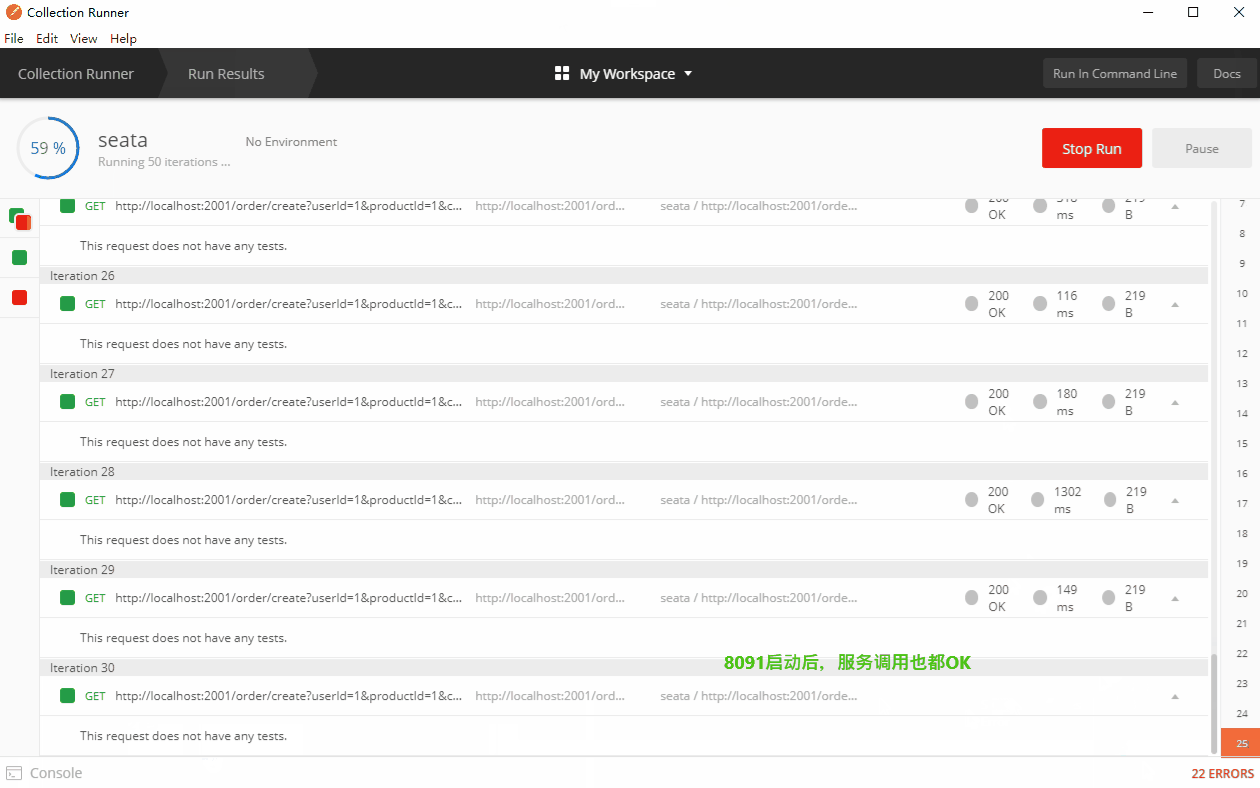
21.5.8、全局事务服务 GTS-阿里云
21.5.8.1、是什么
全局事务服务(Global Transaction Service,简称 GTS)是一款高性能、高可靠、接入简单的分布式事务中间件,用于解决分布式环境下的事务一致性问题。 在单机数据库下很容易维持事务的 ACID(Atomicity、Consistency、Isolation、Durability)特性,但在分布式系统中并不容易,GTS 可以保证分布式系统中的分布式事务的 ACID 特性。 GTS 支持 DRDS、RDS、MySQL 等多种数据源,可以配合 EDAS 和 Dubbo 等微服务框架使用, 兼容 MQ 实现事务消息。通过各种组合,可以轻松实现分布式数据库事务、多库事务、消息事务、服务链路级事务等多种业务需求。
21.5.8.2、GTS与Seata
- Seata:开源框架
- GTS:付费的商用框架