23种设计模式
[TOC]
1、引子
1、设计模式采用的七大原则:
单一职责原则
接口隔离原则
依赖倒转原则
里氏替换原则
开闭原则(ocp)
工厂模式
迪米特原则
合成复用原则
单例设计模式一共有 8 种写法:
- 饿汉式 两种
- 懒汉式 三种
- 双重检查
- 静态内部类
- 枚举
2、设计模式的重要性
- 软件工程中,设计模式(design pattern)是对软件设计中普遍存在(反复出现)的各种问题,所提出的解决方案。这个术语是由埃里希·伽玛(Erich Gamma)等人在 1990 年代从建筑设计领域引入到计算机科学的
- 拿实际工作经历来说, 当一个项目开发完后,如果客户提出增新功能,怎么办?(可扩展性,使用设计模式,软件具有很好的扩展性)
- 如果项目开发完后,原来程序员离职,你接手维护该项目怎么办? (维护性[可读性、规范性])
- 目前程序员门槛越来越高,一线IT公司(大厂),都会问你在实际项目中使用过什么设计模式,怎样使用的,解决了什么问题
- 设计模式在软件中哪里?面向对象(oo)=>功能模块[设计模式+算法(数据结构)]=>框架[使用到多种设计模式]=> 架构 [服务器集群]
- 如果想成为合格软件工程师,那就花时间来研究下设计模式是非常必要的.
3、设计模式的讲解过程
讲解的步骤
- 应用场景
- 普通代码解决
- 设计模式解决【对比】
- 剖析原理
- 分析实现步骤(图解)
- 代码实现
- 框架或项目源码分析(找到使用的地方) 的步骤讲解
2、设计模式七大原则(单接依里开迪合)
2.1、设计模式的目的
编写软件过程中,程序员面临着来自 耦合性,内聚性以及可维护性,可扩展性,重用性,灵活性 等多方面的挑战,设计模式是为了让程序(软件),具有更好的:
- 代码重用性 (即:相同功能的代码,不用多次编写)
- 可读性 (即:编程规范性, 便于其他程序员的阅读和理解)
- 可扩展性 (即:当需要增加新的功能时,非常的方便,称为可维护)
- 可靠性 (即:当我们增加新的功能后,对原来的功能没有影响)
- 使程序呈现高内聚,低耦合的特性
2.2 、设计模式七大原则
设计模式原则,其实就是程序员在编程时,应当遵守的原则,也是各种设计模式的基础(即:设计模式为什么这样设计的依据)
设计模式常用的七大原则有:
- 单一职责原则
- 接口隔离原则
- 依赖倒转(倒置)原则
- 里氏替换原则
- 开闭原则
- 迪米特法则
- 合成复用原则
2.3、单一职责原则(Single Responsibility Principle)
2.3.1、基本介绍
单一职责的含义是:类的职责单一,引起类变化的原因单一。对类来说的,即一个类应该只负责一项职责。解释一下,这也是灵活的前提,如果我们把类拆分成最小的职能单位,那组合与复用就简单的多了,如果一个类做的事情太多,在组合的时候,必然会产生不必要的方法出现,这实际上是一种污染。
如类 A 负责两个不同职责:职责 1,职责 2。当职责 1 需求变更而改变 A 时,可能造成职责 2 执行错误,所以需要将类 A 的粒度分解为 A1,A2。
SRP优点:消除耦合,减小因需求变化引起代码僵化。
2.3.2、应用实例
需求:以交通工具案例讲解(海陆空)
方案 1 [分析说明]
1 | public class SingleResponsibility1 { |
方案 2 [分析说明]
1 | public class SingleResponsibility1 { |
方案 3 [分析说明]
1 | public class SingleResponsibility3 { |
2.3.3、单一职责原则注意事项和细节
- 降低类的复杂度,一个类只负责一项职责。
- 提高类的可读性,可维护性
- 降低变更引起的风险
- 在实际编码的过程中很难将它恰当地运用,需要结合实际情况进行运用。
- 通常情况下,我们应当遵守单一职责原则,只有逻辑足够简单,才可以在代码级违反单一职责原则;只有类中方法数量足够少,可以在方法级别保持单一职责原则
2.4 、接口隔离原则(Interface Segregation Principle)
2.4.1、基本介绍
它的含义是尽量使用职能单一的接口,而不使用职能复杂、全面的接口。
接口是为了让子类实现的,如果子类想达到职能单一,那么接口也必须满足职能单一。 相反,如果接口融合了多个不相关的方法,那它的子类就被迫要实现所有方法,尽管有些方法是根本用不到的。这就是接口污染。
客户端不应该依赖它不需要的接口,即一个类对另一个类的依赖应该建立在最小的接口上
先看一张图:
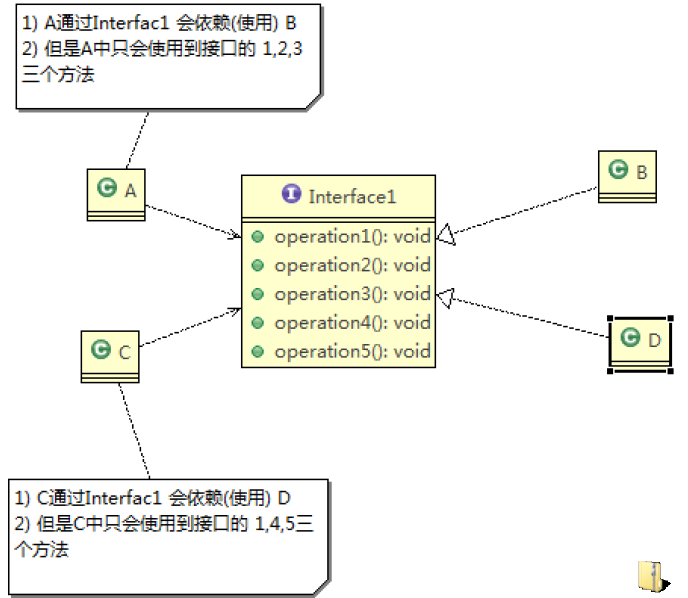
类 A 通过接口 Interface1 依赖类 B,类 C 通过接口 Interface1 依赖类 D,如果接口 Interface1 对于类 A 和类 C来说不是最小接口,那么类 B 和类 D 必须去实现他们不需要的方法。
按隔离原则应当这样处理:
将接口 Interface1 拆分为独立的几个接口**(这里我们拆分成 **3 个接口**)**,类 A 和类 C 分别与他们需要的接口建立依赖关系。也就是采用接口隔离原则
2.4.2、应用实例
1 | public class Segregation1 { |
2.4.3、应传统方法的问题和使用接口隔离原则改进
类 A 通过接口 Interface1 依赖类 B,类 C 通过接口 Interface1 依赖类 D,如果接口 Interface1 对于类 A 和类 C来说不是最小接口,那么类 B 和类 D 必须去实现他们不需要的方法
将接口 Interface1 拆分为独立的几个接口,类 A 和类 C 分别与他们需要的接口建立依赖关系。也就是采用接口隔离原则
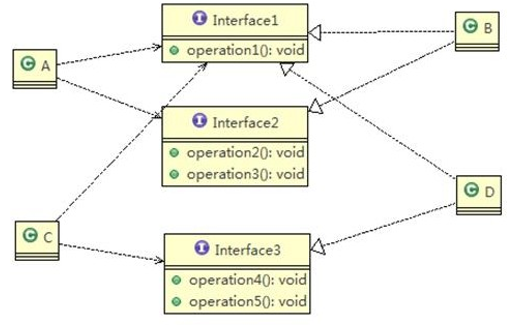
接口 Interface1 中出现的方法,根据实际情况拆分为三个接口:
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80public class Segregation1 {
public static void main(String[] args) {
// TODO Auto-generated method stub
// 使用一把
A a = new A();
a.depend1(new B()); // A 类通过接口去依赖 B 类
a.depend2(new B());
a.depend3(new B());
C c = new C();
c.depend1(new D()); // C 类通过接口去依赖(使用)D 类
c.depend4(new D());
c.depend5(new D());
}
}
// 接 口 1
interface Interface1 {
void operation1();
}
// 接 口 2
interface Interface2 {
void operation2();
void operation3();
}
// 接 口 3
interface Interface3 {
void operation4();
void operation5();
}
class B implements Interface1, Interface2 {
public void operation1() {
System.out.println("B 实现了 operation1");
}
public void operation2() {
System.out.println("B 实现了 operation2");
}
public void operation3() {
System.out.println("B 实现了 operation3");
}
}
class D implements Interface1, Interface3 {
public void operation1() {
System.out.println("D 实现了 operation1");
}
public void operation4() {
System.out.println("D 实现了 operation4");
}
public void operation5() {
System.out.println("D 实现了 operation5");
}
}
class A { // A 类通过接口 Interface1,Interface2 依赖(使用) B 类,但是只会用到 1,2,3 方法
public void depend1(Interface1 i) {
i.operation1();
}
public void depend2(Interface2 i) {
i.operation2();
}
public void depend3(Interface2 i) {
i.operation3();
}
}
class C { // C 类通过接口 Interface1,Interface3 依赖(使用) D 类,但是只会用到 1,4,5 方法
public void depend1(Interface1 i) {
i.operation1();
}
public void depend4(Interface3 i) {
i.operation4();
}
public void depend5(Interface3 i) {
i.operation5();
}
}
2.4.4、接口隔离原则注意事项和细节
- 接口隔离原则的思想在于建立单一接口,尽可能地去细化接口,接口中的方法尽可能少
- 但是凡事都要有个度,如果接口设计过小,则会造成接口数量过多,使设计复杂化。所以一定要适度。
2.5 、依赖倒转原则(Dependence Inversion Principle)
2.5.1、基本介绍
依赖倒转原则(Dependence Inversion Principle)是指:
- 高层模块不应该依赖低层模块,二者都应该依赖其抽象
- 抽象不应该依赖细节,细节应该依赖抽象
- 依赖倒转(倒置)的中心思想是面向接口编程,面向抽象编程,解耦调用和被调用者
- 依赖倒转原则是基于这样的设计理念:相对于细节的多变性,抽象的东西要稳定的多。以抽象为基础搭建的架构比以细节为基础的架构要稳定的多。在 java 中,抽象指的是接口或抽象类,细节就是具体的实现类
- 当两个模块之间存在紧密的耦合关系时,最好的方法就是分离接口和实现:在依赖之间定义一个抽象的接口使得高层模块调用接口,而底层模块实现接口的定义,以此来有效控制耦合关系,达到依赖于抽象的设计目标。
- 使用接口或抽象类的目的是制定好规范,而不涉及任何具体的操作,把展现细节的任务交给他们的实现类去完成
2.5.2、应用实例
请编程完成 Person 接收消息 的功能。
实现方案 1 + 分析说明:
1 | public class DependecyInversion { |
实现方案 2(依赖倒转) + 分析说明(同时也满足了开闭原则ocp)
1 | public class DependecyInversion { |
2.5.3、 依赖关系传递的三种方式和应用案例
2.5.3.1、接口传递
实现:
1 | public class DependencyPass { |
2.5.3.2、构造方法传递
实现:
1 | public class DependencyPass { |
2.5.3.3、setter 方式传递
实现:
1 | public class DependencyPass { |
2.5.4、依赖倒转原则的注意事项和细节
- 低层模块尽量都要有抽象类或接口,或者两者都有,程序稳定性更好.
- 变量的声明类型尽量是抽象类或接口, 这样我们的变量引用和实际对象间,就存在一个缓冲层,利于程序扩展和优化
- 继承时遵循里氏替换原则.
2.6、里氏替换原则(Liskov Substitution Principle)
2.6.1、OO 中的继承性的思考和说明
- 继承包含这样一层含义:父类中凡是已经实现好的方法,实际上是在设定规范和契约,虽然它不强制要求所有的子类必须遵循这些契约,但是如果子类对这些已经实现的方法任意修改,就会对整个继承体系造成破坏。
- 继承在给程序设计带来便利的同时,也带来了弊端。比如使用继承会给程序带来侵入性,程序的可移植性降低, 增加对象间的耦合性,如果一个类被其他的类所继承,则当这个类需要修改时,必须考虑到所有的子类,并且父类修改后,所有涉及到子类的功能都有可能产生故障
- 里氏替换原则的重点在不影响原功能,而不是不覆盖原方法。
- 问题提出:在编程中,如何正确的使用继承? => 里氏替换原则
2.6.2、 基本介绍
- 里氏替换原则(Liskov Substitution Principle)在 1988 年,由麻省理工学院的以为姓里的女士提出的。
- 里氏替换原则的含义是:子类可以在任何地方替换它的父类。
- 也就是说在程序中将基类替换为子类,程序的行为不会发生任何变化。
- Liskov替换原则是关于继承机制的设计原则,违反了Liskov替换原则就必然导致违反开放封闭原则
- 如果对每个类型为 T1 的对象 o1,都有类型为 T2 的对象 o2,使得以 T1 定义的所有程序 P 在所有的对象 o1 都代换成 o2 时,程序 P 的行为没有发生变化,那么类型 T2 是类型 T1 的子类型。换句话说,所有引用基类的地方必须能透明地使用其子类的对象。
- 在使用继承时,遵循里氏替换原则,在**
子类中尽量不要重写父类的方法**。 - 里氏替换原则告诉我们,继承实际上让两个类耦合性增强了,在适当的情况下,可以通过**
聚合,组合,依赖**来解决问题。
里氏原则的优点:
- 能够保证系统具有良好的拓展性
- 同时实现基于多态的抽象机制
- 能够减少代码冗余
- 避免运行期的类型判别
2.6.3、 一个程序引出的问题和思考

程序员原本是想调用b中继承的a的func1的方法求出11-3,但b无意重写了a的func1方法,使相减变成了相加。
2.6.4、解决方法
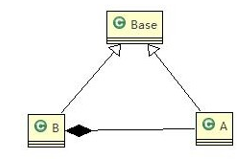
我们发现原来运行正常的相减功能发生了错误。原因就是类 B 无意中重写了父类的方法,造成原有功能出现错误。在实际编程中,我们常常会通过重写父类的方法完成新的功能,这样写起来虽然简单,但整个继承体系的复用性会比较差。特别是运行多态比较频繁的时候
通用的做法是:原来的父类和子类都继承一个更通俗的基类,原有的继承关系去掉,采用依赖,聚合,组合等关系代替.
即:子类可以扩展父类的功能,但不能改变父类原有的功能。
改进方案:
代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49public class Liskov {
public static void main(String[] args) {
A a = new A();
System.out.println("11-3=" + a.func1(11, 3));
System.out.println("1-8=" + a.func1(1, 8));
System.out.println("-----------------------");
B b = new B();
//因为B类不再继承A类,因此调用者,不会再认为func1是求减法
//调用完成的功能就会很明确
System.out.println("11+3=" + b.func1(11, 3));//这里本意是求出11+3
System.out.println("1+8=" + b.func1(1, 8));// 1+8
System.out.println("11+3+9=" + b.func2(11, 3));
//使用组合仍然可以使用到A类相关方法
System.out.println("11-3=" + b.func3(11, 3));// 这里本意是求出11-3
}
}
//创建一个更加基础的基类
class Base {
//把更加基础的方法和成员写到Base类
public int func1(int num1, int num2) {}
}
// A类继承了Base
class A extends Base {
// 重写func1返回两个数的差
public int func1(int num1, int num2) {
return num1 - num2;
}
}
// B类继承了Base
// 增加了一个新功能:完成两个数相加,然后和9求和
class B extends Base {
//如果B需要使用A类的方法,使用组合关系
private A a = new A();
//这里,重写了Base类的方法,
public int func1(int a, int b) {
return a + b;
}
public int func2(int a, int b) {
return func1(a, b) + 9;
}
//我们仍然想使用A的方法
public int func3(int a, int b) {
return this.a.func1(a, b);
}
}
2.7、开闭原则(Open Closed Principle)
2.7.1、基本介绍
- 开闭原则(Open Closed Principle)是编程中最基础、最重要的设计原则
- 一个软件实体如类,模块和函数应该对扩展开放(对提供方)**,对修改关闭(对使用方)。用抽象构建框架,用实现扩展细节**。
- 采用逆向思维方式来想。如果每次需求变动都去修改原有的代码,那原有的代码就存在被修改错误的风险,当然这其中存在有意和无意的修改,都会导致原有正常运行的功能失效的风险,这样很有可能会展开可怕的蝴蝶效应,使维护工作剧增。
- 所以当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。
- 编程中遵循其它原则,以及使用设计模式的目的就是遵循开闭原则。
2.7.2、看下面一段代码
实现画图形的功能
类图:
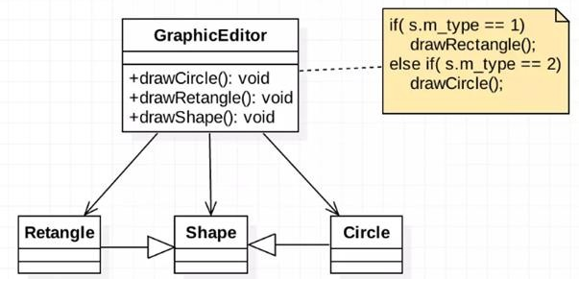
代码:

但我们增加一个功能:画三角形
方式1:
1 | public class Ocp { |
2.7.3、方式 1 的优缺点
优点是比较好理解,简单易操作。
缺点是违反了设计模式的 ocp 原则,即**对扩展开放(提供方),对修改关闭(使用方)**。即当我们给类增加新功能的时候,尽量不修改代码,或者尽可能少修改代码.
比如我们这时要新增加一个图形种类三角形,我们需要做如下修改,修改的地方较多(使用方要修改两次)
代码演示(方式2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48public class Ocp {
public static void main(String[] args) {
GraphicEditor graphicEditor = new GraphicEditor();
graphicEditor.drawShape(new Rectangle());
graphicEditor.drawShape(new Circle());
//使用方直接使用
graphicEditor.drawShape(new Triangle());
}
}
//这是一个用于绘图的类 [使用方]
class GraphicEditor {
//接收Shape对象,调用draw方法
public void drawShape(Shape s) {
s.draw();
}
}
//Shape类,基类(使用抽象类)
abstract class Shape {
//抽象方法
public abstract void draw();
}
// 继承抽象类Shape
class Rectangle extends Shape {
public void draw() {
// TODO Auto-generated method stub
System.out.println(" 绘制矩形 ");
}
}
// 继承抽象类Shape
class Circle extends Shape {
public void draw() {
// TODO Auto-generated method stub
System.out.println(" 绘制圆形 ");
}
}
//新增功能:画三角形
// 继承抽象类Shape
class Triangle extends Shape {
public void draw() {
// TODO Auto-generated method stub
System.out.println(" 绘制三角形 ");
}
}
2.7.4、改进的思路分析
把创建 Shape 类做成抽象类,并提供一个抽象的 draw 方法,让子类去实现即可,这样我们有新的图形种类时,只需要让新的图形类继承 Shape,并实现 draw 方法即可,使用方的代码就不需要修改-> 满足了开闭原则
2.7.5、开闭原则注意事项和细节
- OCP 可以具有良好的可扩展性,可维护性。
- 不可能让一个系统的所有模块都满足 OCP 原则,我们能做到的是尽可能地不要修改已经写好的代码,已有的功能,而是去扩展它。
2.8、迪米特法则(Demeter Principle)
2.8.1、基本介绍
- 迪米特原则要求尽量的封装,尽量的独立,尽量的使用低级别的访问修饰符。就是说一个对象应当对其他对象有尽可能少的了解,不和陌生人说话。
- 一个对象应该对其他对象保持最少的了解
- 类与类关系越密切,耦合度越大
- 迪米特法则(Demeter Principle)又叫最少知道原则,即一个类对自己依赖的类知道的越少越好。也就是说,对于被依赖的类不管多么复杂,都尽量将逻辑封装在类的内部。对外除了提供的 public 方法,不对外泄露任何信息
- 迪米特法则还有个更简单的定义:只与直接的朋友通信
- 直接的朋友:每个对象都会与其他对象有耦合关系,只要两个对象之间有耦合关系,我们就说这两个对象之间是朋友关系。耦合的方式很多,依赖,关联,组合,聚合等。其中,我们称出现成员变量,方法参数,方法返回值中的类为直接的朋友,而出现在局部变量中的类不是直接的朋友。也就是说,陌生的类最好不要以局部变量的形式出现在类的内部。最好将其封装到直接朋友里面。
- 迪米特原则要求类之间的直接联系尽量的少,两个类的访问,通过第三个中介类来实现。
2.8.2、应用实例
有一个学校,下属有各个学院和总部,现要求打印出学校总部员工 ID 和学院员工的 id。编程实现上面的功能, 看代码演示
1 | //客户端 |
2.8.3、应用实例改进
前面设计的问题在于 SchoolManager 中,CollegeEmployee 类并不是 SchoolManager 类的直接朋友 (分析)
按照迪米特法则,应该避免类中出现这样非直接朋友关系的耦合
对代码按照迪米特法则 进行改进:
代码演示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78//客户端
public class Demeter1 {
public static void main(String[] args) {
//创建了一个 SchoolManager 对象
SchoolManager schoolManager = new SchoolManager();
//输出学院的员工id 和 学校总部的员工信息
schoolManager.printAllEmployee(new CollegeManager());
}
}
//学校总部员工类
class Employee {
private String id;
public void setId(String id) {
this.id = id;
}
public String getId() {
return id;
}
}
//学院的员工类
class CollegeEmployee {
private String id;
public void setId(String id) {
this.id = id;
}
public String getId() {
return id;
}
}
//管理学院员工的管理类
class CollegeManager {
//添加学院的员工
public List<CollegeEmployee> getAllEmployee() {
List<CollegeEmployee> list = new ArrayList<CollegeEmployee>();
//这里我们增加了10个员工到 list
for (int i = 0; i < 10; i++) {
CollegeEmployee emp = new CollegeEmployee();
emp.setId("学院员工id= " + i);
list.add(emp);
}
return list;
}
//输出学院员工的信息
public void printEmployee() {
//获取到学院员工
List<CollegeEmployee> list1 = getAllEmployee();
System.out.println("------------学院员工------------");
for (CollegeEmployee e : list1) {
System.out.println(e.getId());
}
}
}
//学校管理类
class SchoolManager {
//返回学校总部的员工
public List<Employee> getAllEmployee() {
List<Employee> list = new ArrayList<Employee>();
//这里我们增加了5个员工到 list
for (int i = 0; i < 5; i++) {
Employee emp = new Employee();
emp.setId("学校总部员工id= " + i);
list.add(emp);
}
return list;
}
//该方法完成输出学校总部和学院员工信息(id)
void printAllEmployee(CollegeManager sub) {
//分析问题
//1. 将输出学院的员工方法,封装到CollegeManager
sub.printEmployee();
//获取到学校总部员工
List<Employee> list2 = this.getAllEmployee();
System.out.println("------------学校总部员工------------");
for (Employee e : list2) {
System.out.println(e.getId());
}
}
}
2.8.4、迪米特法则注意事项和细节
迪米特法则的核心是降低类之间的耦合
但是注意:由于每个类都减少了不必要的依赖,因此迪米特法则只是要求降低类间(对象间)耦合关系, 并不是要求完全没有依赖关系
2.9、合成复用原则(Composite Reuse Principle)
2.9.1、基本介绍
原则是尽量使用合成/聚合的方式,而不是使用继承
聚合组合是一种 “黑箱” 复用,因为细节对象的内容对客户端来说是不可见的。
因为继承的耦合性更大,组合聚合只是引用其他的类的方法,而不会受引用的类的继承而改变血统。说白了就是我只用你的方法,但我们并不是同类。
在面向对象的设计中,如果直接继承基类,会破坏封装,因为继承将基类的实现细节暴露给子类;如果基类的实现发生了改变,则子类的实现也不得不改变;从基类继承而来的实现是静态的,不可能在运行时发生改变,没有足够的灵活性。于是就提出了组合/聚合复用原则,也就是在实际开发设计中,尽量使用组合/聚合,不要使用类继承。
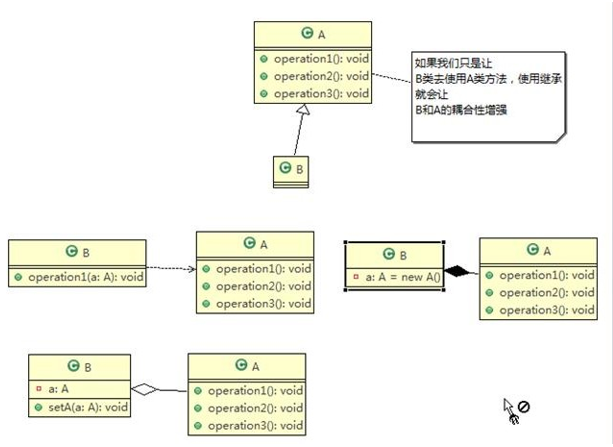
2.10、设计原则核心思想
- 找出应用中可能需要变化之处,把它们独立出来,不要和那些不需要变化的代码混在一起。
- 针对接口编程,而不是针对实现编程。
- 为了交互对象之间的松耦合设计而努力
2.11、设计七大原则总结
这 7 种设计原则是软件设计模式必须尽量遵循的原则,是设计模式的基础。在实际开发过程中,并不是一定要求所有代码都遵循设计原则,而是要综合考虑人力、时间、成本、质量,不刻意追求完美,要在适当的场景遵循设计原则。这体现的是一种平衡取舍,可以帮助我们设计出更加优雅的代码结构。
各种原则要求的侧重点不同,下面我们分别用一句话归纳总结软件设计模式的七大原则,如下表所示。
| 设计原则 | 一句话归纳 | 目的 |
|---|---|---|
| 开闭原则 | 对扩展开放,对修改关闭 | 降低维护带来的新风险 |
| 依赖倒置原则 | 高层不应该依赖低层,要面向接口编程 | 更利于代码结构的升级扩展 |
| 单一职责原则 | 一个类只干一件事,实现类要单一 | 便于理解,提高代码的可读性 |
| 接口隔离原则 | 一个接口只干一件事,接口要精简单一 | 功能解耦,高聚合、低耦合 |
| 迪米特法则 | 不该知道的不要知道,一个类应该保持对其它对象最少的了解,降低耦合度 | 只和朋友交流,不和陌生人说话,减少代码臃肿 |
| 里氏替换原则 | 不要破坏继承体系,子类重写方法功能发生改变,不应该影响父类方法的含义 | 防止继承泛滥 |
| 合成复用原则 | 尽量使用组合或者聚合关系实现代码复用,少使用继承 | 降低代码耦合 |
实际上,这些原则的目的只有一个:降低对象之间的耦合,增加程序的可复用性、可扩展性和可维护性。
记忆口诀:访问加限制,函数要节俭,依赖不允许,动态加接口,父类要抽象,扩展不更改。
在程序设计时,我们应该将程序功能最小化,每个类只干一件事。若有类似功能基础之上添加新功能,则要合理使用继承。对于多方法的调用,要会运用接口,同时合理设置接口功能与数量。最后类与类之间做到低耦合高内聚。
3、UML 类图
3.1、UML 基本介绍
UML——Unified modeling language UML (统一建模语言),是一种用于软件系统分析和设计的语言工具,它用于帮助软件开发人员进行思考和记录思路的结果
UML 本身是一套符号的规定,就像数学符号和化学符号一样,这些符号用于描述软件模型中的各个元素和他们之间的关系,比如类、接口、实现、泛化、依赖、组合、聚合等,如右图:
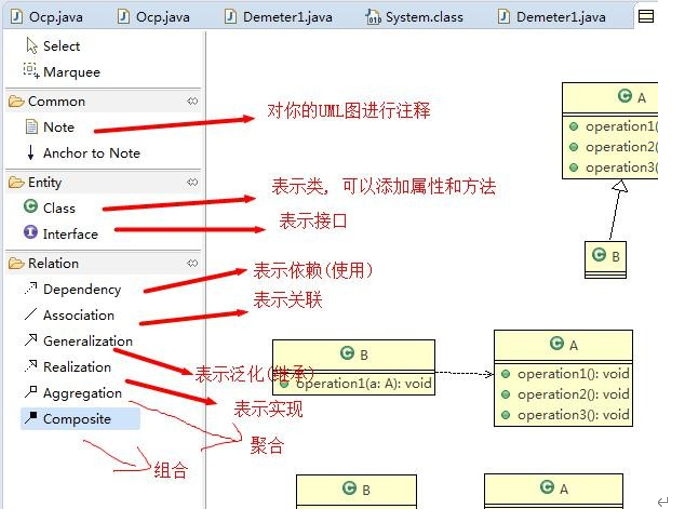
使用 UML 来建模,常用的工具有 Rational Rose , 也可以使用一些插件来建模
3.2、UML 图
画 UML 图与写文章差不多,都是把自己的思想描述给别人看,关键在于思路和条理,UML 图分类:
- 用例图(use case)
- 静态结构图:类图、对象图、包图、组件图、部署图
- 动态行为图:交互图(时序图与协作图)、状态图、活动图
说明:
- 类图是描述类与类之间的关系的,是 UML 图中最核心的
- 在讲解设计模式时,我们必然会使用类图,为了让学员们能够把设计模式学到位,需要先给大家讲解类图
3.3、UML 类图
用于描述系统中的类**(对象)本身的组成和类(对象)**之间的各种静态关系。
类之间的关系:依赖、泛化(继承)、实现、关联、聚合与组合。
类图简单举例代码:
1
2
3
4
5
6
7
8
9public class Person{ //代码形式->类图
private Integer id; private String name;
public void setName(String name){
this.name=name;
}
public String getName(){
return name;
}
}类图

3.4、类图—依赖关系(Dependence)
只要是在类中用到了对方,那么他们之间就存在依赖关系。如果没有对方,连编绎都通过不了。
对应类图:
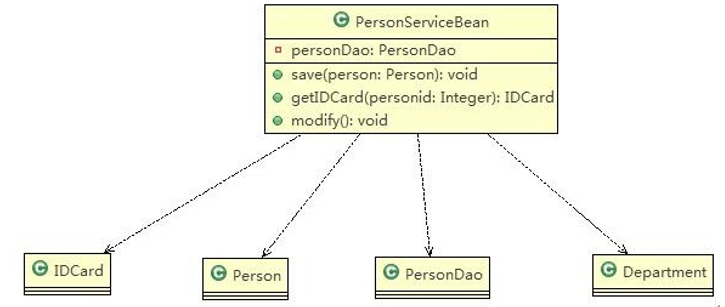
依赖关系小结:
- 类中用到了对方
- 如果是类的成员属性
- 如果是方法的返回类型
- 是方法接收的参数类型
- 方法中使用到
3.5、类图—泛化关系(generalization)
泛化关系实际上就是继承关系,他是依赖关系的特例
相关类图:
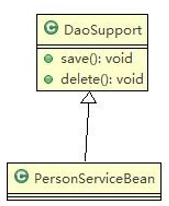
泛化关系小结:
- 泛化关系实际上就是继承关系
- 如果 A 类继承了 B 类,我们就说 A 和 B 存在泛化关系
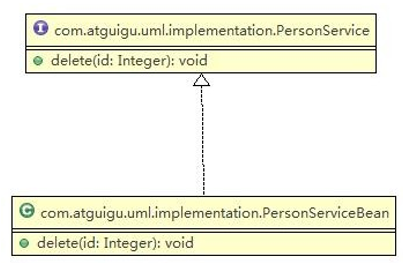
3.6、类图—实现关系(Implementation)
实现关系实际上就是 A 类实现 B 接口,他是依赖关系的特例
相关类图:
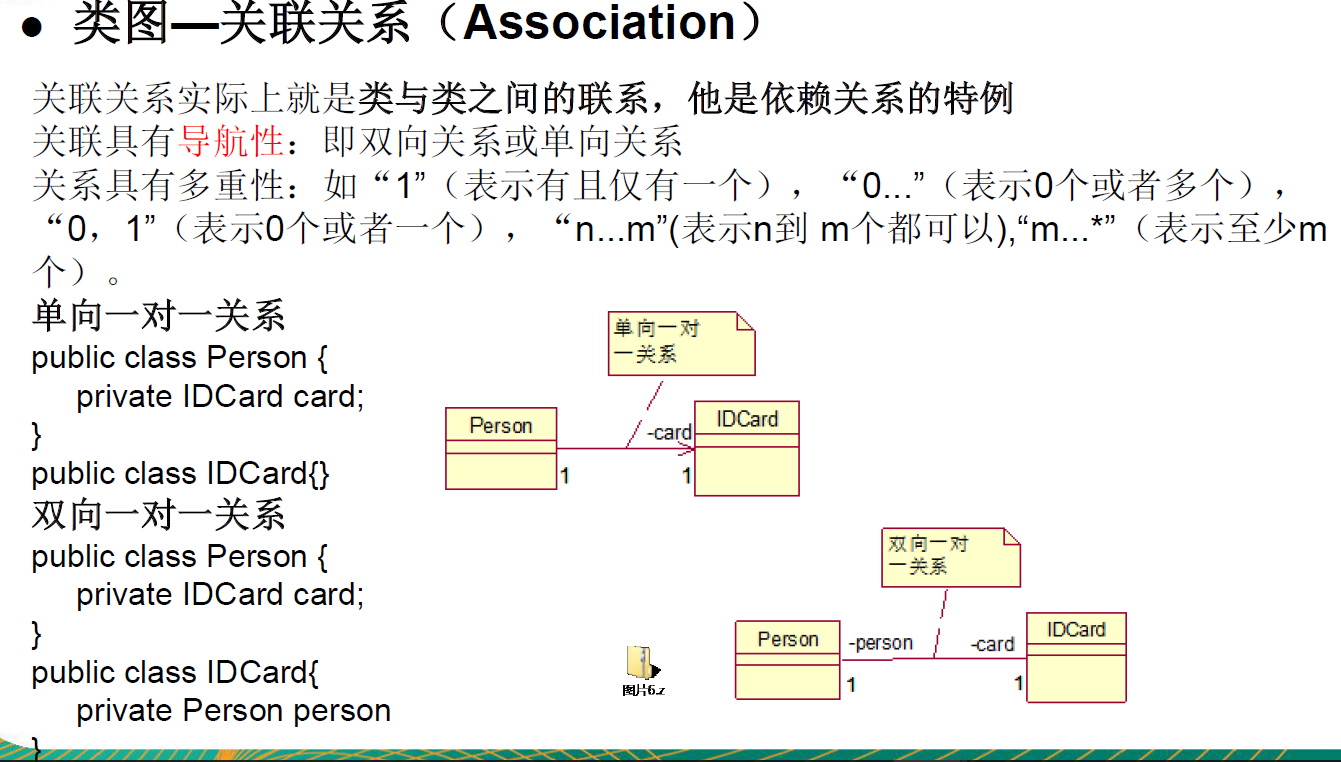
3.7、类图—关联关系(Association)
3.8、类图—聚合关系(Aggregation)
3.8.1、基本介绍
聚合关系(Aggregation)表示的是整体和部分的关系,整体与部分可以分开。聚合关系是关联关系的特例,所以他具有关联的导航性与多重性。
如:一台电脑由键盘(keyboard)、显示器(monitor),鼠标等组成;组成电脑的各个配件是可以从电脑上分离出来的,使用带空心菱形的实线来表示:

3.9、类图—组合关系(Composition)
3.9.1、基本介绍
组合关系:也是整体与部分的关系,但是整体与部分不可以分开。
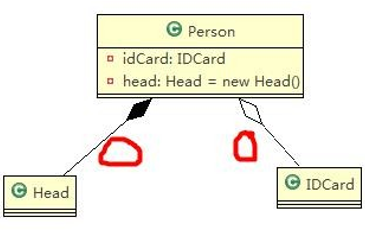
再看一个案例:在程序中我们定义实体:Person 与 IDCard、Head, 那么 Head 和 Person 就是 组合,IDCard 和Person 就是聚合。
但是如果在程序中 Person 实体中定义了对 IDCard 进行级联删除,即删除 Person 时连同 IDCard 一起删除,那么 IDCard 和 Person 就是组合了.
代码:
1 | public class Person{ |
对应类图:
4、设计模式概述
4.1、设计模式介绍
- 设计模式是程序员在面对同类软件工程设计问题所总结出来的有用的经验,模式不是代码,而是某类问题的通用解决方案,设计模式(Design pattern)代表了最佳的实践。这些解决方案是众多软件开发人员经过相当长的一段时间的试验和错误总结出来的。
- 设计模式的本质提高软件的维护性,通用性和扩展性,并降低软件的复杂度。
- <<设计模式>> 是经典的书,作者是 Erich Gamma、Richard Helm、Ralph Johnson 和 John Vlissides Design(俗称 “四人组 GOF”)
- 设计模式并不局限于某种语言,java,php,c++ 都有设计模式.
4.2、设计模式类型
设计模式分为三种类型,共 23 种
- 创建型模式:单例模式、抽象工厂模式、原型模式、建造者模式、工厂模式。
- 结构型模式:适配器模式、桥接模式、装饰模式、组合模式、外观模式、享元模式、代理模式。
- 行为型模式:模版方法模式、命令模式、访问者模式、迭代器模式、观察者模式、中介者模式、备忘录模式、解释器模式(Interpreter 模式)、状态模式、策略模式、职责链模式(责任链模式)。
注意:不同的书籍上对分类和名称略有差别
对于创建型模式的概述请看第27点
对于结构型模式的概述请看第28点
对于行为型模式的概述请看第29点
5、单例设计模式Singleton(创建型设计模式)

5.1、单例设计模式介绍
所谓类的单例设计模式,就是采取一定的方法保证在整个的软件系统中,对某个类只能存在一个对象实例, 并且该类**只提供一个取得其对象实例的方法(静态方法)**。
比如 Hibernate 的 SessionFactory,它充当数据存储源的代理,并负责创建 Session 对象。SessionFactory 并不是轻量级的,一般情况下,一个项目通常只需要一个 SessionFactory 就够,这是就会使用到单例模式。
注意:
- 单例类只有一个实例对象;
- 该单例对象必须由单例类自行创建;
- 单例类对外提供一个访问该单例的全局访问点。
测试方法(除了枚举):
1 | public class Singleton { |
5.2、单例设计模式八种方式
加黑属于推荐使用
- 饿汉式(两种)
- 饿汉式**(静态常量)**
- 饿汉式(静态代码块)
- 懒汉式(三种)
- 懒汉式(线程不安全)
- 懒汉式(线程安全,同步方法)
- 懒汉式(同步代码块)
- 双重检查
- 静态内部类
- 枚举
5.3、饿汉式(两种)
5.3.1、饿汉式(静态常量)
使用步骤:
- 构造器私有化 (防止外部使用new创建实例)
- 类的内部创建对象
- 向外暴露一个静态的公共方法getInstance
代码实现:
1 | // 饿汉式(静态常量) |
优缺点说明:
- 优点:这种写法比较简单,就是在类装载的时候就完成实例化。避免了线程同步问题。
- 缺点:在类装载的时候就完成实例化,没有达到 Lazy Loading 的效果。如果从始至终从未使用过这个实例,则会造成内存的浪费
- 这种方式基于
classloder机制避免了多线程的同步问题,不过,instance 在类装载时就实例化,在单例模式中大多数都是调用 getInstance 方法, 但是导致类装载的原因有很多种,因此不能确定有其他的方式(或者其他的静态方法)导致类装载,这时候初始化 instance 就没有达到lazy loading的效果 - 结论:这种单例模式可用,可能造成内存浪费,同时也不能实现懒加载(lazy loading)
5.3.2、饿汉式(静态代码块)
使用步骤:
- 构造器私有化 (防止外部使用new创建实例)
- 在静态代码块中,创建单例对象
- 向外暴露一个静态的公共方法getInstance
代码:
1 | // 饿汉式(静态代码块) |
优缺点说明:
- 这种方式和上面的方式其实类似,只不过将类实例化的过程放在了静态代码块中,也是在类装载的时候,就执行静态代码块中的代码,初始化类的实例。优缺点和上面是一样的。
- 结论:这种单例模式可用,但是可能造成内存浪费
5.4、懒汉式(三种)
5.4.1、懒汉式(线程不安全)
使用步骤:
- 构造器私有化 (防止外部使用new创建实例)
- 提供一个静态的公有方法getInstance(),当使用到该方法时,才去创建 instance
代码:
1 | // 懒汉式(线程不安全) |
优缺点说明:
- 起到了 Lazy Loading 的效果,但是只能在单线程下使用。
- 如果在多线程下,一个线程进入了 if (singleton == null)判断语句块,还未来得及往下执行,另一个线程也通过了这个判断语句,这时便会产生多个实例。所以在多线程环境下不可使用这种方式。(线程不安全)
- 结论:在实际开发中,不要使用这种方式.
5.4.2、懒汉式(线程安全,同步方法)
使用步骤:
- 构造器私有化 (防止外部使用new创建实例)
- 提供一个静态的公有方法getInstance(),加入同步处理的代码synchronized ,解决线程安全问题
代码:
1 | // 懒汉式(线程安全,同步方法) |
优缺点说明:
- 解决了线程安全问题
- 效率太低了,每个线程在想获得类的实例时候,执行getInstance()方法都要进行同步。而其实这个方法只执行一次实例化代码就够了,后面的想获得该类实例,直接 return 就行了。方法进行同步效率太低。
- 结论:在实际开发中,不推荐使用这种方式
5.4.3、懒汉式(同步代码块)
- 构造器私有化 (防止外部使用new创建实例)
- 提供一个静态的公有方法getInstance(),加入同步产生实例化的的代码块,解决效率问题。
代码:

优缺点说明:
- 这种方式,本意是想对第四种实现方式的改进,因为前面同步方法效率太低,改为同步产生实例化的的代码块。
- 但是这种同步并不能起到线程同步的作用。跟第3种实现方式遇到的情形一致,假如一个线程进入了if (singleton == null)判断语句块,还未来得及往下执行,另一个线程也通过了这个判断语句,这时便会产生多个实例。(线程不安全)
- 结论:在实际开发中,**
不能使用**这种方式
5.5、双重检查
使用步骤:
- 构造器私有化 (防止外部使用new创建实例)
- 提供一个静态的公有方法,加入**双重检查代码(双if)**,解决线程安全问题, 同时解决懒加载问题
代码:
1 | // 双重检查 |
优缺点说明:
- Double-Check 概念是多线程开发中常使用到的,如代码中所示,我们进行了两次 if (singleton == null)检查,这样就可以保证线程安全了。
- 是对懒汉式(线程安全,同步方法)的优化
- 这样,实例化代码只用执行一次,后面再次访问时,判断 if (singleton == null),直接 return 实例化对象,也避免的反复进行方法同步。
- 线程安全;延迟加载;效率较高
- 结论:在实际开发中,推荐使用这种单例设计模式
其他说明:
- 双重检锁虽然是线程安全的,会出现内部成员变量空指针异常,如果要使用,需将类实例用volatile修饰
- volatile 是改变立即更新到主存,保证变化各线程可见,即:立即从主内存中获取值,更新工作内存的值。在多线程情况下,不仅防止指令重排,而且保证happes-before规则,前一个线程的操作对后一个线程可见。(happens-before规则相关)
- 如果不用volatile关键字,有可能会出现异常。因为instance = new Singleton();并不是一个原子操作。new对象分为三步:
- 第一步:分配对象的内存空间
- 第二步:初始化对象
- 第三步:设置instance指向内存空间
- 但是这个被返回的instance是有问题的——它还没有被初始化(第二步还未被执行)。
- 这里必须要volatile,volatile就是保证一个线程更新了instance,其余线程立马可知,不然第二个if没有用。(可见性)
- volitile保证了线程间的可见性,和一定程度上的顺序性(不能保证原子性),更好的方式是用一个boolean变量标识对象是否创建过(原子性)
双重检查创建单例实现步骤
- 第一个if(singleton==null){}:第一层检查,检查是否有引用指向对象,高并发情况下会有多个线程同时进
- synchronized (Singleton.class) {}:第一层锁,保证只有一个线程进入
- 第二个if(singleton==null){}:第二层检查
- 双重检查,防止多个线程同时进入第一层检查(因单例模式只允许存在一个对象,故在创建对象之前无引用指向对象,所有线程均可进入第一层检查)
- 当某一线程获得锁创建一个Singleton对象时,即已有引用指向对象,singleton不为空,从而保证只会创建一个对象
- 假设没有第二层检查,那么第一个线程创建完对象释放锁后,后面进入对象也会创建对象,会产生多个对象。(5.4.3的情况)
- instance = new Singleton():volatile关键字作用为禁止指令重排,保证返回Singleton对象一定在创建对象后
- 该语句为非原子性,实际上会执行以下内容:
- 在堆上开辟空间
- 属性初始化
- 引用指向对象
- 假设以上三个内容为三条单独指令,因指令重排可能会导致执行顺序为1->3->2(正常为1->2->3),当单例模式中存在普通变量需要在构造方法中进行初始化操作时,单线程情况下,顺序重排没有影响;但在多线程情况下,假如线程1执行singleton=new Singleton()语句时先1再3,由于系统调度线程2的原因没来得及执行步骤2,但此时已有引用指向对象也就是singleton!=null,故线程2在第一次检查时不满足条件直接返回singleton,此时singleton为一个没有被步骤2正确初始化的singleton。
- volatile关键字可保证singleton=new Singleton()语句执行顺序为123,因其为非原子性依旧可能存在系统调度问题(即执行步骤时被打断),但能确保的是只要singleton!=null,就表明一定执行了属性初始化操作;而若在步骤3之前被打断,此时singleton依旧为null,其他线程可进入第一层检查向下执行创建对象。
- 该语句为非原子性,实际上会执行以下内容:
5.6、静态内部类
使用步骤:
- 构造器私有化 (防止外部使用new创建实例)
- 写一个静态内部类,该类中有一个静态属性 Singleton
- 提供一个静态的公有方法,直接返回SingletonInstance.INSTANCE
代码:
1 | // 静态内部类完成, 推荐使用 |
优缺点说明:
- 这种方式采用了类装载的机制来保证初始化实例时只有一个线程。
- 静态内部类方式在 Singleton 类被装载时并不会立即实例化,而是在需要实例化时,调用 getInstance 方法,才会装载 SingletonInstance 类,从而完成 Singleton 的实例化。
- 类的静态属性只会在第一次加载类的时候初始化,所以在这里,JVM 帮助我们保证了线程的安全性,在类进行初始化时,别的线程是无法进入的。
- 优点:避免了线程不安全,利用静态内部类特点实现延迟加载,效率高
- 缺点:不能传参
- 结论:在实际开发中,推荐使用这种单例设计模式
其他说明:
- 静态内部类:这里的关键是类在加载的时候是线程安全的,一个类只会被加载一次
- JVM初始化时机:
- 首次,主动使用才会初始化。即只有第一次加载类的时候初始化。
- 之后调用getInstance()方法,直接返回对象,不会再次初始化了
- 这种方式只适用于静态域的情况,双检锁方式可在实例域需要延迟初始化时使用。
5.7、枚举
使用步骤:
- 直接使用枚举实现单例
- 在枚举里面有INSTANCE属性
- 外部直接通过Singleton.INSTANCE的方式创建实例
代码:
1 | public class SingletonTest { |
优缺点说明:
- 这借助 JDK1.5 中添加的枚举来实现单例模式。不仅能避免多线程同步问题,而且还能防止反序列化重新创建新的对象。
- JVM 会阻止反射获取枚举类的私有构造方法
- 枚举真正实现了单例,把反序列化和反射创建第二对象的路都堵死了
- 这种方式是 Effective Java 作者 Josh Bloch 提倡的方式
- 缺点:无法进行懒加载。如果Singleton必须拓展一个超类,而不是扩展Enum的时候,则不宜使用这个方法。
- 结论:在实际开发中,推荐使用这种单例设计模式
5.8、单例模式在 JDK 应用的源码分析
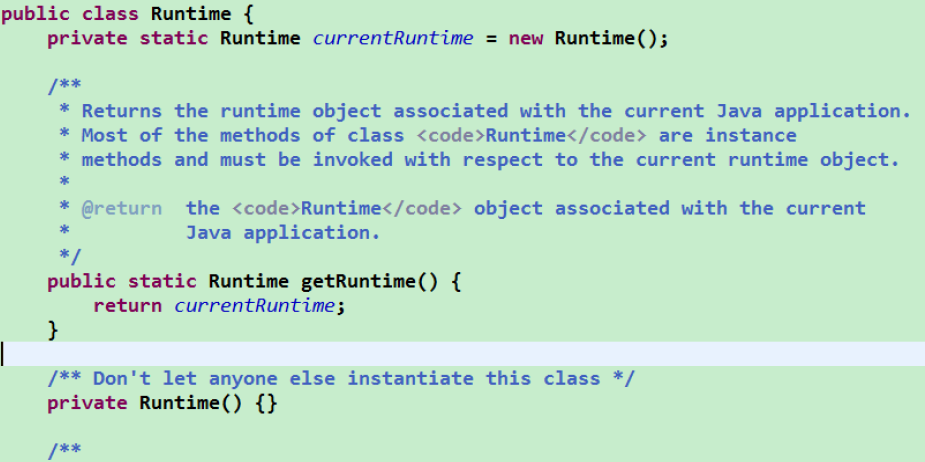
我们 JDK 中,java.lang.Runtime 就是经典的单例模式(饿汉式)
原码:
5.9、单例模式总结
5.9.1、单例模式的优缺点
优点:
- 单例模式可以保证内存里只有一个实例,减少了内存的开销。
- 可以避免对资源的多重占用。
- 单例模式设置全局访问点,可以优化和共享资源的访问。
缺点:
- 单例模式一般没有接口,扩展困难。如果要扩展,则除了修改原来的代码,没有第二种途径,违背开闭原则。
- 在并发测试中,单例模式不利于代码调试。在调试过程中,如果单例中的代码没有执行完,也不能模拟生成一个新的对象。
- 单例模式的功能代码通常写在一个类中,如果功能设计不合理,则很容易违背单一职责原则。
5.9.2、单例模式的应用场景
对于 Java 来说,单例模式可以保证在一个 JVM 中只存在单一实例。单例模式的应用场景主要有以下几个方面。
- 需要频繁创建的一些类,使用单例可以降低系统的内存压力,减少 GC。
- 某类只要求生成一个对象的时候,如一个班中的班长、每个人的身份证号等。
- 某些类创建实例时占用资源较多,或实例化耗时较长,且经常使用。
- 某类需要频繁实例化,而创建的对象又频繁被销毁的时候,如多线程的线程池、网络连接池等。
- 频繁访问数据库或文件的对象。
- 对于一些控制硬件级别的操作,或者从系统上来讲应当是单一控制逻辑的操作,如果有多个实例,则系统会完全乱套。
- 当对象需要被共享的场合。由于单例模式只允许创建一个对象,共享该对象可以节省内存,并加快对象访问速度。如 Web 中的配置对象、数据库的连接池等。
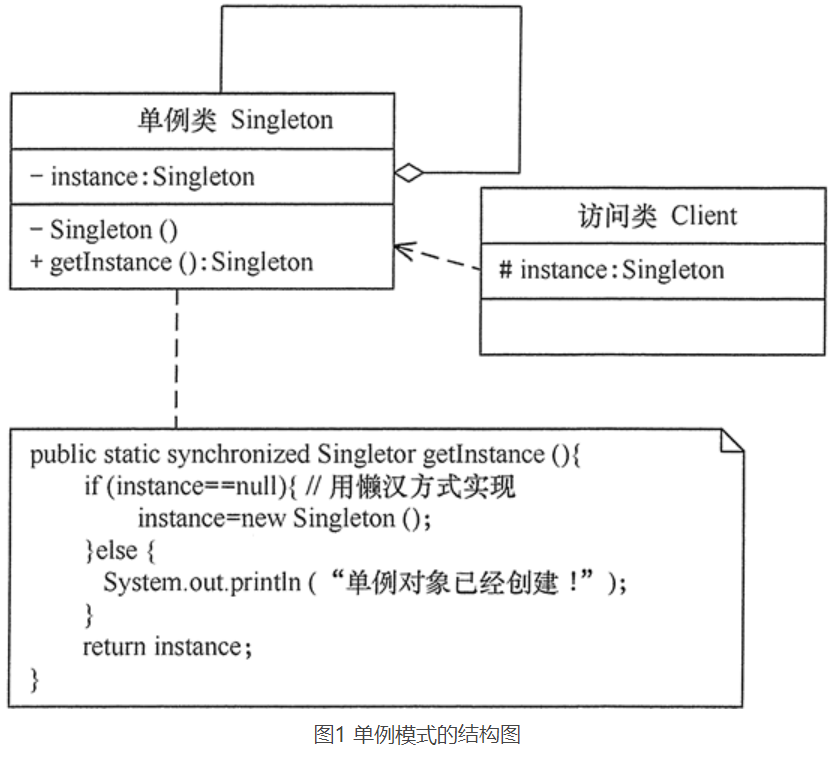
5.9.3、单例模式的结构
单例模式的主要角色如下。
- 单例类:包含一个实例且能自行创建这个实例的类。
- 访问类:使用单例的类。
结构:
5.9.4、相关的设计模式
在以下模式中, 多数情况下只会生成一个实例。
- AbstractFactory模式
- Builder模式
- Facade模式
- Prototype模式
5.9.5、单例模式注意事项和细节说明
- 单例模式保证了 系统内存中该类只存在一个对象,节省了系统资源,对于一些需要频繁创建销毁的对象,使用单例模式可以提高系统性能
- 当想实例化一个单例类的时候,必须要记住使用相应的获取对象的方法,而不是使用 new
- 枚举是最安全的单例,是不可破坏的,其余所有的单例都是可以用反射破坏的
- 那我们什么时候应该用Singleton呢?实际上,很多程序,尤其是Web程序,大部分服务类都应该被视作Singleton,如果全部按Singleton的写法写,会非常麻烦,所以,通常是通过约定让框架(例如Spring)来实例化这些类,保证只有一个实例,调用方自觉通过框架获取实例而不是
new操作符。因此,除非确有必要,否则Singleton模式一般以“约定”为主,不会刻意实现它。 - 经验之谈:一般情况下,不建议使用第 1 种和第 2 种懒汉方式,建议使用第 3 种饿汉方式。只有在要明确实现 lazy loading 效果时,才会使用第 5 种静态内部方式。如果涉及到反序列化创建对象时,可以尝试使用第 6 种枚举方式。如果有其他特殊的需求,可以考虑使用第 4 种双检锁方式。
5.9.6、反射与反序列化破坏单例模式的方法及解决办法
除枚举方式外, 其他方法都会通过反射或反序列化的方式破坏单例
5.9.6.1、反射破坏单例模式
通过反射获得单例类的构造函数,由于该构造函数是private的,通过setAccessible(true)指示反射的对象在使用时应该取消 Java 语言访问检查,使得私有的构造函数能够被访问,这样使得单例模式失效。
1 | public class Test { |
如果我们想要阻止单例破坏,可以在构造方法中进行判断,若已有实例, 则阻止生成新的实例,解决办法如下:
1 | private SingletonObject1(){ |
5.9.6.2、反序列化破坏单例模式
如果单例类实现了序列化接口Serializable, 就可以通过反序列化破坏单例。
我们使用正常的方式来获取一个对象。通过序列化将对象写入文件中,然后我们通过反序列化的到一个对象,我们再对比这个对象,输出的内存地址和布尔结果都表示这不是同一个对象。
1 | public class HungrySingleton implements Serializable{ |
这里我们使用之前的饿汉式的单例作为例子。在之前饿汉式的代码上做点小改动。就是让我们的单例类实现 Serializable接口。然后我们在测试类中测试一下怎么破坏。
1 | public class SingletonTest { |
解决方法:
所以我们可以不实现序列化接口,如果非得实现序列化接口,可以重写反序列化方法readResolve(), 反序列化时直接返回相关单例对象。
1 | public Object readResolve() throws ObjectStreamException{ |
5.9.7、单例模式的扩展
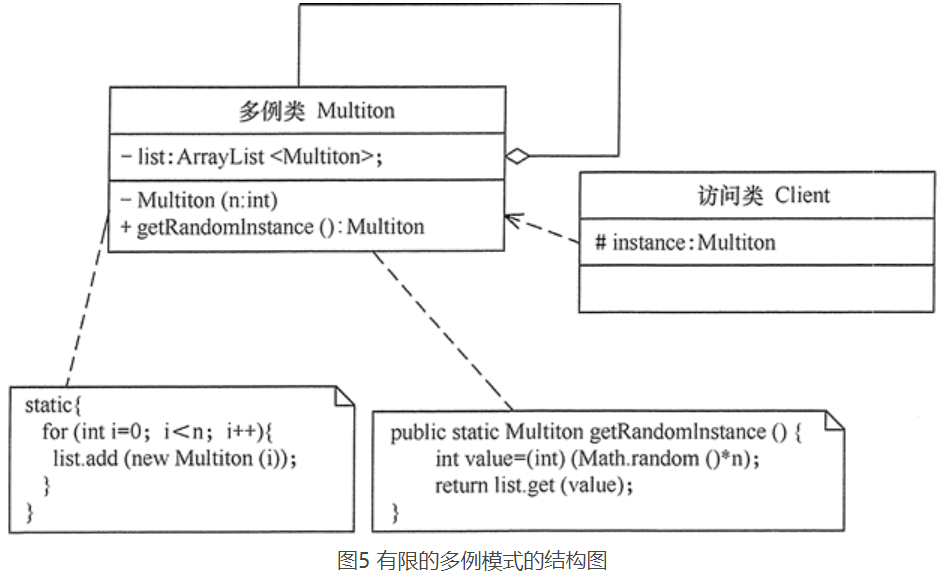
单例模式可扩展为有限的多例(Multitcm)模式,这种模式可生成有限个实例并保存在 ArrayList 中,客户需要时可随机获取,结构图:
6、工厂模式(创建型设计模式)
在日常开发中,凡是需要生成复杂对象的地方,都可以尝试考虑使用工厂模式来代替。
注意:上述复杂对象指的是类的构造函数参数过多等对类的构造有影响的情况,因为类的构造过于复杂,如果直接在其他业务类内使用,则两者的耦合过重,后续业务更改,就需要在任何引用该类的源代码内进行更改,光是查找所有依赖就很消耗时间了,更别说要一个一个修改了。
工厂模式的定义:定义一个创建产品对象的工厂接口,将产品对象的实际创建工作推迟到具体子工厂类当中。这满足创建型模式中所要求的“创建与使用相分离”的特点。
按实际业务场景划分,工厂模式有 3 种不同的实现方式,分别是
- 简单工厂模式
- 工厂方法模式
- 抽象工厂模式
6.1、简单工厂模式SimpleFactory
6.1.1、简单工厂模式介绍
- 简单工厂模式是属于创建型模式,是工厂模式的一种。简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例。简单工厂模式是工厂模式家族中最简单实用的模式。
- 简单工厂模式:定义了一个创建对象的类,由这个类来封装实例化对象的行为(代码)
- 在软件开发中,当我们会用到大量的创建某种、某类或者某批对象时,就会使用到工厂模式。
- 我们把被创建的对象称为“产品”,把创建产品的对象称为“工厂”。如果要创建的产品不多,只要一个工厂类就可以完成,这种模式叫“简单工厂模式”。
- 在简单工厂模式中创建实例的方法通常为静态(static)方法,因此简单工厂模式(Simple Factory Pattern)又叫作静态工厂方法模式(Static Factory Method Pattern)。
可总结:
- 一个调用者想创建一个对象,只要知道其名称就可以了。
- 扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
- 屏蔽产品的具体实现,调用者只关心产品的接口。
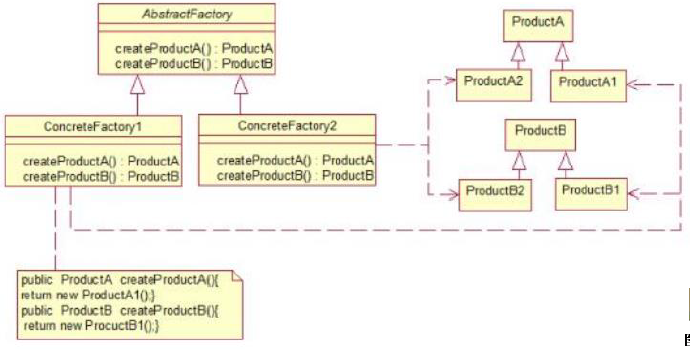
6.1.2、模式的结构与实现
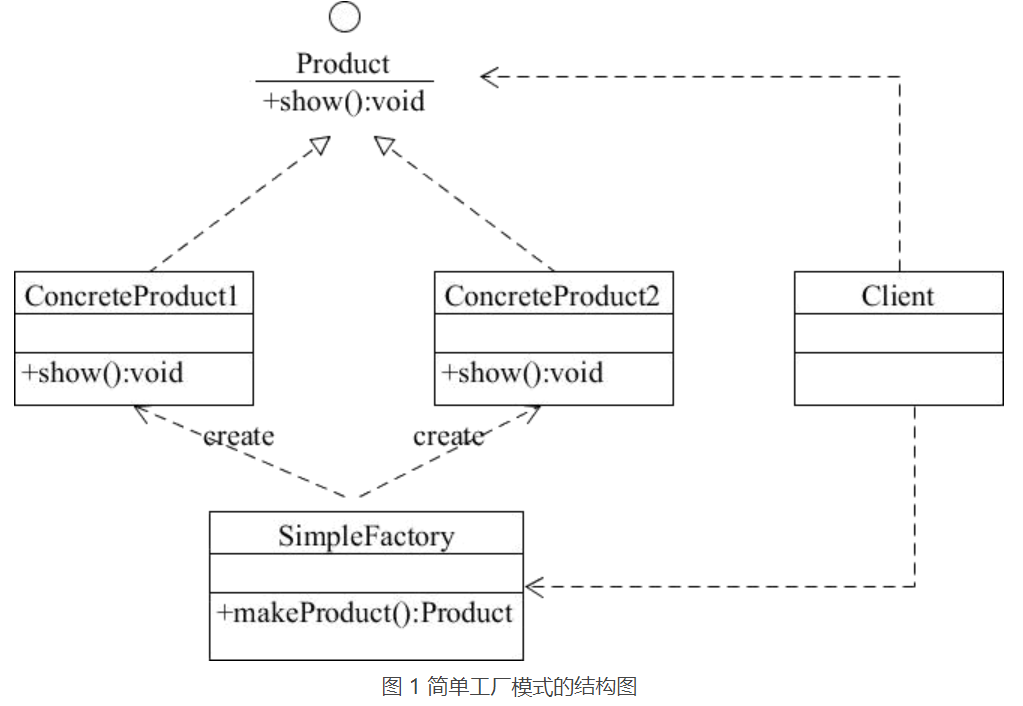
简单工厂模式的主要角色如下:
- 简单工厂(SimpleFactory):是简单工厂模式的核心,负责实现创建所有实例的内部逻辑。工厂类的创建产品类的方法可以被外界直接调用,创建所需的产品对象。
- 抽象产品(Product):是简单工厂创建的所有对象的父类,负责描述所有实例共有的公共接口。
- 具体产品(ConcreteProduct):是简单工厂模式的创建目标。
其结构图如下图所示:
根据上图写出该模式的代码如下:(模板)
1 | public class Client { |
6.1.3、应用实例
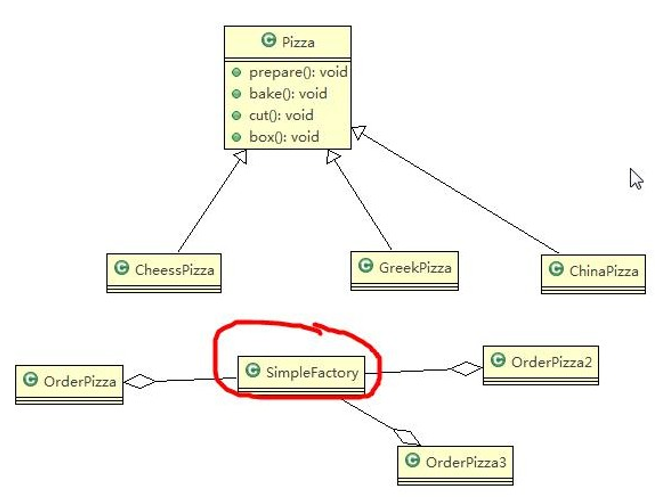
看一个具体的需求:披萨的项目:要便于披萨种类的扩展,要便于维护
- 披萨的种类很多(比如 GreekPizz、CheesePizz 等)
- 披萨的制作有 prepare,bake, cut, box
- 完成披萨店订购功能。
使用简单工厂模式实现:
简单工厂模式的设计方案: 定义一个可以实例化 Pizaa 对象的类,封装创建对象的代码。
代码实现(省略pizza抽象类与具体实现类的编写):
根据简单工厂模式创建:
创建工厂类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18//简单工厂类
public class SimpleFactory {
//根据orderType 返回对应的Pizza 对象
public Pizza createPizza(String orderType) {
Pizza pizza = null;
if (orderType.equals("greek")) {
pizza = new GreekPizza();
pizza.setName(" 希腊披萨 ");
} else if (orderType.equals("cheese")) {
pizza = new CheesePizza();
pizza.setName(" 奶酪披萨 ");
} else if (orderType.equals("pepper")) {
pizza = new PepperPizza();
pizza.setName("胡椒披萨");
}
return pizza;
}
}创建订购披萨类OrderPizza
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39public class OrderPizza {
//定义一个简单工厂对象
SimpleFactory simpleFactory;
Pizza pizza = null;
//构造器
public OrderPizza(SimpleFactory simpleFactory) {
setFactory(simpleFactory);
}
public void setFactory(SimpleFactory simpleFactory) {
String orderType = ""; //用户输入的
this.simpleFactory = simpleFactory; //设置简单工厂对象
do {
orderType = getType();
pizza = this.simpleFactory.createPizza(orderType);
//输出pizza
if(pizza != null) { //订购成功
pizza.prepare();
pizza.bake();
pizza.cut();
pizza.box();
} else {
System.out.println(" 订购披萨失败 ");
break;
}
}while(true);
}
// 写一个方法,可以获取客户希望订购的披萨种类
private String getType() {
try {
BufferedReader strin = new BufferedReader(new InputStreamReader(System.in));
System.out.println("input pizza 种类:");
String str = strin.readLine();
return str;
} catch (IOException e) {
e.printStackTrace();
return "";
}
}
}客户端PizzaStore:
1
2
3
4
5
6
7
8//相当于一个客户端,发出订购
public class PizzaStore {
public static void main(String[] args) {
//使用简单工厂模式
new OrderPizza(new SimpleFactory());
System.out.println("~~退出程序~~");
}
}
根据静态工厂模式创建:
创建静态工厂类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class SimpleFactory {
//简单工厂模式 也叫 静态工厂模式
public static Pizza createPizza(String orderType) {
Pizza pizza = null;
if (orderType.equals("greek")) {
pizza = new GreekPizza();
pizza.setName(" 希腊披萨 ");
} else if (orderType.equals("cheese")) {
pizza = new CheesePizza();
pizza.setName(" 奶酪披萨 ");
} else if (orderType.equals("pepper")) {
pizza = new PepperPizza();
pizza.setName("胡椒披萨");
}
return pizza;
}
}创建订购披萨类OrderPizza
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public class OrderPizza {
Pizza pizza = null;
String orderType = "";
// 构造器
public OrderPizza() {
do {
orderType = getType();
pizza = SimpleFactory.createPizza2(orderType);
// 输出pizza
if (pizza != null) { // 订购成功
pizza.prepare();
pizza.bake();
pizza.cut();
pizza.box();
} else {
System.out.println(" 订购披萨失败 ");
break;
}
} while (true);
}
// 写一个方法,可以获取客户希望订购的披萨种类
private String getType() {
try {
BufferedReader strin = new BufferedReader(new InputStreamReader(System.in));
System.out.println("input pizza 种类:");
String str = strin.readLine();
return str;
} catch (IOException e) {
e.printStackTrace();
return "";
}
}
}客户端PizzaStore:
1
2
3
4
5
6
7
8//相当于一个客户端,发出订购
public class PizzaStore {
public static void main(String[] args) {
//使用静态工厂模式
new OrderPizza();
System.out.println("~~退出程序~~");
}
}
6.1.4、简单工厂模式(静态工厂模式)的相关说明
优点:
- 工厂类包含必要的逻辑判断,可以决定在什么时候创建哪一个产品的实例。客户端可以免除直接创建产品对象的职责,很方便的创建出相应的产品。工厂和产品的职责区分明确。
- 客户端无需知道所创建具体产品的类名,只需知道参数即可。
- 也可以引入配置文件,在不修改客户端代码的情况下更换和添加新的具体产品类。
缺点:
- 简单工厂模式的工厂类单一,负责所有产品的创建,职责过重,一旦异常,整个系统将受影响。且工厂类代码会非常臃肿,违背高聚合原则。
- 使用简单工厂模式会增加系统中类的个数(引入新的工厂类),增加系统的复杂度和理解难度
- 系统扩展困难,一旦增加新产品不得不修改工厂逻辑,在产品类型较多时,可能造成逻辑过于复杂
- 简单工厂模式使用了 static 工厂方法,造成工厂角色无法形成基于继承的等级结构。
应用场景
对于产品种类相对较少的情况,考虑使用简单工厂模式。使用简单工厂模式的客户端只需要传入工厂类的参数,不需要关心如何创建对象的逻辑,可以很方便地创建所需产品。
简单来说,简单工厂模式有一个具体的工厂类,可以生成多个不同的产品,属于创建型设计模式。简单工厂模式不在 GoF 23 种设计模式之列。
6.2、工厂方法模式Factory Method
6.2.1、工厂方法模式介绍
- 简单工厂模式提到了违背了开闭原则,而“工厂方法模式”是对简单工厂模式的进一步抽象化,其好处是可以使系统在不修改原来代码的情况下引进新的产品,即满足开闭原则。
- 工厂方法模式:定义了一个创建对象的抽象方法,由子类决定要实例化的类。工厂方法模式将对象的实例化推迟到子类。
6.2.2、模式的结构与实现
工厂方法模式由抽象工厂、具体工厂、抽象产品和具体产品等4个要素构成。本节来分析其基本结构和实现方法。
6.2.2.1. 模式的结构
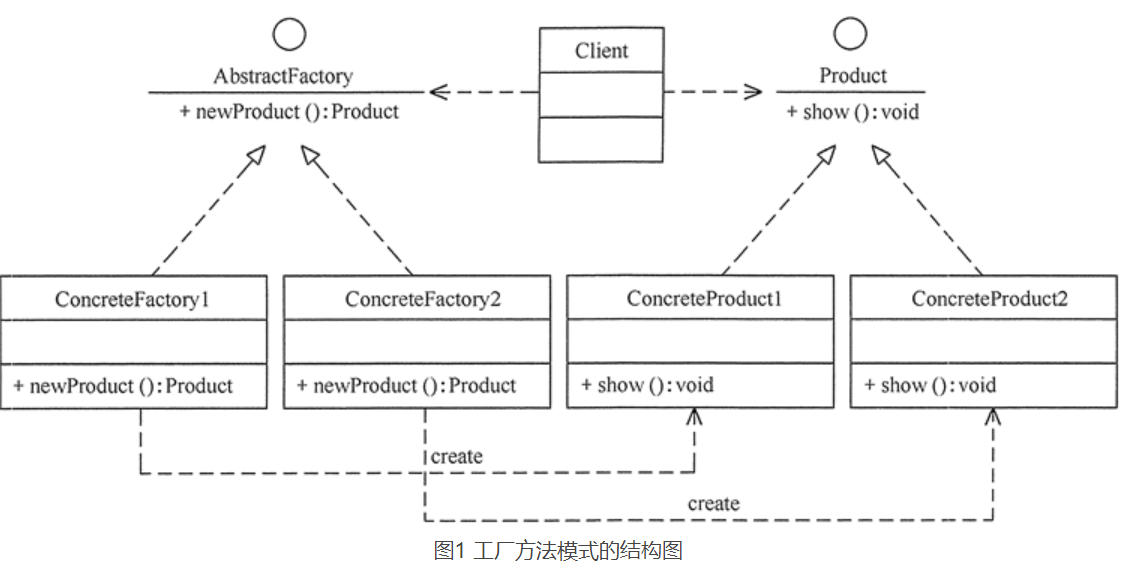
工厂方法模式的主要角色如下。
- 抽象工厂(Abstract Factory):提供了创建产品的接口,调用者通过它访问具体工厂的工厂方法 newProduct() 来创建产品。
- 具体工厂(ConcreteFactory):主要是实现抽象工厂中的抽象方法,完成具体产品的创建。
- 抽象产品(Product):定义了产品的规范,描述了产品的主要特性和功能。
- 具体产品(ConcreteProduct):实现了抽象产品角色所定义的接口,由具体工厂来创建,它同具体工厂之间一一对应。
其结构图如图 1 所示:
6.2.2.2、模式的实现
根据图 1 写出该模式的代码如下:
1 | package FactoryMethod; |
6.2.3、应用实例
披萨项目新的需求:客户在点披萨时,可以点不同口味的披萨,比如 北京的奶酪 pizza、北京的胡椒 pizza 或者是伦敦的奶酪 pizza、伦敦的胡椒 pizza
思路分析图解:
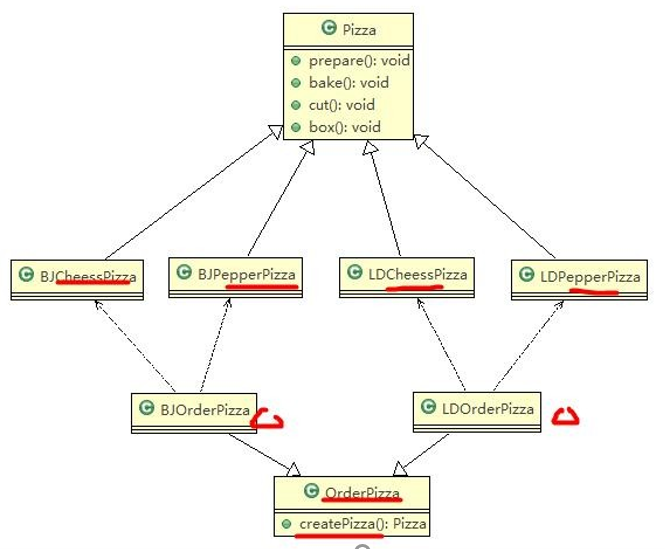
代码实现:
订购披萨OrderPizza
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public abstract class OrderPizza {
//定义一个抽象方法,createPizza , 让各个工厂子类自己实现
abstract Pizza createPizza(String orderType);
// 构造器
public OrderPizza() {
Pizza pizza = null;
String orderType; // 订购披萨的类型
do {
orderType = getType();
pizza = createPizza(orderType); //抽象方法,由工厂子类完成
//输出pizza 制作过程
pizza.prepare();
pizza.bake();
pizza.cut();
pizza.box();
} while (true);
}
// 写一个方法,可以获取客户希望订购的披萨种类
private String getType() {
try {
BufferedReader strin = new BufferedReader(new InputStreamReader(System.in));
System.out.println("input pizza 种类:");
String str = strin.readLine();
return str;
} catch (IOException e) {
e.printStackTrace();
return "";
}
}
}北京的pizza继承OrderPizza(伦敦同)
1
2
3
4
5
6
7
8
9
10
11
12
13public class BJOrderPizza extends OrderPizza {
Pizza createPizza(String orderType) {
Pizza pizza = null;
if(orderType.equals("cheese")) {
pizza = new BJCheesePizza();
} else if (orderType.equals("pepper")) {
pizza = new BJPepperPizza();
}
// TODO Auto-generated method stub
return pizza;
}
}客户端:
1
2
3
4
5
6
7
8
9
10
11
12public class PizzaStore {
public static void main(String[] args) {
String loc = "bj";
if (loc.equals("bj")) {
//创建北京口味的各种Pizza
new BJOrderPizza();
} else {
//创建伦敦口味的各种Pizza
new LDOrderPizza();
}
}
}
6.2.4、工厂方法模式的相关说明
优点:
- 用户只需要知道具体工厂的名称就可得到所要的产品,无须知道产品的具体创建过程。
- 灵活性增强,对于新产品的创建,只需多写一个相应的工厂类。
- 典型的解耦框架。高层模块只需要知道产品的抽象类,无须关心其他实现类,满足迪米特法则、依赖倒置原则和里氏替换原则。
缺点:
- 类的个数容易过多,增加复杂度
- 增加了系统的抽象性和理解难度
- 抽象产品只能生产一种产品,此弊端可使用抽象工厂模式解决。
应用场景:
- 客户只知道创建产品的工厂名,而不知道具体的产品名。如 TCL 电视工厂、海信电视工厂等。
- 创建对象的任务由多个具体子工厂中的某一个完成,而抽象工厂只提供创建产品的接口。
- 客户不关心创建产品的细节,只关心产品的品牌
注意:
当需要生成的产品不多且不会增加,一个具体工厂类就可以完成任务时,可删除抽象工厂类。这时工厂方法模式将退化到简单工厂模式。
6.2.5、工厂方法模式的登场角色补充(来自《图解设计模式》)
在 Factory Method 模式中有以下登场角色。 通过查看 Factory Method 模式的类图,我们可以知道, 父类(框架)这一方的 Creator 角色和 Product 角色的关系与子类(具体加工)这一方的 ConcreteCreator 角色和 ConcreteProduct 角色的关系是平行的。
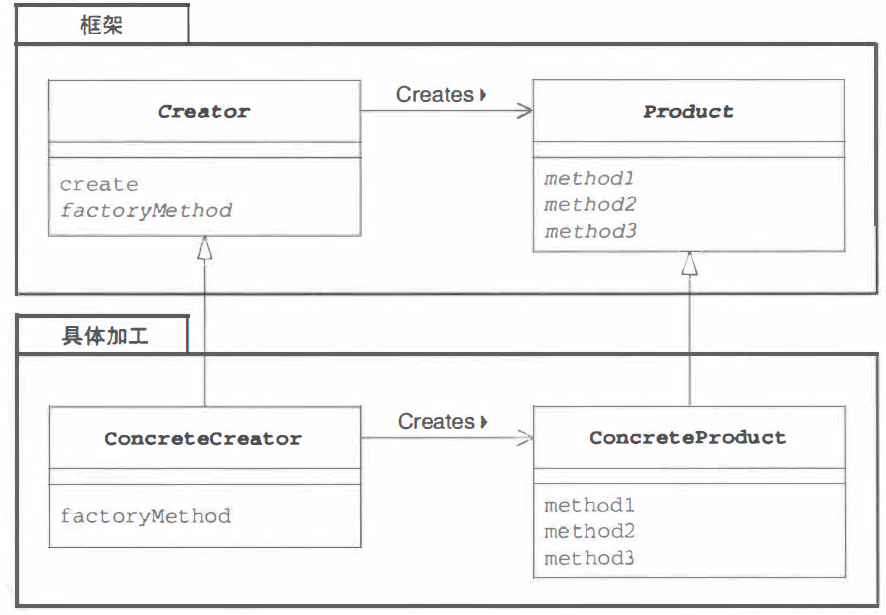
Product (产品)
Product角色属于框架这一方, 是一个抽象类。它定义了在Factory Method模式中生成的那些实例所持有的接口(API), 但具体的处理则由子类ConcreteProduct角色决定。 在示例程序中由Product类扮演此角色。
Creator (创建者)
Creator角色属千框架这一方, 它是负责生成 Product角色的抽象类,但具体的处理则由子类ConcreteCreator角色决定。 在示例程序中, 由Factory类扮演此角色。
Creator角色对于实际负责生成实例的ConcreteCreator角色一无所知,它唯一知道的就是, 只要调用Product角色和生成实例的方法(图4-3中的factoryMethod 方法), 就可以生成Productde的实例。 在示例程序中,createProduct 方法是用于生成实例的方法。 不用new关键字来生成实例, 而是调用生成实例的专用方法来生成实例, 这样就可以防止父类与其他具体类耦合。
ConcreteProduct (具体的产品)
Concrete Product角色属于具体加工这一方,它决定了具体的产品。 在示例程序中, 由IDCard 类扮演此角色。
ConcreteCreator (具体的创建者)
ConcreteCreator角色属于具体加工这一方, 它负责生成具体的产品。 在示例程序中,由IDCardFactory类扮演此角色。
6.2.6、相关的设计模式
Template Method 模式
Factory Method模式是Template Method的典型应用。在示例程序中, create方法就是模板方法。
Singleton 模式
在多数情况下我们都可以将Singleton模式用于扮演Creator角色(或是ConcreteCreator角色) 的类。这是因为在程序中没有必要存在多个 Creator角色(或是ConcreteCreator角色)的实例。不过在示例程序中, 我们并没有使用Singleton模式。
Composite 模式
有时可以将 Composite模式用于Product角色(或是ConcreteProduct角色)。
Iterator 模式
有时, 在Iterator模式中使用iterator方法生成Iterator的实例时会使用Factory Method 模式。
6.3、抽象工厂模式Abstract Factory
6.3.1、抽象工厂模式介绍
- 前面介绍的工厂方法模式中考虑的是一类产品的生产,如畜牧场只养动物、电视机厂只生产电视机、计算机软件学院只培养计算机软件专业的学生等。
- 同种类称为同等级,也就是说:工厂方法模式只考虑生产同等级的产品,但是在现实生活中许多工厂是综合型的工厂,能生产多等级(种类) 的产品,如农场里既养动物又种植物,电器厂既生产电视机又生产洗衣机或空调,大学既有软件专业又有生物专业等。
- 抽象工厂模式将考虑多等级产品的生产,将同一个具体工厂所生产的位于不同等级的一组产品称为一个产品族.
抽象工厂(AbstractFactory)模式的定义:定义了一个 interface 用于创建相关或有依赖关系的对象簇,而无需指明具体的类,是一种为访问类提供一个创建一组相关或相互依赖对象的接口,且访问类无须指定所要产品的具体类就能得到同族的不同等级的产品的模式结构。可以看作:抽象工厂是一个超级工厂,围绕一个超级工厂创建其他工厂,该超级工厂又称为其他工厂的工厂。
抽象工厂模式是工厂方法模式的升级版本,工厂方法模式只生产一个等级的产品,而抽象工厂模式可生产多个等级的产品。抽象工厂模式可以将简单工厂模式和工厂方法模式进行整合。
从设计层面看,抽象工厂模式就是对简单工厂模式的改进(或者称为进一步的抽象)。
将工厂抽象成两层,AbsFactory(**抽象工厂)** 和 具体实现的工厂子类。程序员可以根据创建对象类型使用对应的工厂子类。这样将单个的简单工厂类变成了工厂簇,更利于代码的维护和扩展。
使用抽象工厂模式一般要满足以下条件。
- 系统中有多个产品族,每个具体工厂创建同一族但属于不同等级结构的产品。
- 系统一次只可能消费其中某一族产品,即同族的产品一起使用。
6.3.2、模式的结构与实现
6.3.2.1、模式的结构
抽象工厂模式的主要角色如下。
- 抽象工厂(Abstract Factory):提供了创建产品的接口,它包含多个创建产品的方法 newProduct(),可以创建多个不同等级的产品。
- 具体工厂(Concrete Factory):主要是实现抽象工厂中的多个抽象方法,完成具体产品的创建。
- 抽象产品(Product):定义了产品的规范,描述了产品的主要特性和功能,抽象工厂模式有多个抽象产品。
- 具体产品(ConcreteProduct):实现了抽象产品角色所定义的接口,由具体工厂来创建,它同具体工厂之间是多对一的关系。
6.3.2.2、模式的实现类图(具体代码)
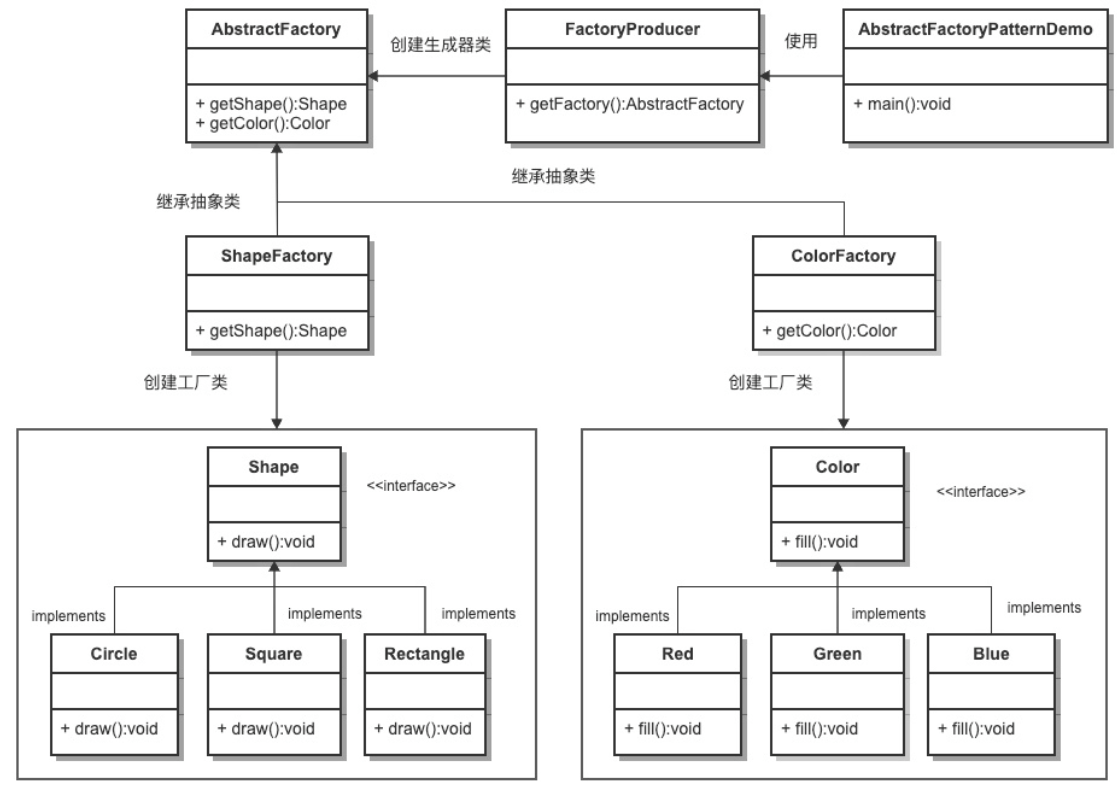
6.3.3、应用实例
使用抽象工厂模式来完成披萨项目。
类图:
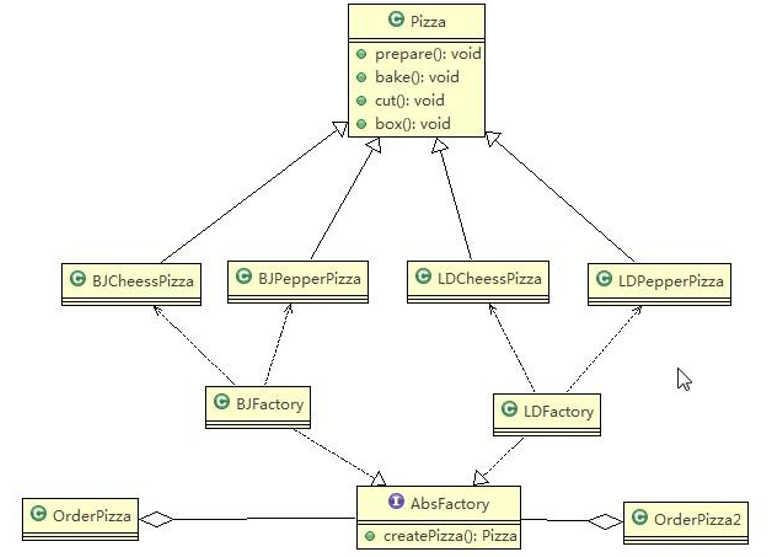
代码:
抽象工厂:
1 | //一个抽象工厂模式的抽象层(接口) |
北京工厂实现抽象工厂生产披萨(伦敦同)
1 | //这是工厂子类 |
订购披萨:
1 | public class OrderPizza { |
客户端:
1 | public class PizzaStore { |
6.3.4、抽象工厂模式的相关说明
抽象工厂模式除了具有工厂方法模式的优点外,其他主要优点如下。
- 可以在类的内部对产品族中相关联的多等级产品共同管理,而不必专门引入多个新的类来进行管理。
- 当需要产品族时,抽象工厂可以保证客户端始终只使用同一个产品的产品组。
- 抽象工厂增强了程序的可扩展性,当增加一个新的产品族时,不需要修改原代码,满足开闭原则。
其缺点是:当产品族中需要增加一个新的产品时,所有的工厂类都需要进行修改。增加了系统的抽象性和理解难度
模式的应用场景
抽象工厂模式最早的应用是用于创建属于不同操作系统的视窗构件。如 Java 的 AWT 中的 Button 和 Text 等构件在 Windows 和 UNIX 中的本地实现是不同的。
- 当需要创建的对象是一系列相互关联或相互依赖的产品族时,如电器工厂中的电视机、洗衣机、空调等。
- 系统中有多个产品族,但每次只使用其中的某一族产品。如有人只喜欢穿某一个品牌的衣服和鞋。
- 系统中提供了产品的类库,且所有产品的接口相同,客户端不依赖产品实例的创建细节和内部结构。
模式的扩展
抽象工厂模式的扩展有一定的“开闭原则”倾斜性:
- 当增加一个新的产品族时只需增加一个新的具体工厂,不需要修改原代码,满足开闭原则。
- 当产品族中需要增加一个新种类的产品时,则所有的工厂类都需要进行修改,不满足开闭原则。
另一方面,当系统中只存在一个等级结构的产品时,抽象工厂模式将退化到工厂方法模式。
进阶阅读
如果您想了解抽象工厂在框架源码中的应用,可阅读以下文章。
6.3.5、相关的设计模式
Builder模式
Abstract Factory模式通过调用抽象产品的接口 (APl) 来组装抽象产品, 生成具有复杂结构的实例。
Builder模式则是分阶段地制作复杂实例。
Factory Method模式
有时AbstractFactory模式中零件和产品的生成会使用到Factory Method模式。
Composite模式
有时AbstractFactory模式在制作产品时会使用Composite模式。
Singleton模式
有时AbstractFactory模式中的具体工厂会使用Singleton模式。
6.4、工厂模式在 JDK-Calendar 应用的源码分析
JDK 中的 Calendar 类中,就使用了简单工厂模式
原码:

其中createCalendar()方法:

6.5、工厂模式小结
工厂模式的意义
将实例化对象的代码提取出来,放到一个类中统一管理和维护,达到和主项目的依赖关系的解耦。从而提高项目的扩展和维护性。
三种工厂模式
- 简单工厂模式(不在23种之中)
- 工厂方法模式
- 抽象工厂模式
设计模式的依赖抽象原则
创建对象实例时,不要直接 new 类, 而是把这个 new 类的动作放在一个工厂的方法中,并返回。有的书上说, 变量不要直接持有具体类的引用。
不要让类继承具体类,而是继承抽象类或者是实现 interface(接口)
不要覆盖基类中已经实现的方法。
7、原型模式ProtoType(创建型设计模式)
7.1、基本介绍
- 原型模式(Prototype 模式)是指:用原型实例指定创建对象的种类,并且通过拷贝这些原型,创建新的对象
- 原型模式是一种创建型设计模式,允许一个对象再创建另外一个可定制的对象,无需知道如何创建的细节
- 工作原理是:通过将一个原型对象传给那个要发动创建的对象,这个要发动创建的对象通过请求原型对象拷贝它们自己来实施创建,即 对象**.clone**()
7.2、原型模式原理结构图-uml 类图
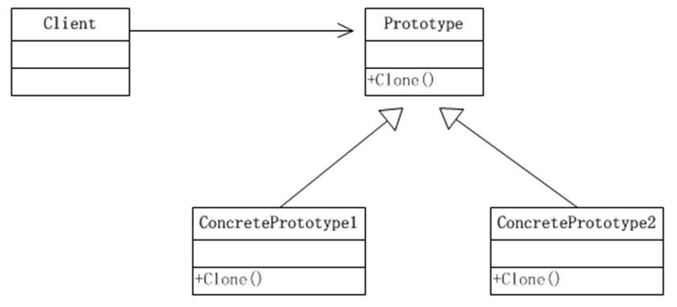
原理结构图说明:
- Prototype : 原型类,声明一个克隆自己的接口
- ConcretePrototype: 具体的原型类, 实现一个克隆自己的操作
- Client: 使用者;让一个原型对象克隆自己,从而创建一个新的对象(属性一样)
7.3、应用举例
克隆羊问题:
现在有一只羊 tom,姓名为: tom, 年龄为:1,颜色为:白色,请编写程序创建和 tom 羊 属性完全相同的 10只羊。
7.3.1、传统方式解决克隆羊问题
7.3.1.1、思路分析(类图)

7.3.1.2、相关代码:(在Client中)
1 | //传统的方法 |
7.3.1.3、传统的方式的优缺点
- 优点是比较好理解,简单易操作。
- 在创建新的对象时,总是需要重新获取原始对象的属性,如果创建的对象比较复杂时,效率较低
- 总是需要重新初始化对象,而不是动态地获得对象运行时的状态, 不够灵活
7.3.1.4、改进方法(使用原型模式)
Java 中 Object 类是所有类的根类,Object 类提供了一个 clone()方法,该方法可以将一个 Java 对象复制一份,但是需要实现 clone 的 Java 类必须要实现一个接口 Cloneable,该接口表示该类能够复制且具有复制的能力 =>原型模式
7.3.2、原型模式解决克隆羊问题
实现步骤:
- 实例实现接口Cloneable,并重写Object的clone方法
- 在Client使用创建的实例的clone方法进行对象的克隆
代码实现:
sheep:
1 | public class Sheep implements Cloneable { |
Client:
1 | public class Client { |
使用原型模式改进传统方式,让程序具有更高的效率和扩展性。
7.4、浅拷贝和深拷贝
7.4.1、浅拷贝的介绍
- 对于数据类型是基本数据类型的成员变量,浅拷贝会直接进行值传递,也就是将该属性值复制一份给新的对象。
- 对于String,虽然String不是基本数据结构,而是应用数据类型。但是在JVM中存在字符串常量池会存储已创建的字符串。在克隆的时候也是引用也是直接指向字符串常量池里的字符串。所以在clone当中可以将String近似于看作基本数据类型。
- 对于数据类型是引用数据类型的成员变量,比如说成员变量是某个数组、某个类的对象等,那么浅拷贝会进行引用传递,也就是只是将该成员变量的引用值(内存地址)复制一份给新的对象。因为实际上两个对象的该成员变量都指向同一个实例。在这种情况下,在一个对象中修改该成员变量会影响到另一个对象的该成员变量值。
- 前面我们克隆羊就是浅拷贝(里面的friend是同一个friend,即所有的克隆羊都有同一个朋友)
- 浅拷贝是使用默认的 clone()方法来实现:sheep = (Sheep) super.clone();
7.4.2、深拷贝基本介绍
- 复制对象的所有基本数据类型的成员变量值
- 为所有引用数据类型的成员变量申请存储空间,并复制每个引用数据类型成员变量所引用的对象,直到该对象可达的所有对象。也就是说,对象进行深拷贝要对整个对象(包括对象的引用类型)进行拷贝
- 深拷贝实现方式 1:重写 clone 方法来实现深拷贝
- 深拷贝实现方式 2:通过对象序列化实现深拷贝(推荐)
7.4.3、深拷贝应用实例
7.4.3.1、使用 重写 clone 方法实现深拷贝
DeepCloneableTarget:其他实例当中的成员变量:实现克隆接口与序列化接口Serializable, Cloneable
1 | public class DeepCloneableTarget implements Serializable, Cloneable { |
DeepProtoType:要进行克隆的实例类,其中有成员变量DeepCloneableTarget
1 | public class DeepProtoType implements Serializable, Cloneable{ |
Client:对DeepProtoType进行克隆
1 | public class Client { |
7.4.3.2、使用序列化来实现深拷贝
DeepCloneableTarget:同上
DeepProtoType:要进行克隆的实例类,其中有成员变量DeepCloneableTarget
1 | public class DeepProtoType implements Serializable, Cloneable{ |
Client:对DeepProtoType进行克隆
1 | public class Client { |
7.4.3.3、对于实例类的成员变量为本身的实例的深拷贝:
使用序列化可以实现,但是使用clone方法会报StackOverflowError异常
sheep:
1 | public class Sheep implements Cloneable, Serializable { |
Client:
1 | public class Client { |
7.4.4、对于深拷贝的clone方法与序列化方法
7.4.4.1、clone方法
- clone方法分成两步:
- 先克隆基本数据类型和String
- 在对其引用数据类型进行多次克隆
- 如果想要深拷贝一个对象, 这个对象必须要实现Cloneable接口,实现clone方法,并且在clone方法内部,把该对象引用的其他对象也要clone一份 , 这就要求这个被引用的对象必须也要实现Cloneable接口并且实现clone方法。
- clone实际上就是实现了多重clone,实例本身有其他的应用数据类型(除String),就先重写其他的引用数据类型的clone方法;若在其他的应用数据类型(除String)又有其他的引用数据类型,又重复该过程,直到做到所有的成员变量都完成clone。
- 所以,如果在拷贝一个对象时,要想让这个拷贝的对象和源对象完全彼此独立,那么在引用链上的每一级对象都要被显式的拷贝。所以创建彻底的深拷贝是非常麻烦的,尤其是在引用关系非常复杂的情况下, 或者在引用链的某一级上引用了一个第三方的对象, 而这个对象没有实现clone方法, 那么在它之后的所有引用的对象都是被共享的。或者如果某一个类没有实现Cloneable接口,我们还要对其进行深拷贝的话,就必然需要修改该类,这样就违反了OCP原则。
- 所以在开发中这种深拷贝方式不常用。
7.4.4.2、序列化方法
- 序列化方法也分成两步
- 将要实现克隆的实例进行序列化
- 在将其进行反序列化出来实现实例的拷贝
- 使用该类的对象必须要实现Serializable接口,否则是没有办法实现克隆的。无须继承Cloneable接口实现clone()方法。
- 在内存中通过字节流的拷贝是比较容易实现的。把母对象写入到一个字节流中,再从字节流中将其读出来,这样就可以创建一个新的对象了,并且该新对象与母对象之间并不存在引用共享的问题,真正实现对象的深拷贝。
- 能实现对于实例类的成员变量为本身的实例的深拷贝
- 缺点:使用该类的对象必须要实现Serializable接口,所以在一些类并没有实现Serializable接口,如果还要对其进行深拷贝的话,就必然需要修改该类,这样就违反了OCP原则。
- 所以在开发中推荐使用这种方式进行深拷贝。
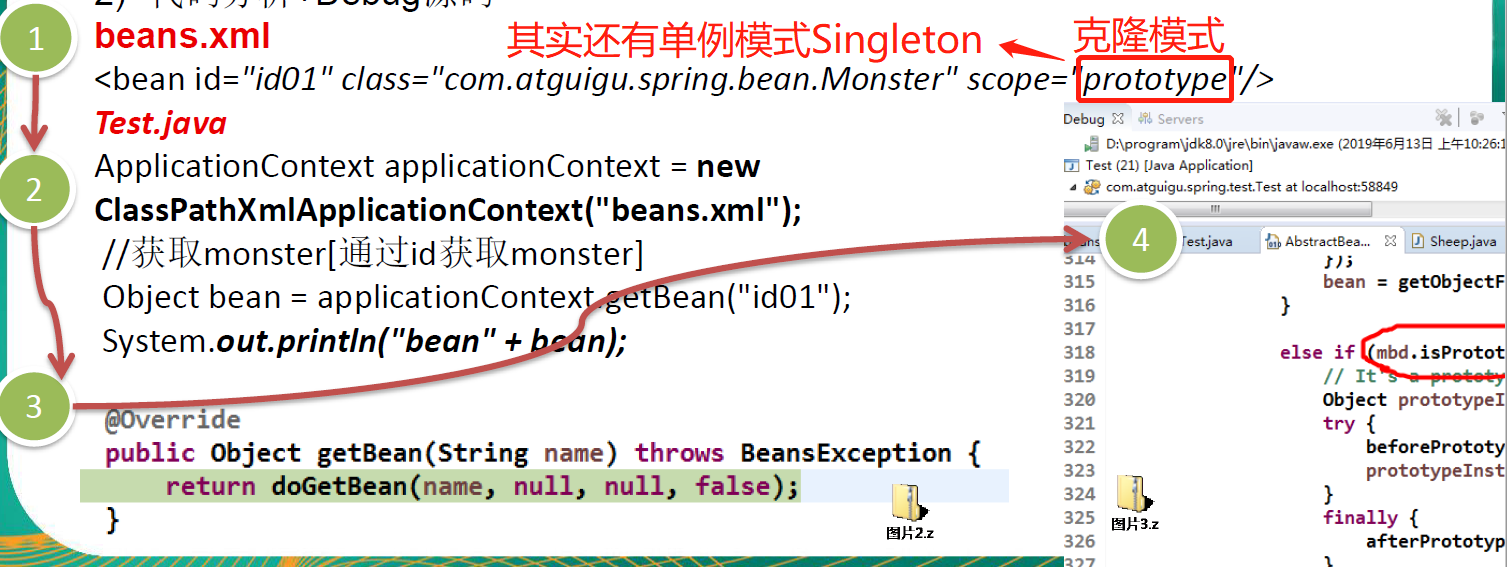
7.5、原型模式在 Spring 框架中源码分析
Spring 中原型 bean 的创建,就是原型模式的应用
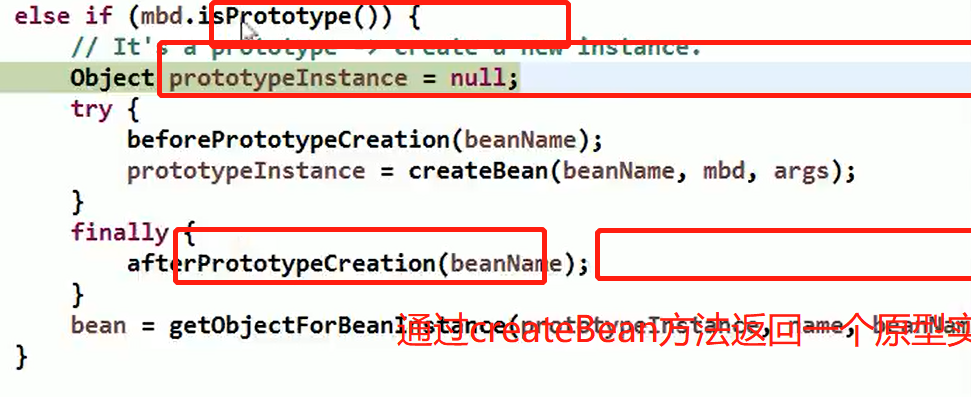
7.6、new一个对象的过程和clone一个对象的过程区别
关于new:
new操作符的本意是分配内存。程序执行到new操作符时,会先去看new操作符后面的类型,因为知道了类型,才能知道要分配多大的内存空间。分配完内存之后,再调用构造函数,填充对象的各个域,这一步叫做对象的初始化,构造方法返回后,一个对象创建完毕,可以把它的引用(也就是地址)发布到外部,在外部就可以使用这个引用操作这个对象。
关于clone:
clone在第一步是和new相似的,都是分配内存,调用clone方法时,分配的内存和原对象(即调用clone方法的对象)相同,然后再使用原对象中对应的各个域,填充新对象的域,填充完成之后,clone方法返回,一个新的相同的对象被创建,同样可以把这个新对象的引用发布到外部。
- clone()不会调用构造方法;new会调用构造方法。
- new对象时根据类型确定分配内存空间的大小, clone是根据原对象分配内
7.7、原型模式的总结
原型模式的优点:
- Java 自带的原型模式基于内存二进制流的复制,在性能上比直接 new 一个对象更加优良。
- 它逃避了构造函数的约束。
- 可以使用深克隆方式保存对象的状态,使用原型模式将对象复制一份,并将其状态保存起来,简化了创建对象的过程,以便在需要的时候使用(例如恢复到历史某一状态),可辅助实现撤销操作。
原型模式的缺点:
- 需要为每一个类都配置一个 clone 方法
- clone 方法位于类的内部,当对已有类进行改造的时候,需要修改代码,违背了开闭原则。
- 当实现深克隆时,需要编写较为复杂的代码,而且当对象之间存在多重嵌套引用时,为了实现深克隆,每一层对象对应的类都必须支持深克隆,实现起来会比较麻烦。因此,深克隆、浅克隆需要运用得当。
原型模式的应用场景:
- 对象之间相同或相似,即只是个别的几个属性不同的时候。
- 创建对象成本较大,例如初始化时间长,占用CPU太多,或者占用网络资源太多等,需要优化资源。类初始化需要消化非常多的资源,这个资源包括数据、硬件资源等。
- 创建一个对象需要繁琐的数据准备或访问权限等,需要提高性能或者提高安全性。
- 一个对象需要提供给其他对象访问,而且各个调用者可能都需要修改其值时,可以考虑使用原型模式拷贝多个对象供调用者使用
- 资源优化场景
- 一个对象多个修改者的场景
- 想要生成实例的框架不依赖与具体的类,解耦框架与生成的实例
在实际项目中,原型模式很少单独出现,一般是和工厂方法模式一起出现,通过 clone 的方法创建一个对象,然后由工厂方法提供给调用者。原型模式已经与 Java 融为浑然一体,大家可以随手拿来使用。
在 Spring 中,原型模式应用的非常广泛,例如 scope=’prototype’、JSON.parseObject() 等都是原型模式的具体应用。
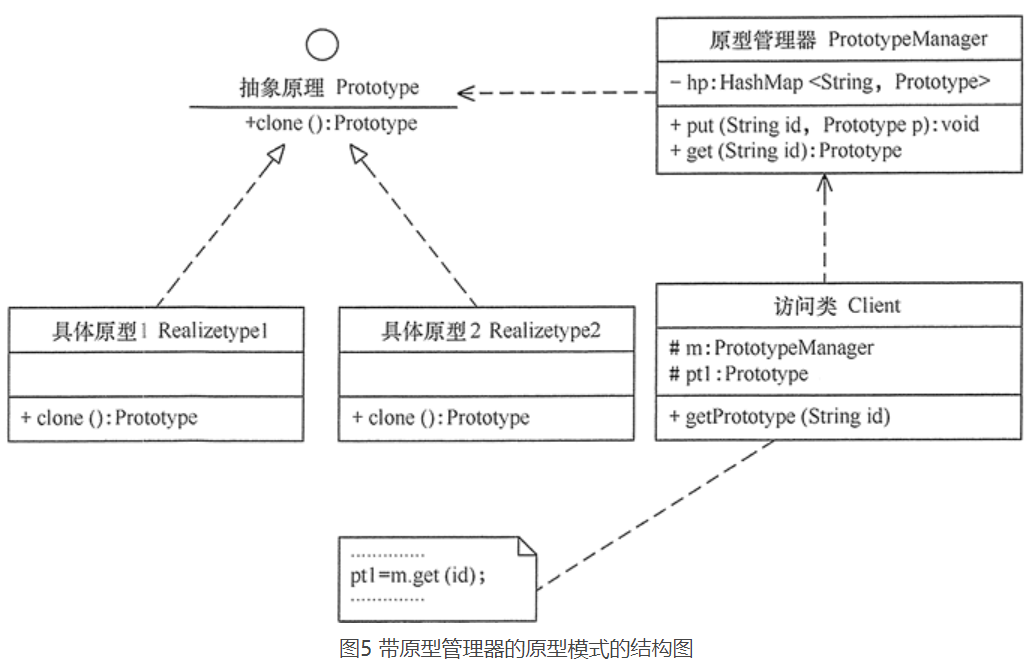
7.8、原型模式的扩展(带原型管理器的原型模式)
原型模式可扩展为带原型管理器的原型模式,它在原型模式的基础上增加了一个原型管理器 PrototypeManager 类。该类用 HashMap 保存多个复制的原型,Client 类可以通过管理器的 get(String id) 方法从中获取复制的原型。其结构图:
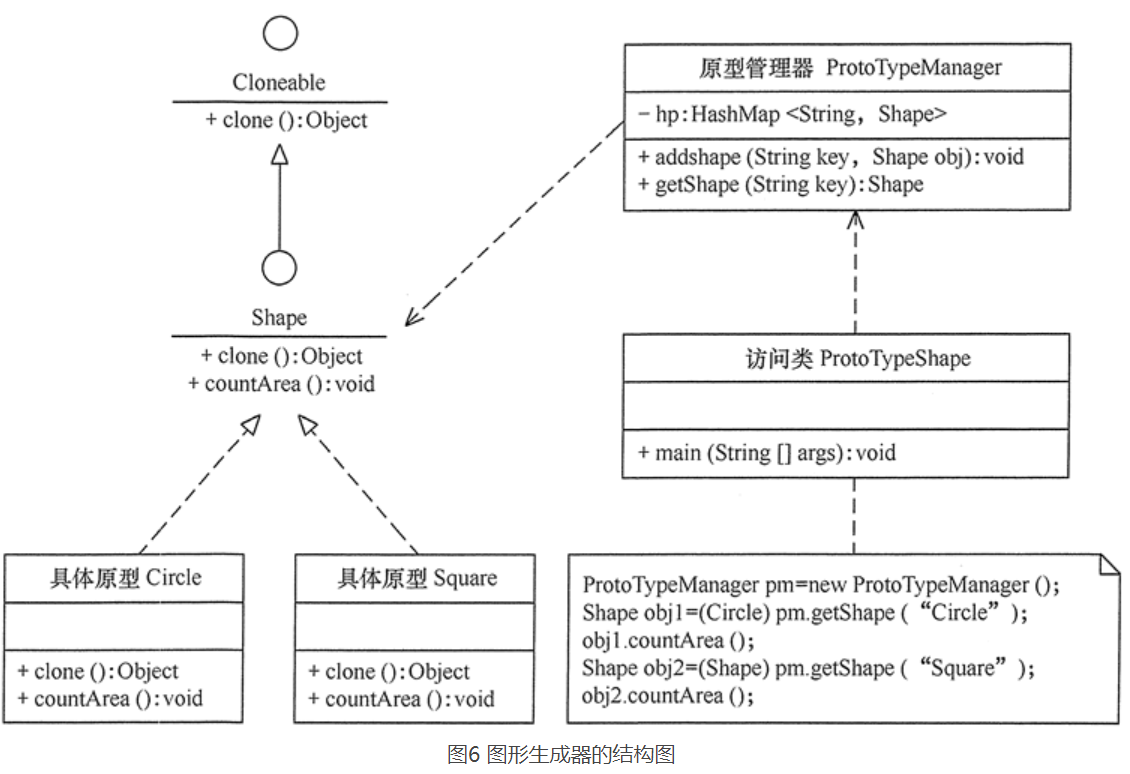
举例:
用带原型管理器的原型模式来生成包含“圆”和“正方形”等图形的原型,并计算其面积。分析:本实例中由于存在不同的图形类,例如,“圆”和“正方形”,它们计算面积的方法不一样,所以需要用一个原型管理器来管理它们,是其结构图:
ProtoTypeManager :
1 | class ProtoTypeManager { |
7.9、进阶阅读
原型模式也称为克隆模式,如果您想深入了解原型(克隆)模式,可以猛击阅读下面的文章。
7.10、相关的设计模式
Flyweight 模式
使用Prototype模式可以生成一个与当前实例的状态完全相同的实例。 而使用Flyweight模式可以在不同的地方使用同一个实例。
Memento 模式
使用Prototype模式可以生成一个与当前实例的状态完全相同的实例。而使用Memento模式可以保存当前实例的状态, 以实现快照和撤销功能。
Composite 模式以及 Decorator 模式
经常使用Composite模式和Decorator模式时, 需要能够动态地创建复杂结构的实例。 这时可 以使用Prototype模式, 以帮助我们方便地生成实例。
Command 模式
想要复制Command模式中出现的命令时, 可以使用Prototype模式。
7.11、原型模式的注意事项和细节
- 创建新的对象比较复杂时,可以利用原型模式简化对象的创建过程,同时也能够提高效率
- 不用重新初始化对象,而是动态地获得对象运行时的状态
- 如果原始对象发生变化(增加或者减少属性),其它克隆对象的也会发生相应的变化,无需修改代码
- 在实现深克隆的时候可能需要比较复杂的代码
- Cloneable接口是一个标记接口,没有声明方法
- 缺点:需要为每一个类配备一个克隆方法,这对全新的类来说不是很难,但对已有的类进行改造时,需要修改其源代码,违背了 ocp 原则。
- 原型模式应用不是很广泛,因为很多实例会持有类似文件、Socket这样的资源,而这些资源是无法复制给另一个对象共享的,只有存储简单类型的“值”对象可以复制。
8、建造者模式Builder(创建型设计模式)
8.1、基本介绍
- 建造者模式(Builder Pattern) 又叫生成器模式,是一种对象构建模式。它可以将复杂对象的建造过程抽象出来(抽象类别),使这个抽象过程的不同实现方法可以构造出不同表现(属性)的对象。
- 建造者模式将一个复杂对象的构造与它的表示分离,使同样的构建过程可以创建不同的表示。它是将一个复杂的对象分解为多个简单的对象,然后一步一步构建而成。它将变与不变相分离,即产品的组成部分是不变的,但每一部分是可以灵活选择的。
8.2、建造者模原理结构图-uml类图与模板实现
8.2.1、建造者模式的四个角色
建造者(Builder)模式由产品、抽象建造者、具体建造者、指挥者等 4 个要素构成
- Product(产品角色): 它是包含多个组成部件的复杂对象,由具体建造者来创建其各个零部件。
- Builder(抽象建造者): 它是一个包含创建产品各个子部件的抽象方法的接口,通常还包含一个返回**复杂产品的方法 getResult()**。
- ConcreteBuilder(具体建造者): 实现 Builder 接口,完成复杂产品的各个部件的具体创建方法。
- Director(指挥者): 构建一个使用 Builder 接口的对象。它主要是用于创建一个复杂的对象。它主要有两个作用:
- 隔离了客户与对象的生产过程
- 负责控制产品对象的生产过程
8.2.2、建造者模式原理类图
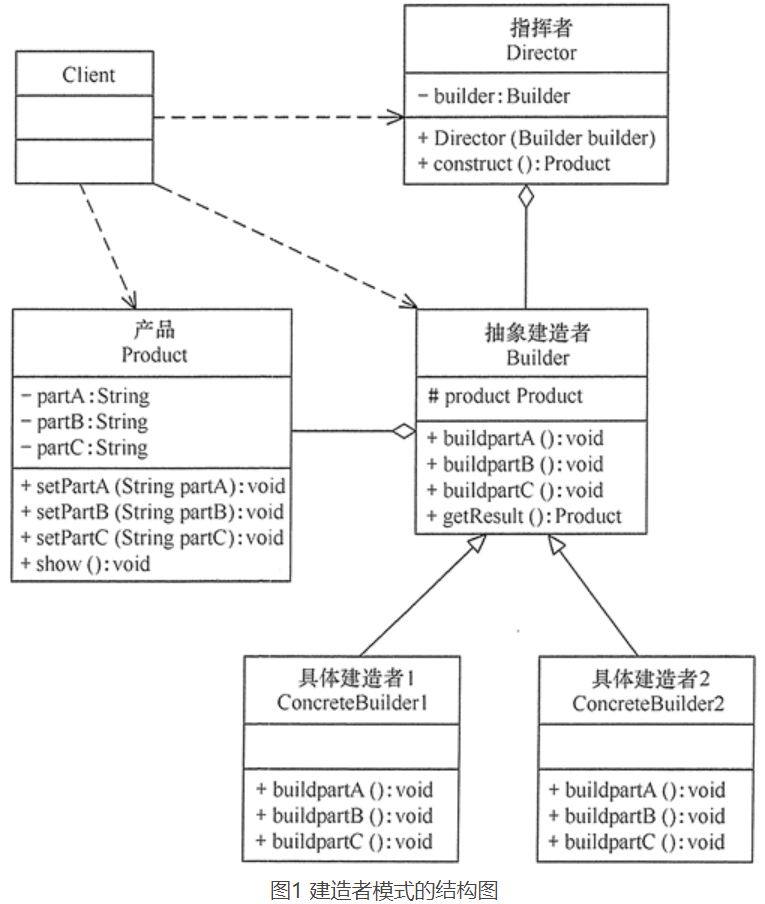
8.2.3、类图的模板代码实现
产品角色Product:包含多个组成部件的复杂对象
1 | class Product { |
抽象建造者Builder:包含创建产品各个子部件的抽象方法
1 | abstract class Builder { |
具体建造者ConcreteBuilder:实现了抽象建造者接口
1 | public class ConcreteBuilder extends Builder { |
指挥者Director:调用建造者中的方法完成复杂对象的创建
1 | class Director { |
客户类
1 | public class Client { |
8.3、应用举例
盖房项目需求
- 需要建房子:这一过程为打桩、砌墙、封顶
- 房子有各种各样的,比如普通房,高楼,别墅,各种房子的过程虽然一样,但是要求不要相同的.
- 请编写程序,完成需求.
8.3.1、传统方法
类图:
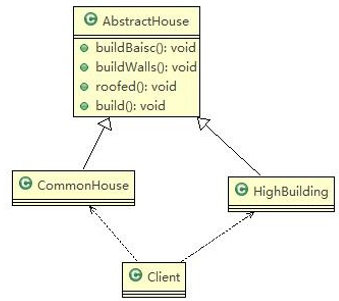
传统方式的问题分析
- 优点是比较好理解,简单易操作。
- 设计的程序结构,过于简单,没有设计缓存层对象,程序的扩展和维护不好. 也就是说,这种设计方案,把产品(**即:房子) 和 **创建产品的过程(即:建房子流程) 封装在一起,耦合性增强了。
- 解决方案:将产品和产品建造过程解耦 => 建造者模式
8.3.2、建造者模式解决盖房子问题
思路分析图解(类图)
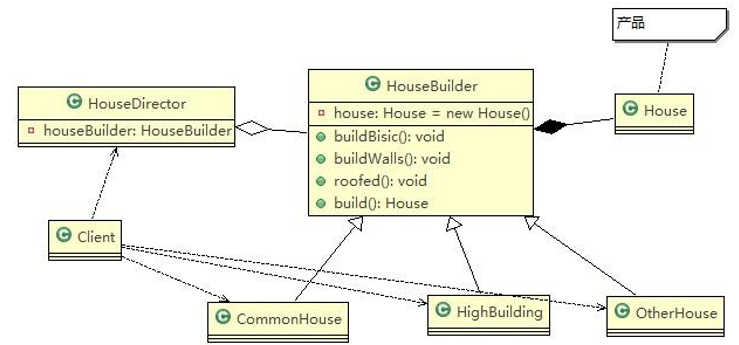
8.4、建造者模式在JDK中的应用与源码分析
java.lang.StringBuilder 中的建造者模式
代码说明:
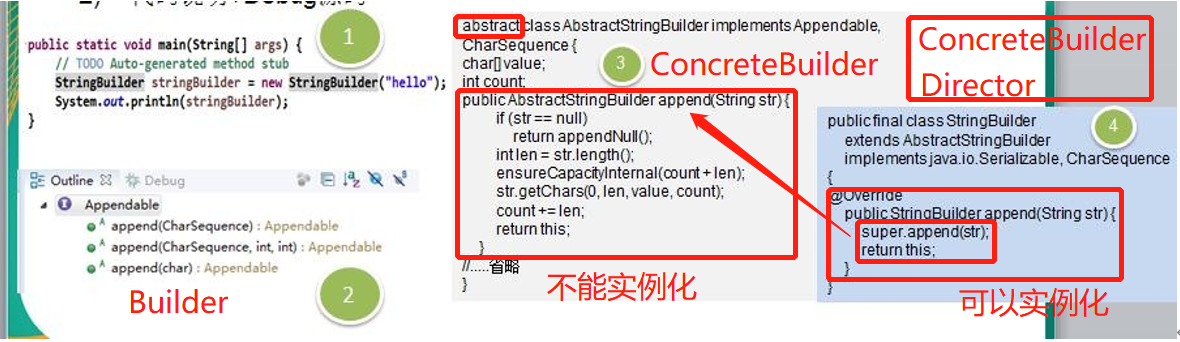
源码中建造者模式角色分析
- Appendable 接口定义了多个 append 方法(抽象方法), 即 Appendable 为抽象建造者(builder), 定义了抽象方法
- AbstractStringBuilder 实现了 Appendable 接口方法,这里的 AbstractStringBuilder 已经是建造者(ConcreteBuilder),只是不能实例化
- StringBuilder 即充当了指挥者角色(Director),同时充当了具体的建造者(ConcreteBuilder),建造方法的实现是由 AbstractStringBuilder 完成 , 而 StringBuilder 继承了 AbstractStringBuilder。直接使用了AbstractStringBuilder实现的方法。
8.5、建造者模式与工厂模式对区别
- 抽象工厂模式实现对产品家族的创建,一个产品家族是这样的一系列产品:具有不同分类维度的产品组合,采用抽象工厂模式不需要关心构建过程,只关心什么产品由什么工厂生产即可。
- 建造者模式则是要求按照指定的蓝图建造产品,它的主要目的是通过组装零配件而产生一个新产品。
主要区别:
- 建造者模式更加注重方法的调用顺序,工厂模式注重创建对象。
- 创建对象的力度不同,建造者模式创建复杂的对象,由各种复杂的部件组成,工厂模式创建出来的对象都一样
- 关注重点不一样,工厂模式只需要把对象创建出来就可以了,而建造者模式不仅要创建出对象,还要知道对象由哪些部件组成。
- 建造者模式根据建造过程中的顺序不一样,最终对象部件组成也不一样。
建造者模式唯一区别于工厂模式的是针对复杂对象的创建。也就是说,如果创建简单对象,通常都是使用工厂模式进行创建,而如果创建复杂对象,就可以考虑使用建造者模式。
当需要创建的产品具备复杂创建过程时,可以抽取出共性创建过程,然后交由具体实现类自定义创建流程,使得同样的创建行为可以生产出不同的产品,分离了创建与表示,使创建产品的灵活性大大增加。
8.6、建造者模式总结
主要优点如下:
- 封装性好,构建和表示分离。
- 扩展性好,各个具体的建造者相互独立,有利于系统的解耦。
- 客户端不必知道产品内部组成的细节,建造者可以对创建过程逐步细化,而不对其它模块产生任何影响,便于控制细节风险。
缺点如下:
- 产品的组成部分必须相同,这限制了其使用范围。
- 如果产品的内部变化复杂,如果产品内部发生变化,则建造者也要同步修改,后期维护成本较大。
模式的应用场景:
- 相同的方法,不同的执行顺序,产生不同的结果。
- 多个部件或零件,都可以装配到一个对象中,但是产生的结果又不相同。
- 产品类非常复杂,或者产品类中不同的调用顺序产生不同的作用。
- 初始化一个对象特别复杂,参数多,而且很多参数都具有默认值。
8.7、进阶阅读
如果您想了解建造者模式在实际项目中的应用,可猛击阅读以下文章。
8.8、相关的设计模式
Template Method 模式
- 在 Builder 模式中, Director 角色控制 Builder 角色。
- 在 Template Method 模式中 , 父类控制子类。
Composite 模式
有些情况下 Builder 模式生成的实例构成了 Composite 模式。
Abstract Factory 模式
Builder 模式和 Abstract Factory 模式都用千生成复杂的实例。
Facade 模式
在 Builder 模式中, Director 角色通过组合 Builder 角色中的复杂方法向外部提供可以简单生成 实例的接口 (API) (相当于示例程序中的 construct 方法)。
Facade 模式中的 Facade 角色则是通过组合内部模块向外部提供可以简单调用的接口 (API)。
8.9、建造者模式的注意事项和细节
- 客户端(使用程序)不必知道产品内部组成的细节,将产品本身与产品的创建过程解耦,使得相同的创建过程可以创建不同的产品对象
- 每一个具体建造者都相对独立,而与其他的具体建造者无关,因此可以很方便地替换具体建造者或增加新的具体建造者, 用户使用不同的具体建造者即可得到不同的产品对象
- 可以更加精细地控制产品的创建过程 。将复杂产品的创建步骤分解在不同的方法中,使得创建过程更加清晰, 也更方便使用程序来控制创建过程
- 增加新的具体建造者无须修改原有类库的代码,指挥者类针对抽象建造者类编程,系统扩展方便,符合“开闭原则”
- 建造者(Builder)模式在应用过程中可以根据需要改变,如果创建的产品种类只有一种,只需要一个具体建造者,这时可以省略掉抽象建造者,甚至可以省略掉指挥者角色。
- 建造者模式所创建的产品一般具有较多的共同点,其组成部分相似,如果产品之间的差异性很大,则不适合使用建造者模式,因此其使用范围受到一定的限制。
- 如果产品的内部变化复杂,可能会导致需要定义很多具体建造者类来实现这种变化,导致系统变得很庞大,因此在这种情况下,要考虑是否选择建造者模式.
9、适配器模式Adapter(结构型模式)
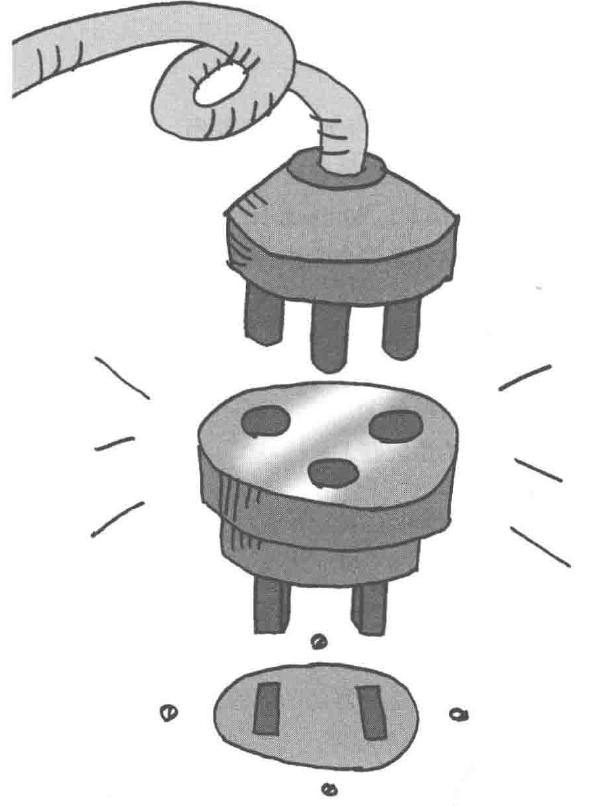
9.1、基本介绍
适配器模式(Adapter Pattern)将某个类的接口转换成客户端期望的另一个接口表示,主的目的是兼容性,让原本因接口不匹配不能一起工作的两个类可以协同工作。其别名为包装器(Wrapper)
适配器模式属于结构型模式
主要分为三类
- 类适配器模式
- 对象适配器模式
- 接口适配器模式
工作原理
适配器模式:将一个类的接口转换成另一种接口.让原本接口不兼容的类可以兼容
从用户的角度看不到被适配者,是解耦的
用户调用适配器转化出来的目标接口方法,适配器再调用被适配者的相关接口方法
用户收到反馈结果,感觉只是和目标接口交互,如图
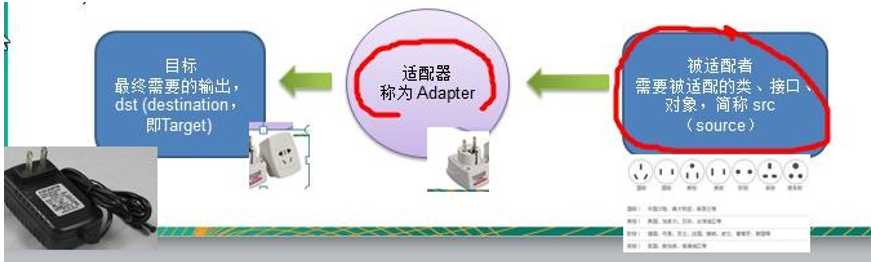
9.2、适配器模式原理结构图-uml类图
适配器模式(Adapter)包含以下主要角色。
- 目标(Target)接口:当前系统业务所期待的接口,它可以是抽象类或接口。
- 被适配者(Adaptee\src)类:它是被访问和适配的现存组件库中的组件接口。
- 适配器(Adapter)类:它是一个转换器,通过继承(类适配器)或引用(对象适配器)适配者的对象,把适配者接口转换成目标接口,让客户按目标接口的格式访问适配者。
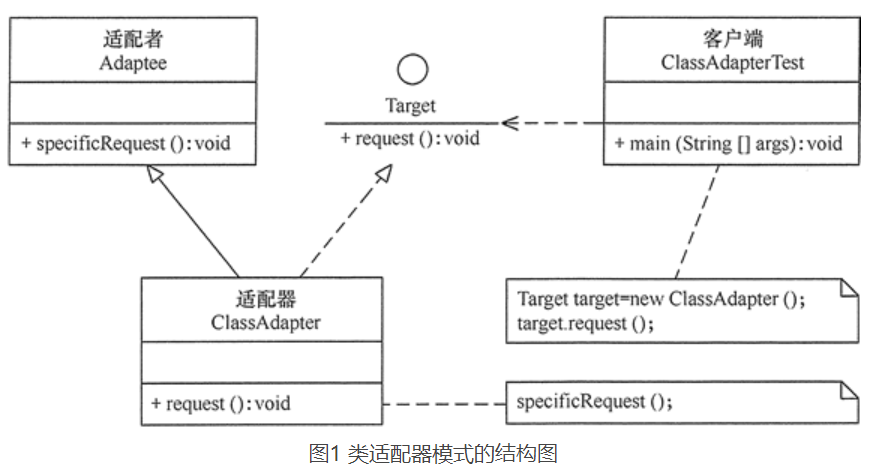
9.2.1、类适配器模式
结构图:
代码:
1 | package adapter; |
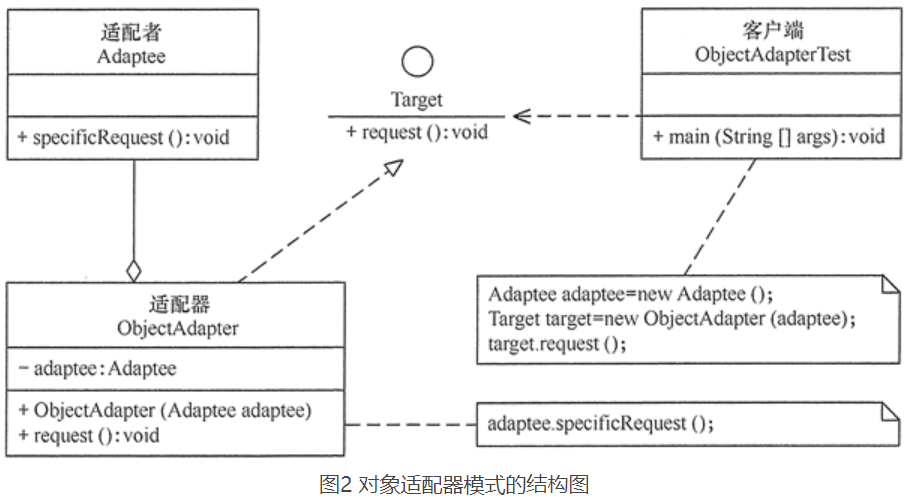
9.2.2、对象适配器模式
结构图:
代码实现:
1 | package adapter; |
9.2.3、接口适配器模式
结构图:
代码:
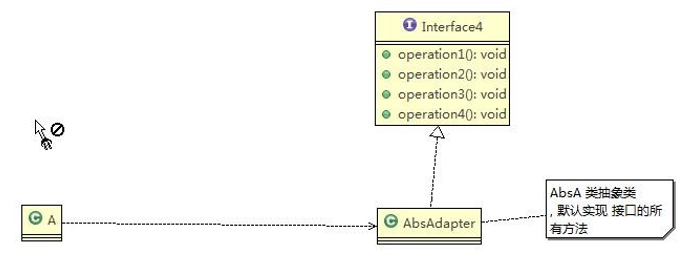
Interface4(适配者(Adaptee)类):
1 | public interface Interface4 { |
AbsAdapter(适配器(Adapter)类):
1 | //在AbsAdapter 我们将 Interface4 的方法进行默认实现 |
Client():只需要去覆盖我们 需要使用 接口方法
1 | public class Client { |
9.3、三种适配器模式的基本介绍
9.3.1、类适配器模式
实现步骤:Adapter 类,通过继承 src 类,实现 dst 类接口,完成 src->dst 的适配
类适配器模式注意事项和细节:
- 由于其继承了 src 类,所以它可以根据需求重写 src 类的方法,使得 Adapter 的灵活性增强了。
- Java 是单继承机制,所以类适配器需要继承 src 类这一点算是一个缺点, 因为这要求 dst 必须是接口,有一定局限性。
- 由于Adapter继承了src类,所以不可避免的会去重写src的方法。在一定程度上违反了里氏原则与合成复用原则。
- src 类的方法在 Adapter 中都会暴露出来,也增加了使用的成本。
9.3.2、对象适配器模式
对象适配器模式介绍
- 基本思路和类的适配器模式相同,只是将 Adapter 类作修改,不是继承 src 类,而是持有 src 类的实例(依赖),以解决兼容性的问题**。
- 实现步骤:持有 src 类,实现 dst 类接口,完成 src->dst 的适配
- 根据“合成复用原则”,在系统中尽量使用关联关系(聚合)来替代继承关系。
- 对象适配器模式是适配器模式常用的一种
对象适配器模式注意事项和细节
- 对象适配器和类适配器其实算是同一种思想,只不过实现方式不同。
- 根据合成复用原则,使用聚合替代继承, 所以它解决了类适配器必须继承 src 的局限性问题,也不再要求 dst必须是接口。
- 使用成本更低,更灵活。
9.3.3、接口适配器模式
接口适配器模式介绍
- 一些书籍称为:适配器模式(Default Adapter Pattern)**或缺省适配器模式**。
- 核心思路:当不需要全部实现接口提供的方法时,可先设计一个抽象类实现接口,并为该接口中每个方法提供一个默认实现(空方法),那么该抽象类的子类可有选择地覆盖父类的某些方法来实现需求
- 适用于一个接口不想使用其所有的方法的情况。
接口适配器模式注意事项和细节
- 在JDK8开始,接口就可以默认实现了,所以这个可以不要抽象类,全部弄个默认实现就好。
- 然后定义接口的实现类可有选择地覆盖接口的默认方法来实现需求
9.4、应用举例
需求:
以生活中充电器的例子来讲解适配器,充电器本身相当于 Adapter,220V 交流电相当于 src (即被适配者),我们的目 dst(即 目标)是 5V 直流电。
9.4.1、使用类适配器模式实现
思路分析(类图)
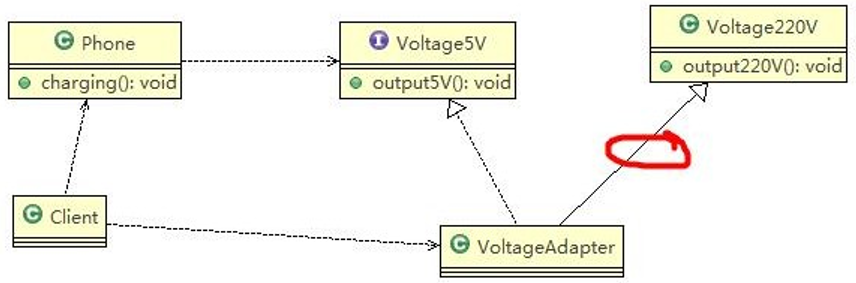
代码实现
Voltage220V:被适配者(Adaptee\src)类
1 | //被适配的类 |
IVoltage5V:目标(Target)接口
1 | //适配接口 |
VoltageAdapter:适配器(Adapter)类
1 | //适配器类 |
phone\Client:客户端进行使用
phone:
1 | public class Phone { |
Client:
1 | public class Client { |
9.4.2、使用对象适配器模式实现
Voltage220V:被适配者(Adaptee\src)类:同上
IVoltage5V:目标(Target)接口:同上
VoltageAdapter:适配器(Adapter)类
1 | //适配器类 |
phone\Client:客户端进行使用
phone:同上
Client:
1 | public class Client { |
9.4.3、接口适配器模式应用实例
Android 中的属性动画 ValueAnimator 类可以通过 addListener(AnimatorListener listener)方法添加监听器, 那么常规写法如下:
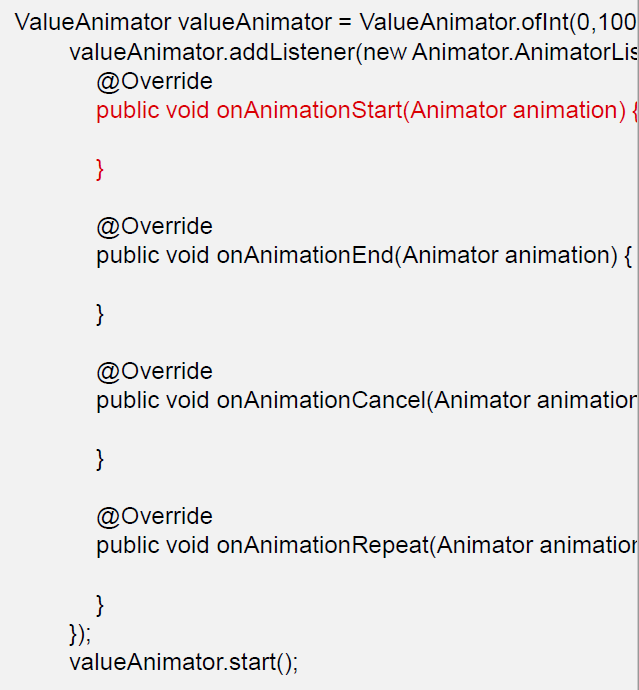
有时候我们不想实现 Animator.AnimatorListener 接口的全部方法,我们只想监听 onAnimationStart,我们会如下写

AnimatorListenerAdapter 类,就是一个接口适配器,代码如下图:它空实现了Animator.AnimatorListener 类(src)的所有方法
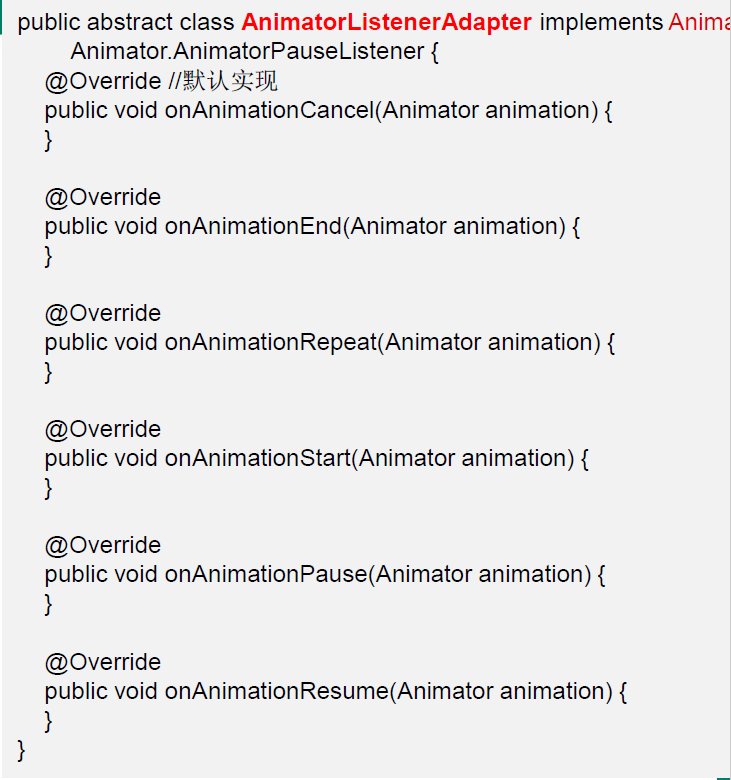
AnimatorListener 是一个接口

程序里的匿名内部类就是 Listener 具体实现类

9.5、适配器模式在Spring MVC的应用与源码分析
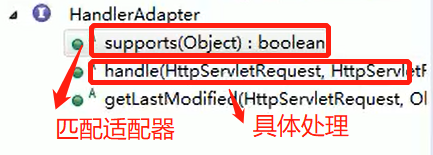
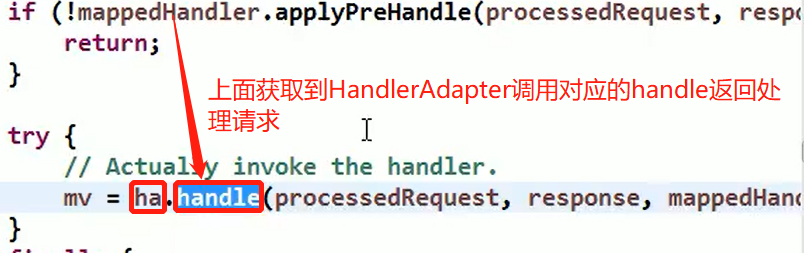
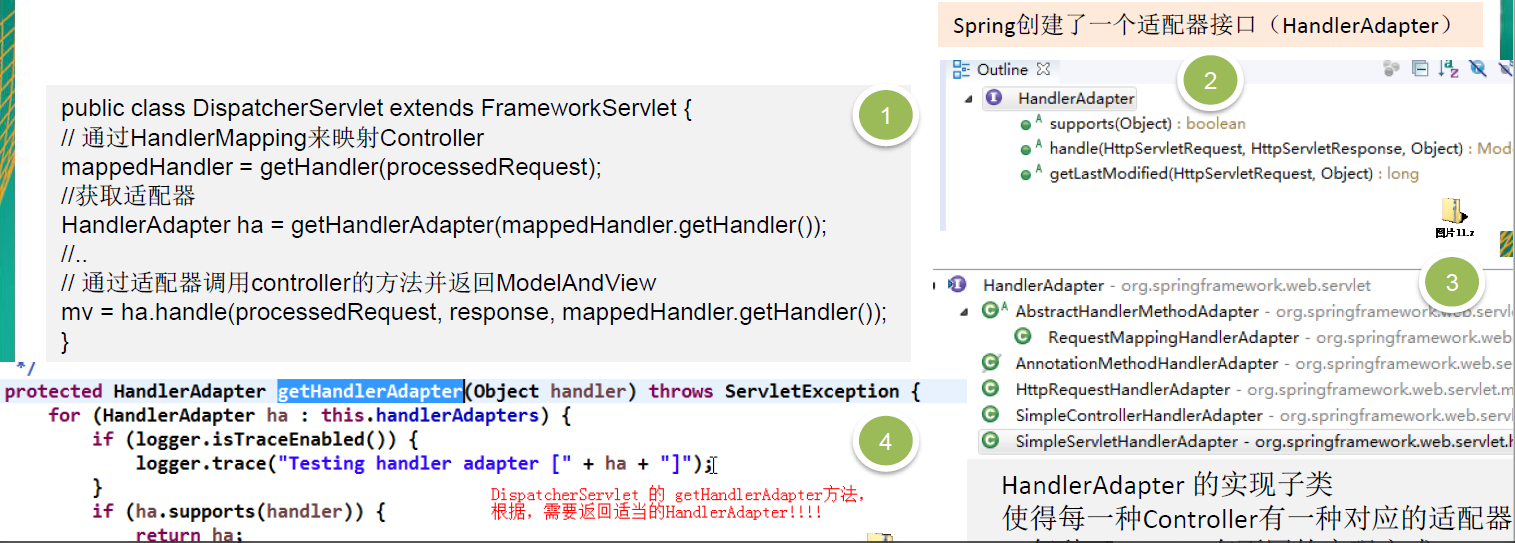
SpringMvc 中的 HandlerAdapter, 就使用了适配器模式
SpringMVC 处理请求的流程回顾
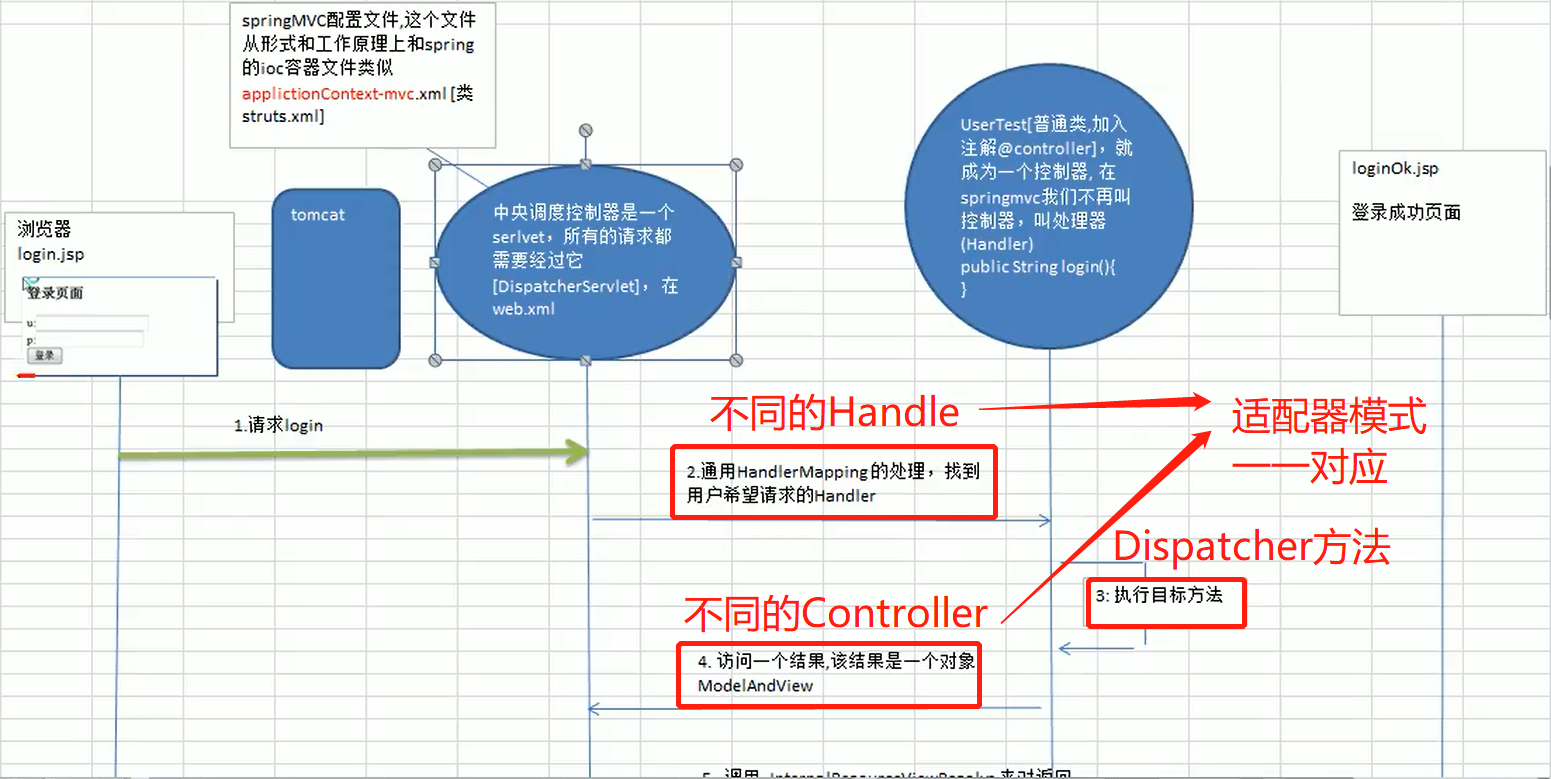

使用 HandlerAdapter 的原因分析:
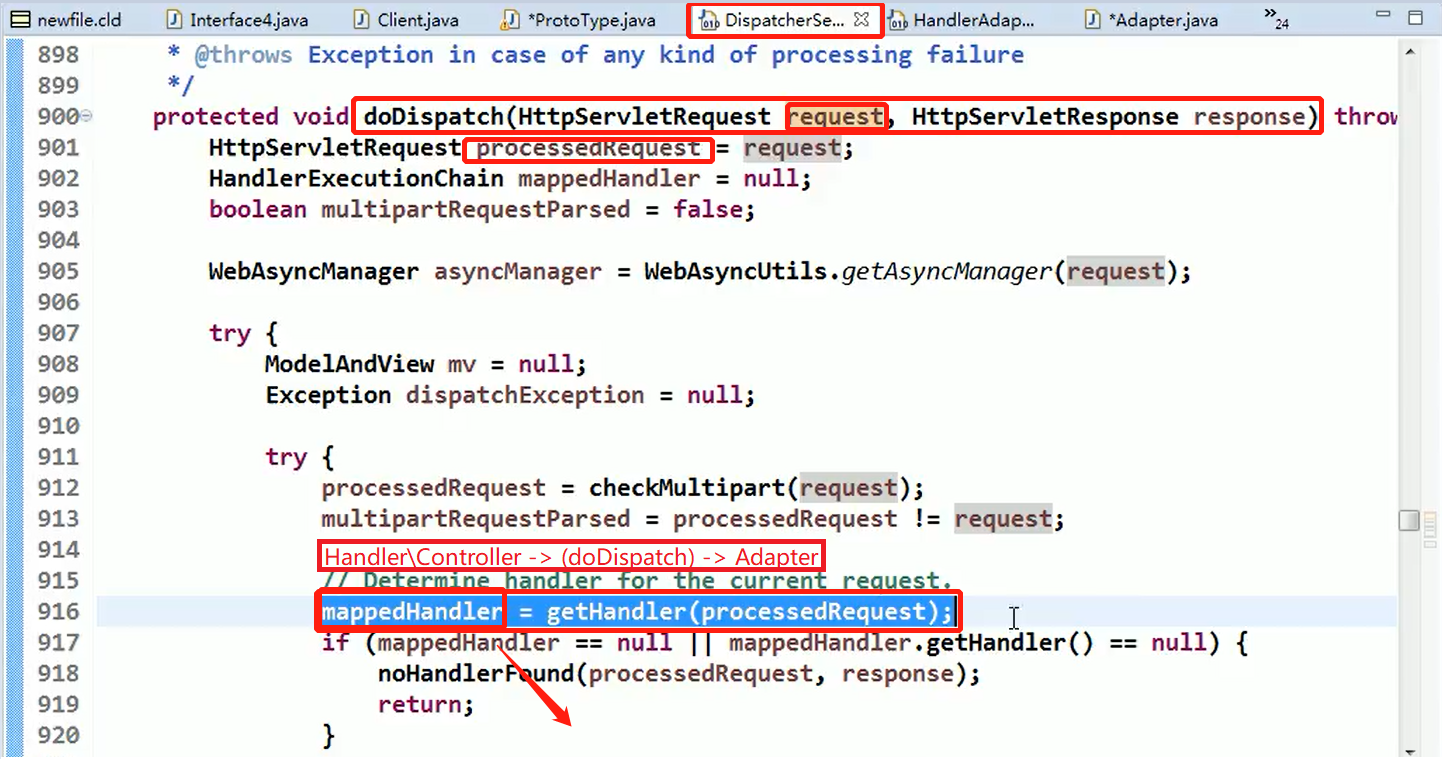
可以看到处理器的类型不同,有多重实现方式,那么调用方式就不是确定的,如果需要直接调用 Controller 方法,需要调用的时候就得不断是使用 if else 来进行判断是哪一种子类然后执行。那么如果后面要扩展 Controller, 就得修改原来的代码,这样违背了 OCP 原则。
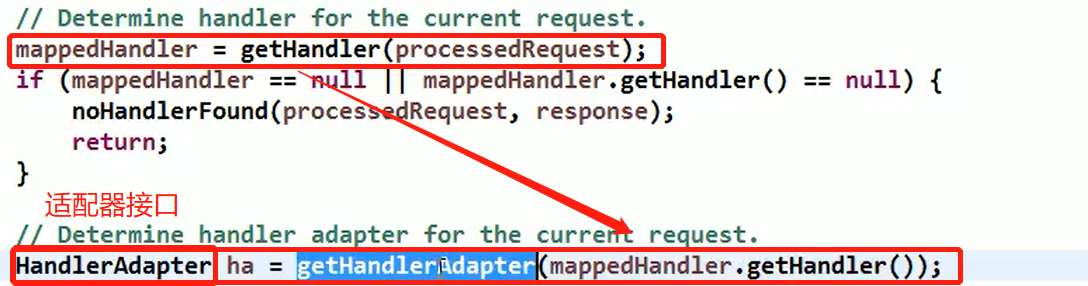
代码分析+Debug 源码

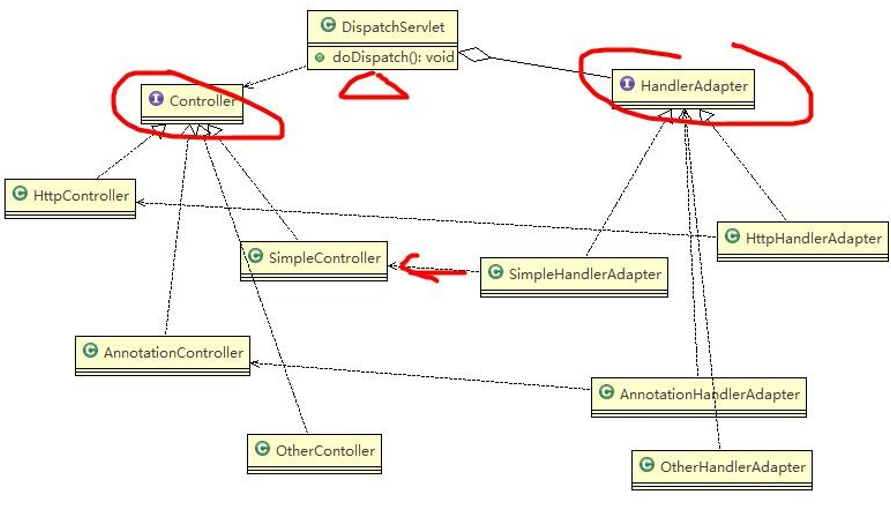
相关类图: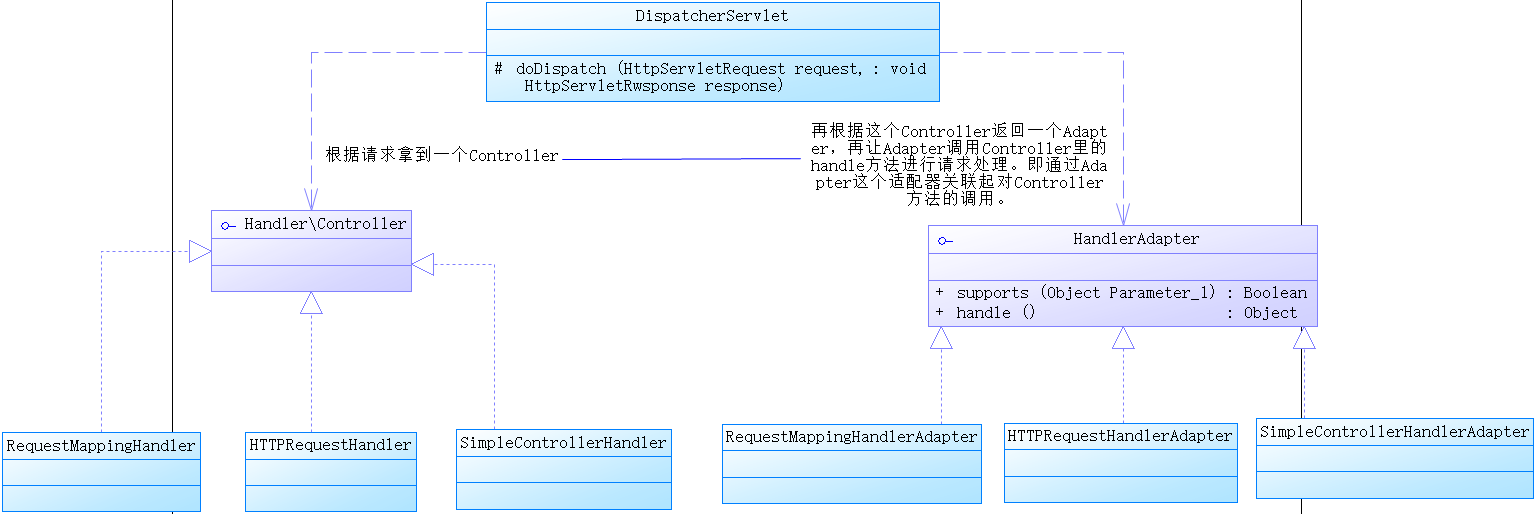
动手写 SpringMVC 通过适配器设计模式获取到对应的 Controller 的源码:
相关类图:
实现代码:
HandlerAdapter:一个Adapter接口
1 | //定义一个Adapter接口 |
Controller:
1 | //多种Controller实现 |
DispatchServlet:
1 | import java.util.ArrayList; |
相关补充:
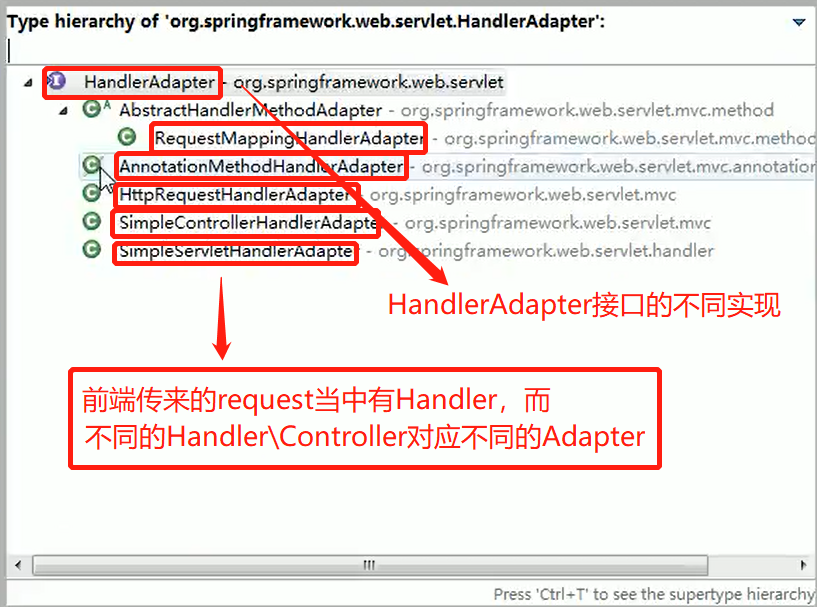
- Spring定义了一个适配接口,使得每一种Controller有一种对应的适配器实现类
- 适配器代替Controller执行相应的方法
- 扩展Controller时(即添加一个OtherController),只需要增加一个适配器类就完成了SpringMVC的扩展了(满足OCP原则)
9.6、适配器模式总结
主要优点如下:
- 客户端通过适配器可以透明地调用目标接口。
- 复用了现存的类,程序员不需要修改原有代码而重用现有的适配者类。
- 将目标类和适配者类解耦,解决了目标类和适配者类接口不一致的问题。
- 在很多业务场景中符合开闭原则。
其缺点是:
- 适配器编写过程需要结合业务场景全面考虑,可能会增加系统的复杂性。
- 增加代码阅读难度,降低代码可读性,过多使用适配器会使系统代码变得凌乱。
模式的应用场景:
- 以前开发的系统存在满足新系统功能需求的类,但其接口同新系统的接口不一致。
- 使用第三方提供的组件,但组件接口定义和自己要求的接口定义不同。
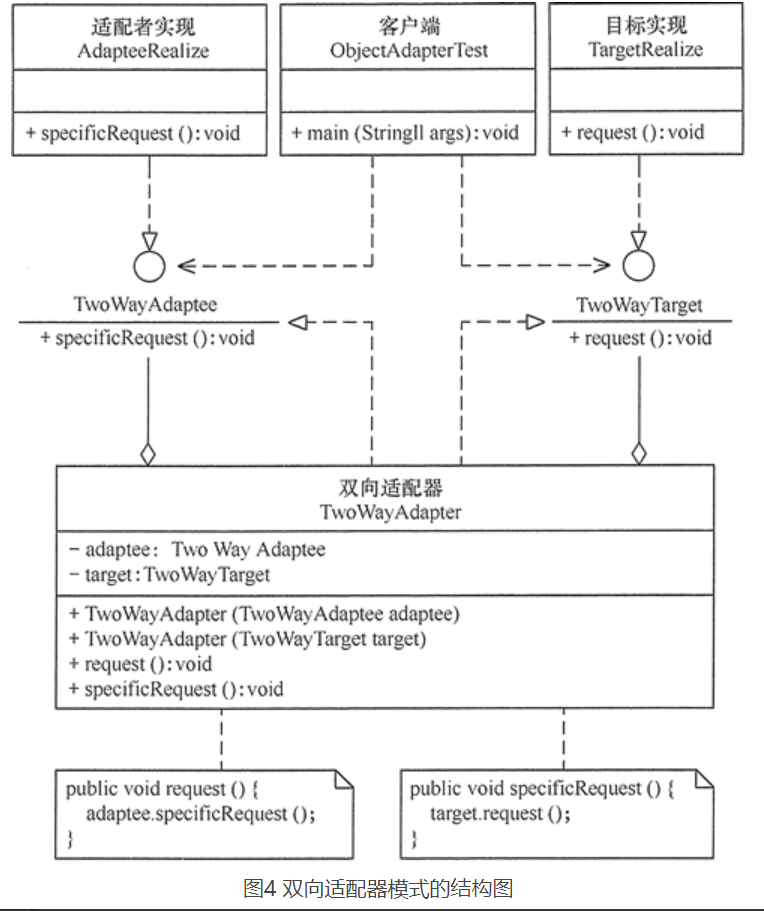
9.7、适配器模式的扩展
适配器模式(Adapter)可扩展为双向适配器模式,双向适配器类既可以把适配者接口转换成目标接口,也可以把目标接口转换成适配者接口,其结构图如图所示。
相关代码:
1 | package adapter; |
9.8、进阶阅读
如果您想了解适配器模式在实际中的应用,可猛击阅读以下文章。
9.9、相关的设计模式
Bridge模式
Adapter模式用千连接接口(API)不同的类,而Bridge模式则用于连接类的功能层次结构与实现层次结构。
Decorator 模式
Adapter 模式用于填补不同接口 (API) 之间的缝隙,而 Decorator 模式则是在不改变接口 (API)的前提下增加功能。
9.10、适配器模式的注意事项和细节
- 三种命名方式,是根据 src 是以怎样的形式给到 Adapter(在 Adapter 里的形式)来命名的。
- 类适配器:以类给到,在 Adapter 里,就是将 src 当做类,继承
- 对象适配器:以对象给到,在 Adapter 里,将 src 作为一个对象,持有接口适配器:以接口给到,在 Adapter 里,将 src 作为一个接口,实现
- Adapter 模式最大的作用还是将原本不兼容的接口融合在一起工作。
- 实际开发中,实现起来不拘泥于我们讲解的三种经典形式
10、桥接模式Bridge(结构型模式)
10.1、基本介绍
- 桥接模式(Bridge 模式)是指:将实现与抽象放在两个不同的类层次中,使两个层次可以独立改变。
- 是一种结构型设计模式
- Bridge 模式基于类的最小设计原则,通过使用封装、聚合及继承等行为让不同的类承担不同的职责。它的主要特点是把抽象(Abstraction)与行为实现(Implementation)分离开来,从而可以保持各部分的独立性以及应对他们的功能扩展
- 它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦。
- 将抽象与实现分离,使它们可以独立变化。它是用组合关系代替继承关系来实现,从而降低了抽象和实现这两个可变维度的耦合度。
10.2、桥接模式原结构图-uml类图
可以将抽象化部分与实现化部分分开,取消二者的继承关系,改用组合关系。
10.2.1、 模式的结构
桥接(Bridge)模式包含以下主要角色。
- 抽象化(Abstraction)角色:定义抽象类,并包含一个对实现化对象的引用。
- 扩展抽象化(Refined Abstraction)角色:是抽象化角色的子类,实现父类中的业务方法,并通过组合关系调用实现化角色中的业务方法。
- 实现化(Implementor)角色:定义实现化角色的接口,供扩展抽象化角色调用。
- 具体实现化(Concrete Implementor)角色:给出实现化角色接口的具体实现。
相关类图:
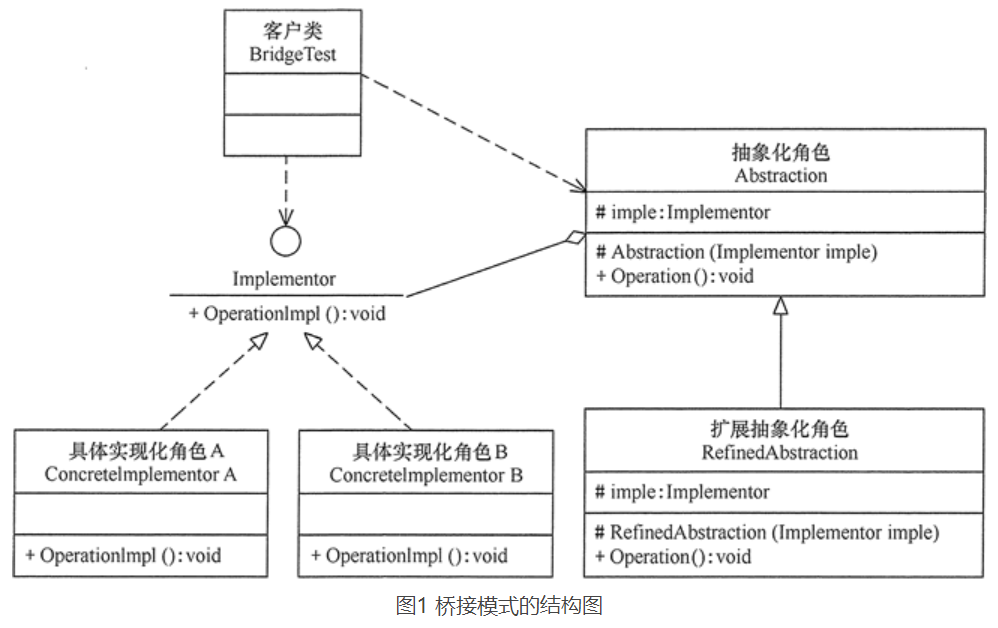
代码实现:
1 | package bridge; |
10.3、应用举例
手机操作问题:
现在对不同手机类型的不同品牌实现操作编程(比如:开机、关机、上网,打电话等),如图:
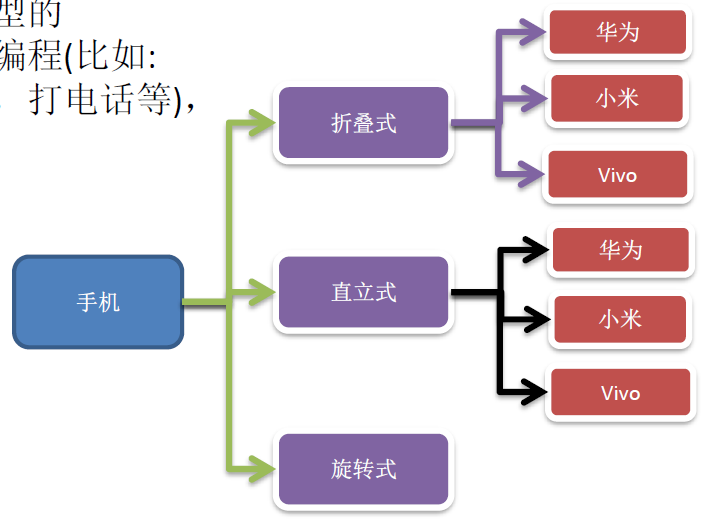
10.3.1、使用传统方式
实现类图:
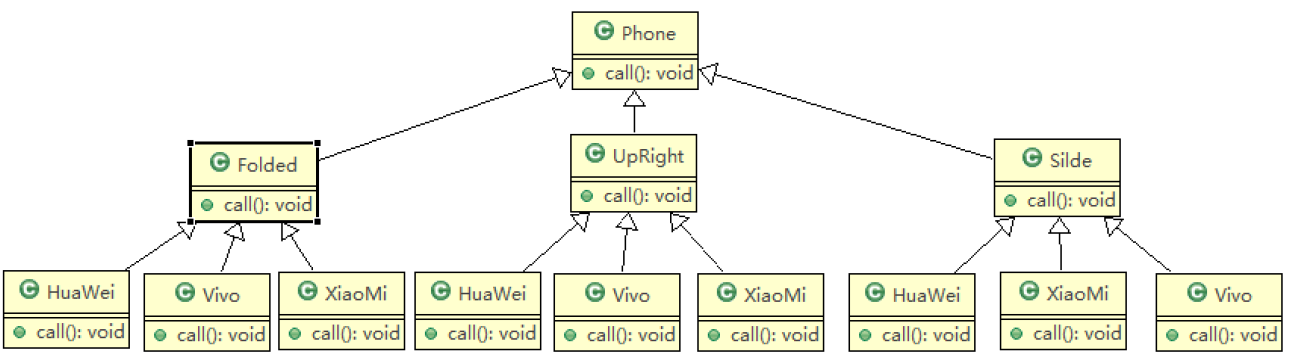
传统方案解决手机操作问题分析
- 扩展性问题(类爆炸),如果我们再增加手机的样式(旋转式),就需要增加各个品牌手机的类,同样如果我们增加一个手机品牌,也要在各个手机样式类下增加。
- 违反了单一职责原则,当我们增加手机样式时,要同时增加所有品牌的手机,这样增加了代码维护成本.
- 解决方案-使用桥接模式
10.3.2、使用桥接模式
对应的类图
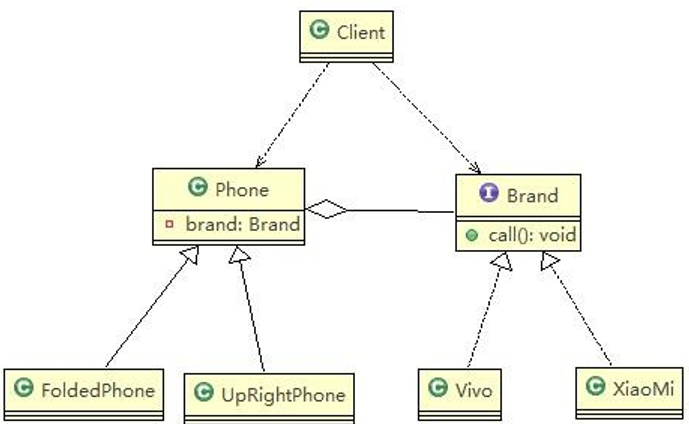
对于类图的相关解析:
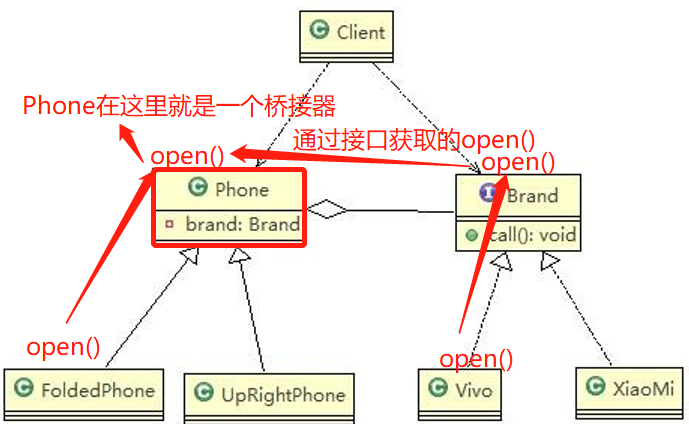
- 在FoldedPhone调用的open()方法其实调用了其父类Phone的open()方法
- 然而在Phone当中是通过聚合了Brand接口拿到了open()方法
- 而Vivo类才是真正实现Brank接口open()方法的实现类
- 所以FoldedPhone调用的open()方法最终是调用了Vivo的open()方法
- 而Phone在这其中起到了一个桥接的作用
代码实现:
Brand:实现化(Implementor)
1 | //接口 |
Phone:抽象化(Abstraction)
1 | public abstract class Phone { |
FoldedPhone:扩展抽象化(Refined Abstraction)(UpRightPhone类似)
1 | //折叠式手机类,继承 抽象类 Phone |
Vivo:具体实现化(Concrete Implementor)(XiaoMi类似)
1 | public class Vivo implements Brand { |
Client:调用者
1 | public class Client { |
10.4、桥接模式在JDBC的应用与源码分析
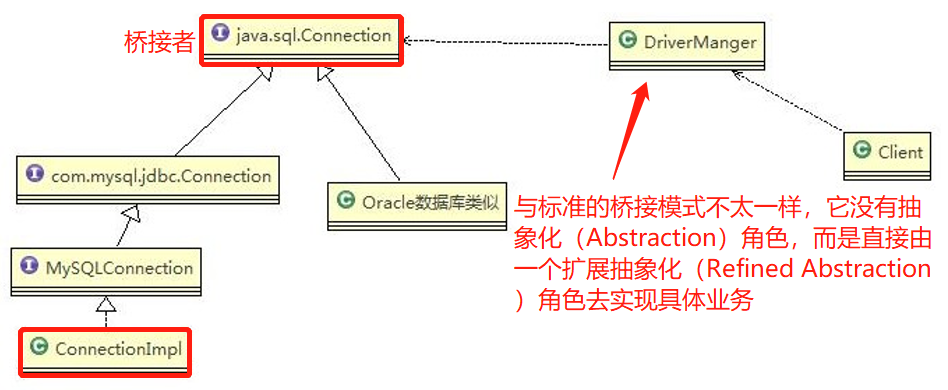
JDBC的 Driver 接口,如果从桥接模式来看,Driver 就是一个接口,下面可以有 MySQL 的 Driver,Oracle 的Driver,这些就可以当做实现接口类
代码分析+Debug 源码
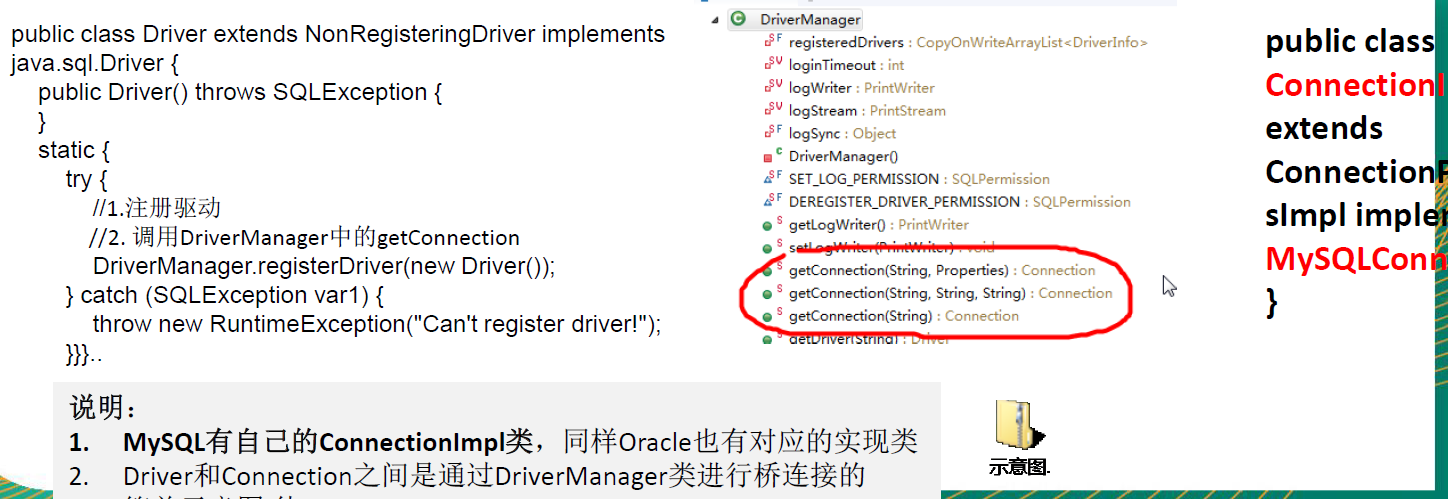
相关类图:
10.5、桥接模式总结
桥接模式遵循了里氏替换原则和依赖倒置原则,最终实现了开闭原则,对修改关闭,对扩展开放。这里将桥接模式的优缺点总结如下。
优点:
- 抽象与实现分离,扩展能力强
- 符合开闭原则
- 符合合成复用原则
- 其实现细节对客户透明
缺点:
由于聚合关系建立在抽象层,要求开发者针对抽象化进行设计与编程,能正确地识别出系统中两个独立变化的维度,这增加了系统的理解与设计难度。
桥接模式的应用场景:
当一个类内部具备两种或多种变化维度时,使用桥接模式可以解耦这些变化的维度,使高层代码架构稳定。
桥接模式通常适用于以下场景:
- 当一个类存在两个独立变化的维度,且这两个维度都需要进行扩展时。
- 当一个系统不希望使用继承或因为多层次继承导致系统类的个数急剧增加时。
- 当一个系统需要在构件的抽象化角色和具体化角色之间增加更多的灵活性时。
桥接模式的一个常见使用场景就是替换继承。我们知道,继承拥有很多优点,比如,抽象、封装、多态等,父类封装共性,子类实现特性。继承可以很好的实现代码复用(封装)的功能,但这也是继承的一大缺点。因为父类拥有的方法,子类也会继承得到,无论子类需不需要,这说明继承具备强侵入性(父类代码侵入子类),同时会导致子类臃肿。因此,在设计模式中,有一个原则为优先使用组合/聚合,而不是继承(合成复用原则)。
在实际系统开发时常见的应用场景:
JDBC 驱动程序
银行转账系统转账分类:
网上转账,柜台转账,AMT 转账 (抽象层)
转账用户类型:普通用户,银卡用户,金卡用户.. (实现层)
消息管理
消息类型:即时消息,延时消息 (抽象层)
消息分类:手机短信,邮件消息,QQ 消息… (实现层)

很多时候,我们分不清该使用继承还是组合/聚合或其他方式等,其实可以从现实语义进行思考。因为软件最终还是提供给现实生活中的人使用的,是服务于人类社会的,软件是具备现实场景的。当我们从纯代码角度无法看清问题时,现实角度可能会提供更加开阔的思路。
10.6、桥接模式的扩展
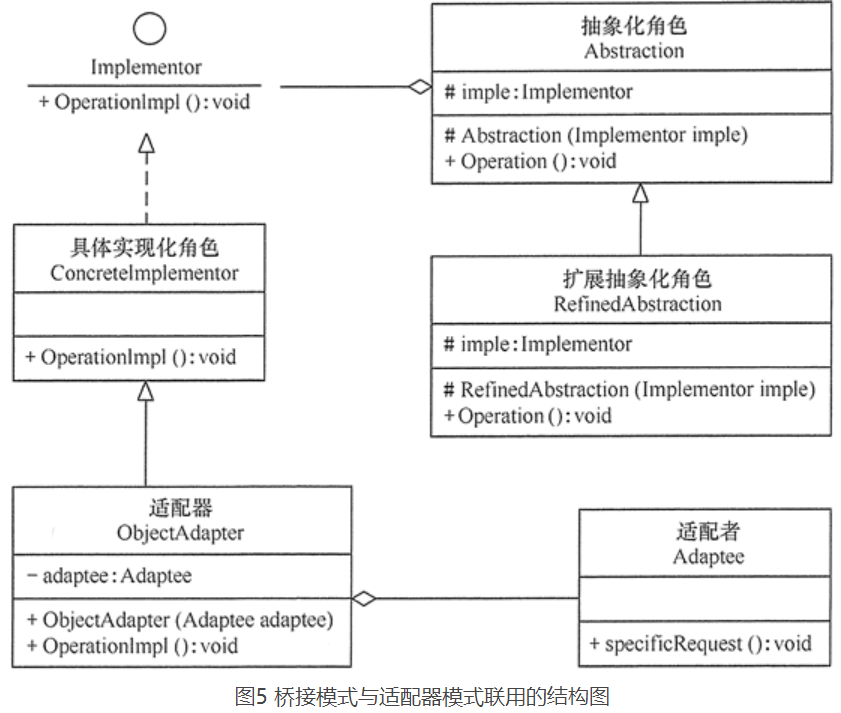
在软件开发中,有时桥接(Bridge)模式可与适配器模式联合使用。当桥接(Bridge)模式的实现化角色的接口与现有类的接口不一致时,可以在二者中间定义一个适配器将二者连接起来,其具体结构图如图所示。
10.7、进阶阅读
如果您想深入了解桥接模式,可猛击阅读以下文章。
10.8、相关设计模式
Template Method 模式
在 Template Method 模式中使用了 "类的实现层次结构"。父类调用抽象方法, 而子类实现抽象方法。
Abstract Factory 模式
为了能够根据需求设计出良好的 ConcreteImplementor 角色, 有时我们会使用Abstract Factory 模式。
Adapter 模式
使用 Bridge 模式可以达到类的功能层次结构与类的实现层次结构分离的目的, 并在此基础上使这些层次结构结合起来。
而使用Adapter 模式则可以结合那些功能上相似但是接口 (API) 不同的类。
10.9、桥接模式的注意事项和细节
- 实现了抽象和实现部分的分离,从而极大的提升了系统的灵活性,让抽象部分和实现部分独立开来,这有助于系统进行分层设计,从而产生更好的结构化系统。
- 对于系统的高层部分,只需要知道抽象部分和实现部分的接口就可以了,其它的部分由具体业务来完成。
- 桥接模式替代多层继承方案,可以减少子类的个数,降低系统的管理和维护成本
- 桥接模式的引入增加了系统的理解和设计难度,由于聚合关联关系建立在抽象层,要求开发者**针对抽象进行设计和编程桥接模式要求正确识别出系统中两个独立变化的维度(抽象、和实现)**,因此其使用范围有一定的局限性。
11、装饰者模式Decorator(结构型模式)
11.1、基本介绍
- 装饰者模式:在不改变现有对象结构的情况下,动态的将新功能附加到对象上。在对象功能扩展方面,它比继承更有弹性,装饰者模式也**体现了开闭原则(ocp)**。
- 它属于对象结构型模式
11.2、装饰者模式原理结构图-uml类图
通常情况下,扩展一个类的功能会使用继承方式来实现。但继承具有静态特征,耦合度高,并且随着扩展功能的增多,子类会很膨胀(类爆炸)。如果使用组合关系来创建一个包装对象(即装饰对象)来包裹真实对象,并在保持真实对象的类结构不变的前提下,为其提供额外的功能,这就是装饰器模式的目标。装饰者模式就像打包一个快递。
下面来分析其基本结构和实现方法。
11.2.1、模式的结构
装饰器模式主要包含以下角色:
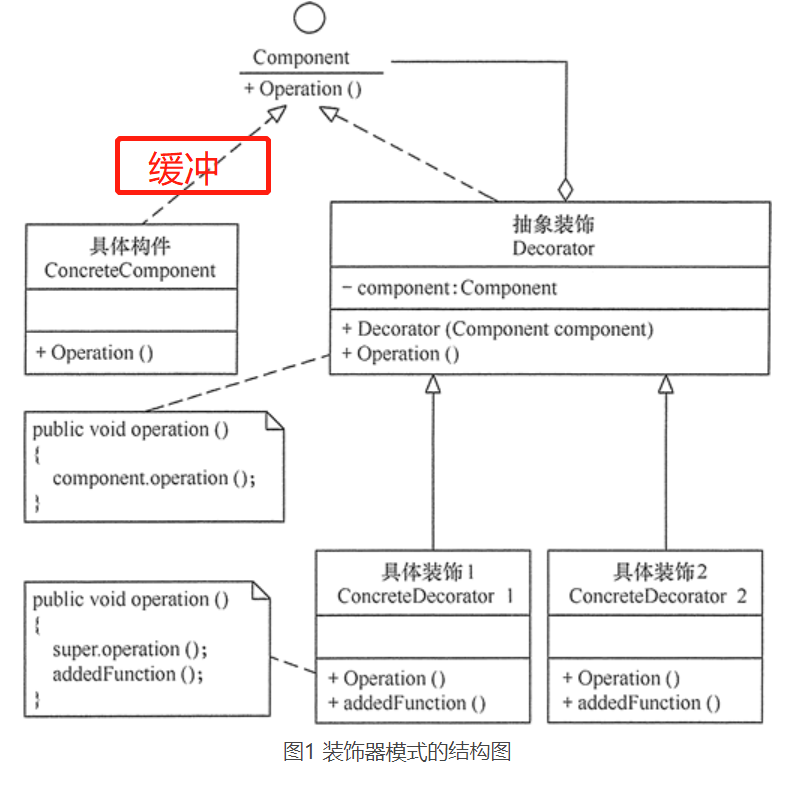
- 抽象构件(Component)角色:定义一个抽象接口以规范准备接收附加责任的对象。(被装饰者)
- 具体构件(ConcreteComponent)角色:实现抽象构件,通过装饰角色为其添加一些职责。
- 抽象装饰(Decorator)角色:继承抽象构件,并包含具体构件的实例(组合),可以通过其子类扩展具体构件的功能。(装饰者)
- 具体装饰(ConcreteDecorator)角色:实现抽象装饰的相关方法,并给具体构件对象添加附加的责任。
- (可选)缓冲角色:如果有太多的具体构建角色,可以在具体构件(ConcreteComponent)角色与抽象构件(Component)角色建立一个缓冲角色。抽取具体构件(ConcreteComponent)角色的公共部分,对其进行进一步的抽象。
装饰器模式的结构图:
11.2.2、实现代码
1 | package decorator; |
11.3、应用举例
星巴克咖啡订单项目(咖啡馆):
- 咖啡种类/单品咖啡:Espresso(意大利浓咖啡)、ShortBlack、LongBlack(美式咖啡)、Decaf(无因咖啡)
- 调料:Milk、Soy(豆浆)、Chocolate
- 要求在扩展新的咖啡种类时,具有良好的扩展性、改动方便、维护方便
- 使用 OO 的来计算不同种类咖啡的费用: 客户可以点单品咖啡,也可以单品咖啡+调料组合。
11.3.1、使用方案1(较差)解决需求
思路分析(类图):
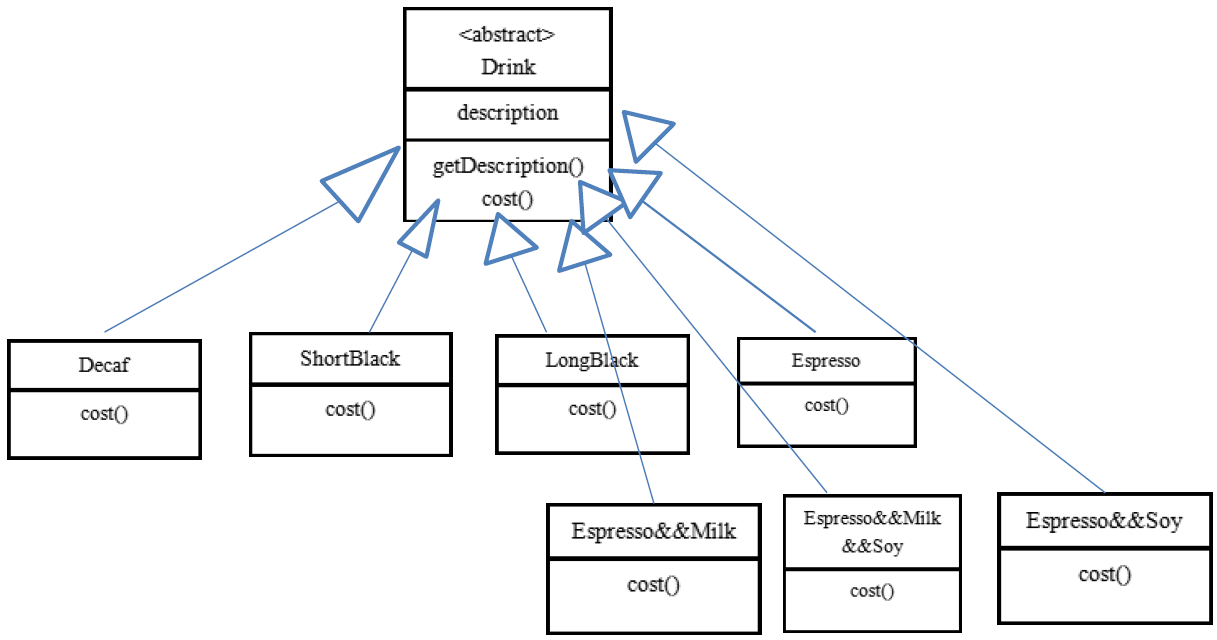
方案 1-解决星巴克咖啡订单实现与问题分析
- Drink 是一个抽象类,表示饮料
- des 就是对咖啡的描述, 比如咖啡的名字
- cost() 方法就是计算费用,Drink 类中做成一个抽象方法.
- Decaf 就是单品咖啡, 继承 Drink, 并实现 cost
- Espress && Milk 就是单品咖啡+调料, 这个组合很多
- 问题:这样设计,会有很多类,当我们增加一个单品咖啡,或者一个新的调料,类的数量就会倍增,就会出现类爆炸
11.3.2、使用方案2(较好)解决需求
思路分析(类图):
前面分析到方案 1 因为咖啡单品+调料组合会造成类的倍增,因此可以做改进:
- 将调料内置到 Drink 类,这样就不会造成类数量过多。从而提高项目的维护性
- 说明: milk,soy,chocolate 可以设计为 Boolean,表示是否要添加相应的调料.
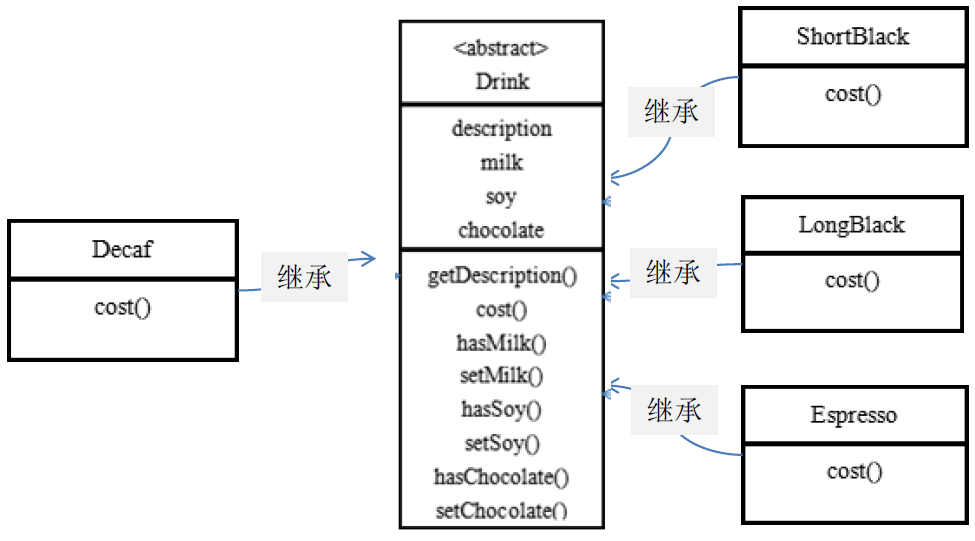
方案 2-解决星巴克咖啡订单问题分析
- 方案 2 将调料放在了Drink当中,把它作为成员变量。它可以控制类的数量,不至于造成很多的类。
- 在增加或者删除调料种类时,代码的维护量很大
- 考虑到用户可以添加多份调料时,可以将hasMilk返回一个对应int
- 考虑使用 装饰者 模式
11.3.3、使用装饰者模式解决需求
说明:
- Drink 类就是前面说的抽象类,Component
- ShortBlack 就单品咖啡
- Decorator 是一个装饰类,含有一个被装饰的对象(Drink obj)
- Decorator 的cost 方法进行一个费用的叠加计算,递归的计算价格
- Coffee类就是具体构件(ConcreteComponent)角色与抽象构件(Component)角色之间的缓冲角色,将ShortBlack等等各种咖啡抽象成一个Coffee类
类图:
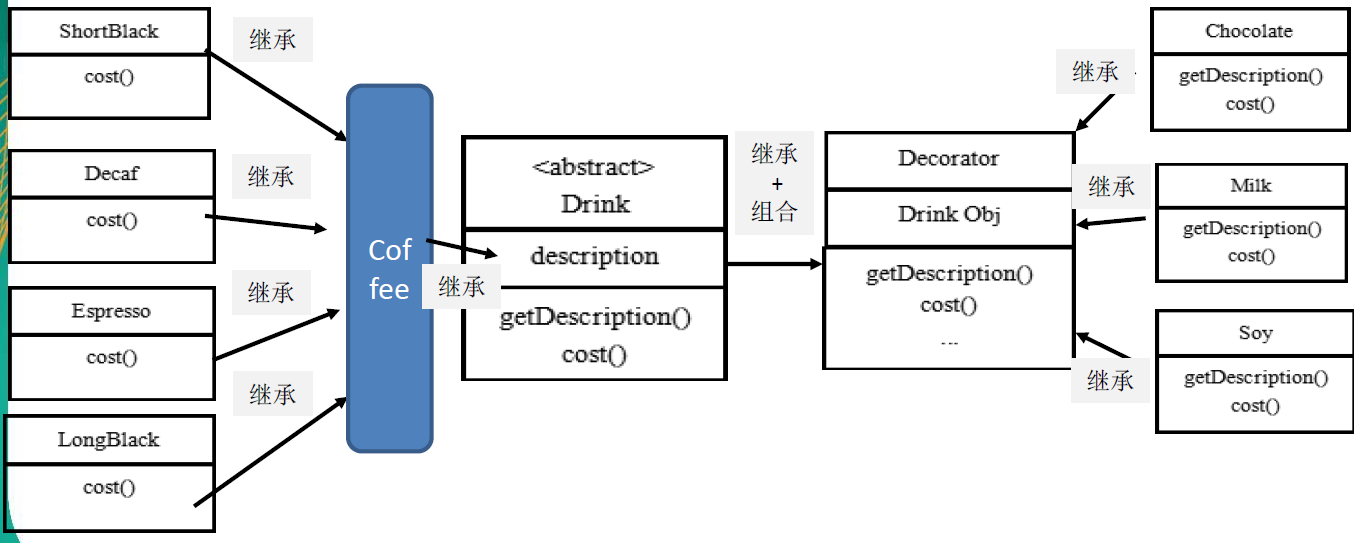
装饰者模式下的订单:2 份巧克力+一份牛奶的 LongBlack的CoffeeBar(Client)实现思路:
- Milk包含了LongBlack
- 一份Chocolate包含了(Milk+LongBlack)
- 一份Chocolate包含了(Chocolate+Milk+LongBlack)
- 这样不管是什么形式的单品咖啡+调料组合,通过递归方式可以方便的组合和维护。
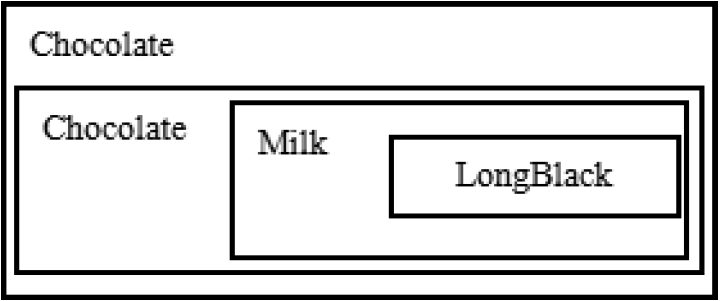
实现代码:
Drink:饮料抽象类。抽象构件(Component)角色
1 | public abstract class Drink { |
Coffee:咖啡类。(可选)缓冲角色
1 | public class Coffee extends Drink { |
ShortBlack:具体咖啡对象。具体构件(ConcreteComponent)角色(其他具体咖啡类类似)
1 | public class ShortBlack extends Coffee{ |
Decorator:调料装饰者。抽象装饰(Decorator)角色
1 | public class Decorator extends Drink { |
Milk:牛奶。具体装饰(ConcreteDecorator)角色
1 | public class Milk extends Decorator { |
CoffeeBar:星巴克。调用2 份巧克力+一份牛奶的 LongBlack
1 | public class CoffeeBar { |
11.4、装饰者模式在IO结构的应用与源码
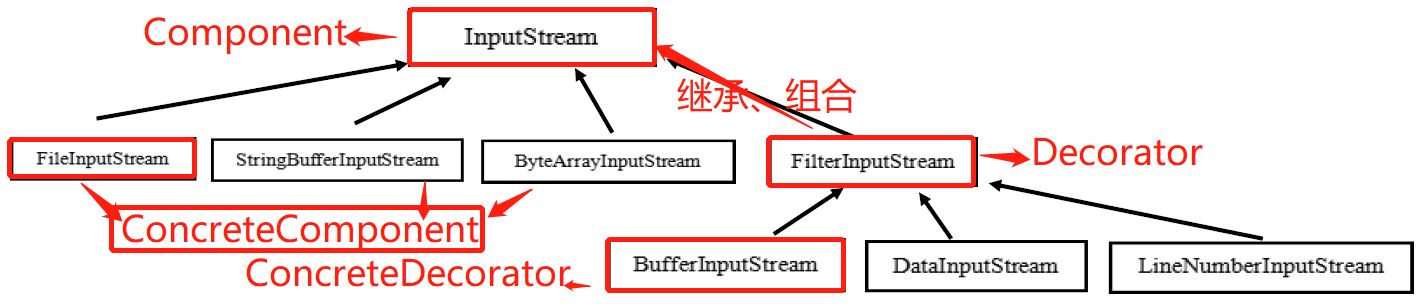
Java 的 IO 结构,FilterInputStream 就是一个装饰者
相关类图:
源码:
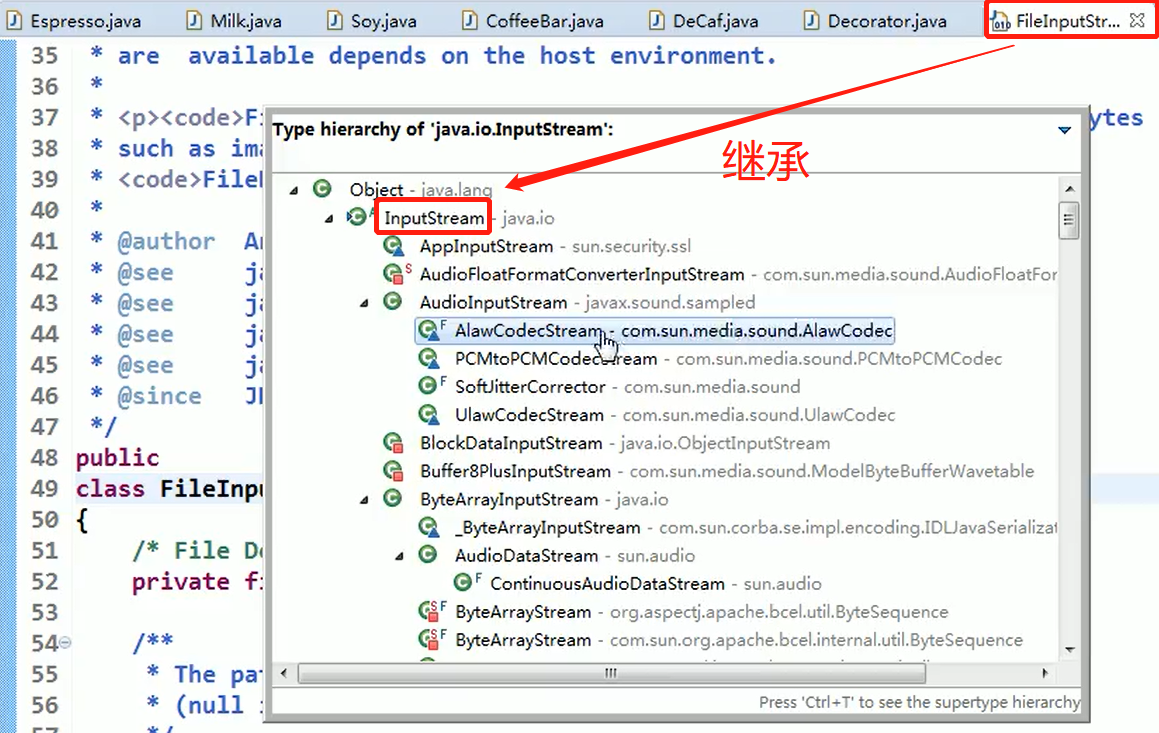


对源码的解析:
- InputStream 是抽象类, 类似我们前面讲的 Drink
- FileInputStream 是 InputStream 子类,类似我们前面的 DeCaf, LongBlack
- FilterInputStream 是 InputStream 子类:类似我们前面 的 Decorator 修饰者
- DataInputStream 是 FilterInputStream 子类,具体的修饰者,类似前面的 Milk, Soy 等
- FilterInputStream 类 有 protected volatile InputStream in; 即含被装饰者
- 分析得出在jdk 的io体系中,就是使用装饰者模式
11.5、装饰者模式总结
主要优点有:
- 装饰器是继承的有力补充,比继承灵活,在不改变原有对象的情况下,动态的给一个对象扩展功能,即插即用
- 通过使用不用装饰类及这些装饰类的排列组合,可以实现不同效果
- 装饰器模式完全遵守开闭原则
- 装饰类和被装饰类可以独立发展,不会相互耦合,装饰模式是继承的一个替代模式,装饰模式可以动态扩展一个实现类的功能。
主要缺点:
- 装饰器模式会增加许多子类,过度使用会增加程序得复杂性。
装饰者模式的应用场景:
- 当需要给一个现有类添加附加职责,而又不能采用生成子类的方法进行扩充时。例如,该类被隐藏或者该类是终极类或者采用继承方式会产生大量的子类。
- 当需要通过对现有的一组基本功能进行排列组合而产生非常多的功能时,采用继承关系很难实现,而采用装饰器模式却很好实现。
- 当对象的功能要求可以动态地添加,也可以再动态地撤销时。(可插拔)
装饰器模式在 Java 语言中的最著名的应用莫过于 Java I/O 标准库的设计了。例如,InputStream 的子类 FilterInputStream,OutputStream 的子类 FilterOutputStream,Reader 的子类 BufferedReader 以及 FilterReader,还有 Writer 的子类 BufferedWriter、FilterWriter 以及 PrintWriter 等,它们都是抽象装饰类。
11.6、装饰者模式扩展
装饰器模式所包含的 4 个角色不是任何时候都要存在的,在有些应用环境下模式是可以简化的,如以下两种情况。
11.6.1、如果只有一个具体构件而没有抽象构件时,可以让抽象装饰继承具体构件
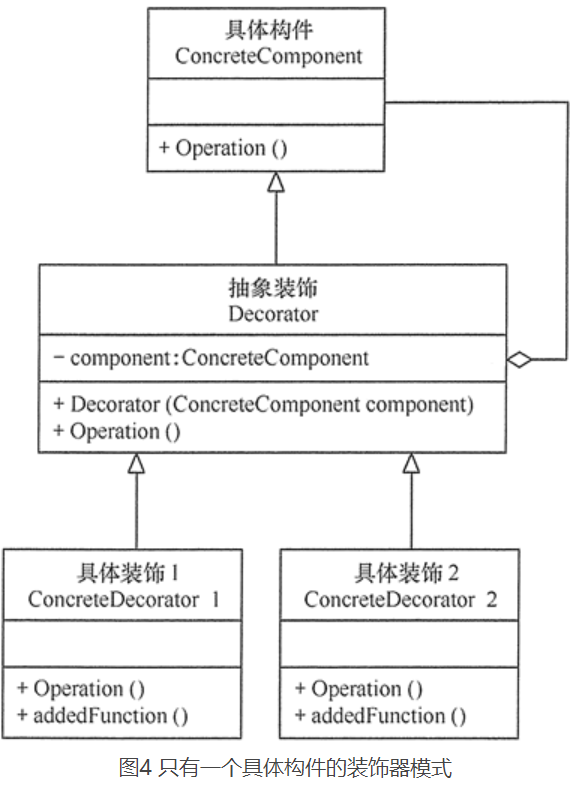
11.6.2、如果只有一个具体装饰时,可以将抽象装饰和具体装饰合并
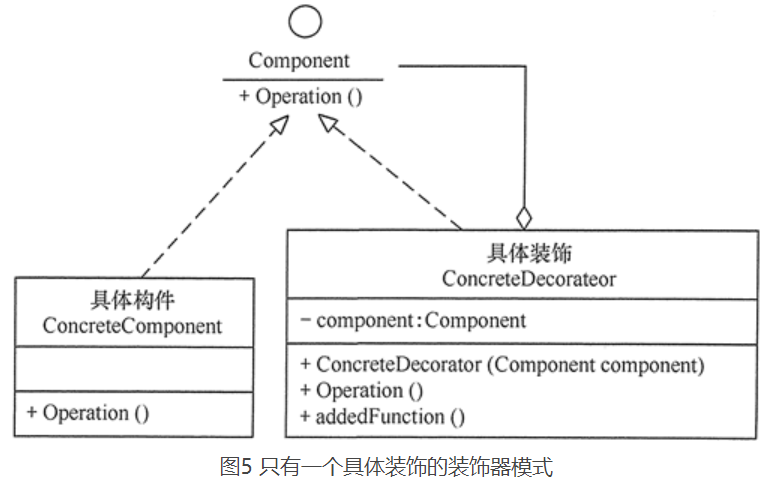
11.7、进阶阅读
如果您想深入了解装饰器模式,可猛击阅读以下文章。
11.8、相关设计模式
Adapter模式
Decorator 模式可以在不改变被装饰物的接口 (API) 的前提下, 为被装饰物添加边框(透明性)。
Adapter 模式用千适配两个不同的接口 (API)。
Stragety模式
Decorator 模式可以像改变被装饰物的边框或是为被装饰物添加多重边框那样, 来增加类的功能。
Stragety 模式通过整体地替换算法来改变类的功能。
11.9、装饰者模式的注意事项与细节
- 得益于接口(API)的透明性, Decorator模式中也形成了类似千Composite模式中的递归结构。
- 也就是说, 装饰边框里面的 ”被装饰物” 实际上又是别的物体的 "装饰边框"。就像是剥洋葱时以为洋葱心要出来了, 结果却发现还是皮。
- 不过, Decorator模式虽然与Composite模式一样, 都具有递归 结构, 但是它们的使用目的不同。
- Decorator模式的主要目的是通过添加装饰物来增加对象的功能。
12、组合模式Composite(结构型模式)
12.1、基本介绍
组合模式(Composite Pattern),又叫部分整体模式,它创建了对象组的树形结构,将对象组合成树状结构以表示“整体-部分”的层次关系。
组合模式依据树形结构来组合对象,用来表示部分以及整体层次。
这种类型的设计模式属于结构型模式。
组合模式使得用户对单个对象和组合对象的访问具有一致性,即:组合能让客户以一致的方式处理个别对象以及组合对象
组合模式创建了一个包含自己对象组的类。该类提供了修改相同对象组的方式。
组合模式一般用来描述整体与部分的关系,它将对象组织到树形结构中,顶层的节点被称为根节点,根节点下面可以包含树枝节点和叶子节点,树枝节点下面又可以包含树枝节点和叶子节点,树形结构图如下:
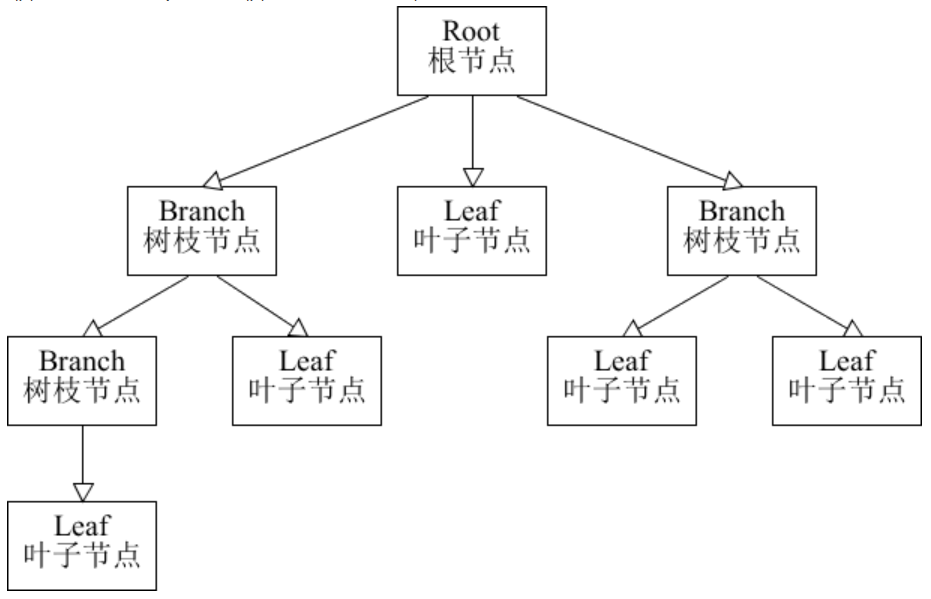
由上图可以看出,其实根节点和树枝节点本质上属于同一种数据类型,可以作为容器使用;而叶子节点与树枝节点在语义上不属于用一种类型。但是在组合模式中,会把树枝节点和叶子节点看作属于同一种数据类型(用统一接口定义),让它们具备一致行为。
这样,在组合模式中,整个树形结构中的对象都属于同一种类型,带来的好处就是用户不需要辨别是树枝节点还是叶子节点,可以直接进行操作,给用户的使用带来极大的便利。
12.2、组合模式的原理结构图-uml类图
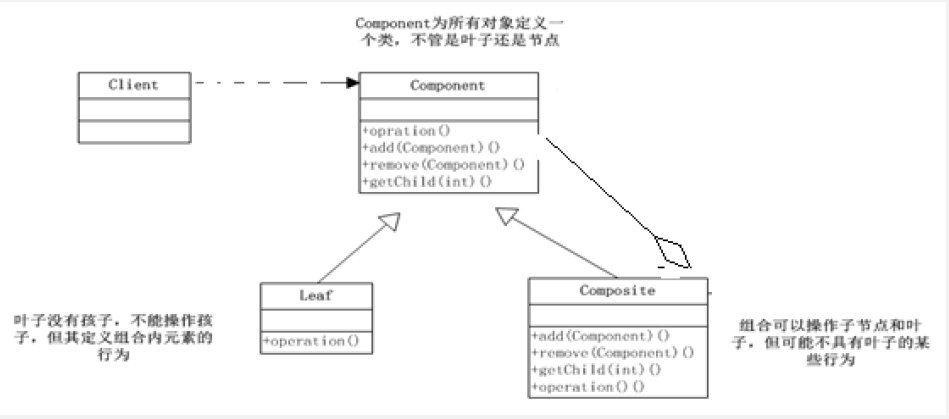
组合模式主要包含以下角色:
- 抽象构件(Component)角色:这是组合中对象声明接口,在适当情况下,实现所有类共有的接口默认行为,用于访问和管理Component 子部件, Component 可以是抽象类或者接口
- 树叶构件(Leaf)角色: 在组合中表示叶子节点,叶子节点没有子节点。用于继承或实现抽象构件。
- 树枝构件(Composite)角色 / 中间构件:是组合中的分支节点对象,非叶子节点,用于存储子部件。它的主要作用是存储和管理子部件,在Component接口中实现子部件的相关操作,比如增加(add), 删除(remove)。
装饰器模式的结构图:
代码实现:
1 | public class CompositePattern { |
12.3、应用举例
看一个学校院系展示需求
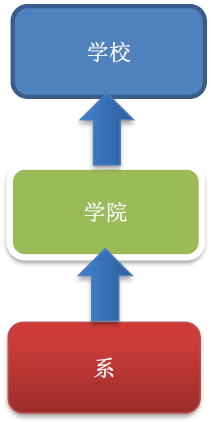
编写程序展示一个学校院系结构:需求是这样,要在一个页面中展示出学校的院系组成,一个学校有多个学院, 一个学院有多个系。如图:

12.3.1、传统方案解决需求
思路解析(类图)
传统方案解决学校院系展示存在的问题分析
- 将学院看做是学校的子类,系是学院的子类,这样实际上是站在组织大小来进行分层次的
- 实际上我们的要求是 :在一个页面中展示出学校的院系组成,一个学校有多个学院,一个学院有多个系, 因此这种方案,不能很好实现的管理的操作,比如对学院、系的添加,删除,遍历等
- 解决方案:把学校、院、系都看做是组织结构,他们之间没有继承的关系,而是一个树形结构,可以更好的实现管理操作。 => 组合模式
12.3.2、组合模式进阶需求
思路分析和图解(类图)
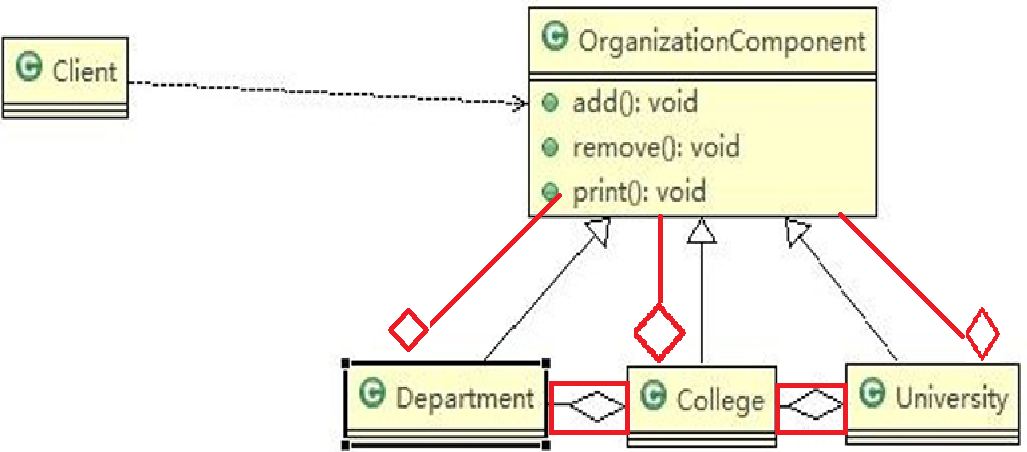
代码实现
OrganizationComponent:组织。抽象构件(Component)角色
1 | public abstract class OrganizationComponent { |
University:大学,组织的一种,管理学院College。树枝构件(Composite)角色 / 中间构件
1 | //University 就是 Composite , 可以管理College |
College:学院,组织的一种,被University管理,管理各个专业。树枝构件(Composite)角色 / 中间构件
1 | import java.util.ArrayList; |
Department:专业,组织的一种,被学院College管理,本身是叶子构件,没有管理对象。树叶构件(Leaf)角色
1 | public class Department extends OrganizationComponent { |
Client:调用方
1 | public class Client { |
12.4、组合模式在JDK的应用与源码
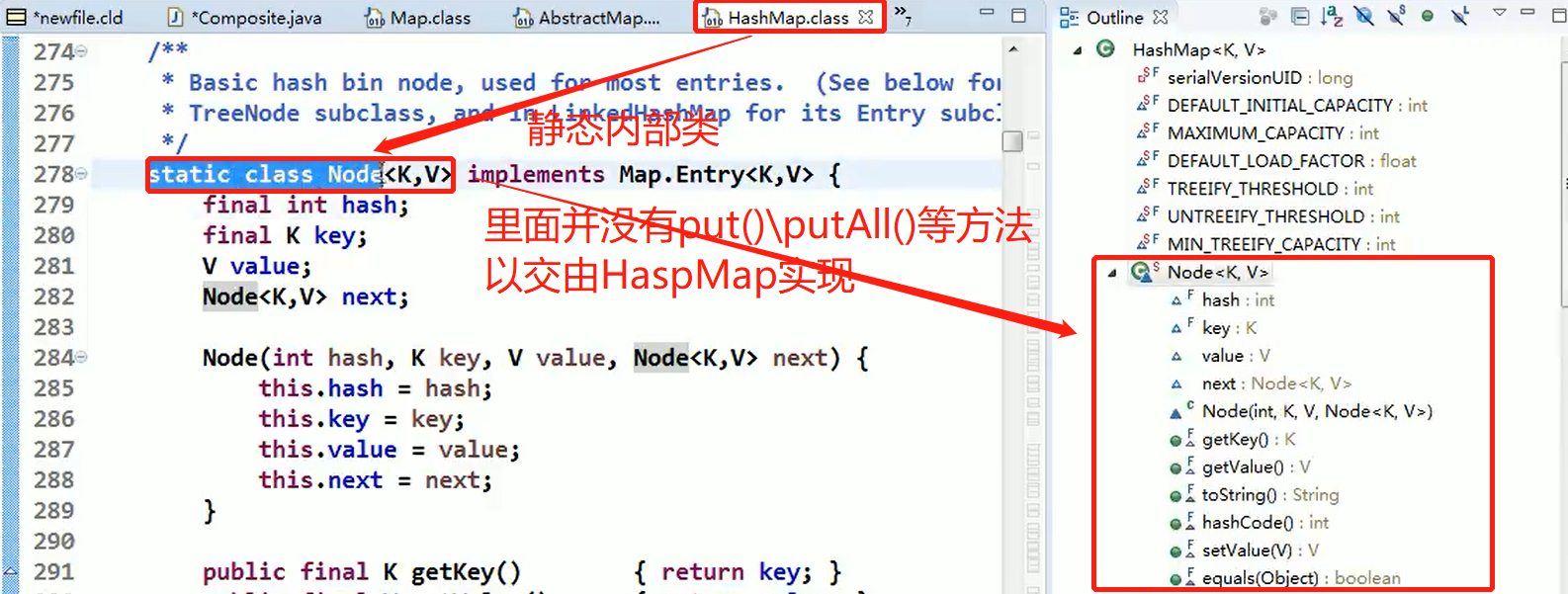
Java 的集合类-HashMap 就使用了组合模式
代码分析+Debug 源码:
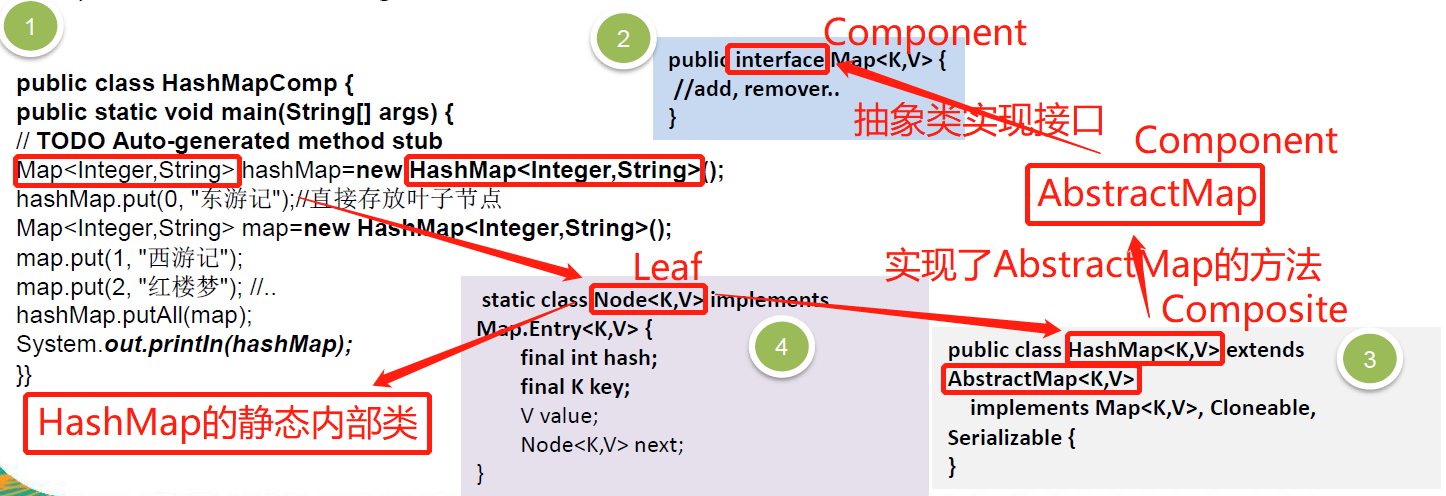
相关类图:
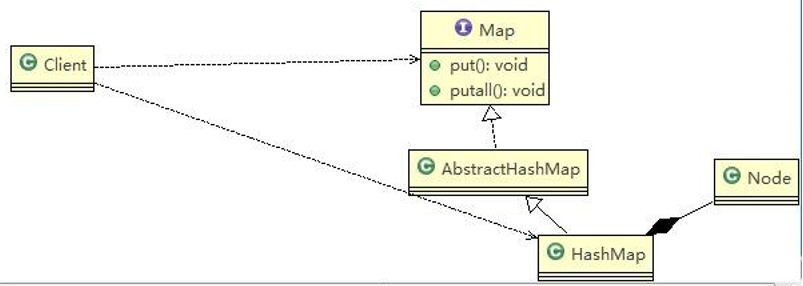
说明:
Map 就是一个抽象的构建 (类似我们的Component)
HashMap是一个中间的构建(Composite), 实现/继承了相关方法put, putall等等
Node 是 HashMap的静态内部类,类似Leaf叶子节点, 这里就没有put, putall等方法
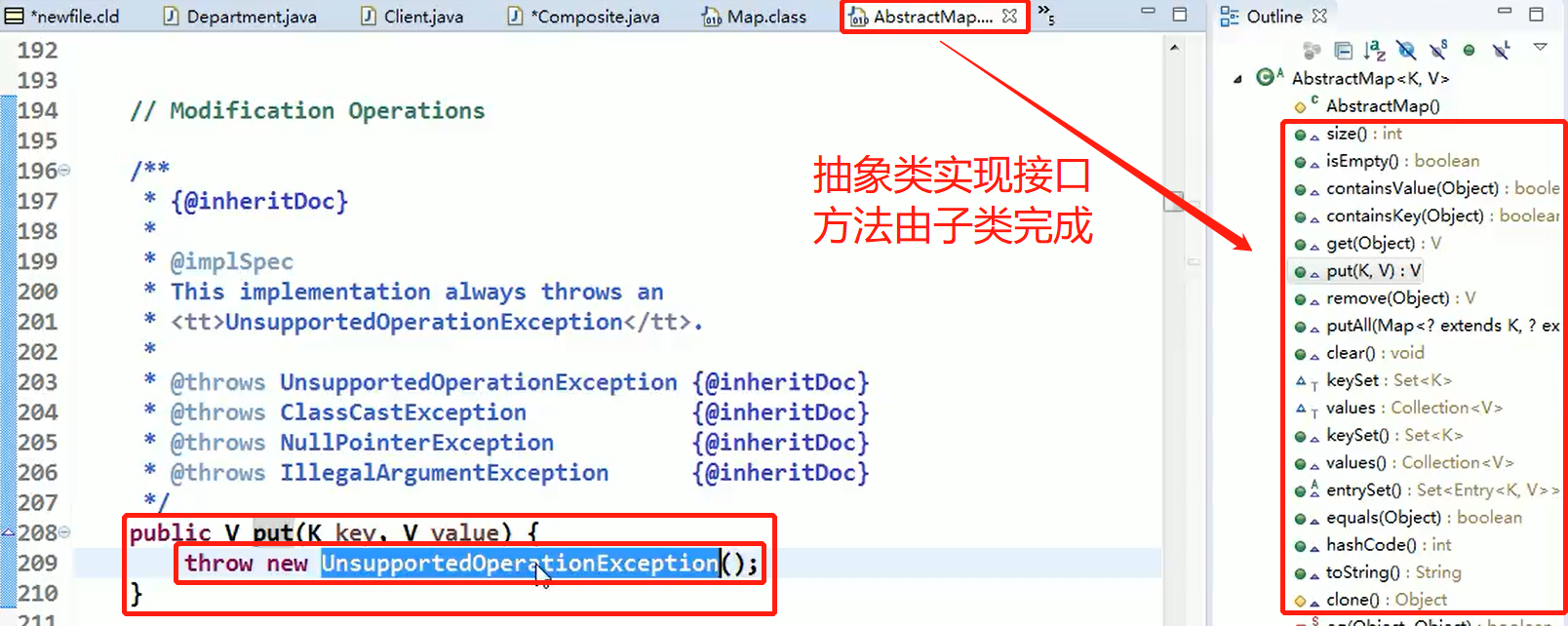
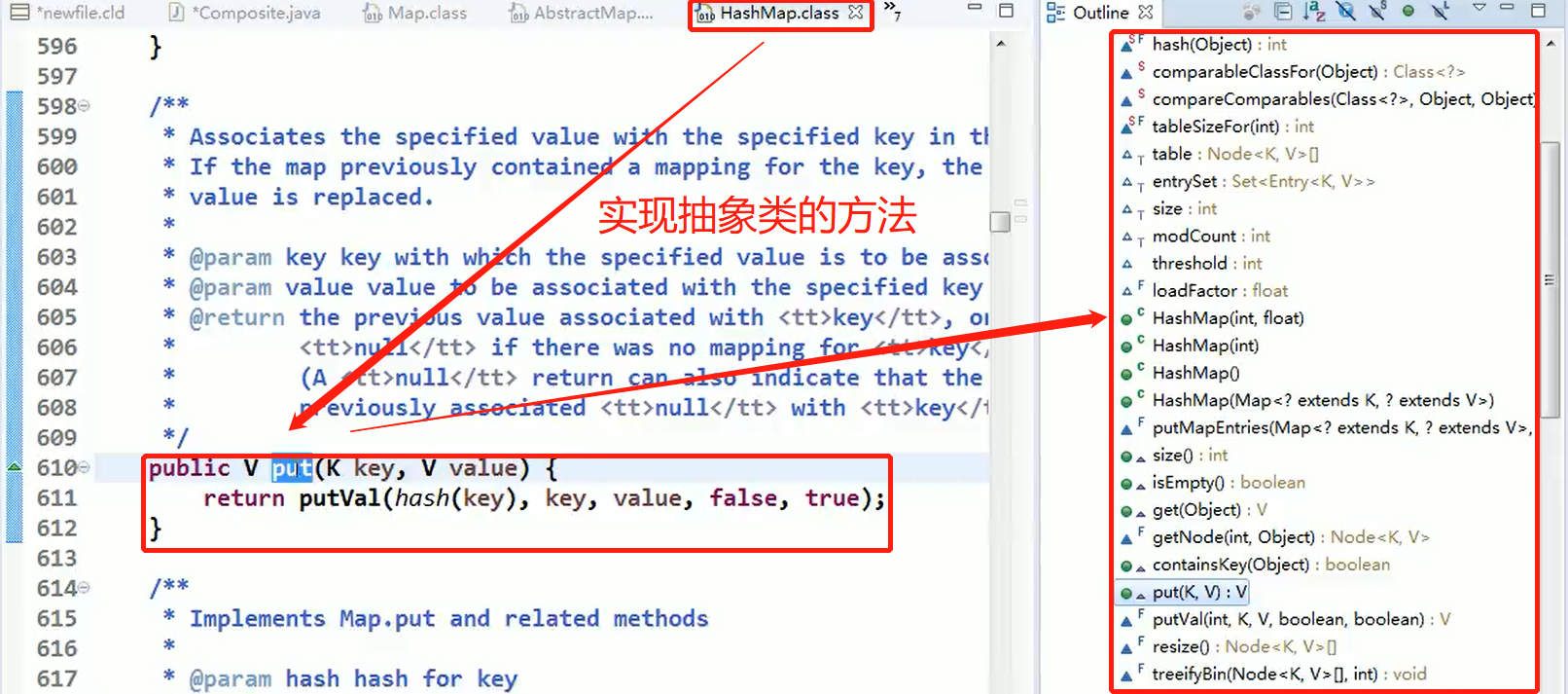
static class Node<K,V> implements Map.Entry<K,V>
Map:
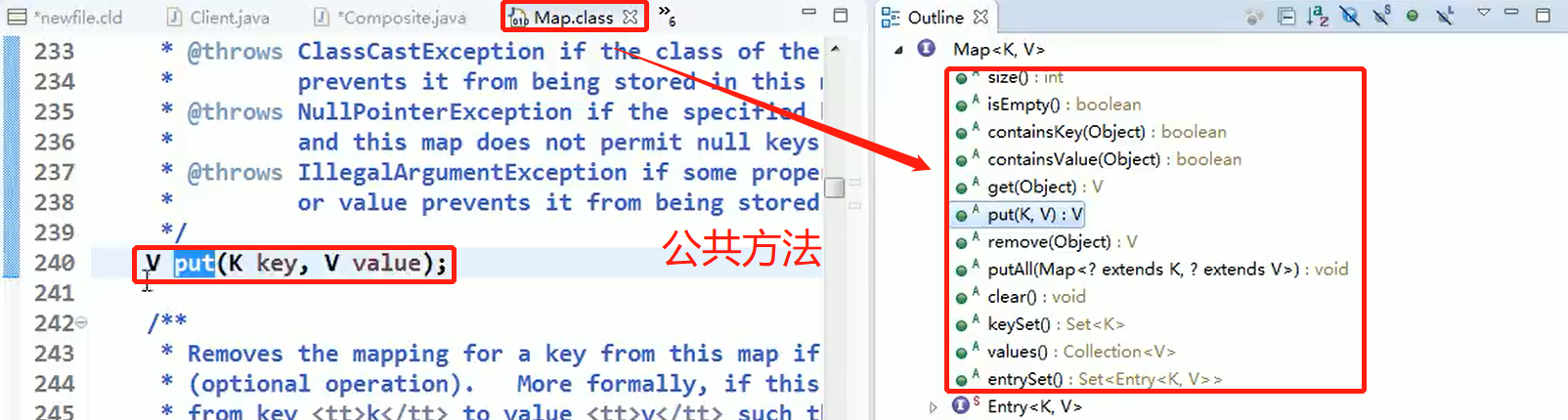
AbstractMap:
HashMap:
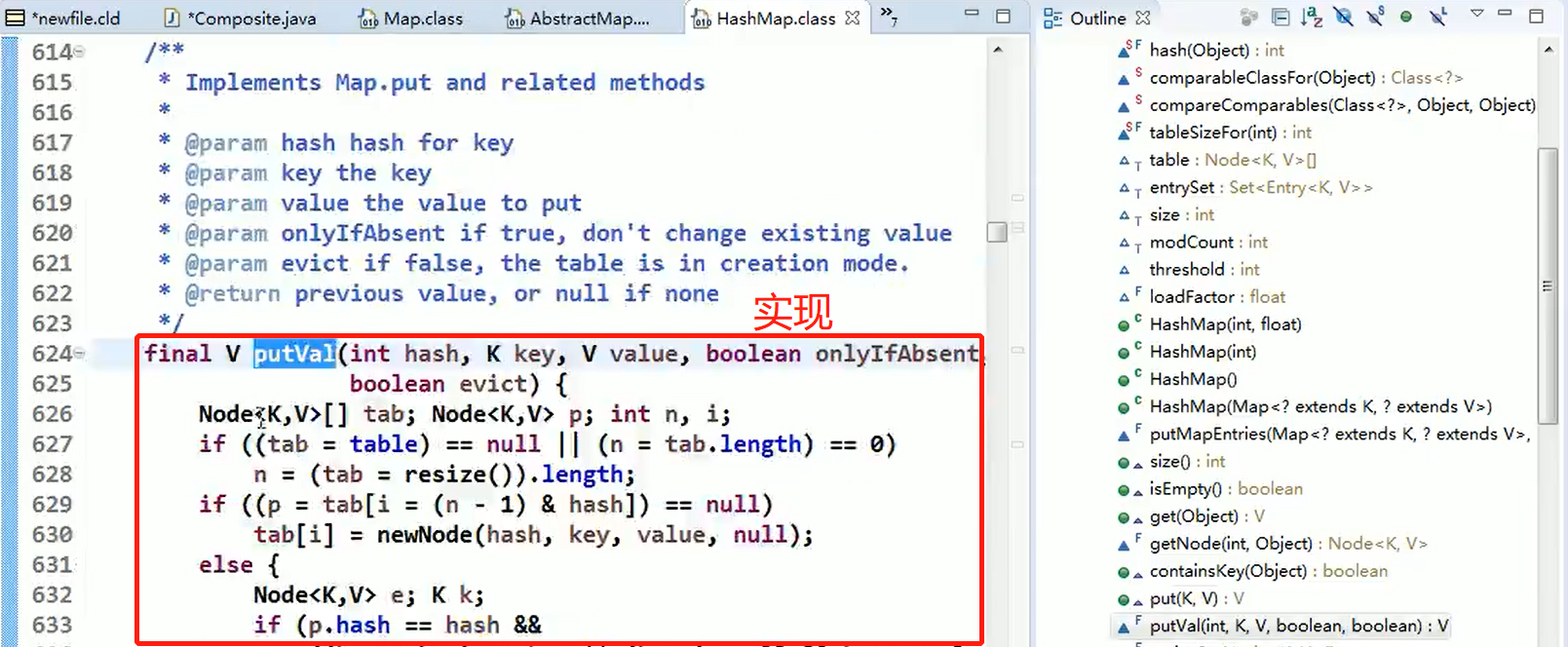
Node:HashMap的静态内部类
12.5、组合模式总结
主要优点有:
- 组合模式使得客户端代码可以一致地处理单个对象和组合对象,无须关心自己处理的是单个对象,还是组合对象,这简化了客户端代码;
- 更容易在组合体内加入新的对象,客户端不会因为加入了新的对象而更改源代码,满足“开闭原则”;
主要缺点是:
- 设计较复杂,客户端需要花更多时间理清类之间的层次关系;
- 不容易限制容器中的构件;
- 不容易用继承的方法来增加构件的新功能;
组合模式的应用场景
- 在需要表示一个对象整体与部分的层次结构的场合。
- 要求对用户隐藏组合对象与单个对象的不同,用户可以用统一的接口使用组合结构中的所有对象的场合。
应用实例:
- 算术表达式包括操作数、操作符和另一个操作数,其中,另一个操作符也可以是操作数、操作符和另一个操作数。
- 在 JAVA AWT 和 SWING 中,对于 Button 和 Checkbox 是树叶,Container 是树枝。
12.6、组合模式扩展
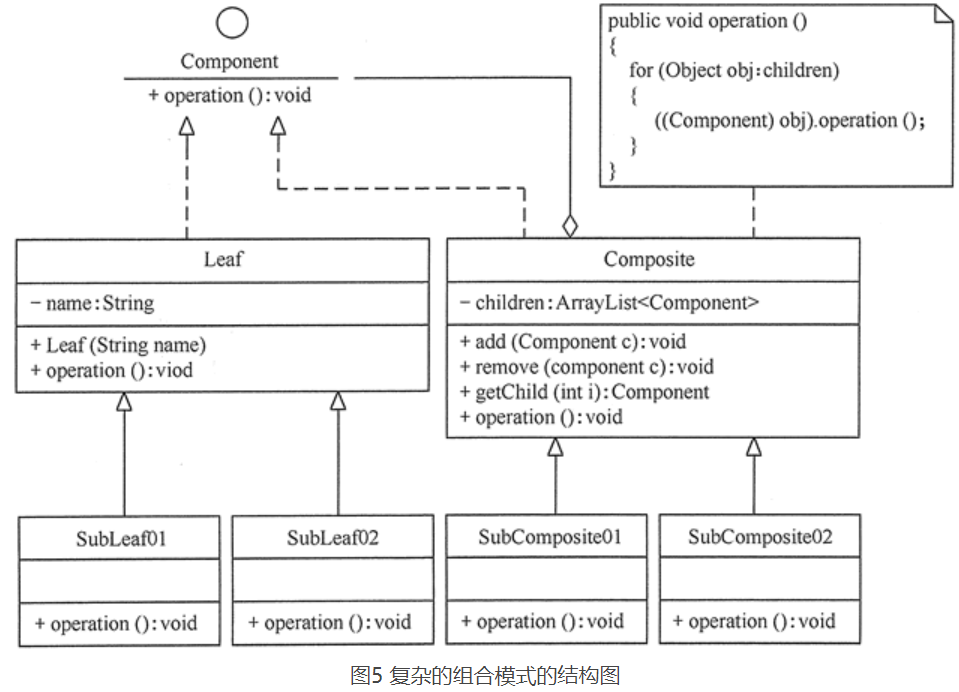
如果对前面介绍的组合模式中的树叶节点和树枝节点进行抽象,也就是说树叶节点和树枝节点还有子节点,这时组合模式就扩展成复杂的组合模式了,如 Java AWT/Swing 中的简单组件 JTextComponent 有子类 JTextField、JTextArea,容器组件 Container 也有子类 Window、Panel。复杂的组合模式的结构图如图所示。
12.7、进阶阅读
如果您想深入了解组合模式,可猛击阅读以下文章。
12.8、相关设计模式
Command模式
使用Command模式编写宏命令时使用了Composite模式。
Visitor模式
可以使用Visitor模式访问Composite模式中的递归结构。
Decorator 模式
Composite模式通过Component角色使容器(Composite角色)和内容(Leaf角色)具有一致性
Decorator模式使装饰框和内容具有一致性。
12.9、组合模式的注意事项与细节
- 简化客户端操作。客户端只需要面对一致的对象而不用考虑整体部分或者节点叶子的问题。
- 具有较强的扩展性。当我们要更改组合对象时,我们只需要调整内部的层次关系,客户端不用做出任何改动。满足了OCP原则。
- 方便创建出复杂的层次结构。客户端不用理会组合里面的组成细节,容易添加节点或者叶子从而创建出复杂的树形结构。
- 需要遍历组织机构,或者处理的对象具有树形结构时, 非常适合使用组合模式.
- 要求较高的抽象性,如果节点和叶子有很多差异性的话,比如很多方法和属性都不一样,不适合使用组合模式
13、外观模式Facade(结构型模式)
13.1、基本介绍
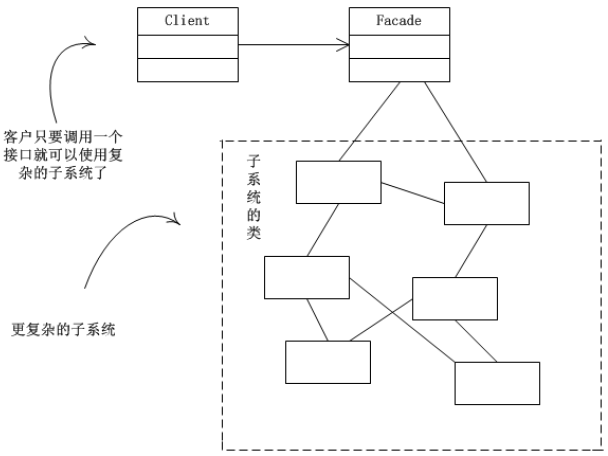
- 外观模式(Facade),也叫过程模式、门面模式:外观模式为子系统中的一组接口提供一个一致的界面,此模式定义了一个高层接口,这个接口使得这一子系统更加容易使用
- 外观模式通过定义一个一致的接口,用以屏蔽内部子系统的细节,使得调用端只需跟这个接口发生调用,而无需关心这个子系统的内部细节。这样会大大降低应用程序的复杂度,提高了程序的可维护性。
- 外观设计模式属于结构型模式,它向现有的系统添加一个接口,来隐藏系统的复杂性。
- 在日常编码工作中,我们都在有意无意的大量使用外观模式。只要是高层模块需要调度多个子系统(2个以上的类对象),我们都会自觉地创建一个新的类封装这些子系统,提供精简的接口,让高层模块可以更加容易地间接调用这些子系统的功能。尤其是现阶段各种第三方SDK、开源类库,很大概率都会使用外观模式。
13.2、外观模式的原理结构图-uml类图
外观(Facade)模式的结构比较简单,主要是定义了一个高层接口。它包含了对各个子系统的引用,客户端可以通过它访问各个子系统的功能。现在来分析其基本结构和实现方法。
13.2.1、模式的结构
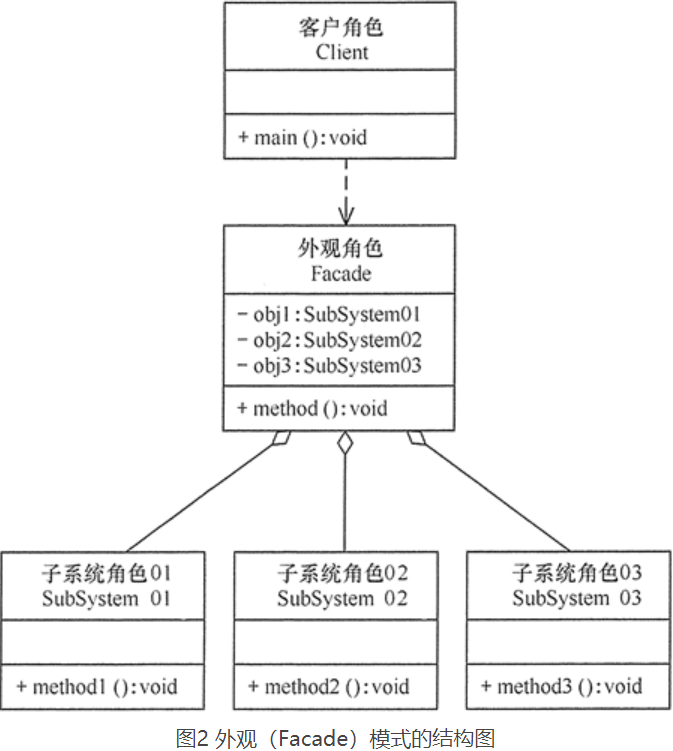
外观(Facade)模式包含以下主要角色。
- 外观(Facade)角色:为多个子系统对外提供一个统一的接口。
- 子系统(Sub System)角色:实现系统的部分功能,客户可以通过外观角色访问它。
- 客户(Client)角色:通过一个外观角色访问各个子系统的功能。
其结构图类图:
13.2.2、模式的实现
外观模式的实现代码如下:
1 | package facade; |
13.3、应用举例

13.3.1、使用传统方式解决需求
思路解析(相关类图):
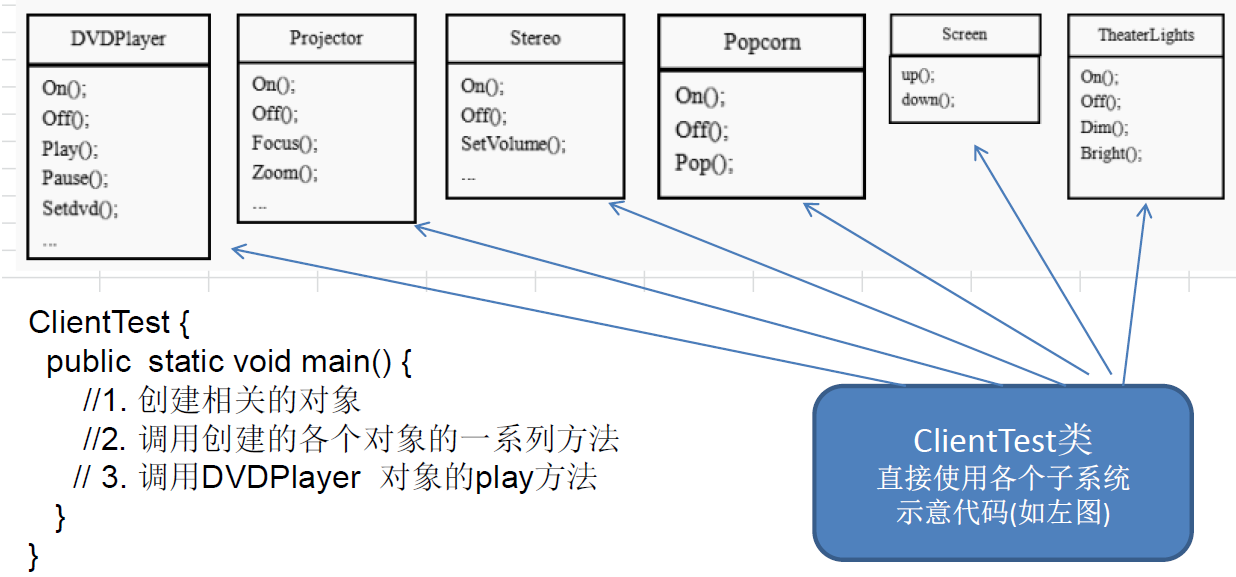
传统方式解决影院管理问题分析
在 ClientTest 的 main 方法中,创建各个子系统的对象,并直接去调用子系统(对象)相关方法,会造成调用过程混乱,没有清晰的过程
不利于在 ClientTest 中,去维护对子系统的操作
解决思路:定义一个高层接口,给子系统中的一组接口提供一个一致的界面(比如在高层接口提供四个方法ready, play, pause, end ),用来访问子系统中的一群接口
也就是说:就是通过定义一个一致的接口(界面类),用以屏蔽内部子系统的细节(既使子系统之间互相调用),使得调用端只需跟这个接口发生调用,而无需关心这个子系统的内部细节 => 外观模式
13.3.2、使用外观模式解决需求
传统方式解决影院管理说明:
- 外观模式可以理解为转换一群接口,客户只要调用一个接口,而不用调用多个接口才能达到目的。比如:在 pc 上安装软件的时候经常有一键安装选项(省去选择安装目录、安装的组件等等),还有就是手机的重启功能(把关机和启动合为一个操作)。
- 外观模式就是解决多个复杂接口带来的使用困难,起到简化用户操作的作用
思路解析(类图):
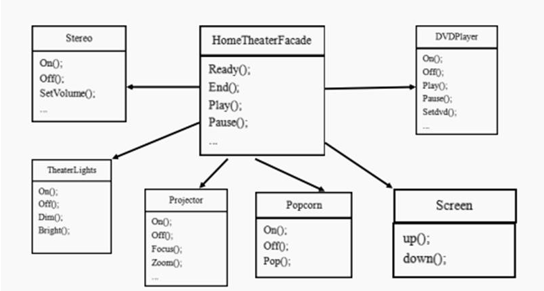
代码实现:
Screen:显示器。子系统(Sub System)角色,使用单例模式实现子系统角色的创建。(其他子系统角色类似)
1 | public class Screen { |
HomeTheaterFacade:家庭电影院外观控制器。外观(Facade)角色
1 | public class HomeTheaterFacade { |
Client:客户端。客户(Client)角色
1 | public class Client { |
13.4、外观模式在Mybatis的应用与源码
MyBatis 中的 Configuration 去创建 MetaObject 对象使用到外观模式
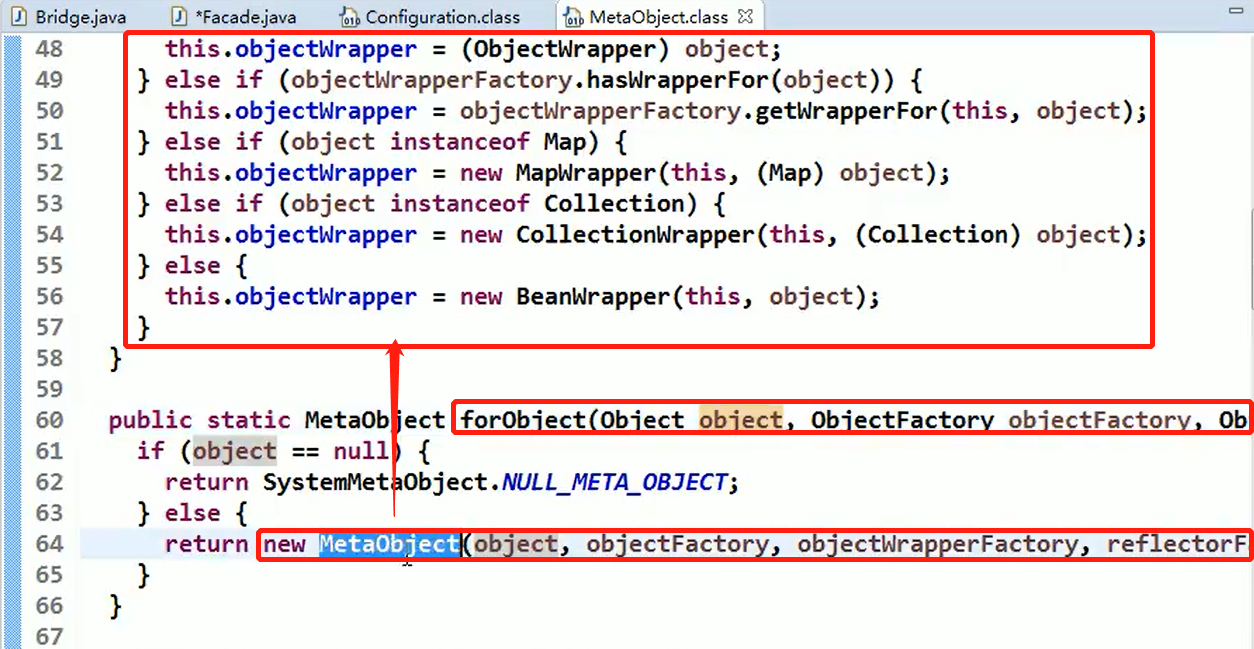
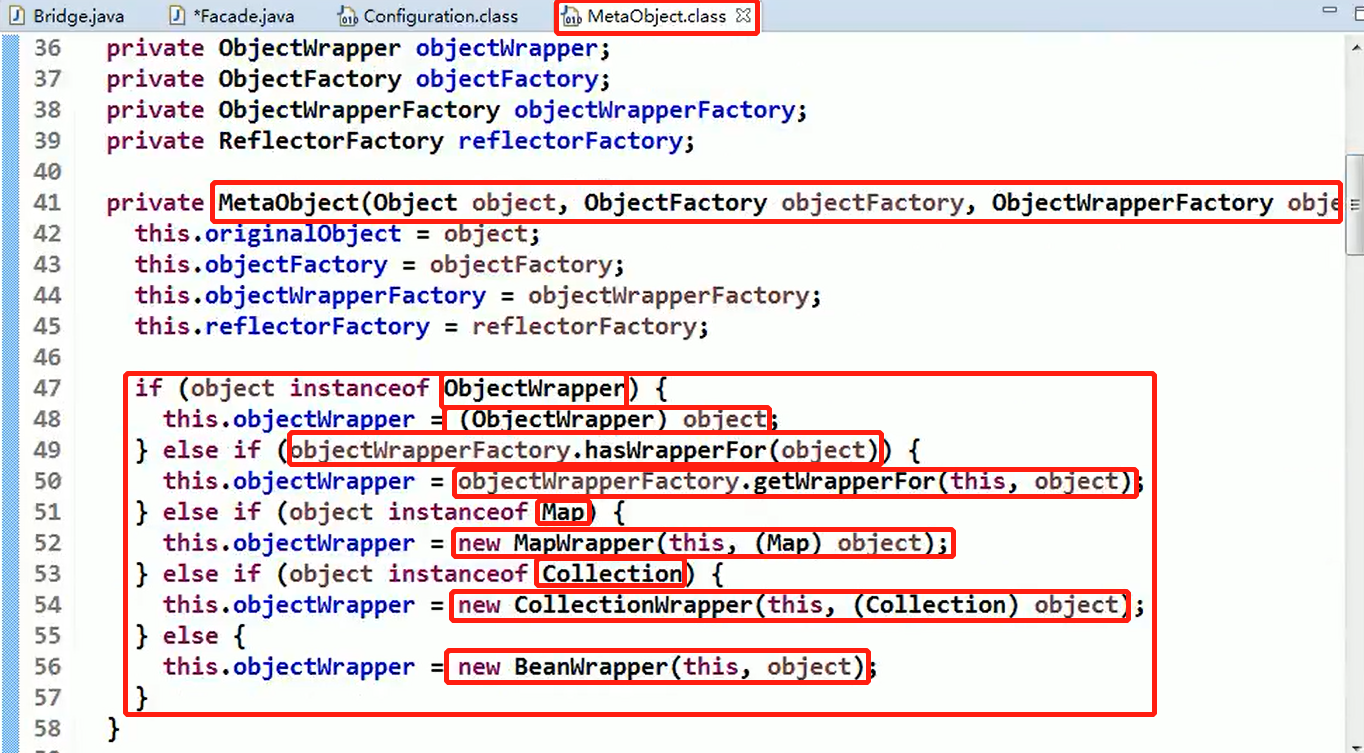
代码分析+Debug 源码+示意图
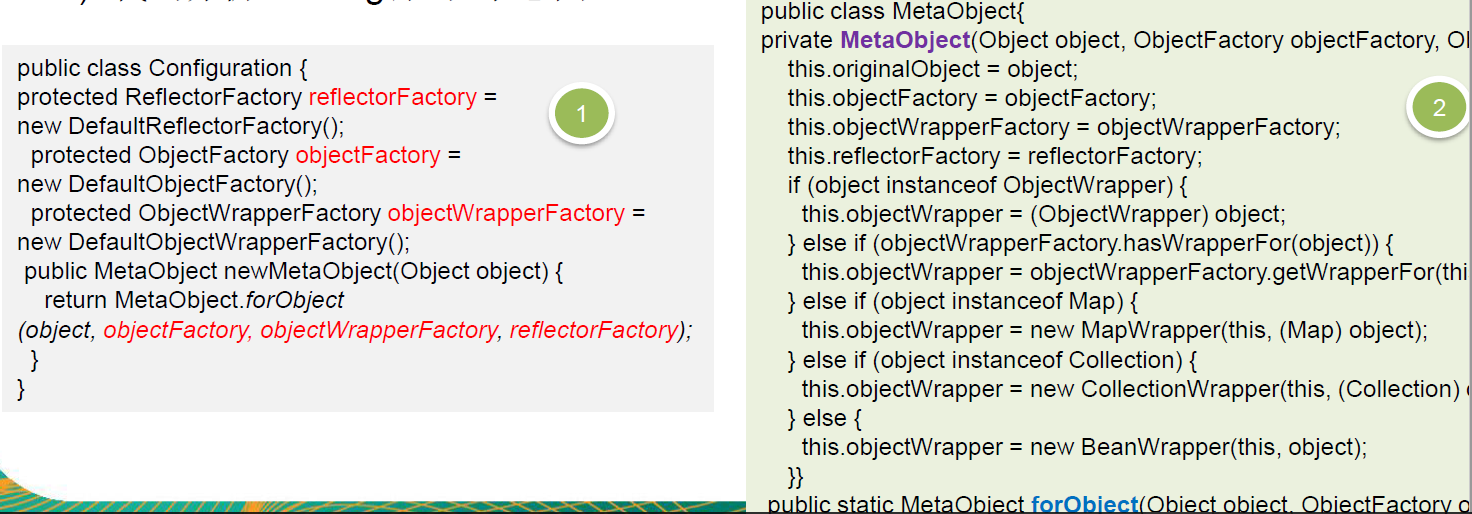
对源码中使用到的外观模式的角色类图:
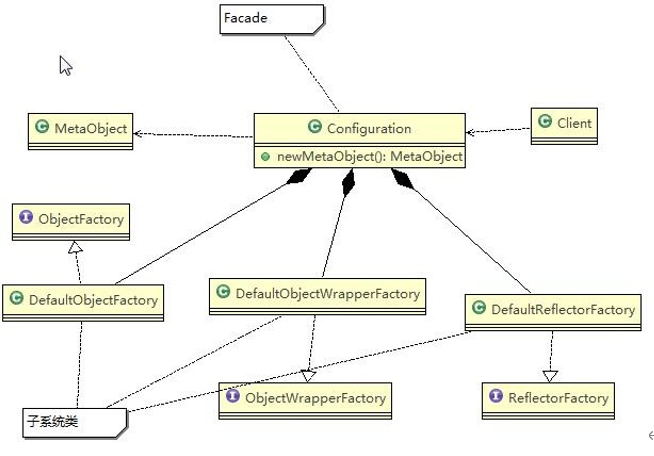
Mybatis的Configuration:(Facade外观)
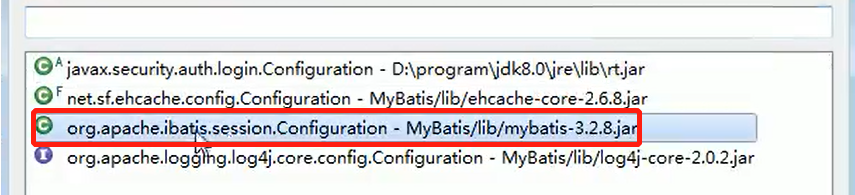
Configuration中组合的三个工厂对象:(子系统Sub System)
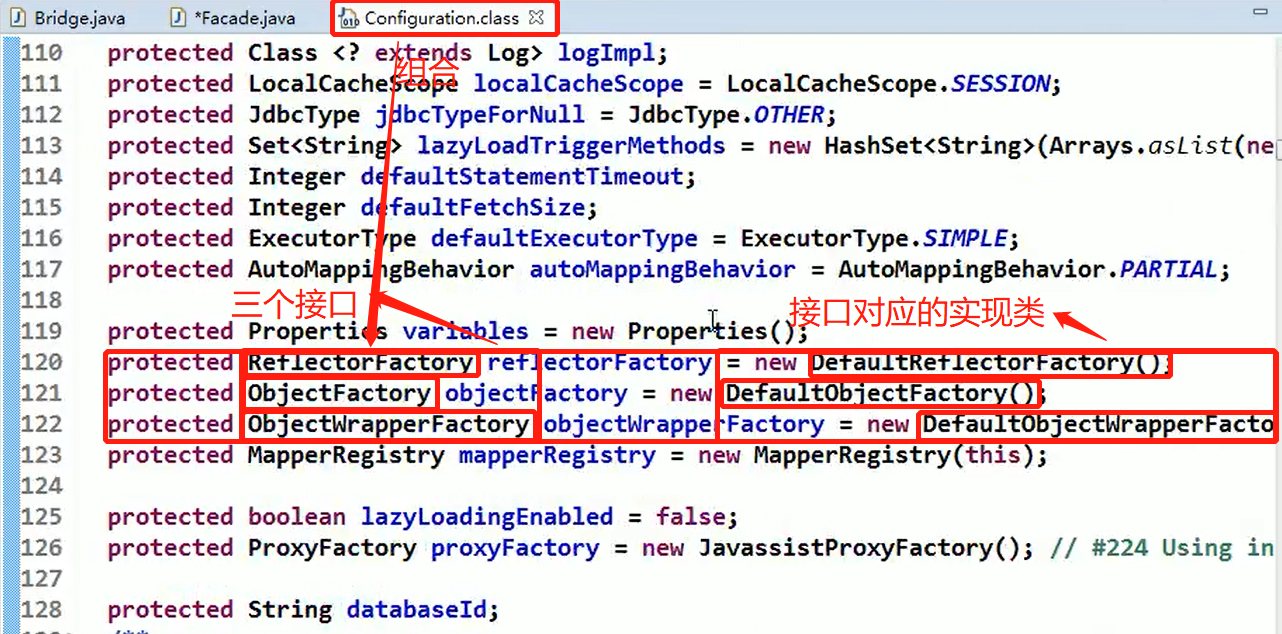
Configuration中的newMetaObject()方法
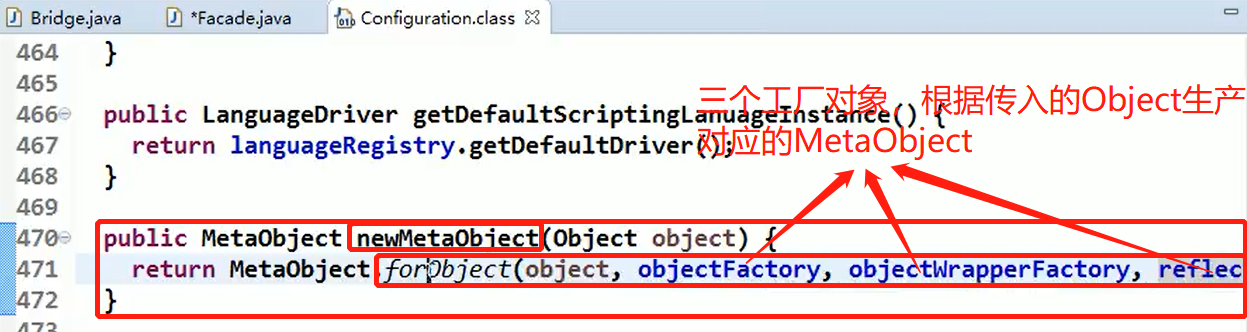
MetaObject:Client借助Mybatis的Configuration生成的对象
13.5、外观模式总结
外观(Facade)模式是“迪米特法则”的典型应用
主要优点:
- 降低了子系统与客户端之间的耦合度,使得子系统的变化不会影响调用它的客户类。
- 对客户屏蔽了子系统组件,减少了客户处理的对象数目,并使得子系统使用起来更加容易。
- 降低了大型软件系统中的编译依赖性,简化了系统在不同平台之间的移植过程,因为编译一个子系统不会影响其他的子系统,也不会影响外观对象。
主要缺点:
- 不能很好地限制客户使用子系统类,很容易带来未知风险。
- 增加新的子系统可能需要修改外观类或客户端的源代码,违背了“开闭原则”,继承重写都不合适。
外观模式的应用场景:
- 对分层结构系统构建时,使用外观模式定义子系统中每层的入口点可以简化子系统之间的依赖关系。
- 当一个复杂系统的子系统很多时,外观模式可以为系统设计一个简单的接口供外界访问。
- 当客户端与多个子系统之间存在很大的联系时,引入外观模式可将它们分离,从而提高子系统的独立性和可移植性。
外观模式应用实例:
- 去医院看病,可能要去挂号、门诊、划价、取药,让患者或患者家属觉得很复杂,如果有提供接待人员,只让接待人员来处理,就很方便
- JAVA 的三层开发模式:Controller、Service、Dao
- 很多Web程序,内部有多个子系统提供服务,经常使用一个统一的Facade入口,例如一个
RestApiController,使得外部用户调用的时候,只关心Facade提供的接口,不用管内部到底是哪个子系统处理的。 - 更复杂的Web程序,会有多个Web服务,这个时候,经常会使用一个统一的网关入口来自动转发到不同的Web服务,这种提供统一入口的网关就是Gateway,它本质上也是一个Facade,但可以附加一些用户认证、限流限速的额外服务。
13.6、外观模式扩展
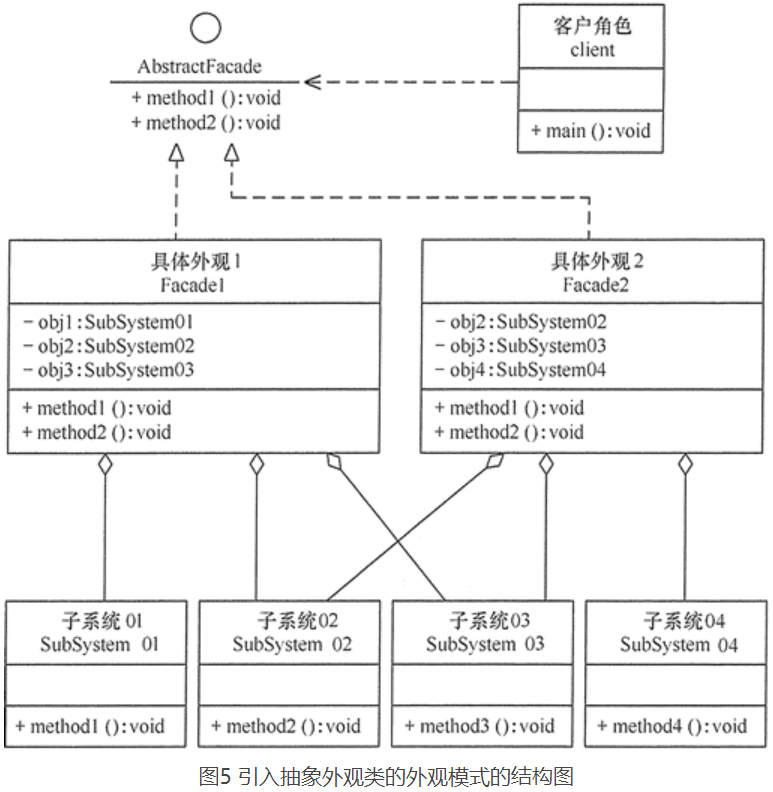
在外观模式中,当增加或移除子系统时需要修改外观类,这违背了“开闭原则”。如果引入抽象外观类,则在一定程度上解决了该问题,其结构图如图所示:
13.7、进阶阅读
如果您想了解外观模式的实际应用,可猛击阅读《使用外观模式整合调用已知API》一节。
13.8、相关设计模式
Abstract Factory 模式
可以将AbstractFactory模式看作生成复杂实例时的Facade模式。 因为它提供了 “要想生成这个实例只需要调用这个方法就OK了" 的简单接口。
Singleton 模式
有时会使用Singleton模式创建Facade角色。
Mediator 模式
在Facade模式中,Facade角色单方面地使用其他角色来提供高层接口(API)。
而在Mediator模式中,Mediator角色作为Colleague角色间的仲裁者负责调停。 可以说, Facade模式是单向的, 而Mediator角色是双向的。
13.9、外观模式的注意事项与细节
- 外观模式对外屏蔽了子系统的细节,因此外观模式降低了客户端对子系统使用的复杂性
- 外观模式对客户端与子系统的耦合关系 - 解耦,让子系统内部的模块更易维护和扩展
- 通过合理的使用外观模式,可以帮我们更好的划分访问的层次
- 当系统需要进行分层设计时,可以考虑使用 Facade 模式
- 在维护一个遗留的大型系统时,可能这个系统已经变得非常难以维护和扩展,此时可以考虑为新系统开发一个Facade 类,来提供遗留系统的比较清晰简单的接口,让新系统与 Facade 类交互,提高复用性
- 不能过多的或者不合理的使用外观模式,使用外观模式好,还是直接调用模块好。要以让系统有层次,利于维护为目的。
14、享元模式Flyweight(结构型模式)
14.1、基本介绍
享元模式(Flyweight Pattern) 也叫 蝇量模式: 运用共享技术有效地支持大量细粒度的对象。它通过共享已经存在的对象来大幅度减少需要创建的对象数量、避免大量相似类的开销,从而提高系统资源的利用率。
享元模式属于结构型模式,它提供了减少对象数量从而改善应用所需的对象结构的方式
常用于系统底层开发,解决系统的性能问题。像数据库连接池,里面都是创建好的连接对象,在这些连接对象中有我们需要的则直接拿来用,避免重新创建,如果没有我们需要的,则创建一个。
享元模式能够解决重复对象的内存浪费的问题,当系统中有大量相似对象,需要缓冲池时。不需总是创建新对象,可以从缓冲池里拿。这样可以降低系统内存,同时提高效率
享元模式的核心思想:如果一个对象实例一经创建就不可变,那么反复创建相同的实例就没有必要,直接向调用方返回一个共享的实例就行,这样即节省内存,又可以减少创建对象的过程,提高运行速度。(注意区别单例模式)
一言蔽之:通过尽量共享实例来避免new出实例。
享元模式经典的应用场景就是池技术了,String 常量池、数据库连接池、缓冲池等等都是享元模式的应用,享元模式是池技术的重要实现方式
14.2、享元模式的原理结构图-uml类图
14.2.1、内部状态与外部状态
享元模式的定义提出了两个要求,细粒度和共享对象。因为要求细粒度,所以不可避免地会使对象数量多且性质相近,此时我们就将这些对象的信息分为两个部分:内部状态和外部状态。
- 内部状态指对象共享出来的信息,存储在享元信息内部,并且不会随环境的改变而改变;
- 外部状态指对象得以依赖的一个标记,随环境的改变而改变,不可共享。
比如围棋、五子棋、跳棋,它们都有大量的棋子对象,围棋和五子棋只有黑白两色,跳棋颜色多一点,所以棋子颜色就是棋子的内部状态;而各个棋子之间的差别就是位置的不同,当我们落子后,落子颜色是定的,但位置是变化的,所以棋子坐标就是棋子的外部状态。
又比如,连接池中的连接对象,保存在连接对象中的用户名、密码、连接URL等信息,在创建对象的时候就设置好了,不会随环境的改变而改变,这些为内部状态。而当每个连接要被回收利用时,我们需要将它标记为可用状态,这些为外部状态。
享元模式的本质是缓存共享对象,降低内存消耗。
举个例子:围棋理论上有 361 个空位可以放棋子,每盘棋都有可能有两三百个棋子对象产生,因为内存空间有限,一台服务器很难支持更多的玩家玩围棋游戏,如果用享元模式来处理棋子,那么棋子对象就可以减少到只有两个实例,这样就很好的解决了对象的开销问题
14.2.2、模式的结构
享元模式的主要角色有如下。
- 抽象享元角色(Flyweight)(轻量级):是所有的具体享元类的基类,为具体享元规范需要实现的公共接口,非享元的外部状态以参数的形式通过方法传入。
- 具体享元(Concrete Flyweight)角色:实现抽象享元角色中所规定的接口。
- 非享元(Unsharable Flyweight)角色:是不可以共享的外部状态,它以参数的形式注入具体享元的相关方法中。一般不会出现在享元工厂。
- 享元工厂(Flyweight Factory)角色(轻量级):负责创建和管理享元角色。用于构建一个池容器(集合), 同时提供从池中获取对象方法(池技术)。当客户对象请求一个享元对象时,享元工厂检査系统中是否存在符合要求的享元对象,如果存在则提供给客户;如果不存在的话,则创建一个新的享元对象。
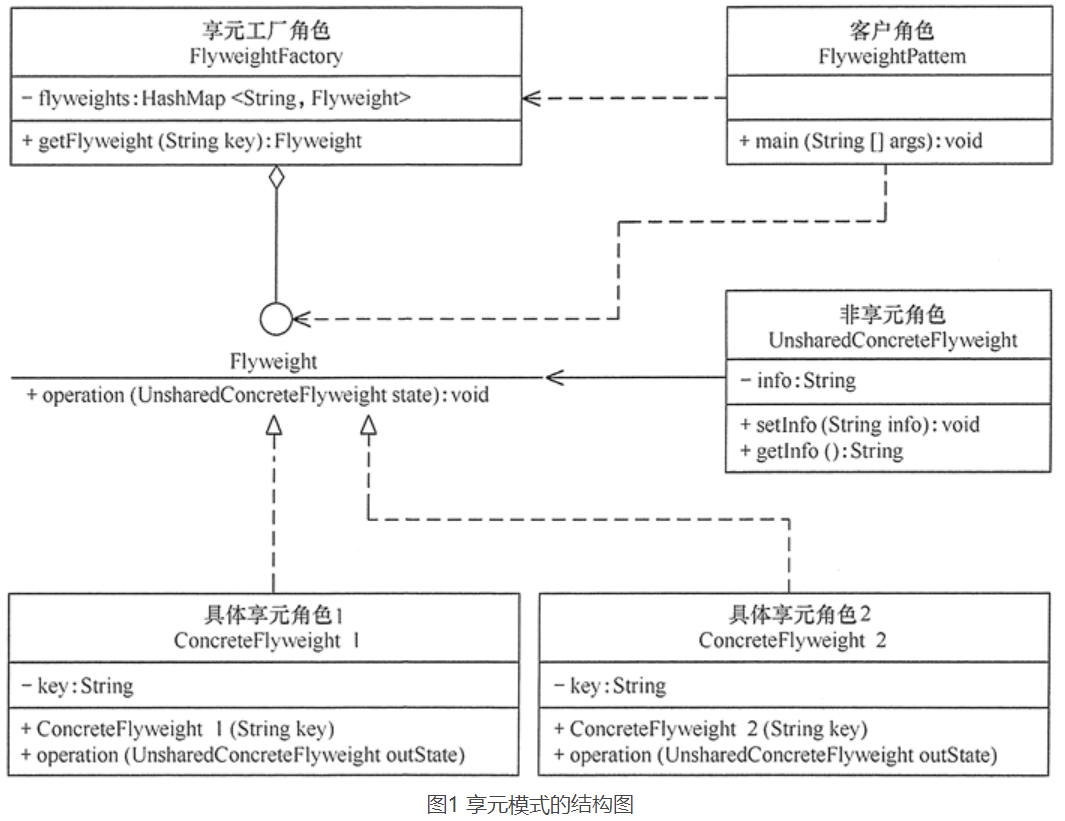
享元模式的结构图,其中:
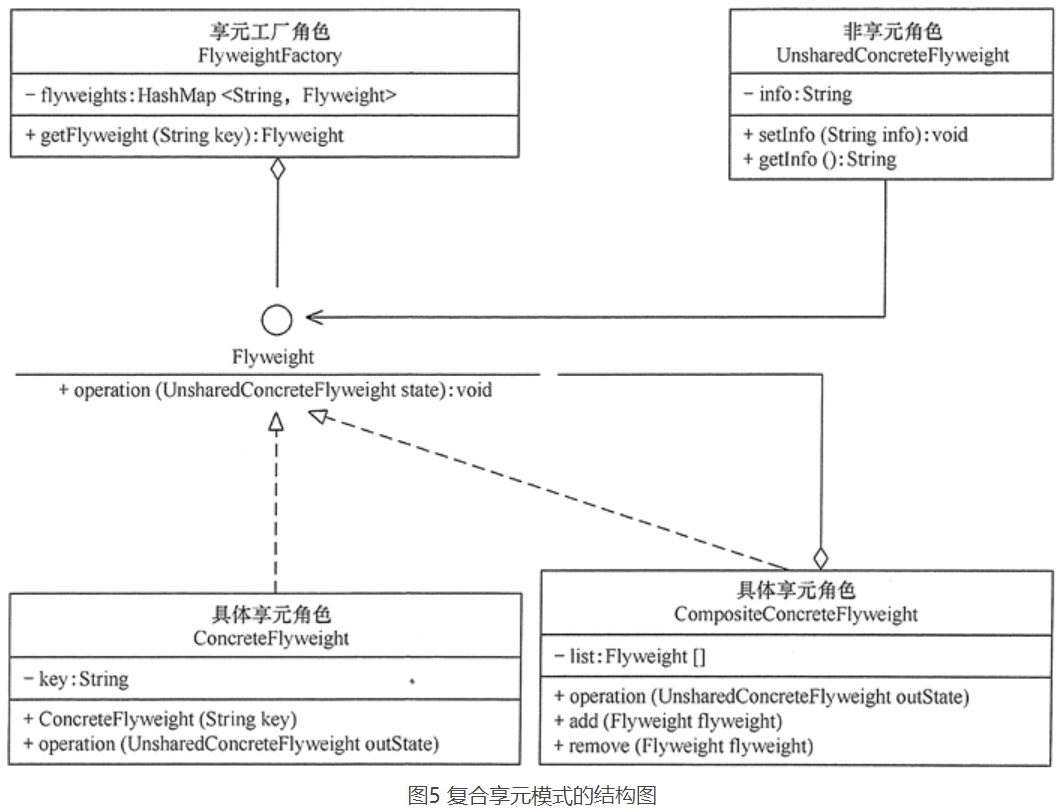
- UnsharedConcreteFlyweight 是非享元角色,里面包含了非共享的外部状态信息 info;
- Flyweight 是抽象享元角色,里面包含了享元方法 operation(UnsharedConcreteFlyweight state),非享元的外部状态以参数的形式通过该方法传入;
- ConcreteFlyweight 是具体享元角色,包含了关键字 key,它实现了抽象享元接口;
- FlyweightFactory 是享元工厂角色,它是关键字 key 来管理具体享元;
- 客户角色通过享元工厂获取具体享元,并访问具体享元的相关方法。
14.2.3、代码实现
1 | public class FlyweightPattern { |
14.3、应用举例
展示网站项目需求:
小型的外包项目,给客户 A 做一个产品展示网站,客户 A 的朋友感觉效果不错,也希望做这样的产品展示网站,但是要求都有些不同:
- 有客户要求以新闻的形式发布
- 有客户人要求以博客的形式发布
- 有客户希望以微信公众号的形式发布
14.3.1、使用传统方式解决需求
- 直接复制粘贴一份,然后根据客户不同要求,进行定制修改
- 给每个网站租用一个空间
思路分析(类图):
传统方案解决网站展现项目问题分析:
- 需要的网站结构相似度很高,而且都不是高访问量网站,如果分成多个虚拟空间来处理,相当于一个相同网站的实例对象很多,造成服务器的资源浪费
- 解决思路:整合到一个网站中,共享其相关的代码和数据,对于硬盘、内存、CPU、数据库空间等服务器资源都可以达成共享,减少服务器资源
- 对于代码来说,由于是一份实例,维护和扩展都更加容易
- 上面的解决思路就可以使用享元模式来解决
14.3.2、使用享元模式解决需求
思路分析和图解(类图):
代码实现:
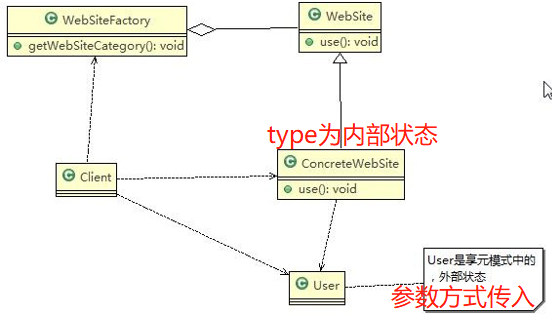
WebSite:网站,当中的use方法传入外部状态User。抽象享元角色(Flyweight)
1 | public abstract class WebSite { |
ConcreteWebSite:具体网站,继承WebSite,包含有内部状态type。具体享元(Concrete Flyweight)角色
1 | //具体网站 |
User:用户,不同的用户的构建网站的类型不同,属于外部状态,通过方法参数传入。非享元(Unsharable Flyweight)角色
1 | public class User { |
WebSiteFactory:网站工厂类,根据需要返回一个网站。享元工厂(Flyweight Factory)角色
1 | import java.util.HashMap; |
Client:客户端调用
1 | public class Client { |
14.4、享元模式在JDK-Integer的应用与源码
Integer 中的享元模式
1 | public class FlyWeight { |
代码分析:
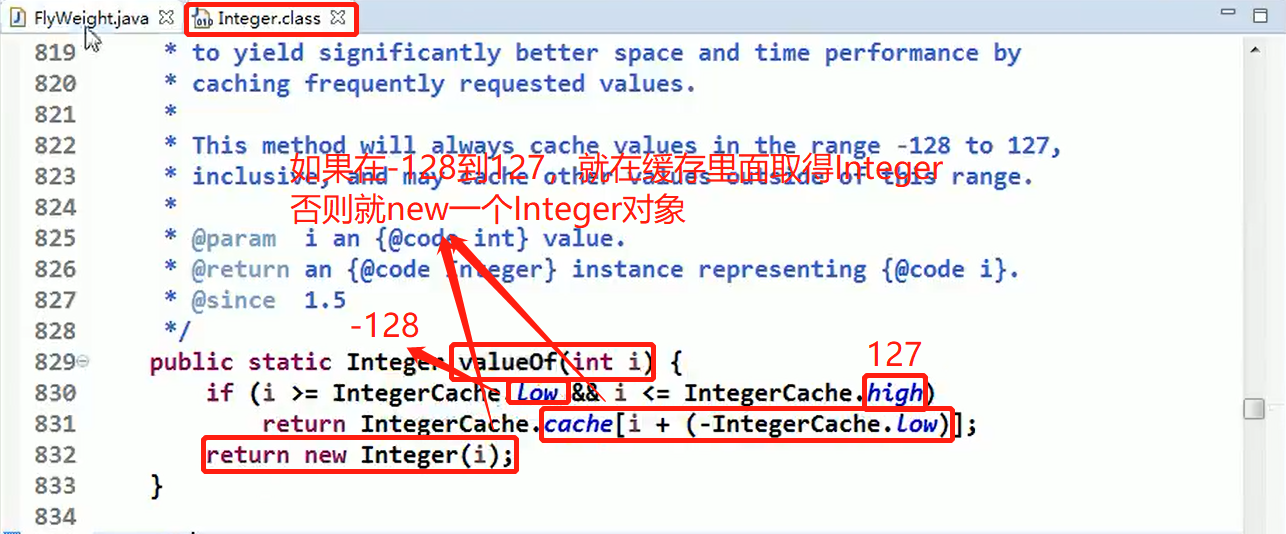
- 如果 Integer.valueOf(x)的参数 x 在 -128 — 127 之间,就是使用享元模式返回,如果不在范围内,则仍然 new 一个Integer对象
- 在valueOf 方法中,先判断值是否在 IntegerCache 中,如果不在,就创建新的Integer(new);否则,就直接从缓存池返回
- valueOf 方法,就使用到享元模式
- 如果使用valueOf 方法得到一个Integer 实例,范围在 -128 - 127 ,执行速度比 new 快
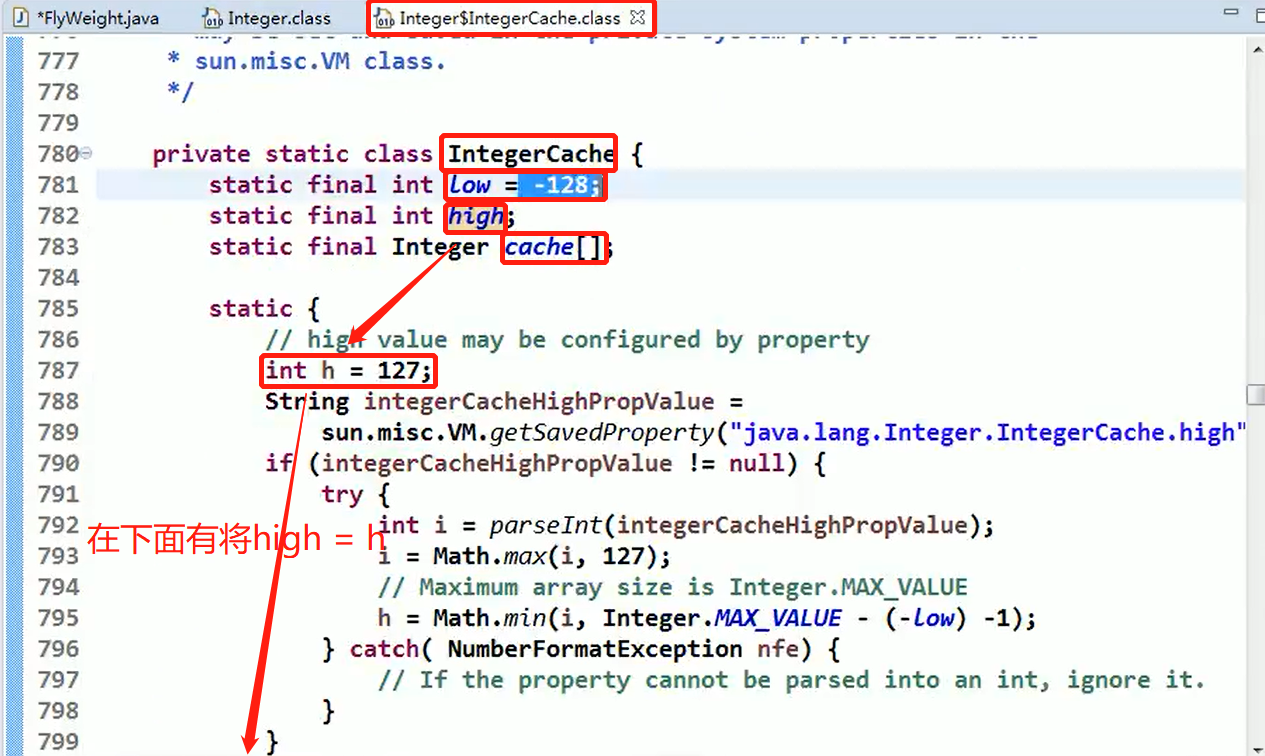
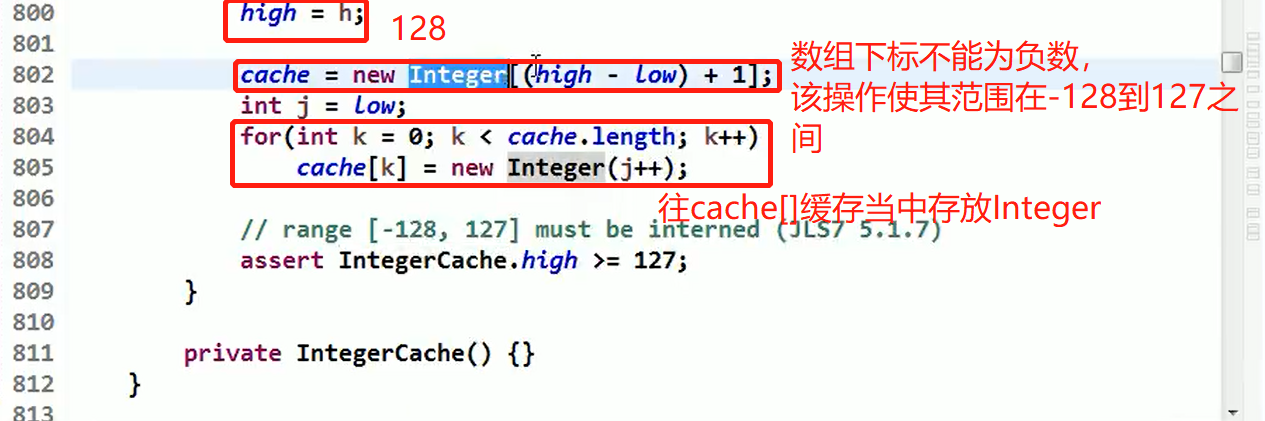
为什么使用Integer.valueOf(x)并且其参数 x 的范围在 -128 — 127 之间就是同一个对象,看源码:
Debug 源码+说明:
Integer:
Integer当中的IntegerCache:
14.5、享元模式总结
主要优点是
- 相同对象只要保存一份,这降低了系统中对象的数量,从而降低了系统中细粒度对象给内存带来的压力。
主要缺点是:
- 为了使对象可以共享,需要将一些不能共享的状态外部化,这将增加程序的复杂性。
- 享元模式提高了系统的复杂度。需要分离出内部状态和外部状态,而外部状态具有固有化的性质,不应该随着内部状态的变化而变化,否则会造成系统的混乱。这是我们使用享元模式需要注意的地方。
- 读取享元模式的外部状态会使得运行时间稍微变长。
享元模式的应用场景:
当系统中多处需要同一组信息时,可以把这些信息封装到一个对象中,然后对该对象进行缓存,这样,一个对象就可以提供给多出需要使用的地方,避免大量同一对象的多次创建,降低大量内存空间的消耗。
享元模式其实是工厂方法模式的一个改进机制,享元模式同样要求创建一个或一组对象,并且就是通过工厂方法模式生成对象的,只不过享元模式为工厂方法模式增加了缓存这一功能。
享元模式是通过减少内存中对象的数量来节省内存空间的,所以以下几种情形适合采用享元模式。
- 系统中存在大量相同或相似的对象,这些对象耗费大量的内存资源。
- 大部分的对象可以按照内部状态进行分组,且可将不同部分外部化,这样每一个组只需保存一个内部状态。
- 由于享元模式需要额外维护一个保存享元的数据结构(多为HashMap\HashTable),所以应当在有足够多的享元实例时才值得使用享元模式。
14.6、享元模式扩展
在前面介绍的享元模式中,其结构图通常包含可以共享的部分和不可以共享的部分。在实际使用过程中,有时候会稍加改变,即存在两种特殊的享元模式:单纯享元模式和复合享元模式
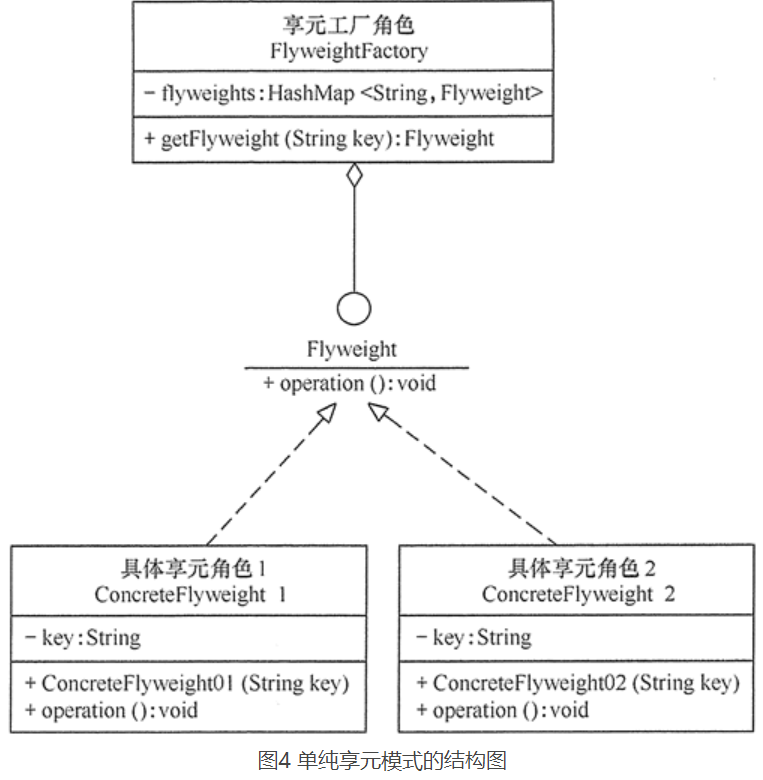
14.6.1、单纯享元模式
这种享元模式中的所有的具体享元类都是可以共享的,不存在非共享的具体享元类。如类图所示:
14.6.2、复合享元模式
这种享元模式中的有些享元对象是由一些单纯享元对象组合而成的,它们就是复合享元对象。虽然复合享元对象本身不能共享,但它们可以分解成单纯享元对象再被共享。如类图所示:
14.7、进阶阅读
如果您想深入了解享元模式,可猛击阅读以下文章。
14.8、相关设计模式
Proxy 模式
如果生成实例的处理需要花费较长时间, 那么使用 Flyweight 模式可以提高程序的处理速度。
而 Proxy 模式则是通过设置代理提高程序的处理速度。
Composite 模式
有时可以使用 Flyweight 模式共享 Composite 模式中的 Leaf 角色。
Singleton 模式
在 FlyweightFactory 角色中有时会使用 Singleton 模式。
此外如果使用了 Singleton 模式,由于只会生成一个 Singleton 角色,因此所有使用该实例的地方都共享同一个实例。 在 Singleton 角色的实例中只持有内部(固有)信息。
14.9、享元模式的注意事项与细节
- 在享元模式这样理解,“享”就表示共享,“元”表示对象
- 系统中有大量对象,这些对象消耗大量内存,并且对象的状态大部分可以外部化时,我们就可以考虑选用享元模式
- 用唯一标识码判断,如果在内存中有,则返回这个唯一标识码所标识的对象,用 HashMap/HashTable 存储
- 享元模式大大减少了对象的创建,降低了程序内存的占用,提高效率
- 享元模式提高了系统的复杂度。需要分离出内部状态和外部状态,而外部状态具有固有化的性质,不应该随着内部状态的变化而变化,否则会造成系统的混乱。这是我们使用享元模式需要注意的地方。
- 使用享元模式时,注意划分内部状态和外部状态,并且需要有一个工厂类加以控制。
- 在使用享元模式的时候要注意:不要让被共享的实例被垃圾回收机制(GC)回收了。
- 享元模式经典的应用场景是需要缓冲池的场景,比如 String 常量池、数据库连接池。
14.10、享元模式与单例模式的区别
单例模式是整个应用系统共用一个实例对象。
享元模式是整个系统共用好几个同类型对象。
连接池本身是单例模式,连接池里的多个连接对象是享元模式。
而且享元模式的共享对象是按需分配的,如果不够还会再创建!
而单例模式绝对不会重复创建第二个对象,这是本质不同!
享元模式里的共享对象在使用时一定是线程私有的。
就比如共享单车,虽然是共享的,但在使用时一定是只属于你的
享元模式的共享对象是有借有还的,在宏观上是共享的。
15、代理模式Proxy(结构型模式)
15.1、基本介绍
代理模式:为一个对象提供一个替身,以控制对这个对象的访问。即通过代理对象访问目标对象。这时,访问对象不适合或者不能直接引用目标对象,代理对象作为访问对象和目标对象之间的中介。
这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能。
被代理的对象可以是远程对象、创建开销大的对象或需要安全控制的对象
代理模式有不同的形式, 主要有三种:
- 静态代理模式:
- 静态代理在使用时,需要定义接口或者父类,被代理对象(即目标对象)与代理对象一起实现相同的接口或者是继承相同父类。
- 动态代理模式 (JDK 代理、接口代理):
- 代理对象不需要实现接口,但是目标对象要实现接口,否则不能用动态代理
- 代理对象的生成,是利用 JDK 的 API (反射),动态的在内存中构建代理对象
- 动态代理也叫做:JDK 代理、接口代理
- JDK 中生成代理对象的 API:
- 代理类所在包:java.lang.reflect.Proxy
- JDK 实现代理只需要使用 newProxyInstance 方法,但是该方法需要接收三个参数,完整的写法是:
- static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces,InvocationHandler h )
- ClassLoader loader : 指定当前目标对象使用的类加载器, 获取加载器的方法固定
- Class<?>[] interfaces: 目标对象实现的接口类型,使用泛型方法确认类型
- InvocationHandler h : 事情处理,执行目标对象的方法时,会触发事情处理器方法, 会把当前执行的目标对象方法作为参数传入
- Cglib 代理模式(可以在内存动态的创建对象,而不需要实现接口, 他是属于动态代理的范畴) :
- 静态代理和 JDK 代理模式都要求目标对象是实现一个接口,但是有时候目标对象只是一个单独的对象,并没有实现任何的接口,这个时候可使用目标对象子类来实现代理-这就是 Cglib 代理。
- Cglib 代理也叫作子类代理**,它是在内存中构建一个子类对象从而实现对目标对象功能扩展**, 有些书也将Cglib 代理归属到动态代理。
- Cglib 是一个强大的高性能的代码生成包,它可以在运行期扩展 java 类与实现 java 接口。它广泛的被许多 AOP 的框架使用,例如 Spring AOP,实现方法拦截
- 在 AOP 编程中如何选择代理模式:
- 目标对象需要实现接口,用 JDK 代理
- 目标对象不需要实现接口,用 Cglib 代理
- Cglib 包的底层是通过使用
字节码处理框架 ASM来转换字节码并生成新的类
- 静态代理模式:
代理模式总的类图:
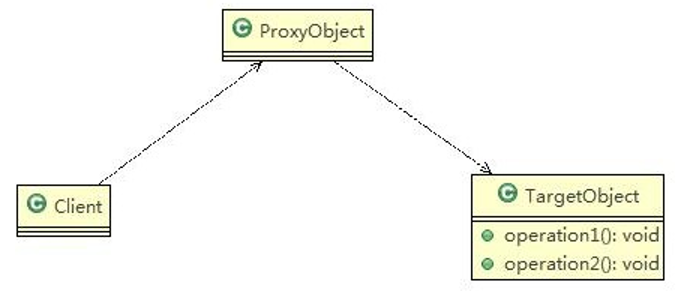
15.2、代理模式的原理结构图-uml类图
代理模式的主要角色如下:
- 抽象主题(Subject)类:通过接口或抽象类声明真实主题和代理对象实现的业务方法。
- 真实主题(Real Subject)类:实现了抽象主题中的具体业务,是代理对象所代表的真实对象,是最终要引用的对象。
- 代理(Proxy)类:提供了与真实主题相同的接口,其内部含有对真实主题的引用,它可以访问、控制或扩展真实主题的功能。
15.2.1、静态代理模式
相关类图:
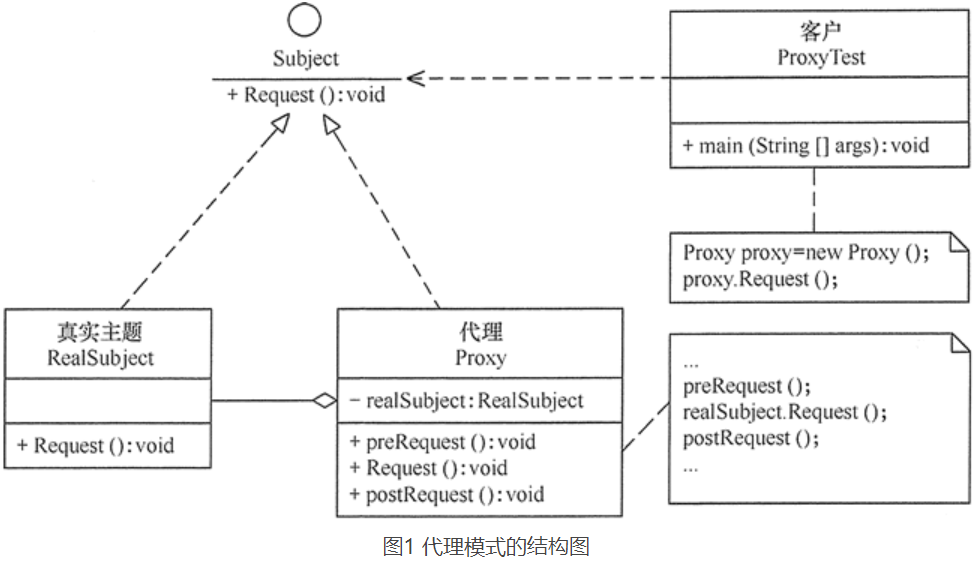
代码实现:
1 | package proxy; |
15.2.2、JDK动态代理模式
相关类图: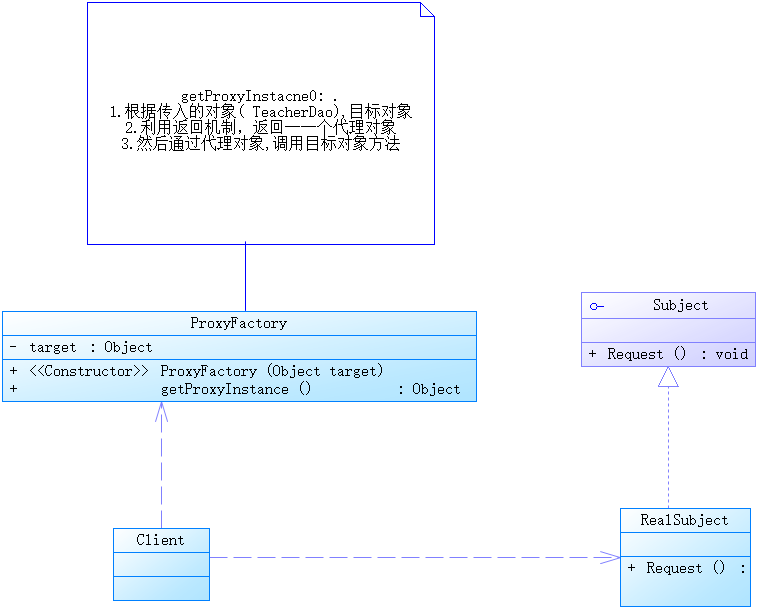
执行原理:
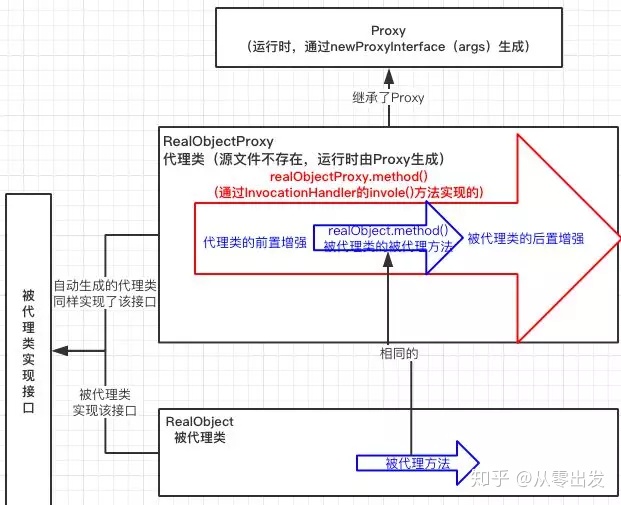
代码实现:
1 | public class Client { |
15.2.3、Cglib代理模式
相关类图:
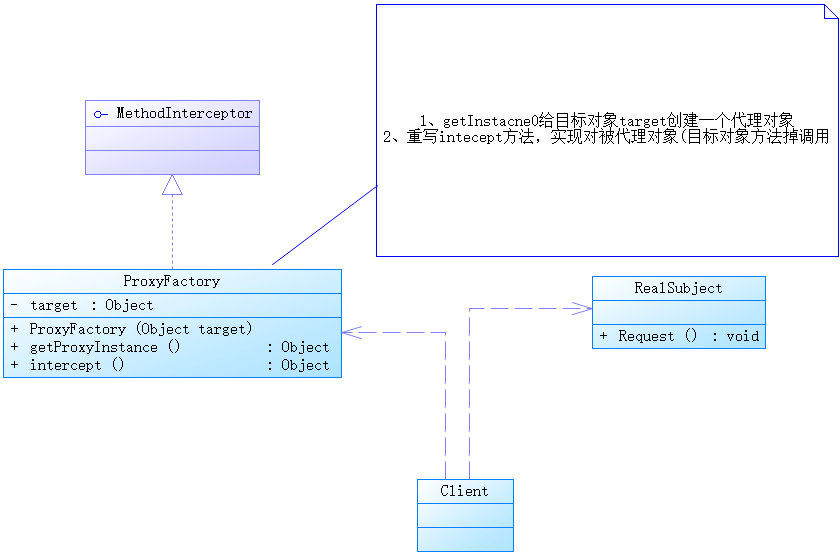
执行原理: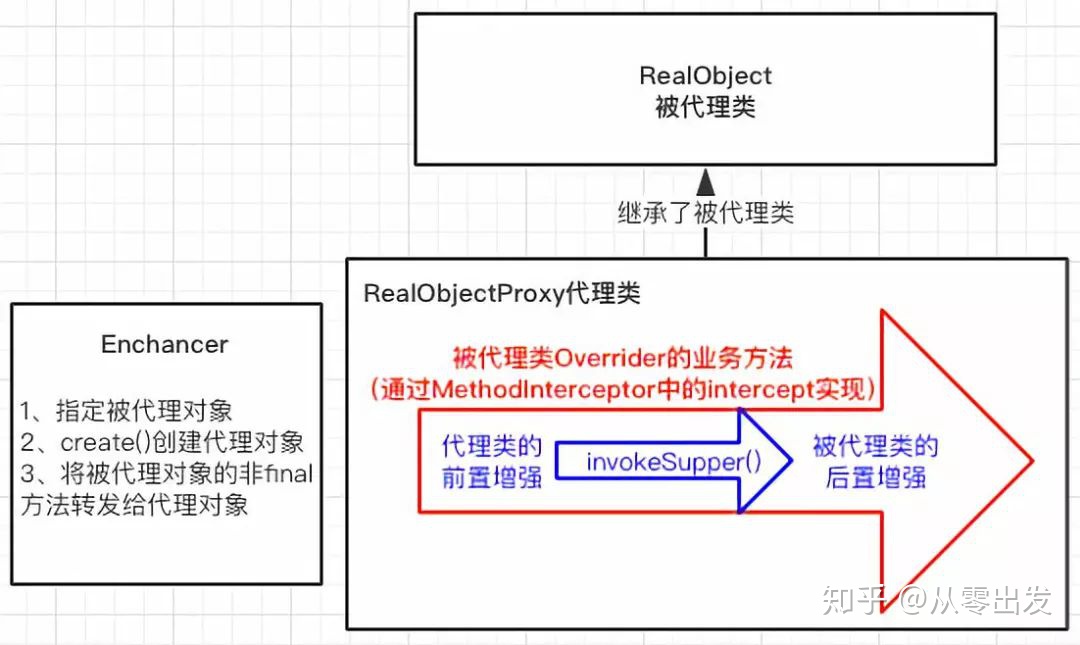
代码实现:
1 | public class Client { |
15.3、应用举例
具体要求:
- 定义一个接口:ITeacherDao
- 目标对象 TeacherDAO 实现接口 ITeacherDAO
- 使用静态代理方式,就需要在代理对象 TeacherDAOProxy 中也实现 ITeacherDAO
- 调用的时候通过调用代理对象的方法来调用目标对象.
15.3.1、使用静态代理模式解决需求
思路分析图解(类图):
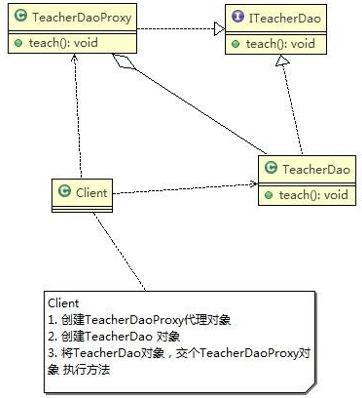
实现代码:
ITeacherDao:教师操作接口。抽象主题(Subject)类
1 | //接口 |
TeacherDao:教师操作接口实现类。真实主题(Real Subject)类
1 | public class TeacherDao implements ITeacherDao { |
TeacherDaoProxy:教师操作代理对象。代理(Proxy)类
1 | //代理对象,静态代理 |
Client:调用方。
1 | public class Client { |
15.3.2、使用动态代理模式解决需求
思路分析图解(类图):
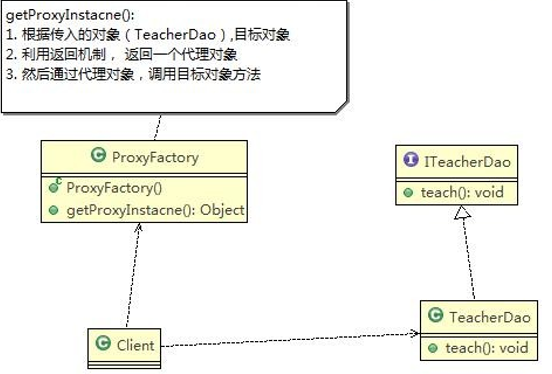
代码实现:
ITeacherDao:教师操作接口。抽象主题(Subject)类
1 | //接口 |
TeacherDao:教师操作接口实现类。真实主题(Real Subject)类
1 | public class TeacherDao implements ITeacherDao { |
ProxyFactory:代理工厂,用来生成代理对象。生成的对象:代理(Proxy)类
1 | import java.lang.reflect.InvocationHandler; |
Client:调用方。
1 | public class Client { |
15.3.3、使用cglib代理模式解决需求
思路分析图解(类图):
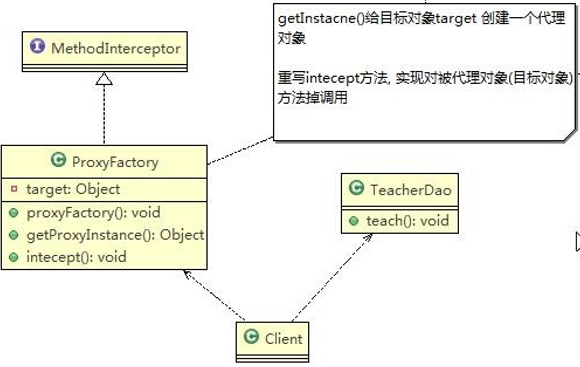
代码实现:
TeacherDao:教师操作类。真实主题(Real Subject)类
1 | public class TeacherDao { |
ProxyFactory:代理工厂,实现cglib的MethodInterceptor接口,用来生成代理对象。生成的对象:代理(Proxy)类
1 | import java.lang.reflect.Method; |
Client:调用方。
1 | public class Client { |
15.4、代理模式总结
15.4.1、静态代理优缺点
- 优点:
- 在不修改目标对象的功能前提下, 能通过代理对象对目标功能扩展
- 缺点:
- 因为代理对象需要与目标对象实现一样的接口,所以会有很多代理类
- 一旦接口增加方法,目标对象与代理对象都要维护
15.4.2、JDK动态代理优缺点
- 优点:
- JDK原声动态代理时java原声支持的、不需要任何外部依赖
- 缺点:
- 但是它只能基于接口进行代理(因为它已经继承了proxy了,java不支持多继承)
15.4.3、Cglib动态代理优缺点
优点:
- CGLIB通过继承的方式进行代理、无论目标对象没有没实现接口都可以代理
缺点:
需要引入 cglib 的 jar 文件
在内存中动态构建子类,注意代理的类不能为 final,否则报错java.lang.IllegalArgumentException:
目标对象的方法如果为 final/static,那么就不会被拦截,即不会执行目标对象额外的业务方法。(final修饰的方法不能被覆写)
15.4.4、两种动态代理模式的对比(JDK VS CGLIB)
| JDK原生动态代理 | CGLB动态代理 | |
|---|---|---|
| 核心原理 | 基于”接口实现”方式 | 基于类集成方式 |
| 优点 | Java原生支持的,不需要任何依赖 | 对与代理的目标对象无限制,无需实现接口 |
| 不足之处 | 只能基于接口进行实现 | 无法处理final方法 |
| 实现方式 | Java原生支持,不需要任何依赖 | 需要引用JAR包cglib-nodep-3.2.5.jar和asm.jar |
15.4.5、代理模式总结
主要优点有:
- 代理模式在客户端与目标对象之间起到一个中介作用和保护目标对象的作用;
- 代理对象可以扩展目标对象的功能;
- 代理模式能将客户端与目标对象分离,在一定程度上降低了系统的耦合度,增加了程序的可扩展性
主要缺点是(有些缺点可通过动态代理解决):
- 代理模式会造成系统设计中类的数量增加
- 在客户端和目标对象之间增加一个代理对象,会造成请求处理速度变慢;
- 增加了系统的复杂度;
应用场景:
当无法或不想直接引用某个对象或访问某个对象存在困难时,可以通过代理对象来间接访问。使用代理模式主要有两个目的:一是保护目标对象,二是增强目标对象。
远程代理:
- 远程代理即Remote Proxy,本地的调用者持有的接口实际上是一个代理,这个代理负责把对接口的方法访问转换成远程调用,然后返回结果。
- 这种方式通常是为了隐藏目标对象存在于不同地址空间的事实,方便客户端访问。例如,用户申请某些网盘空间时,会在用户的文件系统中建立一个虚拟的硬盘,用户访问虚拟硬盘时实际访问的是网盘空间。
- Java内置的RMI机制就是一个完整的远程代理模式。
虚拟代理:
- 虚代理即Virtual Proxy,它让调用者先持有一个代理对象,但真正的对象尚未创建。如果没有必要,这个真正的对象是不会被创建的,直到客户端需要真的必须调用时,才创建真正的对象。
- 这种方式通常用于要创建的目标对象开销很大时。例如,下载一幅很大的图像需要很长时间,因某种计算比较复杂而短时间无法完成,这时可以先用小比例的虚拟代理替换真实的对象,消除用户对服务器慢的感觉。
- JDBC的连接池返回的JDBC连接(Connection对象)就可以是一个虚代理,即获取连接时根本没有任何实际的数据库连接,直到第一次执行JDBC查询或更新操作时,才真正创建实际的JDBC连接。
保护代理:
- 保护代理即Protection Proxy,它用代理对象控制对原始对象的访问,常用于鉴权。
- 这种方式通常用于控制不同种类客户对真实对象的访问权限。
智能引用:
- 智能引用即Smart Reference,它也是一种代理对象,如果有很多客户端对它进行访问,通过内部的计数器可以在外部调用者都不使用后自动释放它。
- 主要用于调用目标对象时,代理附加一些额外的处理功能。例如,增加计算真实对象的引用次数的功能,这样当该对象没有被引用时,就可以自动释放它。
延迟加载:
- 延迟加载即Cache缓存代理。指为了提高系统的性能,延迟对目标的加载。例如,Hibernate 中就存在属性的延迟加载和关联表的延时加载。
- 当请求图片文件等资源时,先到缓存代理取,如果取到资源则 ok,如果取不到资源,再到公网或者数据库取,然后缓存。
防火墙(Firewall)代理:内网通过代理穿透防火墙,实现对公网的访问。
同步化(Synchronization)代理:主要使用在多线程编程中,完成多线程间同步工作
Copy-on-Write 代理:它是虚拟代理的一种,把复制(克隆)操作延迟到只有在客户端真正需要时才执行。一般来说,对象的深克隆是一个开销较大的操作,Copy-on-Write代理可以让这个操作延迟,只有对象被用到的时候才被克隆。
Immer提供了一种更方便的不可变状态操作方式。详情:Copy-on-write + Proxy = ?
其方便之处主要体现在:
- 只有一个(核心)API:
produce(currentState, producer: (draftState) => void): nextState - 不引入额外的数据结构:没有 List、Map、Set 等任何自定义数据结构,因此也不需要特殊的相等性比较方法
- 数据操作完全基于类型:用纯原生 API 操作数据,符合直觉
- 只有一个(核心)API:
应用实际:
- spring aop
- 我们实际使用的DataSource,例如HikariCP,都是基于代理模式实现的,原理同上,但增加了更多的如动态伸缩的功能(一个连接空闲一段时间后自动关闭)。
- 买火车票不一定在火车站买,也可以去代售点。
- 一张支票或银行存单是账户中资金的代理。支票在市场交易中用来代替现金,并提供对签发人账号上资金的控制。
15.5、代理模式扩展
动态代理的一种实现类图:
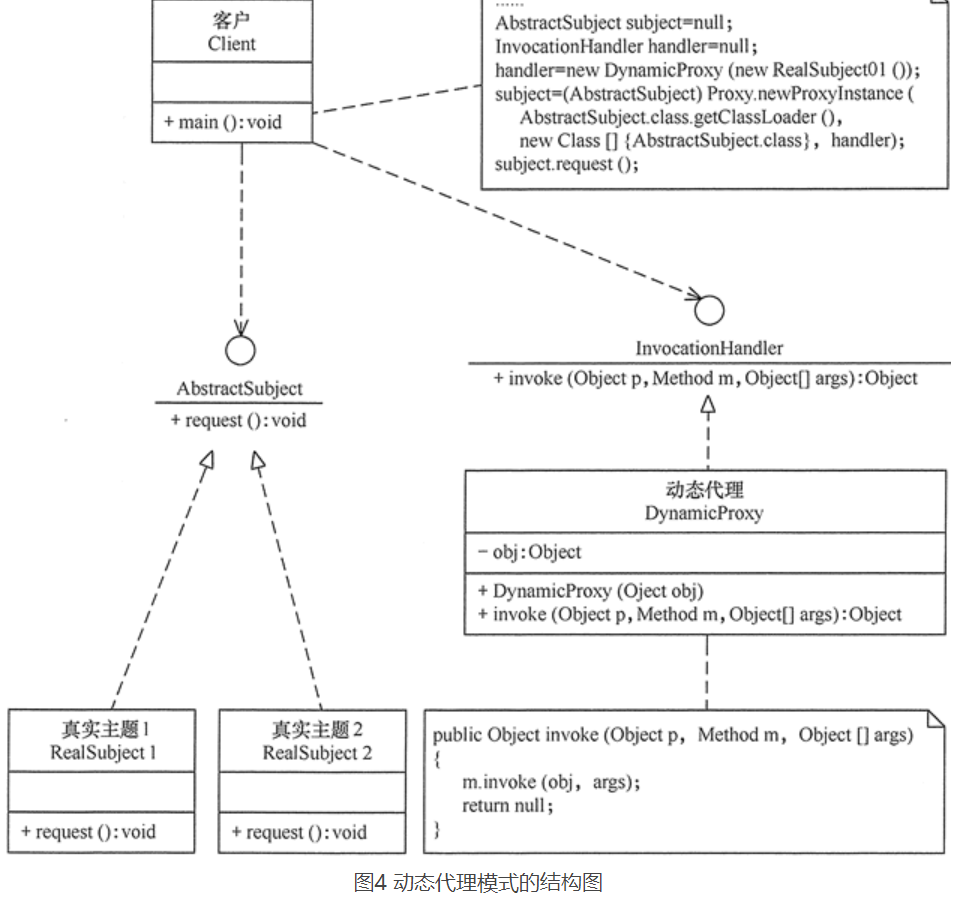
15.6、进阶阅读
如果您想深入了解代理模式,可猛击阅读以下文章。
15.7、相关设计模式
Adapter 模式:
Adapter 模式适配了两种具有不同接口 (API) 的对象,以使它们可以一同工作。而在 Proxy 模式中,Proxy 角色与Rea)Subject 角色的接口 (API) 是相同的(透明性)。
Decorator 模式:
Decorator 模式与 Proxy 模式在实现上很相似.不过它们的使用目的不同。
Decorator 模式的目的在于增加新的功能。而在 Proxy 模式中,与增加新功能相比,它更注重通过设置代理人的方式来减轻本人的工作负担。
15.8、代理模式与其他模式的区别
15.8.1、Proxy模式VSDecorator模式
- Decorator模式让调用者自己创建核心类,然后组合各种功能
- Proxy模式决不能让调用者自己创建再组合,否则就失去了代理的功能
- Proxy模式让调用者认为获取到的是核心类接口,但实际上是代理类。
- 装饰器模式为了增强功能,而代理模式是为了加以控制。
15.8.2、Proxy模式VSAdapter模式
- 适配器模式主要改变所考虑对象的接口
- 代理模式不能改变所代理类的接口
15.9、代理模式的注意事项与细节
- 代理模式通过封装一个已有接口,并向调用方返回相同的接口类型,能让调用方在不改变任何代码的前提下增强某些功能(例如,鉴权、延迟加载、连接池复用等)。
- 静态代理模式:代理对象与目标对象(被代理对象)都实现同一个接口或者继承同一个抽象类
- JDK动态代理模式:目标对象(被代理对象)需要实现接口或继承抽象类,而代理对象不用,它由一个代理工厂来生产
- CGLIB动态代模式:目标对象(被代理对象)不需要实现接口或继承抽象类,但是用来生产代理对象的代理工厂需要实现cglib的MethodInterceptor接口。
16、模板方法模式Template Method(行为型模式)
16.1、基本介绍
- 模板方法模式(Template Method Pattern),又叫模板模式(Template Pattern)**,在一个抽象类公开定义了执行它的方法的模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行**。
- 简单说,模板方法模式定义一个操作中的算法的骨架,而将一些步骤延迟到子类中,使得子类可以不改变一个算法的结构,就可以重定义该算法的某些特定步骤
- 模板方法的核心思想是:父类定义骨架,子类实现某些细节。
- 这种类型的设计模式属于行为型模式。
16.2、模板方法模式的原理结构图-uml类图
模板方法模式需要注意抽象类与具体子类之间的协作。它用到了虚函数的多态性技术以及“不用调用我,让我来调用你”的反向控制技术。
16.2.1、模式的结构
模板方法模式包含以下主要角色:
- 抽象类/抽象模板(Abstract Class)
- 抽象模板类,负责给出一个算法的轮廓和骨架。它由一个模板方法和若干个基本方法构成。这些方法的定义如下:
- 模板方法:定义了算法的骨架,按某种顺序调用其包含的基本方法。
- 基本方法:是整个算法中的一个步骤,包含以下几种类型:
- 抽象方法:在抽象类中声明,由具体子类实现。
- 具体方法:在抽象类中已经实现,在具体子类中可以继承或重写它。
- 钩子方法:在抽象类中已经实现,我们可以定义一个方法,它默认不做任何事,子类可以视情况要不要覆盖它。包括用于判断的逻辑方法和需要子类重写的空方法两种。
- 抽象模板类,负责给出一个算法的轮廓和骨架。它由一个模板方法和若干个基本方法构成。这些方法的定义如下:
- 具体子类/具体实现(Concrete Class):具体实现类,实现抽象类中所定义的抽象方法和钩子方法,它们是一个顶级逻辑的一个组成步骤。
相关类图:
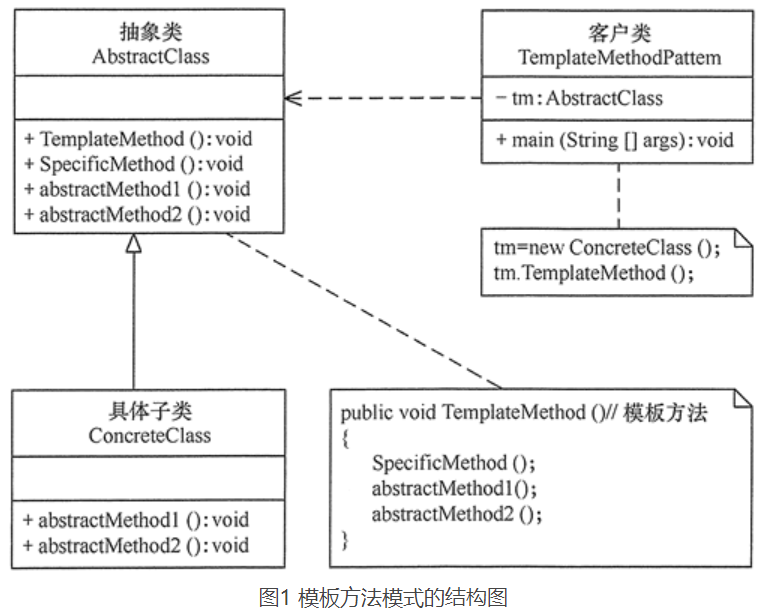
16.2.2、模式的实现
1 | public class TemplateMethodPattern { |
16.3、应用举例
豆浆制作问题:
编写制作豆浆的程序,说明如下:
- 制作豆浆的流程 选材—>添加配料—>浸泡—>放到豆浆机打碎
- 通过添加不同的配料,可以制作出不同口味的豆浆
- 也可以不添加配料,制作纯豆浆(钩子方法)
- 选材、浸泡和放到豆浆机打碎这几个步骤对于制作每种口味的豆浆都是一样的
- 请使用模板方法模式完成
思路分析和图解(类图):

代码实现:
SoyaMilk:制作豆浆的抽象类。抽象类/抽象模板(Abstract Class)
1 | //抽象类,表示豆浆 |
RedBeanSoyaMilk:红豆豆浆。具体子类/具体实现(Concrete Class)(PeanutSoyaMilk等等其他豆浆类似)
1 | public class RedBeanSoyaMilk extends SoyaMilk { |
PureSoyaMilk:纯豆浆。具体子类/具体实现(Concrete Class)(钩子方法)
1 | public class PureSoyaMilk extends SoyaMilk{ |
Client:调用制作豆浆。客户端
1 | public class Client { |
16.4、模板方法模式在Spring框架的应用与源码
Spring IOC 容器初始化时运用到的模板方法模式
代码分析+角色分析+说明类图:
16.4.1、说明类图
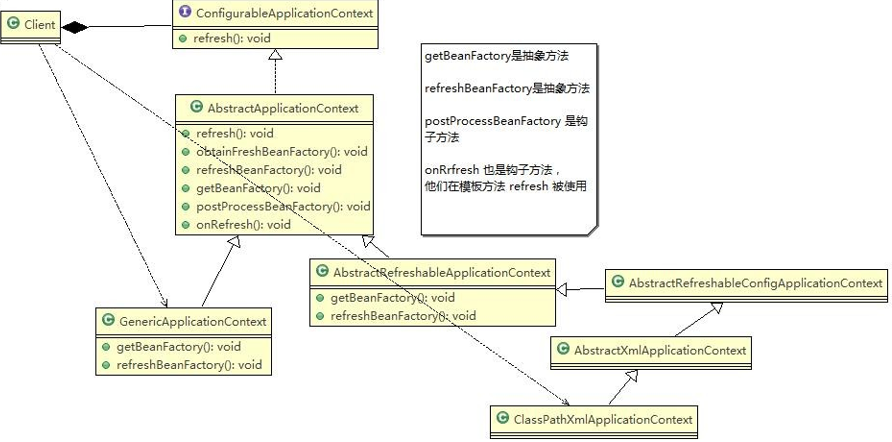
16.4.2、角色分析
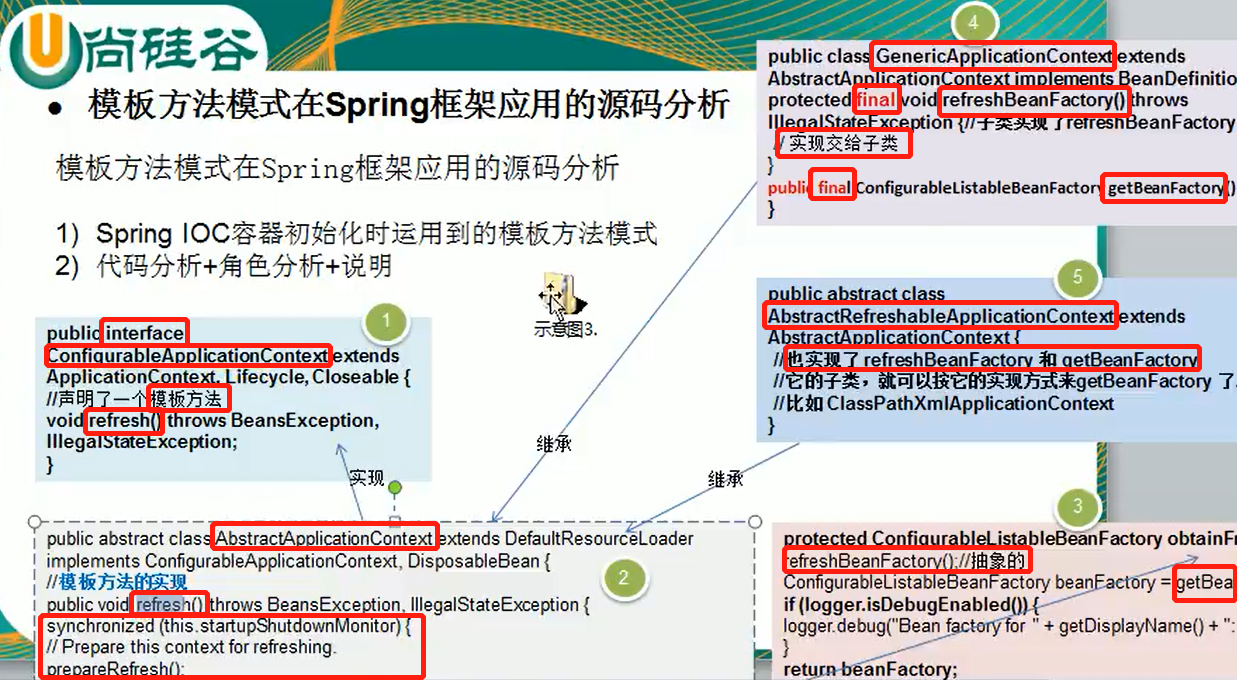

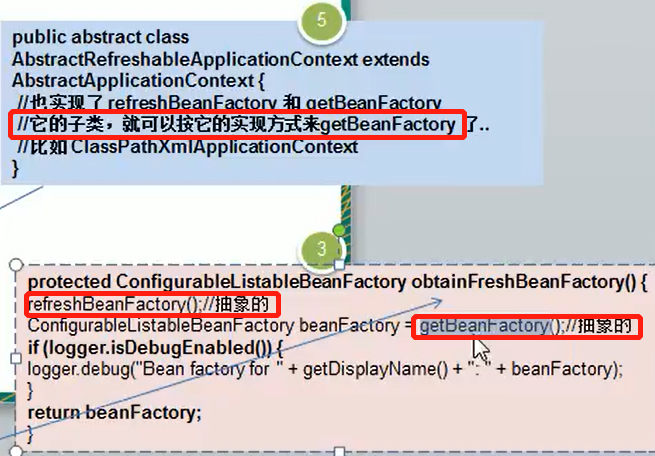
16.4.3、代码分析
ConfigurableApplicationContext接口与refresh()抽象模板方法


AbstractApplicationContext抽象类实现了ConfigurableApplicationContext接口,并对refresh()模板方法进行了重写
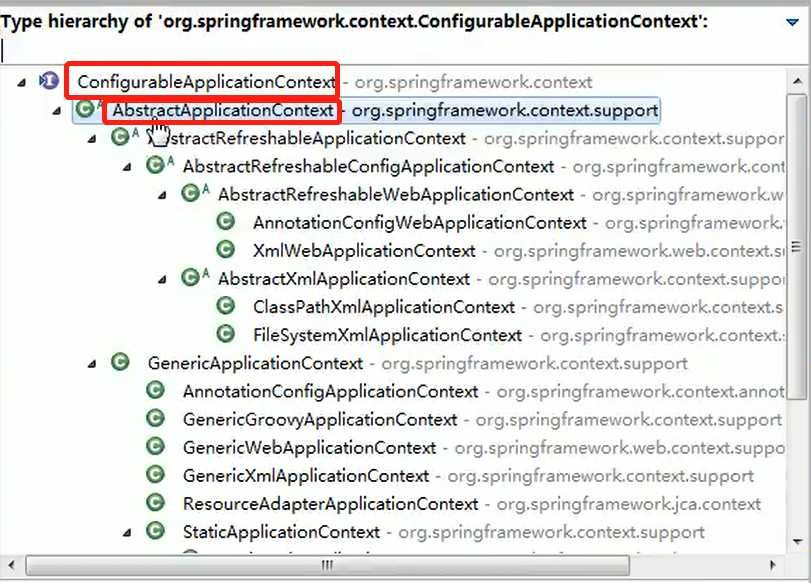

refresh()模板方法:
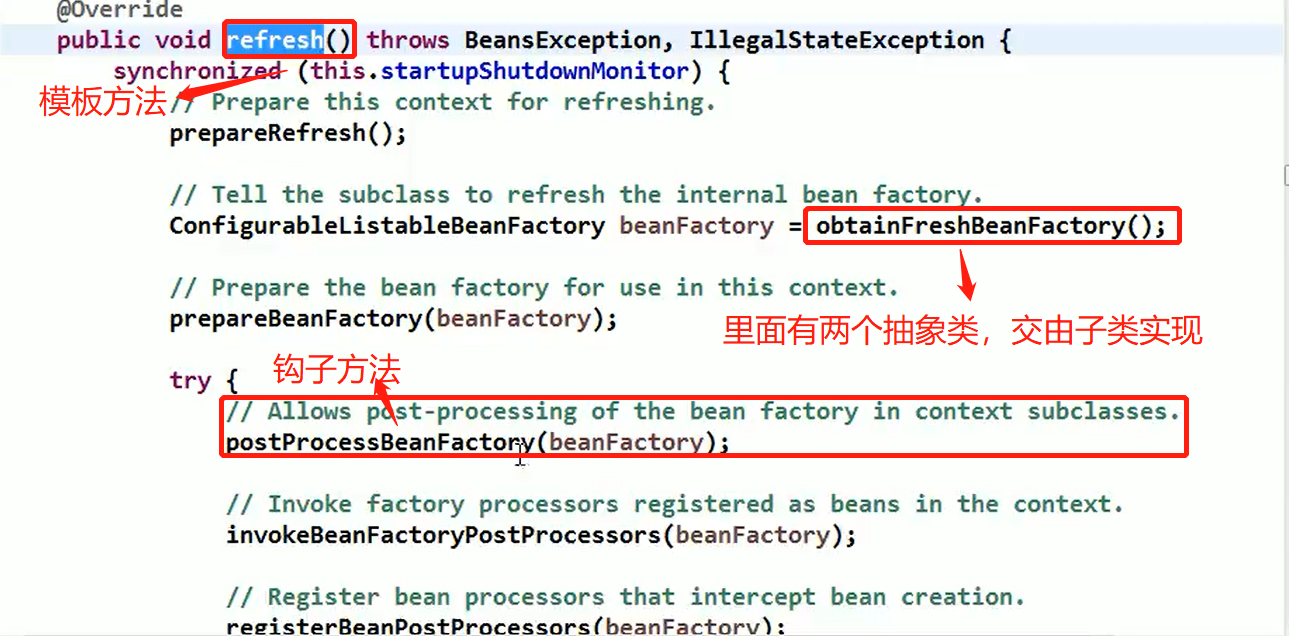
refresh()模板方法当中的obtainFreshBeanFactory()方法

refresh()模板方法当中的钩子方法postProcessBeanFactory()与onRefresh()
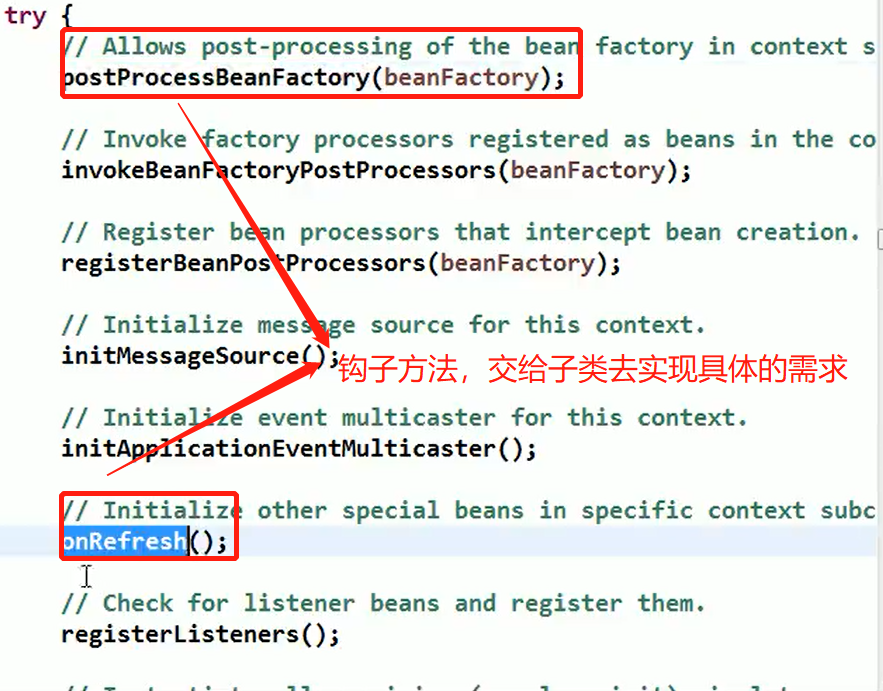

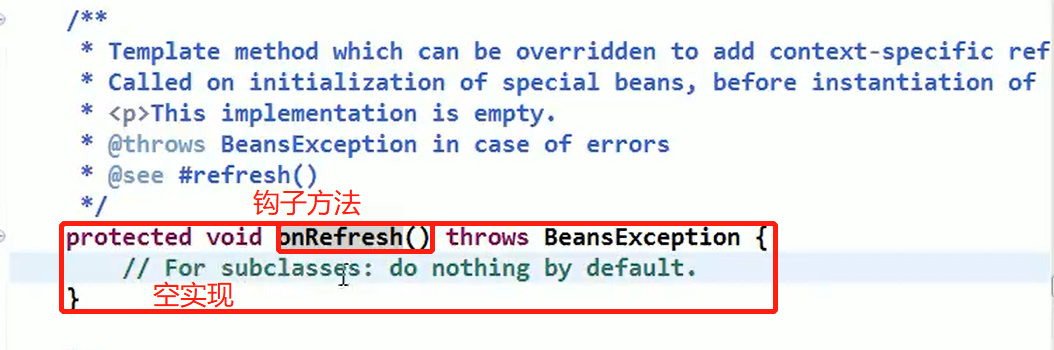
GenericApplicationContext类继承了AbstractApplicationContext抽象类,对父类的getBeanFactory()与refreshBeanFactory()抽象方法进行重写
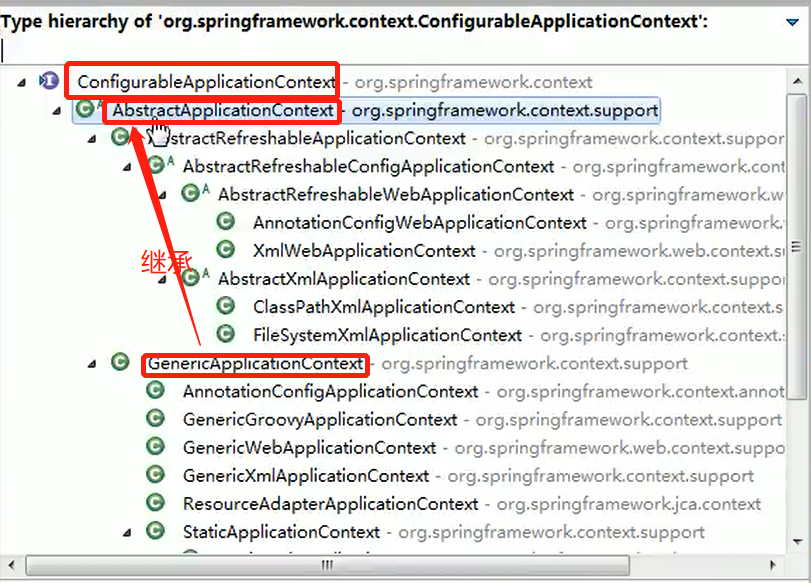
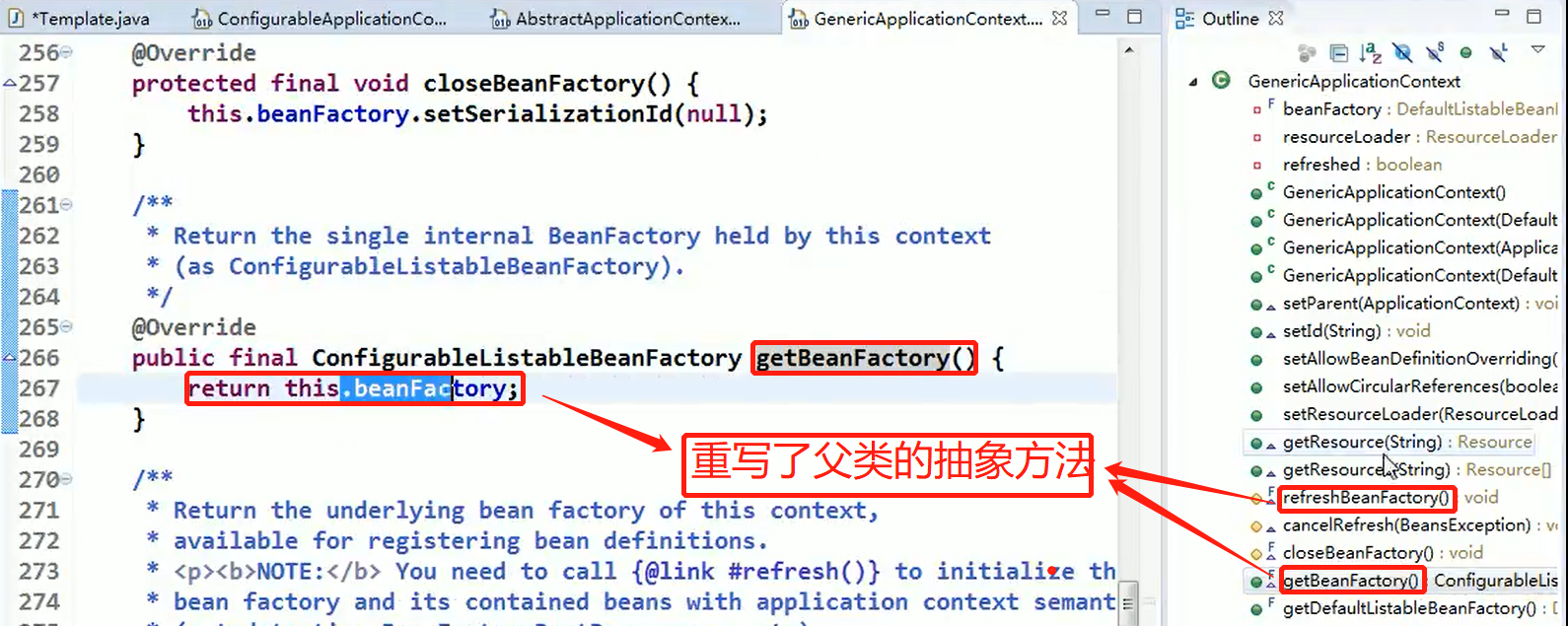
XmlWebApplicationContext类、ClassPathXmlApplicationContext类等等子类继承了各自的父类。最好按照父类定义好的模板去实现对应的需求。
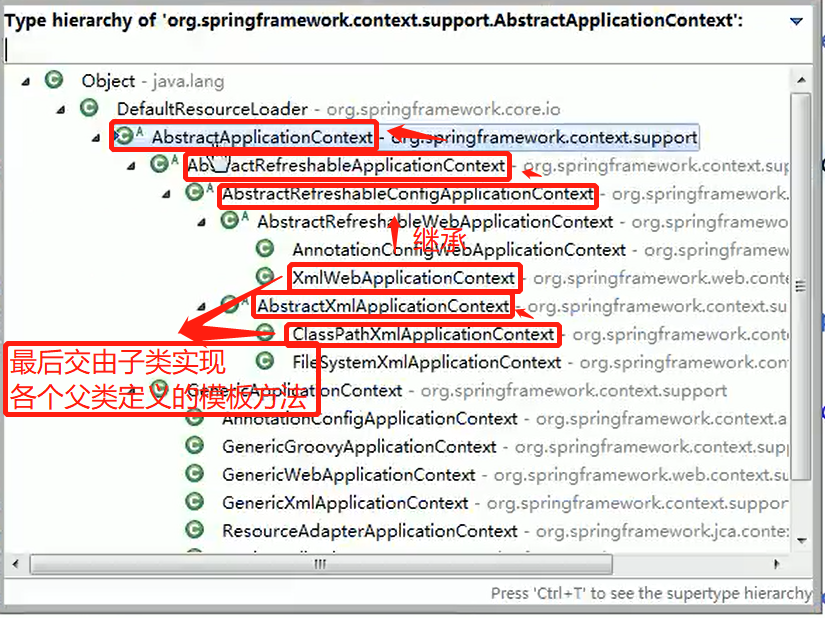
16.5、模板方法模式总结
主要优点:
- 它封装了不变部分,扩展可变部分。它把认为是不变部分的算法封装到父类中实现,而把可变部分算法由子类继承实现,便于子类继续扩展。
- 它在父类中提取了公共的部分代码,便于代码复用。
- 部分方法是由子类实现的,因此子类可以通过扩展方式增加相应的功能,符合开闭原则。
主要缺点:
- 对每个不同的实现都需要定义一个子类,这会导致类的个数增加,系统更加庞大,设计也更加抽象,间接地增加了系统实现的复杂度。
- 父类中的抽象方法由子类实现,子类执行的结果会影响父类的结果,这导致一种反向的控制结构,它提高了代码阅读的难度。
- 由于继承关系自身的缺点,如果父类添加新的抽象方法,则所有子类都要改一遍。
模式的应用场景:
- 算法的整体步骤很固定,但其中个别部分易变时,这时候可以使用模板方法模式,将容易变的部分抽象出来,供子类实现。
- 当多个子类存在公共的行为时,可以将其提取出来并集中到一个公共父类中以避免代码重复。首先,要识别现有代码中的不同之处,并且将不同之处分离为新的操作。最后,用一个调用这些新的操作的模板方法来替换这些不同的代码。
- 当需要控制子类的扩展时,模板方法只在特定点调用钩子操作,这样就只允许在这些点进行扩展。
应用实例:
- 在造房子的时候,地基、走线、水管都一样,只有在建筑的后期才有加壁橱加栅栏等差异
- spring 中对 Hibernate 的支持,将一些已经定好的方法封装起来,比如开启事务、获取 Session、关闭 Session 等,程序员不重复写那些已经规范好的代码,直接丢一个实体就可以保存。
16.6、模板方法模式扩展
在模板方法模式中,基本方法包含:抽象方法、具体方法和钩子方法,正确使用“钩子方法”可以使得子类控制父类的行为。如下面例子中,可以通过在具体子类中重写钩子方法 HookMethod1() 和 HookMethod2() 来改变抽象父类中的运行结果,其结构图:
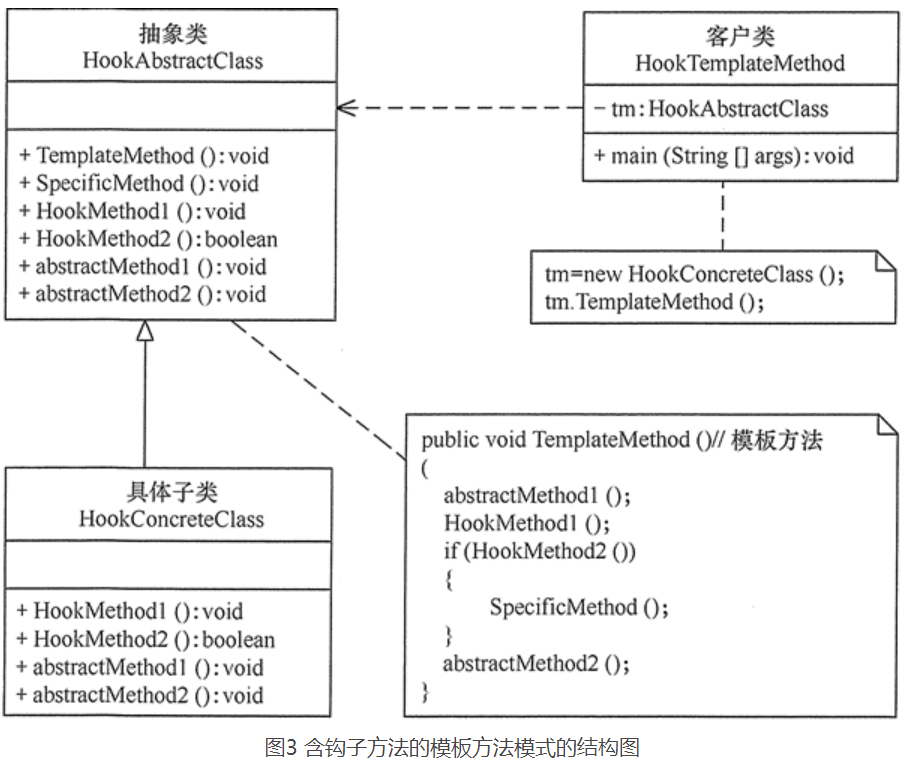
代码实现:
1 | public class HookTemplateMethod { |
如果钩子方法 HookMethod1() 和钩子方法 HookMethod2() 的代码改变,则程序的运行结果也会改变。
16.7、进阶阅读
如果您想深入了解模板方法模式,可猛击阅读以下文章。
16.8、相关设计模式
Factory Method 模式
Factory Method模式是将Template Method模式用于生成实例的一个典型例子。
Strategy 模式
在Template Method模式中, 可以使用继承改变程序的行为。 这是因为Template Method模式在父类中定义程序行为的框架.在子类中决定具体的处理。
与此相对的是Strategy模式 , 它可以使用委托改变程序的行为。 与Template Method模式中改 变部分程序行为不同的是,Strategy模式用于替换整个算法。
16.9、模板方法模式的注意事项与细节
- 基本思想是:算法只存在于一个地方,也就是在父类中,容易修改。需要修改算法时,只要修改父类的模板方法或者已经实现的某些步骤,子类就会继承这些修改。
- 实现了最大化代码复用。父类的模板方法和已实现的某些步骤会被子类继承而直接使用。
- 既统一了算法,也提供了很大的灵活性。父类的模板方法确保了算法的结构保持不变,同时由子类提供部分步骤的实现。
- 该模式的不足之处:每一个不同的实现都需要一个子类实现,导致类的个数增加,使得系统更加庞大
- 一般模板方法都加上
final关键字, 防止子类重写模板方法。 - 模板方法模式使用场景:当要完成在某个过程,该过程要执行一系列步骤 ,这一系列的步骤基本相同,但其个别步骤在实现时可能不同,通常考虑用模板方法模式来处理
- 模板方法是一种高层定义骨架,底层实现细节的设计模式,适用于流程固定,但某些步骤不确定或可替换的情况。
17、命令模式Command(行为型模式)
17.1、基本介绍
- 命令(Command)模式的定义如下:将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。这样两者之间通过命令对象进行沟通,这样方便将命令对象进行储存、传递、调用、增加与管理。
- 命令模式(Command Pattern):在软件设计中,我们经常需要向某些对象发送请求,但是并不知道请求的接收者是谁,也不知道被请求的操作是哪个,我们只需在程序运行时指定具体的请求接收者即可,此时,可以使用命令模式来进行设计
- 命名模式使得请求发送者与请求接收者消除彼此之间的耦合,让对象之间的调用关系更加灵活,实现解耦。
- 在命名模式中,会将一个请求封装为一个对象,以便使用不同参数来表示不同的请求(即命名)**,同时命令模式也支持可撤销**的操作。
- 通俗易懂的理解:将军发布命令,士兵去执行。其中有几个角色:将军(命令发布者)、士兵(命令的具体执行者)、命令(连接将军和士兵)。Invoker 是调用者(将军),Receiver 是被调用者(士兵),MyCommand 是命令,实现了 Command 接口,持有接收对象
17.2、命令模式的原理结构图-uml类图
17.2.1、模式的结构
命令模式包含以下主要角色。
- 抽象命令类(Command)角色:是命令角色,需要执行的所有命令都在这里,拥有执行命令的抽象方法 execute(),可以是接口或抽象类
- 具体命令类(Concrete Command)角色:是抽象命令类的具体实现类,它拥有接收者对象,并通过调用接收者的功能来完成命令要执行的操作。将一个接受者对象与一个动作绑定,调用接受者相应的操作,实现 execute
- 实现者/接收者(Receiver)角色:执行命令功能的相关操作,是具体命令对象业务的真正实现者。
- 调用者/请求者(Invoker)角色:是请求的发送者,它通常拥有很多的命令对象,并通过访问命令对象来执行相关请求,它不直接访问接收者。
其结构图如图:
173.2.2、模式的实现
1 | package command; |
17.3、应用举例
17.1 智能生活项目需求
- 我们买了一套智能家电,有照明灯、风扇、冰箱、洗衣机,我们只要在手机上安装 app 就可以控制对这些家电工作。
- 这些智能家电来自不同的厂家,我们不想针对每一种家电都安装一个 App,分别控制,我们希望只要一个app就可以控制全部智能家电。
- 要实现一个 app 控制所有智能家电的需要,则每个智能家电厂家都要提供一个统一的接口给 app 调用,这时 就可以考虑使用命令模式。
- 命令模式可将“动作的请求者”从“动作的执行者”对象中解耦出来.
- 在我们的例子中,动作的请求者是手机 app,动作的执行者是每个厂商的一个家电产
- 编写程序,使用命令模式完成前面的智能家电项目
思路分析和图解
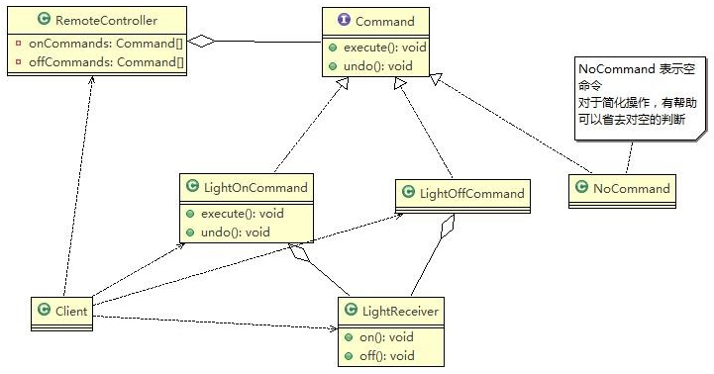
代码实现:
Command:命令接口。抽象命令类(Command)角色
1 | //创建命令接口 |
LightReceiver:电灯接受者。实现者/接收者(Receiver)角色
1 | public class LightReceiver { |
LightOnCommand:打开电灯的操作。具体命令类(Concrete Command)角色
1 | public class LightOnCommand implements Command { |
LightOffCommand:关闭电灯的操作。具体命令类(Concrete Command)角色
1 | public class LightOffCommand implements Command { |
NoCommand:空命令。具体命令类(Concrete Command)角色
1 | /** |
RemoteController:遥控器。调用者/请求者(Invoker)角色
1 | public class RemoteController { |
Client:客户端。调用遥控器RemoteController
1 | public class Client { |
17.4、命令模式在Spring框架的应用与源码
Spring 框架的 JdbcTemplate 就使用到了命令模式
代码分析:

具体代码:
JdbcTemplate类的query方法
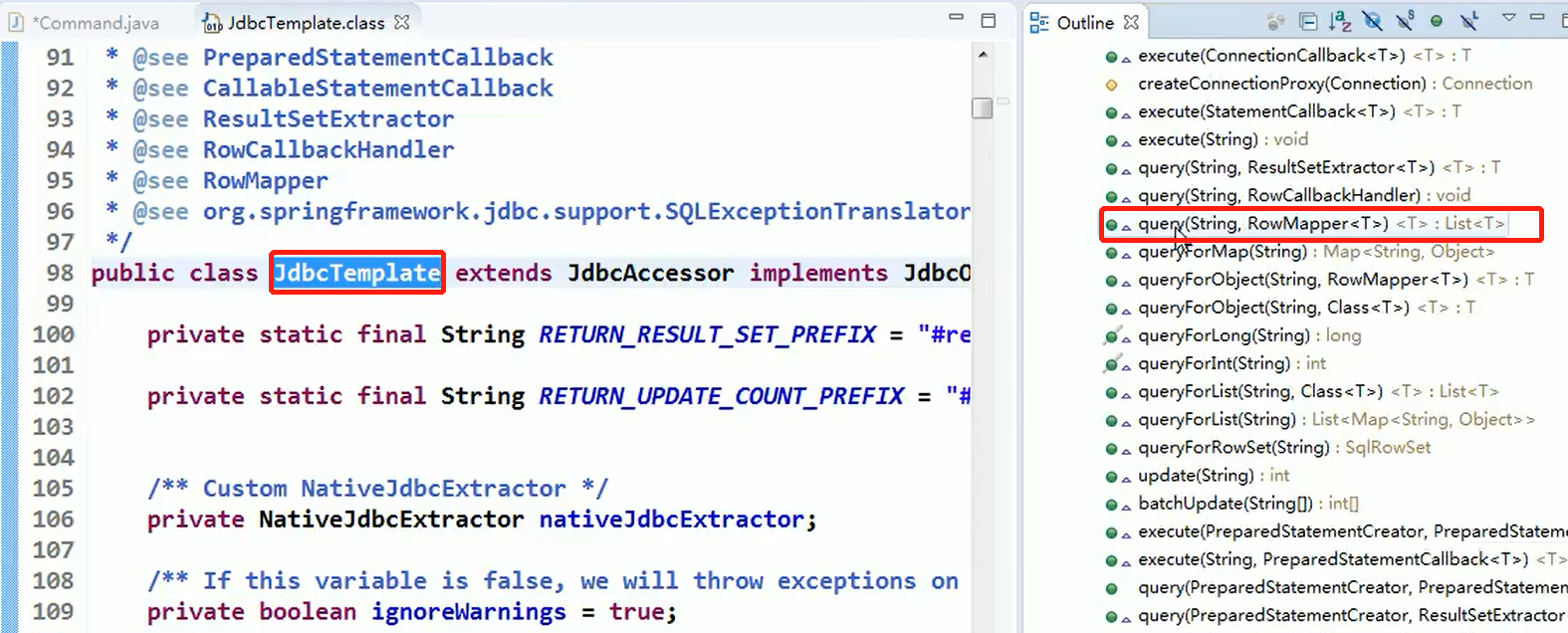
在query方法使用递归调用了query方法

query方法:
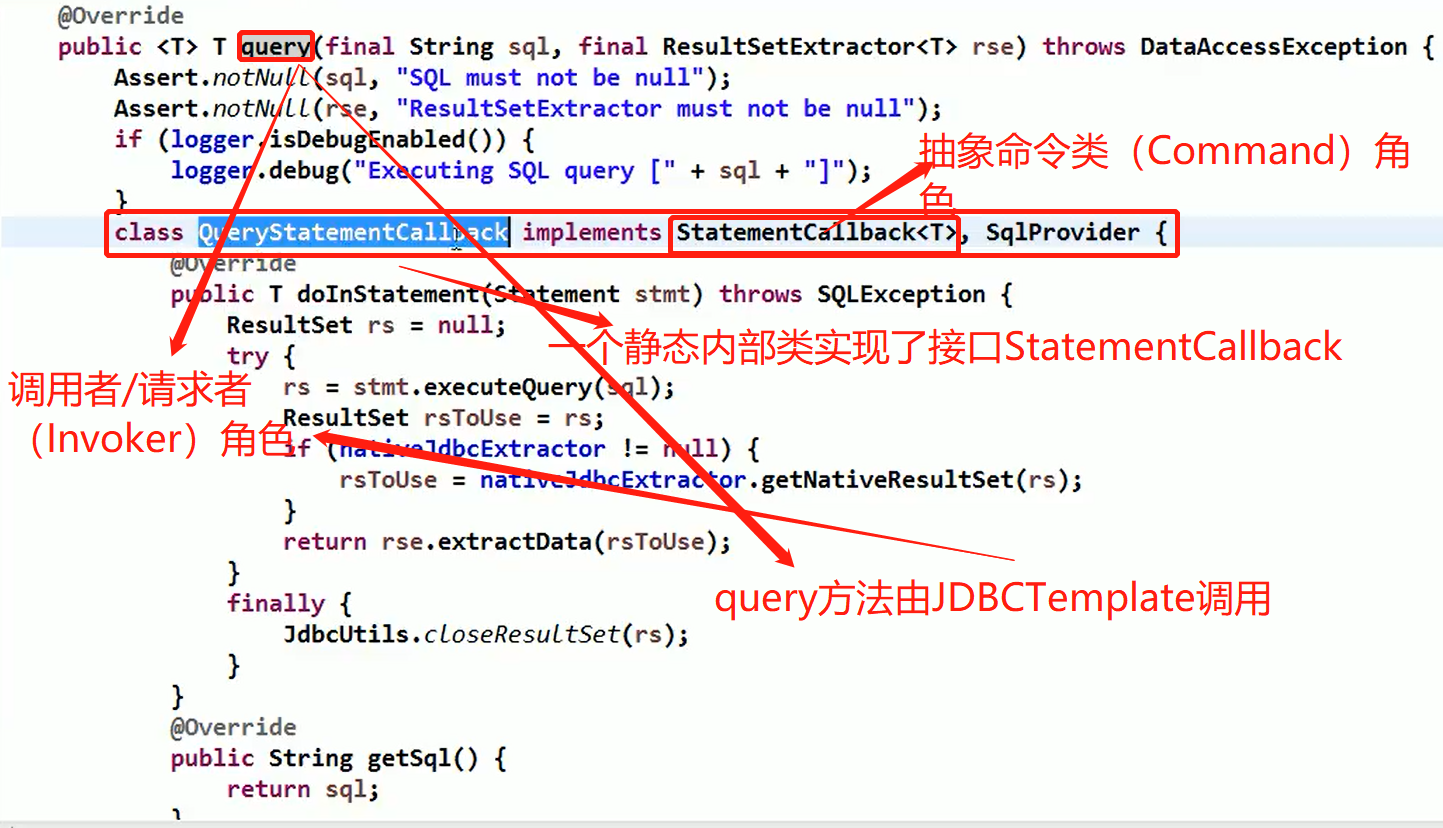
StatementCallback接口,里面有doInstatement抽象方法
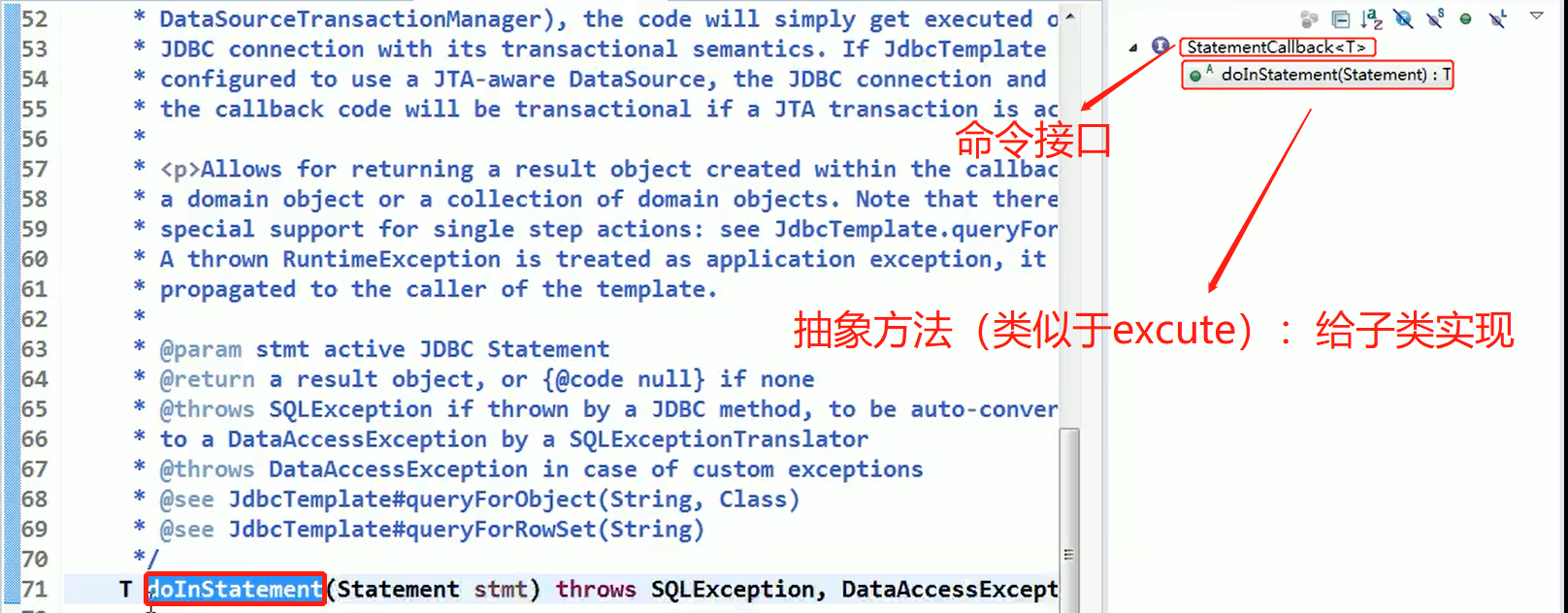
QueryStatementCallback这个静态内部类实现了StatementCallback接口,在里面实现了doInstatement抽象方法

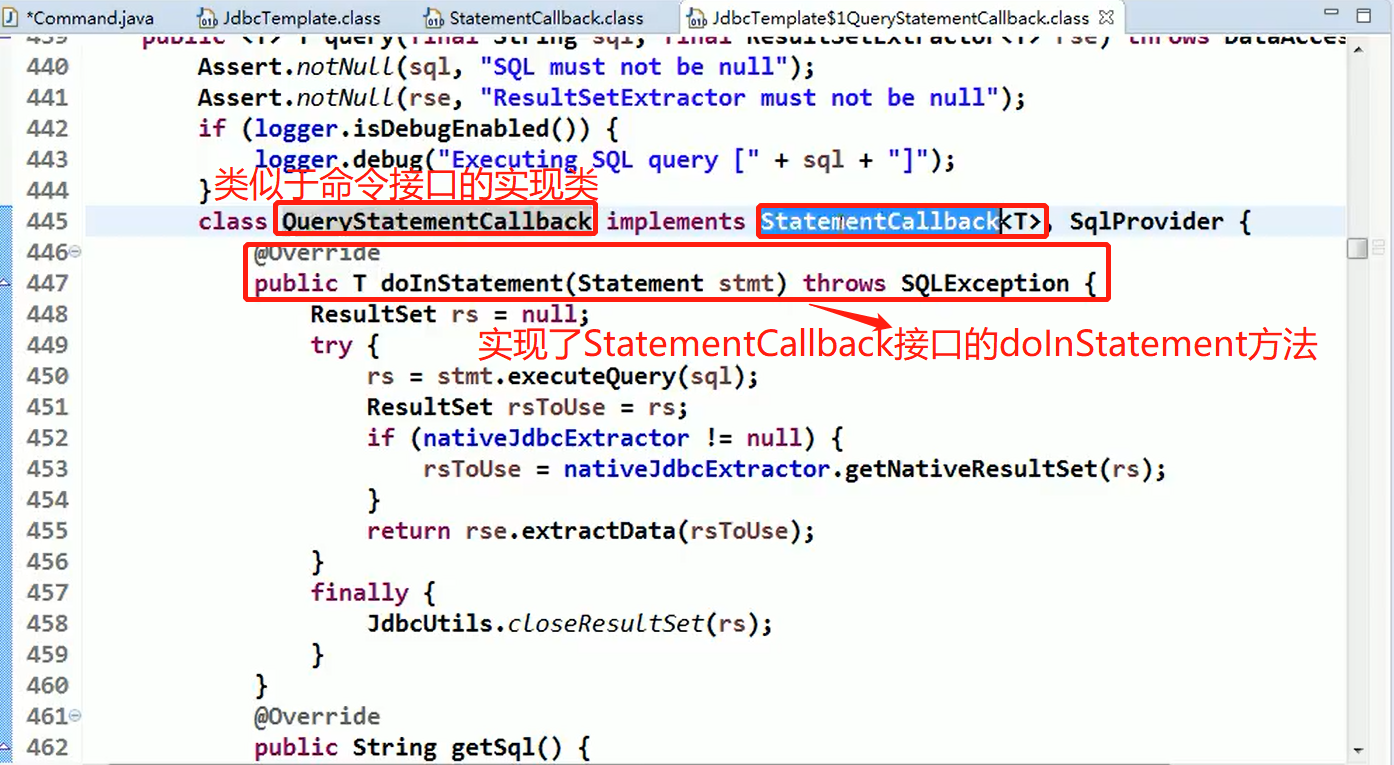
同时,QueryStatementCallback又作为实现者/接收者(Receiver) 角色执行execute方法

StatementCallback接口的其他实现类:ExecuteStatementCallback

ExecuteStatementCallback的excute方法:最后调用了JdbcTemplate的excute方法
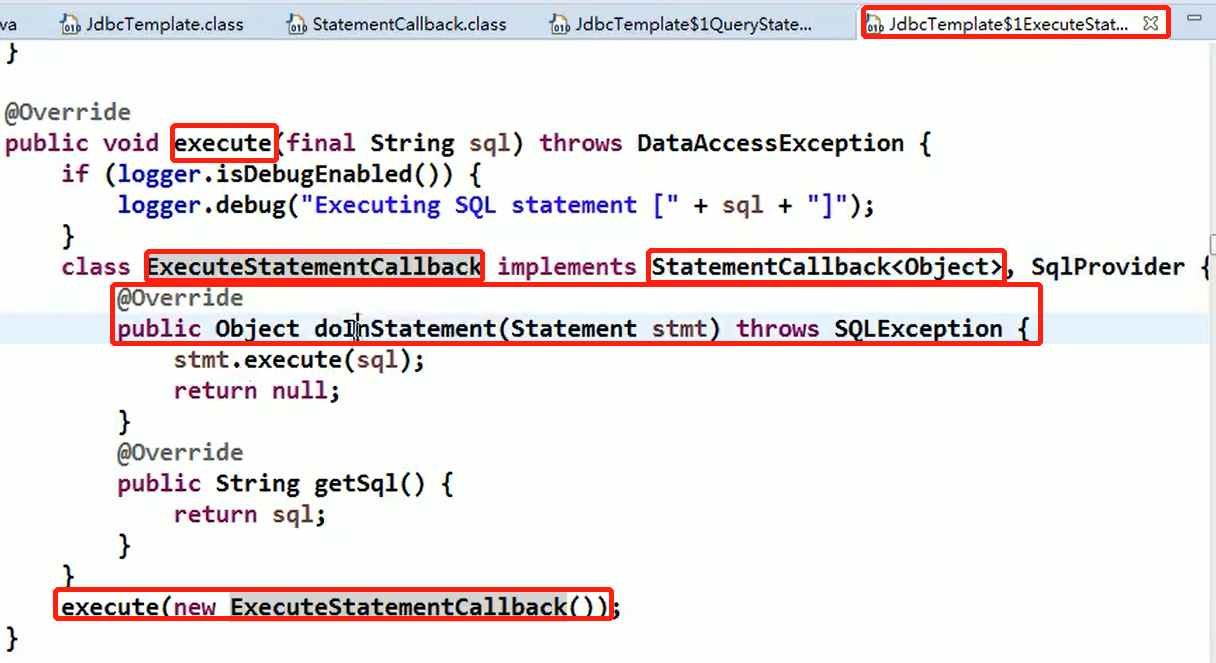
JdbcTemplate的excute方法:
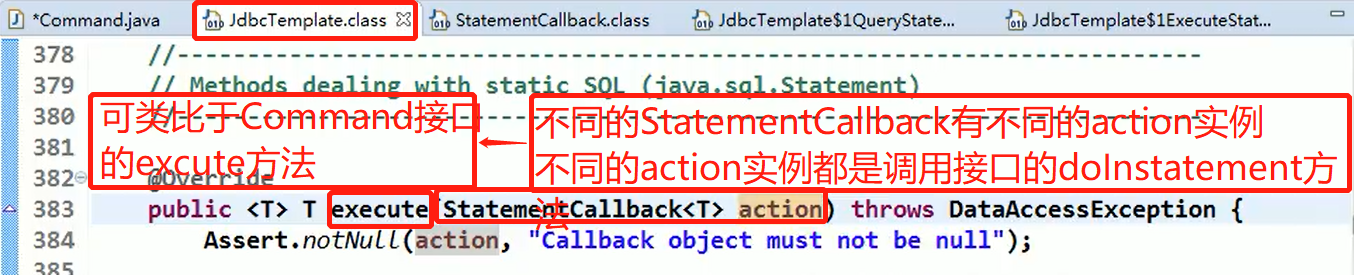

17.5、命令模式总结
主要优点:
- 通过引入中间件(抽象接口)降低系统的耦合度。
- 扩展性良好,增加或删除命令非常方便。采用命令模式增加与删除命令不会影响其他类,且满足“开闭原则”。
- 可以实现宏命令。命令模式可以与组合模式结合,将多个命令装配成一个组合命令,即宏命令。
- 方便实现 Undo 和 Redo 操作。命令模式可以与后面介绍的备忘录模式结合,实现命令的撤销与恢复。
- 可以在现有命令的基础上,增加额外功能。比如日志记录,结合装饰器模式会更加灵活。
缺点是:
- 可能产生大量具体的命令类。因为每一个具体操作都需要设计一个具体命令类,这会增加系统的复杂性。
- 命令模式的结果其实就是接收方的执行结果,但是为了以命令的形式进行架构、解耦请求与实现,引入了额外类型结构(引入了请求方与抽象命令接口),增加了理解上的困难。不过这也是设计模式的通病,抽象必然会额外增加类的数量,代码抽离肯定比代码聚合更加难理解。
命令模式的应用场景:
当系统的某项操作具备命令语义,且命令实现不稳定(变化)时,可以通过命令模式解耦请求与实现。使用抽象命令接口使请求方的代码架构稳定,封装接收方具体命令的实现细节。接收方与抽象命令呈现弱耦合(内部方法无需一致),具备良好的扩展性。
命令模式通常适用于以下场景:
- 请求调用者需要与请求接收者解耦时,命令模式可以使调用者和接收者不直接交互。
- 系统随机请求命令或经常增加、删除命令时,命令模式可以方便地实现这些功能。
- 当系统需要执行一组操作时,命令模式可以定义宏命令来实现该功能。
- 当系统需要支持命令的撤销(Undo)操作和恢复(Redo)操作时,可以将命令对象存储起来,采用备忘录模式来实现。
- 界面的一个按钮都是一条命令、模拟 CMD(DOS 命令)订单的撤销/恢复、触发- 反馈机制
17.6、命令模式扩展
在软件开发中,有时将命令模式与前面学的组合模式联合使用,这就构成了宏命令模式,也叫组合命令模式。宏命令包含了一组命令,它充当了具体命令与调用者的双重角色,执行它时将递归调用它所包含的所有命令,其具体结构图如图:
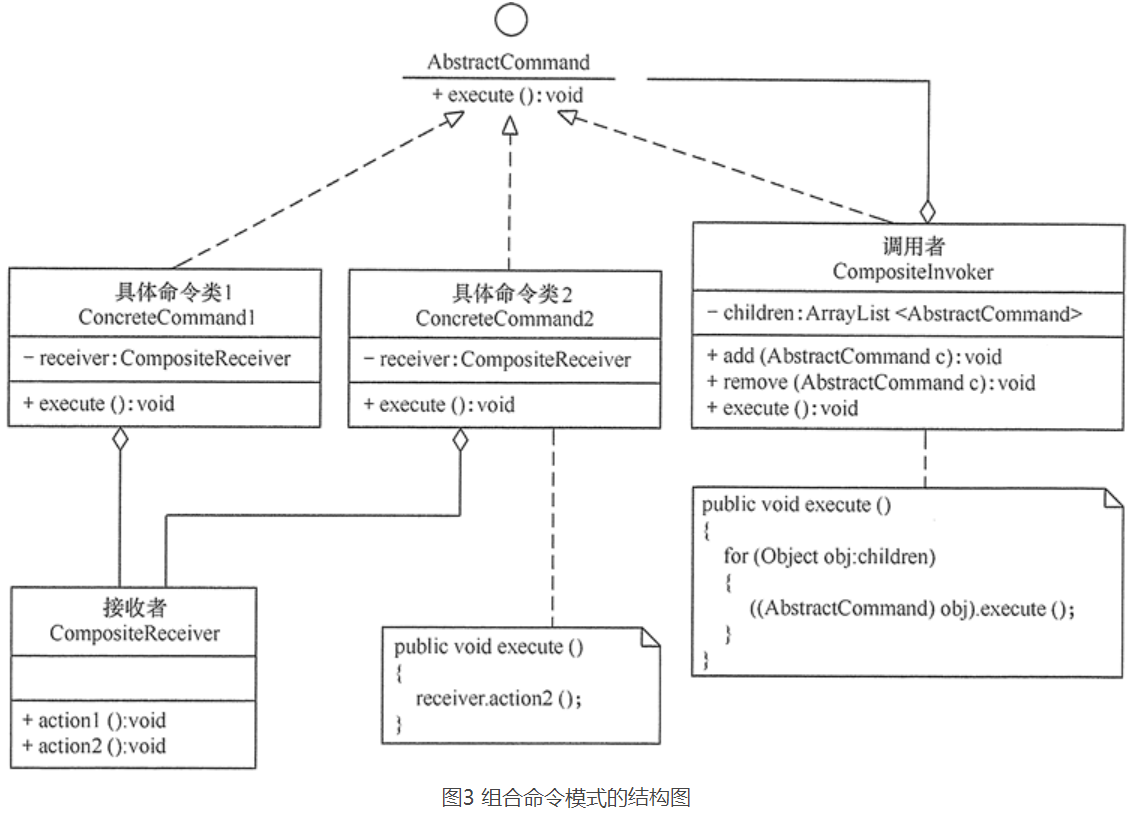
实现代码:
1 | package command; |
17.7、进阶阅读
如果您想深入了解命令模式,可猛击阅读以下文章。
17.8、相关设计模式
Composite 模式
有时会使用Composite模式实现宏命令(macrocommand)。
Memento 模式
有时会使用Memento模式来保存Command角色的历史记录。
Protype 模式
有时会使用Protype模式复制发生的事件(生成的命令)。
17.9、命令模式的注意事项与细节
- 将发起请求的对象与执行请求的对象解耦。发起请求的对象是调用者,调用者只要调用命令对象的 execute()方法就可以让接收者工作,而不必知道具体的接收者对象是谁、是如何实现的,命令对象会负责让接收者执行请求的动作,也就是说:”请求发起者”和“请求执行者”之间的解耦是通过命令对象实现的,命令对象起到了纽带桥梁的作用。
- 容易设计一个命令队列。只要把命令对象放到列队,就可以多线程的执行命令
- 容易实现对请求的撤销和重做
- 命令模式不足:可能导致某些系统有过多的具体命令类,增加了系统的复杂度,这点在在使用的时候要注意
- 空命令也是一种设计模式,它为我们省去了判空的操作。在上面的实例中,如果没有用空命令,我们每按下一个按键都要判空,这给我们编码带来一定的麻烦。
- 命令模式经典的应用场景:界面的一个按钮都是一条命令、模拟 CMD(DOS 命令)订单的撤销/恢复、触发- 反馈机制
18、访问者模式Visitor(行为型模式)

18.1、基本介绍
- 访问者模式(Visitor Pattern),封装一些作用于某种数据结构的各元素的操作,它可以在不改变数据结构的前提下定义作用于这些元素的新的操作。为数据结构中的每个元素提供多种访问方式。它将对数据的操作与数据结构进行分离,是行为类模式中最复杂的一种模式。
- 主要将数据结构与数据操作分离,解决数据结构和操作耦合性问题
- 访问者模式的基本工作原理是:在被访问的类里面加一个对外提供接待访问者的接口
- 访问者模式主要应用场景是:需要对一个对象结构中的对象进行很多不同操作(这些操作彼此没有关联)**,同时需要避免让这些操作”污染”这些对象的类**,可以选用访问者模式解决
18.2、访问者模式的原理结构图-uml类图
访问者(Visitor)模式实现的关键是如何将作用于元素的操作分离出来封装成独立的类
18.2.1、模式的结构
访问者模式包含以下主要角色。
- 抽象访问者(Visitor)角色:定义一个访问具体元素的接口,为每个具体元素类对应一个访问操作 visit() ,该操作中的**参数类型标识了被访问的
具体元素**。即:为该对象结构中的 ConcreteElement 的每一个类声明一个 visit 操作。 - 具体访问者(ConcreteVisitor)角色:实现抽象访问者角色中声明的各个访问操作,确定访问者访问一个元素时该做什么。
- 抽象元素(Element)角色:声明一个包含接受操作 accept() 的接口,被接受的访问者对象作为 accept() 方法的参数。即:定义一个 accept 方法,接收一个访问者对象。(与抽象访问者(Visitor)角色实现互相关联(但相关联的抽象元素的具体实现类))
- 具体元素(ConcreteElement)角色:实现抽象元素角色提供的 accept() 操作,其方法体通常都是 visitor.visit(this) (双分派),另外具体元素中可能还包含本身业务逻辑的相关操作。
- 对象结构(Object Structure)角色:是一个包含元素角色的容器,提供让访问者对象遍历容器中的所有元素的方法,通常由
List、Set、Map等聚合类实现。
其结构图类图:
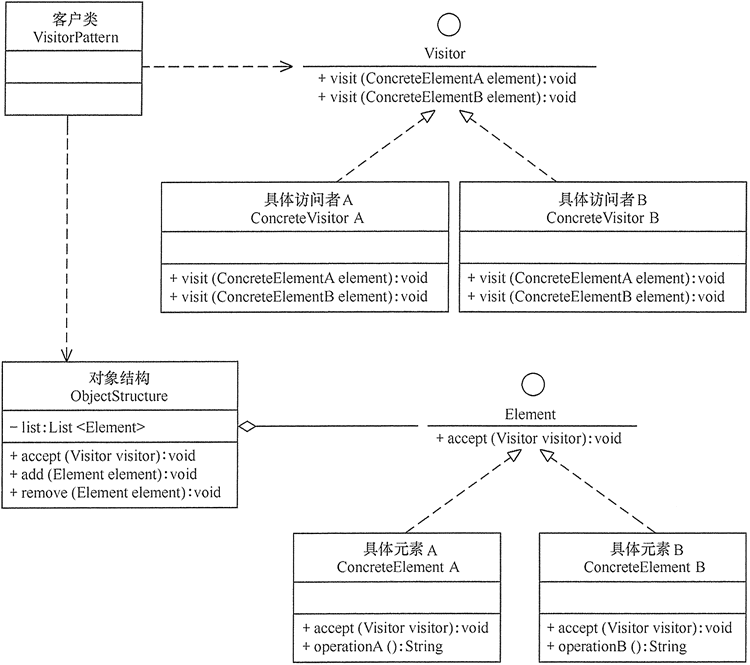
18.2.2、代码实现
1 | package net.biancheng.c.visitor; |
18.3、应用举例
测评系统的需求
将观众分为男人和女人,对歌手进行测评,当看完某个歌手表演后,得到他们对该歌手不同的评价(评价有不同的种类,比如 成功、失败等,之后会增加一种状态“待定”以测试程序的扩展性)
18.3.1、使用传统方式解决需求
思路分析:

传统方式的问题分析:
- 如果系统比较小,还是 ok 的,但是考虑系统增加越来越多新的功能时,对代码改动较大,违反了 ocp 原则, 不利于维护
- 扩展性不好,比如增加了新的人员类型,或者管理方法,都不好做
- 引出我们会使用新的设计模式 – 访问者模式
18.3.2、使用访问者模式解决需求
思路分析(类图):
代码实现:
Action:行为抽象类,在里面的方法将具体元素作为参数传入。抽象访问者(Visitor)角色
1 | public abstract class Action { |
Success:成功的行为。具体访问者(ConcreteVisitor)角色(Fail失败与Wait待定等等行为类似)
1 | public class Success extends Action { |
Person:人类,将访问者Visitor作为参数传入accept()方法。抽象元素(Element)角色
1 | public abstract class Person { |
Man:男人,重写父类的accept方法,并在accept方法里调用访问者的方法并将this作为参数传入,以此实现双分派。具体元素(ConcreteElement)角色(Woman女人类类似)
1 | //说明 |
ObjectStructure:对象结构(Object Structure)角色
1 | import java.util.LinkedList; |
Client:客户端,用来进行调用
1 | public class Client { |
18.4、双分派
整理一下 Visitor 模式中方法的调用关系:
accept(接受)方法的调用方式如下:
element.accept(visitor);
visit(访问)方法的调用方式如下:
visitor.visit(element);
对比一下这两个方法会发现, 它们是相反的关系。 element 接受 visitor, 而 visitor 又访问 element。
在 Visitor 模式中, ConcreteElement 和 ConcreteVisitor 这两个角色共同决定了实际进行的处理。这种消息分发的方式一般被称为双重分发 (double dispatch)。
访问者模式为了实现所谓的“双重分派”,设计了一个回调再回调的机制。因为Java只支持基于多态的单分派模式,这里强行模拟出“双重分派”反而加大了代码的复杂性。
所谓双分派是指不管类怎么变化,我们都能找到期望的方法运行。双分派意味着得到执行的操作取决于请求的种类和两个接收者的类型
上述实例为例,假设我们要添加一个 Wait 的状态类,考察 Man 类和 Woman 类的反应,由于使用了双分派,只需增加一个 Action 子类即可在客户端调用即可,不需要改动任何其他类的代码。
18.5、访问者模式总结
主要优点如下:
- 扩展性好。能够在不修改对象结构中的元素的情况下,为对象结构中的元素添加新的功能。
- 复用性好。可以通过访问者来定义整个对象结构通用的功能,从而提高系统的复用程度。
- 灵活性好。访问者模式将数据结构与作用于结构上的操作解耦,使得操作集合可相对自由地演化而不影响系统的数据结构。
- 符合单一职责原则。访问者模式把相关的行为封装在一起,构成一个访问者,使每一个访问者的功能都比较单一。可以做报表、UI、拦截器与过滤器,适用于数据结构相对稳定的系统
主要缺点如下:
- 增加新的元素类很困难。在访问者模式中,每增加一个新的元素类,都要在每一个具体访问者类中增加相应的具体操作,这违背了“开闭原则”。
- 破坏封装。访问者模式中具体元素对访问者公布细节,这破坏了对象的封装性。
- 违反了依赖倒置原则。访问者模式依赖了具体类,而没有依赖抽象类。
- 具体元素对访问者公布细节,违反了迪米特原则
总结一下就是:易于增加的ConcreteVisitor角色,难以增加的ConcreteElement角色
模式的应用场景:
当系统中存在类型数量稳定(固定)的一类数据结构时,可以使用访问者模式方便地实现对该类型所有数据结构的不同操作,而又不会对数据产生任何副作用(脏数据)。
简而言之,就是当对集合中的不同类型数据(类型数量稳定)进行多种操作时,使用访问者模式。
通常在以下情况可以考虑使用访问者(Visitor)模式:
- 对象结构相对稳定,但其操作算法经常变化的程序。
- 对象结构中的对象需要提供多种不同且不相关的操作,而且要避免让这些操作的变化影响对象的结构。
- 对象结构包含很多类型的对象,希望对这些对象实施一些依赖于其具体类型的操作。
18.6、访问者模式扩展
访问者(Visitor)模式是使用频率较高的一种设计模式,它常常同以下两种设计模式联用。
- 与“迭代器模式”联用。因为访问者模式中的“对象结构”是一个包含元素角色的容器,当访问者遍历容器中的所有元素时,常常要用迭代器。如应用举例中的对象结构是用 List 实现的,它通过 List 对象的 Iterator() 方法获取迭代器。如果对象结构中的聚合类没有提供迭代器,也可以用迭代器模式自定义一个。
- 访问者(Visitor)模式同“组合模式”联用。因为访问者(Visitor)模式中的“元素对象”可能是叶子对象或者是容器对象,如果元素对象包含容器对象,就必须用到组合模式,其结构图如图:
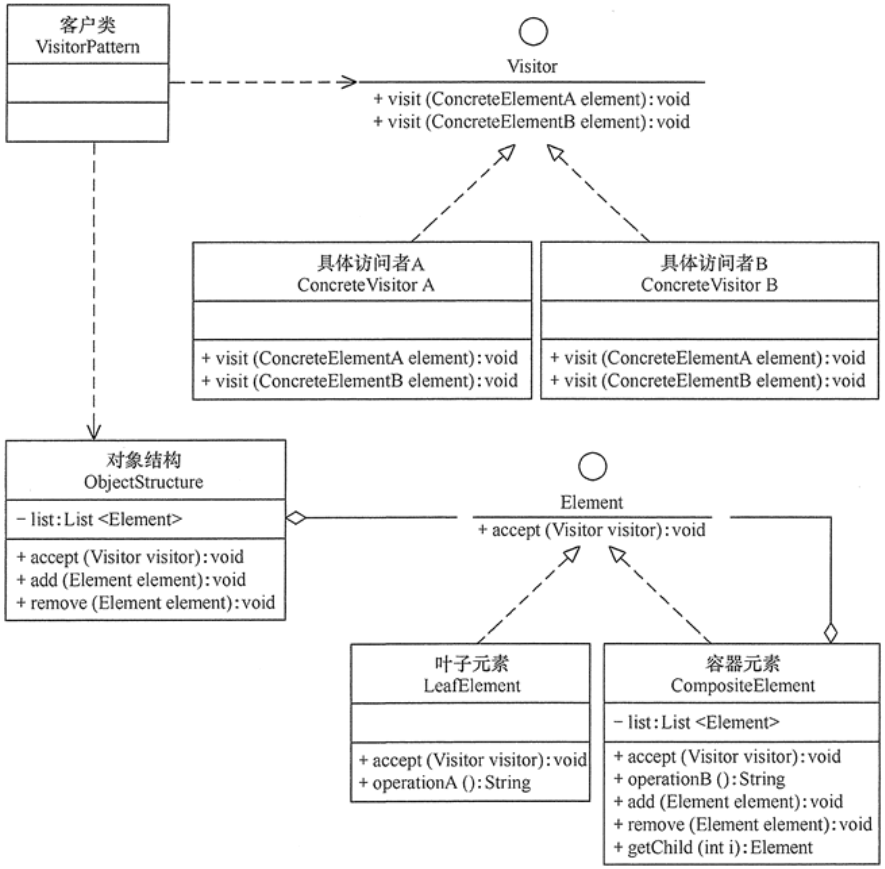
18.7、进阶阅读
如果您想深入了解访问者模式,可猛击阅读以下文章。
18.8、相关设计模式
Iterator模式
Iterator模式和Visitor模式都是在某种数据结构上进行处理。
Iterator模式用于逐个遍历保存在数据结构中的元素。
Visitor模式用于对保存在数据结构中的元素进行某种特定的处理。
Composite模式
有时访问者所访问的数据结构会使用Composite模式。
Interpreter模式
在Interpreter模式中, 有时会使用Visitor模式。 例如, 在生成了语法树后, 可能会使用Visitor 模式访问语法树的各个节点进行处理。
19、迭代器模式Iterator(行为型模式)
19.1、基本介绍
- 迭代器模式(Iterator Pattern)是常用的设计模式,属于行为型模式
- 如果我们的集合元素是用不同的方式实现的,有数组,还有 java 的集合类,或者还有其他方式,当客户端要遍历这些集合元素的时候就要使用多种遍历方式,而且还会暴露元素的内部结构,可以考虑使用迭代器模式解决。
- 迭代器模式,提供一种遍历集合元素的统一接口,用一致的方法遍历集合元素,不需要知道集合对象的底层表示,即:不暴露其内部的结构。
- 迭代器模式在客户访问类与聚合类之间插入一个迭代器,这分离了聚合对象与其遍历行为,对客户也隐藏了其内部细节,且满足“单一职责原则”和“开闭原则”
19.2、迭代器模式的原理结构图-uml类图
迭代器模式是通过将聚合对象的遍历行为分离出来,抽象成迭代器类来实现的,其目的是在不暴露聚合对象的内部结构的情况下,让外部代码透明地访问聚合的内部数据。现在我们来分析其基本结构与实现方法。
19.2.1、 模式的结构
迭代器模式主要包含以下角色:
- 抽象聚合(Aggregate)角色:一个统一的聚合接口, 将客户端和具体聚合解耦。定义存储、添加、删除聚合对象以及创建迭代器对象的接口。
- 具体聚合(ConcreteAggregate)角色:实现抽象聚合类,并提供一个方法,返回一个具体迭代器的实例。该迭代器可以正确遍历集合
- 抽象迭代器(Iterator)角色:定义访问和遍历聚合元素的接口,是java系统提供的,通常包含 hasNext()、remove()、next() 等方法。
- 具体迭代器(Concretelterator)角色:实现抽象迭代器接口中所定义的方法,完成对聚合对象的遍历,记录遍历的当前位置。
- Client :客户端, 通过 Iterator 和 Aggregate 依赖子类
其结构图类图:
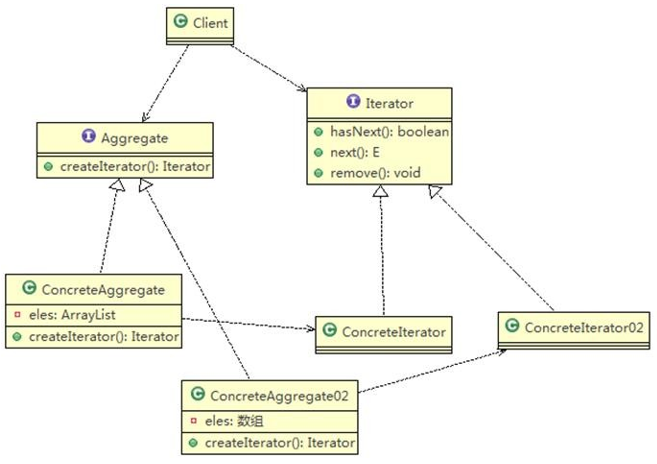
19.2.2、代码实现
1 | package net.biancheng.c.iterator; |
19.3、应用举例
编写程序展示一个学校院系结构:需求是这样,要在一个页面中展示出学校的院系组成,一个学校有多个学院, 一个学院有多个系。如图:

19.3.1、使用传统方式解决需求
思路解析(类图)
传统的方式的问题分析:
- 将学院看做是学校的子类,系是学院的子类,这样实际上是站在组织大小来进行分层次的
- 实际上我们的要求是 :在一个页面中展示出学校的院系组成,一个学校有多个学院,一个学院有多个系, 因此这种方案,不能很好实现的遍历的操作
- 解决方案:=> 迭代器模式
19.3.2、使用迭代器模式解决需求
原理类图:
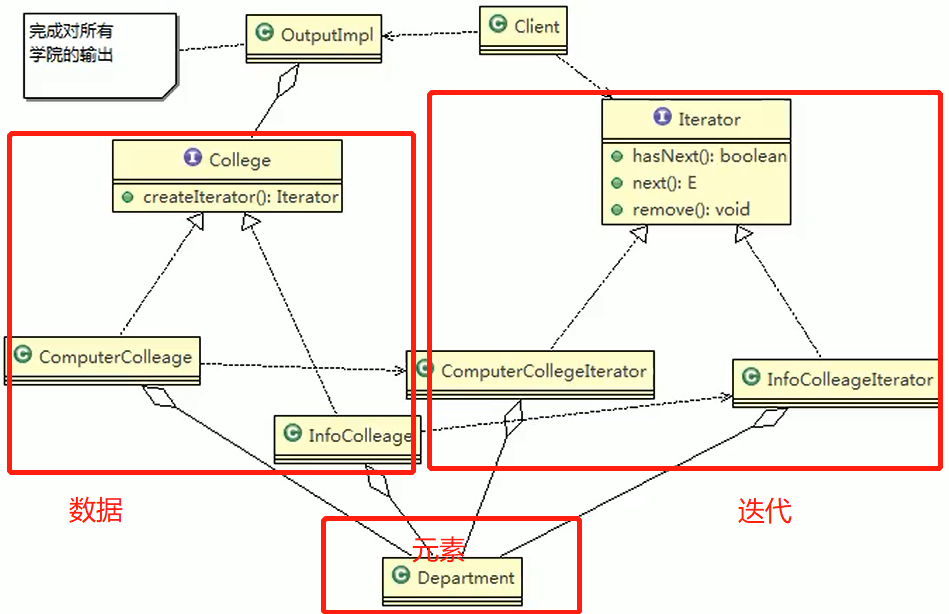
代码实现:
Department:专业。元素。
1 | public class Department { |
抽象迭代器(Iterator)角色:java自带的Iterator迭代器接口
ComputerCollegeIterator:计算机学院迭代器,实现了迭代器接口里的hasNext()与next()方法,具体迭代器(Concretelterator)角色
1 | import java.util.Iterator; |
InfoColleageIterator:信息学院迭代器,实现了迭代器接口里的hasNext()与next()方法,具体迭代器(Concretelterator)角色
1 | import java.util.Iterator; |
College:学院接口,里面有createIterator()方法返回一个迭代器。抽象聚合(Aggregate)角色
1 | import java.util.Iterator; |
ComputerCollege:计算机学院,实现学院接口,里面对专业这个元素采用数组方式存储。具体聚合(ConcreteAggregate)角色
1 | import java.util.Iterator; |
InfoCollege:信息学院,实现学院接口,里面对专业这个元素采用集合方式存储。具体聚合(ConcreteAggregate)角色
1 | import java.util.ArrayList; |
OutPutImpl:遍历实现对象。
1 | import java.util.Iterator; |
Client:客户端
1 | import java.util.ArrayList; |
19.4、迭代器模式在JDK的应用与源码
JDK 的 ArrayList 集合中就使用了迭代器模式
类图:
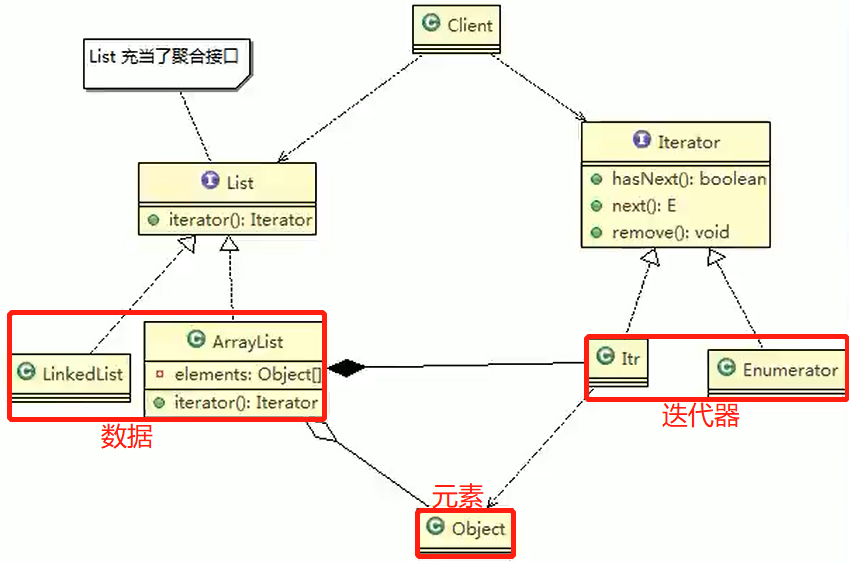
角色说明:
- 内部类 Itr 充当具体实现迭代器 Iterator 的类, 作为 ArrayList 内部类
- List 就是充当了聚合接口,含有一个 iterator() 方法,返回一个迭代器对象
- ArrayList 是实现聚合接口 List 的子类,实现了 iterator()
- Iterator 接口系统提供
- 迭代器模式解决了 不同集合(ArrayList ,LinkedList) 统一遍历问题
代码分析:

List接口,其中有获取迭代器Iterator的抽象方法,交给实现类去实现
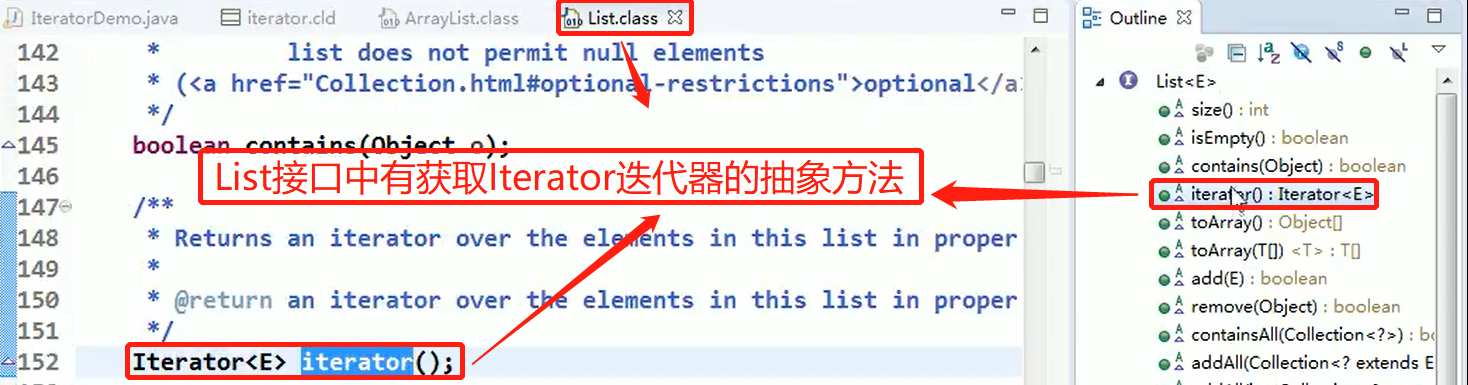
ArrayList实现了List接口,并实现了List接口的Iterator方法

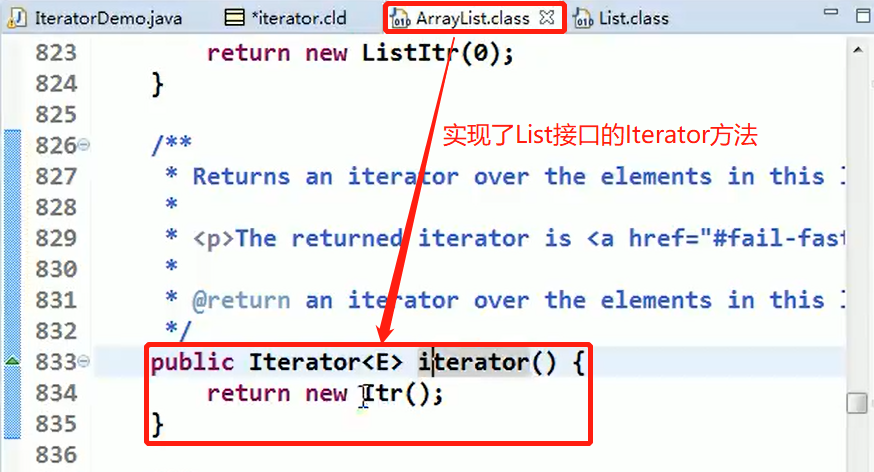
在ArrayList中把元素对象存进了数组里面
Itr为ArrayList的内部类,实现了Iterator接口,并实现了接口的next()方法与hasNext()方法,由于元素是定义在ArrayList当中的,直接使用即可。

另外实现List接口的实现类的LinkedList类
LinkedList继承了AbstractSequentialList类实现了AbstractSequentialList类当中的Iterator迭代器方法

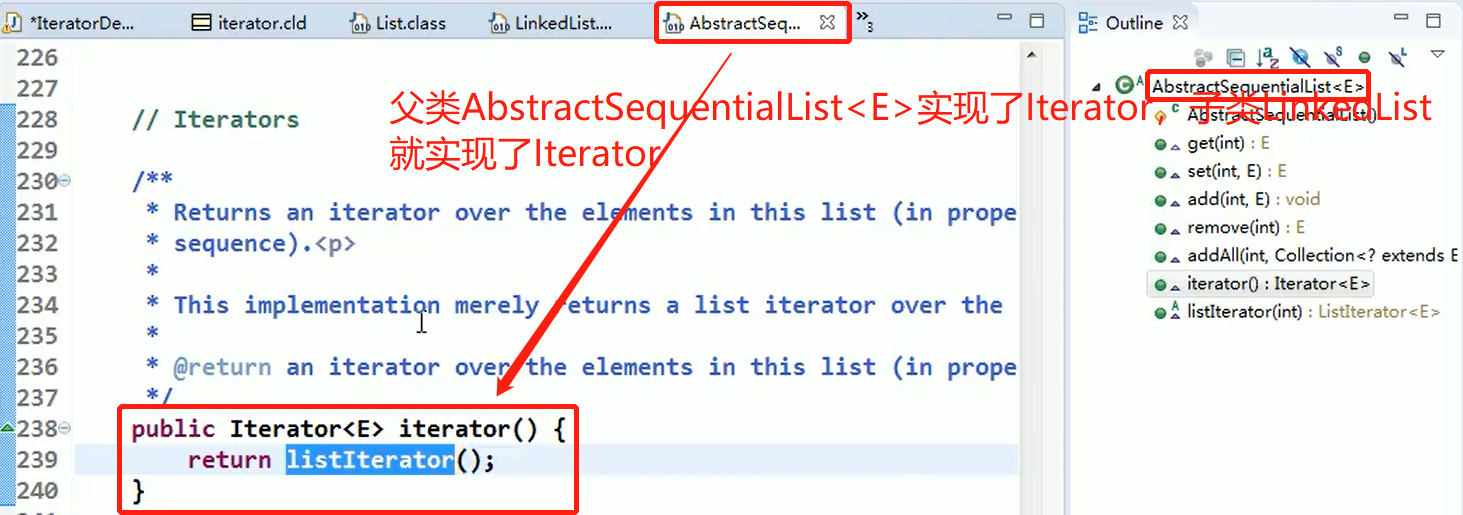
Enumerator实现了Iterator接口
19.5、迭代器模式总结
主要优点如下:
- 访问一个聚合对象的内容而无须暴露它的内部表示。
- 遍历任务交由迭代器完成,这简化了聚合类。
- 它支持以不同方式遍历一个聚合,甚至可以自定义迭代器的子类以支持新的遍历。
- 增加新的聚合类和迭代器类都很方便,无须修改原有代码。
- 封装性良好,为遍历不同的聚合结构提供一个统一的接口。
其主要缺点是:增加了类的个数,这在一定程度上增加了系统的复杂性。
在日常开发中,我们几乎不会自己写迭代器。除非需要定制一个自己实现的数据结构对应的迭代器,否则,开源框架提供的 API 完全够用。
应用场景:
- 当需要为聚合对象提供多种遍历方式时。
- 当需要为遍历不同的聚合结构提供一个统一的接口时。
- 当访问一个聚合对象的内容而无须暴露其内部细节的表示时。
- 当要展示一组相似对象,或者遍历一组相同对象时。
由于聚合与迭代器的关系非常密切,所以大多数语言在实现聚合类时都提供了迭代器类,因此大数情况下使用语言中已有的聚合类的迭代器就已经够了。
19.6、迭代器模式扩展
迭代器模式常常与组合模式结合起来使用,在对组合模式中的容器构件进行访问时,经常将迭代器潜藏在组合模式的容器构成类中。当然也可以构造一个外部迭代器来对容器构件进行访问,其结构图:
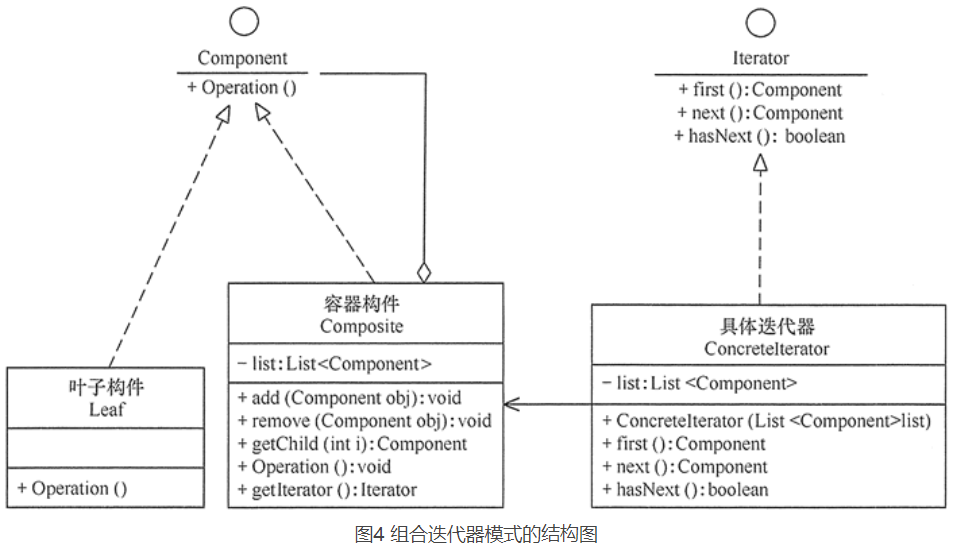
19.7、进阶阅读
如果您想了解迭代器模式在框架源码中的应用,可猛击阅读以下文章。
19.8、相关设计模式
Visitor 模式
Iterator模式是从集合中一个一个取出元素进行遍历, 但是并没有在Iterator接口中声明对取出的元素进行何种处理。
Visitor模式则是在遍历元素集合的过程中, 对元素进行相同的处理。
在遍历集合的过程中对元素进行固定的处理是常有的需求。 Visitor模式正是为了应对这种需求而出现的。 在访问元素集合的过程中对元素进行相同的处理, 这种模式就是Visitor模式。
Composite 模式
Composite模式是具有递归结构的模式, 在其中使用Iterator模式比较困难。
Factory Method 模式
在iterator方法中生成Iterator的实例时可能会使用Factory Method模式。
19.9、迭代器模式的注意事项与细节
提供了一种设计思想,就是一个类应该只有一个引起变化的原因(叫做单一责任原则)。在聚合类中,我们把迭代器分开,就是要把管理对象集合和遍历对象集合的责任分开,这样一来集合改变的话,只影响到聚合对象。而如果遍历方式改变的话,只影响到了迭代器。
20、观察者模式Observer(行为型模式)
20.1、基本介绍
观察者(Observer)模式的定义:指多个对象间存在一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。这种模式有时又称作发布-订阅模式、模型-视图模式,它是对象行为型模式。
观察者模式类似订牛奶业务
奶站/气象局:Subject 用户/第三方网站:Observer
Subject:登记注册、移除和通知
- registerObserver 注 册
- removeObserver 移 除
- notifyObservers() 通知所有的注册的用户,根据不同需求,可以是更新数据,让用户来取,也可能是实施推送, 看具体需求定
- Observer:接收输入
观察者模式:对象之间多对一依赖的一种设计方案,被依赖的对象为 Subject,依赖的对象为 Observer,Subject
通知 Observer 变化,比如这里的奶站是 Subject,是 1 的一方。用户时 Observer,是多的一方。
20.2、观察者模式的原理结构图-uml类图
实现观察者模式时要注意具体目标对象和具体观察者对象之间不能直接调用,否则将使两者之间紧密耦合起来,这违反了面向对象的设计原则。
20.2.1、模式的结构
观察者模式的主要角色如下:
- 抽象主题(Subject)角色:也叫抽象目标类,它提供了一个用于保存观察者对象的聚集类和增加、删除观察者对象的方法,以及通知所有观察者的抽象方法。
- 具体主题(Concrete Subject)角色:也叫具体目标类,它实现抽象目标中的通知方法,当具体主题的内部状态发生改变时,通知所有注册过的观察者对象。
- 抽象观察者(Observer)角色:它是一个抽象类或接口,它包含了一个更新自己的抽象方法,当接到具体主题的更改通知时被调用。
- 具体观察者(Concrete Observer)角色:实现抽象观察者中定义的抽象方法,以便在得到目标的更改通知时更新自身的状态。
观察者模式的结构图:
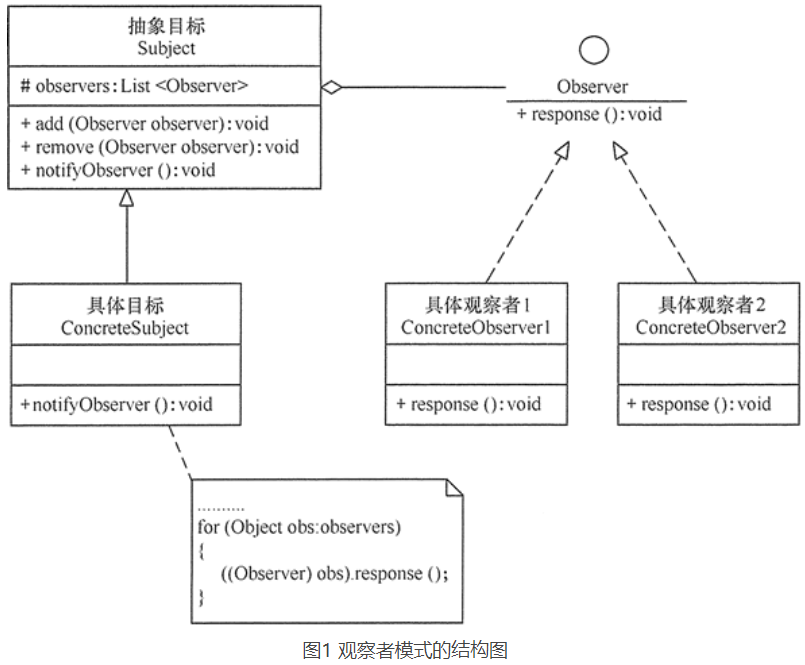
20.2.2、代码实现
1 | package net.biancheng.c.observer; |
20.3、应用举例
天气预报项目需求,具体要求如下:
- 气象站可以将每天测量到的温度,湿度,气压等等以公告的形式发布出去(比如发布到自己的网站或第三方)。
- 需要设计开放型 API,便于其他第三方也能接入气象站获取数据。
- 提供温度、气压和湿度的接口
- 测量数据更新时,要能实时的通知给第三方
20.3.1、使用传统方法解决需求
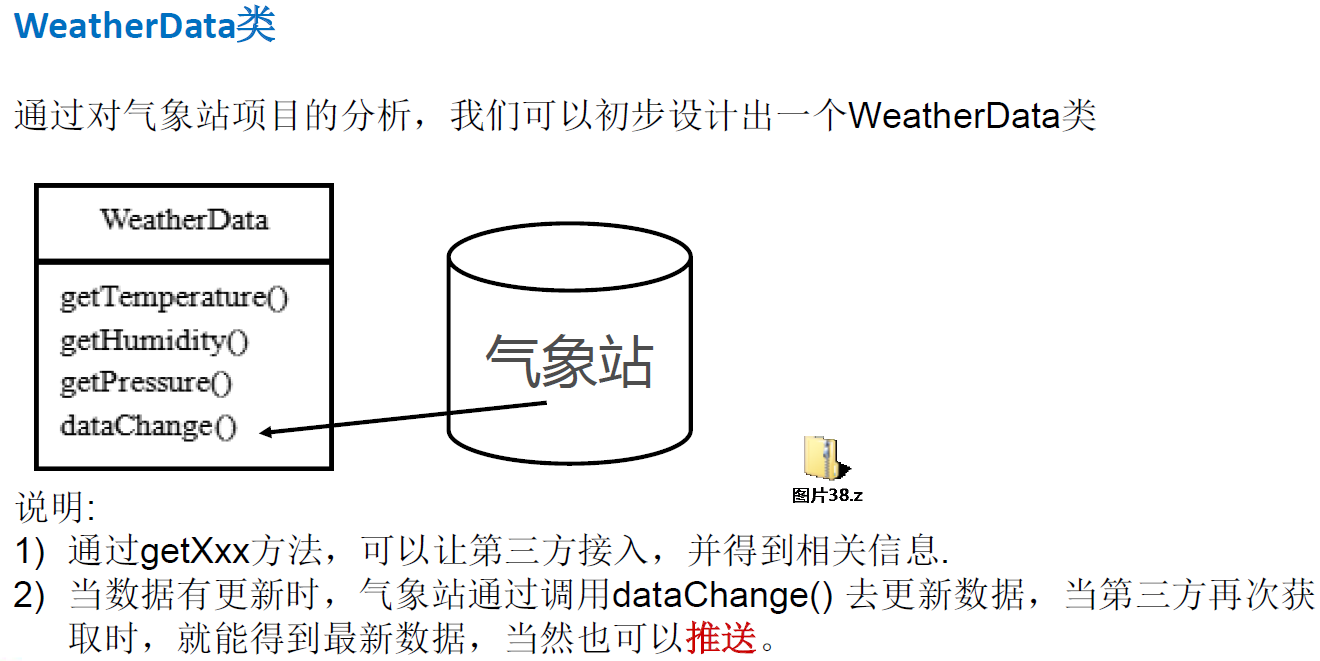

实现代码:
WeatherData:天气情况
CurrentConditions

Client
问题分析:
- 其他第三方接入气象站获取数据的问题
- 无法在运行时动态的添加第三方 (新浪网站)
- 违反 ocp 原则=>观察者模式
1 | //在 WeatherData 中,当增加一个第三方,都需要创建一个对应的第三方的公告板对象,并加入到 dataChange, 不利于维护,也不是动态加入 |
20.3.2、使用观察者模式解决需求
类图说明:
代码实现:
Subject:抽象主题(Subject)角色
1 | //接口, 让WeatherData 来实现 |
WeatherData:包含最新的天气情况信息。具体主题(Concrete Subject)角色
1 | import java.util.ArrayList; |
Observer:观察者接口,由观察者来实现。抽象观察者(Observer)角色
1 | //观察者接口,由观察者来实现 |
CurrentConditions:当前环境。具体观察者(Concrete Observer)角色(百度、新浪等等第三方类似)
1 | public class CurrentConditions implements Observer { |
Client:客户端
1 | public class Client { |
20.4、观察者模式在JDK的应用与源码
Jdk 的 Observable 类就使用了观察者模式
角色分析:
- Observable 的作用和地位等价于 我们前面讲过 Subject
- Observable 是类,不是接口,类中已经实现了核心的方法 ,即管理 Observer 的方法 add.. delete .. notify…
- Observer 的作用和地位等价于我们前面讲过的 Observer, 有 update
- Observable 和 Observer 的使用方法和前面讲过的一样,只是 Observable 是类,通过继承来实现观察者模式
代码分析

Observable:相当于Subject接口,但是Observable为一个普通的类
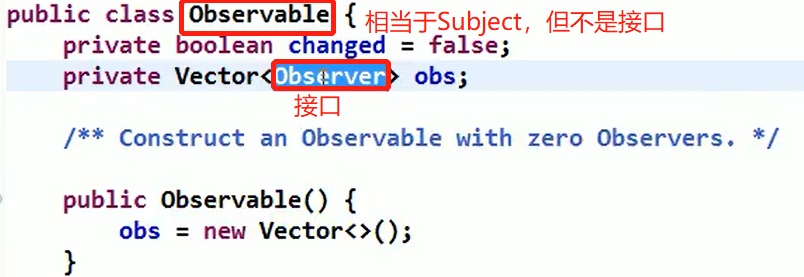
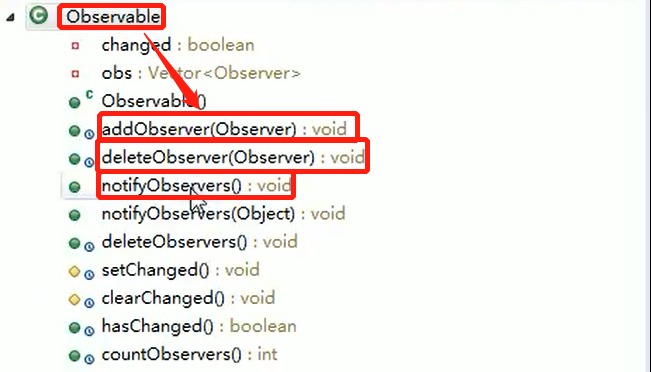
Observe接口:

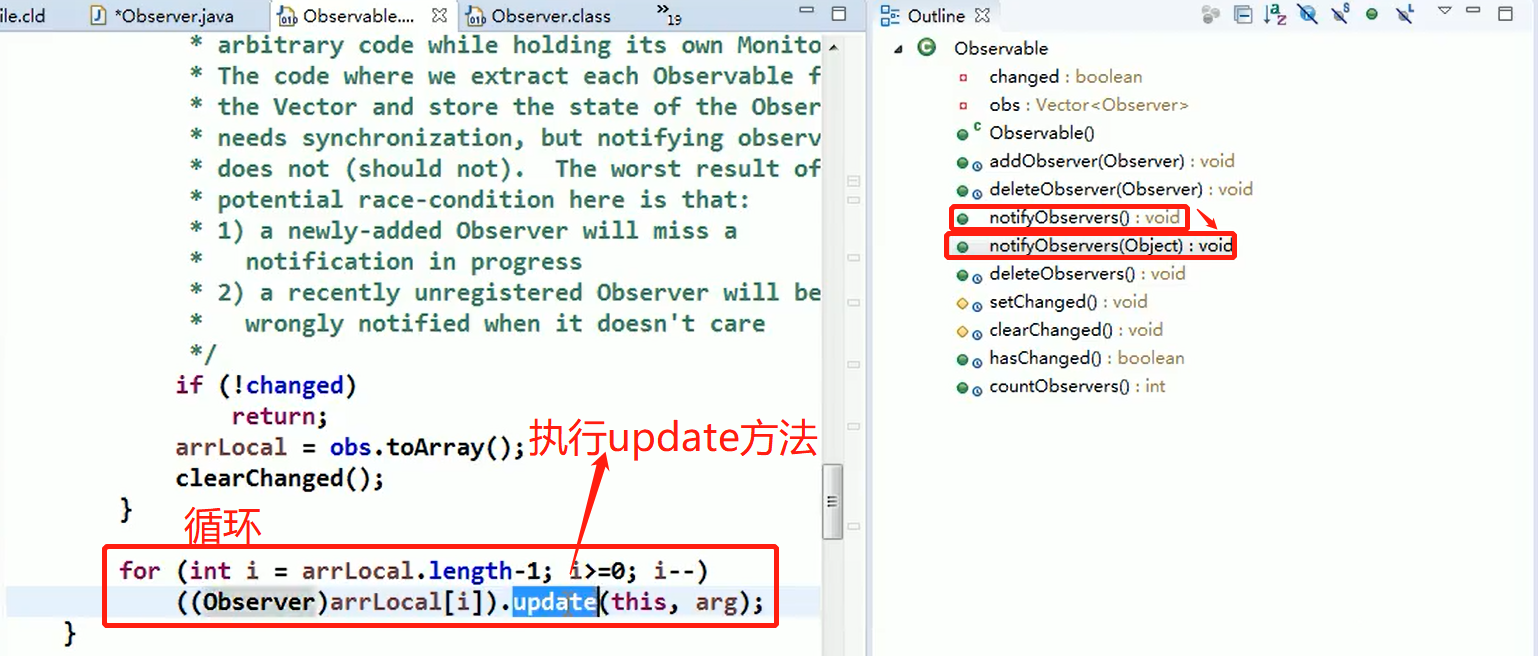
20.5、观察者模式总结
主要优点如下:
- 降低了目标与观察者之间的耦合关系,两者之间是抽象耦合关系。符合依赖倒置原则。
- 目标与观察者之间建立了一套触发机制。
主要缺点如下:
如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃

观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
当观察者对象很多时,通知的发布会花费很多时间,影响程序的效率。
在软件系统中,当系统一方行为依赖另一方行为的变动时,可使用观察者模式松耦合联动双方,使得一方的变动可以通知到感兴趣的另一方对象,从而让另一方对象对此做出响应。
观察者模式的应用情景:
- 对象间存在一对多关系,一个对象的改变将导致其他一个或多个对象也发生改变,而不知道具体有多少对象将发生改变,可以降低对象之间的耦合度。
- 一个对象必须通知其他对象,而并不知道这些对象是谁
- 当一个抽象模型有两个方面,其中一个方面依赖于另一方面时,可将这二者封装在独立的对象中以使它们可以各自独立地改变和复用。
- 实现类似广播机制的功能,不需要知道具体收听者,只需分发广播,系统中感兴趣的对象会自动接收该广播。
- 需要在系统中创建一个触发链,A对象的行为将影响B对象,B对象的行为将影响C对象……,多层级嵌套使用,形成一种链式触发机制,使得事件具备跨域(跨越两种观察者类型)通知。
20.6、观察者模式扩展
在 Java 中,通过 java.util.Observable 类和 java.util.Observer 接口定义了观察者模式,只要实现它们的子类就可以编写观察者模式实例。
20.6.1、 Observable类
Observable 类是抽象目标类,它有一个 Vector 向量,用于保存所有要通知的观察者对象,下面来介绍它最重要的 3 个方法:
- void addObserver(Observer o) 方法:用于将新的观察者对象添加到向量中。
- void notifyObservers(Object arg) 方法:调用向量中的所有观察者对象的 update() 方法,通知它们数据发生改变。通常越晚加入向量的观察者越先得到通知。(类似于栈结构)
- void setChange() 方法:用来设置一个 boolean 类型的内部标志位,注明目标对象发生了变化。当它为真时,notifyObservers() 才会通知观察者。
20.6.2、 Observer 接口
Observer 接口是抽象观察者,它监视目标对象的变化,当目标对象发生变化时,观察者得到通知,并调用 void update(Observable o,Object arg) 方法,进行相应的工作。
20.6.3、对应例子
利用 Observable 类和 Observer 接口实现原油期货的观察者模式实例。
分析:当原油价格上涨时,空方伤心,多方局兴;当油价下跌时,空方局兴,多方伤心。本实例中的抽象目标(Observable)类在 Java 中已经定义,可以直接定义其子类,即原油期货(OilFutures)类,它是具体目标类,该类中定义一个 SetPriCe(float price) 方法,当原油数据发生变化时调用其父类的 notifyObservers(Object arg) 方法来通知所有观察者;另外,本实例中的抽象观察者接口(Observer)在 Java 中已经定义,只要定义其子类,即具体观察者类(包括多方类 Bull 和空方类 Bear),并实现 update(Observable o,Object arg) 方法即可。
相关类图:
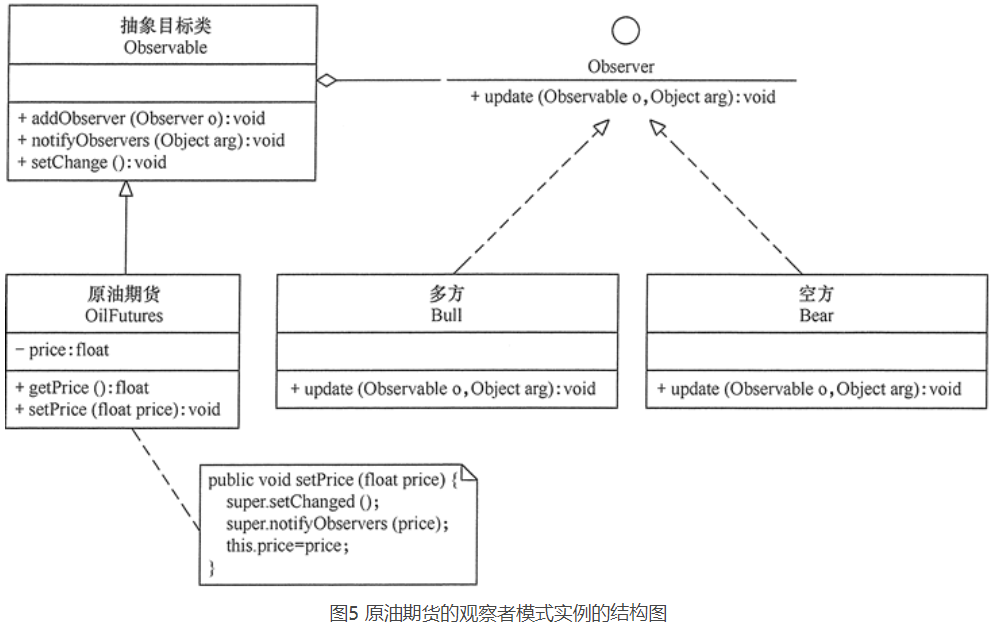
20.6.4、java. util.Observer接口和java. util . Observable类的相关解析
话虽如此,但是java. util.Observer接口和java. util . Observable类并不好用。理由很简单,传递给java. util . Observer接口的Subject角色必须是java . util. Observable类型(或者它的子类型)的。但Java只能单继承, 也就说如果Subject角色已经是某个类的子类了,那么它将无法继承java . util . Observable类。
20.7、进阶阅读
如果您想了解观察者模式在实际项目中的应用,可猛击阅读《基于Java API实现通知机制》文章。
20.8、相关设计模式
Mediator模式
- 在Mediator模式中,有时会使用Observer模式来实现Mediator角色与Colleague角色之间的通信。
- 就“发送状态变化通知”这一- 点而言,Mediator 模式与Observer模式是类似的。不过,两种模式中,通知的目的和视角不同。
- 在Mediator模式中,虽然也会发送通知,不过那不过是为了对Colleague角色进行仲裁而已。
- 而在Observer模式中,将Subject角色的状态变化通知给Observer 角色的目的则主要是为了使Subject角色和Observer角色同步。
20.9、观察者模式的注意事项与细节
- 观察者模式,又称发布-订阅模式,是一种一对多的通知机制,使得双方无需关心对方,只关心通知本身
- JAVA 中已经有了对观察者模式的支持类,但一般不支持使用。
- 避免循环引用。
- 各个观察者是依次获得的同步通知,如果上一个观察者处理太慢,会导致下一个观察者不能及时获得通知。此外,如果观察者在处理通知的时候,发生了异常,还需要被观察者处理异常,才能保证继续通知下一个观察者。
- 如果顺序执行,某一观察者错误会导致系统卡壳,一般采用异步方式。
21、中介者模式Mediator(行为型模式)

21.1、基本介绍
中介者模式(Mediator Pattern),又称调停者模式,是迪米特法则的典型应用。用一个中介对象来封装一系列的对象交互。中介者使各个对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。它的目的是把多方会谈变成双方会谈,从而实现多方的松耦合。
中介者模式属于行为型模式,使代码易于维护
比如 MVC 模式,C(Controller 控制器)是 M(Model 模型)和 V(View 视图)的中介者,在前后端交互时起到了中间人的作用
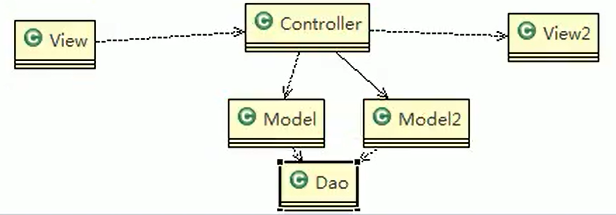
21.2、中介者模式的原理结构图-uml类图
中介者模式实现的关键是找出“中介者”,下面对它的结构和实现进行分析。
21.2.1、模式的结构
中介者模式包含以下主要角色。
- 抽象中介者(Mediator)角色:它是中介者的接口,提供了同事对象注册与转发同事对象信息的抽象方法。
- 具体中介者(Concrete Mediator)角色:实现中介者接口,定义一个 List 来管理同事对象,协调各个同事角色之间的交互关系,因此它依赖于同事角色。
- 抽象同事类(Colleague)角色:定义同事类的接口,保存中介者对象,提供同事对象交互的抽象方法,实现所有相互影响的同事类的公共功能。
- 具体同事类(Concrete Colleague)角色:是抽象同事类的实现者,当需要与其他同事对象交互时,由中介者对象负责后续的交互。
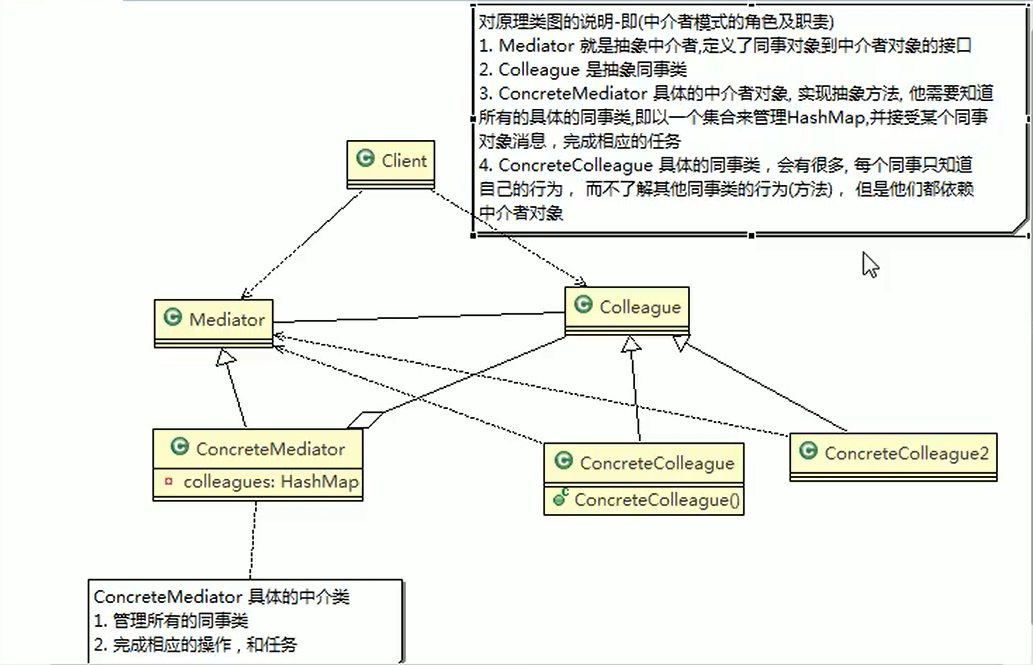
中介者模式的结构图如图:
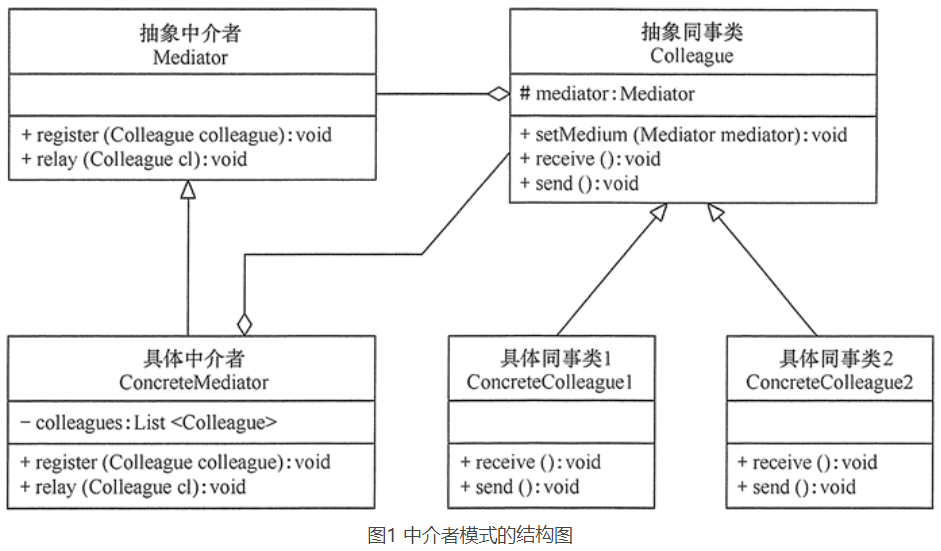
21.2.2、代码实现
1 | package net.biancheng.c.mediator; |
21.3、应用举例
智能家庭项目:
- 智能家庭包括各种设备,闹钟、咖啡机、电视机、窗帘 等
- 主人要看电视时,各个设备可以协同工作,自动完成看电视的准备工作
- 比如流程为:闹铃响起->咖啡机开始做咖啡->窗帘自动落下->电视机开始播放
21.3.1、使用传统方式解决需求
思路分析(类图)
传统的方式的问题分析:
- 当各电器对象有多种状态改变时,相互之间的调用关系会比较复杂
- 各个电器对象彼此联系,你中有我,我中有你,不利于松耦合.
- 各个电器对象之间所传递的消息(参数),容易混乱当系统增加一个新的电器对象时,或者执行流程改变时,代码的可维护性、扩展性都不理想 =》 考虑中介者模式
21.3.2、使用中介者模式解决需求
思路分析(类图):
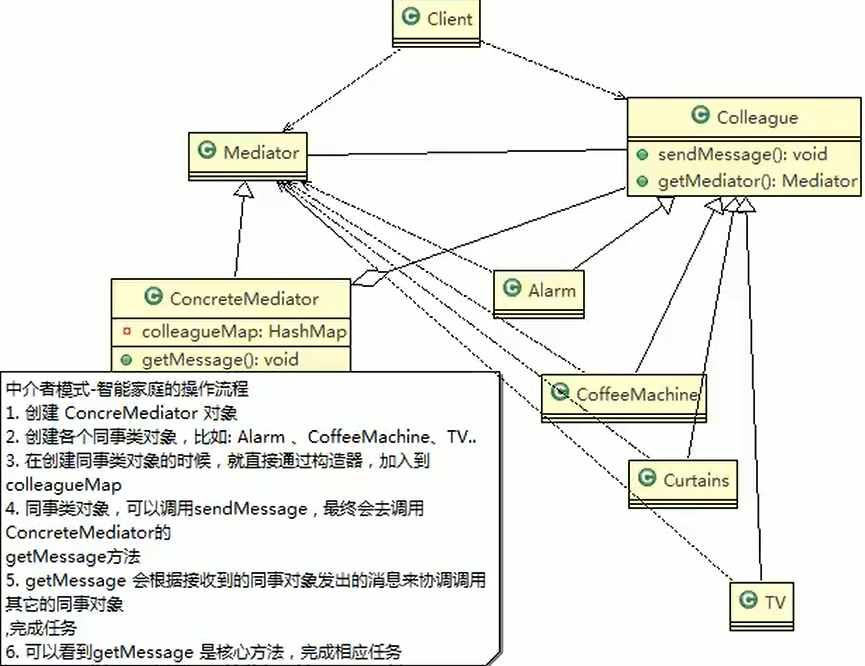
代码实现:
Mediator:中介者。抽象中介者(Mediator)角色
1 | public abstract class Mediator { |
Colleague:抽象同事类(Colleague)角色
1 | //同事抽象类 |
ConcreteMediator:具体中介者(Concrete Mediator)角色
1 | import java.util.HashMap; |
具体同事类(Concrete Colleague)角色:
Alarm:闹钟同事类
1 | //具体的同事类 |
CoffeeMachine:咖啡机
1 | public class CoffeeMachine extends Colleague { |
TV:电视机、Curtains:窗帘类似
Client:客户端。负责调用
1 | public class Client { |
21.4、中介者模式总结
主要优点如下:
- 类之间各司其职,符合迪米特法则。
- 降低了对象之间的耦合性,使得对象易于独立地被复用。
- 将对象间的一对多关联转变为一对一的关联,把多边关系变成多个双边关系,提高系统的灵活性,使得系统易于维护和扩展。
其主要缺点是:
- 中介者模式将原本多个对象直接的相互依赖变成了中介者和多个同事类的依赖关系。
- 当同事类越多时,中介者就会越臃肿,变得复杂且难以维护。
中介者模式的应用场景:
- 当对象之间存在复杂的网状结构关系而导致依赖关系混乱且难以复用时。
- 当想创建一个运行于多个类之间的对象,又不想生成新的子类时。
21.5、中介者模式扩展
在实际开发中,通常采用以下两种方法来简化中介者模式,使开发变得更简单。
- 不定义中介者接口,把具体中介者对象实现成为单例。
- 同事对象不持有中介者,而是在需要的时候直接获取中介者对象并调用。
简化中介者模式的结构图:
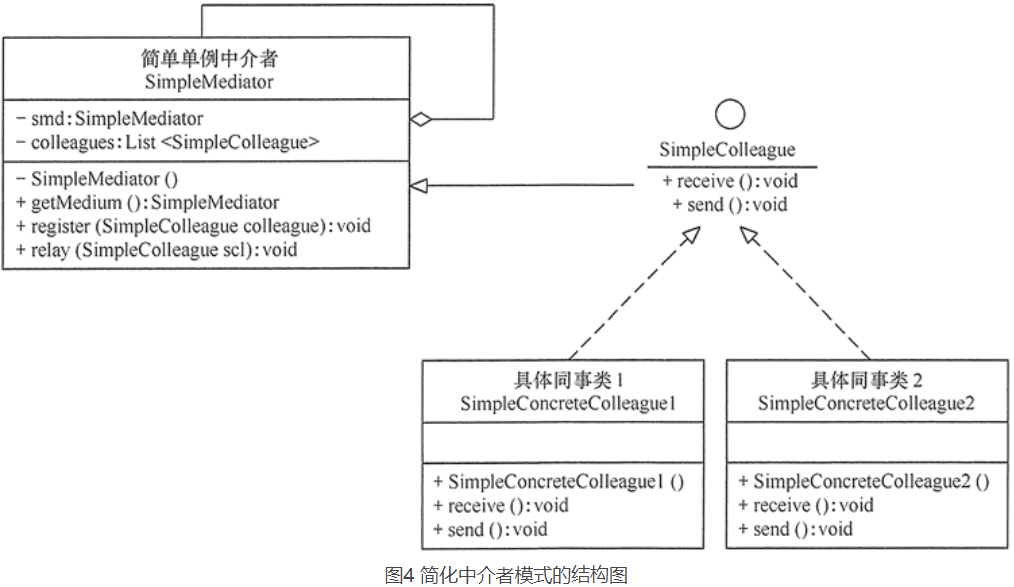
代码实现:
1 | package net.biancheng.c.mediator; |
21.6、进阶阅读
如果您想了解中介者模式在JDK源码中的应用,可猛击阅读《中介者模式在JDK源码中的应用》文章。
21.7、相关设计模式
Facade模式
在Mediator模式中,Mediator 角色与Colleague角色进行交互。
而在Facade模式中,Facade 角色单方面地使用其他角色来对外提供高层接口( API)。因此,可以说Mediator模式是双向的,而Facade模式是单向的。
Observer模式
有时会使用Observer模式来实现Mediator角色与Colleague 角色之间的通信。
21.8、中介者模式的注意事项与细节
- 多个类相互耦合,会形成网状结构,使用中介者模式将网状结构分离为星型结构,进行解耦
- 减少类间依赖,降低了耦合,符合迪米特原则
- 中介者承担了较多的责任,一旦中介者出现了问题,整个系统就会受到影响
- 如果设计不当,中介者对象本身变得过于复杂,这点在实际使用时,要特别注意
22、备忘录模式Memento(行为型模式)
22.1、基本介绍
- 备忘录模式(Memento Pattern),该模式又叫快照模式。在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可将该对象恢复到原先保存的状态。
- 可以这里理解备忘录模式:现实生活中的备忘录是用来记录某些要去做的事情,或者是记录已经达成的共同意见的事情,以防忘记了。而在软件层面,备忘录模式有着相同的含义,备忘录对象主要用来记录一个对象的某种状态,或者某些数据,当用户后悔时能撤销当前操作,使数据恢复到它原先的状态。
- 备忘录模式属于行为型模式。
22.2、备忘录模式的原理结构图-uml类图
备忘录模式的核心是设计备忘录类以及用于管理备忘录的管理者类。
22.2.1、模式的结构
备忘录模式的主要角色如下:
发起人(Originator)角色:记录当前时刻的内部状态信息,提供创建备忘录和恢复备忘录数据的功能,实现其他业务功能,它可以访问备忘录里的所有信息。
备忘录(Memento)角色:负责存储发起人的内部状态,在需要的时候提供这些内部状态给发起人。
Memento角色有以下两种按口( API ):
wide interface - 宽接口( API ):
Memento角色提供的“宽接口( API)”是指所有用于获取恢复对象状态信息的方法的集合。由于宽接口( API)会暴露所有Memento角色的内部信息,因此能够使用宽接口( API)的只有Originator角色。
narrowinterface - 窄接口 ( API ):
Memento角色为外部的Caretaker角色提供了“窄接口( API)”。可以通过窄接口( API)获取的Memento角色的内部信息非常有限,因此可以有效地防止信息泄露。
通过对外提供以上两种接口( API),可以有效地防止对象的封装性被破坏。
守护者(Caretaker)角色:对备忘录进行管理,提供保存与获取备忘录的功能,但其不能对备忘录的内容进行访问与修改。
说明:如果希望保存多个 originator 对象的不同时间的状态也可以,只需要在守护者Caretaker当中使用 HashMap <String, 集合>进行保存就行。
备忘录模式的结构图:
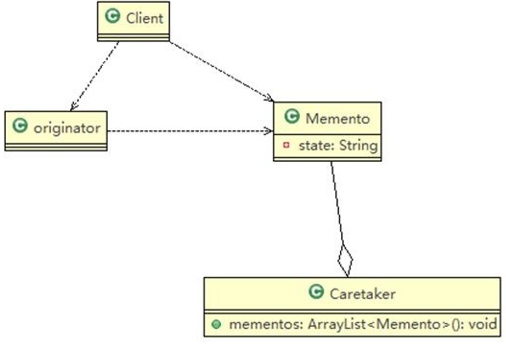
22.2.2、代码实现
发起人(Originator)角色:
1 | public class Originator { |
备忘录(Memento)角色
1 | public class Memento { |
守护者(Caretaker)角色
1 | import java.util.ArrayList; |
Client:客户端
1 | import java.util.ArrayList; |
22.3、应用举例
游戏角色状态恢复问题:
游戏角色有攻击力和防御力,在大战 Boss 前保存自身的状态(攻击力和防御力),当大战 Boss 后攻击力和防御力下降,从备忘录对象恢复到大战前的状态。
22.3.1、使用传统模式解决需求
思路分析(类图):
传统的方式的问题分析:
- 一个对象,就对应一个保存对象状态的对象, 这样当我们游戏的对象很多时,不利于管理,开销也很大。
- 传统的方式是简单地做备份,new 出另外一个对象出来,再把需要备份的数据放到这个新对象,但这就暴露了对象内部的细节
- 解决方案: => 备忘录模式
22.3.2、使用备忘录模式解决需求
思路分析和图解(类图):
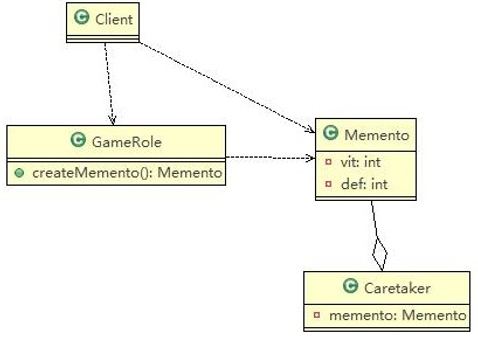
代码实现:
GameRole:游戏角色。发起人(Originator)角色
1 | public class GameRole { |
Memento:备忘录(Memento)角色
1 | public class Memento { |
Caretaker:守护者(Caretaker)角色
1 | import java.util.ArrayList; |
Client:客户端,负责调用。
1 | public class Client { |
22.4、备忘录模式总结
主要优点如下:
- 提供了一种可以恢复状态的机制。当用户需要时能够比较方便地将数据恢复到某个历史的状态。
- 实现了内部状态的封装。除了创建它的发起人之外,其他对象都不能够访问这些状态信息。
- 简化了发起人(Originator)类。发起人不需要管理和保存其内部状态的各个备份,所有状态信息都保存在备忘录中,并由管理者进行管理,这符合单一职责原则。
主要缺点是:
- 资源消耗大。如果要保存的内部状态信息过多或者特别频繁,将会占用比较大的内存资源。而且每一次保存都会消耗一定的内存
备忘录模式应用场景:
- 需要保存与恢复数据的场景,如玩游戏时的中间结果的存档功能。
- 需要提供一个可回滚操作的场景,如 Word、记事本、Photoshop,Eclipse 等软件在编辑时按 Ctrl+Z 组合键,还有数据库中事务操作。
备忘录模式应用实例:
- 后悔药
- 打游戏时的存档
- Windows 里的 ctri + z
- IE 中的后退
- 数据库的事务管理
- 编辑过程中的Undo(撤销)、Redo(重做)、History(历史记录)、Snapshot (快照)都是备忘录模式的应用
22.5、备忘录模式扩展
22.5.1、备忘录模式 + 原型模式
备忘录模式如何同原型模式混合使用。在备忘录模式中,通过定义“备忘录”来备份“发起人”的信息,而原型模式的 clone() 方法具有自备份功能,所以,如果让发起人实现 Cloneable 接口就有备份自己的功能,这时可以删除备忘录类,其结构图
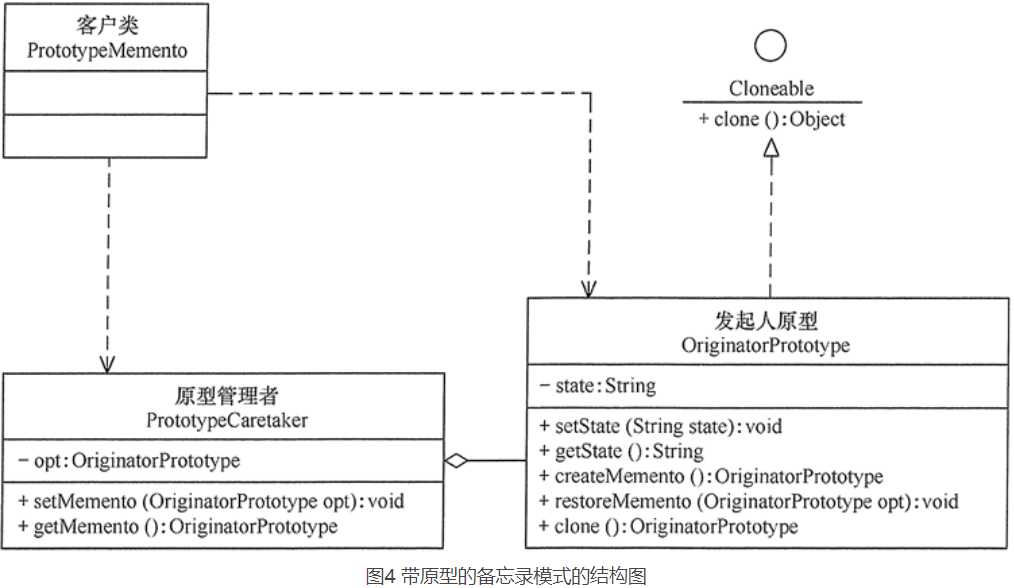
代码实现:
1 | package net.biancheng.c.memento; |
22.5.2、关于备忘录模式在源码当中的应用
由于 JDK、Spring、Mybatis 中很少有备忘录模式,所以该设计模式不做典型应用源码分析。
Spring Webflow 中 DefaultMessageContext 类实现了 StateManageableMessageContext 接口,查看其源码可以发现其主要逻辑就相当于给 Message 备份
22.6、进阶阅读
如果您想了解备忘录模式在实际项目中的应用,可猛击阅读《使用备忘录模式实现草稿箱功能》文章。
22.7、相关设计模式
Command模式
在使用Command模式处理命令时,可以使用Memento模式实现撤销功能。
Protype模式
在Memento模式中,为了能够实现快照和撤销功能,保存了对象当前的状态。保存的信息只是在恢复状态时所需要的那部分信息。
而在Protype模式中,会生成- 一个与当前实例完全相同的另外一个实例。 这两个实例的内容完全一样。
State 模式
在Memento模式中,是用“实例”表示状态。
而在State模式中,则是用“类”表示状态。
22.8、备忘录模式的注意事项与细节
给用户提供了一种可以恢复状态的机制,可以使用户能够比较方便地回到某个历史的状态
实现了信息的封装,使得用户不需要关心状态的保存细节
如果类的成员变量过多,势必会占用比较大的资源,而且每一次保存都会消耗一定的内存, 这个需要注意
为了节约内存,备忘录模式可以和原型模式配合使用
在守护者当中的不同情况:
如果只保存一次状态Memento
1
private Memento memento;
对发起人(Originator)对象保存多次状态Memento
1
private ArrayList<Memento> mementos;
对多个发起人(Originator)角色保存多个状态Memento
1
private HashMap<String, ArrayList<Memento>> rolesMementos;
23、解释器模式Interpreter(行为型模式)
23.1、基本介绍
- 在编译原理中,一个算术表达式通过词法分析器形成词法单元,而后这些词法单元再通过语法分析器构建语法分析树,最终形成一颗抽象的语法分析树。这里的词法分析器和语法分析器都可以看做是解释器
- 解释器模式(Interpreter Pattern):是指给分析对象定义一个语言,并定义该语言的文法表示,再设计一个解析器来解释语言中的句子(表达式)。也就是说,用编译语言的方式来分析应用中的实例。
- 这种模式实现了文法表达式处理的接口,该接口解释一个特定的上下文。
- 这里提到的文法和句子的概念同编译原理中的描述相同,“文法”指语言的语法规则,而“句子”是语言集中的元素。
23.2、编译原理中的“文法、句子、语法树”等相关概念
23.2.1、文法
文法是用于描述语言的语法结构的形式规则。没有规矩不成方圆,例如,有些人认为完美爱情的准则是“相互吸引、感情专一、任何一方都没有恋爱经历”,虽然最后一条准则较苛刻,但任何事情都要有规则,语言也一样,不管它是机器语言还是自然语言,都有它自己的文法规则。
例如,中文中的“句子”的文法如下:
注:这里的符号“::=”表示“定义为”的意思,用“〈”和“〉”括住的是非终结符,没有括住的是终结符。
1 | 〈句子〉::=〈主语〉〈谓语〉〈宾语〉 |
23.2.2、句子
句子是语言的基本单位,是语言集中的一个元素,它由终结符构成,能由“文法”推导出。
例如,上述文法可以推出“我是大学生”,所以它是句子。
23.2.3、语法树
语法树是句子结构的一种树型表示,它代表了句子的推导结果,它有利于理解句子语法结构的层次。
下图所示是“我是大学生”的语法树:
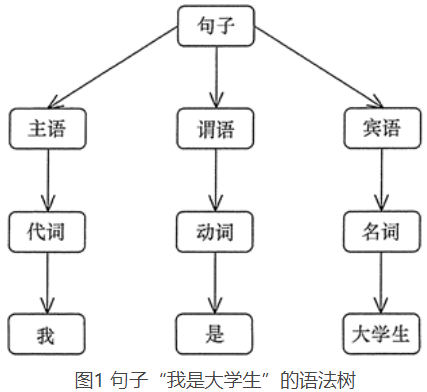
解释器模式的结构与组合模式相似,不过其包含的组成元素比组合模式多,而且组合模式是对象结构型模式,而解释器模式是类行为型模式。
23.3、解释器模式的原理结构图-uml类图
23.3.1、模式的结构
解释器模式包含以下主要角色:
- 抽象表达式(Abstract Expression)角色:定义解释器的接口,约定解释器的解释操作,主要**包含解释方法 interpret()**,这个方法为抽象语法树中所有的节点所共享。
- 终结符表达式(Terminal Expression)角色:是抽象表达式的子类,用来实现文法中与终结符相关的操作,文法中的每一个终结符都有一个具体终结表达式与之相对应。
- 非终结符表达式(Nonterminal Expression)角色:也是抽象表达式的子类,用来实现文法中与非终结符相关的操作,文法中的每条规则都对应于一个非终结符表达式。
- 环境(Context)角色:通常包含各个解释器需要的数据或是公共的功能,一般用来传递被所有解释器共享的数据,后面的解释器可以从这里获取这些值。
- 客户端(Client):主要任务是将需要分析的句子或表达式转换成使用解释器对象描述的抽象语法树,然后调用解释器的解释方法,当然也可以通过环境角色间接访问解释器的解释方法。
解释器模式的结构图:
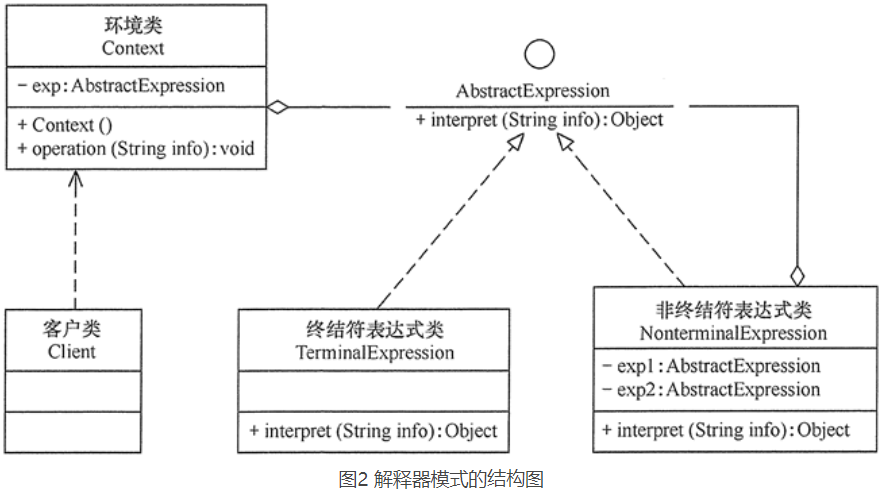
23.3.2、代码实现
解释器模式实现的关键是定义文法规则、设计终结符类与非终结符类、画出结构图,必要时构建语法树,其代码结构如下:
1 | package net.biancheng.c.interpreter; |
23.4、应用举例
四则运算问题:
通过解释器模式来实现四则运算,如计算 a+b-c 的值,具体要求:
先输入表达式的形式,比如 a+b+c-d+e, 要求表达式的字母不能重复
在分别输入 a ,b, c, d, e 的值
最后求出结果:如图

23.4.1、使用传统方式解决需求
传统方案解决四则运算问题分析:
- 编写一个方法,接收表达式的形式,然后根据用户输入的数值进行解析,得到结果
- 问题分析:如果加入新的运算符,比如
*(乘)/(除) 等等,不利于扩展,另外让一个方法来解析会造成程序结构混乱,不够清晰。 - 解决方案:可以考虑使用解释器模式,即: 表达式 -> 解释器(可以有多种) -> 结果
23.4.2、使用解释器模式解决需求
思路分析和图解(类图):
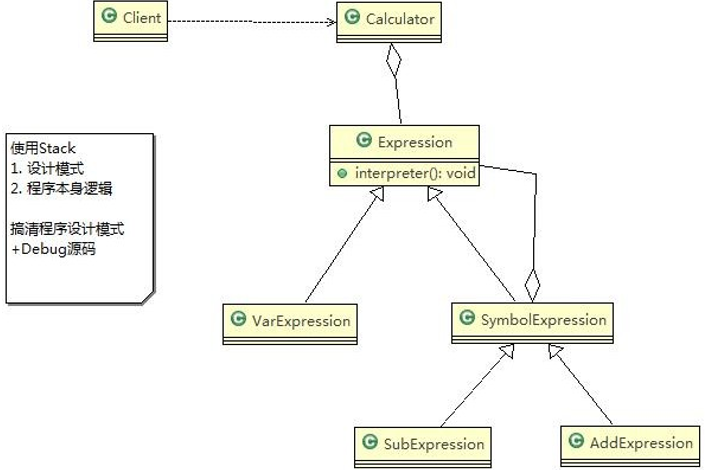
代码实现:
Expression:抽象表达式(Abstract Expression)
1 | import java.util.HashMap; |
VarExpression:变量的解释器。终结符表达式(Terminal Expression)
1 | import java.util.HashMap; |
SymbolExpression:抽象运算符号解析器。非终结符表达式(Nonterminal Expression)
1 | import java.util.HashMap; |
AddExpression:加法解释器(减法解释器SubExpression类似)继承了SymbolExpression
1 | import java.util.HashMap; |
Calculator:计算器。环境(Context)
1 | import java.util.HashMap; |
Client:客户端。负责调用
1 | import java.io.BufferedReader; |
23.5、解释器模式在Spring框架的应用与源码
Spring 框架中 SpelExpressionParser 就使用到解释器模式
代码分析+Debug源码:
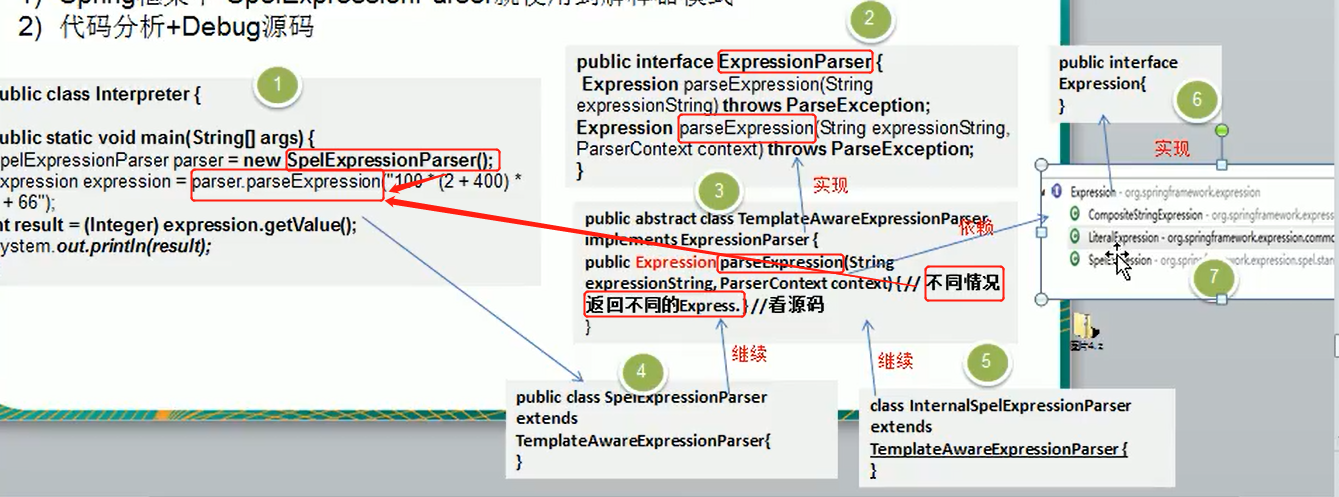
main:
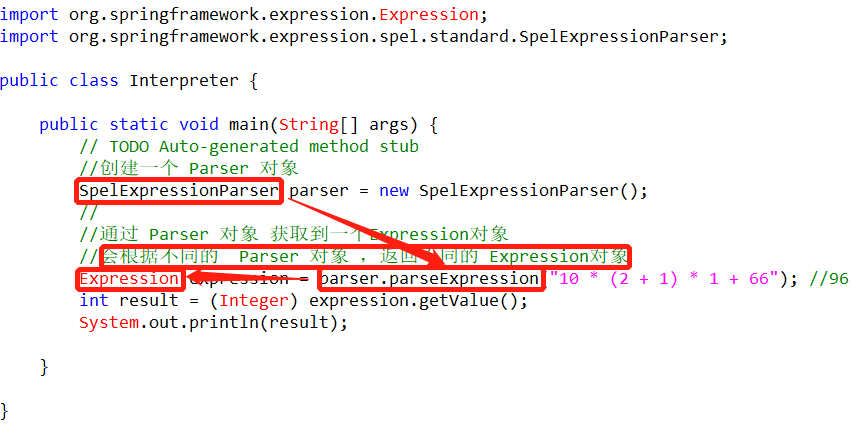
Expression接口:
SpelExpressionParser的parseExpression()方法是继承了其父类TemplateAwareExpressionParser的parseExpression()方法,而TemplateAwareExpressionParser又实现了ExpressionParser接口



TemplateAwareExpressionParser的parseExpression()方法:

其中的parseTemplate()方法
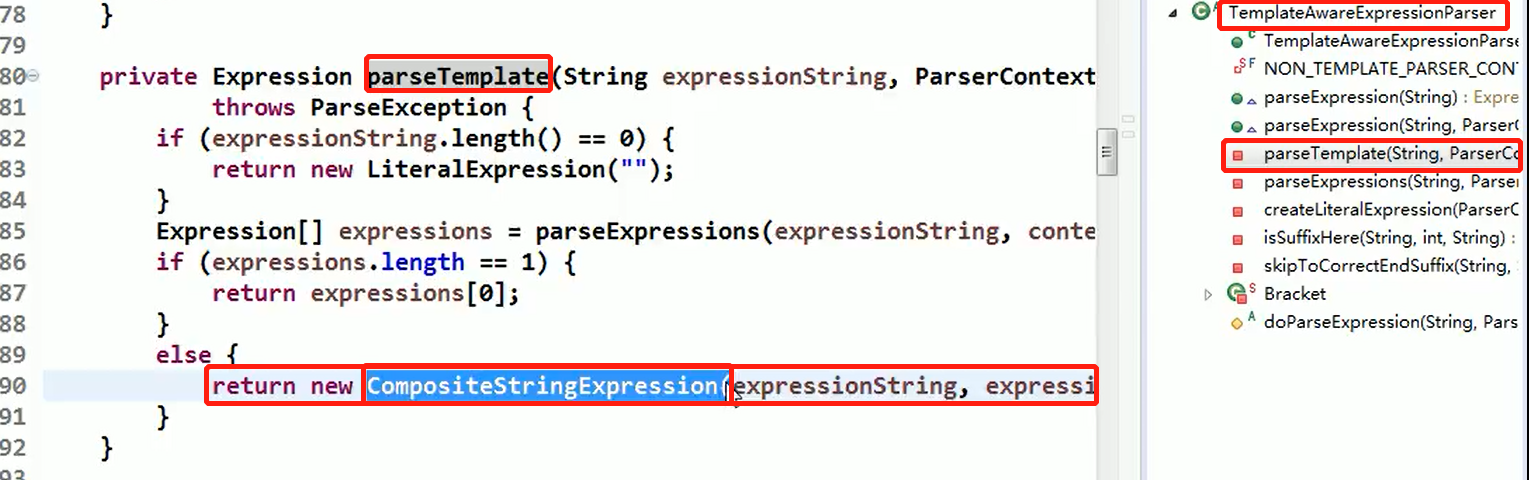
其中的doParseTemplate()方法

子类SpelExpressionParser实现了父类TemplateAwareExpressionParser的doParseTemplate()方法
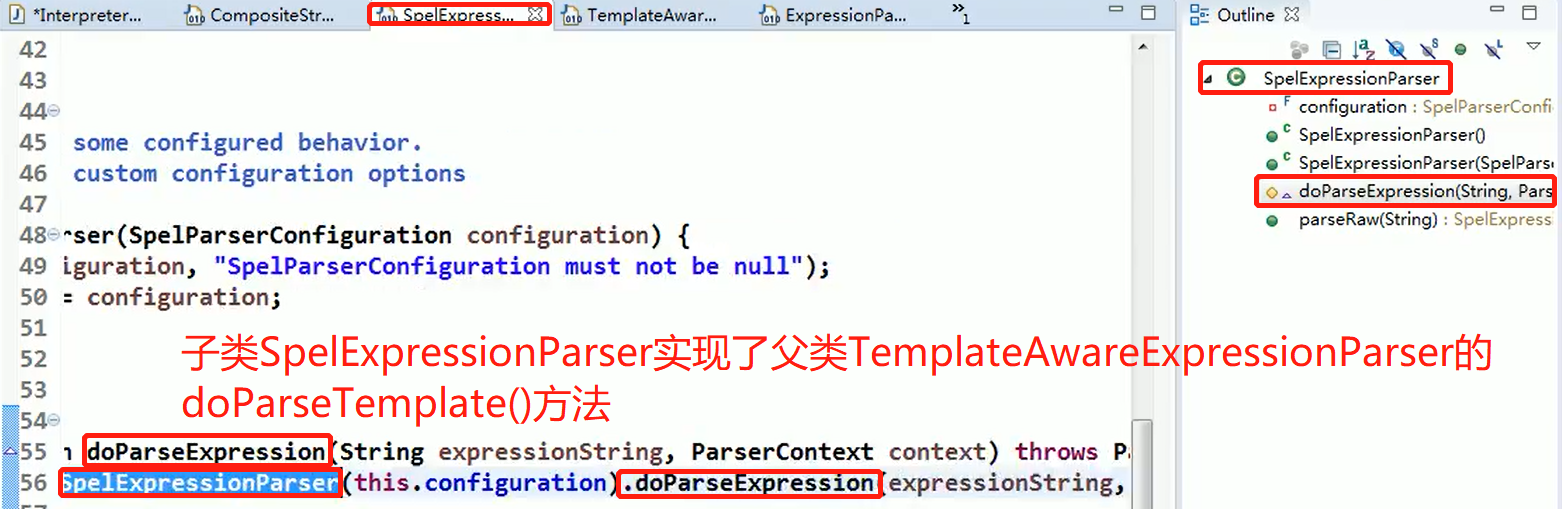
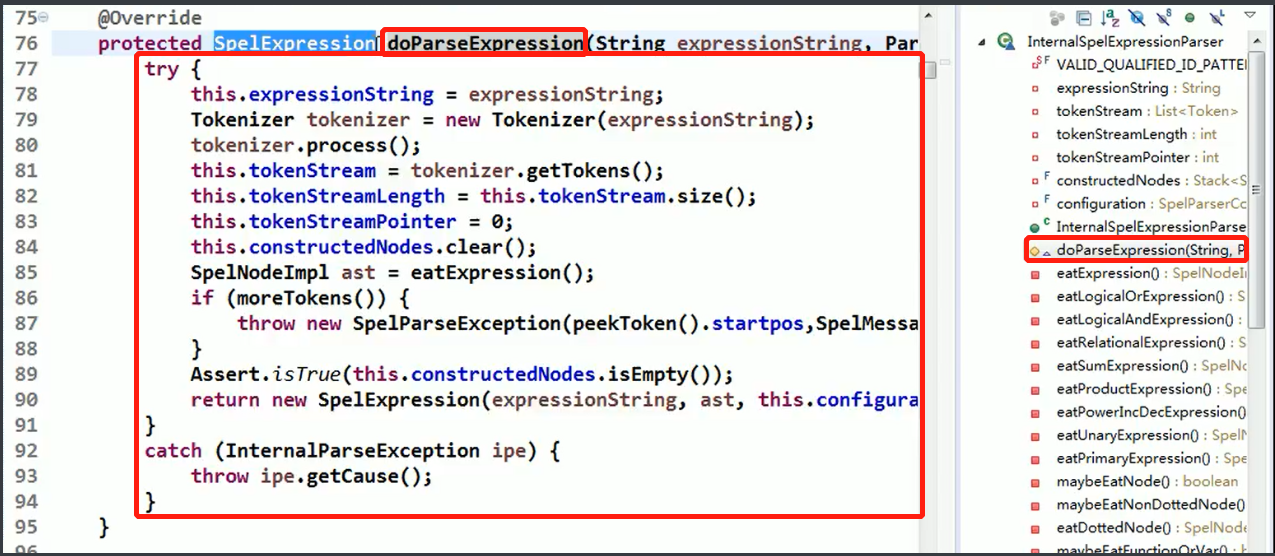
说明:

23.6、解释器模式总结
主要优点如下:
- 扩展性好。由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。
- 容易实现。在语法树中的每个表达式节点类都是相似的,所以实现其文法较为容易。
主要缺点如下:
- 执行效率较低。解释器模式中通常使用大量的循环和递归调用,当要解释的句子较复杂时,其运行速度很慢,且代码的调试过程也比较麻烦。
- 会引起类膨胀。解释器模式中的每条规则至少需要定义一个类,当包含的文法规则很多时,类的个数将急剧增加,导致系统难以管理与维护。
- 可应用的场景比较少。在软件开发中,需要定义语言文法的应用实例非常少,所以这种模式很少被使用到。
应用场景:
- 当语言的文法较为简单,且执行效率不是关键问题时。
- 当问题重复出现,且可以用一种简单的语言来进行表达时。
- 当一个语言需要解释执行,并且语言中的句子可以表示为一个抽象语法树的时候,如 XML 文档解释。
应用实例:编译器、运算表达式计算、正则表达式、机器人等
注意:解释器模式在实际的软件开发中使用比较少,因为它会引起效率、性能以及维护等问题。如果碰到对表达式的解释,在 Java 中可以用 Expression4J 或 Jep 等来设计。
23.7、解释器模式扩展
在项目开发中,如果要对数据表达式进行分析与计算,无须再用解释器模式进行设计了,Java 提供了以下强大的数学公式解析器:Expression4J、MESP(Math Expression String Parser) 和 Jep 等,它们可以解释一些复杂的文法,功能强大,使用简单。
现在以 Jep 为例来介绍该工具包的使用方法。Jep 是 Java expression parser 的简称,即 Java 表达式分析器,它是一个用来转换和计算数学表达式的 Java 库。通过这个程序库,用户可以以字符串的形式输入一个任意的公式,然后快速地计算出其结果。而且 Jep 支持用户自定义变量、常量和函数,它包括许多常用的数学函数和常量。
下面以计算存款利息为例来介绍。存款利息的计算公式是:本金x利率x时间=利息,其相关代码如下:
1 | package net.biancheng.c.interpreter; |
23.8、进阶阅读
如果您想了解解释器模式在框架源码中的应用,可猛击阅读《解释器模式在JDK和Spring源码中的应用》文章。
23.9、相关设计模式
Composite模式
NonterminalExpression角色多是递归结构,因此常会使用Composite模式来实现NonterminalExpression角色
Flyweight 模式
有时会使用Flyweight模式来共享TerminalExpression角色。
Visitor 模式
在推导出语法树后,有时会使用Visitor模式来访问语法树的各个节点。
23.10、解释器模式的注意事项与细节
- 当有一个语言需要解释执行,可将该语言中的句子表示为一个抽象语法树,就可以考虑使用解释器模式,让程序具有良好的扩展
- 使用解释器可能带来的问题:解释器模式会引起类膨胀、解释器模式采用递归调用方法,将会导致调试非常复杂、效率可能降低。
- 解释器模式通过抽象语法树实现对用户输入的解释执行。
- 解释器模式的实现通常非常复杂,且一般只能解决一类特定问题。
24、状态模式State(行为型模式)
24.1、基本介绍
- 状态模式(State Pattern):它主要用来解决对象在多种状态转换时,需要对外输出不同的行为的问题。状态和行为是一一对应的,状态之间可以相互转换
- 对有状态的对象,把复杂的“判断逻辑”提取到不同的状态对象中,允许状态对象在其内部状态发生改变时改变其行为。
- 当一个对象的内在状态改变时,允许改变其行为,这个对象看起来像是改变了其类
- 替代了使用if-else解决问题
24.2、状态模式的原理结构图-uml类图
状态模式把受环境改变的对象行为包装在不同的状态对象里,其意图是让一个对象在其内部状态改变的时候,其行为也随之改变。
24.2.1、模式的结构
状态模式包含以下主要角色:
- 环境类(Context)角色:也称为上下文,它定义了客户端需要的接口,内部维护一个当前状态,并负责具体状态的切换。
- 抽象状态(State)角色:定义一个接口,用以封装环境对象中的特定状态所对应的行为,可以有一个或多个行为。
- 具体状态(Concrete State)角色:实现抽象状态所对应的行为,并且在需要的情况下进行状态切换。
其结构图类图:
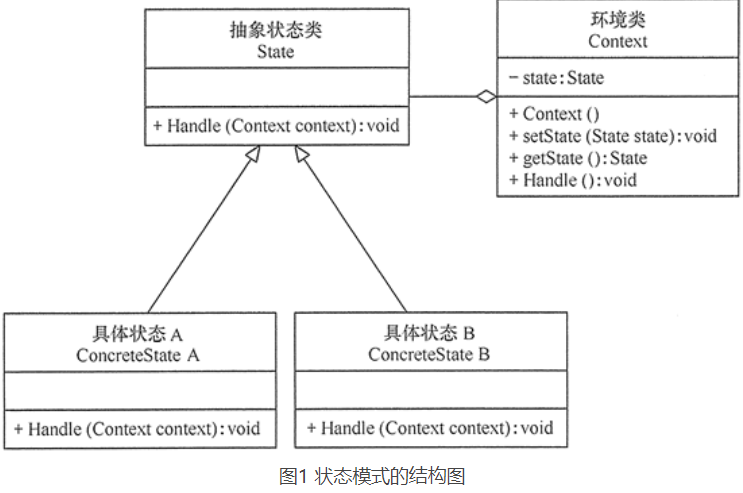
24.2.2、代码实现
1 | public class StatePatternClient { |
24.3、应用举例
APP 抽奖活动问题:
请编写程序完成 APP 抽奖活动 具体要求如下:
假如每参加一次这个活动要扣除用户 50 积分,中奖概率是 10%
奖品数量固定,抽完就不能抽奖
活动有四个状态:
- 可以抽奖
- 不能抽奖
- 发放奖品
- 奖品领完
活动的四个状态转换关系图:
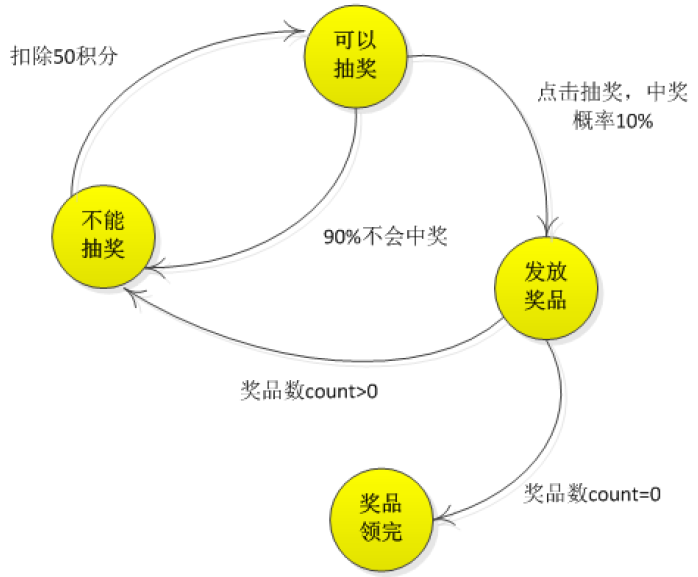
24.3.1、使用传统方式解决需求
通常通过if/else判断抽奖的状态,从而实现不同的逻辑,伪代码如下
1 | if(不能抽奖){ |
传统的方式的问题分析:
- 这类代码难以应对变化,在添加一种状态时,我们需要手动添加if/else
- 在添加一种功能时,要对所有的状态进行判断。
- 因此代码会变得越来越臃肿,并且一旦没有处理某个状态,便会发生极其严重的BUG,难以维护
- 不符合开闭原则
24.3.2、使用状态模式解决需求
思路分析和图解(类图)
- 定义出一个接口叫状态接口,每个状态都实现它。
- 接口有扣除积分方法、抽奖方法、发放奖品方法
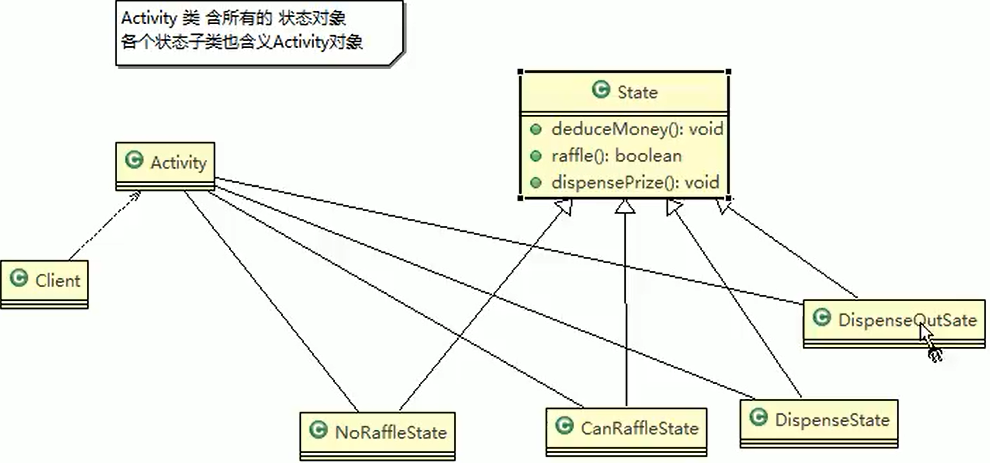
代码实现:
State:抽象状态(State)
1 | /** |
具体状态(Concrete State):四种状态:
NoRaffleState:不能抽奖状态
1 | /** |
CanRaffleState:可以抽奖的状态
1 | import java.util.Random; |
DispenseState:发放奖品的状态
1 | /** |
DispenseOutState:奖品发放完毕状态
1 | /** |
Activity:抽奖活动。环境类(Context)
1 | /** |
Client:客户端,调用者。
1 | /** |
24.4、状态模式在实际项目-借贷平台源码分析
借贷平台的订单,有审核-发布-抢单 等等 步骤,随着操作的不同,会改变订单的状态, 项目中的这个模块实现就会使用到状态模式:
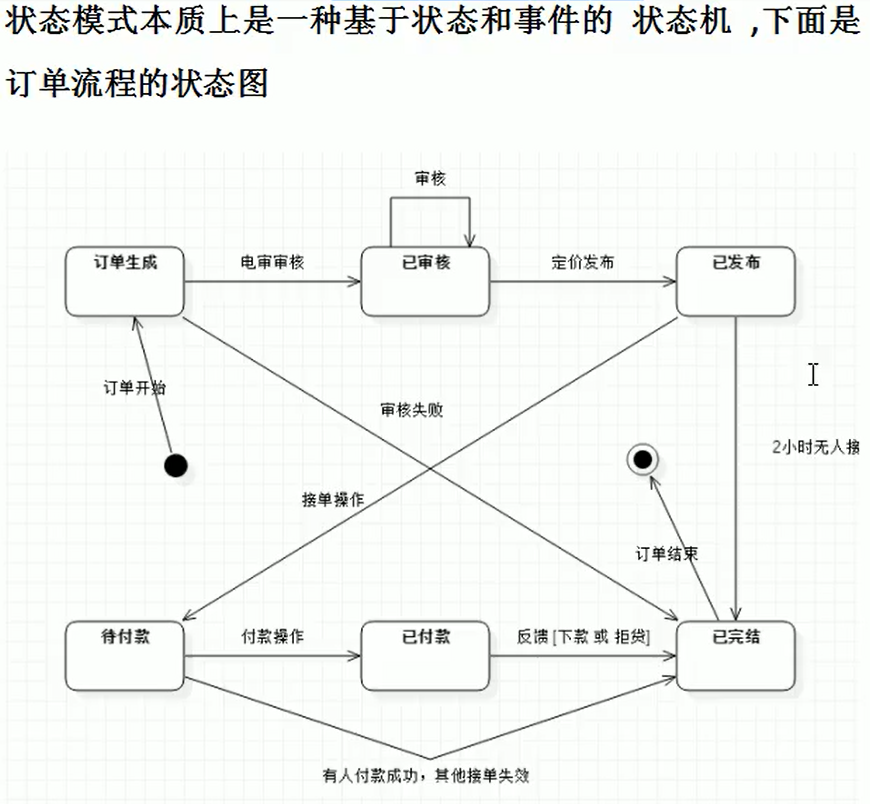

实现类图:
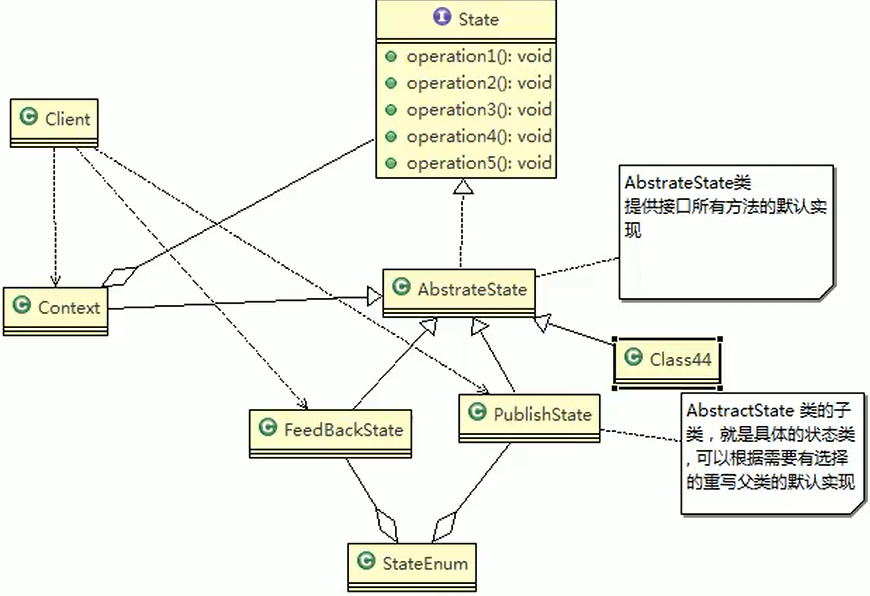
代码实现:
State:
1 | /** |
AbstractState:实现State接口方法的默认实现。子类通过自己的需求进行重写
1 | public abstract class AbstractState implements State { |
各种具体状态类:
1 | //各种具体状态类 |
StateEnum:状态枚举类
1 | /** |
Context:环境上下文
1 | //环境上下文 |
ClientTest:测试类
1 | /**测试类*/ |
24.5、状态模式总结
主要优点如下:
- 结构清晰,状态模式将与特定状态相关的行为局部化到一个状态中,并且将不同状态的行为分割开来,满足“单一职责原则”。
- 枚举可能的状态,在枚举状态之前需要确定状态种类。
- 将状态转换显示化,减少对象间的相互依赖。将不同的状态引入独立的对象中会使得状态转换变得更加明确,且减少对象间的相互依赖。
- 允许状态转换逻辑与状态对象合成一体,而不是某一个巨大的条件语句块。
- 将所有与某个状态有关的行为放到一个类中,并且可以方便地增加新的状态,只需要改变对象状态即可改变对象的行为。
- 可以让多个环境对象共享一个状态对象,从而减少系统中对象的个数
- 状态类职责明确,有利于程序的扩展。通过定义新的子类很容易地增加新的状态和转换。
状态模式的主要缺点如下:
- 状态模式的使用必然会增加系统的类与对象的个数。
- 状态模式的结构与实现都较为复杂,如果使用不当会导致程序结构和代码的混乱。
- 状态模式对开闭原则的支持并不太好,对于可以切换状态的状态模式,增加新的状态类需要修改那些负责状态转换的源码,否则无法切换到新增状态,而且修改某个状态类的行为也需要修改对应类的源码。
状态模式的应用场景:
- 当一个对象的行为取决于它的状态,并且它必须在运行时根据状态改变它的行为时,就可以考虑使用状态模式。
- 一个操作中含有庞大的分支结构,并且这些分支决定于对象的状态时。
- 当一个事件或者对象有很多种状态,状态之间会相互转换,对不同的状态要求有不同的行为的时候, 可以考虑使用状态模式
24.6、状态模式扩展
24.6.1、状态模式 + 享元模式
在有些情况下,可能有多个环境对象需要共享一组状态,这时需要引入享元模式,将这些具体状态对象放在集合中供程序共享,其结构图:
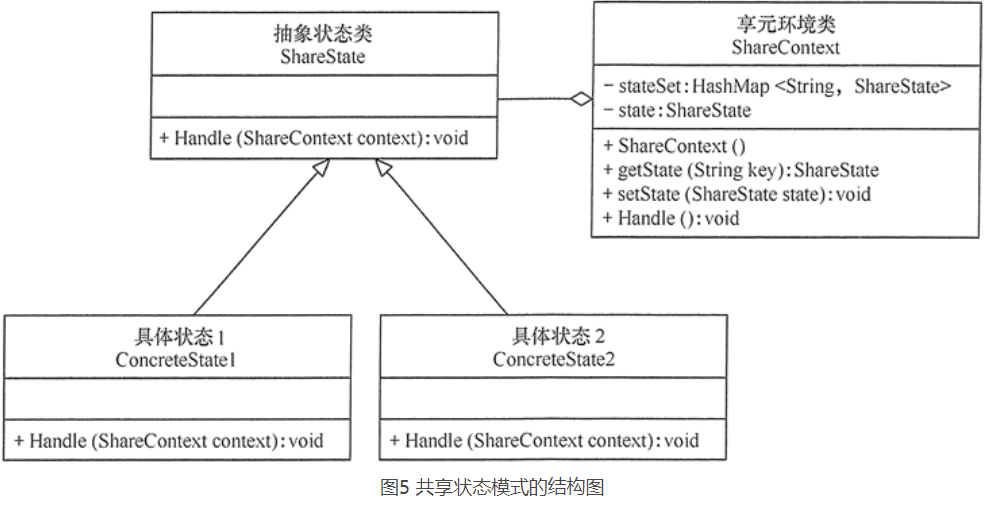
分析:共享状态模式的不同之处是在环境类中增加了一个 HashMap 来保存相关状态,当需要某种状态时可以从中获取,其程序代码如下:
1 | package state; |
24.6.2、状态模式与责任链模式的区别
- 状态模式和责任链模式都能消除 if-else 分支过多的问题。但在某些情况下,状态模式中的状态可以理解为责任,那么在这种情况下,两种模式都可以使用。
- 从定义来看,状态模式强调的是一个对象内在状态的改变,而责任链模式强调的是外部节点对象间的改变。
- 从代码实现上来看,两者最大的区别就是状态模式的各个状态对象知道自己要进入的下一个状态对象,而责任链模式并不清楚其下一个节点处理对象,因为链式组装由客户端负责。
24.6.3、状态模式与策略模式的区别
状态模式和策略模式的 UML 类图架构几乎完全一样,但两者的应用场景是不一样的。策略模式的多种算法行为择其一都能满足,彼此之间是独立的,用户可自行更换策略算法,而状态模式的各个状态间存在相互关系,彼此之间在一定条件下存在自动切换状态的效果,并且用户无法指定状态,只能设置初始状态。
24.7、进阶阅读
如果您想深入了解状态模式,可猛击阅读以下文章。
24.8、相关设计模式
Singleton 模式
Singleton模式常常会出现在ConcreteState角色中。这是因为在表示状态的类中并没有定义任何实例字段(即表示实例的状态的字段)。
Flyweight 模式
在表示状态的类中并没有定义任何实例字段。因此,有时我们可以使用Flyweight模式在多个Context角色之间共享ConcreteState角色。
24.9、状态模式的注意事项与细节
- 代码有很强的可读性。状态模式将每个状态的行为封装到对应的一个类中
- 方便维护。将容易产生问题的 if-else 语句删除了,如果把每个状态的行为都放到一个类中,每次调用方法时都要判断当前是什么状态,不但会产出很多 if-else 语句,而且容易出错
- 会产生很多类。每个状态都要一个对应的类,当状态过多时会产生很多类,加大维护难度
25、策略模式Strategy(行为型模式)
25.1、基本介绍
- 策略模式(Strategy Pattern)中,定义算法族(策略组),分别封装起来,让他们之间可以互相替换,此模式让算法的变化独立于使用算法的客户
- 策略模式属于对象行为模式,它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。
- 在策略模式中,我们创建表示各种策略的对象和一个行为随着策略对象改变而改变的 context 对象。策略对象改变 context 对象的执行算法。
- 策略模式的核心思想是在一个计算方法中把容易变化的算法抽出来作为“策略”参数传进去,从而使得新增策略不必修改原有逻辑。
- 这算法体现了几个设计原则:
- 把变化的代码从不变的代码中分离出来
- 第二、针对接口编程而不是具体类(定义了策略接口)
- 第三、多用组合/聚合,少用继承(客户通过组合方式使用策略)。
25.2、策略模式的原理结构图-uml类图
策略模式是准备一组算法,并将这组算法封装到一系列的策略类里面,作为一个抽象策略类的子类。策略模式的重心不是如何实现算法,而是如何组织这些算法,从而让程序结构更加灵活,具有更好的维护性和扩展性。
25.2.1、模式的结构
策略模式的主要角色如下:
- 抽象策略(Strategy)类:定义了一个公共接口,各种不同的算法以不同的方式实现这个接口,环境角色使用这个接口调用不同的算法,一般使用接口或抽象类实现。
- 具体策略(Concrete Strategy)类:实现了抽象策略定义的接口,提供具体的算法实现。
- 环境(Context)类:持有一个策略类的引用,最终给客户端调用。
其结构图如图:
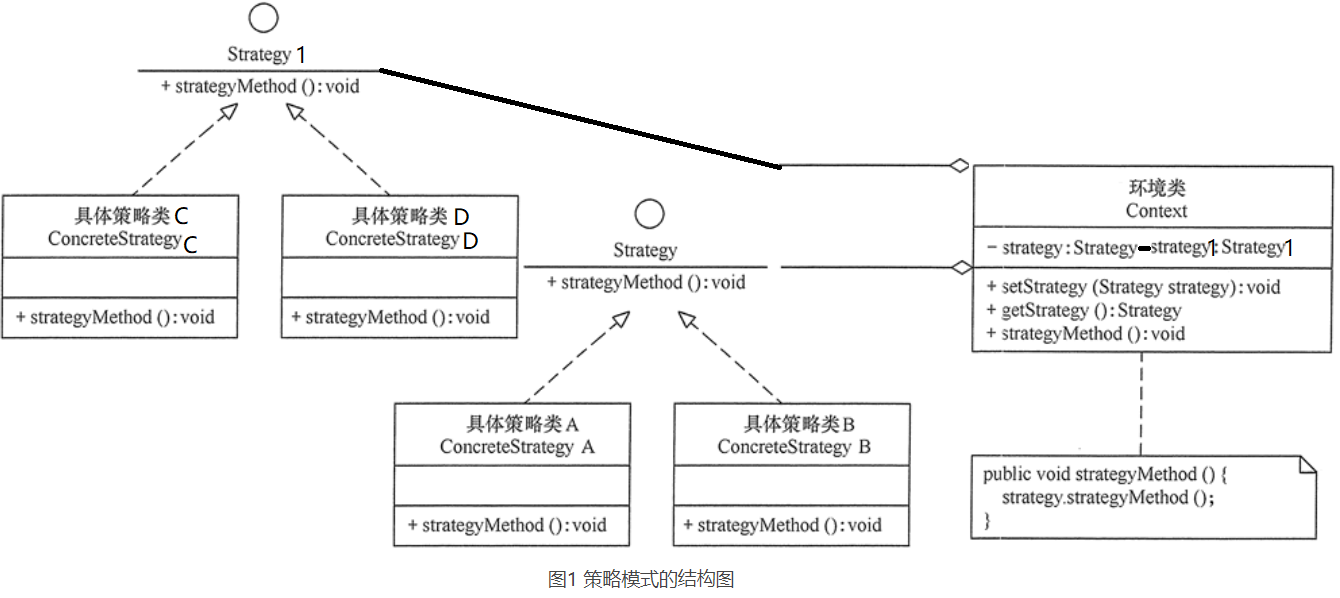
25.3.2、代码实现
1 | public class StrategyPattern { |
25.3、应用举例
编写鸭子项目,具体要求如下:
- 有各种鸭子(比如 野鸭、北京鸭、水鸭等, 鸭子有各种行为,比如 叫、飞行等)
- 显示鸭子的信息
25.3.1、使用传统方式解决需求
传统的设计方案(类图):
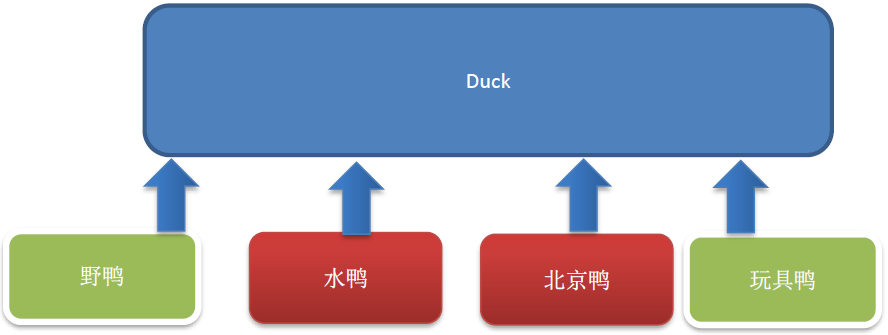
传统的方式实现的问题分析和解决方案:
- 其它鸭子,都继承了 Duck 类,所以 fly 让所有子类都会飞了,这是不正确的
- 上面说的 1 的问题,其实是继承带来的问题:对类的局部改动,尤其超类的局部改动,会影响其他部分。会有溢出效应
- 为了改进 1 问题,我们可以通过覆盖 fly 方法来解决 => 覆盖解决
- 问题又来了,如果我们有一个玩具鸭子 ToyDuck, 这样就需要 ToyDuck 去覆盖 Duck 的所有实现的方法 => 解决思路 -》 策略模式 (strategy pattern)
25.3.2、使用策略模式解决需求
思路分析(类图):
策略模式:分别封装行为接口,实现算法族,超类里放行为接口对象,在子类里具体设定行为对象。
原则就是: 分离变化部分,封装接口,基于接口编程各种功能。此模式让行为的变化独立于算法的使用者。
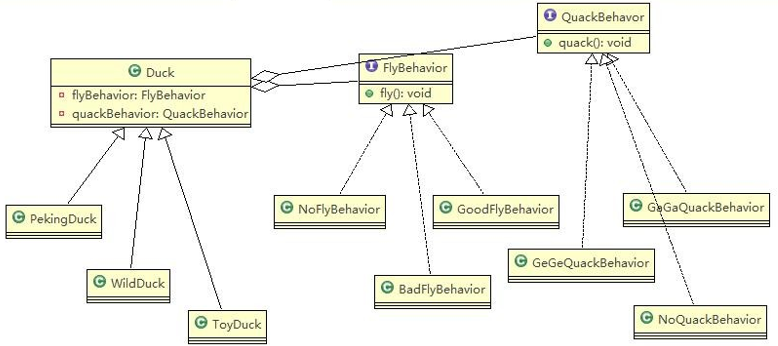
代码实现:
FlyBehavior:飞行。(QuackBehavior:叫行为。等等其它抽象策略与其具体实现类类似)抽象策略(Strategy)
1 | public interface FlyBehavior { |
GoodFlyBehavior:飞行技术高超。(BadFlyBehavior:飞行技术一般、NoFlyBehavior:不会飞行等等类似)具体策略(Concrete Strategy)
1 | public class GoodFlyBehavior implements FlyBehavior { |
Duck:鸭子抽象类。环境(Context)
1 | public abstract class Duck { |
WildDuck:野鸭具体类,继承了鸭子抽象类。(PekingDuck:北京鸭,飞行技术一般、ToyDuck:玩具鸭,不会飞行类似)
1 | public class WildDuck extends Duck { |
Client:客户端,负责调用
1 | public class Client { |
25.4、策略模式在JDK的应用与源码
JDK 的 Arrays 的 Comparator 就使用了策略模式
代码分析+Debug 源码:

main:
1 | import java.util.Arrays; |
Comparator

Array的sort排序方法
25.5、 策略模式总结
主要优点如下:
- 多重条件语句不易维护,而使用策略模式可以避免使用多重条件语句,如 if…else 语句、switch…case 语句。
- 策略模式提供了一系列的可供重用的算法族,恰当使用继承可以把算法族的公共代码转移到父类里面,从而避免重复的代码。
- 策略模式可以提供相同行为的不同实现,客户可以根据不同时间或空间要求选择不同的实现。
- 策略模式提供了对开闭原则的完美支持,可以在不修改原代码的情况下,灵活增加新算法。
- 策略模式把算法的使用放到环境类中,而算法的实现移到具体策略类中,实现了二者的分离。
其主要缺点如下:
- 所有策略类都需要对外暴露。客户端必须理解所有策略算法的区别,以便适时选择恰当的算法类。
- 策略模式造成很多的策略类,增加维护难度。
策略模式的应用场景:
策略模式在很多地方用到,如 Java SE 中的容器布局管理就是一个典型的实例,Java SE 中的每个容器都存在多种布局供用户选择。在程序设计中,通常在以下几种情况中使用策略模式较多。
- 一个系统需要动态地在几种算法中选择一种时,可将每个算法封装到策略类中。
- 一个类定义了多种行为,并且这些行为在这个类的操作中以多个条件语句的形式出现,可将每个条件分支移入它们各自的策略类中以代替这些条件语句。
- 系统中各算法彼此完全独立,且要求对客户隐藏具体算法的实现细节时。
- 系统要求使用算法的客户不应该知道其操作的数据时,可使用策略模式来隐藏与算法相关的数据结构。
- 多个类只区别在表现行为不同,可以使用策略模式,在运行时动态选择具体要执行的行为。
25.6、策略模式扩展(策略模式+工厂模式)
在一个使用策略模式的系统中,当存在的策略很多时,客户端管理所有策略算法将变得很复杂,如果在环境类中使用策略工厂模式来管理这些策略类将大大减少客户端的工作复杂度,其结构图如图:
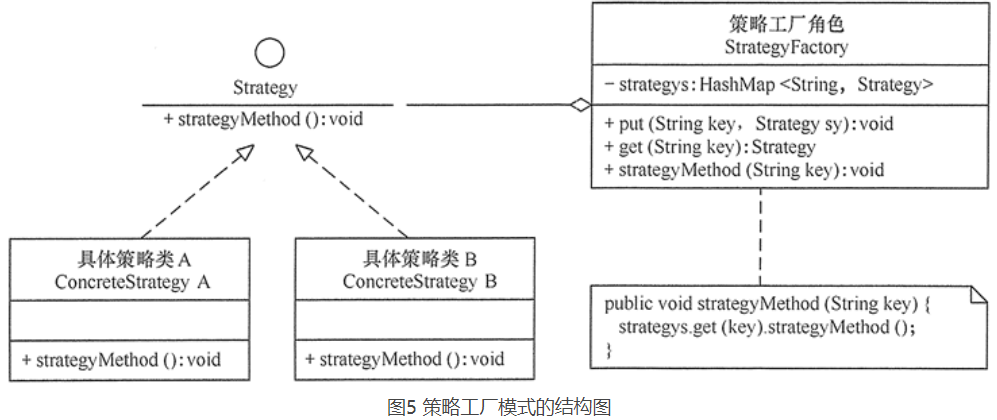
25.7、进阶阅读
如果您想深入了解策略模式,可猛击阅读以下文章。
25.8、相关设计模式
Flyweight模式
有时会使用Flyweight模式让多个地方可以共用ConcreteStrategy角色。
Abstract Factory模式
使用Strategy模式可以整体地替换算法。
使用Abstract Factory模式则可以整体地替换具体工厂、零件和产品。
State 模式
使用Strategy模式和State模式都可以替换被委托对象,而且它们的类之间的关系也很相似。但是两种模式的目的不同。
在Strategy模式中,ConcreteStrategy 角色是表示算法的类。在Strategy模式中,可以替换被委托对象的类。当然如果没有必要,也可以不替换。
而在State模式中,ConcreteState角色是表示“状态”的类。在State模式中,每次状态变化时,被委托对象的类都必定会被替换。
25.9、策略模式的注意事项与细节
- 策略模式的关键是:分析项目中变化部分与不变部分
- 策略模式的核心思想是:多用组合/聚合 少用继承;用行为类组合,而不是行为的继承。更有弹性
- 体现了“对修改关闭,对扩展开放”原则,客户端增加行为不用修改原有代码,只要添加一种策略(或者行为) 即可,避免了使用多重转移语句(if..else if..else)
- 提供了可以替换继承关系的办法: 策略模式将算法封装在独立的 Strategy 类中使得你可以独立于其 Context 改变它,使它易于切换、易于理解、易于扩展
- 需要注意的是:每添加一个策略就要增加一个类,当策略过多是会导致类数目庞大
- 如果一个系统的策略多于四个,就需要考虑使用混合模式(策略模式+工厂模式),解决策略类膨胀的问题。
26、职责链模式Chain of Responsibility(行为型模式)
26.1、基本介绍
- 职责链模式(Chain of Responsibility Pattern), 又叫责任链模式,为请求创建了一个接收者对象的链。这种模式对请求的发送者和接收者进行解耦。
- 为了避免请求发送者与多个请求处理者耦合在一起,于是将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。
- 职责链模式通常每个接收者都包含对另一个接收者的引用(形成闭环)。如果一个对象不能处理该请求,那么它会把相同的请求传给下一个接收者,依此类推。
- 在责任链模式中,客户只需要将请求发送到责任链上即可,无须关心请求的处理细节和请求的传递过程,请求会自动进行传递。所以责任链将请求的发送者和请求的处理者解耦了。
- 这种类型的设计模式属于行为型模式
26.2、职责链模式的原理结构图-uml类图
通常情况下,可以通过数据链表来实现职责链模式的数据结构。
26.2.1、模式的结构
职责链模式主要包含以下角色:
- 抽象处理者(Handler)角色:定义一个处理请求的接口,包含抽象处理方法和一个后继连接Handler对象。
- 具体处理者(Concrete Handler)角色:实现抽象处理者的处理方法,判断能否处理本次请求,如果可以处理请求则处理,否则将该请求转给它的后继者。从而形成一个职责链。
- 请求类(Request)角色 , 含义很多属性,表示一个请求
- 客户类(Client)角色:创建处理链,并向链头的具体处理者对象提交请求,它不关心处理细节和请求的传递过程。
责任链模式的本质是解耦请求与处理,让请求在处理链中能进行传递与被处理;理解责任链模式应当理解其模式,而不是其具体实现。责任链模式的独到之处是将其节点处理者组合成了链式结构,并允许节点自身决定是否进行请求处理或转发,相当于让请求流动起来。
其结构图如图:
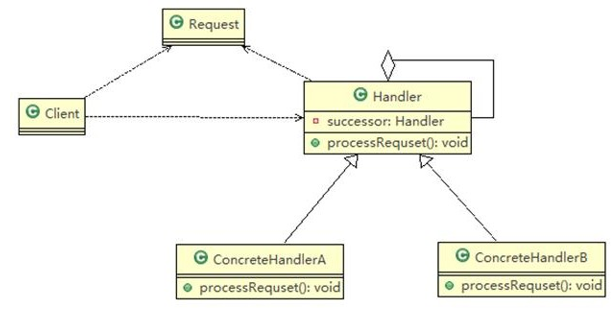
客户端可按下图所示设置责任链:
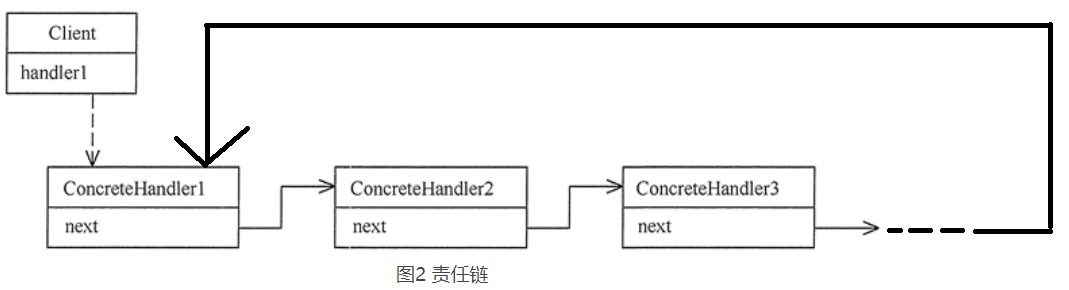
26.2.2、代码实现
1 | package chainOfResponsibility; |
在上面代码中,我们把消息硬编码为 String 类型,而在真实业务中,消息是具备多样性的,可以是 int、String 或者自定义类型。因此,在上面代码的基础上,可以对消息类型进行抽象 Request,增强了消息的兼容性。
26.3、应用举例
学校 OA 系统的采购审批项目:需求是
采购员采购教学器材
- 如果金额 小于等于 5000, 由教学主任审批 (0<=x<=5000)
- 如果金额 小于等于 10000, 由院长审批 (5000<x<=10000)
- 如果金额 小于等于 30000, 由副校长审批 (10000<x<=30000)
- 如果金额 超过 30000 以上,有校长审批 ( 30000<x)
请设计程序完成采购审批项目
26.3.1、使用传统方法解决需求
思路分析(类图):
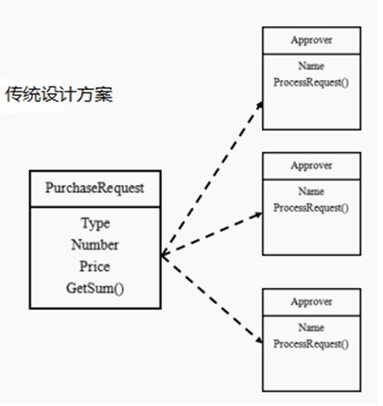
传统方案解决 OA 系统审批问题分析:
传统方式是:接收到一个采购请求后,根据采购金额来调用对应的 Approver (审批人)完成审批。
传统方式的问题分析 :
- 客户端这里会使用到分支判断(比如 switch) 来对不同的采购请求处理, 这样就存在如下问题:
- 如果各个级别的人员审批金额发生变化,在客户端的也需要变化
- 客户端必须明确的知道 有多少个审批级别和访问
- 这样 对一个采购请求进行处理 和 Approver (审批人) 就存在强耦合关系,不利于代码的扩展和维护
- 解决方案 =》 职责链模式
26.3.2、使用职责链模式解决需求
思路分析和图解(类图):
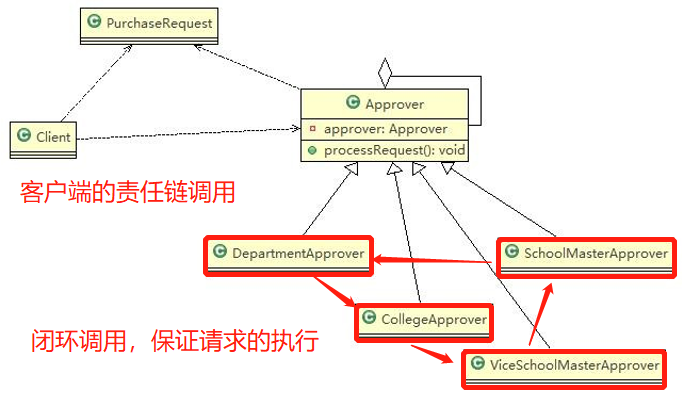
代码实现:
PurchaseRequest:采购请求。请求类(Request)
1 | //请求类 |
Approver:抽象处理者(Handler)
1 | public abstract class Approver { |
DepartmentApprover:教学主任处理类。(其中CollegeApprover:院长处理类(5000<x<=10000)、ViceSchoolMasterApprover:副校长处理类(10000<x<=30000)、SchoolMasterApprover:院长处理类(30000<x)类似)具体处理者(Concrete Handler)
1 | public class DepartmentApprover extends Approver { |
Client:客户类(Client)
1 | public class Client { |
26.4、职责链模式在SpringMVC框架的应用与源码
SpringMVC-HandlerExecutionChain 类就使用到职责链模式
SpringMVC 请求流程简图:
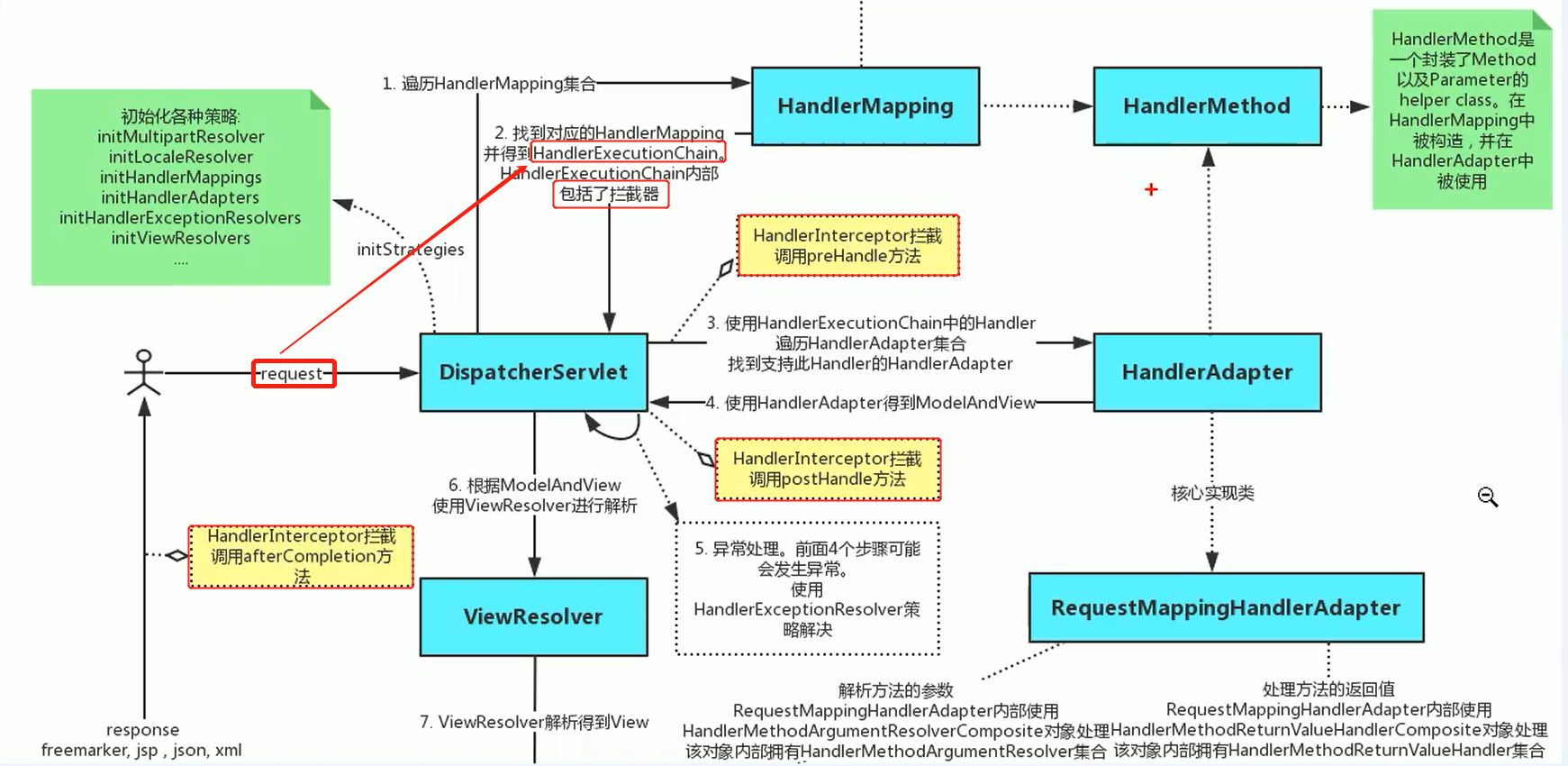
代码分析+Debug 源码:

main:
1 | import org.springframework.web.servlet.HandlerExecutionChain; |
SpringMVC中的最重要的DispatcherServlet类,当中有一个核心方法:doDispatcher方法
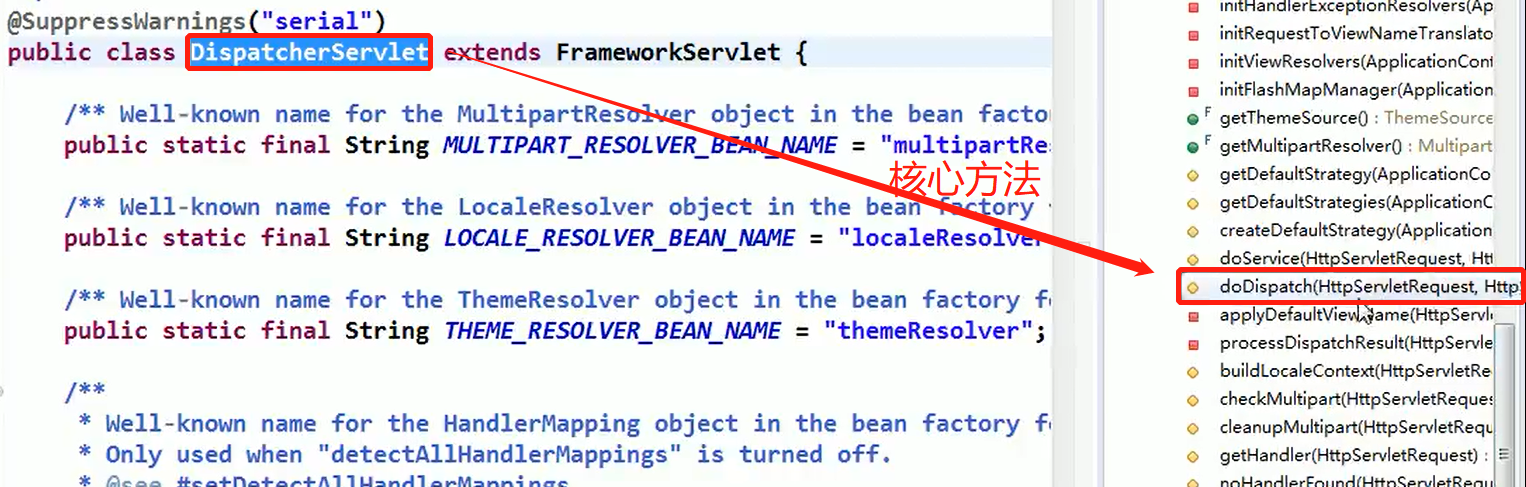
在doDispatcher方法中一开始就获取了HandlerExecutionChain对象
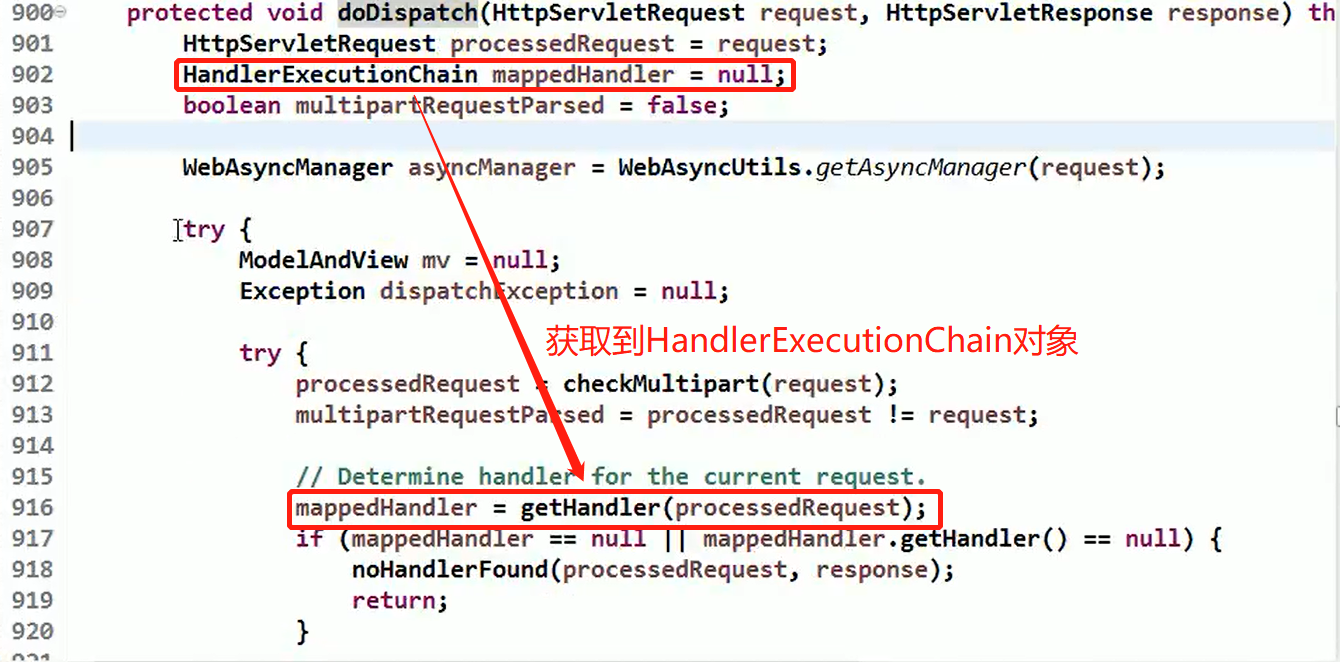
调用preHandle方法:
在得到HandlerExecutionChain对象后调用了其applyPreHandle()方法,在其内部得到了HandlerInterceptor interceptor拦截器并调用了拦截器的interceptor.preHandle方法。调用成功就返回。
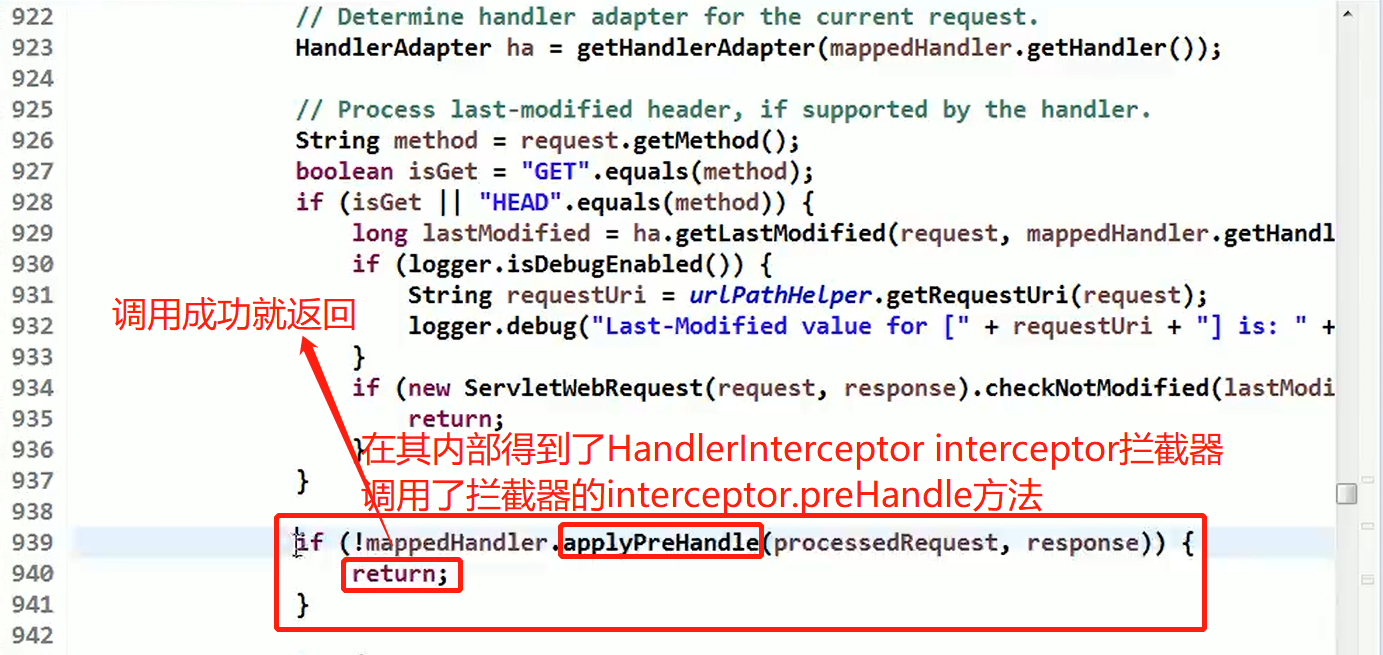
在applyPreHandle()中通过getInterceptors( ) [i] ;方法从拦截器数组当中获取对应的拦截器,并调用了拦截器的preHandle方法。
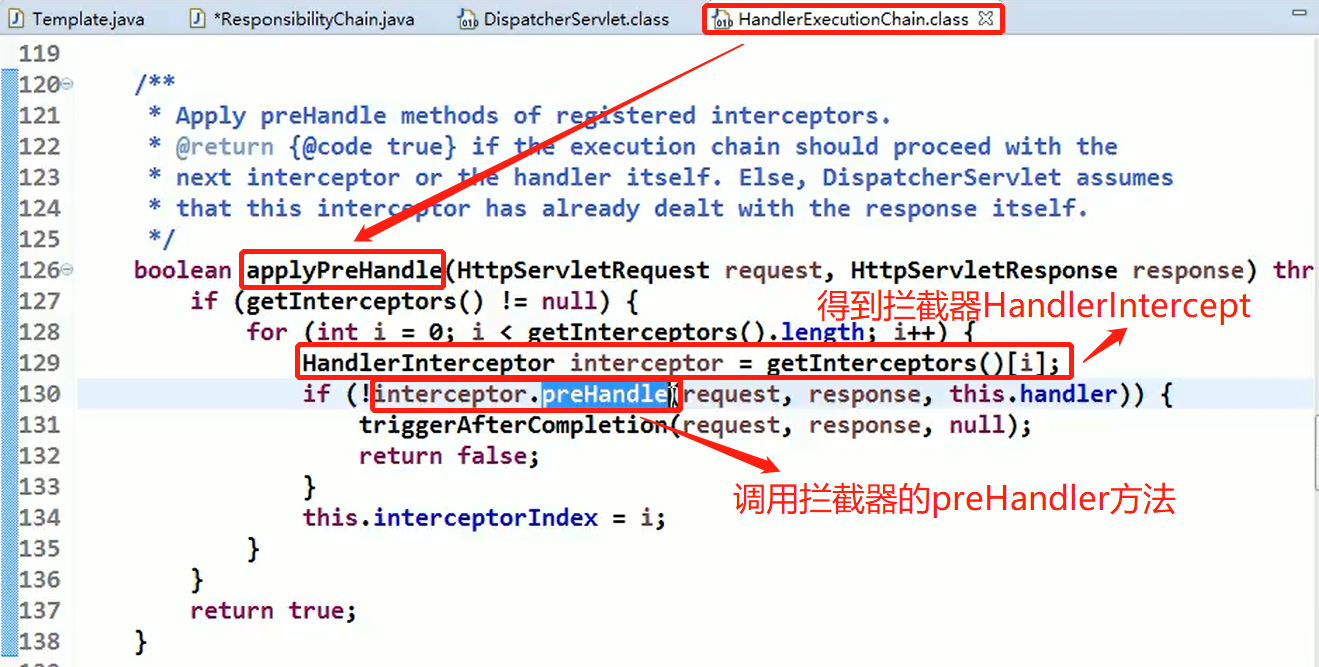
调用postHandle方法:
在doDispatcher方法的applyPreHandle()下面:HandlerExecutionChain对象还调用了其applyPostHandle()方法

在applyPostHandle()中通过getInterceptors() [i] ;方法从拦截器数组当中获取对应的拦截器,并调用了拦截器的postHandle方法。
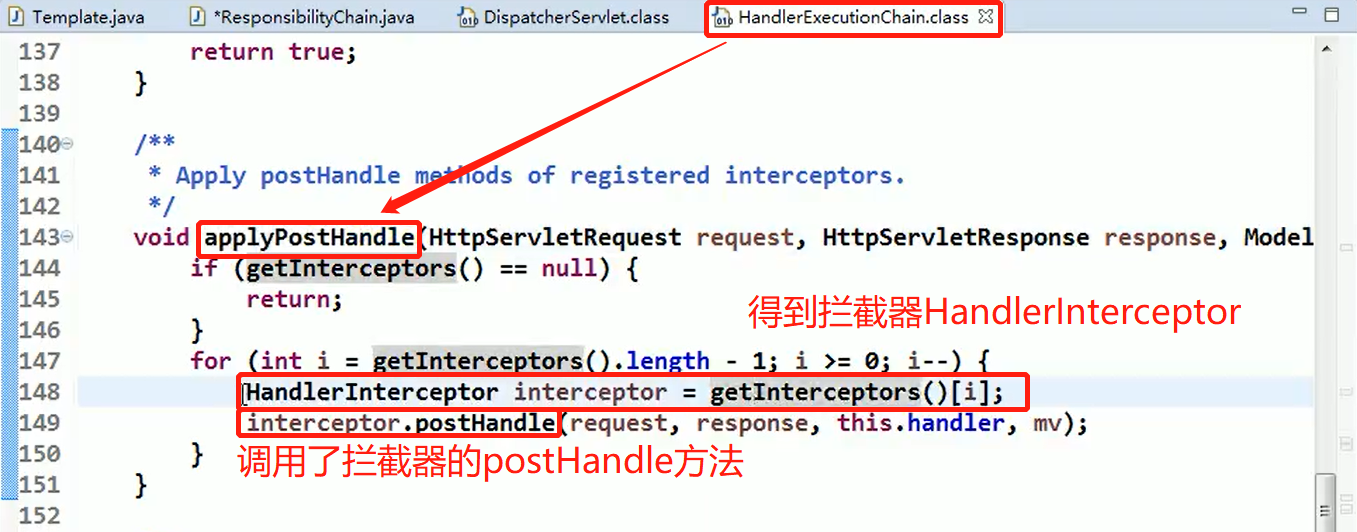
调用afterCompletion方法:
triggerAfterCompletion方法中得到了拦截器HandlerInterceptor并调用了拦截器的interceptor.afterCompletion方法
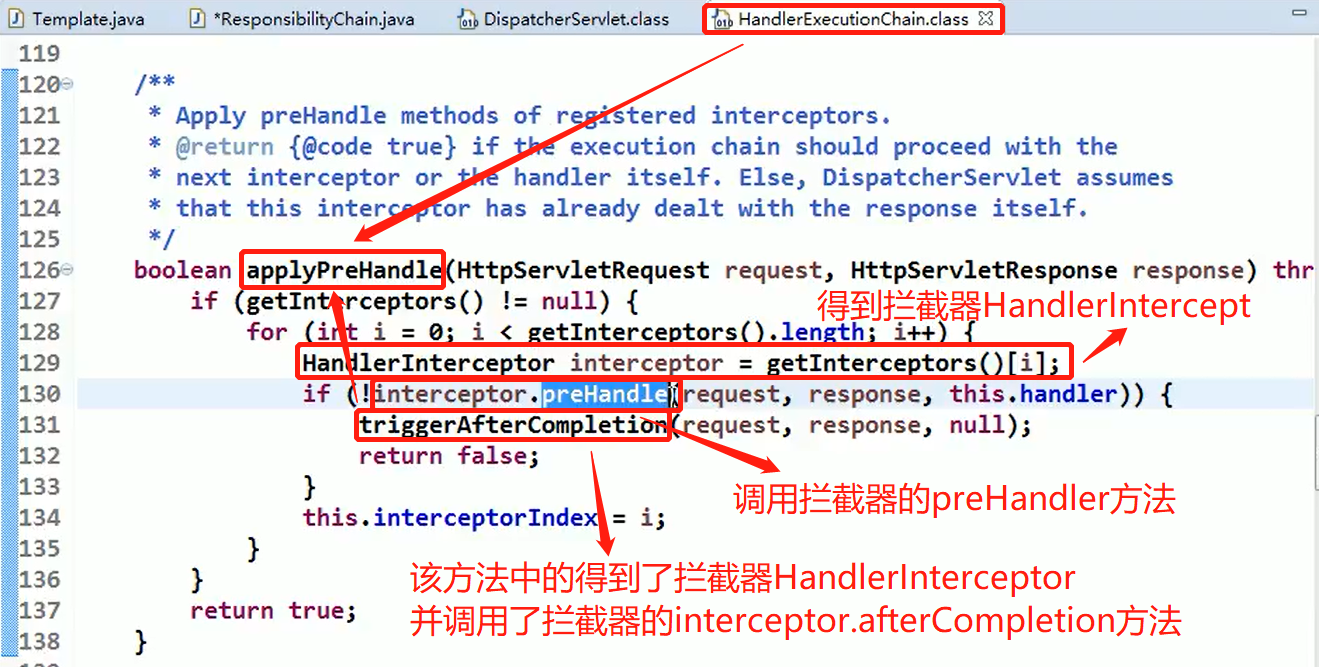

对源码总结
- springmvc 请求的流程图中,执行了 拦截器相关方法 interceptor.preHandler 等等
- 在处理 SpringMvc 请求时,使用到职责链模式还使用到适配器模式
- HandlerExecutionChain 主要负责的是请求拦截器的执行和请求处理,但是他本身不处理请求,只是将请求分配给链上注册处理器执行,这是职责链实现方式,减少职责链本身与处理逻辑之间的耦合,规范了处理流程
- HandlerExecutionChain 维护了 HandlerInterceptor 的集合, 可以向其中注册相应的拦截器.
26.5、职责链模式总结
主要优点如下:
- 降低了对象之间的耦合度。该模式使得一个对象无须知道到底是哪一个对象处理其请求以及链的结构,发送者和接收者也无须拥有对方的明确信息。
- 增强了系统的可扩展性。可以根据需要增加新的请求处理类,满足开闭原则。
- 增强了给对象指派职责的灵活性。当工作流程发生变化,可以动态地改变链内的成员或者调动它们的次序,也可动态地新增或者删除责任。
- 责任链简化了对象之间的连接。每个对象只需保持一个指向其后继者的引用,不需保持其他所有处理者的引用,这避免了使用众多的 if 或者 if···else 语句。
- 责任分担。每个类只需要处理自己该处理的工作,不该处理的传递给下一个对象完成,明确各类的责任范围,符合类的单一职责原则。
主要缺点如下:
- 不能保证每个请求一定被处理。由于一个请求没有明确的接收者,所以不能保证它一定会被处理,该请求可能一直传到链的末端都得不到处理。所以最好形成闭环调用,保证请求一定可以得到调用。
- 对比较长的职责链,请求的处理可能涉及多个处理对象,系统性能将受到一定影响。
- 职责链建立的合理性要靠客户端来保证,增加了客户端的复杂性,可能会由于职责链的错误设置而导致系统出错,如可能会造成循环调用。
- 可能不容易观察运行时的特征,有碍于除错。
模式的应用场景:
- 多个对象可以处理一个请求,但具体由哪个对象处理该请求在运行时自动确定。
- 可动态指定一组对象处理请求,或添加新的处理者。
- 需要在不明确指定请求处理者的情况下,向多个处理者中的一个提交请求。
应用实例:
- JS 中的事件冒泡。
- JAVA WEB 中 Apache Tomcat 对 Encoding 的处理
- Struts2 的拦截器
- jsp servlet 的 Filter
- 责任链模式经常用在拦截、预处理请求等。
26.6、职责链模式扩展
职责链模式存在以下两种情况:
- 纯的职责链模式:一个请求必须被某一个处理者对象所接收,且一个具体处理者对某个请求的处理只能采用以下两种行为之一:自己处理(承担责任);把责任推给下家处理。
- 不纯的职责链模式:允许出现某一个具体处理者对象在承担了请求的一部分责任后又将剩余的责任传给下家的情况,且一个请求可以最终不被任何接收端对象所接收。
26.7、进阶阅读
如果您想深入了解责任链模式,可猛击阅读以下文章。
26.8、相关设计模式
Composite模式
Handler角色经常会使用Composite模式。
Command模式
有时会使用Command模式向Handler角色发送请求。
26.9、职责链模式的注意事项与细节
- 将请求和处理分开,实现解耦,提高系统的灵活性
- 简化了对象,使对象不需要知道链的结构
- 性能会受到影响,特别是在链比较长的时候,因此需控制链中最大节点数量,一般通过在 Handler 中设置一个最大节点数量,在 setNext()方法中判断是否已经超过阀值,超过则不允许该链建立,避免出现超长链无意识地破坏系统性能
- 调试不方便。采用了类似递归的方式,调试时逻辑可能比较复杂
- 最佳应用场景:有多个对象可以处理同一个请求时,比如:多级请求、请假/加薪等审批流程、Java Web 中 Tomcat对 Encoding 的处理、拦截器
27、创建型模式的特点和分类
创建型模式的主要关注点是“怎样创建对象?”,它的主要特点是“将对象的创建与使用分离”。这样可以降低系统的耦合度,使用者不需要关注对象的创建细节,对象的创建由相关的工厂来完成。就像我们去商场购买商品时,不需要知道商品是怎么生产出来一样,因为它们由专门的厂商生产。
创建型模式分为以下几种:
- 单例(Singleton)模式:某个类只能生成一个实例,该类提供了一个全局访问点供外部获取该实例,其拓展是有限多例模式。
- 原型(Prototype)模式:将一个对象作为原型,通过对其进行复制而克隆出多个和原型类似的新实例。
- 工厂方法(FactoryMethod)模式:定义一个用于创建产品的接口,由子类决定生产什么产品。
- 抽象工厂(AbstractFactory)模式:提供一个创建产品族的接口,其每个子类可以生产一系列相关的产品。
- 建造者(Builder)模式:将一个复杂对象分解成多个相对简单的部分,然后根据不同需要分别创建它们,最后构建成该复杂对象。
以上 5 种创建型模式,除了工厂方法模式属于类创建型模式,其他的全部属于对象创建型模式
28、结构型模式概述(结构型模式的分类)
结构型模式描述如何将类或对象按某种布局组成更大的结构。它分为类结构型模式和对象结构型模式,前者采用继承机制来组织接口和类,后者釆用组合或聚合来组合对象。
由于组合关系或聚合关系比继承关系耦合度低,满足“合成复用原则”,所以对象结构型模式比类结构型模式具有更大的灵活性。
结构型模式分为以下 7 种:
- 代理(Proxy)模式:为某对象提供一种代理以控制对该对象的访问。即客户端通过代理间接地访问该对象,从而限制、增强或修改该对象的一些特性。
- 适配器(Adapter)模式:将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。
- 桥接(Bridge)模式:将抽象与实现分离,使它们可以独立变化。它是用组合关系代替继承关系来实现的,从而降低了抽象和实现这两个可变维度的耦合度。
- 装饰(Decorator)模式:动态地给对象增加一些职责,即增加其额外的功能。
- 外观(Facade)模式:为多个复杂的子系统提供一个一致的接口,使这些子系统更加容易被访问。
- 享元(Flyweight)模式:运用共享技术来有效地支持大量细粒度对象的复用。
- 组合(Composite)模式:将对象组合成树状层次结构,使用户对单个对象和组合对象具有一致的访问性。
以上 7 种结构型模式,除了适配器模式分为类结构型模式和对象结构型模式两种,其他的全部属于对象结构型模式。
29、行为型模式概述(行为型模式的分类)
行为型模式用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,它涉及算法与对象间职责的分配。
行为型模式分为类行为模式和对象行为模式,前者采用继承机制来在类间分派行为,后者采用组合或聚合在对象间分配行为。
由于组合关系或聚合关系比继承关系耦合度低,满足“合成复用原则”,所以对象行为模式比类行为模式具有更大的灵活性。
行为型模式是 GoF 设计模式中最为庞大的一类,它包含以下 11 种模式。
- 模板方法(Template Method)模式:定义一个操作中的算法骨架,将算法的一些步骤延迟到子类中,使得子类在可以不改变该算法结构的情况下重定义该算法的某些特定步骤。
- 策略(Strategy)模式:定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的改变不会影响使用算法的客户。
- 命令(Command)模式:将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。
- 职责链(Chain of Responsibility)模式:把请求从链中的一个对象传到下一个对象,直到请求被响应为止。通过这种方式去除对象之间的耦合。
- 状态(State)模式:允许一个对象在其内部状态发生改变时改变其行为能力。
- 观察者(Observer)模式:多个对象间存在一对多关系,当一个对象发生改变时,把这种改变通知给其他多个对象,从而影响其他对象的行为。
- 中介者(Mediator)模式:定义一个中介对象来简化原有对象之间的交互关系,降低系统中对象间的耦合度,使原有对象之间不必相互了解。
- 迭代器(Iterator)模式:提供一种方法来顺序访问聚合对象中的一系列数据,而不暴露聚合对象的内部表示。
- 访问者(Visitor)模式:在不改变集合元素的前提下,为一个集合中的每个元素提供多种访问方式,即每个元素有多个访问者对象访问。
- 备忘录(Memento)模式:在不破坏封装性的前提下,获取并保存一个对象的内部状态,以便以后恢复它。
- 解释器(Interpreter)模式:提供如何定义语言的文法,以及对语言句子的解释方法,即解释器。
以上 11 种行为型模式,除了模板方法模式和解释器模式是类行为型模式,其他的全部属于对象行为型模式。
30、一句话归纳设计模式
| 分类 | 设计模式 | 简述 | 一句话归纳 | 目的 | 生活案例 |
|---|---|---|---|---|---|
| 创建型设计模式 (简单来说就是用来创建对象的) | 工厂模式(Factory Pattern) | 不同条件下创建不同实例 | 产品标准化,生产更高效 | 封装创建细节 | 实体工厂 |
| 单例模式(Singleton Pattern) | 保证一个类仅有一个实例,并且提供一个全局访问点 | 世上只有一个我 | 保证独一无二 | CEO | |
| 原型模式(Prototype Pattern) | 通过拷贝原型创建新的对象 | 拔一根猴毛,吹出千万个 | 高效创建对象 | 克隆 | |
| 建造者模式(Builder Pattern) | 用来创建复杂的复合对象 | 高配中配和低配,想选哪配就哪配 | 开放个性配置步骤 | 选配 | |
| 结构型设计模式 (关注类和对象的组合) | 代理模式(Proxy Pattern) | 为其他对象提供一种代理以控制对这个对象的访问 | 没有资源没时间,得找别人来帮忙 | 增强职责 | 媒婆 |
| 外观模式(Facade Pattern) | 对外提供一个统一的接口用来访问子系统 | 打开一扇门,通向全世界 | 统一访问入口 | 前台 | |
| 装饰器模式(Decorator Pattern) | 为对象添加新功能 | 他大舅他二舅都是他舅 | 灵活扩展、同宗同源 | 煎饼 | |
| 享元模式(Flyweight Pattern) | 使用对象池来减少重复对象的创建 | 优化资源配置,减少重复浪费 | 共享资源池 | 全国社保联网 | |
| 组合模式(Composite Pattern) | 将整体与局部(树形结构)进行递归组合,让客户端能够以一种的方式对其进行处理 | 人在一起叫团伙,心在一起叫团队 | 统一整体和个体 | 组织架构树 | |
| 适配器模式(Adapter Pattern) | 将原来不兼容的两个类融合在一起 | 万能充电器 | 兼容转换 | 电源适配 | |
| 桥接模式(Bridge Pattern) | 将两个能够独立变化的部分分离开来 | 约定优于配置 | 不允许用继承 | 桥 | |
| 行为型设计模式 (关注对象之间的通信) | 模板模式(Template Pattern) | 定义一套流程模板,根据需要实现模板中的操作 | 流程全部标准化,需要微调请覆盖 | 逻辑复用 | 把大象装进冰箱 |
| 策略模式(Strategy Pattern) | 封装不同的算法,算法之间能互相替换 | 条条大道通罗马,具体哪条你来定 | 把选择权交给用户 | 选择支付方式 | |
| 责任链模式(Chain of Responsibility Pattern) | 拦截的类都实现统一接口,每个接收者都包含对下一个接收者的引用。将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止。 | 各人自扫门前雪,莫管他们瓦上霜 | 解耦处理逻辑 | 踢皮球 | |
| 迭代器模式(Iterator Pattern) | 提供一种方法顺序访问一个聚合对象中的各个元素 | 流水线上坐一天,每个包裹扫一遍 | 统一对集合的访问方式 | 逐个检票进站 | |
| 命令模式(Command Pattern) | 将请求封装成命令,并记录下来,能够撤销与重做 | 运筹帷幄之中,决胜千里之外 | 解耦请求和处理 | 遥控器 | |
| 状态模式(State Pattern) | 根据不同的状态做出不同的行为 | 状态驱动行为,行为决定状态 | 绑定状态和行为 | 订单状态跟踪 | |
| 备忘录模式(Memento Pattern) | 保存对象的状态,在需要时进行恢复 | 失足不成千古恨,想重来时就重来 | 备份、后悔机制 | 草稿箱 | |
| 中介者模式(Mediator Pattern) | 将对象之间的通信关联关系封装到一个中介类中单独处理,从而使其耦合松散 | 联系方式我给你,怎么搞定我不管 | 统一管理网状资源 | 朋友圈 | |
| 解释器模式(Interpreter Pattern) | 给定一个语言,定义它的语法表示,并定义一个解释器,这个解释器使用该标识来解释语言中的句子 | 我想说”方言“,一切解释权都归我 | 实现特定语法解析 | 摩斯密码 | |
| 观察者模式(Observer Pattern) | 状态发生改变时通知观察者,一对多的关系 | 到点就通知我 | 解耦观察者与被观察者 | 闹钟 | |
| 访问者模式(Visitor Pattern) | 稳定数据结构,定义新的操作行为 | 横看成岭侧成峰,远近高低各不同 | 解耦数据结构和数据操作 | KPI考核 | |
| 委派模式(Delegate Pattern) | 允许对象组合实现与继承相同的代码重用,负责任务的调用和分配 | 这个需求很简单,怎么实现我不管 | 只对结果负责 | 授权委托书 |
31、其他设计模式(不属于23种)
MVC 模式:Model-View-Controller(模型-视图-控制器) 模式。这种模式用于应用程序的分层开发。
Model(模型) - 模型代表一个存取数据的对象或 JAVA POJO。它也可以带有逻辑,在数据变化时更新控制器。
View(视图) - 视图代表模型包含的数据的可视化。
Controller(控制器) - 控制器作用于模型和视图上。它控制数据流向模型对象,并在数据变化时更新视图。它使视图与模型分离开。
业务代表模式(Business Delegate Pattern):用于对表示层和业务层解耦。它基本上是用来减少通信或对表示层代码中的业务层代码的远程查询功能。在业务层中我们有以下实体:
- 客户端(Client) - 表示层代码可以是 JSP、servlet 或 UI java 代码。
- 业务代表(Business Delegate) - 一个为客户端实体提供的入口类,它提供了对业务服务方法的访问。
- 查询服务(LookUp Service) - 查找服务对象负责获取相关的业务实现,并提供业务对象对业务代表对象的访问。
- 业务服务(Business Service) - 业务服务接口。实现了该业务服务的实体类,提供了实际的业务实现逻辑。
组合实体模式(Composite Entity Pattern):用在 EJB 持久化机制中。一个组合实体是一个 EJB 实体 bean,代表了对象的图解。当更新一个组合实体时,内部依赖对象 beans 会自动更新,因为它们是由 EJB 实体 bean 管理的。以下是组合实体 bean 的参与者:
- 组合实体(Composite Entity) - 它是主要的实体 bean。它可以是粗粒的,或者可以包含一个粗粒度对象,用于持续生命周期。
- 粗粒度对象(Coarse-Grained Object) - 该对象包含依赖对象。它有自己的生命周期,也能管理依赖对象的生命周期。
- 依赖对象(Dependent Object) - 依赖对象是一个持续生命周期依赖于粗粒度对象的对象。
- 策略(Strategies) - 策略表示如何实现组合实体。
数据访问对象模式(Data Access Object Pattern)或 DAO 模式:用于把低级的数据访问 API 或操作从高级的业务服务中分离出来。以下是数据访问对象模式的参与者:
- 数据访问对象接口(Data Access Object Interface) - 该接口定义了在一个模型对象上要执行的标准操作。
- 数据访问对象实体类(Data Access Object concrete class) - 该类实现了上述的接口。该类负责从数据源获取数据,数据源可以是数据库,也可以是 xml,或者是其他的存储机制。
- 模型对象/数值对象(Model Object/Value Object) - 该对象是简单的 POJO,包含了 get/set 方法来存储通过使用 DAO 类检索到的数据。
前端控制器模式(Front Controller Pattern):是用来提供一个集中的请求处理机制,所有的请求都将由一个单一的处理程序处理。该处理程序可以做认证/授权/记录日志,或者跟踪请求,然后把请求传给相应的处理程序。以下是这种设计模式的实体:
- 前端控制器(Front Controller) - 处理应用程序所有类型请求的单个处理程序,应用程序可以是基于 web 的应用程序,也可以是基于桌面的应用程序。
- 调度器(Dispatcher) - 前端控制器可能使用一个调度器对象来调度请求到相应的具体处理程序。
- 视图(View) - 视图是为请求而创建的对象。
拦截过滤器模式(Intercepting Filter Pattern):用于对应用程序的请求或响应做一些预处理/后处理。定义过滤器,并在把请求传给实际目标应用程序之前应用在请求上。过滤器可以做认证/授权/记录日志,或者跟踪请求,然后把请求传给相应的处理程序。以下是这种设计模式的实体:
- 过滤器(Filter) - 过滤器在请求处理程序执行请求之前或之后,执行某些任务。
- 过滤器链(Filter Chain) - 过滤器链带有多个过滤器,并在 Target 上按照定义的顺序执行这些过滤器。
- Target - Target 对象是请求处理程序。
- 过滤管理器(Filter Manager) - 过滤管理器管理过滤器和过滤器链。
- 客户端(Client) - Client 是向 Target 对象发送请求的对象。
服务定位器模式(Service Locator Pattern):用在我们想使用 JNDI 查询定位各种服务的时候。考虑到为某个服务查找 JNDI 的代价很高,服务定位器模式充分利用了缓存技术。在首次请求某个服务时,服务定位器在 JNDI 中查找服务,并缓存该服务对象。当再次请求相同的服务时,服务定位器会在它的缓存中查找,这样可以在很大程度上提高应用程序的性能。以下是这种设计模式的实体:
- 服务(Service) - 实际处理请求的服务。对这种服务的引用可以在 JNDI 服务器中查找到。
- Context / 初始的 Context - JNDI Context 带有对要查找的服务的引用。
- 服务定位器(Service Locator) - 服务定位器是通过 JNDI 查找和缓存服务来获取服务的单点接触。
- 缓存(Cache) - 缓存存储服务的引用,以便复用它们。
- 客户端(Client) - Client 是通过 ServiceLocator 调用服务的对象。
传输对象模式(Transfer Object Pattern):用于从客户端向服务器一次性传递带有多个属性的数据。传输对象也被称为数值对象。传输对象是一个具有 getter/setter 方法的简单的 POJO 类,它是可序列化的,所以它可以通过网络传输。它没有任何的行为。服务器端的业务类通常从数据库读取数据,然后填充 POJO,并把它发送到客户端或按值传递它。对于客户端,传输对象是只读的。客户端可以创建自己的传输对象,并把它传递给服务器,以便一次性更新数据库中的数值。以下是这种设计模式的实体:
- 业务对象(Business Object) - 为传输对象填充数据的业务服务。
- 传输对象(Transfer Object) - 简单的 POJO,只有设置/获取属性的方法。
- 客户端(Client) - 客户端可以发送请求或者发送传输对象到业务对象。
在空对象模式(Null Object Pattern)中,一个空对象取代 NULL 对象实例的检查。Null 对象不是检查空值,而是反应一个不做任何动作的关系。这样的 Null 对象也可以在数据不可用的时候提供默认的行为。
在空对象模式中,我们创建一个指定各种要执行的操作的抽象类和扩展该类的实体类,还创建一个未对该类做任何实现的空对象类,该空对象类将无缝地使用在需要检查空值的地方。
32、设计模式相关的网站
- Wiki Page for Design Patterns - 以一种非常通用的方式检查设计模式。
- Java Programming/Design Patterns - 一篇关于设计模式的好文章。
- The JavaTM Tutorials - 该 Java 教程是为那些想用 Java 编程语言创建应用程序的编程人员提供的实用指南。
- JavaTM 2 SDK, Standard Edition - JavaTM 2 SDK, Standard Edition 的官网。
0、延伸
1、各种生成实例的方法的介绍
在Java中可以使用下面这些方法生成实例。
1、new
一般我们使用Java关键字new生成实例。
可以像下面这样生成Something类的实例并将其保存在obj变量中。
1 | Something obj = new Something(); |
这时, 类名(此处的Something)会出现在代码中 。(即形成强耦合关系)
2、clone
我们也可以使用在Prototype模式中学习过的clone方法, 根据现有 的实例复制出一个新的实例。
我们可以像下面这样根据自身来复制出新的实例(不过不会调用构造函数)。
1 | class Something { |
3、new Instance
使用java.lang.Class类的newinstance方法可以通过Class类的实例生成出Class类所表示的类0的实例(会调用无参构造函数)。
下面我们再看一个例子。 假设我们现在已经有了Something类的实例someobj, 通过下面的表达式可以生成另外一个 Something类的实例。
1 | someobj.getClass().newinstance() |
实际上, 调用newinstance方法可能会导致抛出InstantiationException异常或是 illegalAccessException异常, 因此需要将其置千try…catch语句块中或是用throws关键字指定调用newinstance方法的方法可能会抛出的异常。
2、类名是束缚吗
话说回来, 在源程序中使用类名到底会有什么问题呢?在代码中出现要使用的类的名字不是理 所当然的吗?
这里, 让我们再回忆一下面向对象编程的目标之一,即“作为组件复用” 。
在代码中出现要使用的类的名字并非总是坏事。 不过 ,—旦在代码中出现要使用的类的名字, 就无法与该类分离开来, 也就无法实现复用。
当然 , 可以通过替换源代码或是改变类名来解决这个问题。 但是, 此处说的“作为组件复用”中不包含替换源代码。 以Java来说, 重要的是当手边只有class文件(.class)时, 该类能否被复用。 即使没有Java文件(.java)也能复用该类才是关键。
当多个类必须紧密结合时, 代码中出现这些类的名字是没有问题的。但是如果那些需要被独立 出来作为组件复用的类的名字出现在代码中, 那就有问题了。
3、类的层次与抽象类
父类对子类的要求:
我们在理解类的层次时 , 通常是站在子类的角度进行思考的。也就是说 , 很容易着眼千以 下几点:
- 在子类中可以使用父类中定义的方法
- 可以通过在子类中增加方法以实现新的功能
- 在子类中重写父类的方法可以改变程序的行为
现在 , 让我们稍微改变一下立场 , 站在父类的角度进行思考。在父类中, 我们声明了抽象方法、而将该方法的实现交给了子类。换言之 , 就程序而言,声明抽象方法是希望达到以下目的:
- 期待子类去实现抽象方法
- 要求子类去实现抽象方法
也就是说 ,子类具有实现在父类中所声明的抽象方法的责任。因此,这种责任被称为 “子类责任”(subclass responsibility)。
参考链接:
有关于Copy-on-write代理:
相关书籍:
《图解设计模式》