[TOC]
面试
JAVA SE
1、自增变量
面试
面试代码:
1 | public static void main(String[] args) { |
运行结果:
1 | 4 |
解析
代码相关字节码
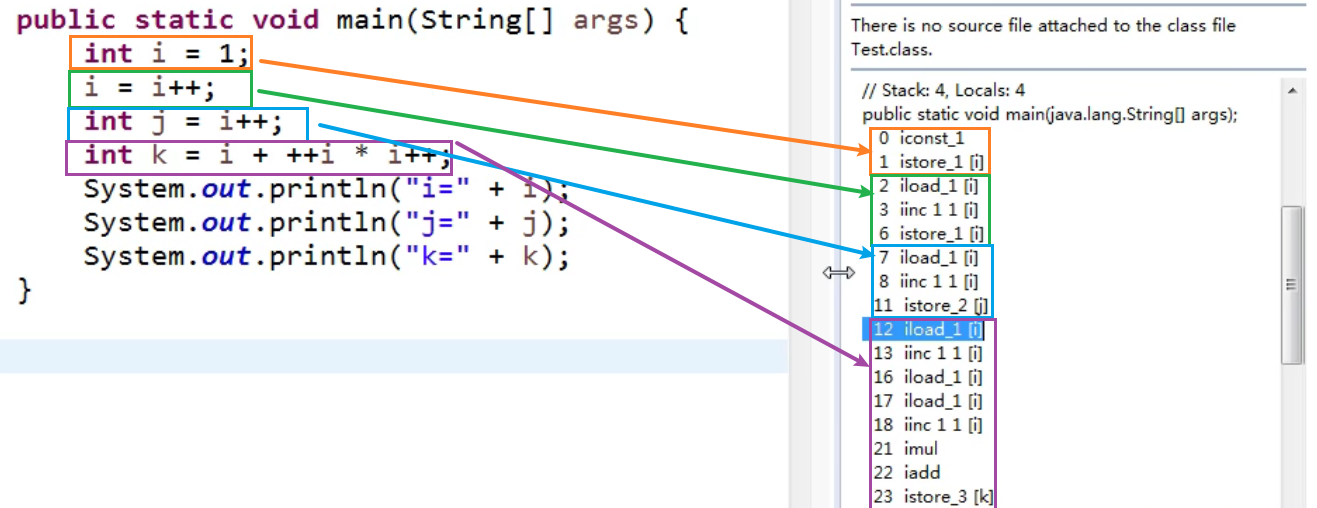
对应的操作数栈与局部变量表执行顺序

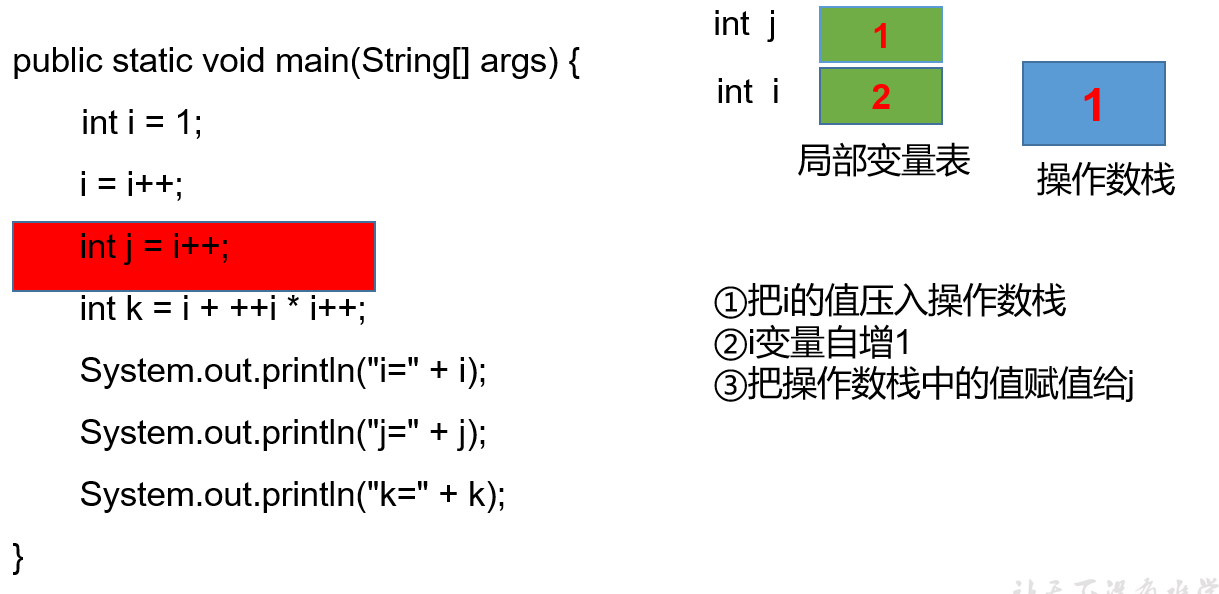

小结
- 赋值=,最后计算
- =右边的从左到右加载值依次压入操作数栈
- 实际先算哪个,看运算符优先级
- 自增、自减操作都是直接修改局部变量表当中变量的值,不经过操作数栈
- 最后的赋值之前,临时结果也是存储在操作数栈中
2、单例模式——Singleton
面试
编程题:写一个Singleton示例
解析
1、什么是Singleton?
- Singleton:在Java中即指单例设计模式,它是软件开发中最常用的设计模式之一。
- 单:唯一
- 例:实例
- 单例设计模式,即某个类在整个系统中只能有一个实例对象可被获取和使用的代码模式。
- 例如:代表JVM运行环境的Runtime类
2、要点
- 一是某个类只能有一个实例;
- 构造器私有化
- 二是它必须自行创建这个实例;
- 含有一个该类的静态变量来保存这个唯一的实例
- 三是它必须自行向整个系统提供这个实例;
- 对外提供获取该实例对象的方式:
- 直接暴露
- 用静态变量的get方法获取
- 对外提供获取该实例对象的方式:
3、几种常见形式
- 饿汉式:直接创建对象,不存在线程安全问题
- 直接实例化饿汉式(简洁直观)
- 枚举式(最简洁、最安全)
- 静态代码块饿汉式(适合复杂实例化)
- 懒汉式:延迟创建对象
- 线程不安全(适用于单线程)
- 线程安全(加锁,适用于多线程)
- 双重检查(适用于多线程,效率比加锁高)
- 静态内部类形式(适用于多线程)
4、实现
1、饿汉式——直接实例化饿汉式(简洁直观)
1 | /* |
2、饿汉式——枚举式(最简洁、最安全)
1 | /* |
3、饿汉式——静态代码块饿汉式(适合复杂实例化)(可以使用配置文件来解耦合)
1 | public class Singleton { |
对应的配置文件single.properties:
1 | info=xxx |
注:该配置文件要放在src目录下面,否则Properties加载不到
4、懒汉式——线程不安全(适用于单线程)
1 | /* |
5、懒汉式——线程安全(加锁,适用于多线程)
1 | public class Singleton { |
6、懒汉式——双重检查(适用于多线程,效率比加锁高)
1 | public class Singleton { |
7、懒汉式——静态内部类形式(适用于多线程)
1 | /* |
小结
- 如果是饿汉式,枚举形式最简单
- 如果是懒汉式,静态内部类形式最简单
3、类初始化与实例初始化
面试
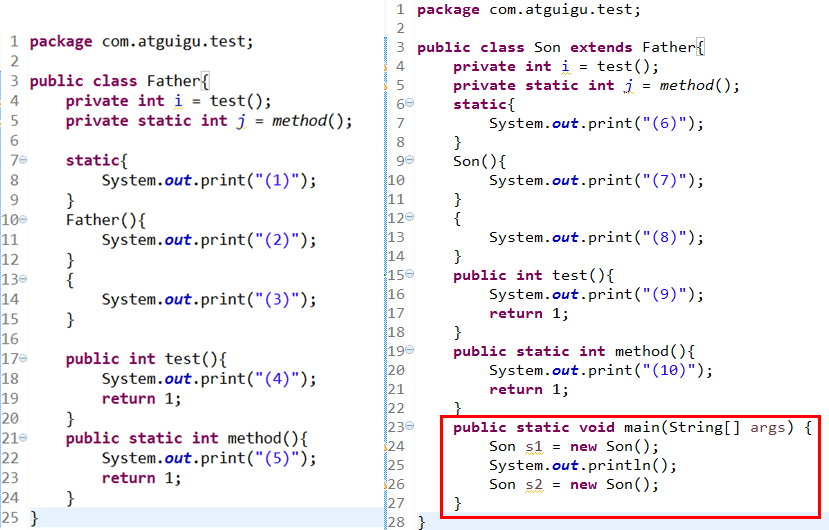
运行结果:
1 | (5)(1)(10)(6)(9)(3)(2)(9)(8)(7) |
解析
1、类初始化过程
- 一个类要创建实例需要先加载并初始化该类
- main方法所在的类需要先加载和初始化
- 一个子类要初始化需要先初始化父类
- 一个类初始化就是执行
()方法 ()方法由静态类变量显示赋值代码和静态代码块组成 - 类变量显示赋值代码和静态代码块代码从上到下顺序执行
()方法只执行一次
2、实例初始化过程
实例初始化就是执行
()方法可能重载有多个,有几个构造器就有几个 方法 ()方法由非静态实例变量显示赋值代码和非静态代码块、对应构造器代码组成 - 非静态实例变量显示赋值代码和非静态代码块代码从上到下顺序执行,而对应构造器的代码最后执行
- 每次创建实例对象,调用对应构造器,执行的就是对应的
方法 方法的首行是super()或super(实参列表),即对应父类的 方法
3、方法的重写
- 哪些方法不可以被重写
- final方法
- 静态方法
- private等子类中不可见方法
- 对象的多态性
- 子类如果重写了父类的方法,通过子类对象调用的一定是子类重写过的代码
- 非静态方法默认的调用对象是this
- this对象在构造器或者说**
方法中就是正在创建的对象**
- 方法的重写与重载的区别
- 方法重写(Override):
- 是子类对父类的允许访问的方法的实现过程进行重新编写,返回值和形参都不能改变。即外壳不变,核心重写!
- 好处在于子类可以根据需要,定义特定于自己的行为。 也就是说子类能够根据需要实现父类的方法。
- 方法的重写规则:
- 参数列表与被重写方法的参数列表必须完全相同。
- 返回类型与被重写方法的返回类型可以不相同,但是必须是父类返回值的派生类(java5 及更早版本返回类型要一样,java7 及更高版本可以不同)。
- 访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为 public,那么在子类中重写该方法就不能声明为 protected。
- 父类的成员方法只能被它的子类重写。
- 声明为 final 的方法不能被重写。
- 声明为 static 的方法不能被重写,但是能够被再次声明。
- 子类和父类在同一个包中,那么子类可以重写父类所有方法,除了声明为 private 和 final 的方法。
- 子类和父类不在同一个包中,那么子类只能够重写父类的声明为 public 和 protected 的非 final 方法。
- 重写的方法能够抛出任何非强制异常,无论被重写的方法是否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以。
- 构造方法不能被重写。
- 如果不能继承一个类,则不能重写该类的方法。
- 方法重载(Overload):
- 重载(overloading) 是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。
- 每个重载的方法(或者构造函数)都必须有一个独一无二的参数类型列表。
- 最常用的地方就是构造器的重载。
- 方法重载规则:
- 被重载的方法必须改变参数列表(参数个数或类型不一样);
- 被重载的方法可以改变返回类型;
- 被重载的方法可以改变访问修饰符;
- 被重载的方法可以声明新的或更广的检查异常;
- 方法能够在同一个类中或者在一个子类中被重载。
- 无法以返回值类型作为重载函数的区分标准。
- 方法重写(Override):
4、方法参数传递机制
面试
1 | import java.util.Arrays; |
运行结果
1 | i = 1 |
解析
以上代码的方法参数传递机制
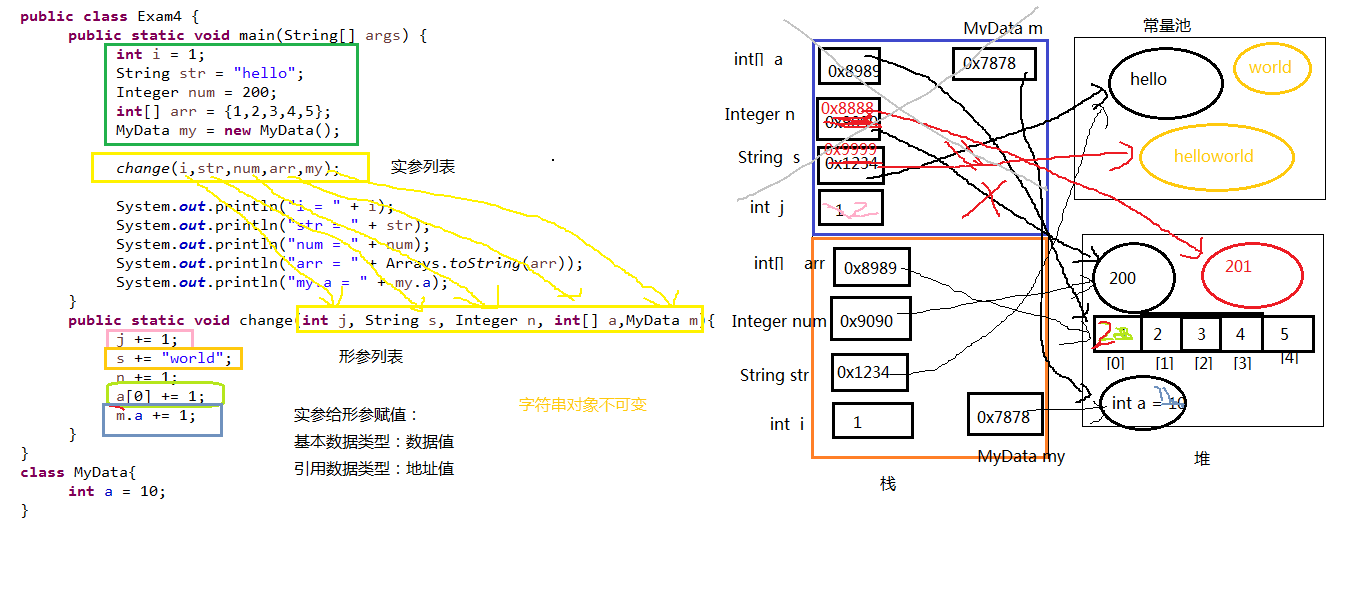
小结
方法的参数传递机制:
- 形参是基本数据类型
- 传递数据值
- 实参是引用数据类型
- 传递地址值
- 特殊的类型:String、包装类等对象不可变性
5、递归与迭代
面试
编程题:有n步台阶,一次只能上1步或2步,共有多少种走法?
- 递归
- 迭代
解析
1、递归

1 | import org.junit.Test; |
2、循环迭代

1 | import org.junit.Test; |
小结
- 方法调用自身称为递归,利用变量的原值推出新值称为迭代。
- 递归
- 优点:大问题转化为小问题,可以减少代码量,同时代码精简,可读性好;
- 缺点:递归调用浪费了空间,而且递归太深容易造成堆栈的溢出。
- 迭代
- 优点:代码运行效率好,因为时间只因循环次数增加而增加,而且没有额外的空间开销;
- 缺点:代码不如递归简洁,可读性好
6、成员变量与局部变量
面试
1 | public class Exam5 { |
运行结果
1 | 2,1,5 |
解析
- 就近原则
- 如果变量同名而且前面没有加this的话,采用的就是就近原则
- 变量的分类
- 成员变量:类变量、实例变量
- 局部变量
- 非静态代码块的执行:每次创建实例对象都会执行
- 方法的调用规则:调用一次执行一次
小结
局部变量与成员变量的区别:
- 声明的位置
- 局部变量:方法体{}中,形参,代码块{}中
- 成员变量:类中方法外
- 类变量:有static修饰
- 实例变量:没有static修饰
- 修饰符
- 局部变量:final
- 成员变量:public、protected、private、final、static、volatile、transient
- 值存储的位置
- 局部变量:栈
- 实例变量:堆
- 类变量:方法区
- 作用域
- 局部变量:从声明处开始,到所属的
}结束 - 实例变量:在当前类中“this.”(有时this.可以缺省),在其他类中“对象名.”访问
- 类变量:在当前类中“类名.”(有时类名.可以省略),在其他类中“类名.”或“对象名.”访问
- 局部变量:从声明处开始,到所属的
- 生命周期
- 局部变量:每一个线程,每一次调用执行都是新的生命周期
- 实例变量:随着对象的创建而初始化,随着对象的被回收而消亡,每一个对象的实例变量是独立的
- 类变量:随着类的初始化而初始化,随着类的卸载而消亡,该类的所有对象的类变量是共享的
当局部变量与xx变量重名时,如何区分:
- 局部变量与实例变量重名
- 在实例变量前面加“this.”
- 局部变量与类变量重名
- 在类变量前面加“类名.”
7、字符串常量java内部加载
面试——《深入理解Java虚拟机第三版》2.4.3
1 | public static void main(String[] args) { |
运行结果:
1 | 58tongcheng |
解析
按照代码结果,java字符串答案为false 必然是两个不同的java,那另外一个java字符串如何加载进来的?
因为有一个初始化的java字符串**(JDK加载时自带的), 在加载
sun.misc.Version这个类的时候进入常量池**。


1、OpenJDK8底层源码说明问题
1、System源码解析
System→ initializeSystemClass→Version:




2、类加载器和rt.jar
根加载器提前部署加载rt.jar

2、关于String 的 intern方法
1 | public native String intern(); |
Returns a canonical representation for the string object.
A pool of strings, initially empty, is maintained privately by the class String.
When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the equals(Object) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String object is returned.
It follows that for any two strings s and t, s.intern() == t.intern() is true if and only if s.equals(t) is true.
All literal strings and string-valued constant expressions are interned. String literals are defined in section 3.10.5 of the The Java™ Language Specification.
Returns:
a string that has the same contents as this string, but is guaranteed to be from a pool of unique strings.
String::intern()是一个本地方法,它的作用是如果字符串常量池中已经包含一个等于此String对象的字符串,则返回代表池中这个字符串的String对象的引用;否则,会将此String对象包含的字符串添加到字符串常量池中,并且返回次String对象的引用。
方法区和运行时常量池的溢出:
由于运行时常量池是方法区的一部分,所以这两个区域的溢出测试可以放在一起进行。在JDK6或者更早之前的HotSpot虚拟机中,常量池都是分配在永久代中,我们可以通过-XX:PermSize和-XX:MaxPermSize限制永久代的大小,即可间接限制其中常量池的容量。而在HotSpot虚拟机在JDK8中完全使用元空间来代替永久代,原本存放在永久代的字符串常量池被移至java堆当中,所以通过限制方法区容量已经没有了意义。如果我们在JDK7以及以上版本,通过限制java堆空间的大小,如:-Xmx。就能看到OOM:Java heap space。
小结
如果在JDK6当中,面试的代码返回的是两个false,因为在JD6当中,intern()方法会把首次遇到的字符串实例复制到永久代的字符串常量池当中存储,返回的也是永久代里面这个字符串实例的引用,与StringBuilder创建的字符串在java堆空间当中,所以必然不可能是同一个引用,结果返回false。
而在JDK7当中,intern()方法实现就不需要拷贝字符串实例到永久代了,因为字符串常量池已经从方法区移动到java堆空间当中,因此intern()方法只需要在字符串常量池里记录一下首次出现的字符串实例即可,因此intern()返回的引用和StringBuilder创建的字符串实例的引用就是同一个,结果返回true。
由于字符串”java”在类加载的时候就已经加载进字符串常量池当中了(不是首次创建),所以之后在java堆空间创建的字符串”java”的引用与在java堆空间的字符串常量池的字符串”java”的引用不是同一个,因此返回false。
注:不只是字符串”java”,在JDK7以及之后的版本中,其他字符串如果有在java初始化类加载的时候进行过加载的话,也是已经加载进java堆的字符串常量池当中了,返回也是false。如zip等等。
JAVA EE
1、Spring Bean 的作用域之间有什么区别
解析:
在Spring中,可以在
默认情况下,Spring只为每个在IOC容器里声明的bean创建唯一一个实例,整个IOC容器范围内都能共享该实例:所有后续的getBean()调用和bean引用都将返回这个唯一的bean实例。该作用域被称为singleton,它是所有bean的默认作用域。
Spring Bean一共有四个作用域,可以通过scope属性来指定bean的作用域:
| 类别 | 说明 |
|---|---|
| singleton | 默认值。当IOC容器一创建就会创建bean的实例(饿汉式),而且是单例的,在SpringIOC容器中仅存在一个Bean实例 |
| prototype | 原型的。当IOC容器一创建不再实例化该bean(懒汉式),每次调用getBean方法时在实例化该bean,而且每调用一次getBean方法就创建一个新的实例对象 |
| request | 每次HTTP请求实例化一个新的bean,该作用域仅适用于WebApplicationContext环境 |
| session | 在同一个HTTP Session会话中共享一个bean,不同的HTTP Session使用不同的Bean。该作用域仅适用于WebApplicationContext环境 |
2、Spring支持的常用数据库事务传播属性和事务隔离级别
解析:
1、什么是事务的传播?
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。
2、事务的传播行为种类
事务的传播行为可以由传播属性指定。Spring定义了7种类传播行为
| 传播属性 | 描述 |
|---|---|
| REQUIRED | 如果有事务在运行,当前的方法就在这个事务内运行,否则,就启动一个新的事务,并在自己的事务内运行 |
| REQUIRES_NEW | 当前的方法必须启动新事务,并在它自己的事务内运行。如果有事务正在运行,应该将它挂起 |
| SUPPORTS | 如果有事务在运行,当前的方法就在这个事务内运行。否则它可以不运行在事务中 |
| NOT_SUPPORTED | 当前的方法不应该运行在事务中,如果有运行的事务,将它挂起 |
| MANDATORY | 当前的方法必须运行在事务内部,如果没有运行的事务,就抛出异常 |
| NEVER | 当前的方法不应该运行在事务内部,如果有运行的事务,就抛出异常 |
| NESTED | 如果有事务在运行,当前的方法就应该在这个事务的嵌套事务内运行,否则,就启动一个新的事务,并在它自己的事务内运行 |
事务传播属性可以在 @Transactional 注解的 propagation 属性中定义。
现在重点来讲一下 REQUIRED 与 REQUIRES_NEW
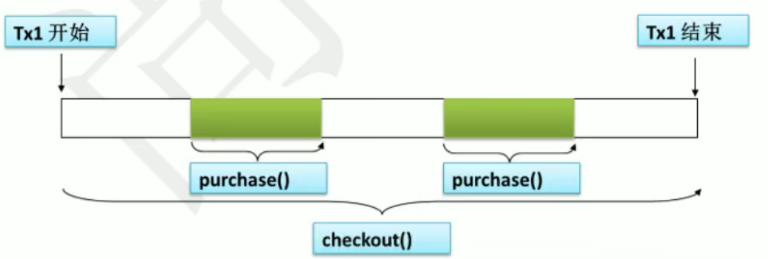
3、例子
现有100现金,去购买价值60元、库存100件的《Spring》与价值50元、库存100件的《SpringMVC》
有两种结果:
- 两本书都买不成,现金依旧有100元,两本书的库存依旧是100件
- 买成了第一本书《Spring》,买不了第二本书《SpringMVC》,现金为40元,《Spring》的库存只剩下99件,而《SpringMVC》的库存依旧有100件
导致以上两种结果的原因是事务的传播行为的不同。
1、REQUIRED
Propagation.REQUIRED:默认值,如果有事务在运行,当前的方法就在这个事务内运行,否则,就启动一个新的事务,并在自己的事务内运行。
结果:两本书都买不成,现金依旧有100元,两本书的库存依旧是100件
解析:
REQUIRED 传播行为:当bookService 的 purchase()方法被另外一个事务方法checkout()调用时,它默认会在现有的事务内运行。这个默认的传播行为就是REQUIRED 。因此在checkout()方法的开始和终止边界类内只有一个事务。这个事务只在checkout()方法结束的时候被提交,结果用户一本书都买不了
2、REQUIRES_NEW
Propagation.REQUIRES_NEW:表示该方法必须启动一个新事务,并在自己的事务内运行。如果有事务在运行,就应该先挂起它。
结果:买成了第一本书《Spring》,买不了第二本书《SpringMVC》,现金为40元,《Spring》的库存只剩下99件,而《SpringMVC》的库存依旧有100件
解析:
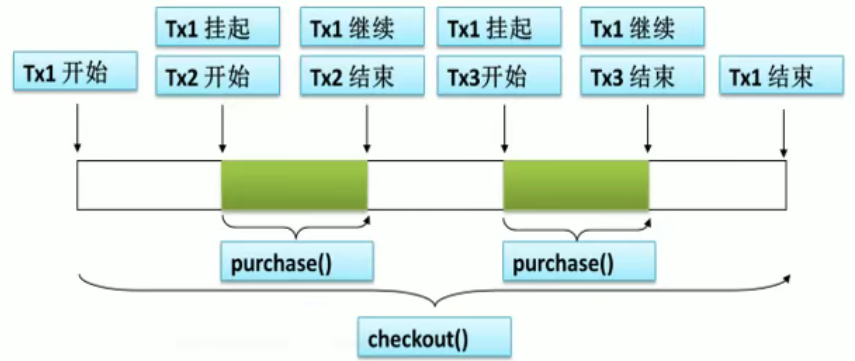
4、数据库的事务并发问题
假设现在有两个事务:Transactional01 和 Transactional02 并发执行。
- 脏读
- Transaction01将某条记录的AGE值从20修改为30。
- Transaction02读取了Transaction01更新后的值:30。
- Transaction01回滚,AGE值恢复到了20。
- Transaction02读取到的30就是一个无效的值。
- 不可重复读
- Transaction01读取了AGE值为20。
- Transaction02将AGE值修改为30。
- Transaction01再次读取AGE值为30,和第一次读取不一致。
- 幻读
- Transaction01读取了STUDENT表中的一部分数据。
- Transaction02向STUDENT表中插入了新的行。
- Transaction01读取了STUDENT表时,多出了一些行。
5、隔离级别
数据库系统必须具有隔离并发运行各个事务的能力,使它们不会相互影响,避免各种并发问题。一个事务与其他事务隔离的程度称为隔离级别。SQL标准中规定了多种事务隔离级别,不同隔离级别对应不同的干扰程度,隔离级别越高,数据一致性就越好,但并发性越弱。
- 读未提交:READ UNCOMMITTED
- 允许TranSaction01读取Transaction02未提交的修改。
- 读已提交:READ COMMITTED
- 要求Transaction01只能读取Transaction02已提交的修改。
- 可重复读:REPEATABLE READ
- 确保Transaction01可以多次从一个字段中读取到相同的值,即Transaction01执行期间禁止其它事务对这个字段进行更新。
- 串行化:SERIALIZABLE
- 确保Transaction01可以多次从一个表中读取到相同的行,在Transaction01执行期间,禁止其它事务对这个表进行添加、更新、删除操作。可以避免任何并发问题,但性能十分低下。
隔离级别属性可以在 @Transactional 注解的 isolation 属性中定义。如:
- Isolation.READ_UNCOMMITTED
- Isolation.READ_COMMITTED
6、各个隔离级别解决并发问题的能力
| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| READ UNCOMMITTED | 有 | 有 | 有 |
| READ COMMITTED | 无 | 有 | 有 |
| REPEATABLE READ | 无 | 无 | 有 |
| SERIALIZABLE | 无 | 无 | 无 |
表格当中的“有”“无”代表的是当前的左边隔离级别有没有上面的并发问题
7、各种数据库产品对事务隔离级别的支持程度
| Oracle | MySql | |
|---|---|---|
| READ UNCOMMITTED | × | √ |
| READ COMMITTED | √(默认) | √ |
| REPEATABLE READ | × | √(默认) |
| SERIALIZABLE | √ | √ |
3、SpringMVC如何解决POST请求中文乱码问题
解析:
需要配置一个字符编码过滤器CharacterEncodingFilter来解决POST请求中文乱码问题
字符编码过滤器CharacterEncodingFilter源码:
1 | public class CharacterEncodingFilter extends OncePerRequestFilter { |
解决问题:
在web.xml中配置CharacterEncodingFilter过滤器
1
2
3
4
5
6
7
8
9
10
11
12
13<!--解决POST请求的请求乱码问题-->
<filter>
<filter-name>CharacterEncodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
<init-param>
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>
</filter>注:该过滤器要配置在web.xml的最上面
在CharacterEncodingFilter过滤器的下面在配置一些过滤器的相关映射
1
2
3
4
5<filter-mapping>
<!-- 注意这里的名字需要和上面配置的filter-name一致-->
<filter-name>CharacterEncodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
注意:
- 以上方法只能解决的是POST请求的中文乱码问题
- 如果把请求修改为GET,依旧会出现中文乱码问题
那么,怎么解决GET请求的中文乱码问题?
最简单的一种方式:修改tomcat服务器的server.xml文件
先找到tomcat服务器的server.xml文件
找到第一个Connector标签
在后面添加
URIEncoding="UTF-8"
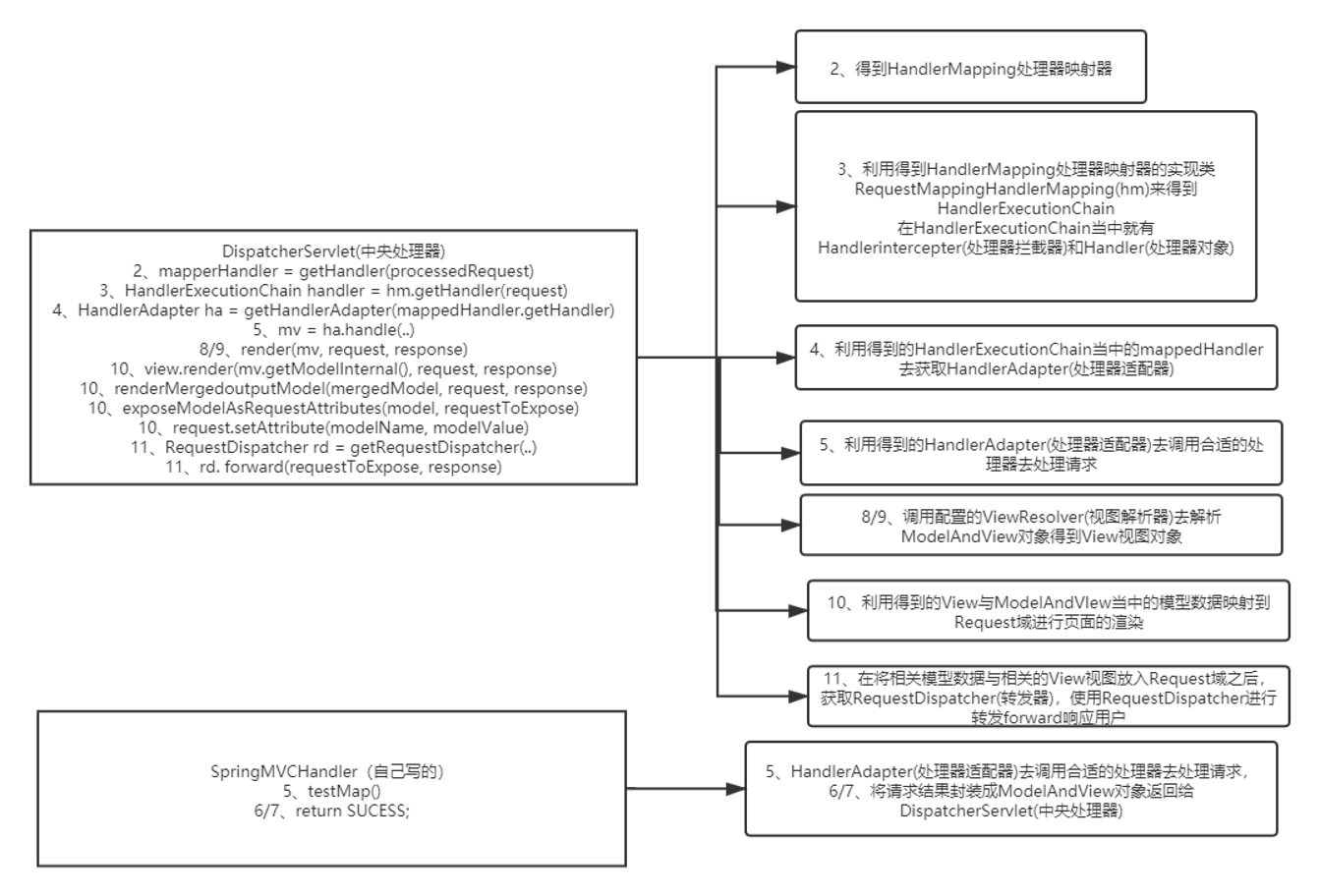
4、简单谈一下SpringMVC的工作流程
解析:
SpringMVC的工作流程图:
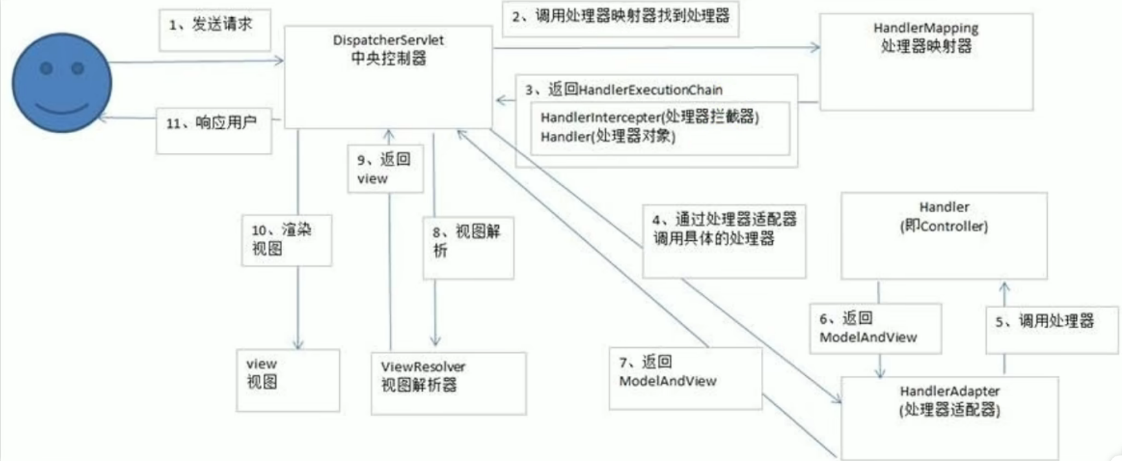
代码执行流程:
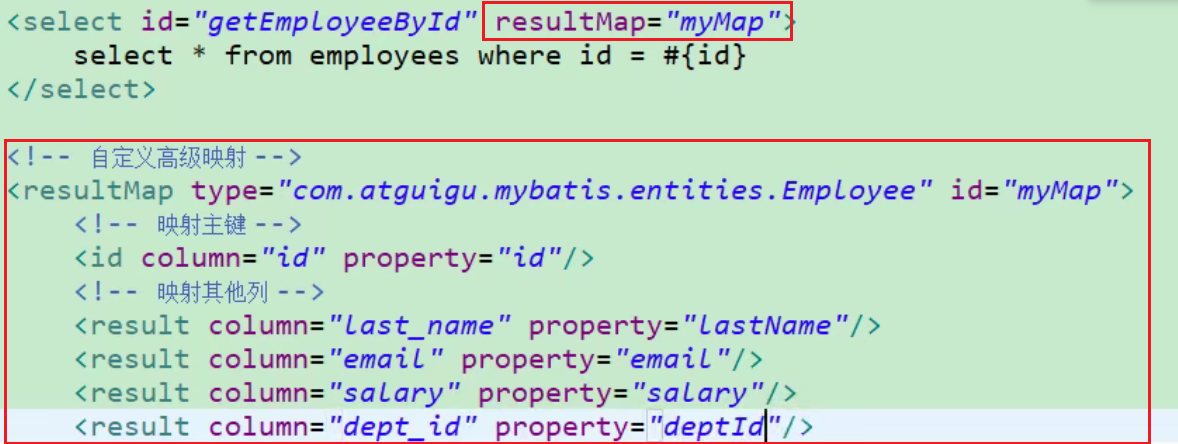
5、MyBatis中当实体类中的属性名和表中的字段名不一样的解决方法
解析:
在对应的mapper文件写sql语句时起别名

在Mybatis的全局配置文件mybatis-config.xml中开启驼峰命名规则
1
2
3
4
5
6<settings>
<!-- 开启驼峰命名规则,可以将数据库中的下划线映射为驼峰命名
例如: last_name 可以映射为lastName
-->
<setting name= "mapUnderscoreToCameLCase" value="true"/>
</settings>在Mapper映射文件中使用resultMap来自定义映射规则
Spring:主要考察IOC + AOP +TX(事务相关)
1、Aop的常用注解

2、有关于Spring aop的面试题
1、Srping aop全部通知顺序问题
你肯定知道spring,那说说aop的全部通知顺序?springboot或springboot2对aop的执行顺序影响?
- SpringBoot1底层使用的是Spring4
- SpringBoot2底层使用的是Spring5
其实问的就是Spring4与Spring5的aop的全部通知顺序的区别?
1、Spring4的aop的全部通知顺序
版本:Spring4.3.13 +springboot1.5.9
spring4默认用的是JDK的动态代理
正常执行:@Before (前置通知)@After(后置通知)@AfterReturning (正常返回)
异常执行:@Before (前置通知)@After(后置通知)@AfterThrowing (方法异常)
Spring4.3.13 +springboot1.5.9:正常aop顺序:

Spring4.3.13 +springboot1.5.9:异常aop顺序:

总结:

2、Spring5的aop的全部通知顺序
版本:Spring5.2.8 +springboot2.3.3
spring5默认动态代理用的是cglib,不再是JDK的动态代理, 因为JDK必须要实现接口,但有些类它并没有实现接口,所以更加通用的话就是cglib
正常执行:@Before(前置通知)@AfterReturning(正常返回)@After(后置通知))
异常执行:@Before(前置通知)@AfterThrowing(方法异常)@After(后置通知))
Spring5+springboot2.3.3:aop正常顺序:

Spring5+springboot2.3.3:aop异常顺序:

总结:

3、Srping aop全部通知顺序总结

2、Spring 的循环依赖问题
1、相关面试题
- 你解释下spring中的三级缓存?
- 三级缓存分别是什么?三个Map有什么异同?
- 什么是循环依赖?请你谈谈?看过 Spring源码吗?一般我们说的 Spring容器是什么?
- 如何检测是否存在循环依赖?实际开发中见过循环依赖的异常吗?
- 多例的情况下,循环依赖问题为什么无法解决?
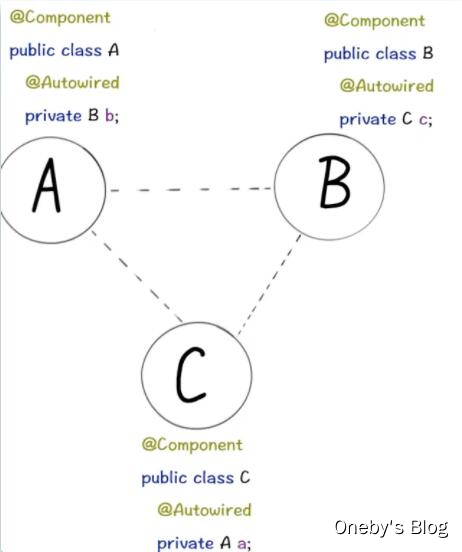
2、什么是循环依赖?
多个 bean 之间相互依赖,形成了一个闭环
比如:A 依赖于 B、B 依赖于 C、C 依赖于 A。
1 | public class CircularDependency { |
通常来说,如果问 Spring 容器内部如何解决循环依赖, 一定是指默认的单例 Bean 中,属性互相引用的场景。也就是说,Spring 的循环依赖,是 Spring 容器注入时候出现的问题
3、两种注入方式对循环依赖的影响

两种注入方式对循环依赖的影响:
- 构造器注入:容易造成无法解决的循环依赖,不推荐使用(If you use predominantly constructor injection, it is possible to create an unresolvable circular dependency scenario.)
- Setter 注入:推荐使用 setter 方式注入单例 bean
spring容器:
- 默认的单例(singleton)的场景是支持循环依赖的,不报错。
- 原型(Prototype)的场景是不支持循环依赖的,会报错。默认单例,修改为原型scope=”prototype” 就导致了循环依赖错误
结论:我们 AB 循环依赖问题只要注入方式是 setter 且bean 的 scope 属性是 singleton,就不会有循环依赖问题
4、那么Spring底层是怎么解决循环依赖的呢
Spring 内部通过 3 级缓存来解决循环依赖
所谓的三级缓存其实就是 Spring 容器内部用来解决循环依赖问题的三个 Map,这三个 Map 在 DefaultSingletonBeanRegistry 类中
只有单例的bean会通过三级缓存提前暴露来解决循环依赖问题,而非单例的bean,每次从容器中获取都是一个新的对象,都会重新创建,所以非单例的bean是没有缓存的,不会将其放到三级缓存中,因此也解决不了循环依赖问题。
那么三级缓存的这三个Map分别是什么?有什么异同?
- 第一级缓存〈也叫单例池)
Map<String, Object> singletonObjects:常说的 Spring 容器就是指它,我们获取单例 bean 就是在这里面获取的,存放已经经历了完整生命周期的Bean对象 - 第二级缓存:
Map<String, Object> earlySingletonObjects,存放早期暴露出来的Bean对象,Bean的生命周期未结束(属性还未填充完整,可以认为是半成品的 bean) - 第三级缓存:
Map<String, ObjectFactory<?>> singletonFactories,存放可以生成Bean的工厂,用于生产(创建)bean对象
5、源码 Deug 前置知识
1、实例化 & 初始化
实例化和初始化的区别:
实例化:堆内存中申请一块内存空间

初始化:完成属性的填充

2、3个Map & 5个方法
三级缓存 + 五大方法:
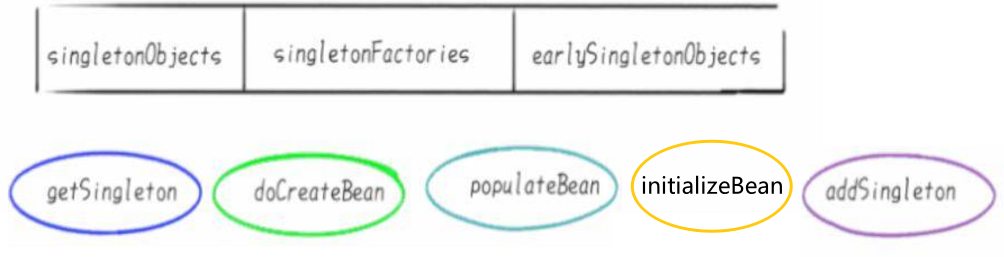
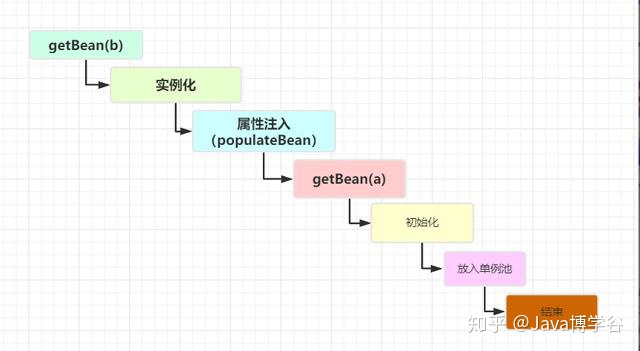
三级缓存《==》3个Map:
- 第一级缓存singletonObjects:存放的是已经初始化好了的Bean,bean名称与bean实例相对应,即所谓的单例池。表示已经经历了完整生命周期的Bean对象
- 第二级缓存earlySingletonObjects:存放的是实例化了,但是未初始化的Bean,bean名称与bean实例相对应。表示Bean的生命周期还没走完(Bean的属性还未填充)就把这个Bean存入该缓存中。也就是实例化但未初始化的bean放入该缓存里
- 第三级缓存singletonFactories:表示存放生成bean的工厂,存放的是FactoryBean,bean名称与bean工厂对应。假如A类实现了FactoryBean,那么依赖注入的时候不是A类,而是A类产生的Bean
五大方法:
getSingleton():从容器里面获得单例的bean,没有的话则会创建 beandoCreateBean():执行创建 bean 的操作(在 Spring 中以 do 开头的方法都是干实事的方法)populateBean():创建完 bean 之后,对 bean 的属性进行填充initializeBean():初始化bean对象,也是在这里完成AOP代理addSingleton():bean 初始化完成之后,添加到单例容器池中,下次执行 getSingleton() 方法时就能获取到
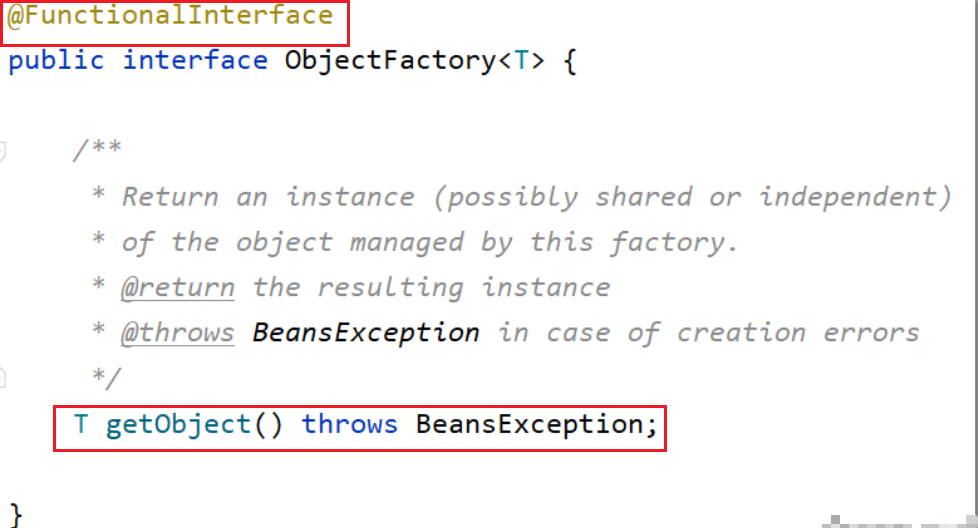
注:关于第三级缓存 Map<String, ObjectFactory<?>> singletonFactories的说明:singletonFactories 的 value 为 ObjectFactory 接口实现类的实例。ObjectFactory 为函数式接口,在该接口中定义了一个 getObject() 方法用于获取 bean,这也正是工厂思想的体现(工厂设计模式)
3、对象在三级缓存中的迁移
A/B 两对象在三级缓存中的迁移说明:
- A创建过程中需要B,于是A将自己放到三级缓存里面,去实例化B
- B实例化的时候发现需要A,于是B先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了A,然后把三级缓存里面的这个A放到二级缓存里面,并删除三级缓存里面的A
- B顺利初始化完毕,将自己放到一级缓存里面(此时B里面的A依然是创建中状态),然后回来接着创建A,此时B已经创建结束,直接从一级缓存里面拿到B,然后完成创建,并将A自己放到一级缓存里面。
6、详细 Debug 流程
技巧:如何阅读框架源码?答:打断点 + 看日志
1、beanA的实例化
在 ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml"); 代码处打上断点,逐步执行(Step Over),发现执行 new ClassPathXmlApplicationContext("applicationContext.xml") 操作时,beanA 和 beanB 都已经被创建好了,因此我们需要进入 new ClassPathXmlApplicationContext("applicationContext.xml") 中
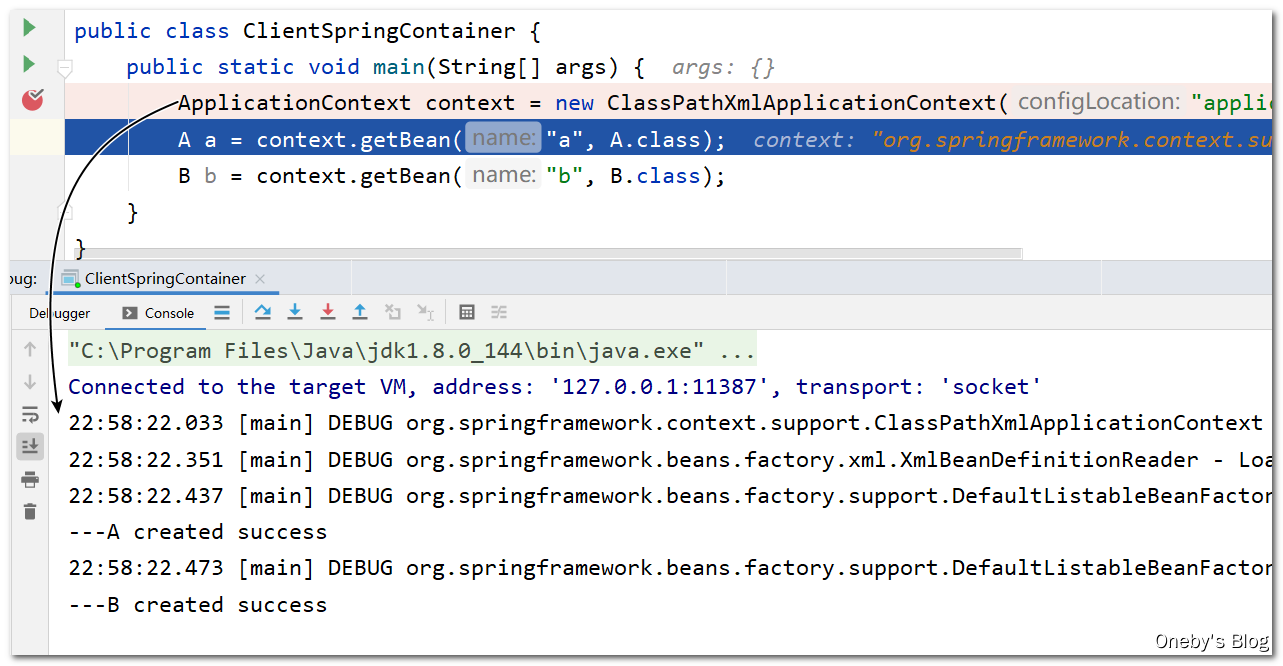
进入 new ClassPathXmlApplicationContext("applicationContext.xml") 中:
点击 Step Into,首先进入了静态代码块中,不管我们的事,使用 Step Out 退出此方法

再次 Step Into,进入 ClassPathXmlApplicationContext 类的构造函数,该构造函数使用 this 调用了另一个重载构造函数

继续 Step Into,进入重载构造函数后单步 Step Over,发现执行完 refresh() 方法后输出如下日志,于是我们将断点打在 refresh() 那一行
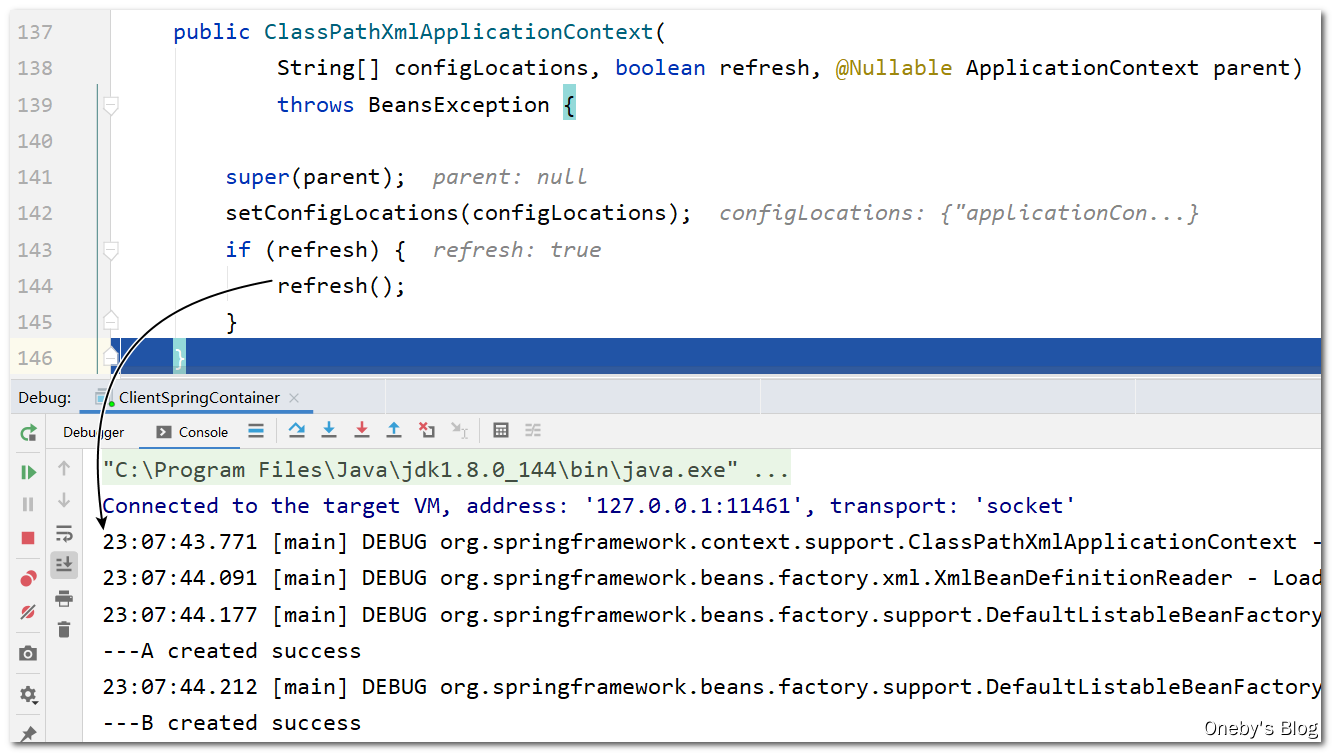
进入 refresh() 方法:
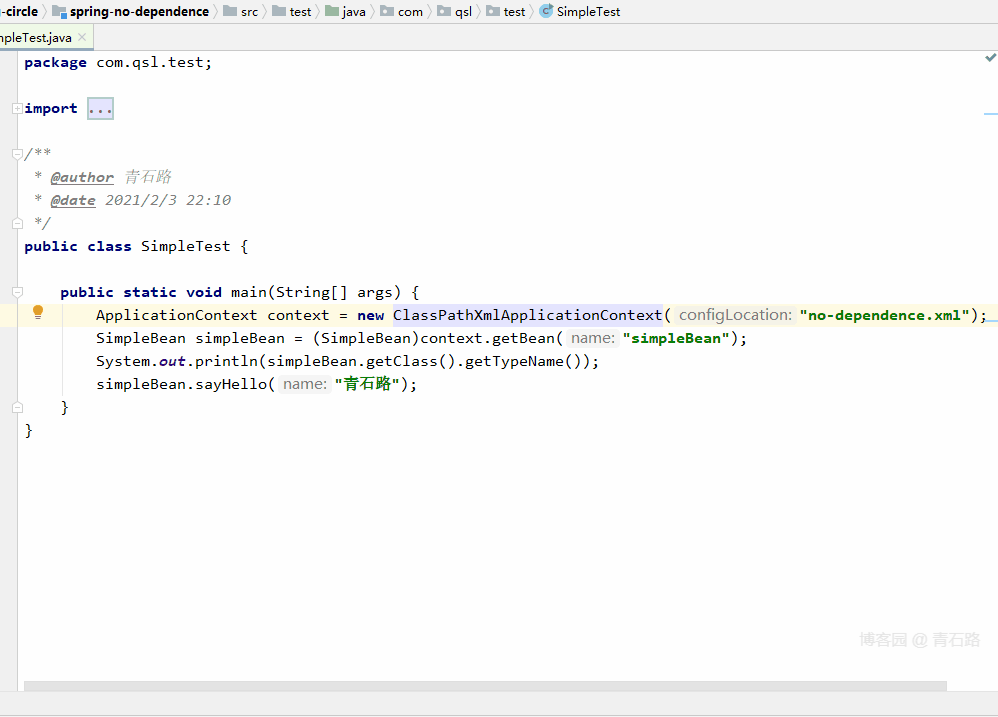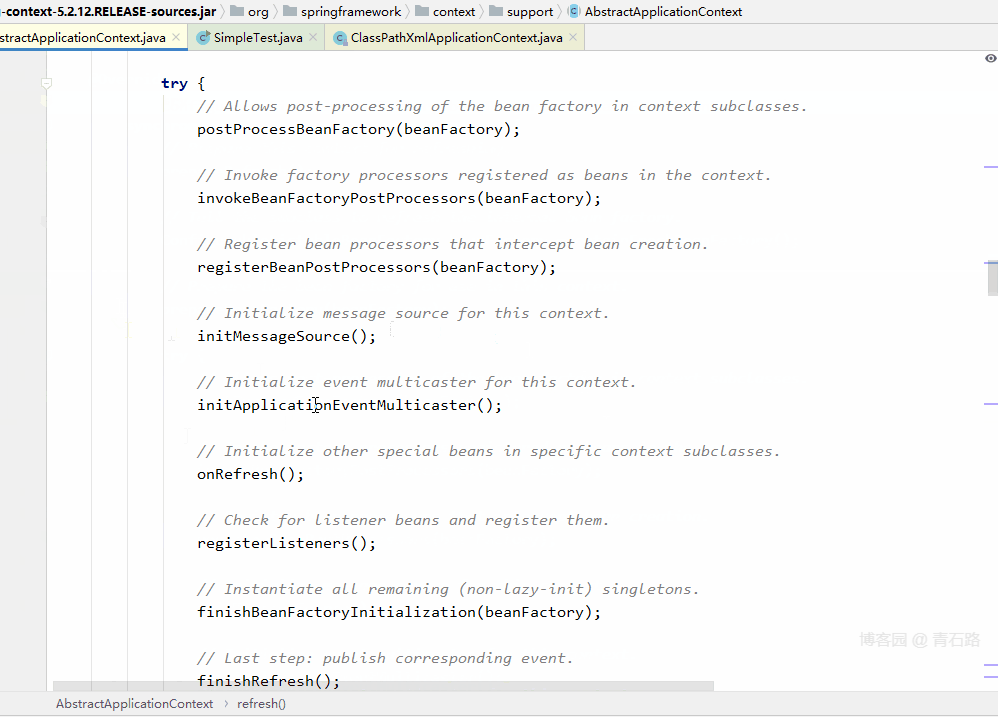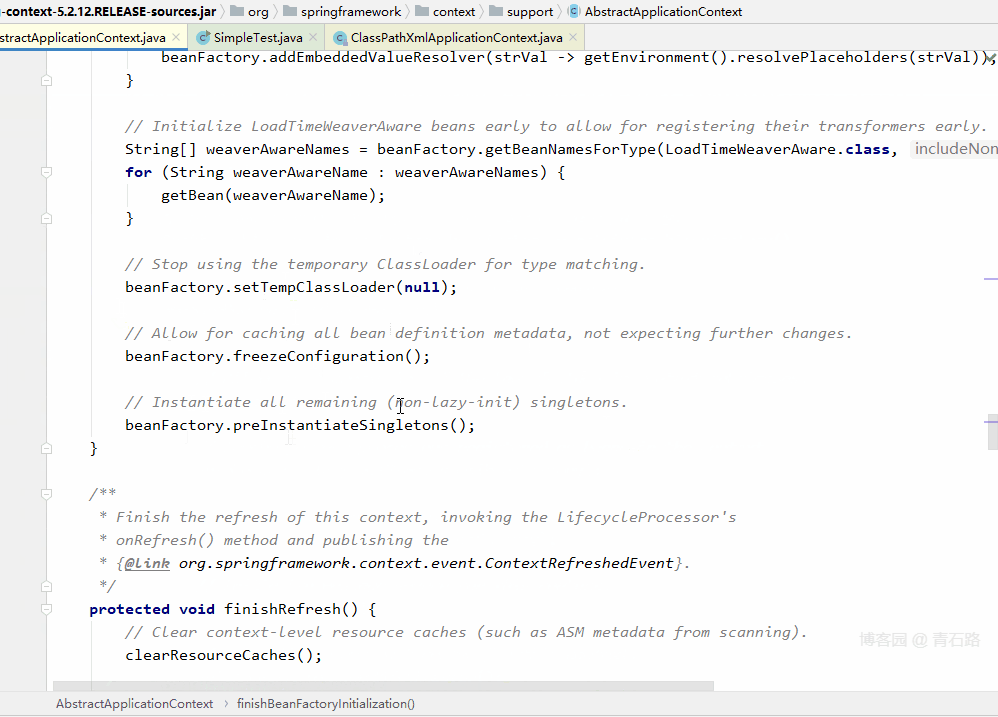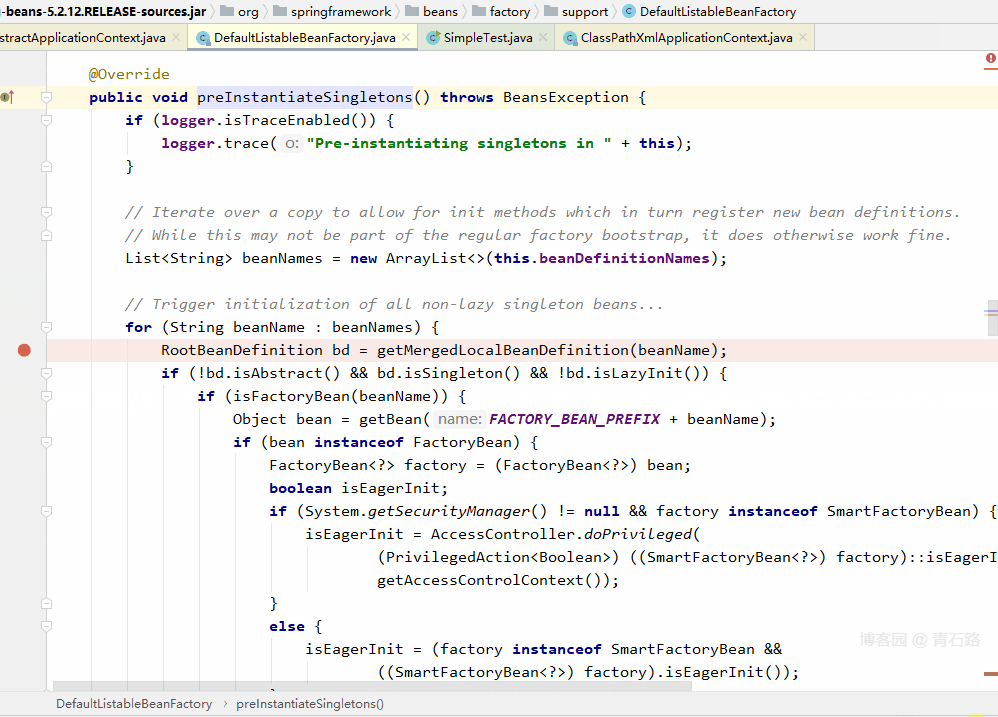
Step Into 进入 refresh() 方法,发现执行完 finishBeanFactoryInitialization(beanFactory) 方法后输出日志,于是我们将断点打在 finishBeanFactoryInitialization(beanFactory) 那一行
从注释也可以看出本方法完成了非懒加载单例 bean的初始化(Instantiate all remaining (non-lazy-init) singletons.)
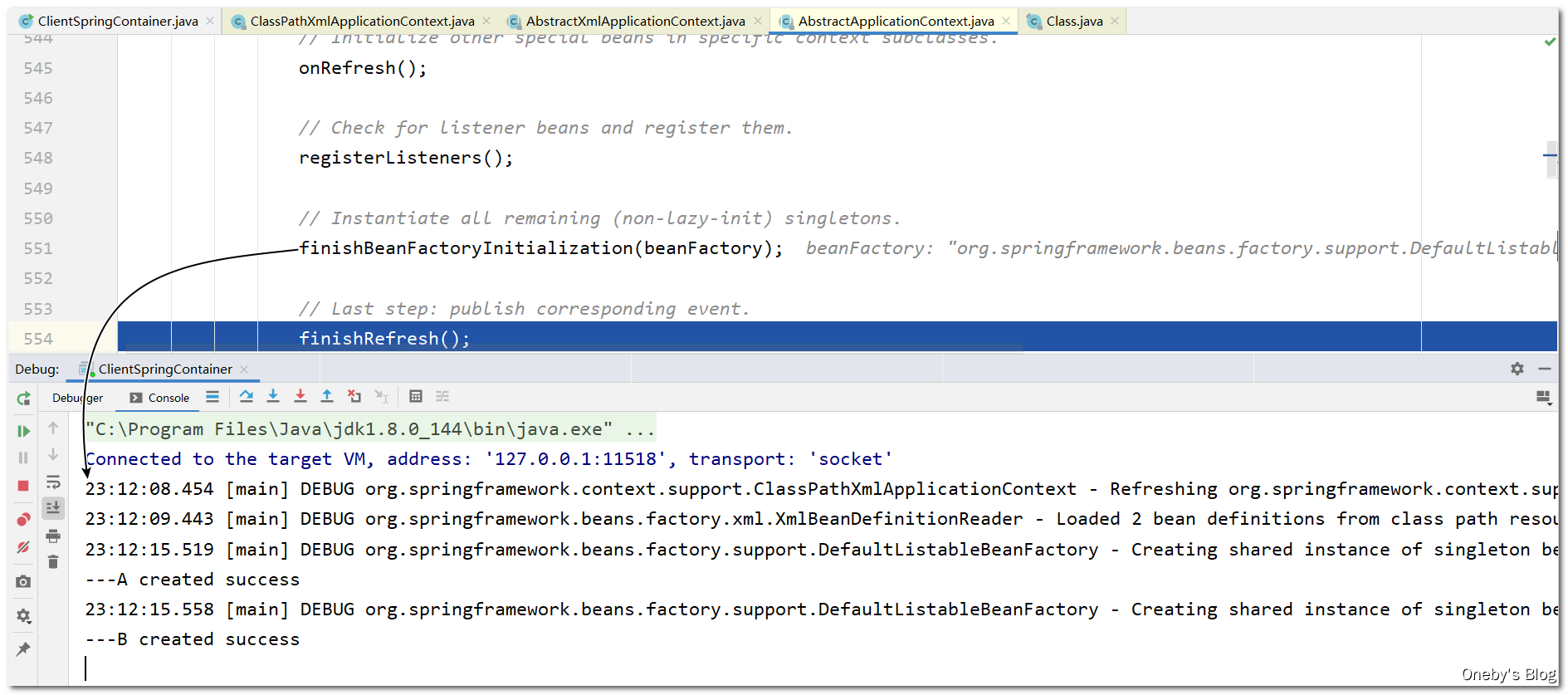
进入 finishBeanFactoryInitialization(beanFactory) 方法:
Step Into 进入 finishBeanFactoryInitialization(beanFactory) 方法,发现执行完 beanFactory.preInstantiateSingletons() 方法后输出日志,于是我们将断点打在 beanFactory.preInstantiateSingletons() 那一行
从注释也可以看出本方法完成了非懒加载单例 bean的初始化(Instantiate all remaining (non-lazy-init) singletons.)
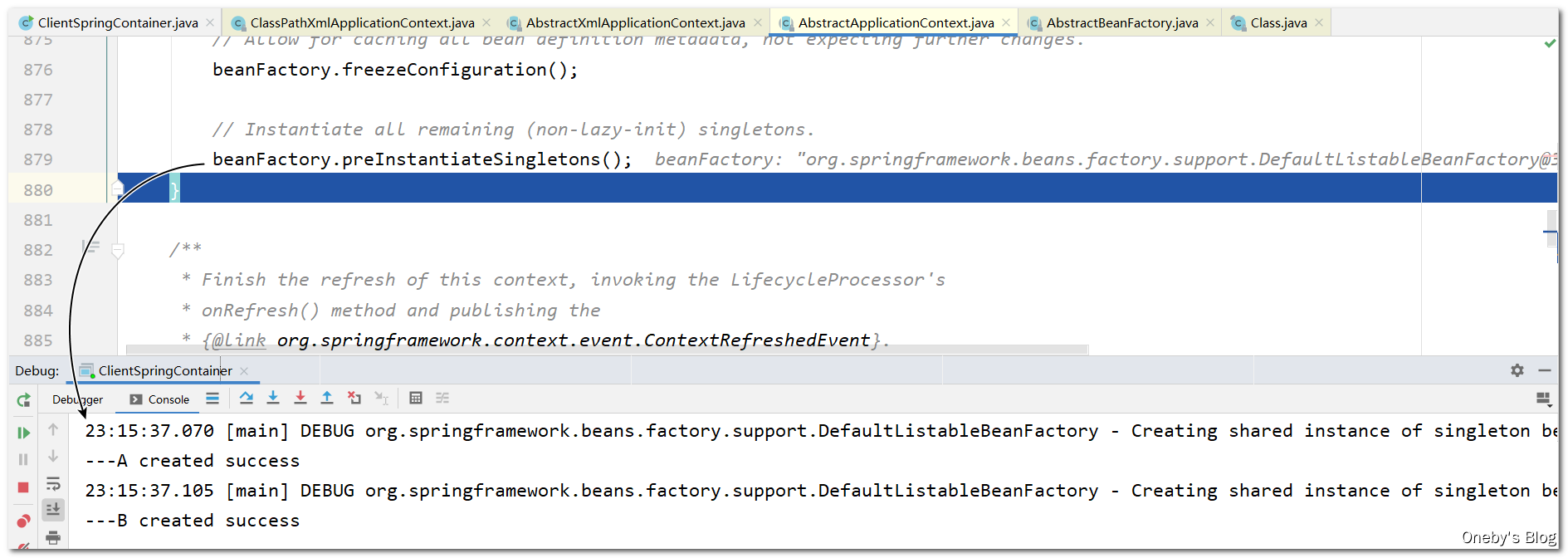
进入 beanFactory.preInstantiateSingletons() 方法:
Step Into 进入 beanFactory.preInstantiateSingletons() 方法,发现执行完 getBean(beanName) 方法后输出日志,于是我们将断点打在 getBean(beanName) 那一行
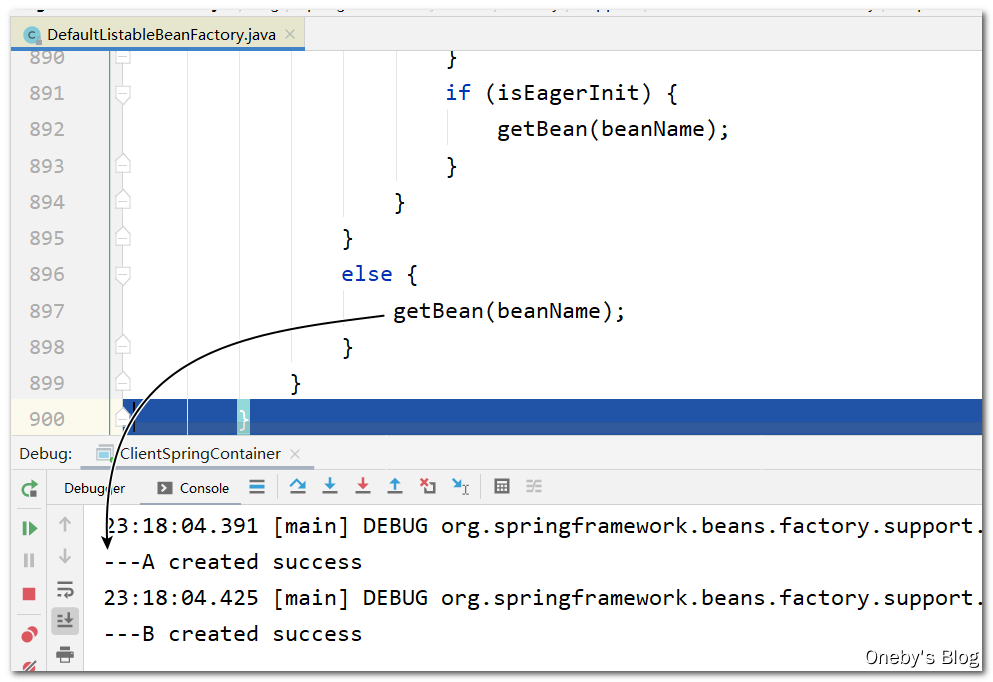
进入 getBean(beanName) 方法:
getBean(beanName) 调用了 doGetBean(name, null, null, false) 方法,即:在 Spring 里面,以do 开头的方法都是干实事的方法

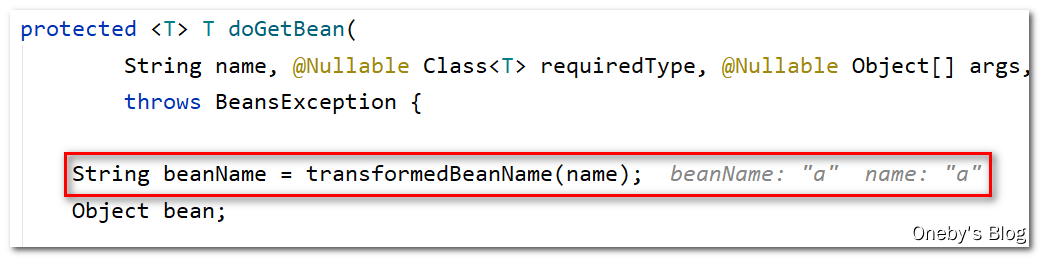
进入 doGetBean(name, null, null, false) 方法:
我们可以给 bean 配置别名,这里的 transformedBeanName(name) 方法就是将用户别名转换为 bean 的真实名称
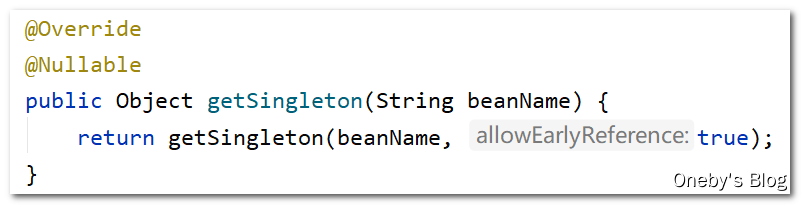
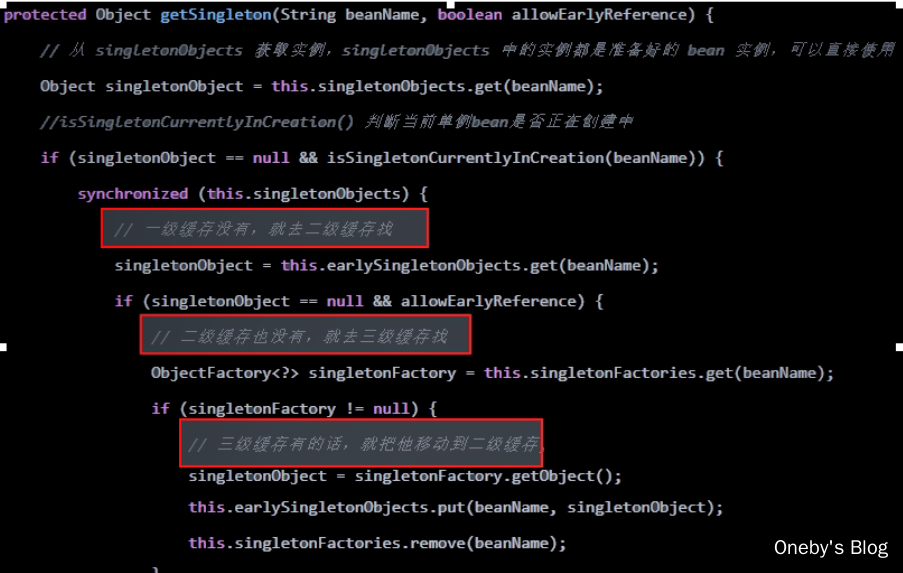
进入 getSingleton(beanName) 方法:
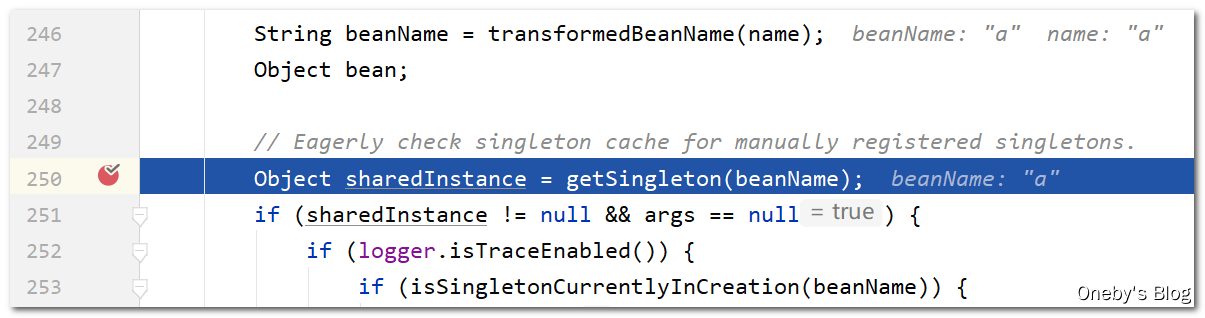
调用了其重载的方法,allowEarlyReference == true 表示可以从三级缓存 earlySingletonObjects 中获取 bean,allowEarlyReference == false 表示不可以从三级缓存 earlySingletonObjects 中获取 bean
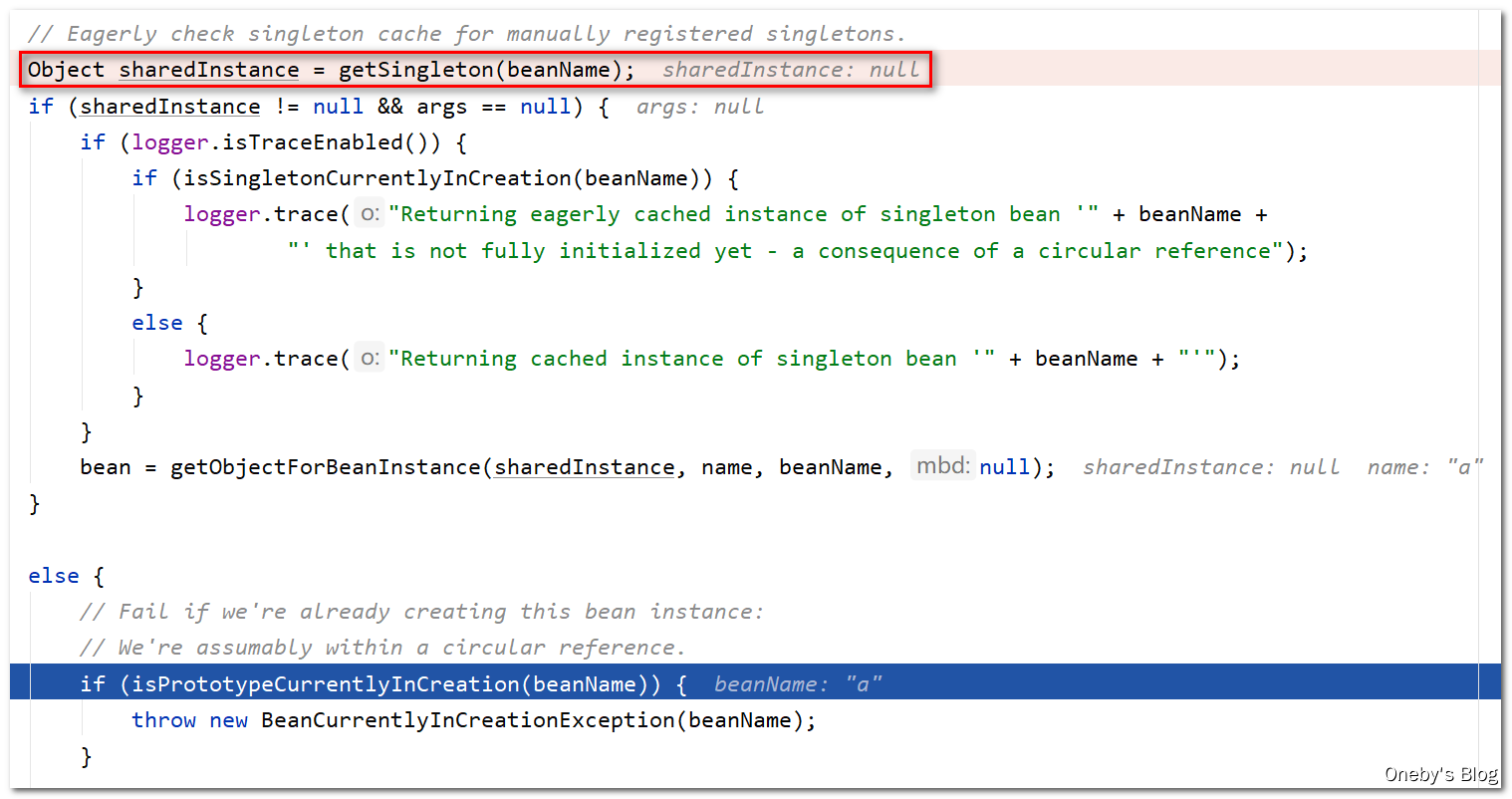
getSingleton(beanName, true) 方法尝试从一级缓存 singletonObjects 中获取 beanA,beanA 现在还没有开始造,(isSingletonCurrentlyInCreation(beanName) 返回 false),获取不到返回 null
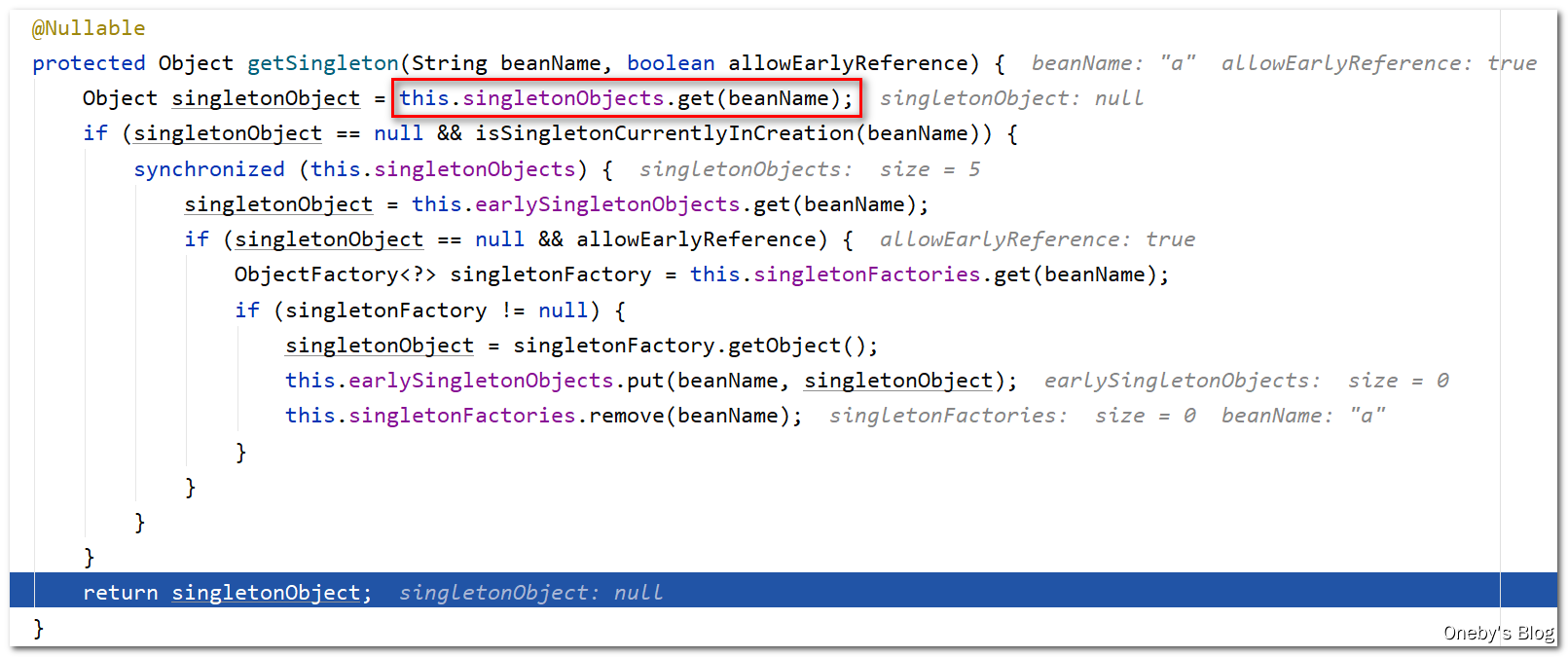
回到 doGetBean(name, null, null, false) 方法中:
getSingleton(beanName)方法返回null
我们所说的 bean 对于 Spring 来说就是一个个的 RootBeanDefinition 实例
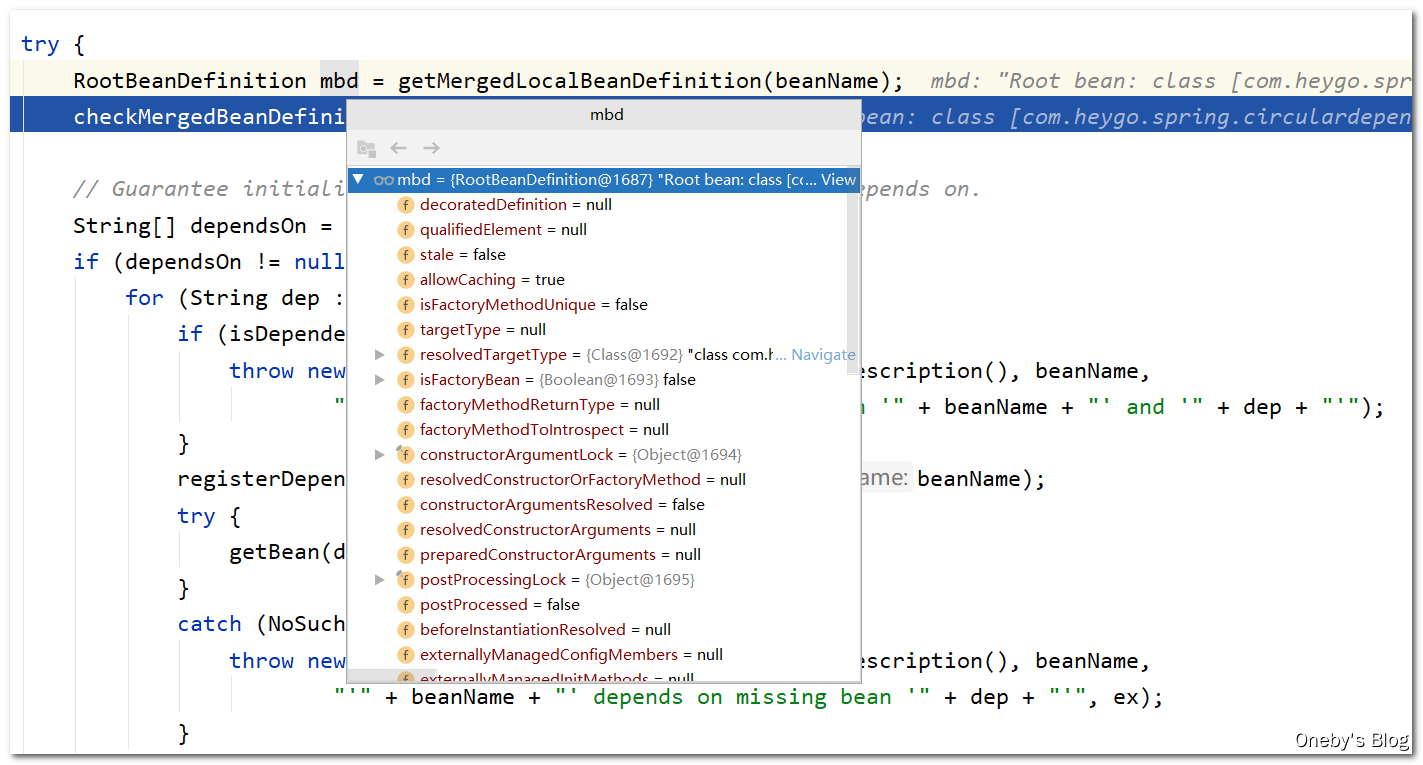
这个 dependsOn 变量对应于 bean 的 depends-on="" 属性,我们没有配置过,因此为 null
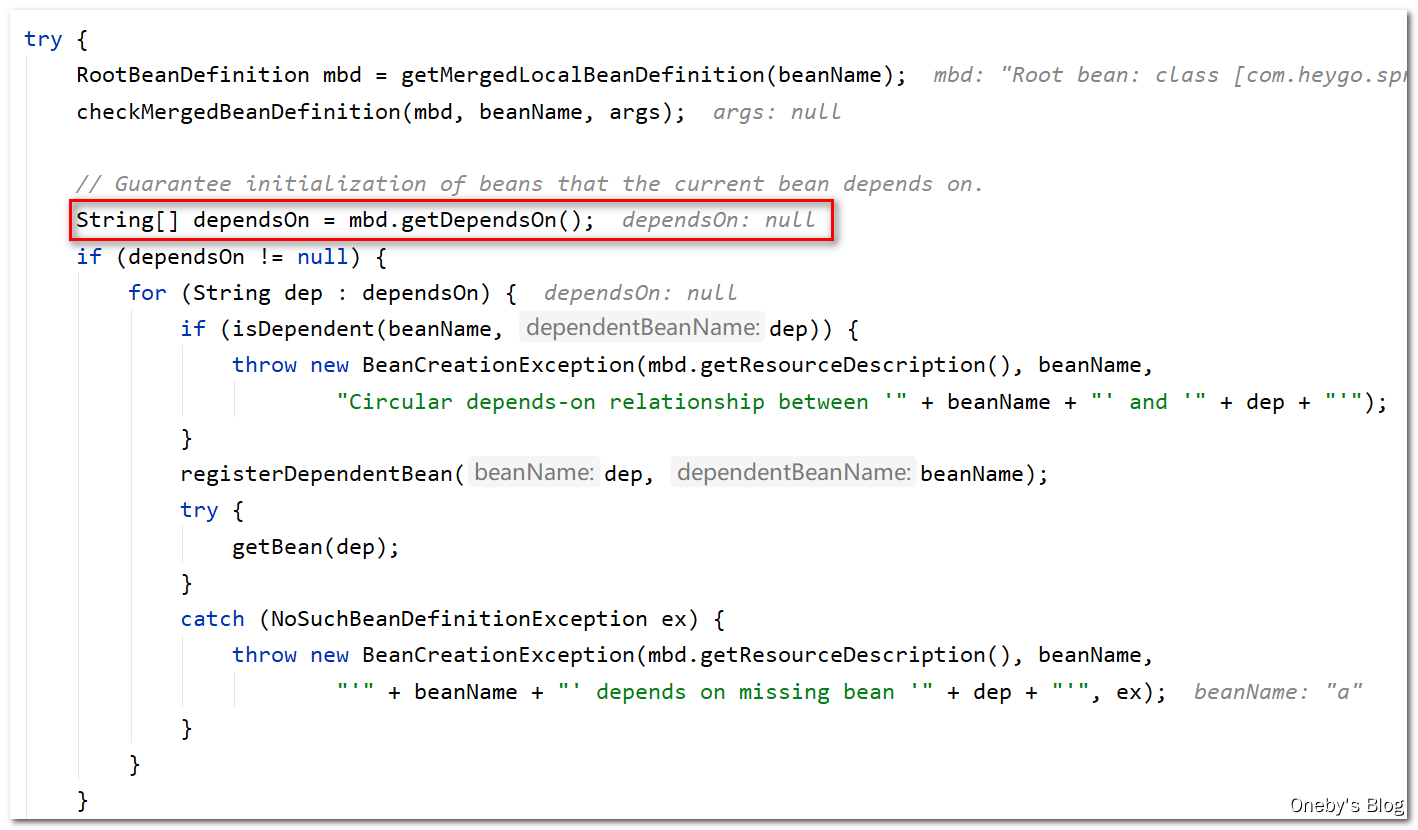
转了一圈发现并没有 beanA,终于要开始准备创建 beanA 啦
进入 getSingleton(beanName, () -> {...} 方法:
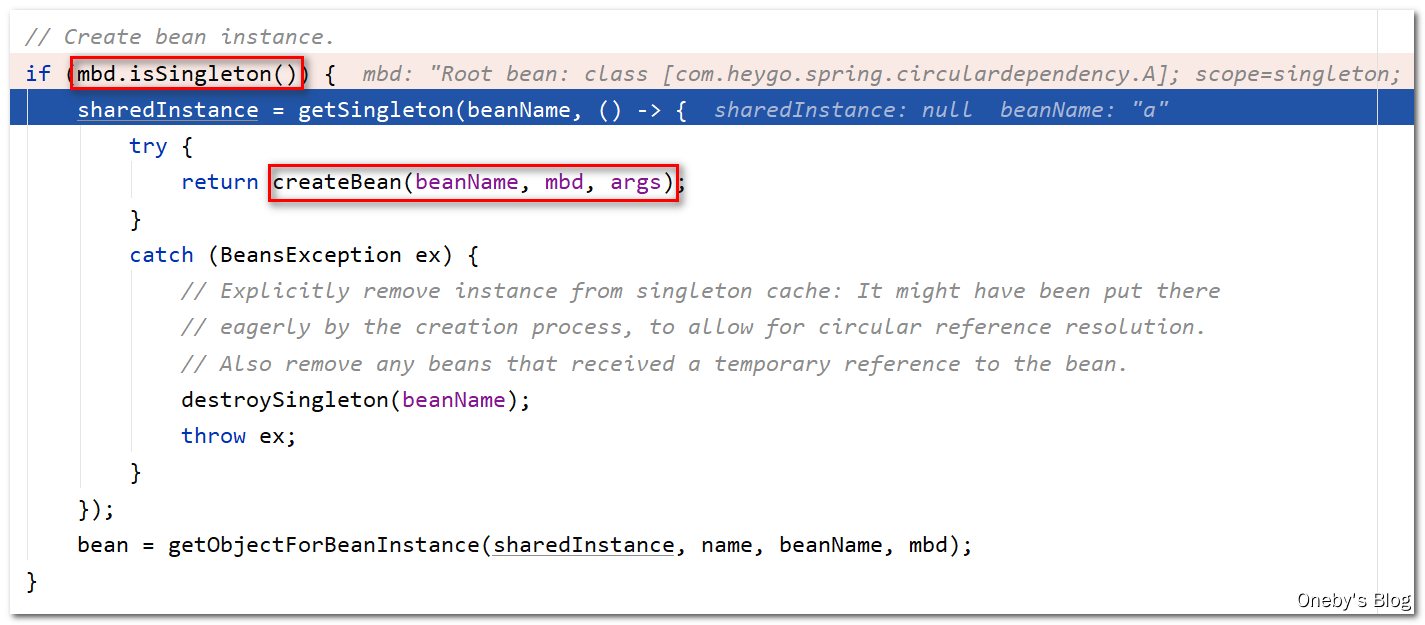
首先尝试从一级缓存 singletonObjects 获取 beanA,那肯定是获取不到,因此 singletonObject == null,那么就需要创建 beanA,此时日志会输出:【Creating shared instance of singleton bean ‘a’】
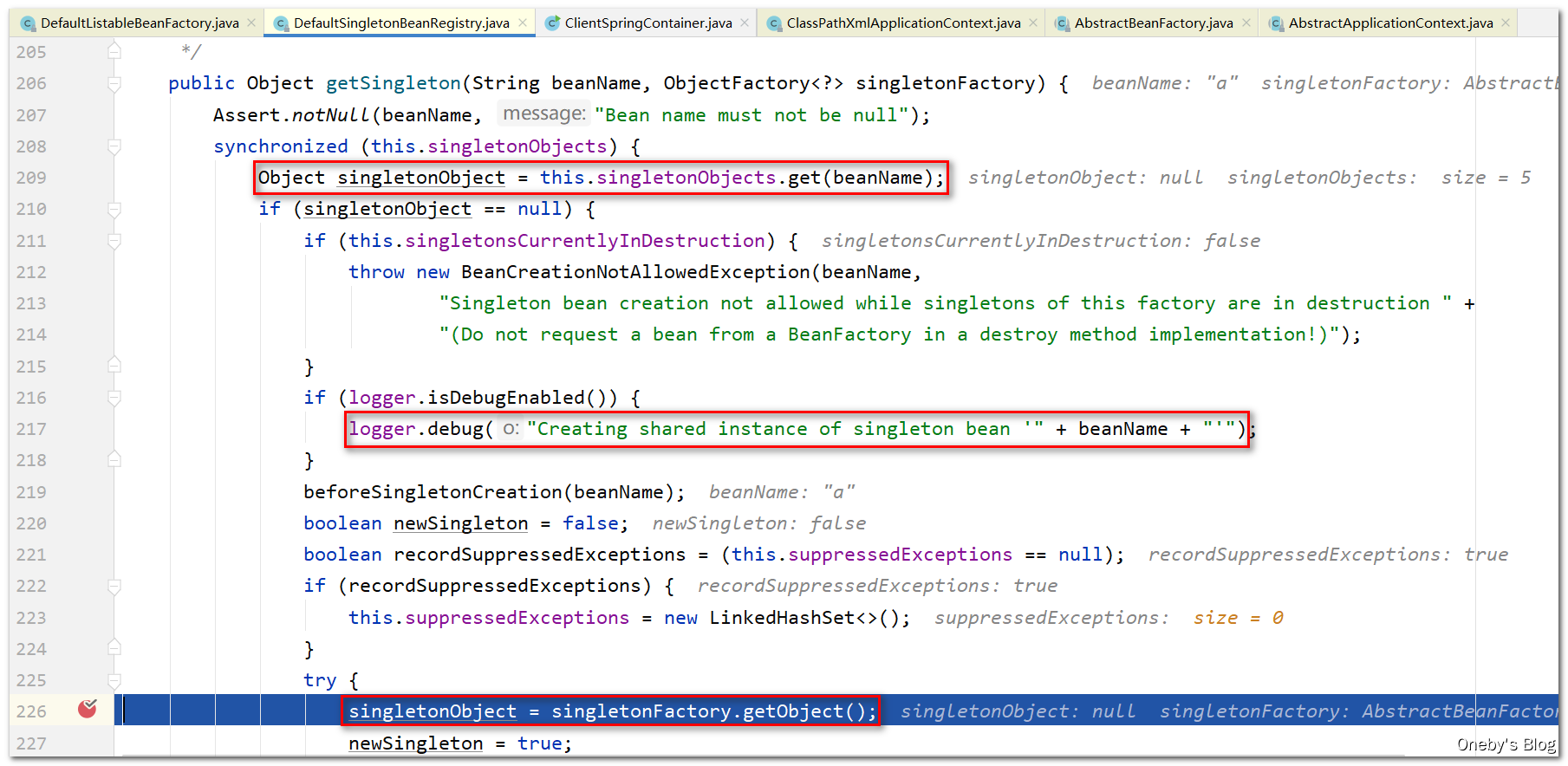
当执行完 singletonObject = singletonFactory.getObject(); 时,会输出【A created success】,这说明执行 singletonFactory.getObject() 方法时将会实例化 beanA,并且根据代码变量名可得知单例工厂创建的,这个单例工厂就是我们传入的 Lambda 表达式
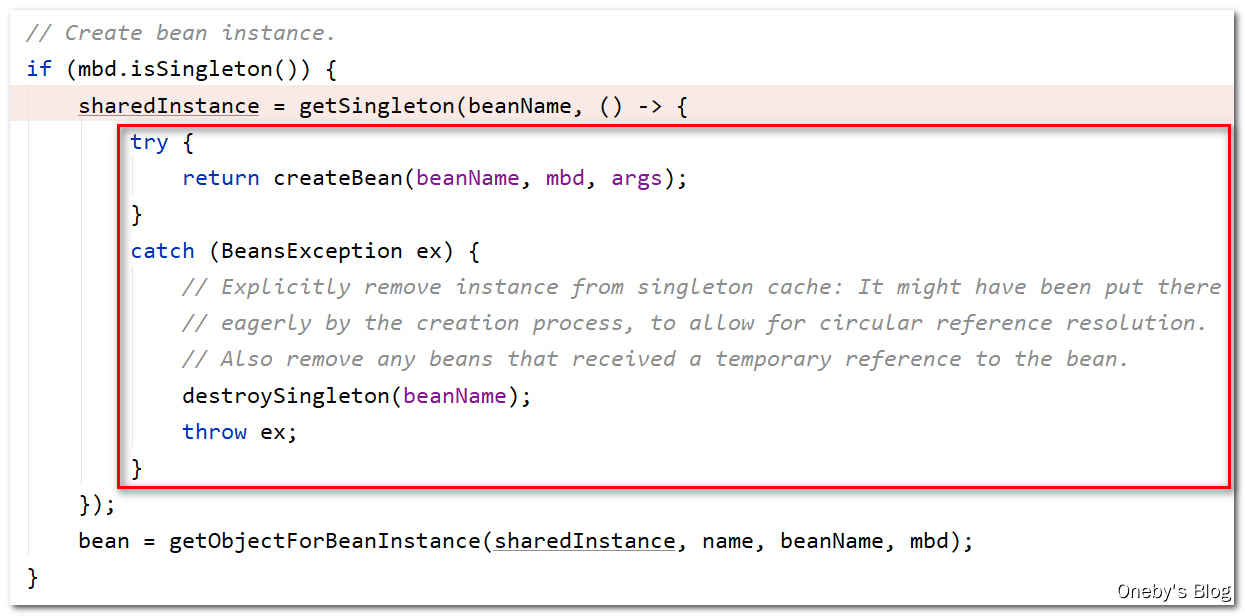
进入 createBean(beanName, mbd, args) 方法:
mbdToUse 将用于创建 beanA:
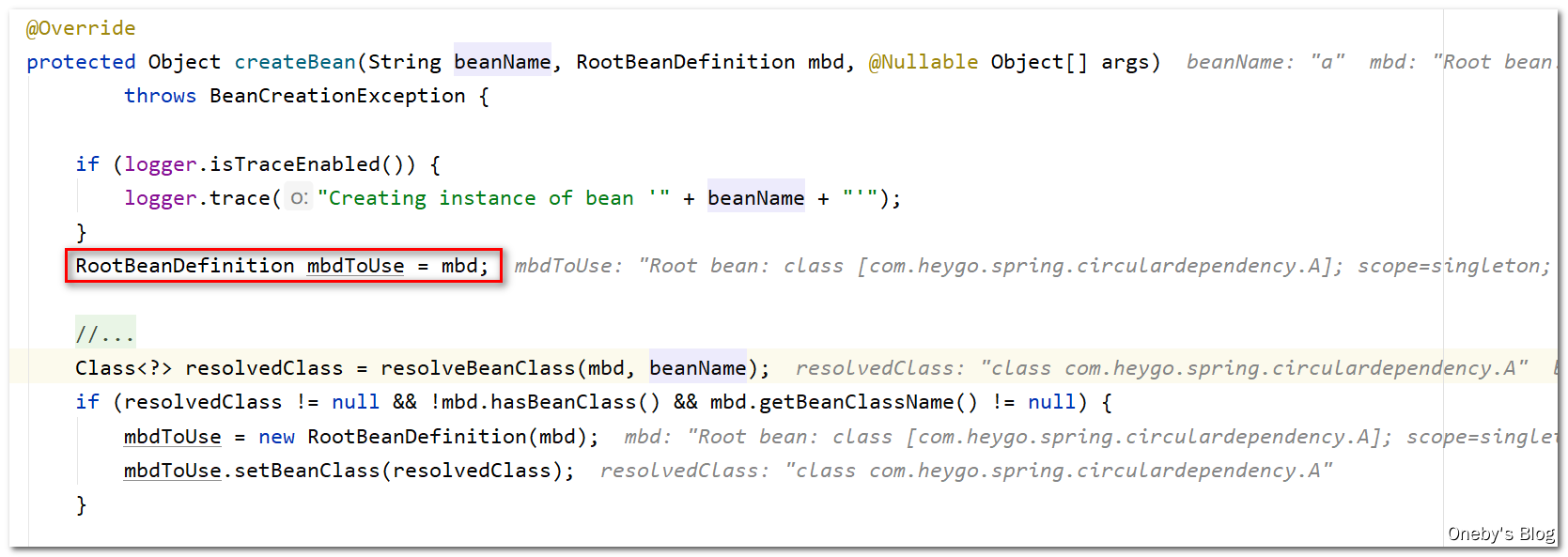
来了,终于要执行 doCreateBean(beanName, mbdToUse, args) 实例化 beanA:
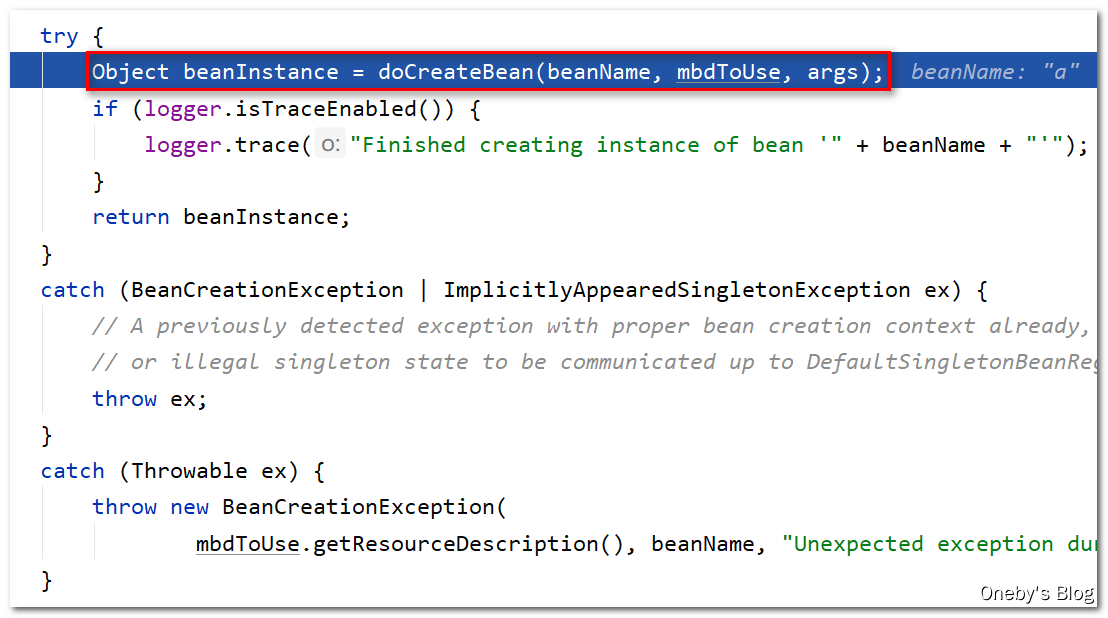
进入 doCreateBean(beanName, mbdToUse, args) 方法:
在 factoryBeanInstanceCache 中并不存在 beanA 对应的 Wrapper 缓存,instanceWrapper == null,因此我们要去创建 beanA 对应的 instanceWrapper,Wrapper 有包裹之意思,instanceWrapper 翻译过来为实例包裹器的意思,形象理解为:beanA 实例化需要经过 instanceWrapper 之手,beanA 实例被 instanceWrapper 包裹在其中
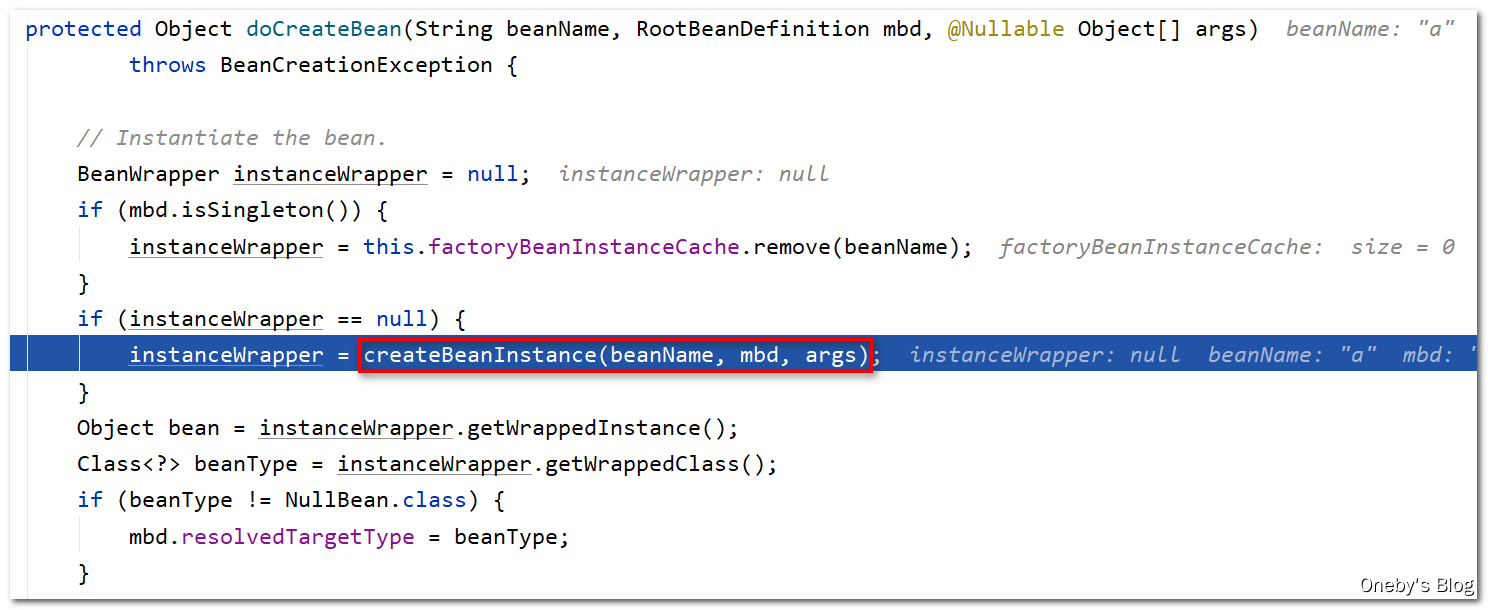
进入 createBeanInstance(beanName, mbd, args) 方法:
这一看就是反射的操作
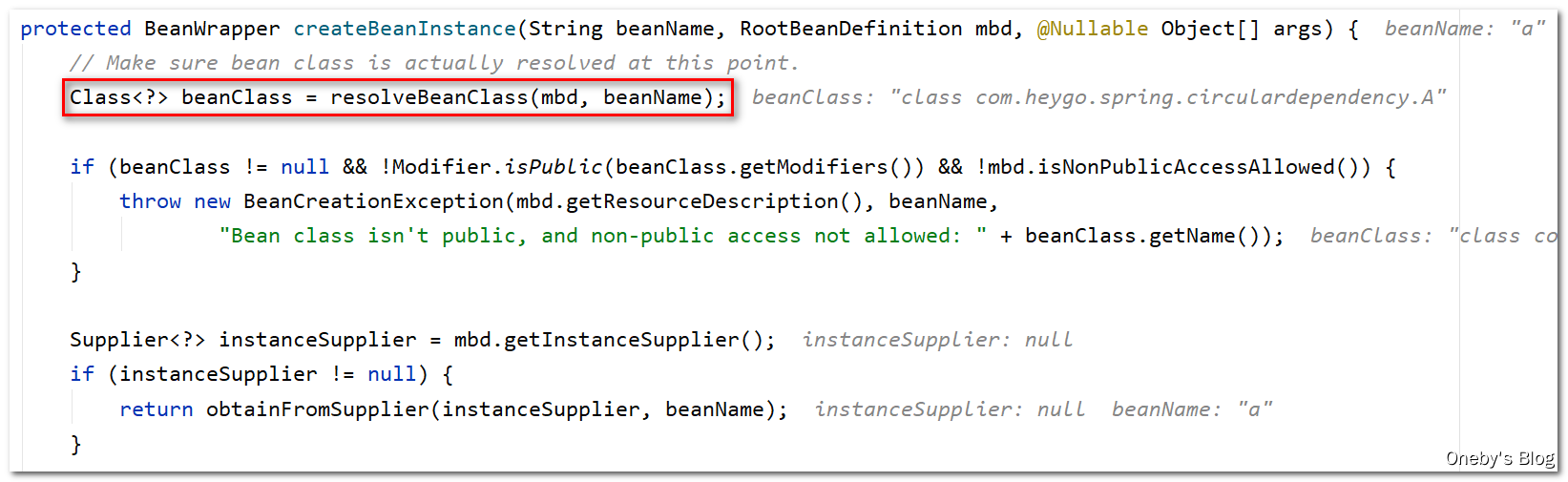
这里有个 resolved 变量,写着注释:Shortcut when re-creating the same bean…,我个人理解是 resolved 标志该 bean 是否已经被实例化了,如果已经被实例化了,那么 resolved == true,这样就不用重复创建同一个 bean 了
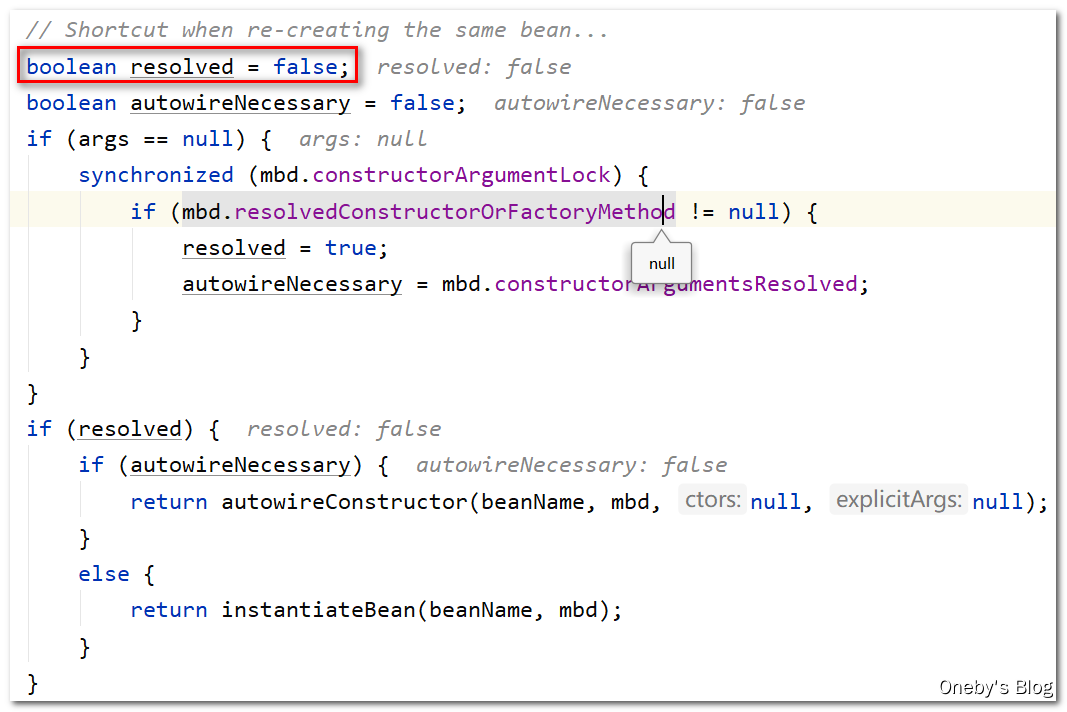
Candidate constructors for autowiring? 难道是构造器自动注入?在 return 的时候调用 instantiateBean(beanName, mbd) 方法实例化 beanA,并将其返回
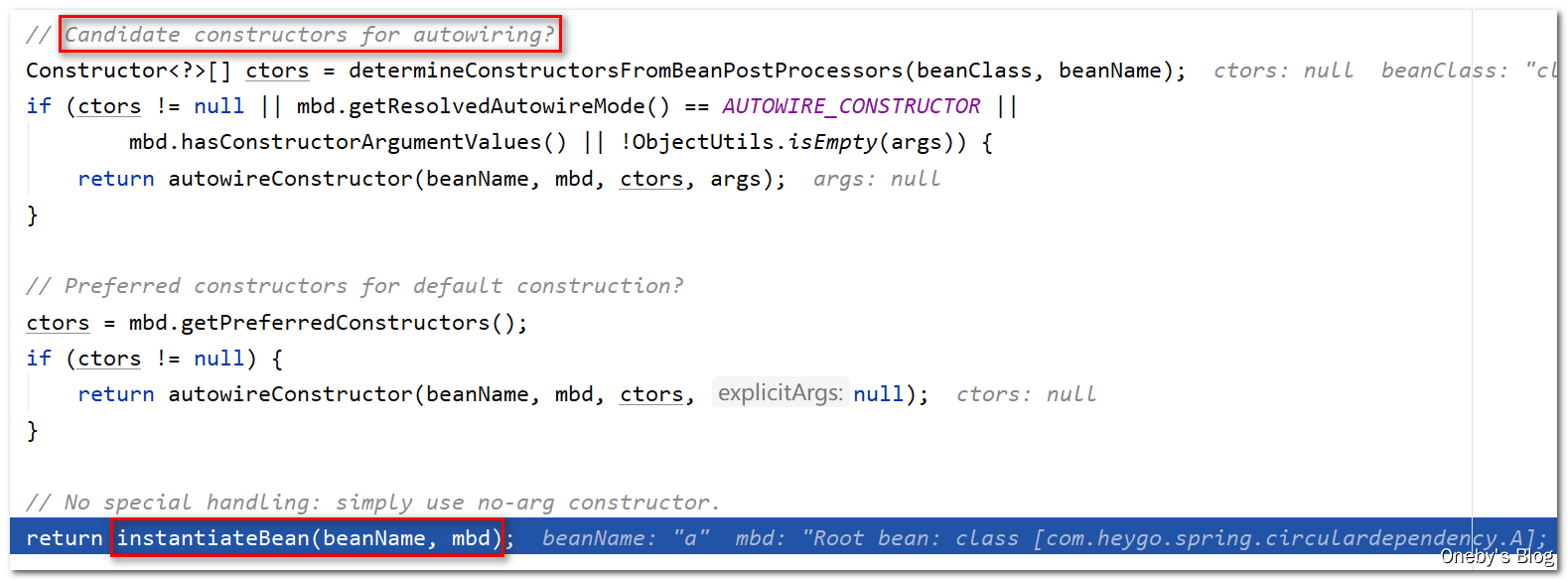
进入 instantiateBean(beanName, mbd) 方法:
getInstantiationStrategy().instantiate(mbd, beanName, this) 方法完成了 beanA 的实例化
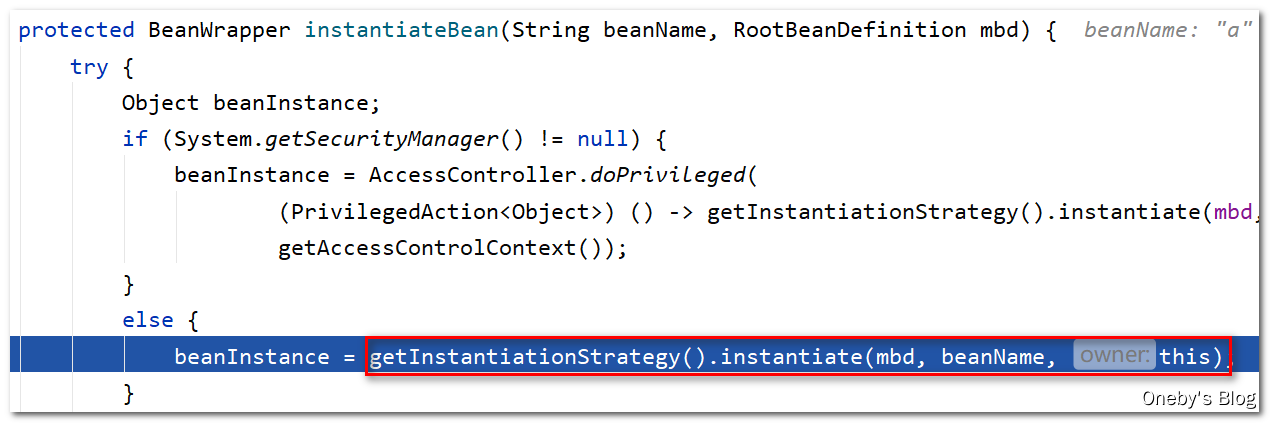
进入 getInstantiationStrategy().instantiate(mbd, beanName, this) 方法:
首先获取已经解析好的构造器 bd.resolvedConstructorOrFactoryMethod,这是第一次创建,当然还没有啦,因此 constructorToUse == null。然后获取 A 的类型,如果发现是接口则直接抛异常。最后获取 A 的公开构造器,并将其赋值给 bd.resolvedConstructorOrFactoryMethod
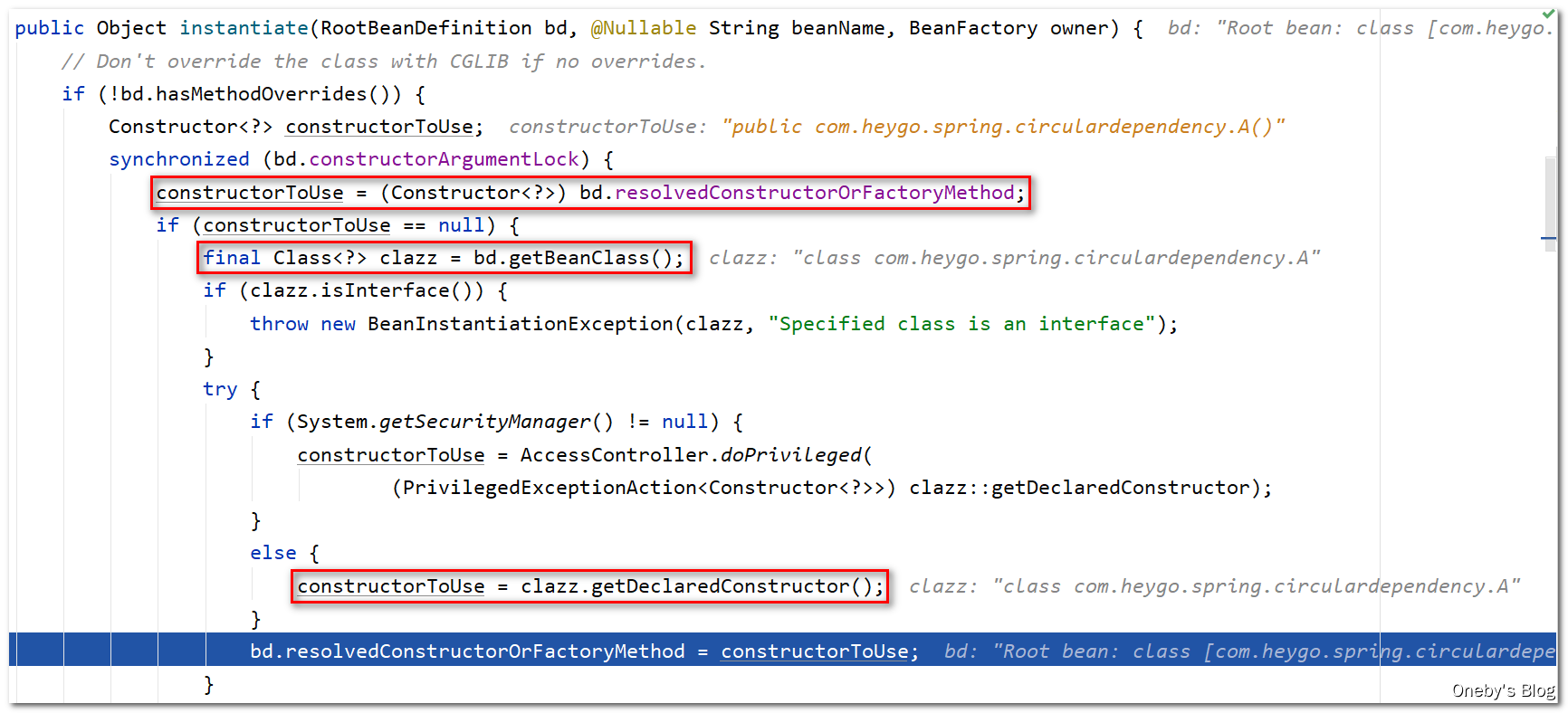
获取构造器的目的当然是为了实例化 beanA
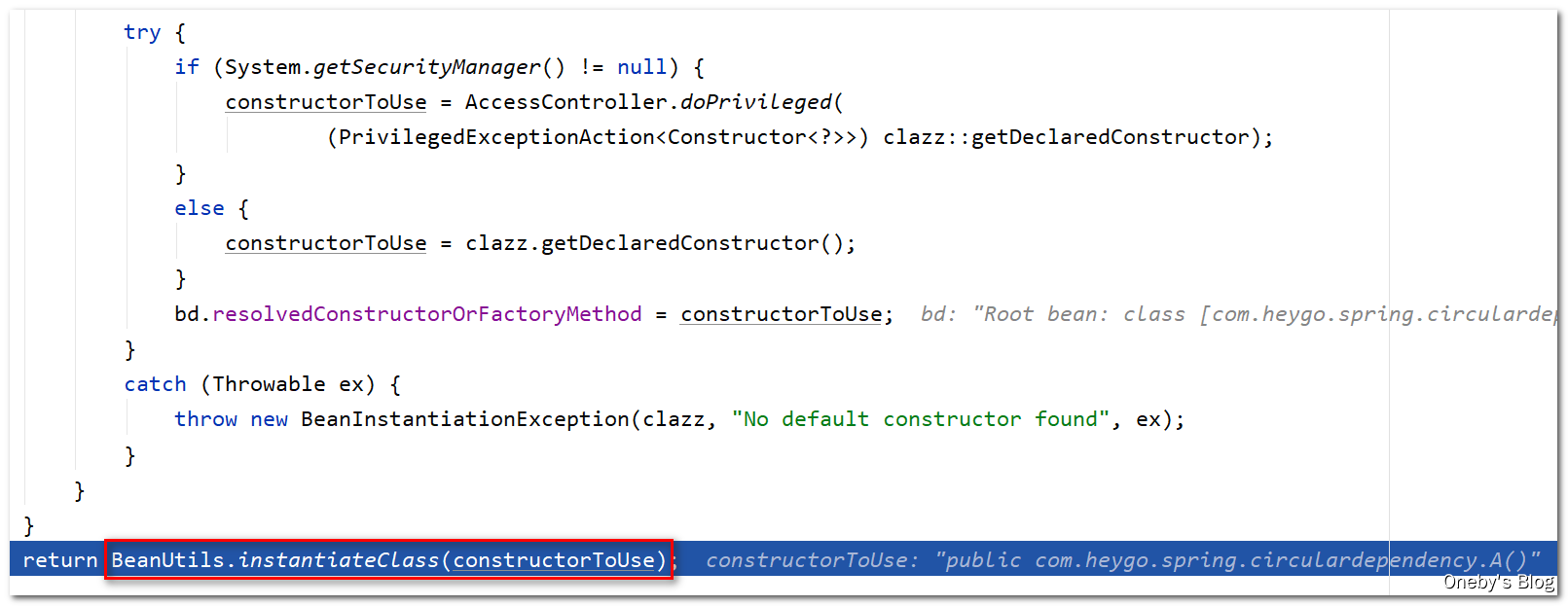
进入 BeanUtils.instantiateClass(constructorToUse) 方法:
通过构造器创建 beanA 实例,Step Over 后会输出:【A created success】,并且会回到 getInstantiationStrategy().instantiate(mbd, beanName, this) 方法中
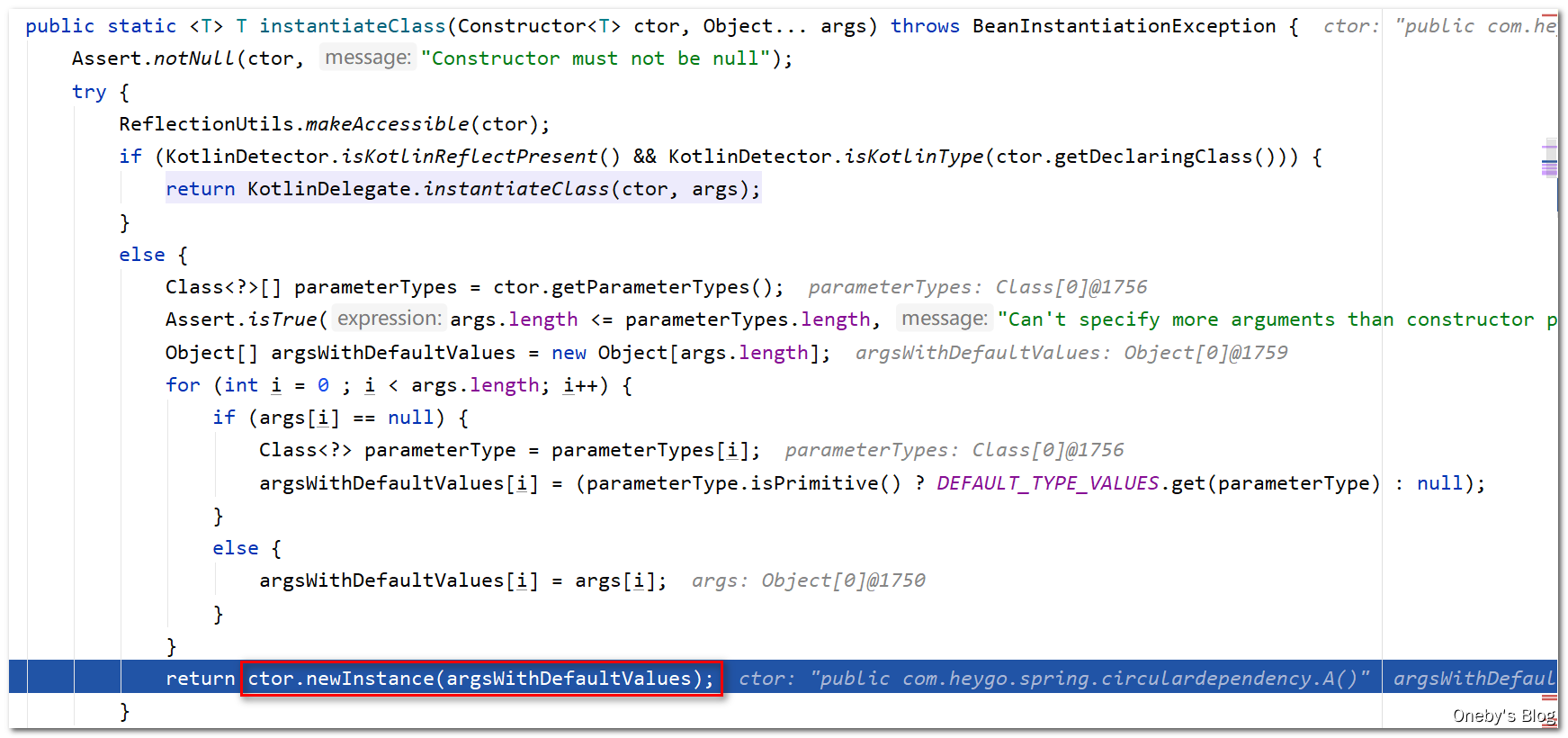
回到 getInstantiationStrategy().instantiate(mbd, beanName, this) 方法中:
在 BeanUtils.instantiateClass(constructorToUse) 方法中创建好了 beanA 实例,不过还没有进行初始化,可以看到属性 b = null,Step Over 后会回到 instantiateBean(beanName, mbd) 方法中
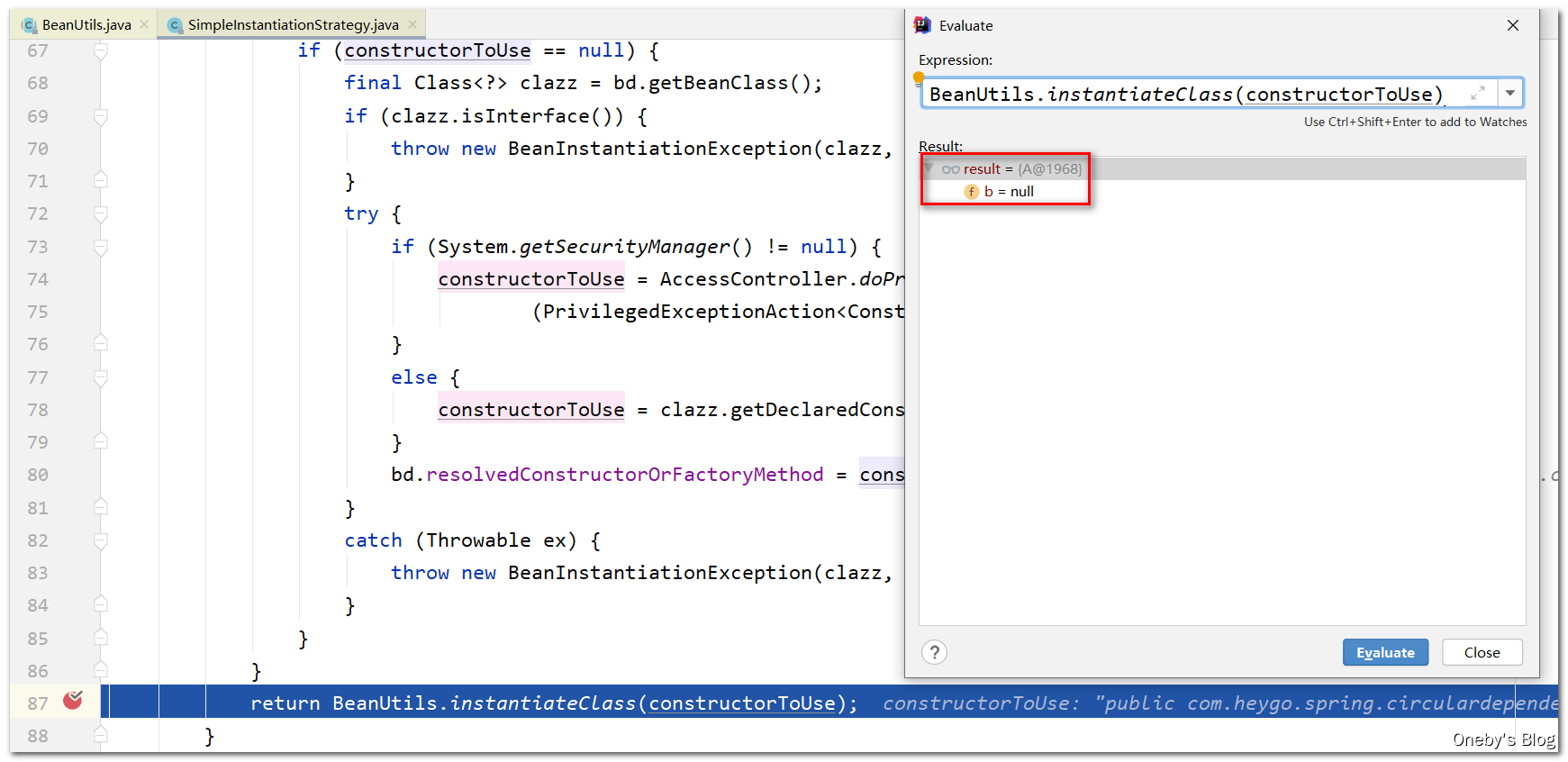
回到 instantiateBean(beanName, mbd) 方法中:
得到刚才创建的 beanA 实例,但其属性并未被初始化
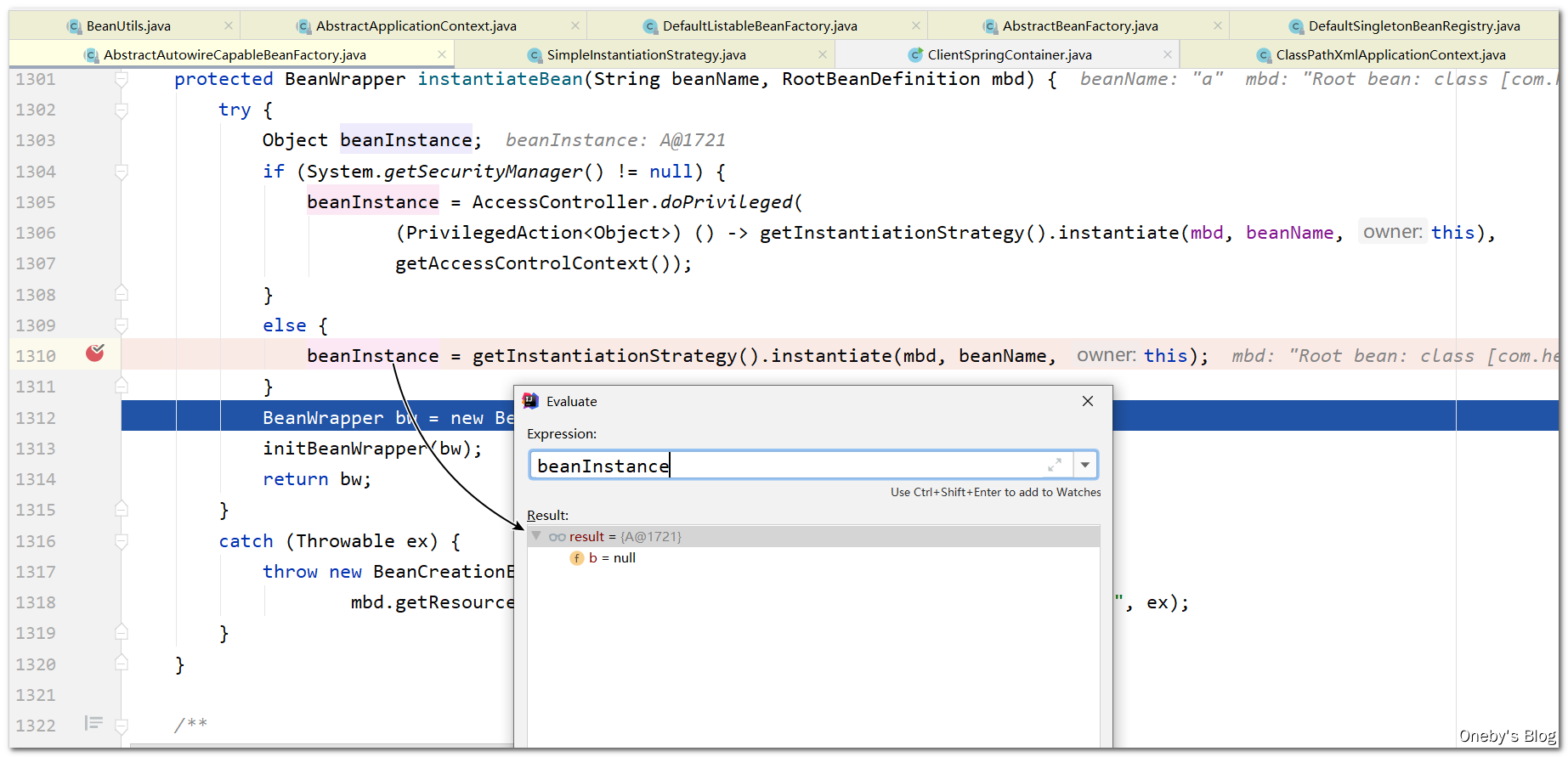
将实例化的 beanA 装进 BeanWrapper 中并返回 bw
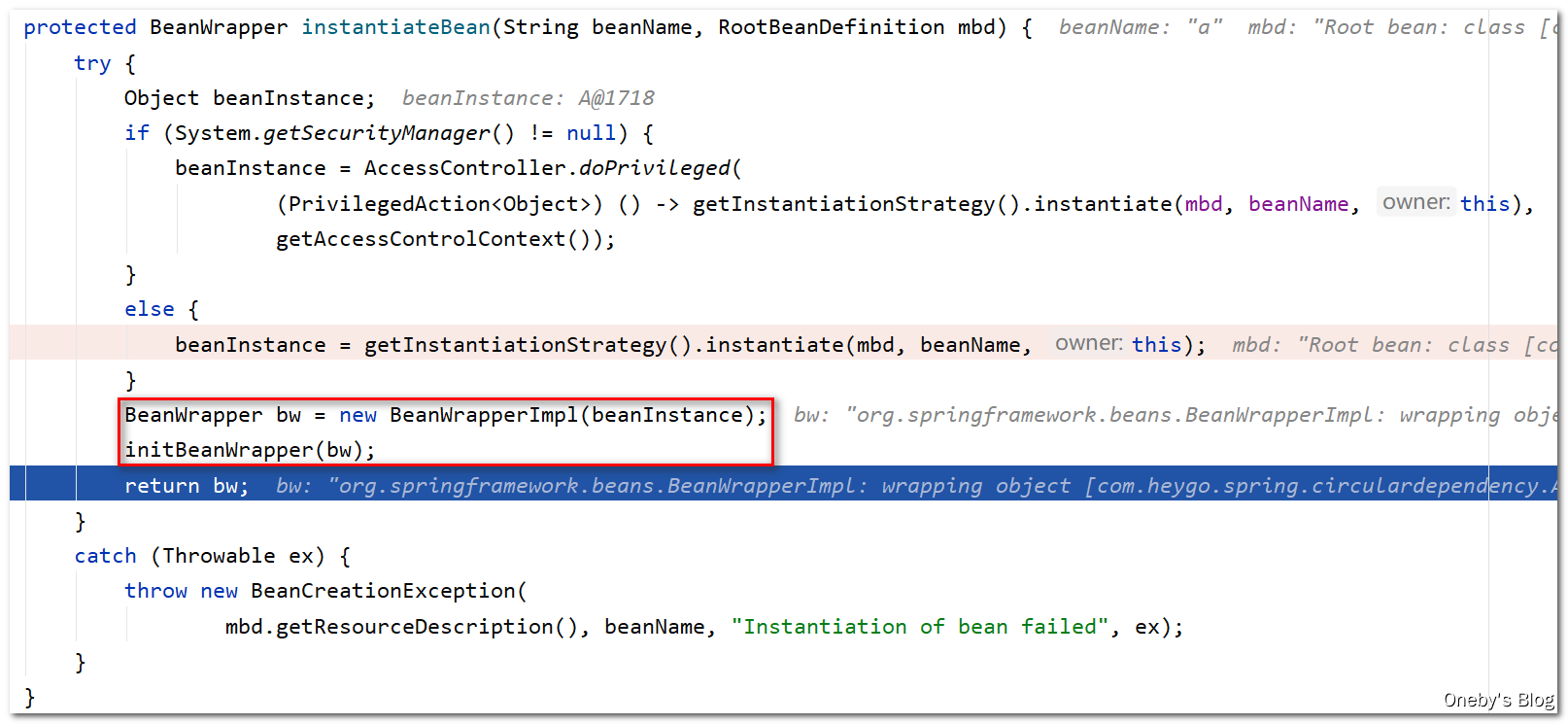
回到 createBeanInstance(beanName, mbd, args) 方法中:
得到刚才创建的 beanWrapper 实例,该 beanWrapper 包裹(封装)了刚才创建的 beanA 实例
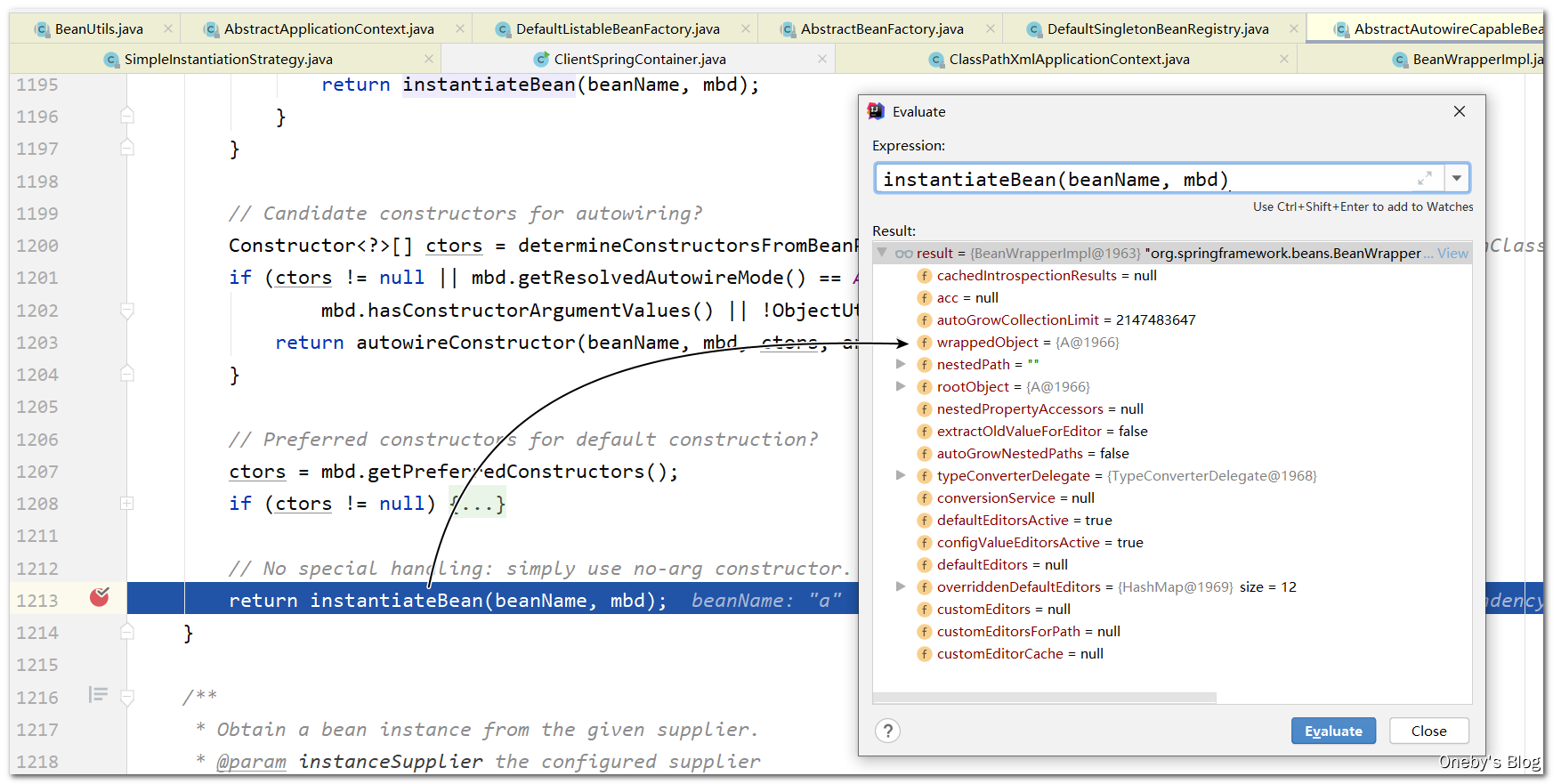
回到 doCreateBean(beanName, mbdToUse, args) 方法中:
在 doCreateBean(beanName, mbdToUse, args) 方法获得 BeanWrapper instanceWrapper,用于封装 beanA 实例
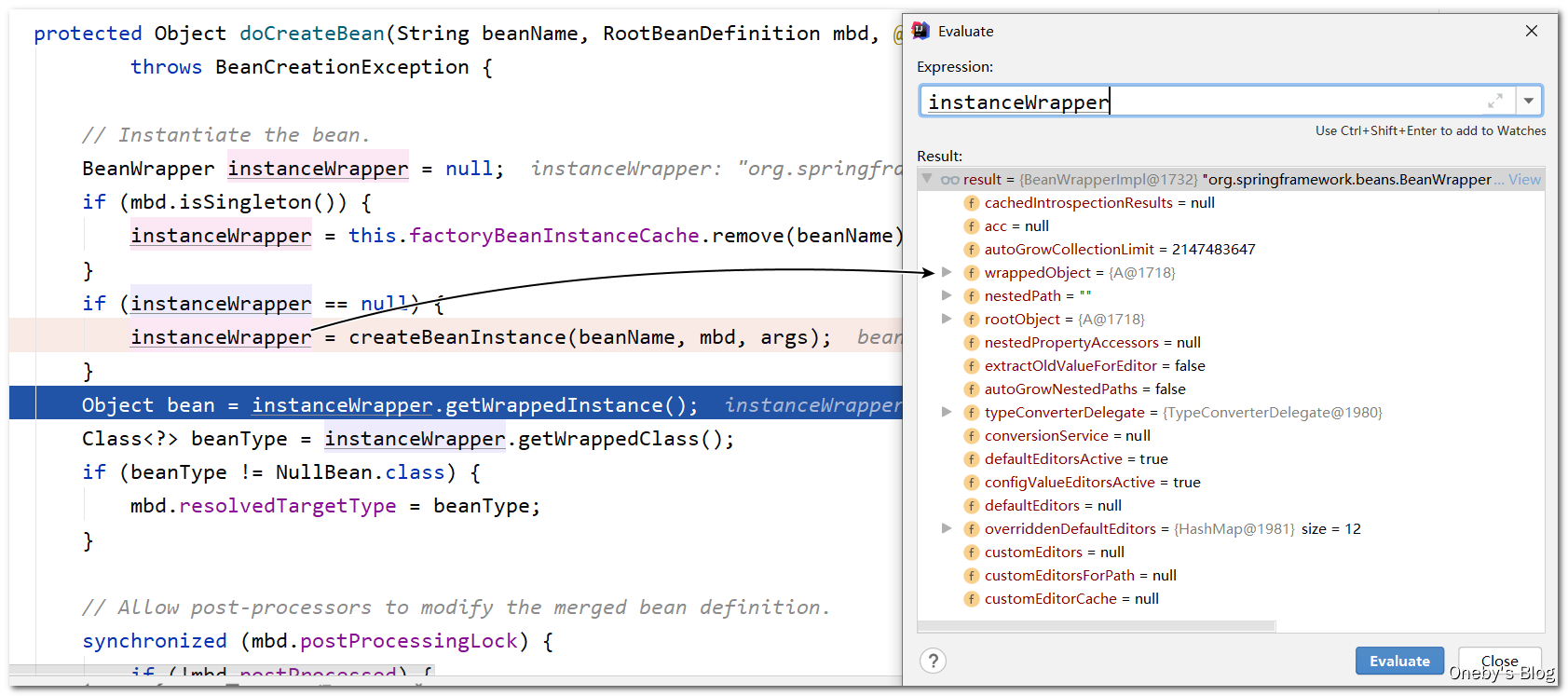
获取并记录 A 的全类名:
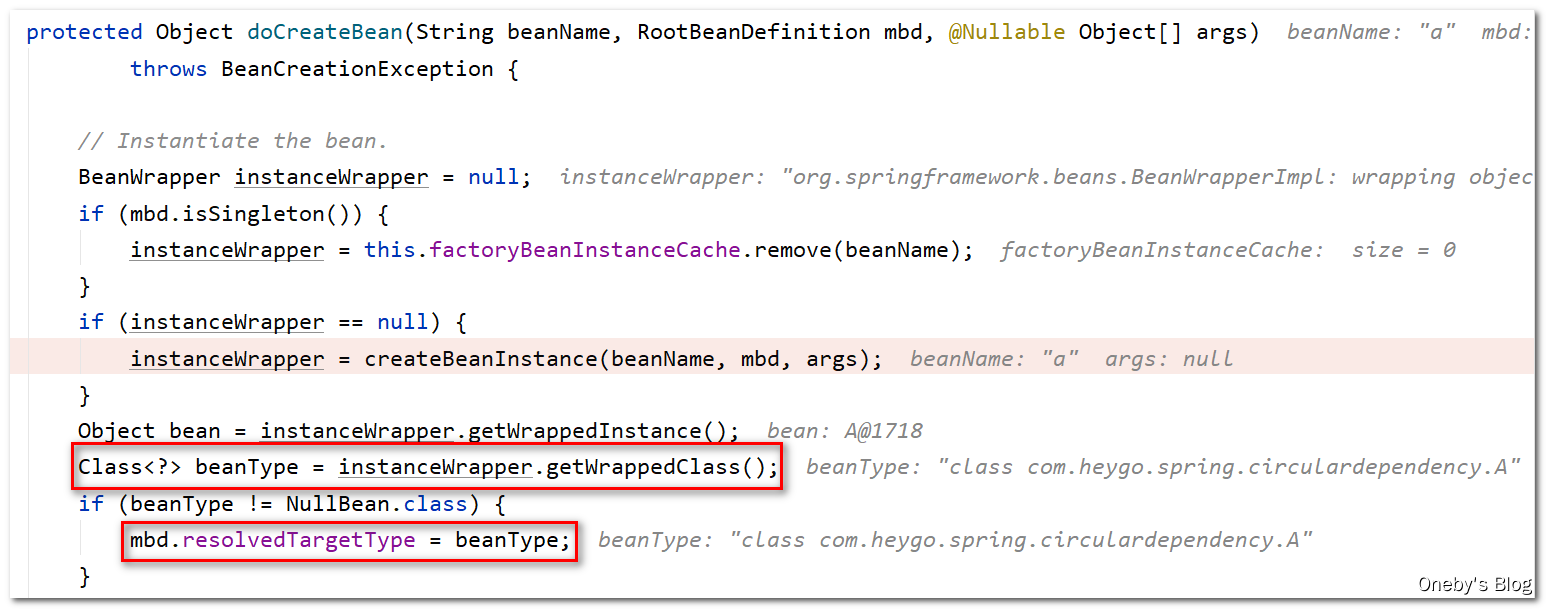
执行 BeanPostProcessor:
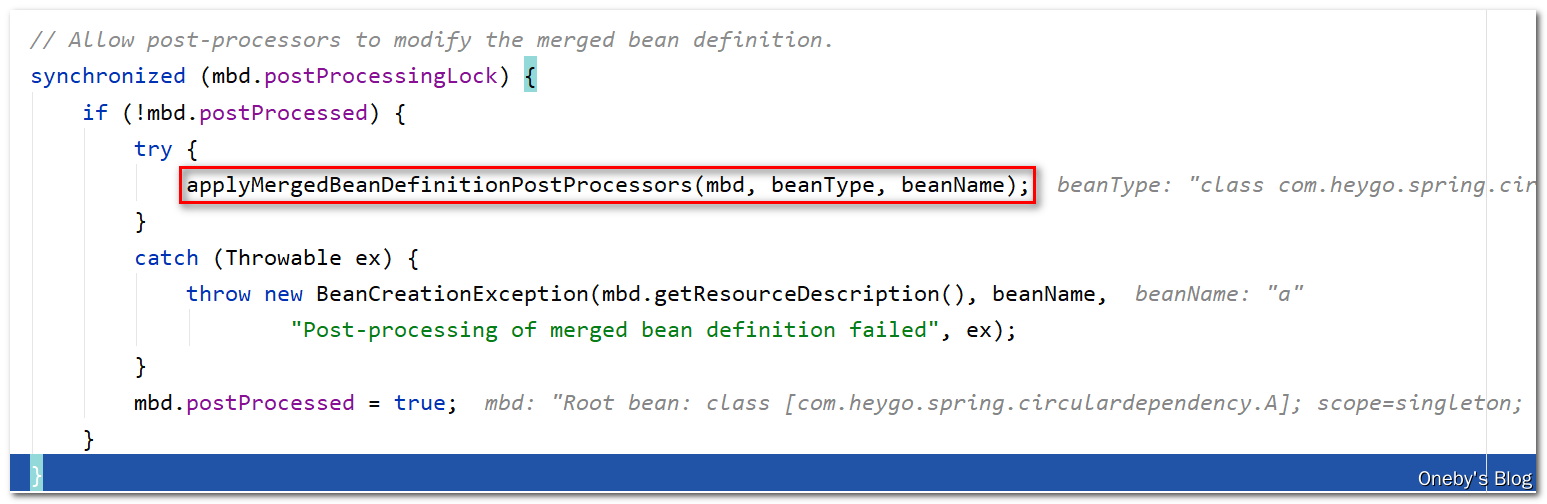
如果该 bean 是单例 bean(mbd.isSingleton()),并且允许循环依赖(this.allowCircularReferences),并且当前 bean 正在创建过程中(isSingletonCurrentlyInCreation(beanName)),那么就允许提前暴露该单例 bean(earlySingletonExposure = true),则会执行 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)) 方法将该 bean 放到三级缓存 singletonFactories 中
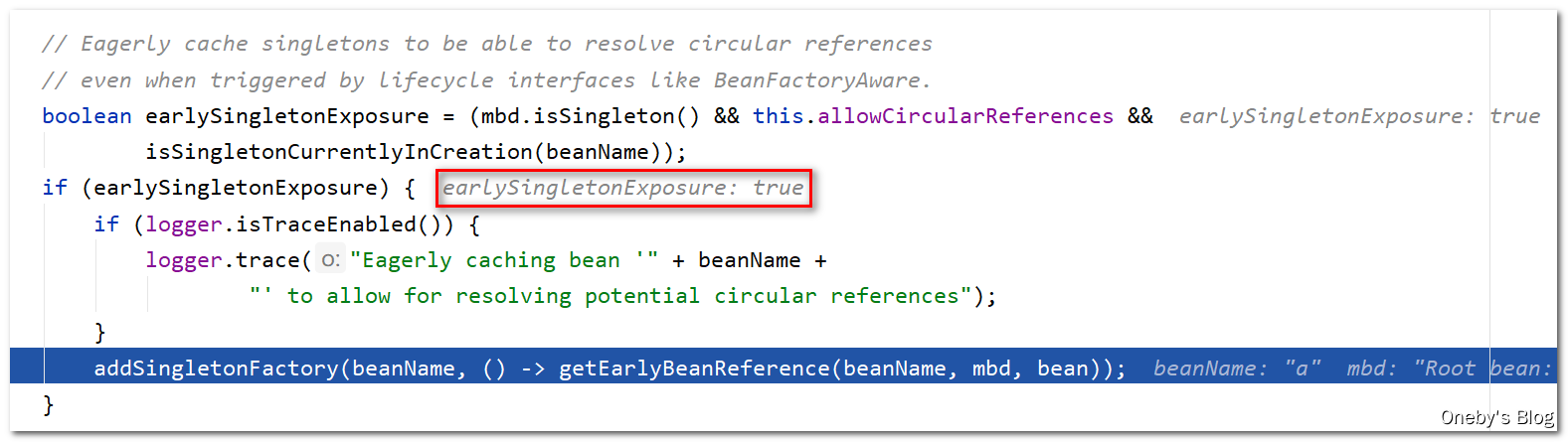
进入 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)) 方法:
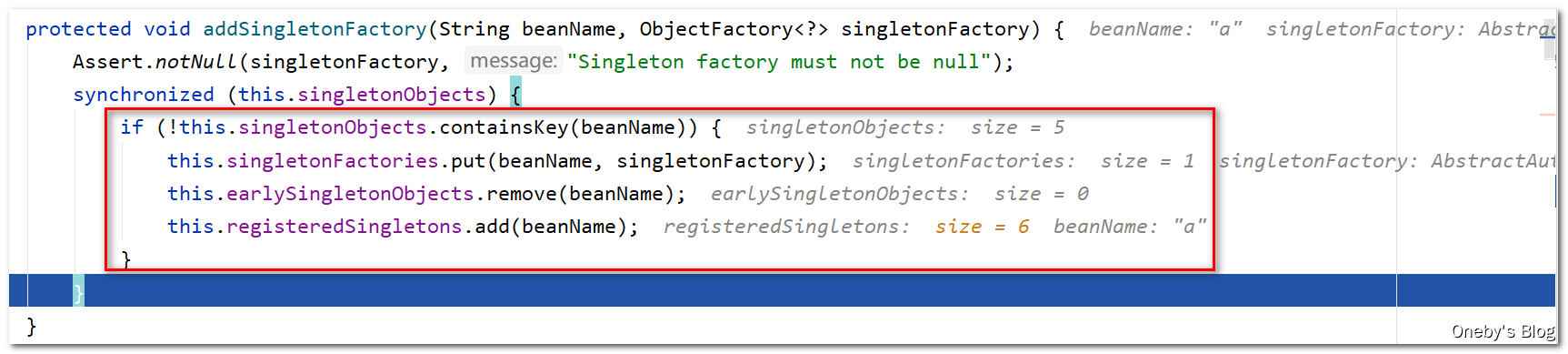
首先去一级缓存 singletonObjects 中找一下有没有 beanA,肯定没有啦~然后将 beanA 添加到三级缓存 singletonFactories 中,并将 beanA 从二级缓存 earlySingletonObjects 中移除(虽然此时的二级缓存当中没有beanA),最后将 beanName 添加至 registeredSingletons 中,表示该 bean 实例已经被注册
2、beanA 的属性填充——初始化
回到 doCreateBean(beanName, mbdToUse, args) 方法中:
接着回到 doCreateBean(beanName, mbdToUse, args) 方法中,需要执行 populateBean(beanName, mbd, instanceWrapper) 方法对 beanA 中的属性进行填充
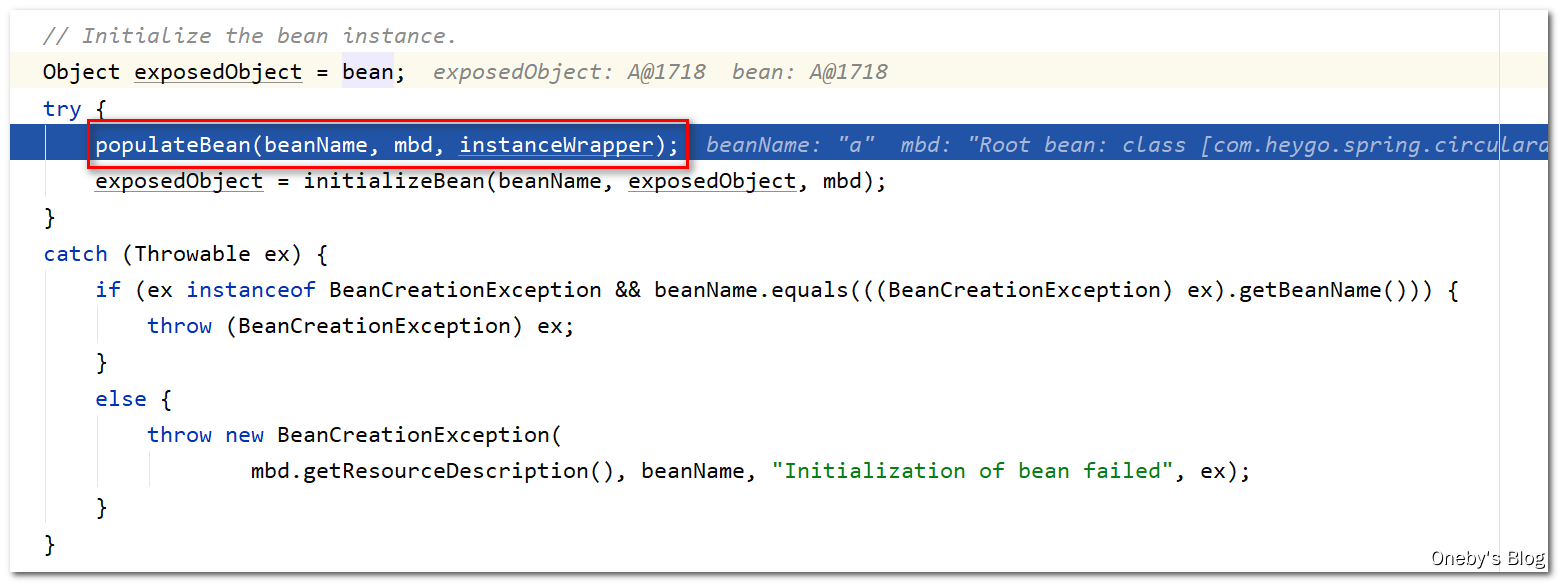
进入 populateBean(beanName, mbd, instanceWrapper) 方法:
反射获取 beanA 的属性列表
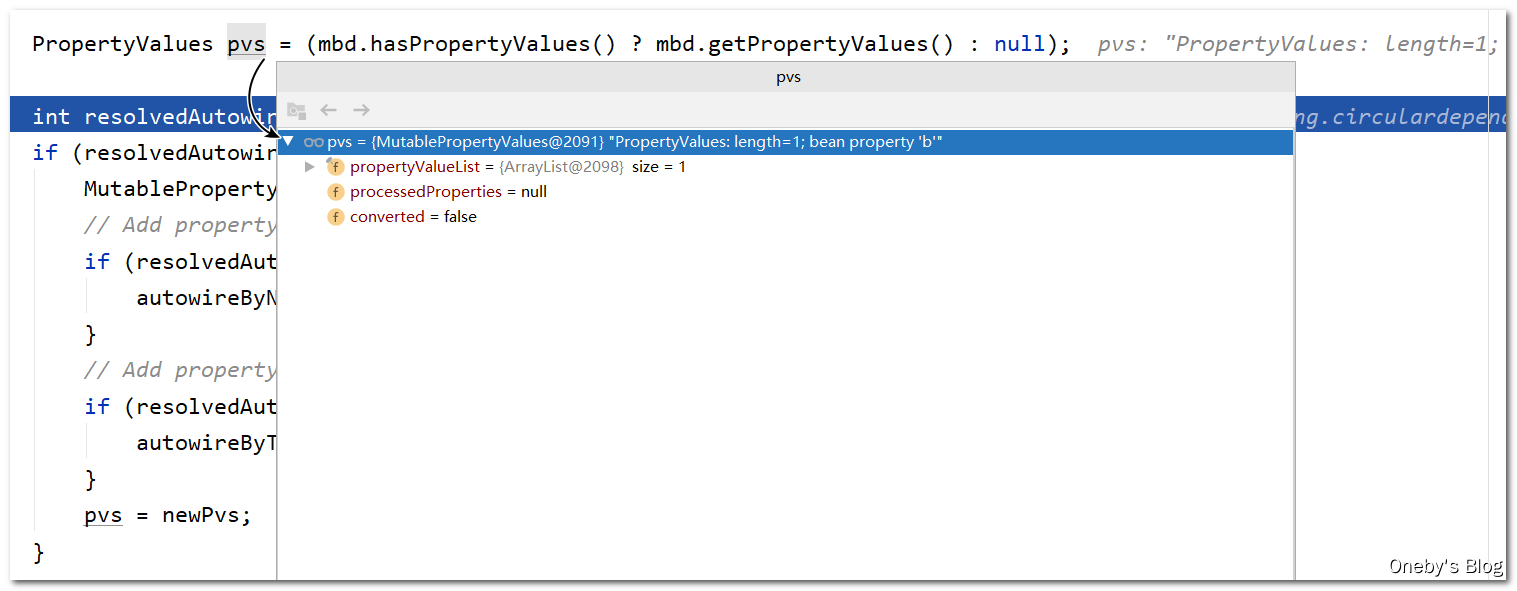
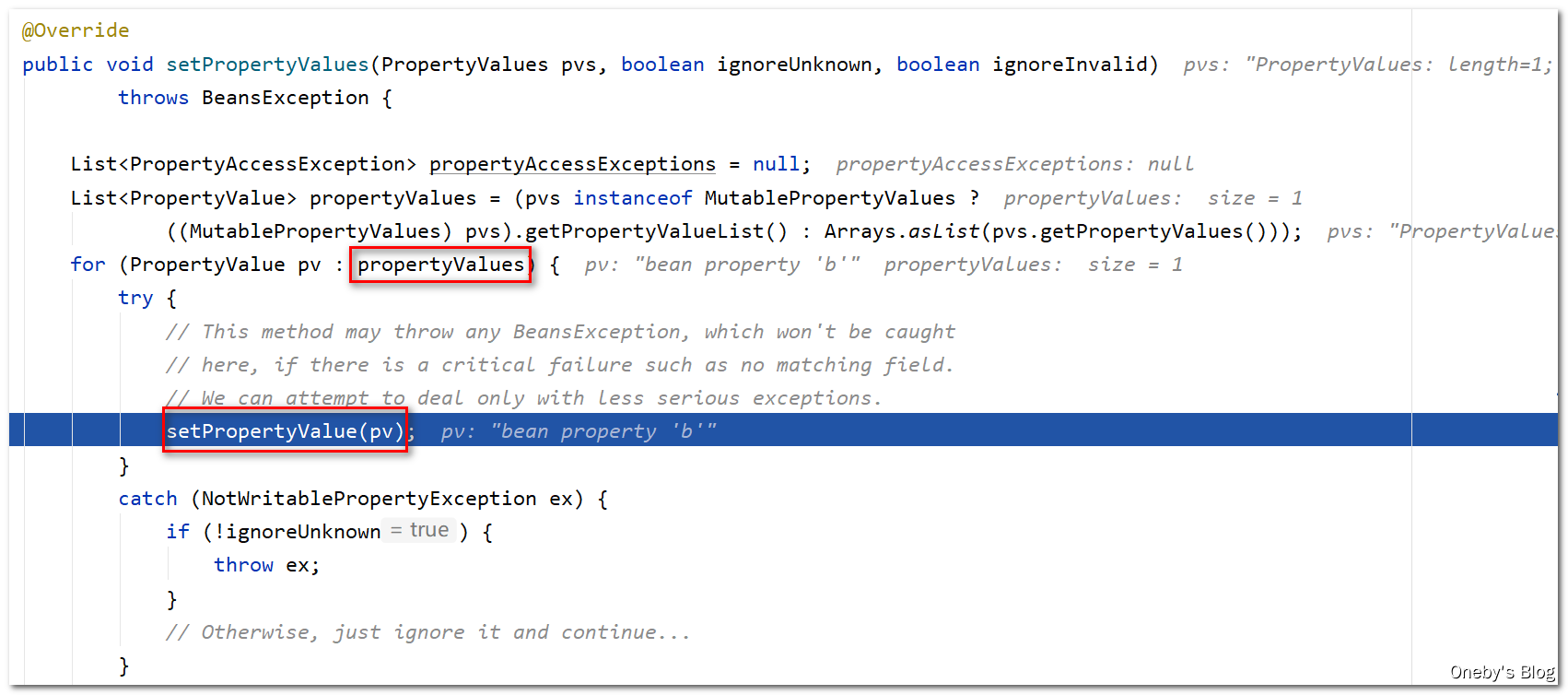
执行 applyPropertyValues(beanName, mbd, bw, pvs) 方法完成 beanA 属性的填充
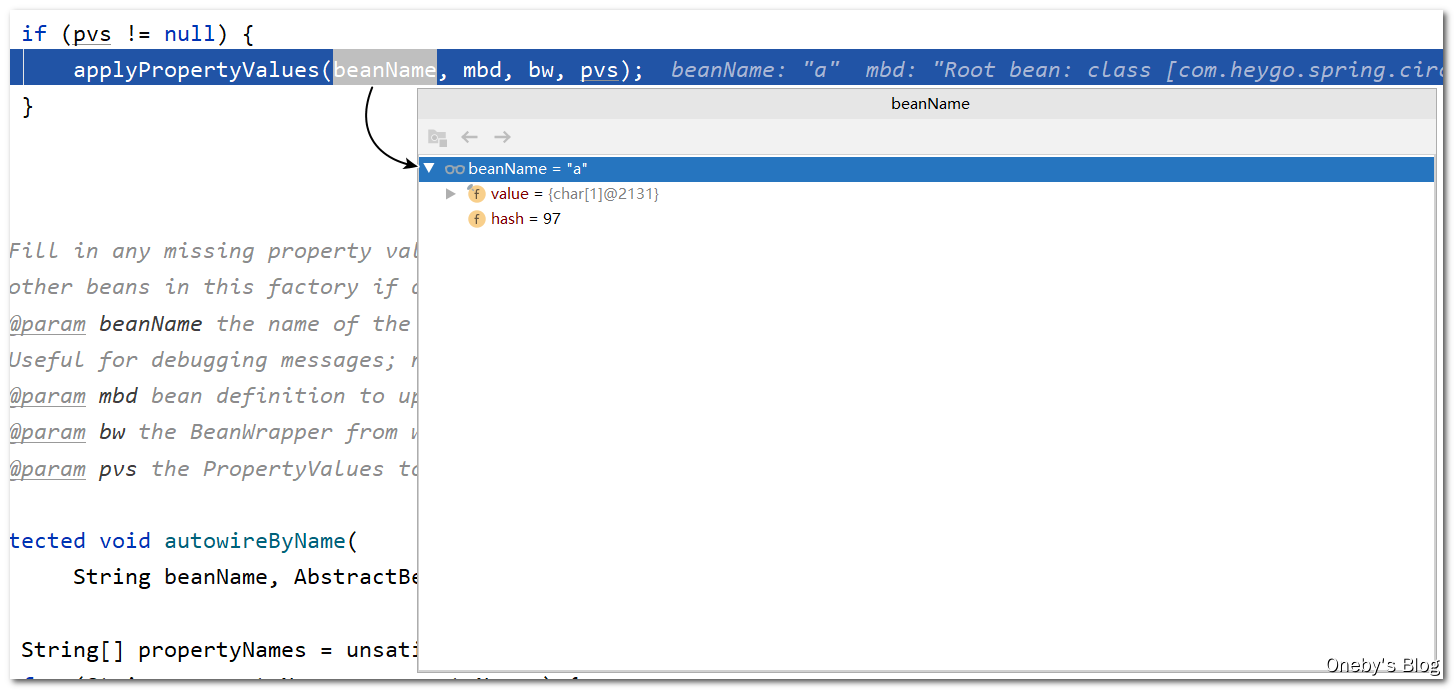
进入 applyPropertyValues(beanName, mbd, bw, pvs) 方法:
取到 beanA 的属性列表,发现有个属性为 b
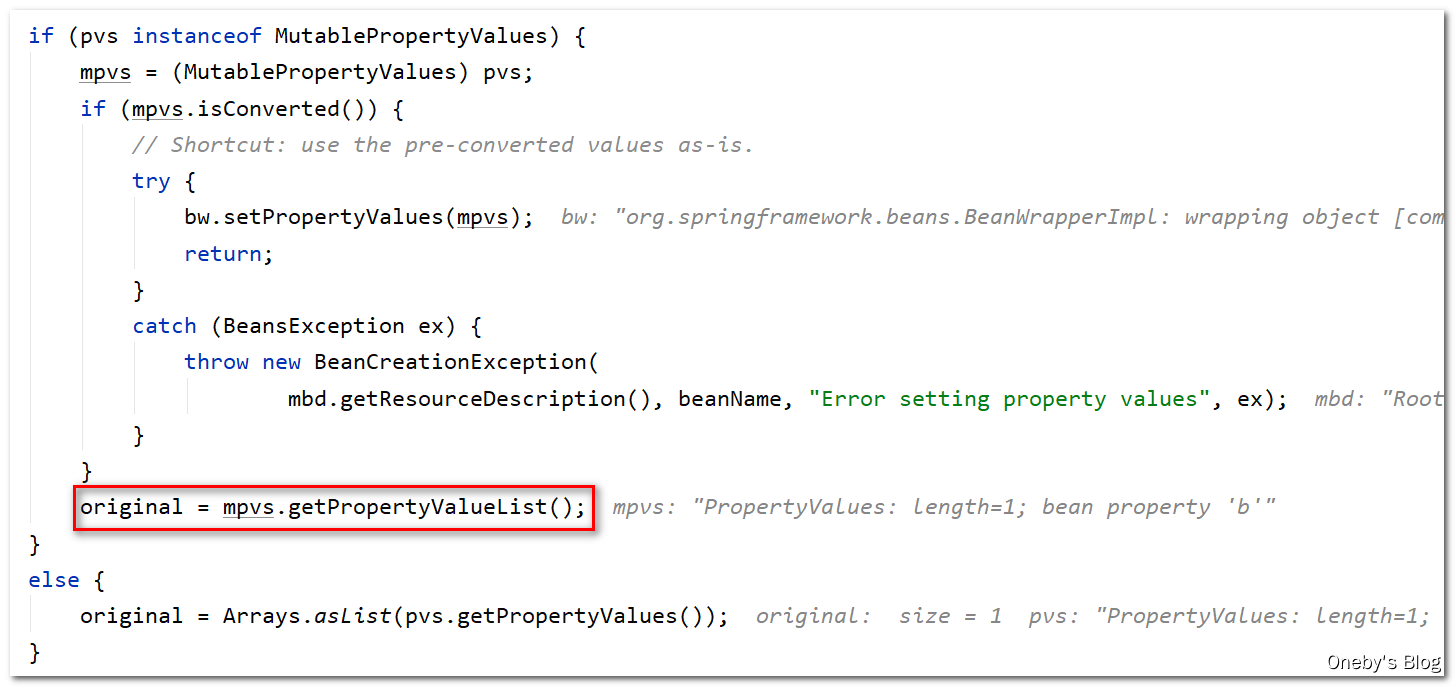
遍历每一个属性,并对每一个属性进行注入,valueResolver.resolveValueIfNecessary(pv, originalValue) 的作用:Given a PropertyValue, return a value, resolving any references to other beans in the factory if necessary.
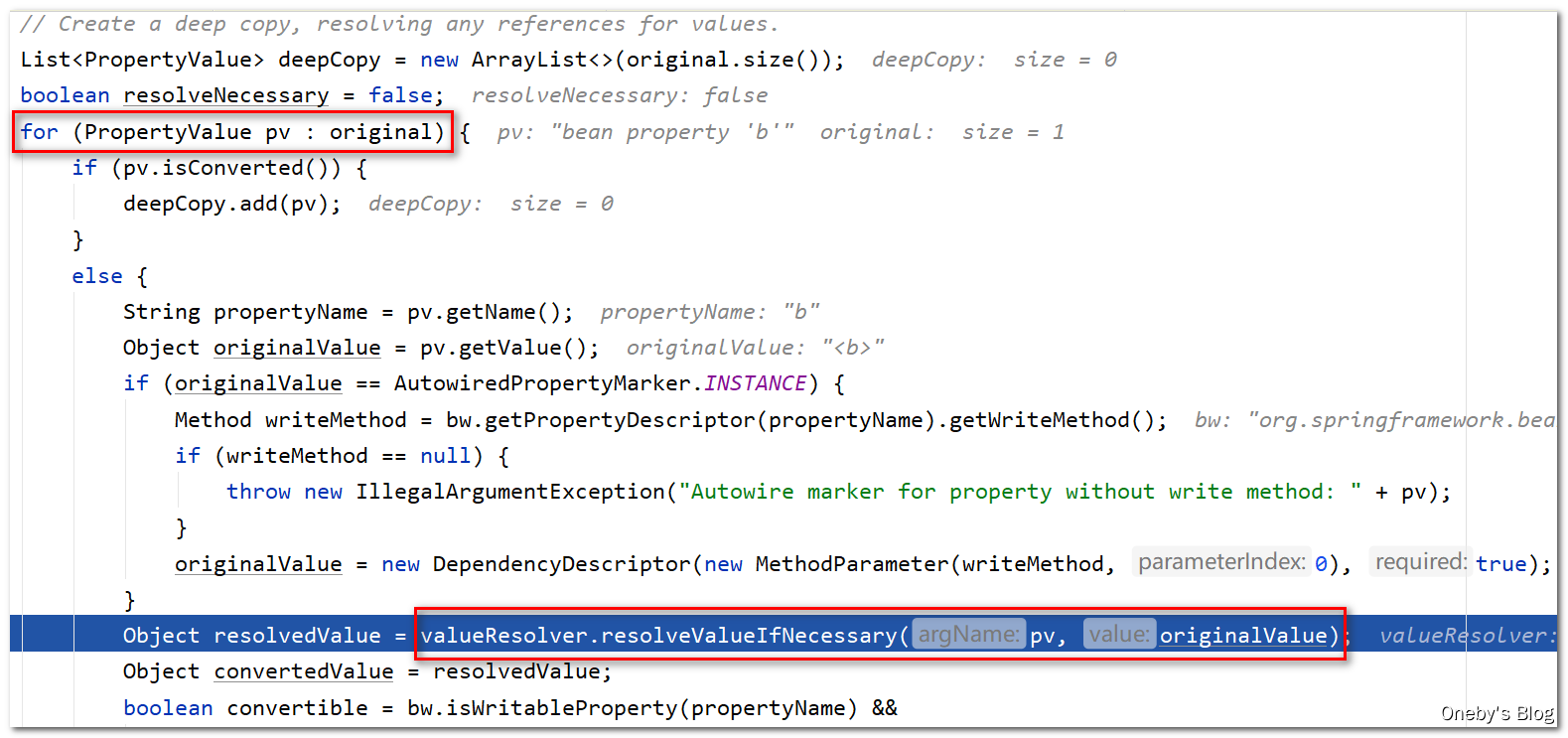
进入 valueResolver.resolveValueIfNecessary(pv, originalValue) 方法:
通过 resolveReference(argName, ref) 解决依赖注入的问题:

进入 resolveReference(argName, ref) 方法:
先获得属性 b 的名称,再通过 this.beanFactory.getBean(resolvedName) 方法获取 beanB 的实例
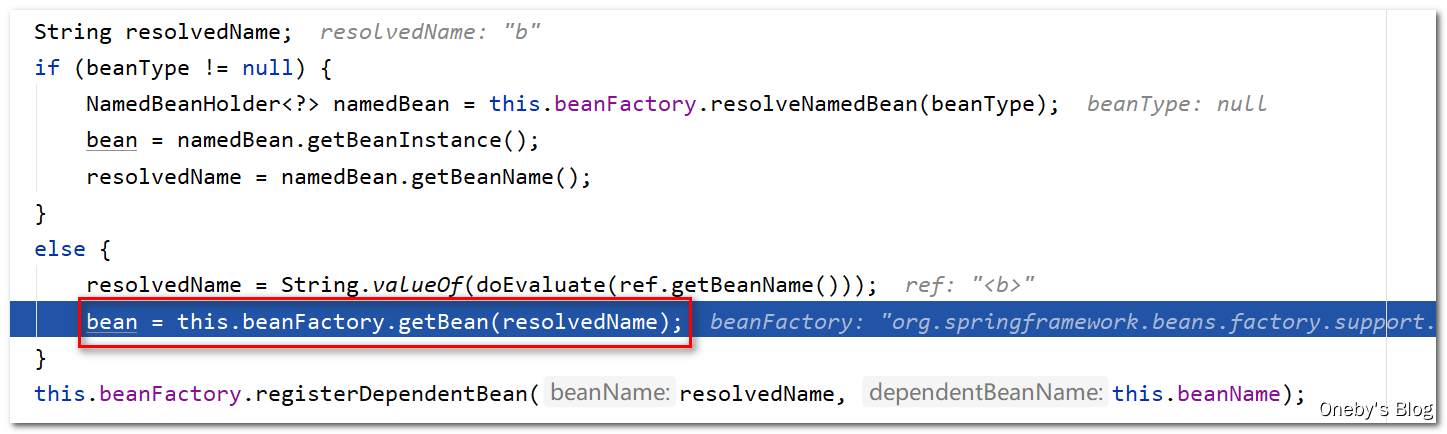
3、beanB 的实例化
进入 this.beanFactory.getBean(resolvedName) 方法:
哦,这熟悉的 doGetBean(name, null, null, false) 方法:

再次执行 doGetBean(name, null, null, false) 方法:
beanB 还没有实例化,因此 getSingleton(beanName) 方法返回 null
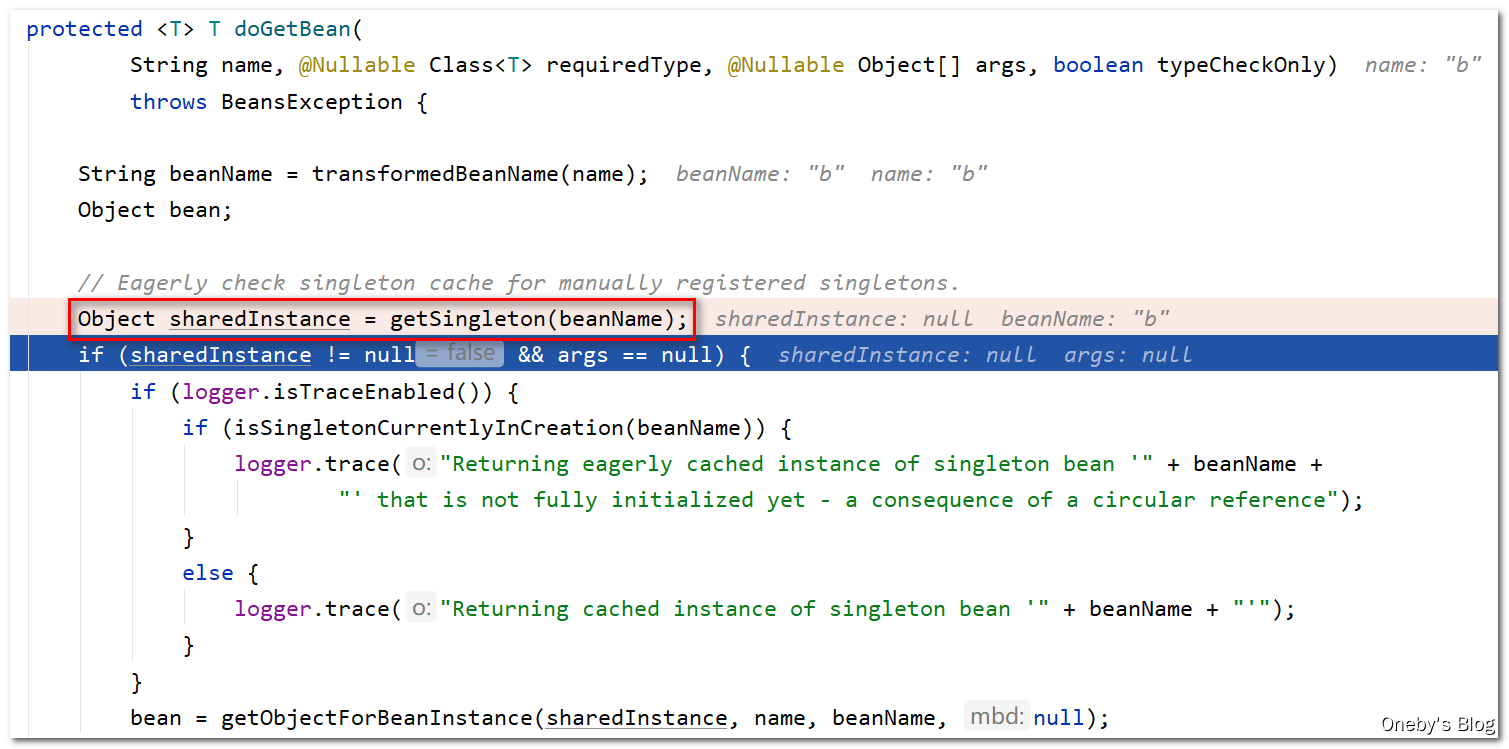
又来到了这个熟悉的地方,先尝试获取 beanB 实例,获取不到就执行 createBean() 的操作
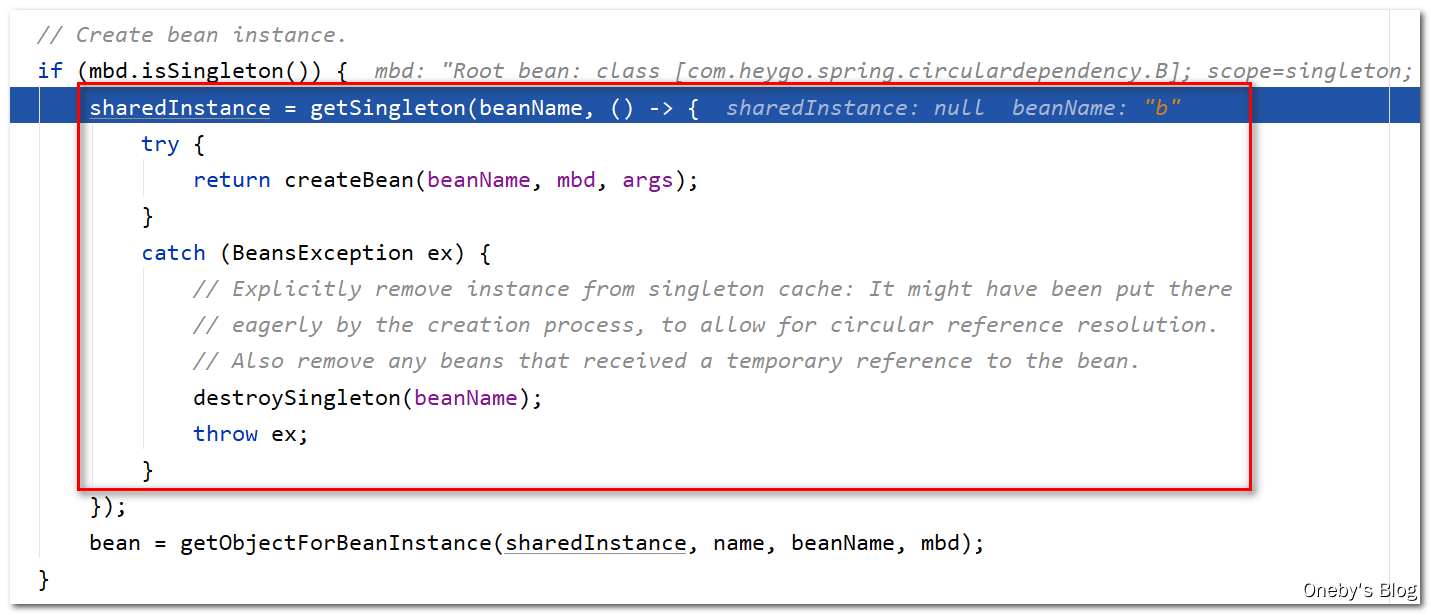
进入 getSingleton(beanName, () -> {... } 方法:
首先尝试从一级缓存 singletonObjects 中获取 beanB,那肯定是获取不到的呀
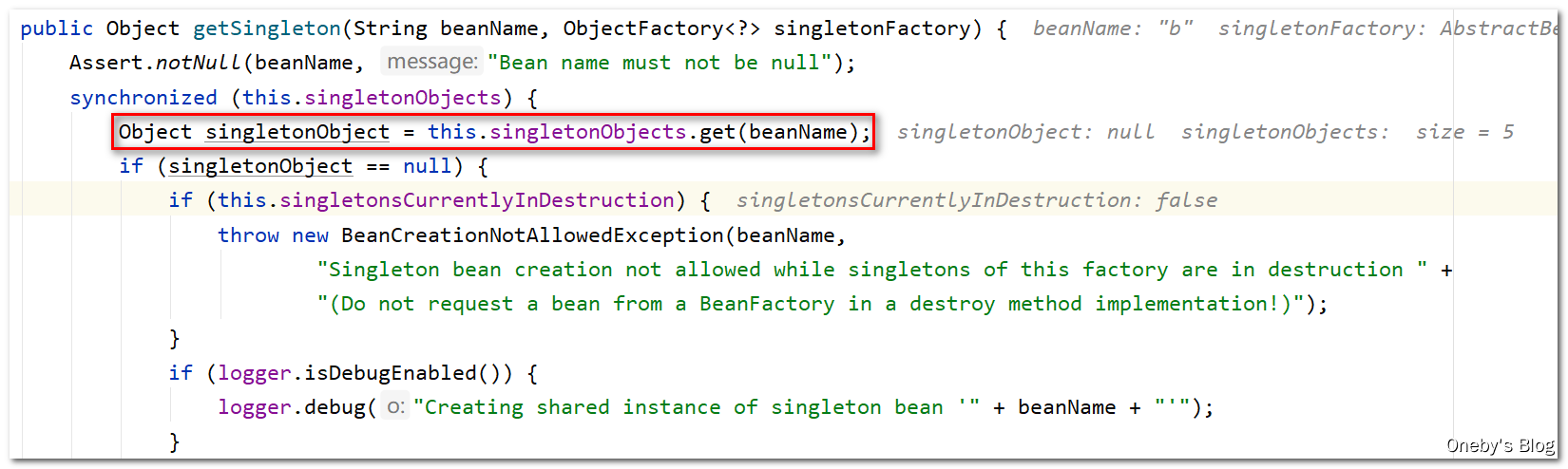
然后就调用 singletonFactory.getObject() 创建 beanB
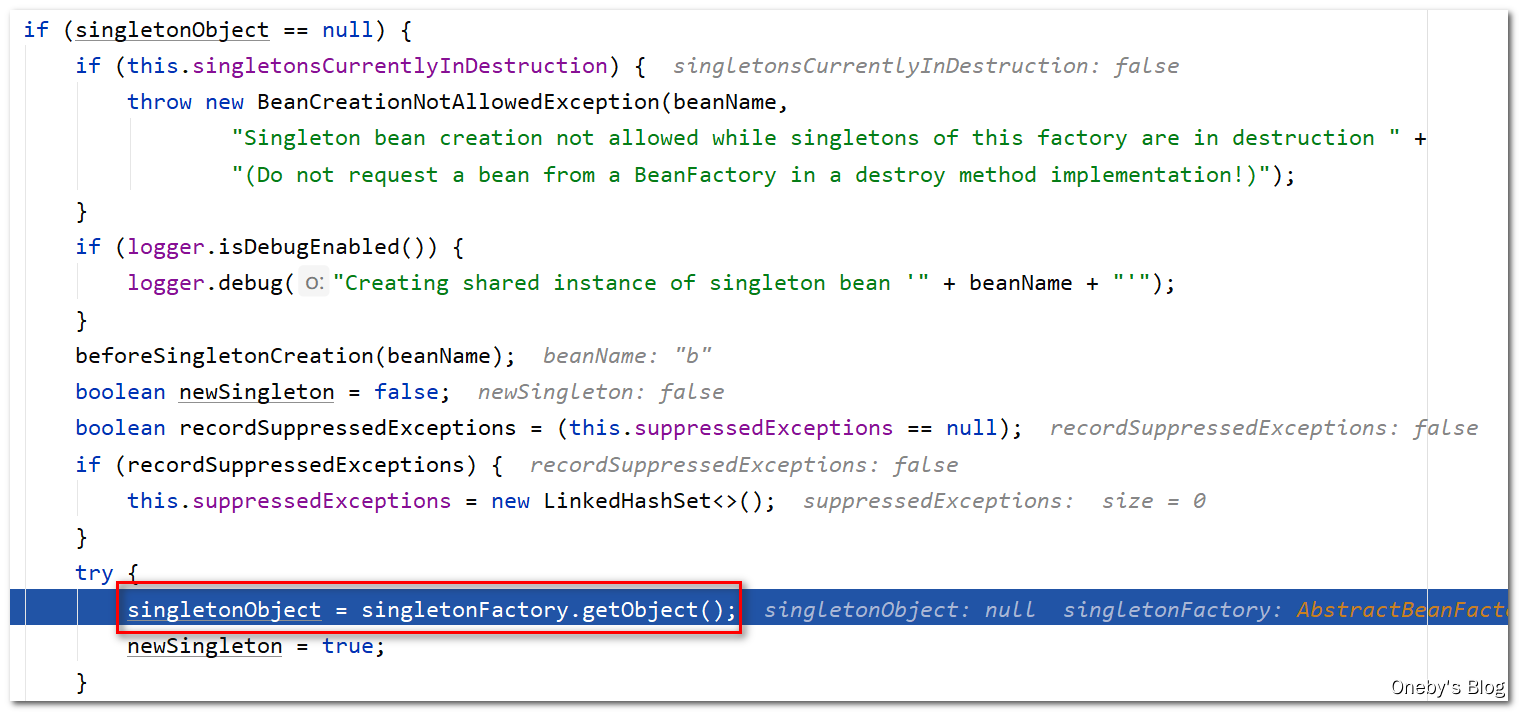
进入 createBean(beanName, mbd, args) 方法:
获取到 beanB 的类型为 com.heygo.spring.circulardependency.B
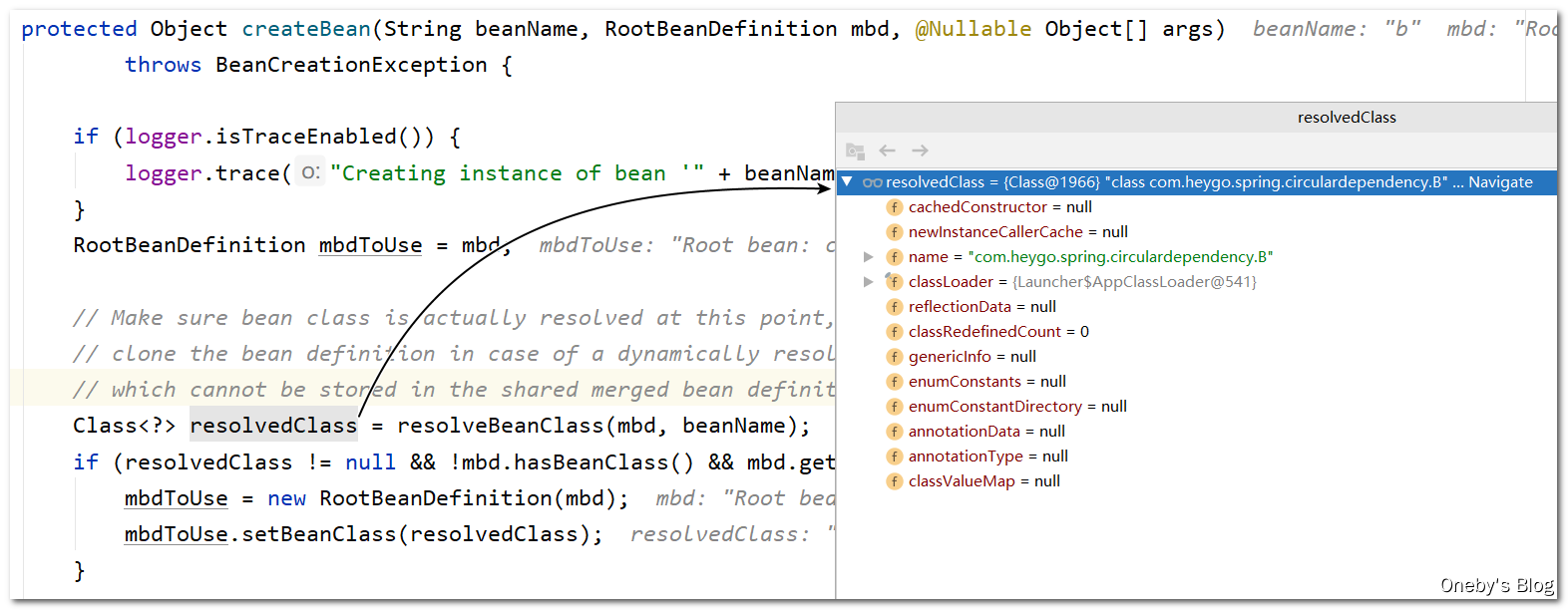
之前创建 beanA 的时候没有看到,现在看到挺有趣的:Give BeanPostProcessors a chance to return a proxy instead of the target bean instance. 也就是说我们可以通过 BeanPostProcessors 返回 bean 的代理,而非 bean 本身。然后喜闻乐见,又来到了 doCreateBean(beanName, mbdToUse, args) 环节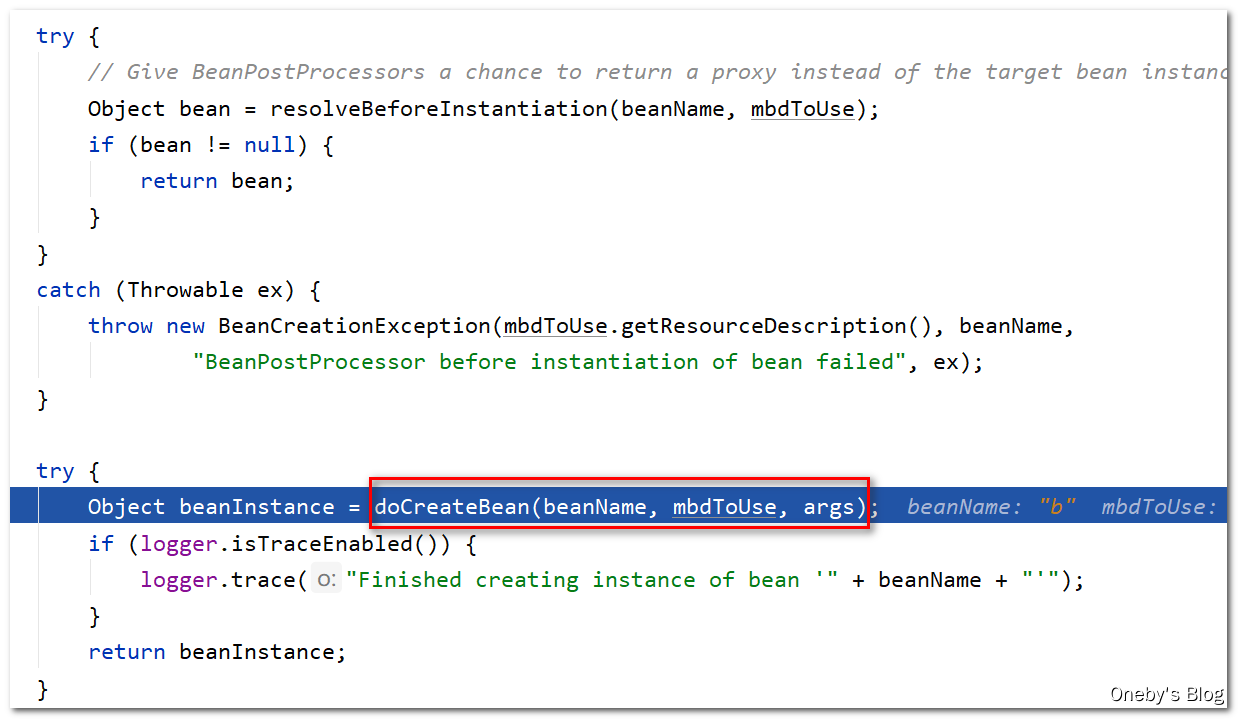
进入 doCreateBean(beanName, mbdToUse, args) 方法:
老样子,创建 beanB 对应的 BeanWrapper instanceWrapper
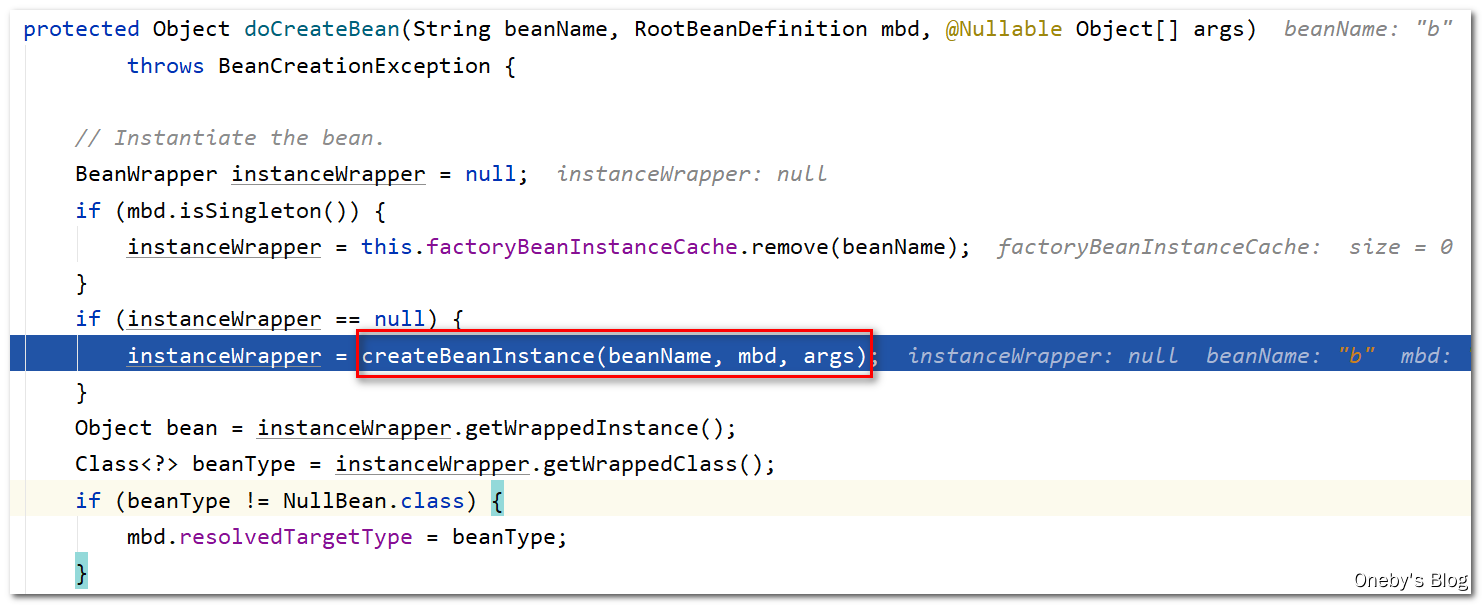
进入 createBeanInstance(beanName, mbd, args) 方法:
调用 instantiateBean(beanName, mbd) 创建 beanWrapper
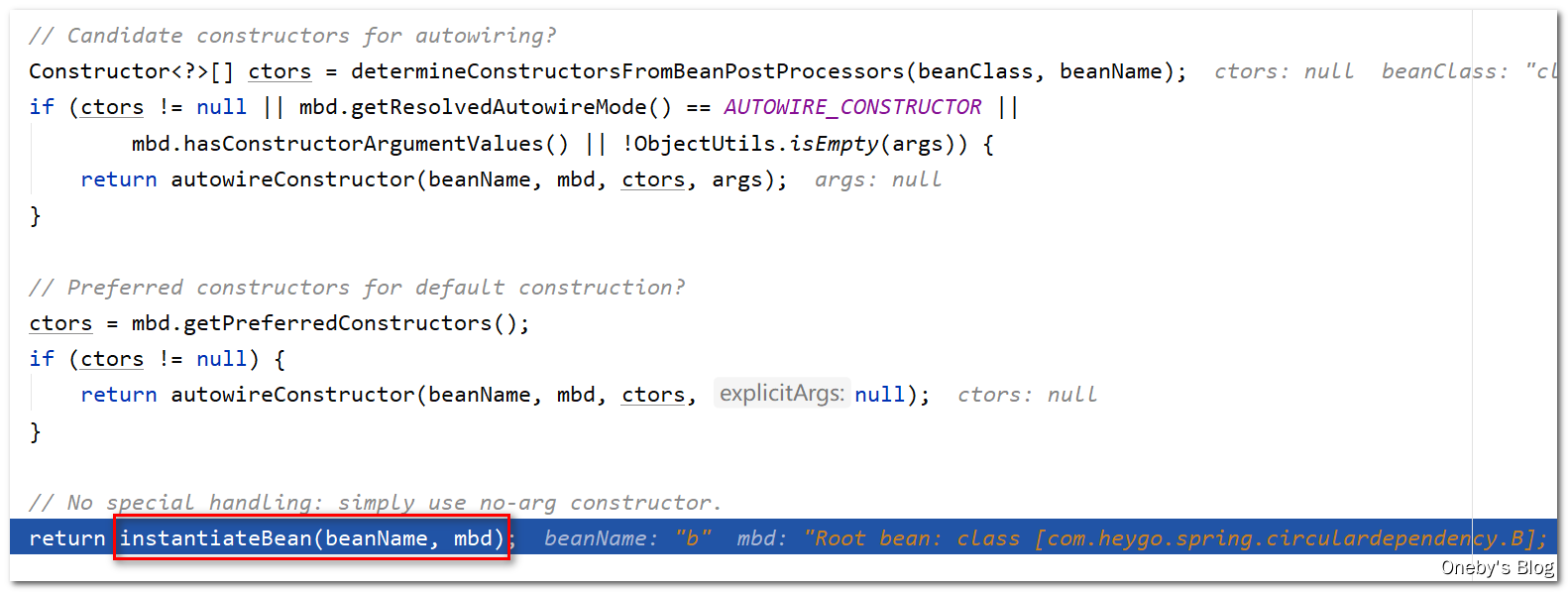
进入 instantiateBean(beanName, mbd) 方法:
调用 getInstantiationStrategy().instantiate(mbd, beanName, this) 创建 beanWrapper
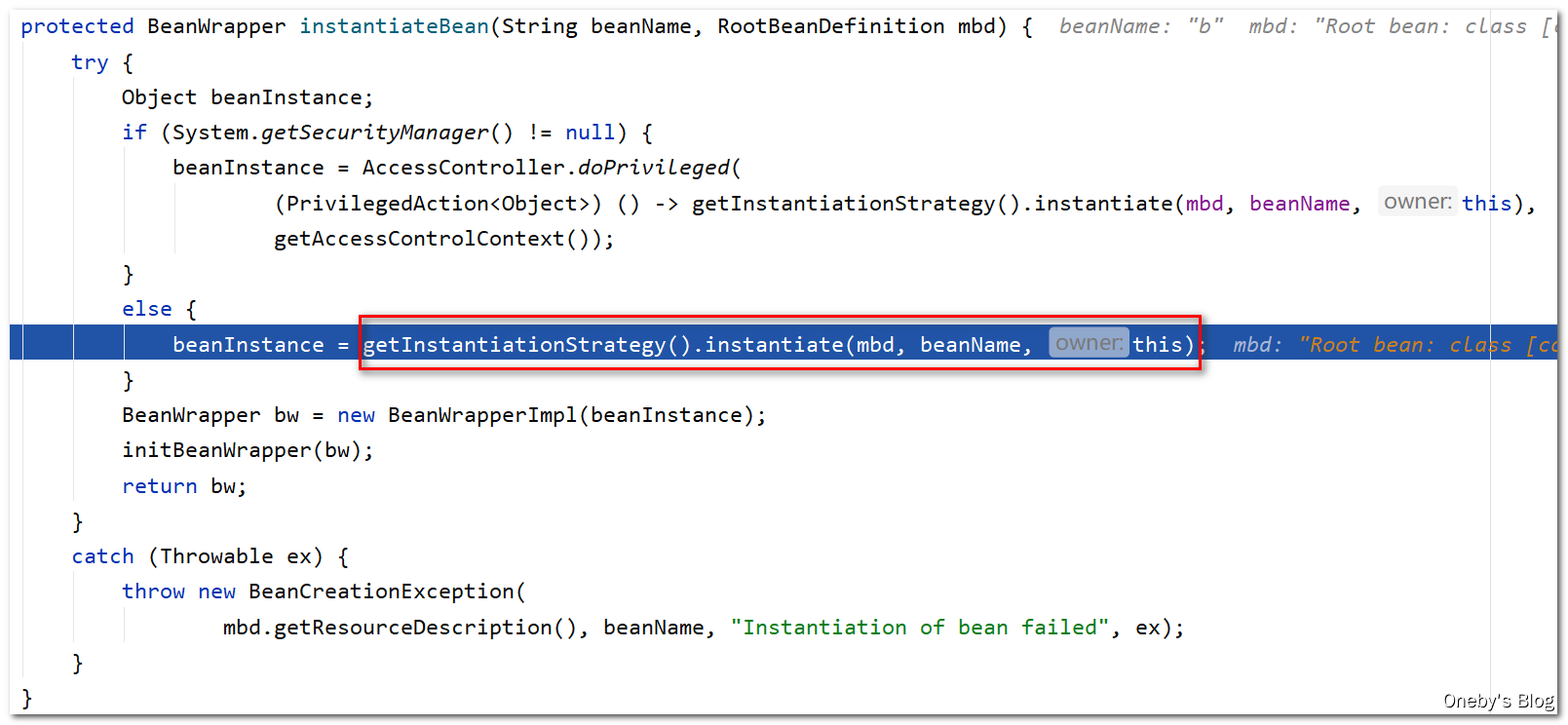
进入 getInstantiationStrategy().instantiate(mbd, beanName, this) 方法:
获取 com.heygo.spring.circulardependency.B 的构造器,并将构造器信息记录在 bd.resolvedConstructorOrFactoryMethod 字段中
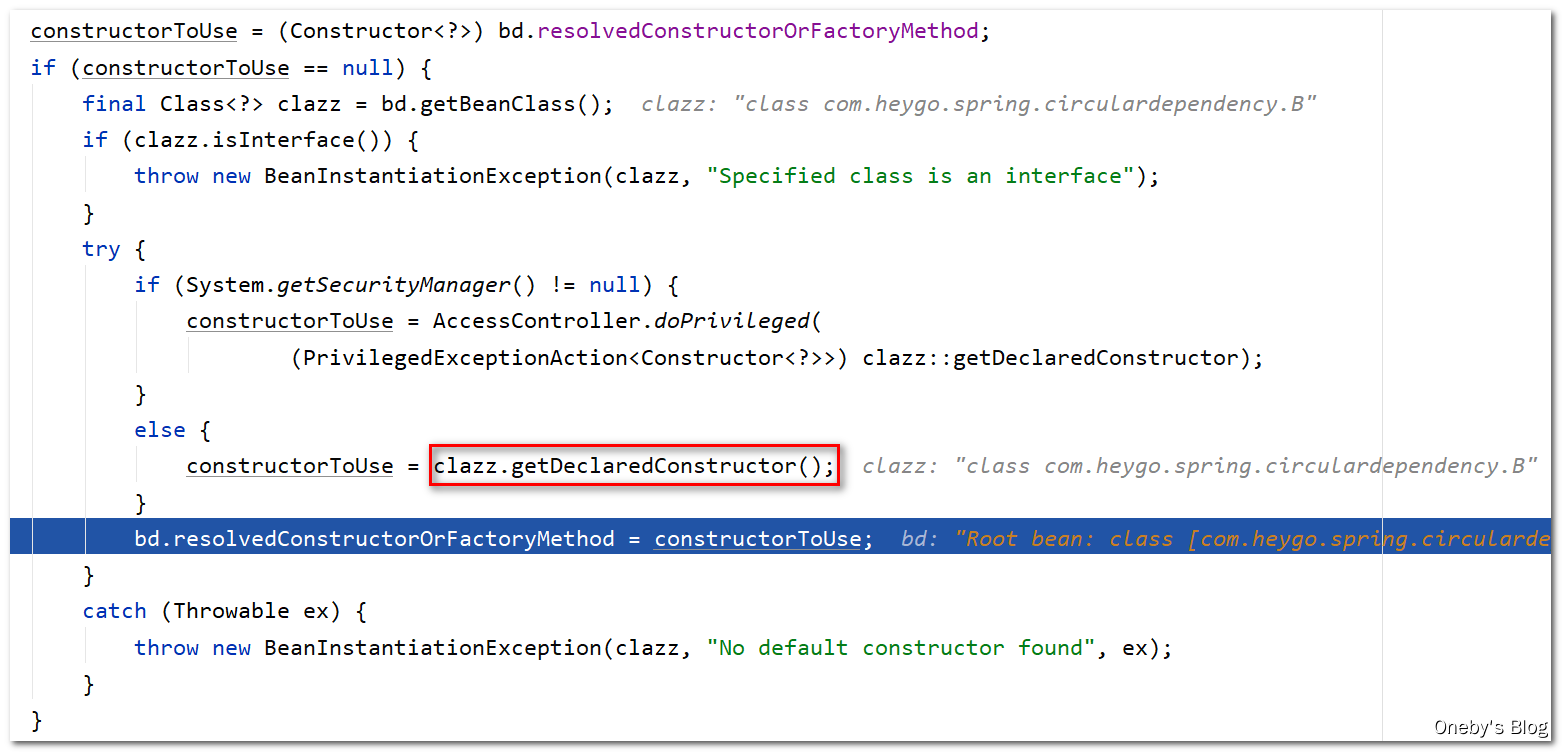
调用 BeanUtils.instantiateClass(constructorToUse) 方法创建 beanB 实例:
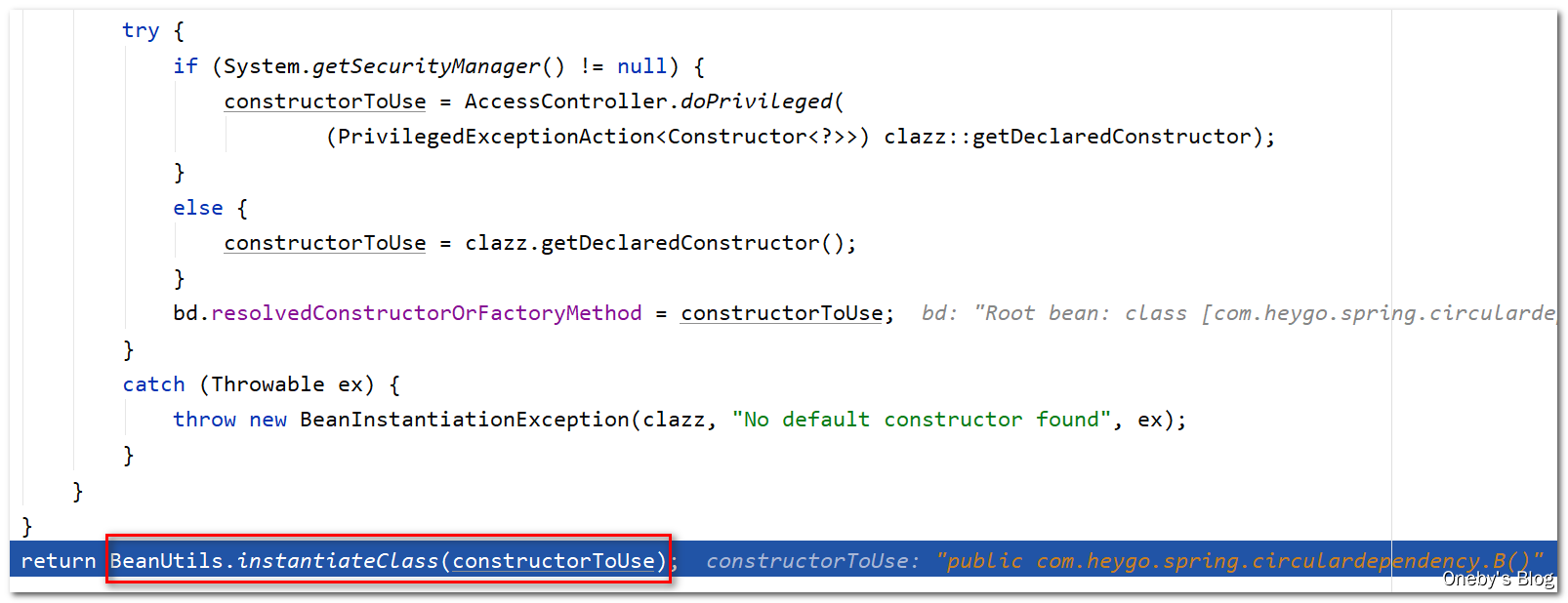
进入 BeanUtils.instantiateClass(constructorToUse) 方法:
通过调用 B 类的构造器创建 beanB 实例,此时控制台会输出:【B created success】
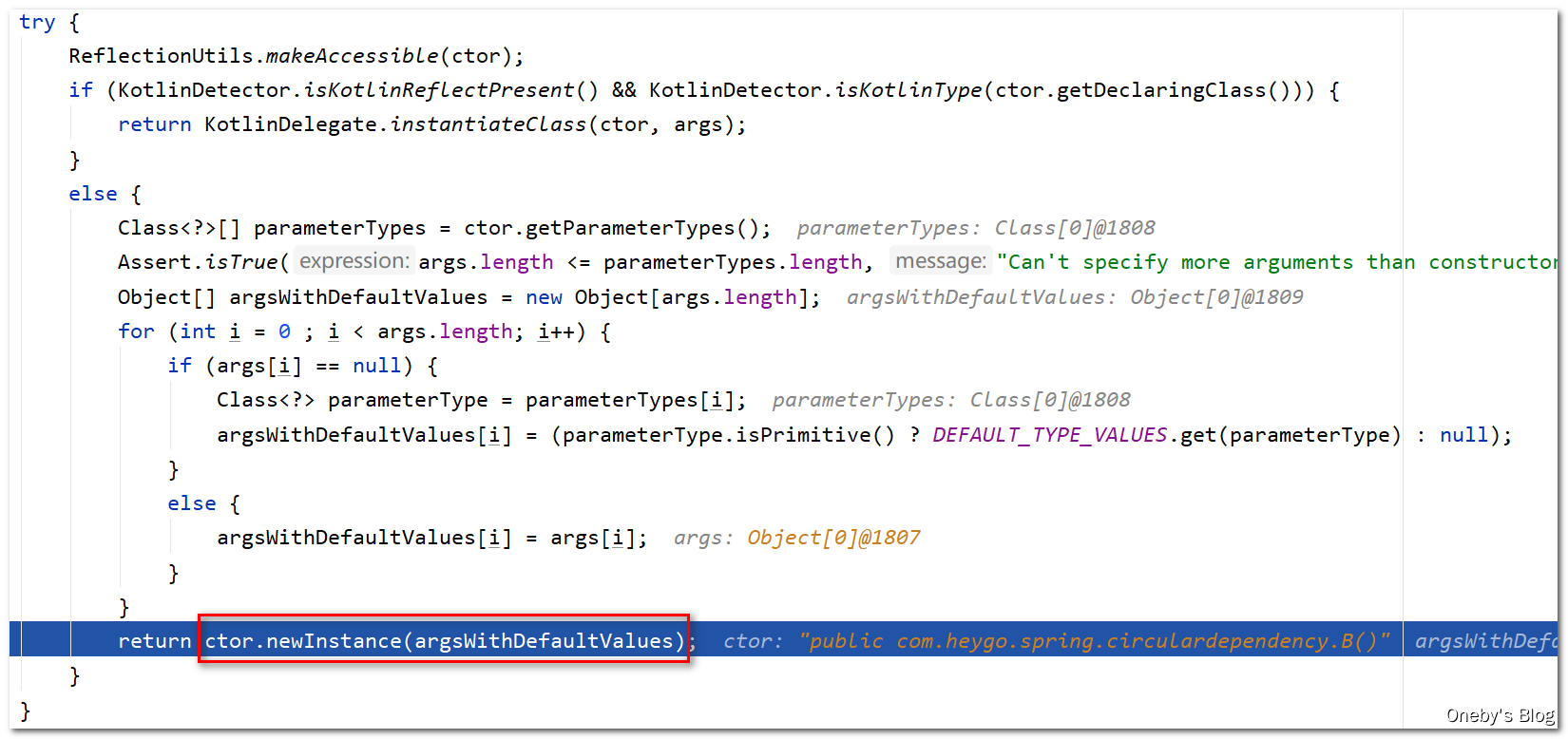
回到 instantiateBean(beanName, mbd) 方法中:
在 instantiateBean(beanName, mbd) 方法中得到创建好的 beanB 实例,并将其丢进 beanWrapper 中,封装为 BeanWrapper bw 对象
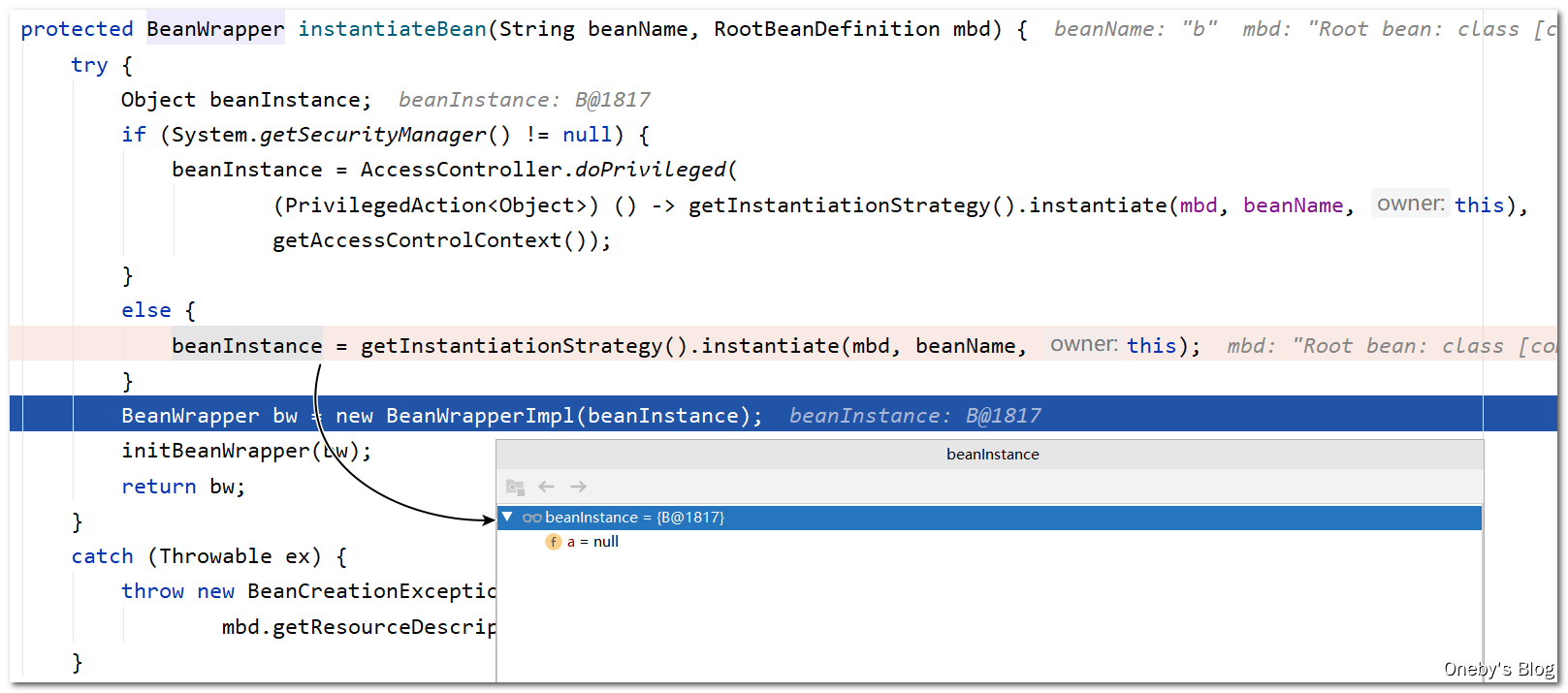
回到 doCreateBean(beanName, mbdToUse, args) 方法中:
createBeanInstance(beanName, mbd, args)方法将返回包装着 beanB 的beanWrapper
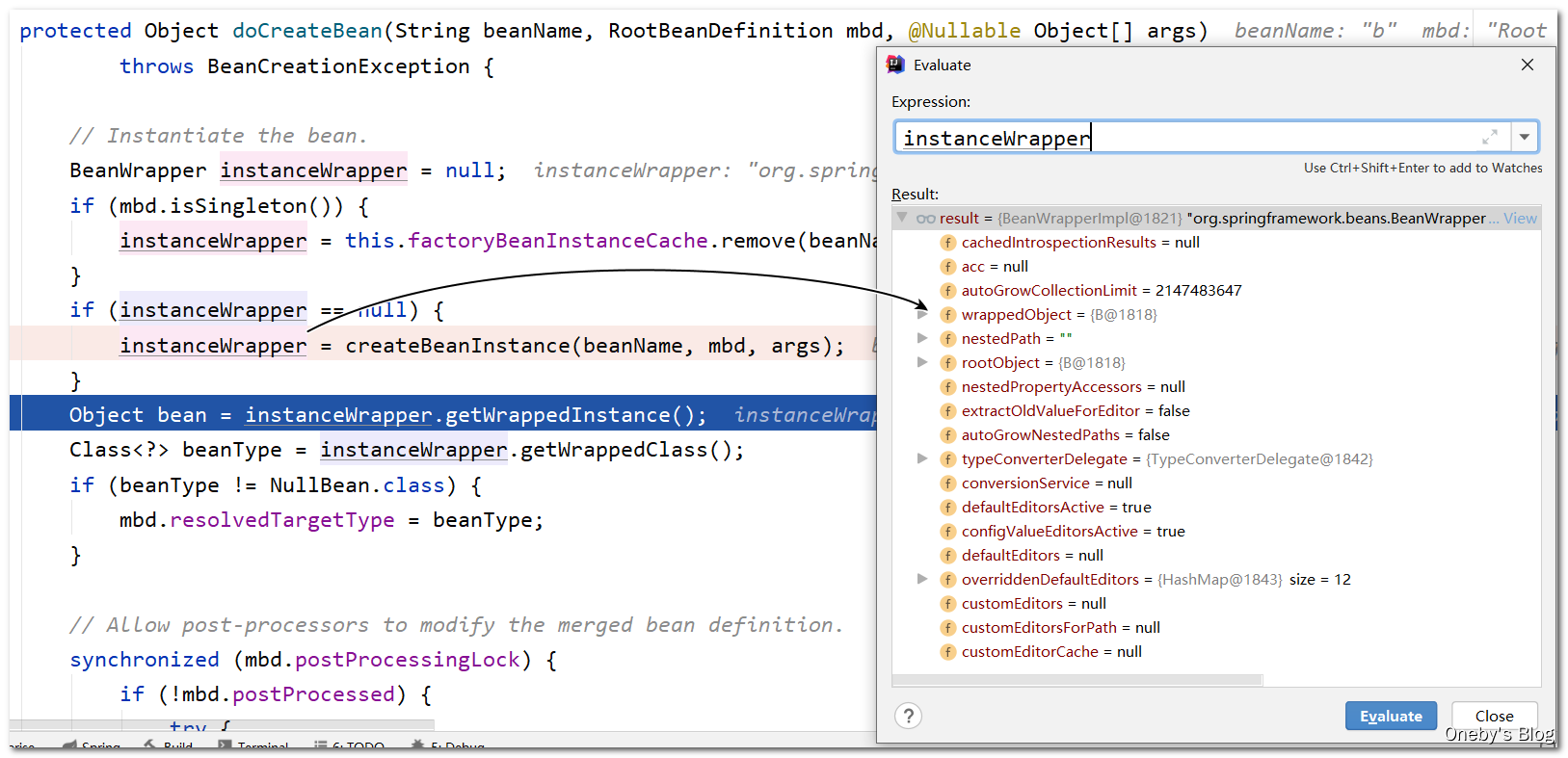
执行 BeanPostProcessor 的处理过程:
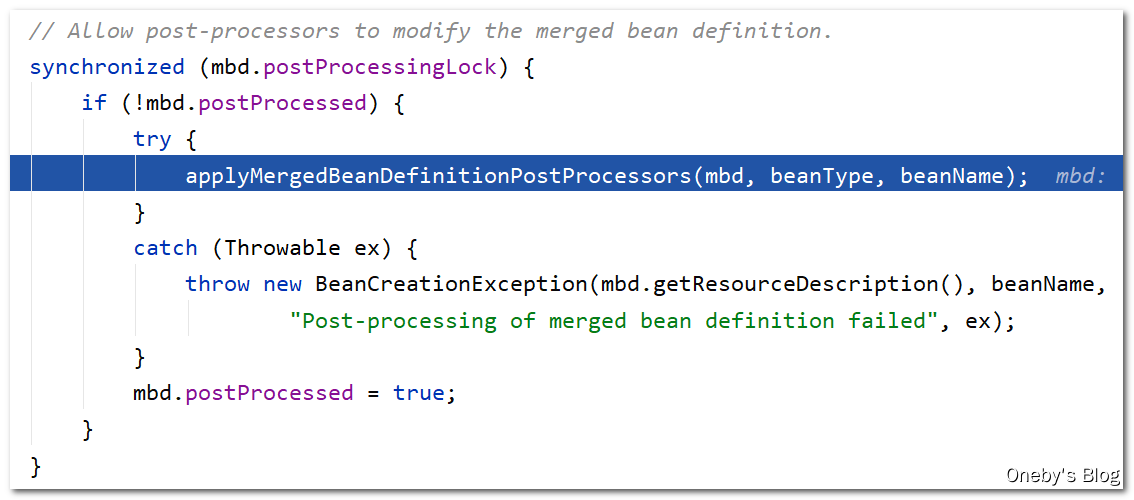
beanB 由于满足单例并且正在被创建,因此 beanB 可以被提前暴露出去(在属性还未初始化的时候可以提前暴露出去),于是执行 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)) 方法将其添加至三级缓存 singletonFactory 中
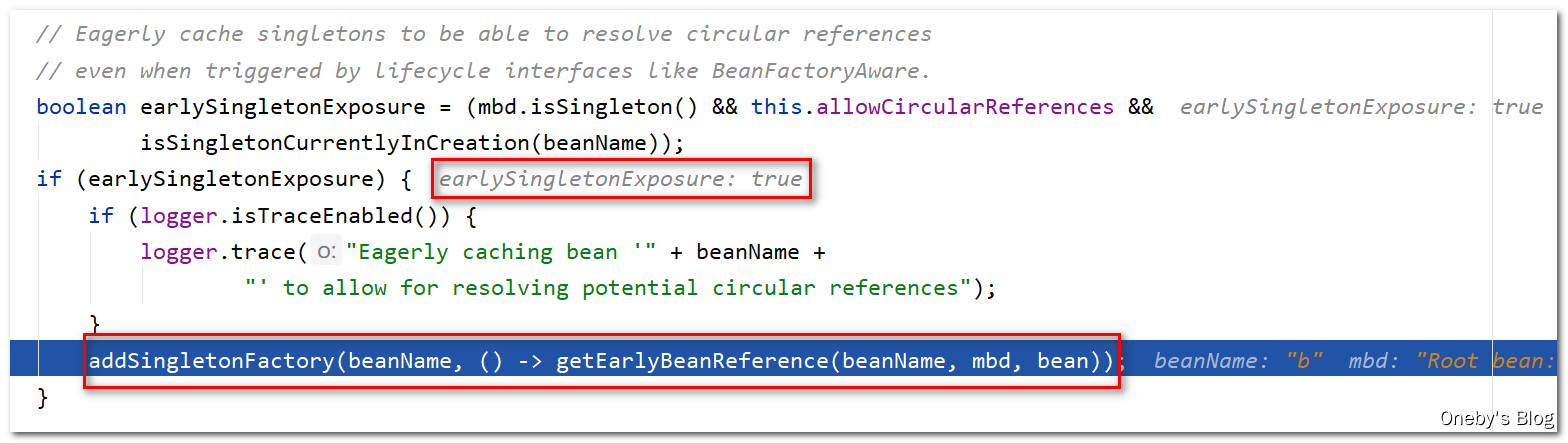
进入 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)) 方法:
将 beanB 实例添加至三级缓存 singletonFactory 中,从二级缓存 earlySingletonObjects 中移除(虽然此时的第二级缓存当中也没有beanB),并注册其 beanName
注:此时第三级缓存有两个值:
- K:beanA,V:beanAFactory的lambda表达式
- K:beanB,V:beanBFactory的lambda表达式
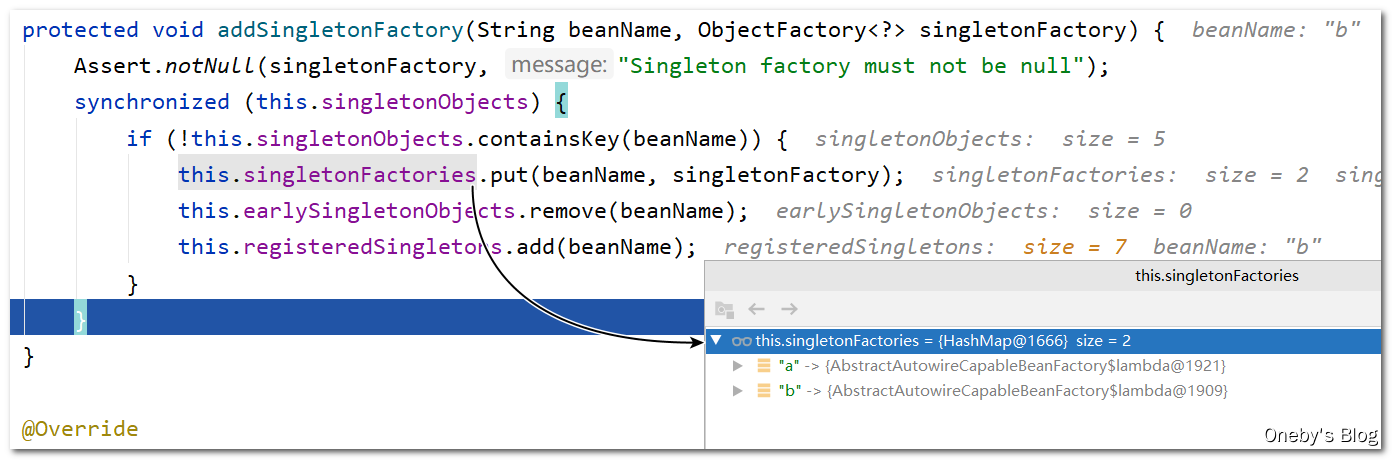
回到 doCreateBean(beanName, mbdToUse, args) 方法中:
执行 populateBean(beanName,mbd,instancewrapper) 方法填充 beanB 的属性
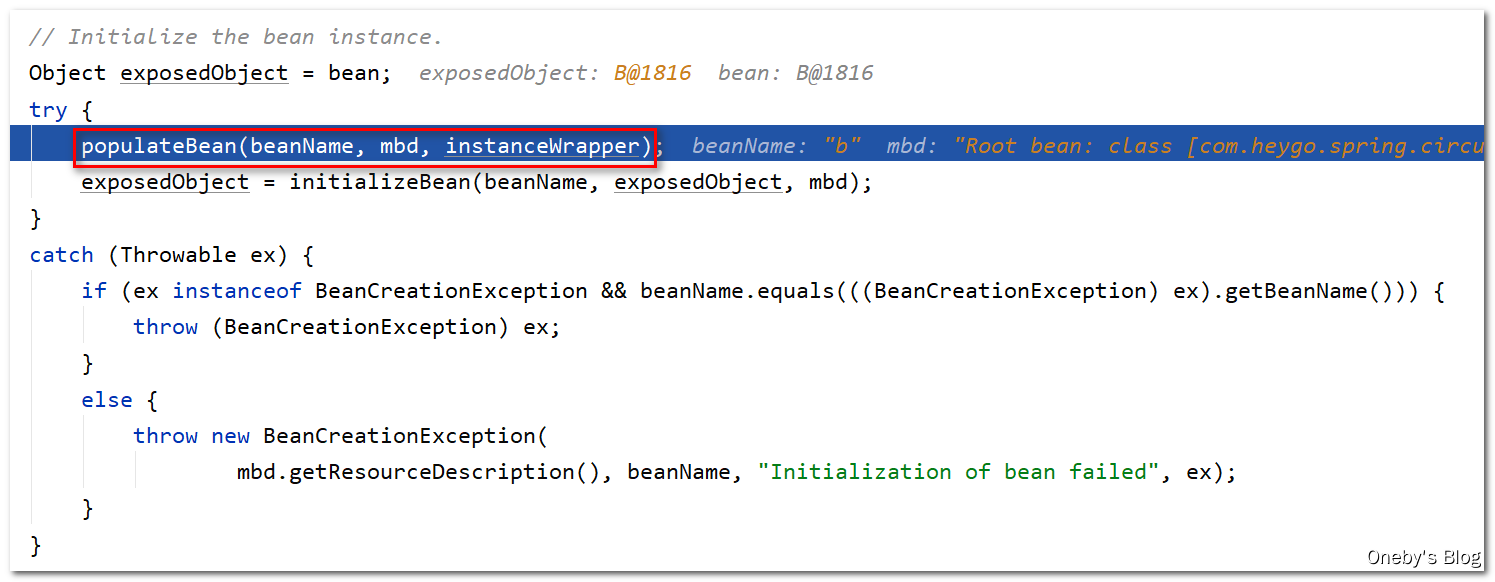
4、beanB 的属性填充——初始化
进入 populateBean(beanName, mbd, instanceWrapper) 方法:
执行 mbd.getPropertyValues() 方法获取 beanB 的属性列表
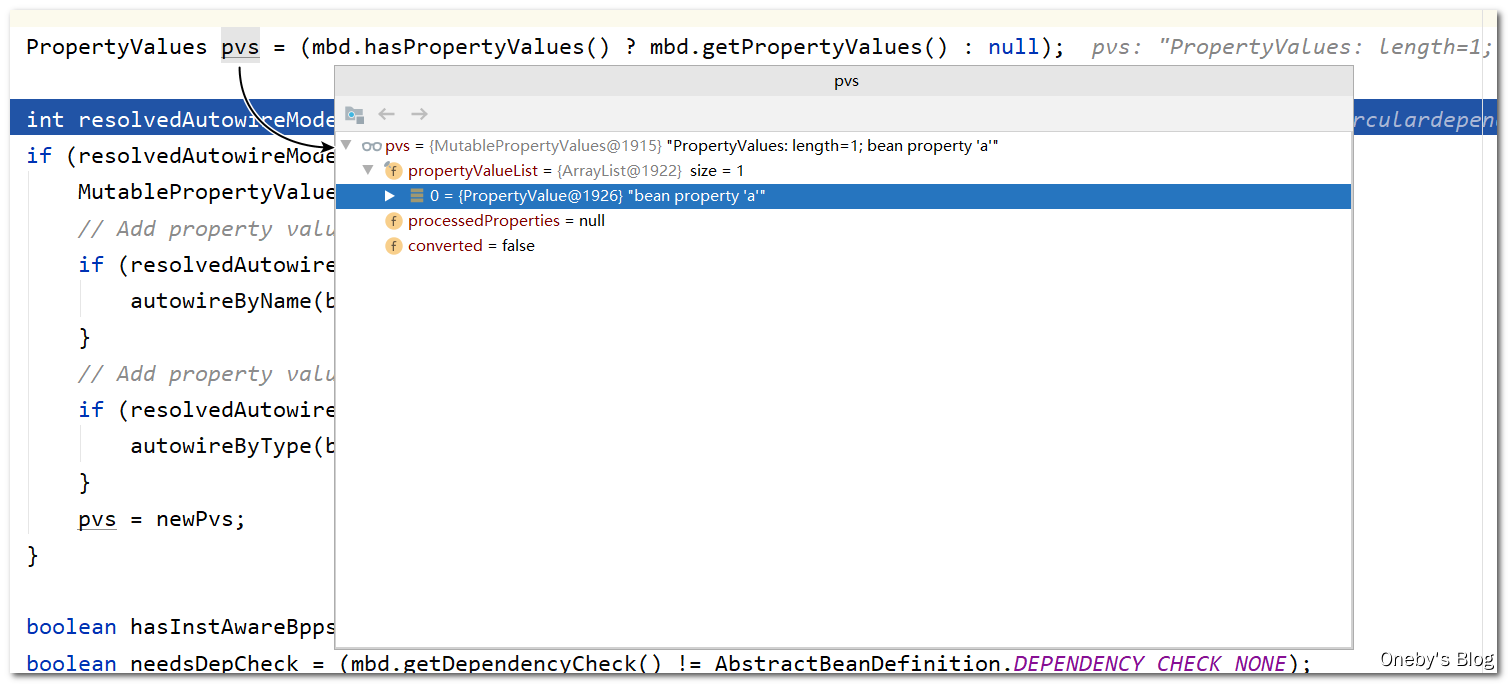
执行 applyPropertyValues(beanName, mbd, bw, pvs) 方法完成 beanB 属性的填充
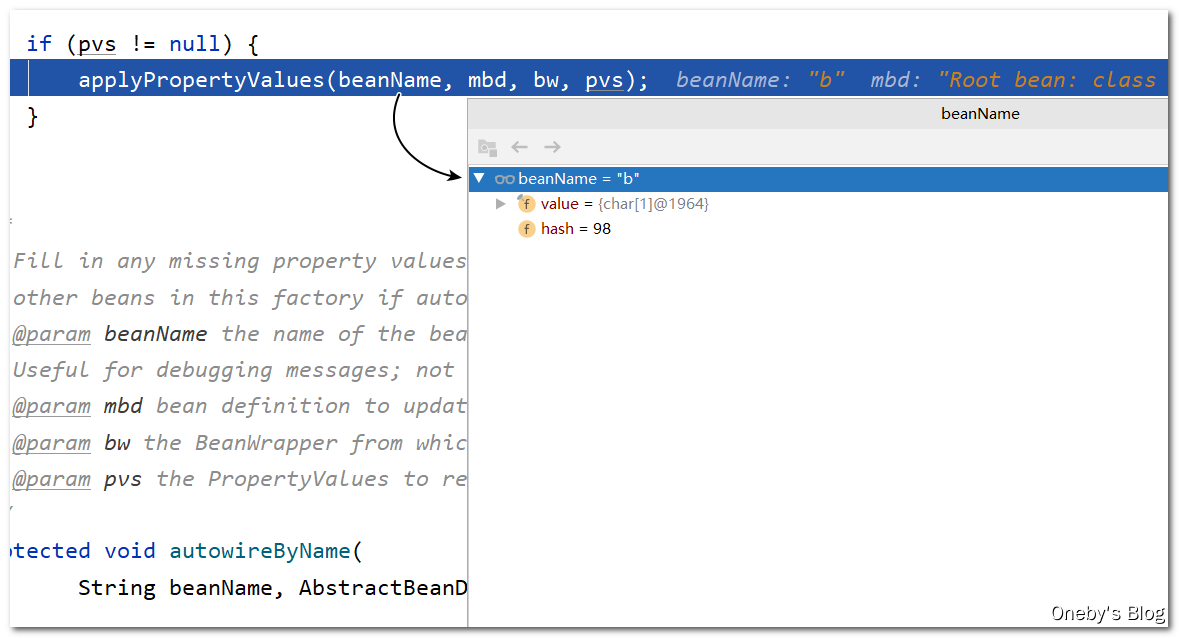
进入 applyPropertyValues(beanName, mbd, bw, pvs) 方法:
执行 mpvs.getPropertyValuelist() 方法获取 beanB 的属性列表
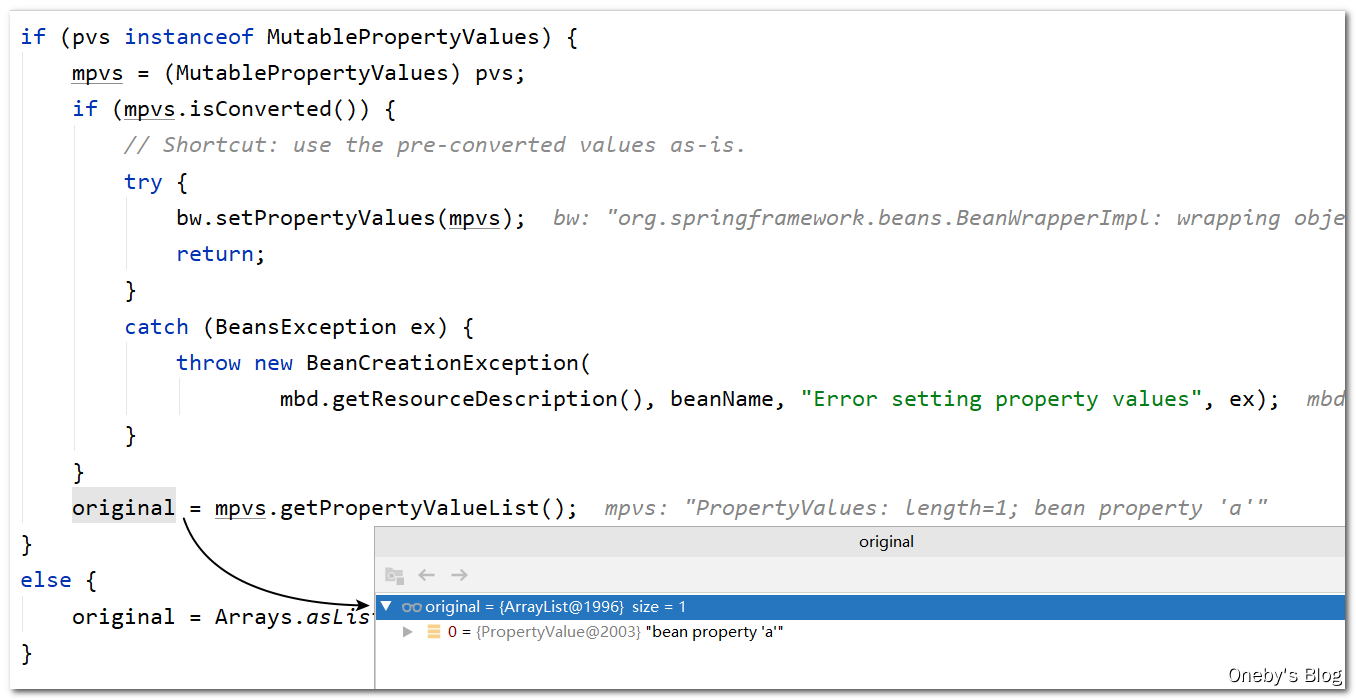
遍历每一个属性,并对每一个属性进行注入,valueResolver.resolveValueIfNecessary(pv, originalValue) 的作用:Given a PropertyValue, return a value, resolving any references to other beans in the factory if necessary.
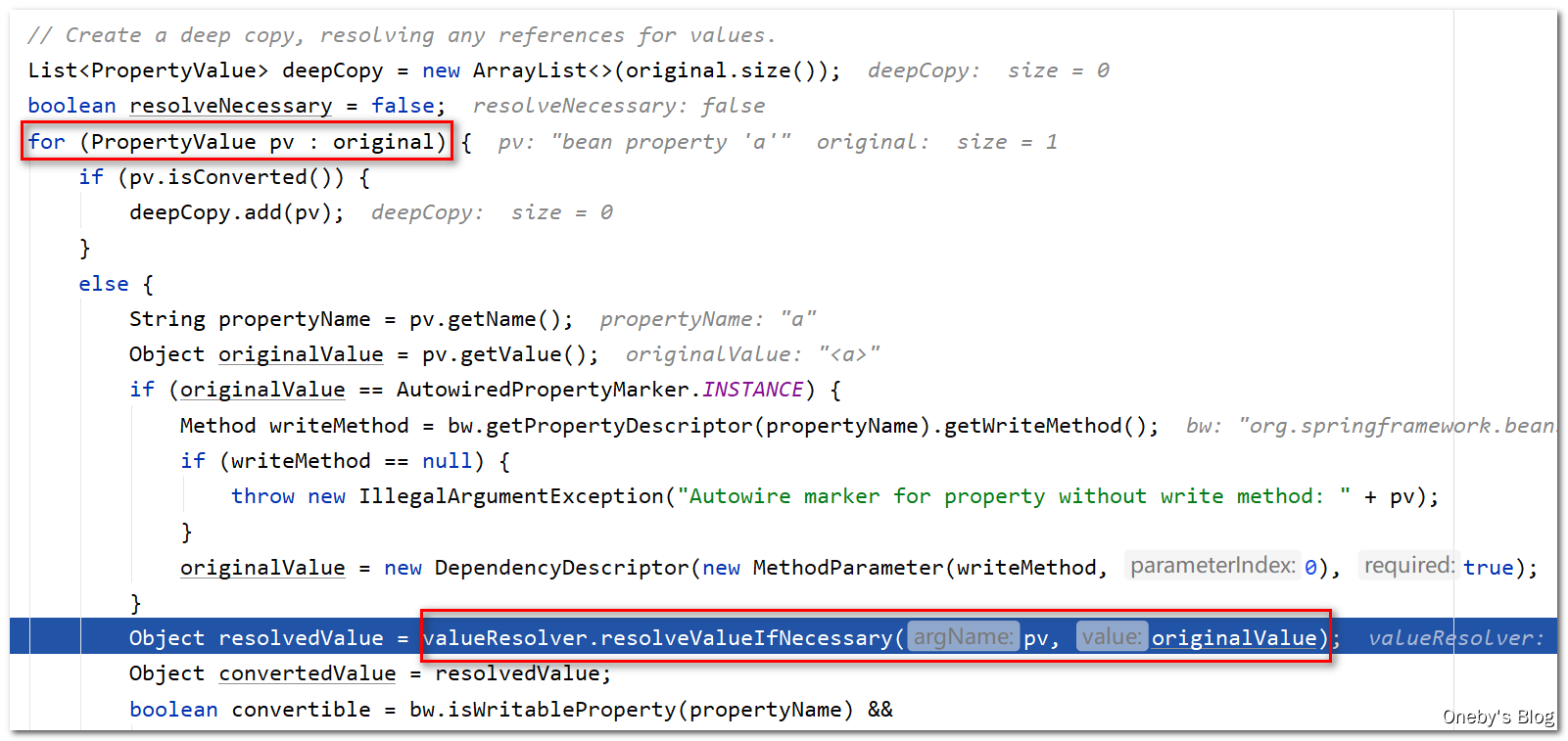
进入 valueResolver.resolveValueIfNecessary(pv, originalValue) 方法:
执行 resolveReference(argName, ref) 方法为 beanB 注入名为 a 属性
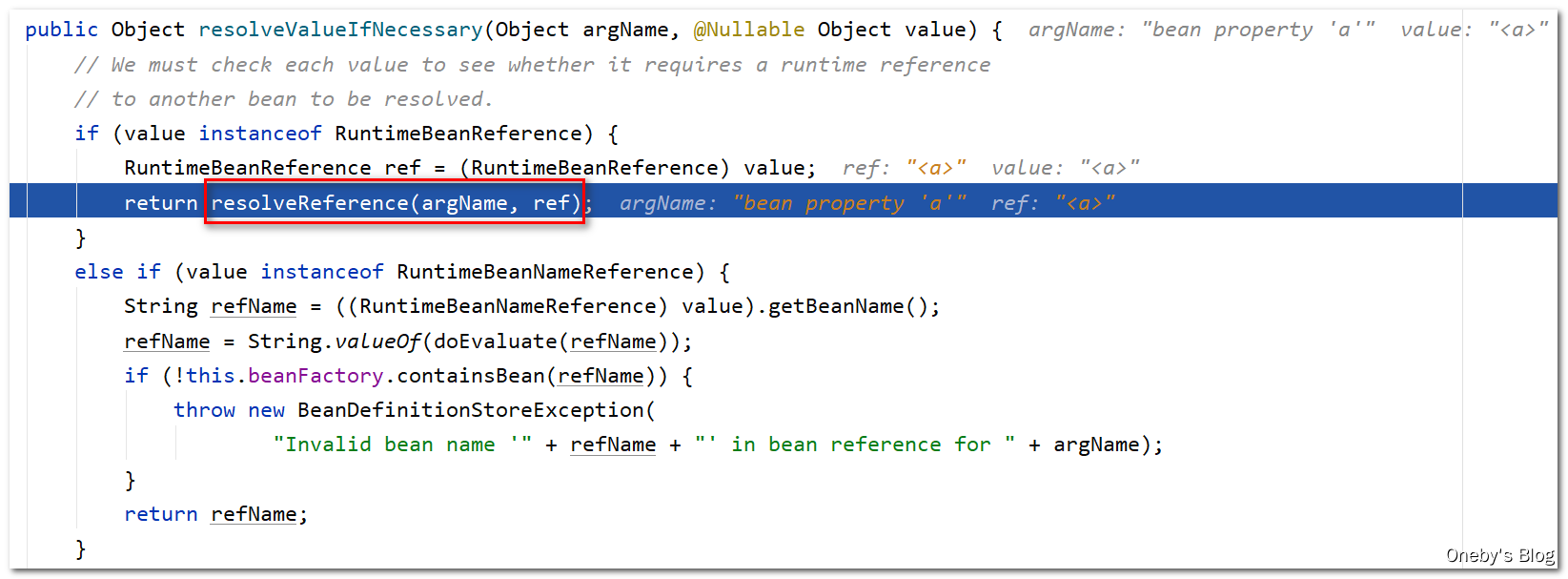
进入 resolveReference(argName, ref) 方法:
执行 this.beanFactory.getBean(resolvedName) 方法获取 beanA 实例,其实就是执行 doGetBean(name, null, null, false) 方法
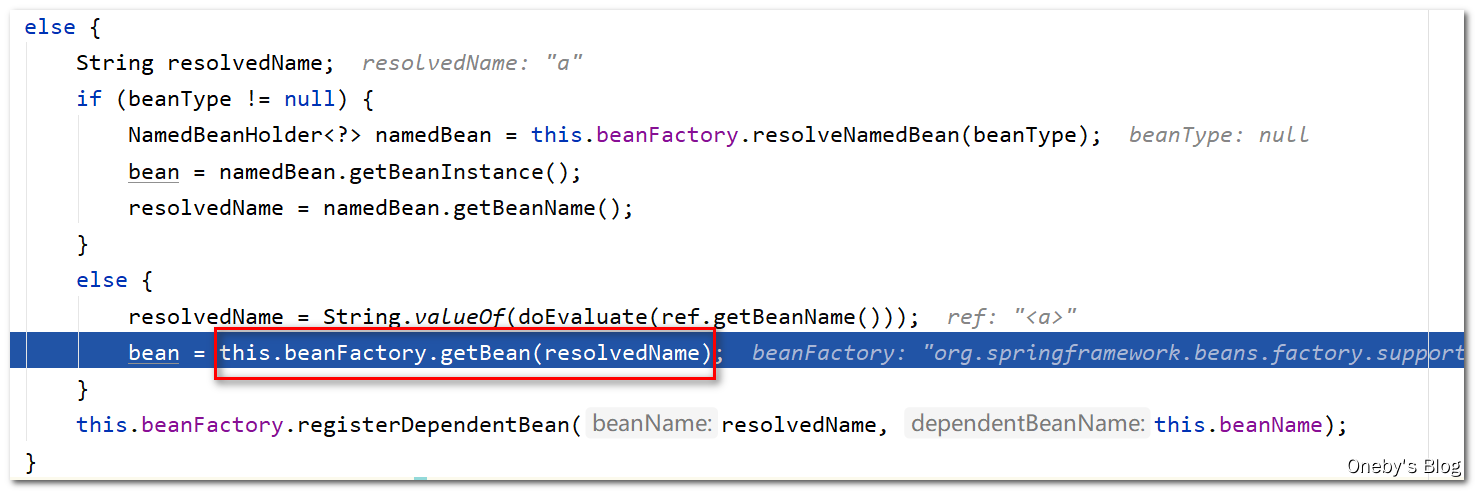
进入 doGetBean(name, null, null, false) 方法:
关键来了,这里执行 getSingleton(beanName) 是够能够获取到 beanA 实例呢?答案是可以
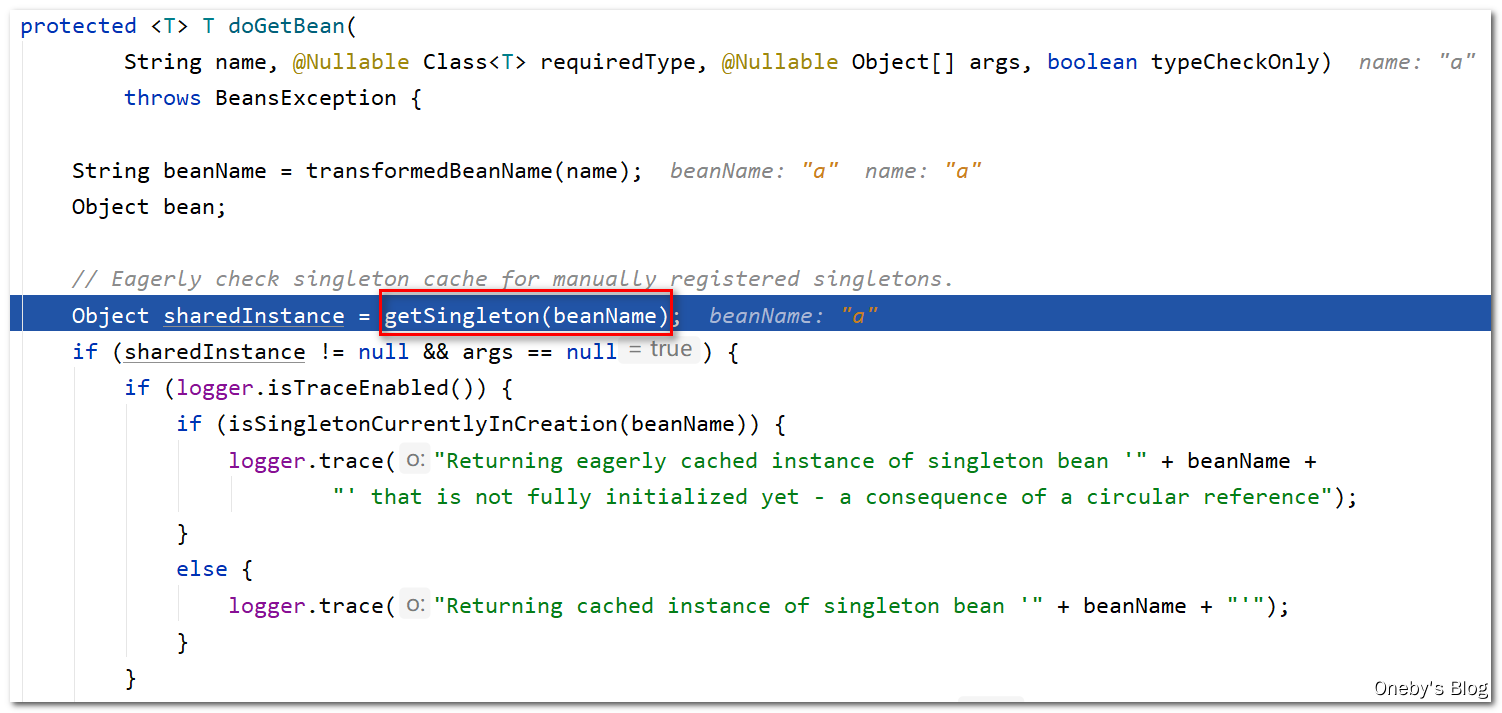
进入 getSingleton(beanName, true) 方法:
getSingleton(beanName) 调用了其重载方法 getSingleton(beanName, true),接下来的逻辑很重要:
beanA 并没有存放在一级缓存
singletonObjects中,因此执行Object singletonObject = this.singletonObjects.get(beanName)后,singletonObject == null,再加上 beanA 正在满足创建的条件(isSingletonCurrentlyInCreation(beanName) == true),因此可以进入第一层 if 判断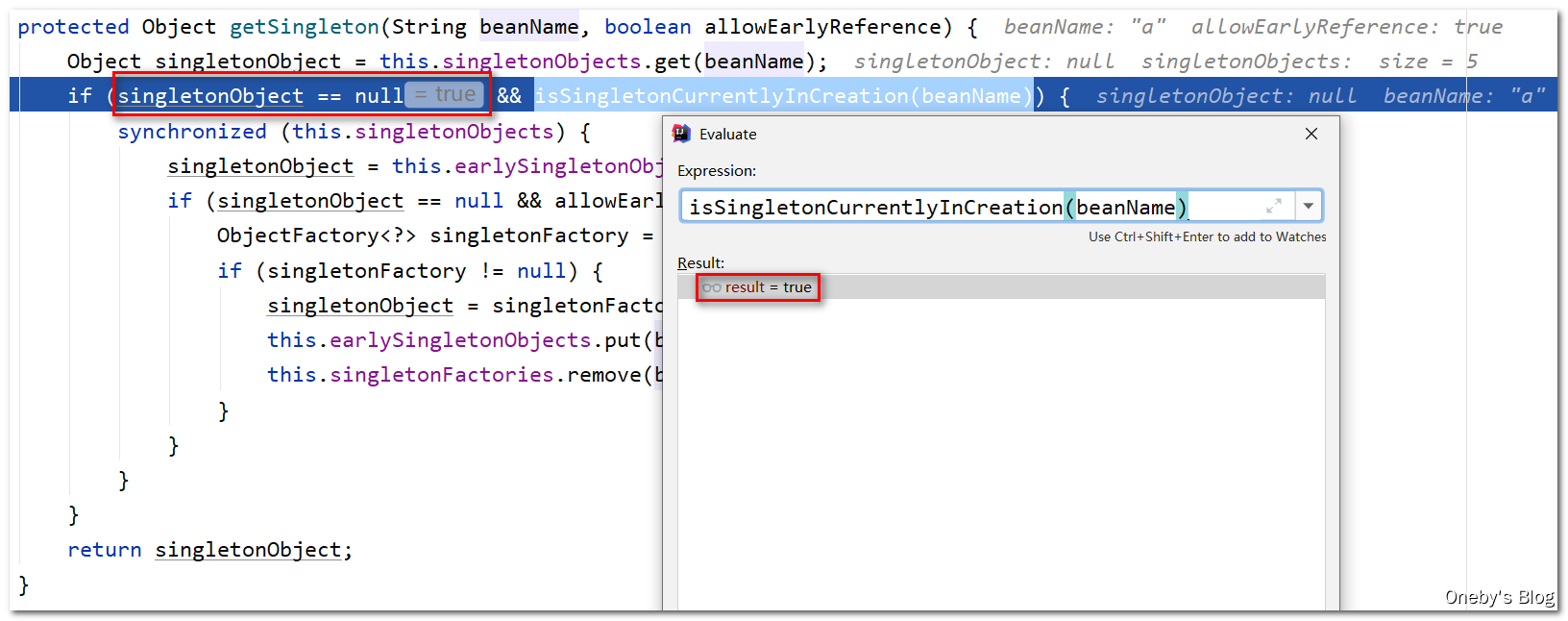
beanA 被存放在三级缓存
singletonFactories中,从二级缓存earlySingletonObjects中获取也是null,因此可以进入第二层if判断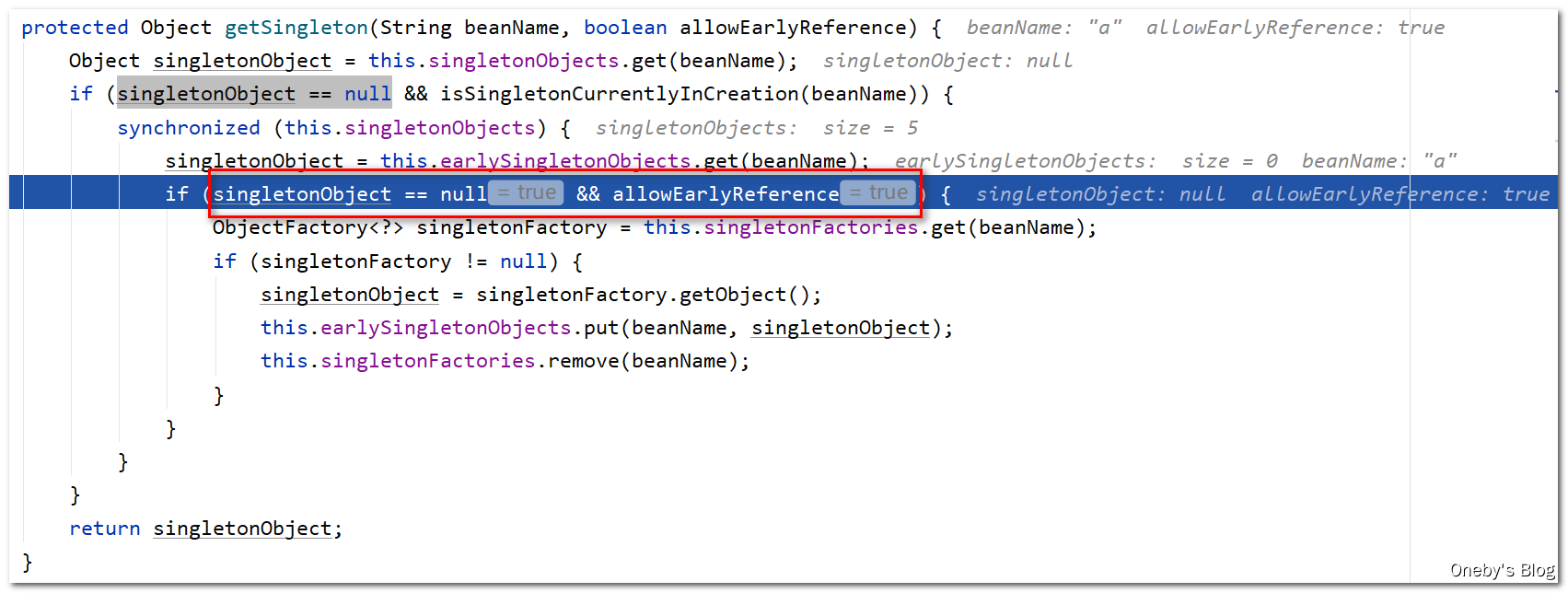
从三级缓存中获取 beanA 肯定不为空,因此可以进入第三层
if判断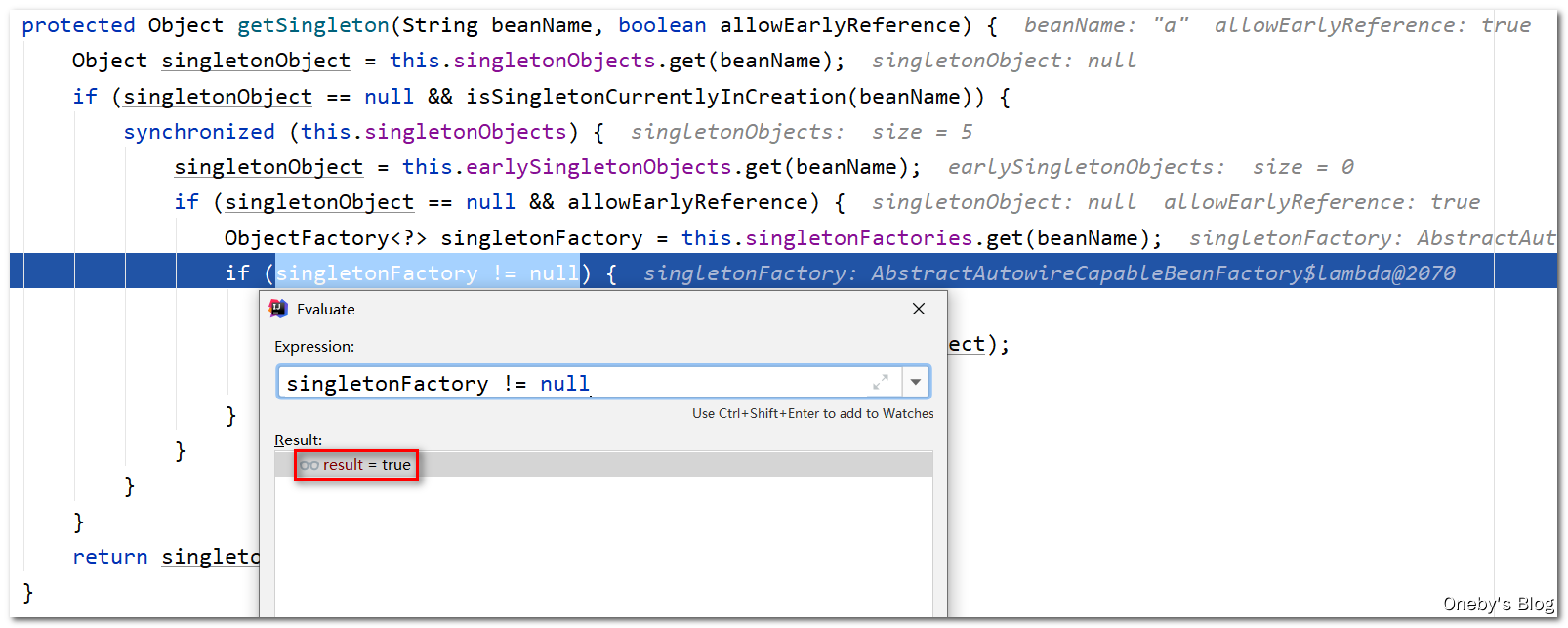
进入第三个if块之后:
- 从单例工厂
singletonFactory中获取 beanA; - 将 beanA 添加至二级缓存
earlySingletonObjects中; - 将 beanA 从三级缓存
singletonFactories中移除
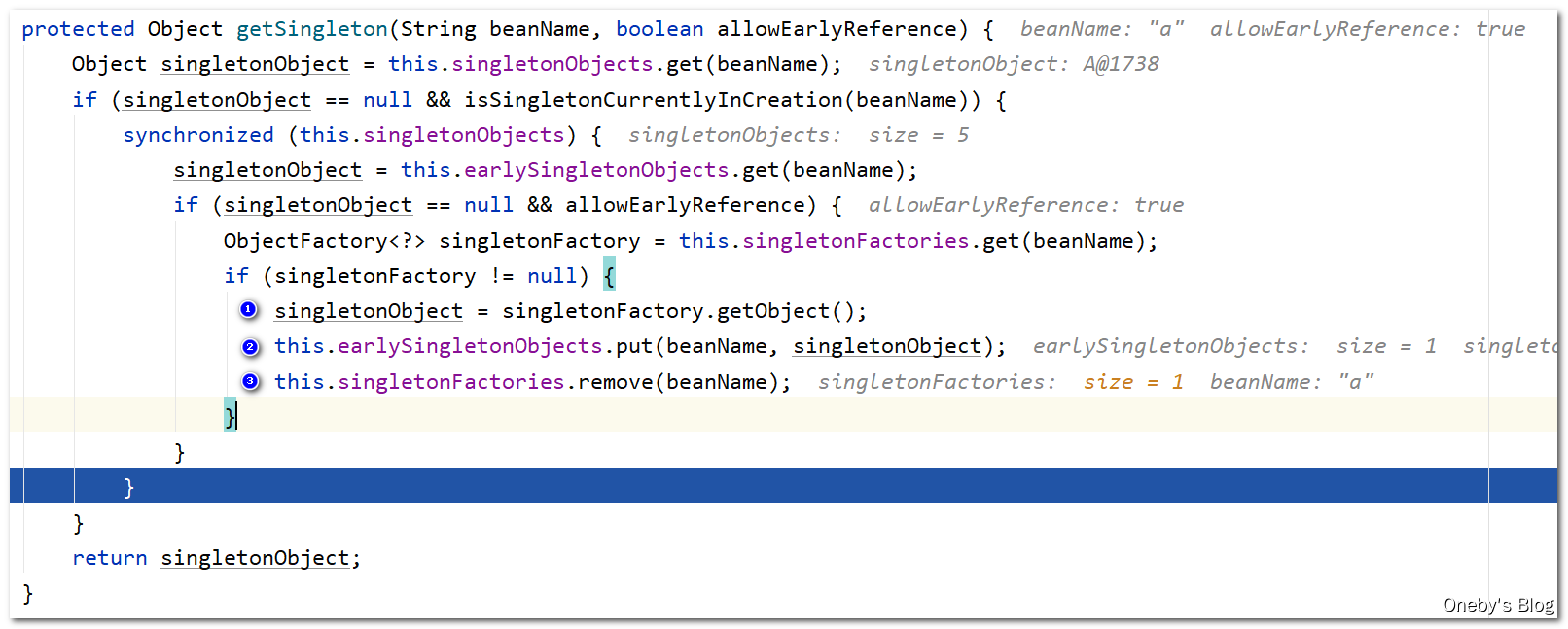
- 从单例工厂
注:
- 此时的第三级缓存当中有K:beanB,V:beanBFactory的lambda表达式
- 此时的第二级缓存当中有K:属性A,V:beanA的实例(未完成初始化)
回到 doGetBean(name, null, null, false) 方法中:
执行 Object sharedInstance = getSingleton(beanName) 将获得之前存入三级缓存 singletonFactories 中的 beanA
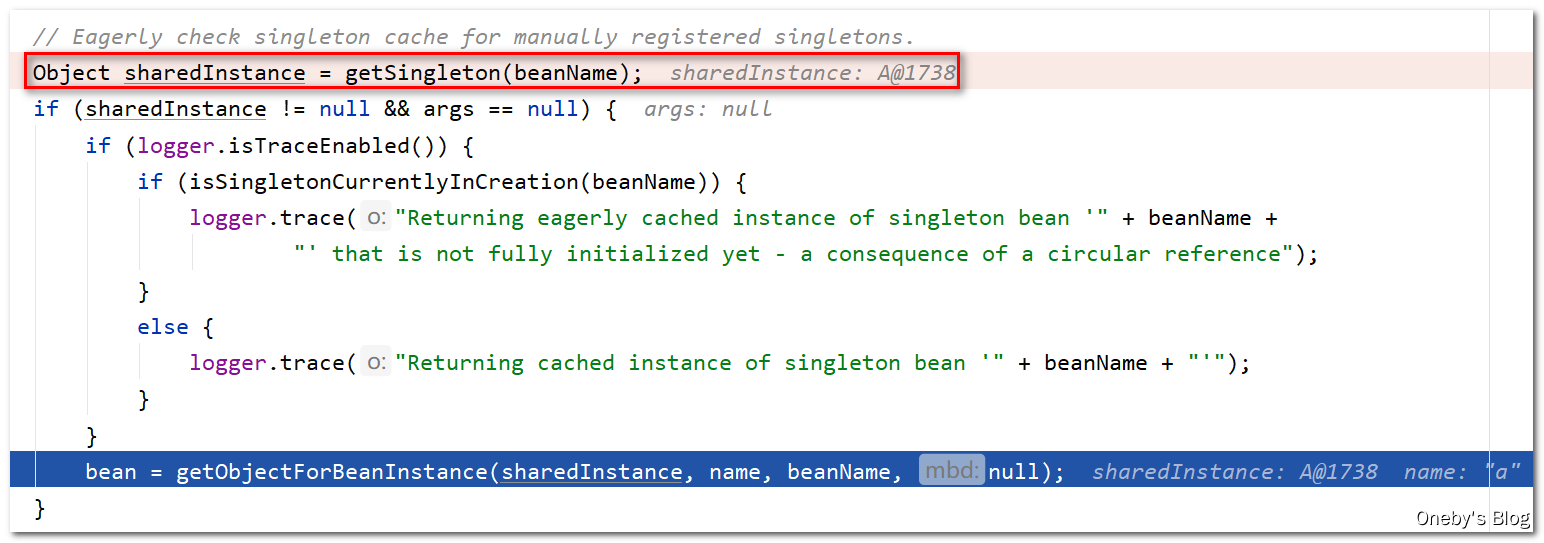
好家伙,获取到 beanA 后就直接返回了
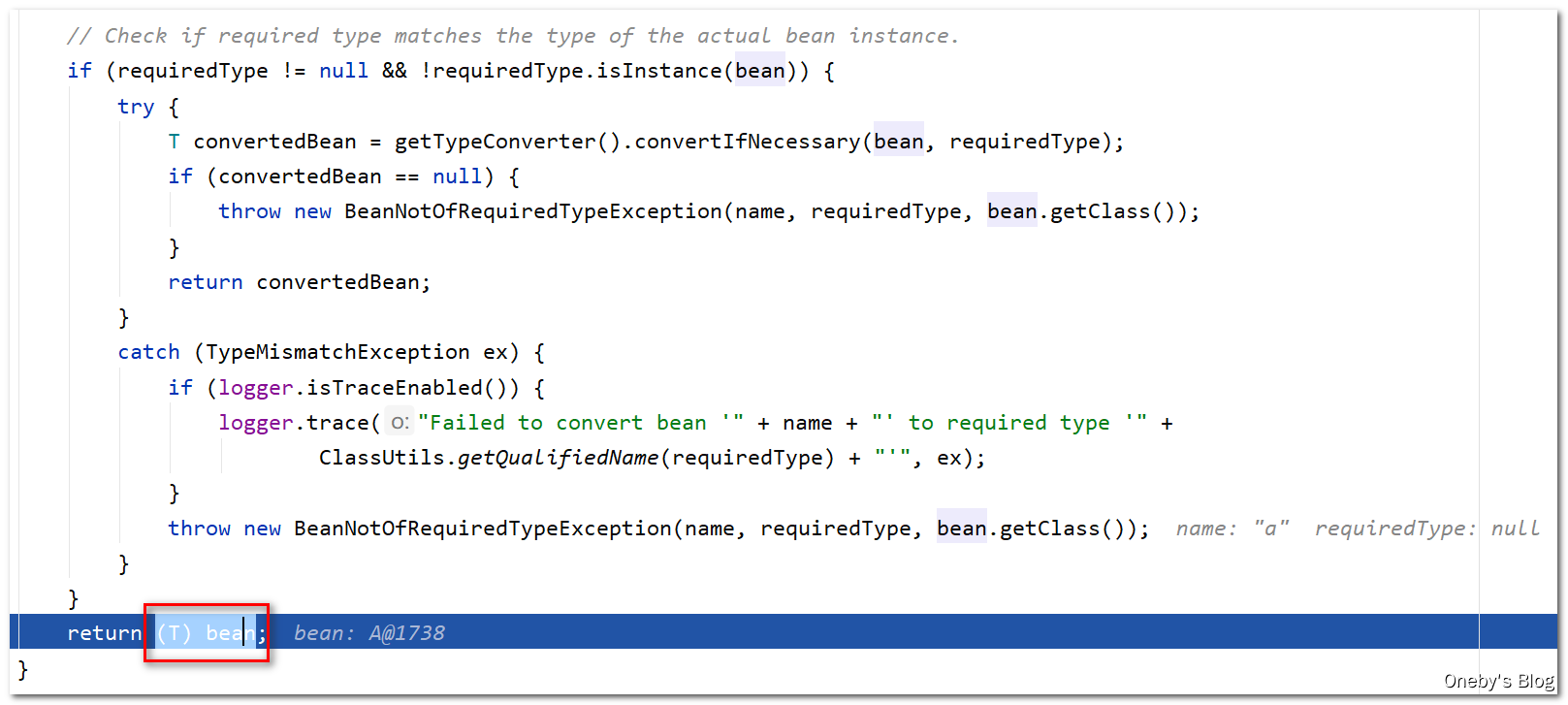
回到 applyPropertyValues(beanName, mbd, bw, pvs) 方法中:
执行 valueResolver.resolveValueIfNecessary(pv, originalValue) 方法获取到 beanA 实例
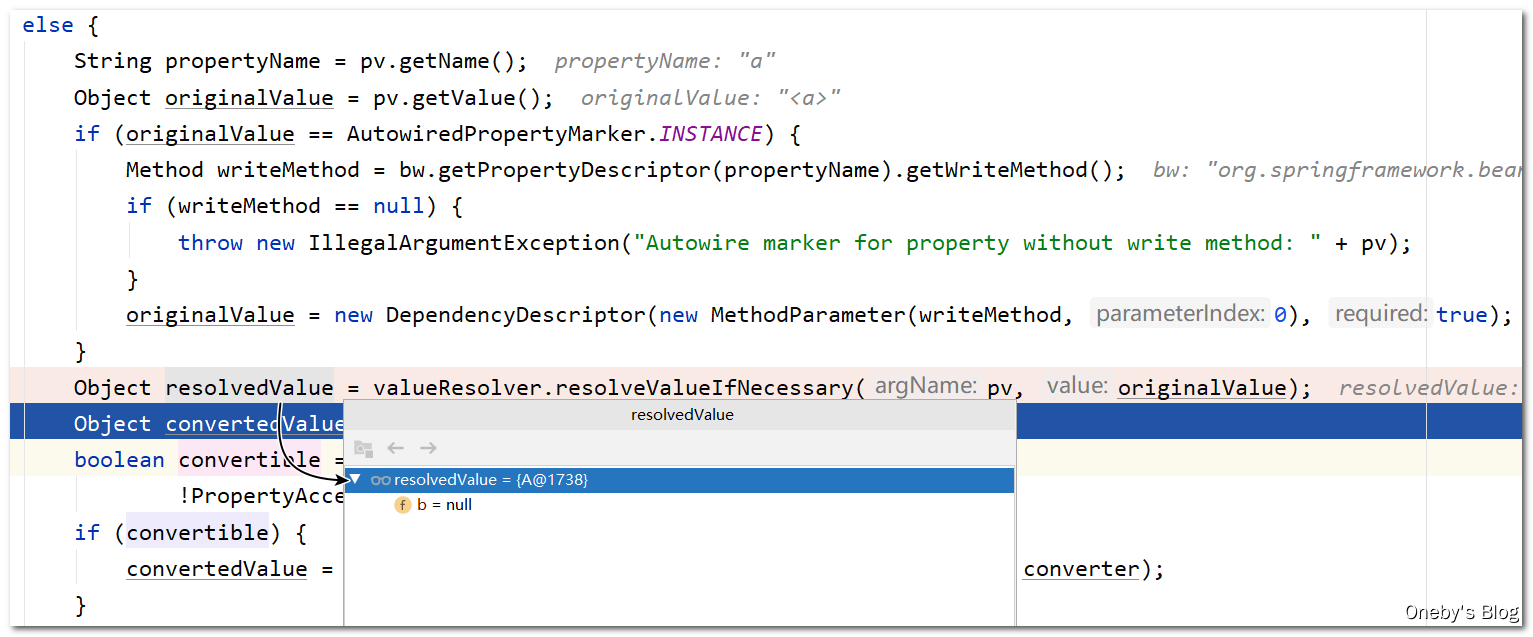
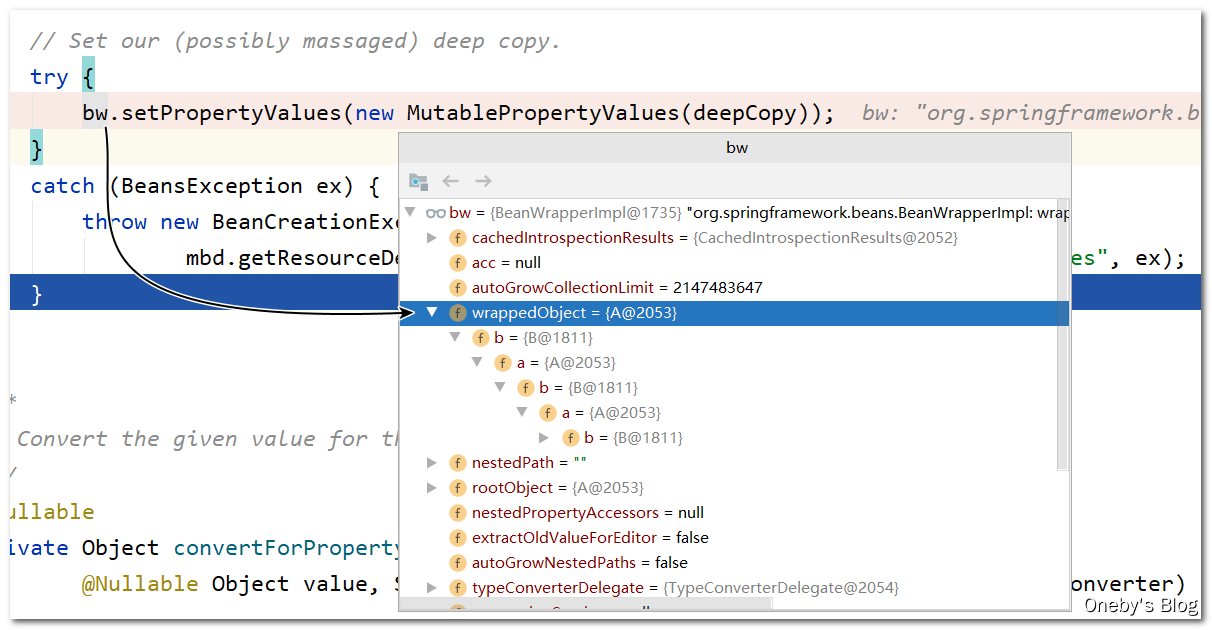
将属性 beanA 添加到 deepCopy 集合中(List<PropertyValue> deepCopy = new ArrayList<>(original.size()))
执行 bw.setPropertyValues(new MutablePropertyValues(deepCopy)) 方法将会填充 beanB 中的 a 属性
进入 bw.setPropertyValues(new MutablePropertyValues(deepCopy)) 方法:
调用了其重载方法 setPropertyValues(pvs, false, false):

进入 setPropertyValues(pvs, false, false) 方法:
在该方法中会对 bean 的每一个属性进行填充(通过 setPropertyValues(pvs, false, false) 方法对属性进行赋值)
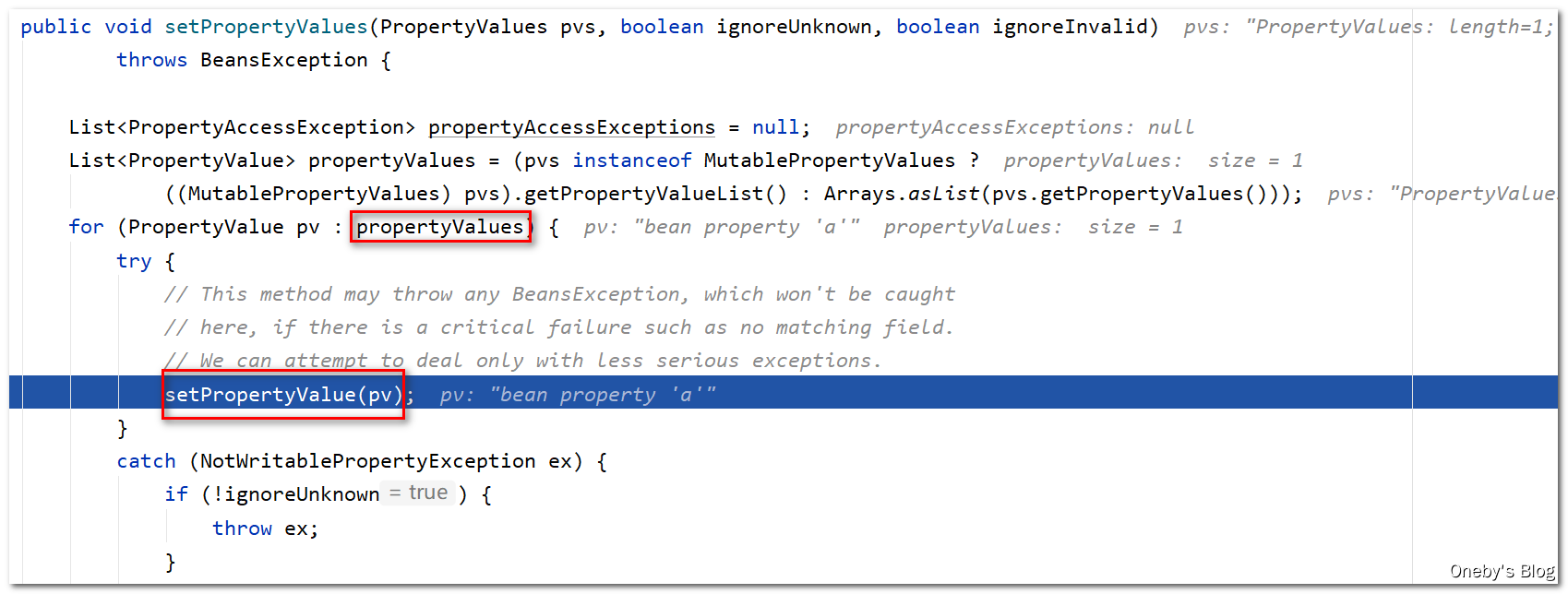
回到 applyPropertyValues(beanName, mbd, bw, pvs) 方法中:
此时 bw 包裹着 beanB,执行 bw.setPropertyValues(new MutablePropertyValues(deepCopy)) 方法会将 deepCopy 中的元素依次赋值给 beanB 的各个属性,此时 beanB 中的 a 属性已经赋值为 beanA
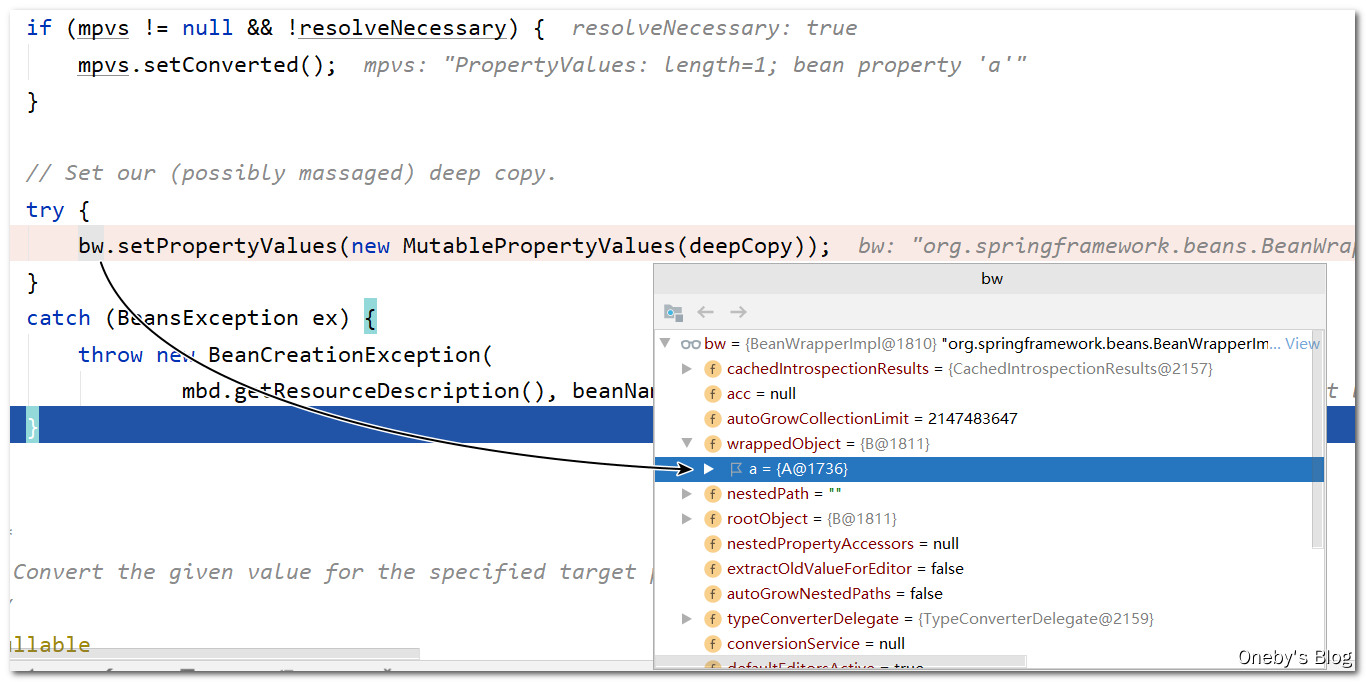
回到 doCreateBean(beanName, mbdToUse, args) 方法中:
因为 instanceWrapper 封装了 beanB,所以执行了 populateBean(beanName, mbd, instanceWrapper) 方法后,beanB 中的 a 属性就已经被填充啦,可以看到 beanB 中有 beanA,但 beanA 中没有 beanB
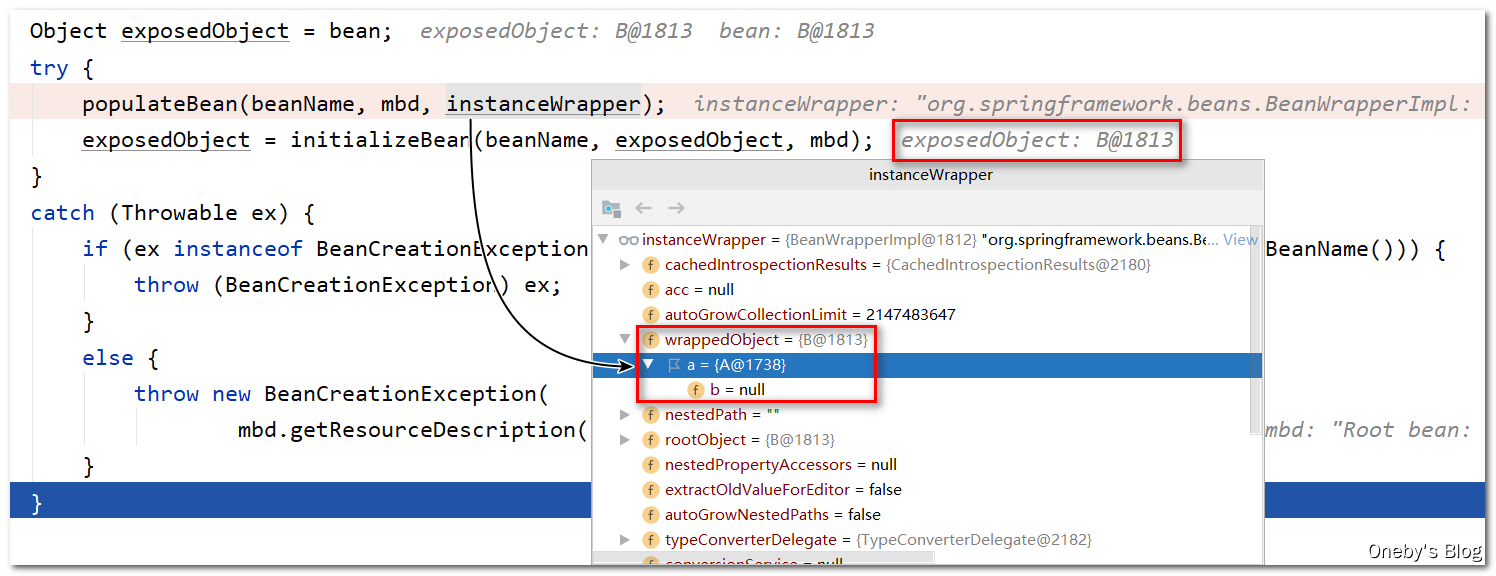
执行 getSingleton(beanName, false) 方法,传入的参数 allowEarlyReference = false,表示不允许从三级缓存 singletonFactories 中获取 beanB
进入 getSingleton(beanName, false) 方法:
由于传入的参数 allowEarlyReference = false,因此第三层 if 判断铁定进不去,而 beanB 在三级缓存 singletonFactories 中存着,因此返回的 singletonObject 为 null
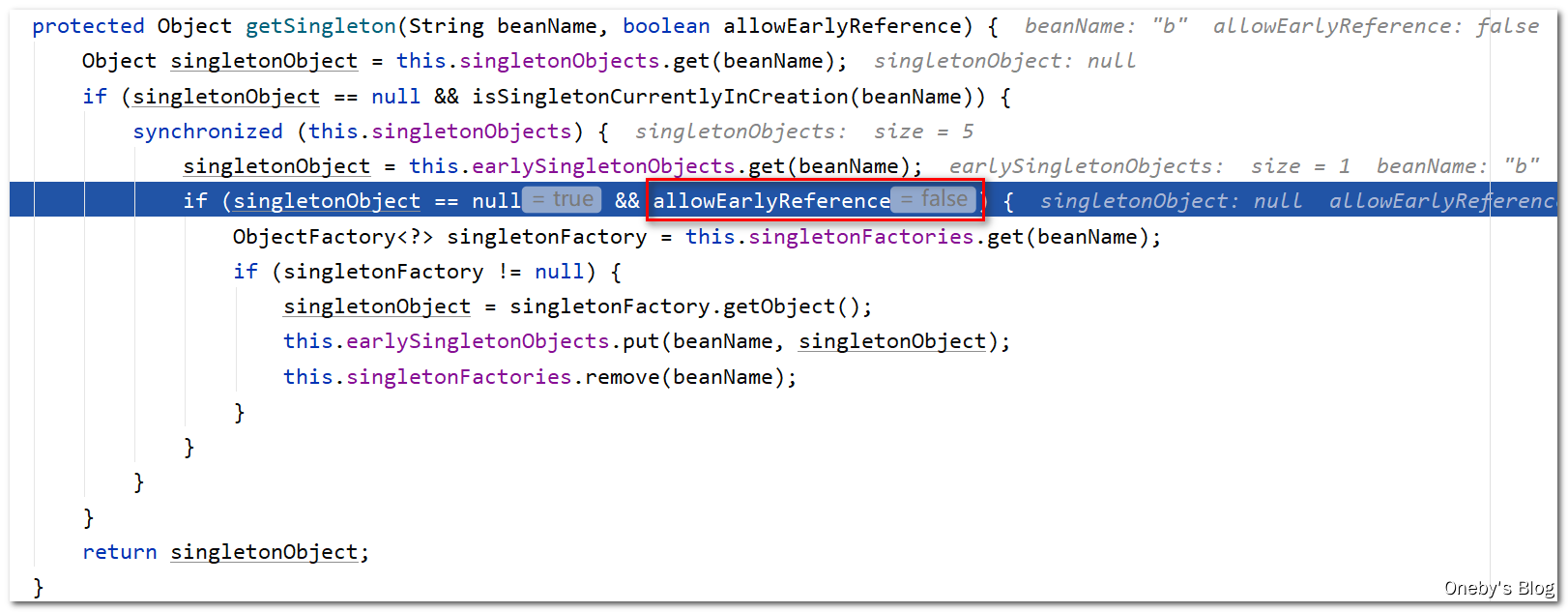
回到 doCreateBean(beanName, mbdToUse, args) 方法中:
这里应该是执行 bean 的 destroy-method ,应该只会在工厂销毁的时候并且 bean 为单例的条件下,其内部逻辑才会执行。registerDisposableBeanIfNecessary(beanName, bean, mbd) 方法的注释如下:Add the given bean to the list of disposable beans in this factory, registering its DisposableBean interface and/or the given destroy method to be called on factory shutdown (if applicable). Only applies to singletons. 最后将 beanB 返回(属性 a 已经填充完毕)
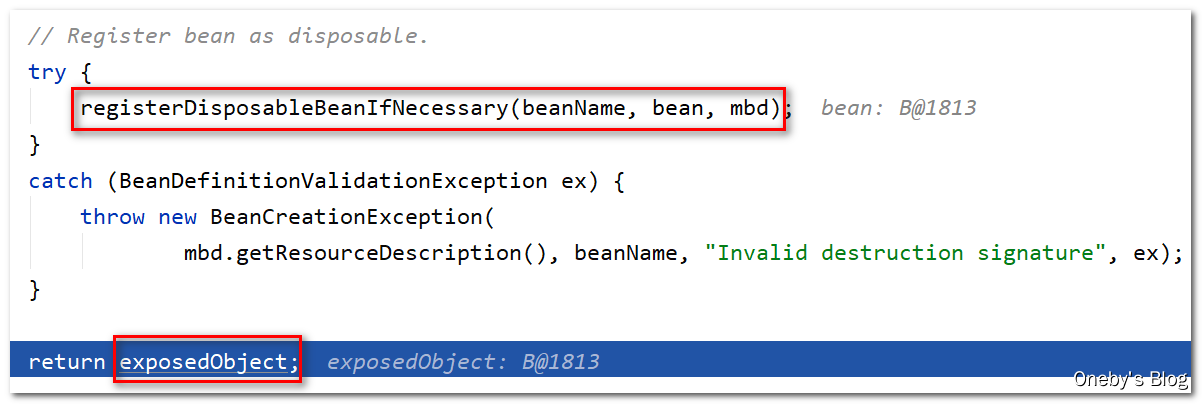
回到 createBean(beanName, mbd, args) 方法:
执行 doCreateBean(beanName, mbdToUse, args) 方法得到包装 beanB 实例(属性 a 已经填充完毕),并将其返回
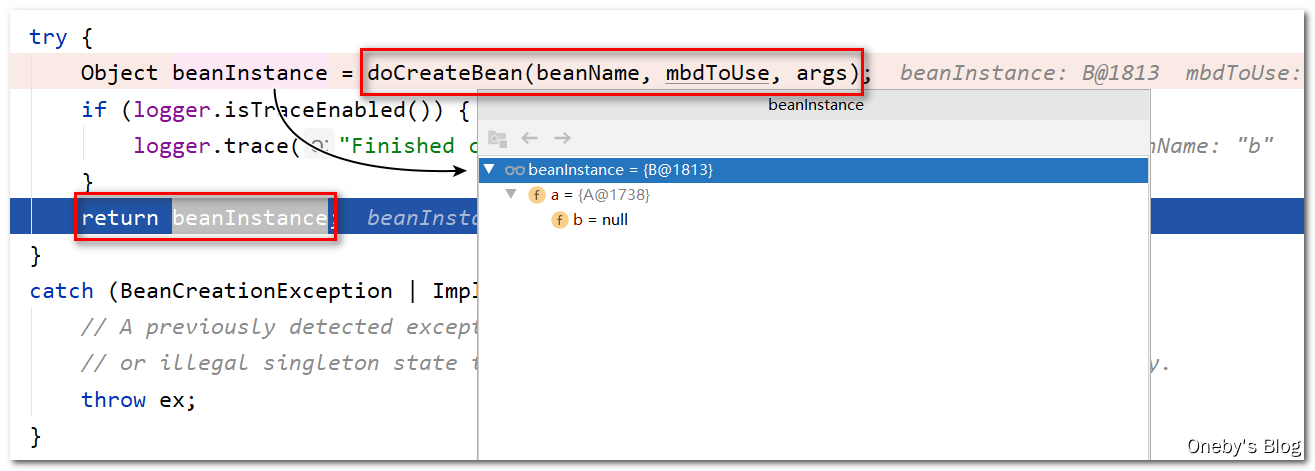
回到 getSingleton(beanName, () -> { ... } 方法中:
执行 singletonFactory.getObject() 方法获取到 beanB 实例,这里的 singletonFactory 是之前调用 getSingleton(beanName, () -> { … } 方法传入的 Lambda 表达式,然后将 newSingleton 设置为 true
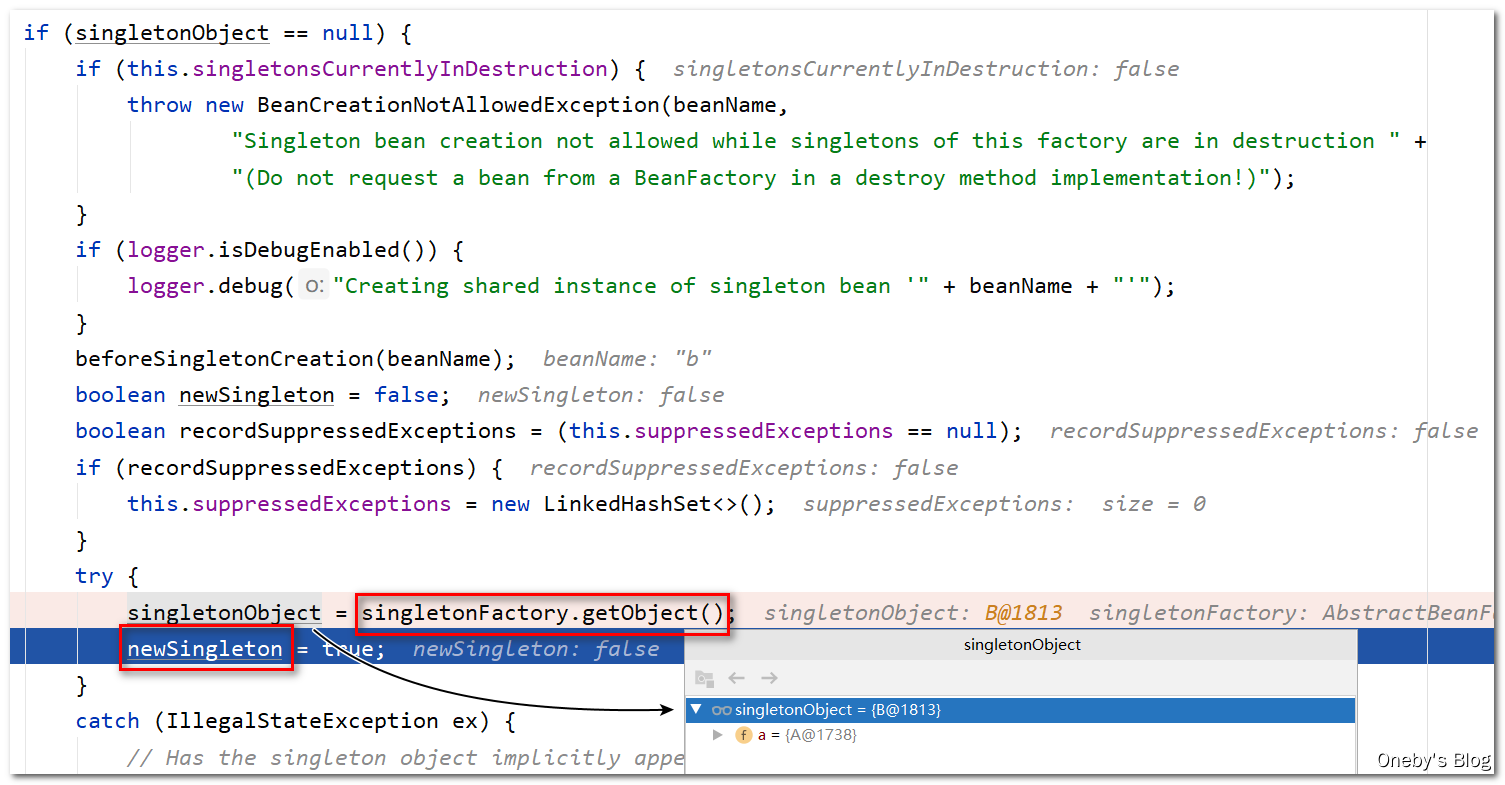
执行 addSingleton(beanName, singletonObject) 方法将 beanB 实例添加到一级缓存 singletonObjects 中
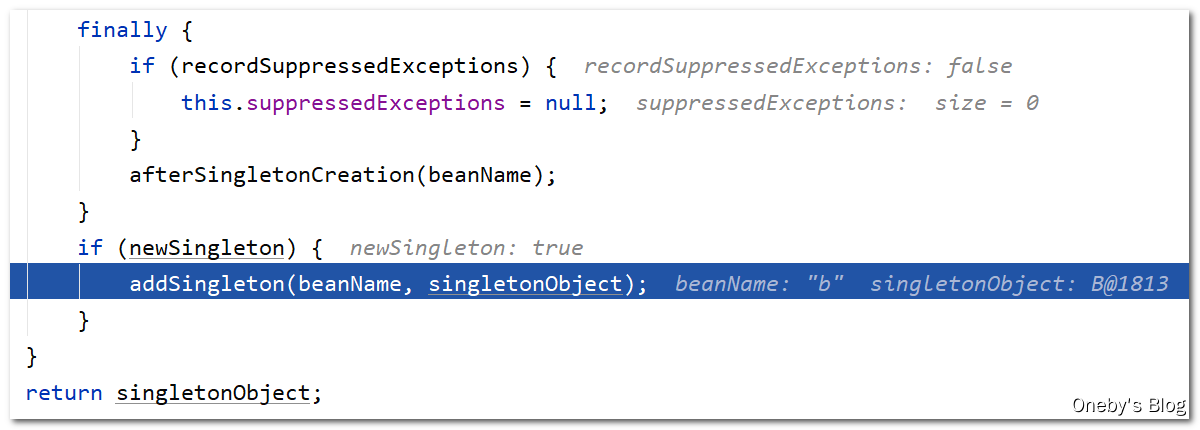
进入 addSingleton(beanName, singletonObject) 方法:
- 将 beanB 放入一级缓存
singletonObjects中 - 将 beanB 从三级缓存
singletonFactories中删除(beanB 确实在三级缓存中) - 将 beanB 从二级缓存
earlySingletonObjects中删除(beanB 并不在二级缓存中) - 将 beanB 的 beanName 注册到
registeredSingletons中(之前添加至三级缓存的时候已经注册过啦~)
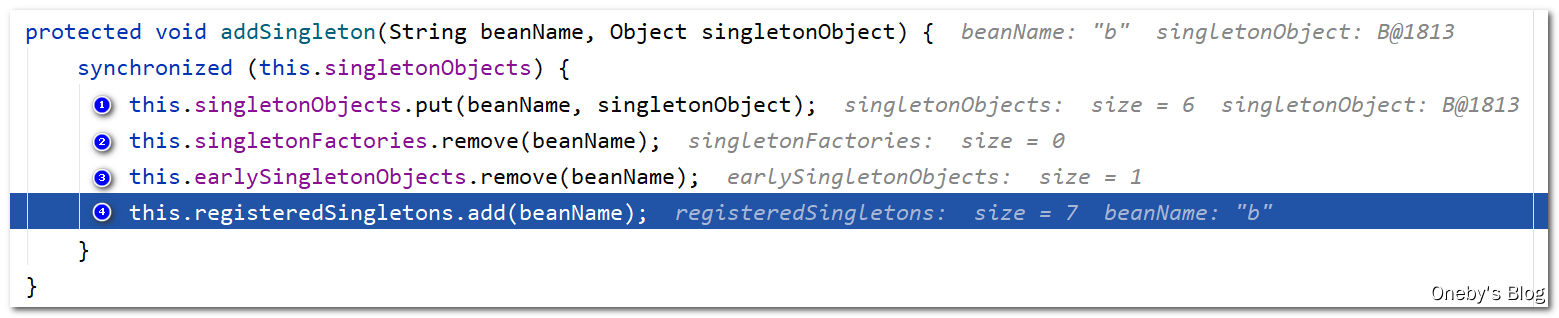
注:
- 此时的第三级缓存当中已经没有东西了
- 第二级缓存当中有K:A,V:beanA的实例(半成品,未初始化)
- 第一级缓存当中有K:B,V:beanB的实例(成品)
回到 getSingleton(beanName, () -> { ... } 方法中:
执行 addSingleton(beanName, singletonObject) 将 beanB 添加到一级缓存 singletonObjects 后,将 beanB 返回
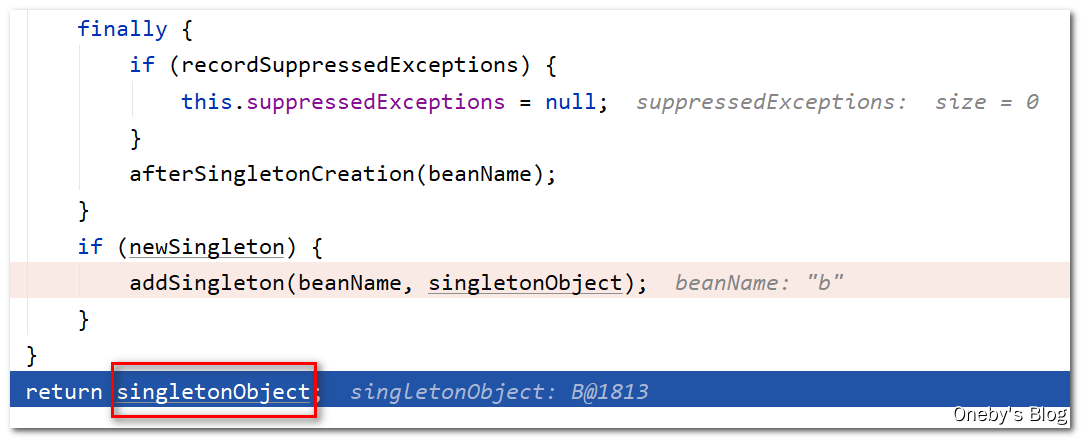
回到 doGetBean(name, null, null, false) 方法中:
执行完 getSingleton(beanName, () -> { ... } 方法后,得到属性已经填充好的 beanB,并且已经将其添加至一级缓存 singletonObjects 中
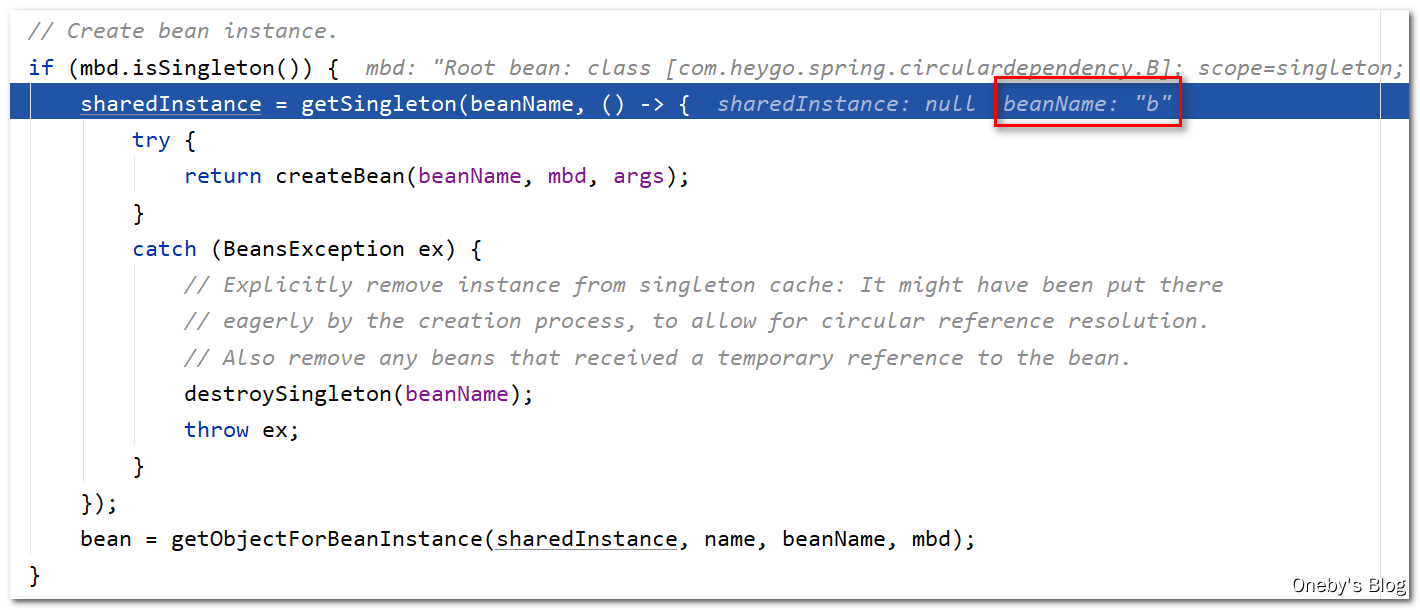
将 beanB 返回,想想返回到哪儿去了呢?当初时因为 beanA 要填充其属性 b,才执行了创建 beanB 的操作,现在返回肯定是将 beanB 返回给 beanA
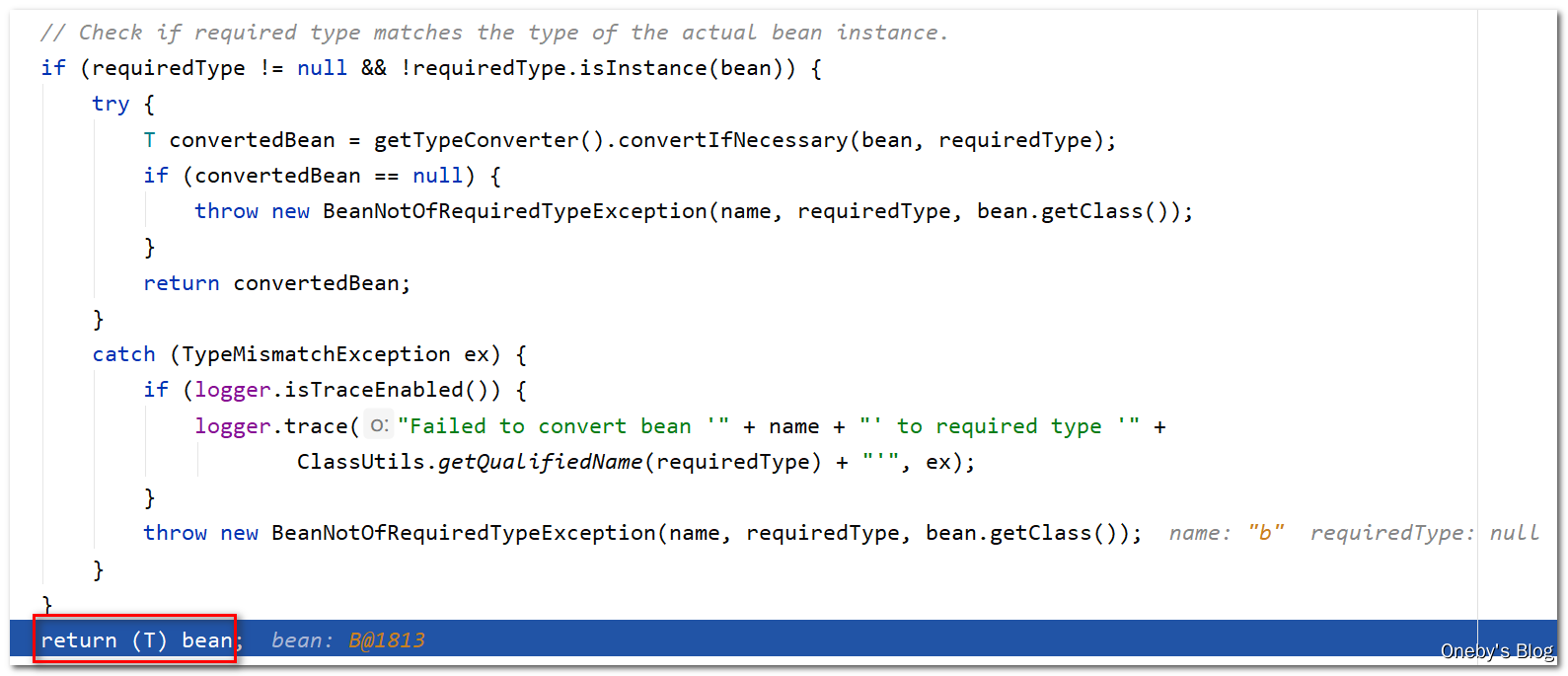
5、beanA 的属性填充
回到 resolveReference(argName, ref) 方法中:
执行完 this.beanFactory.getBean(resolvedName) 方法后,获得了属性填充好的 beanB 实例,并将其实例返回
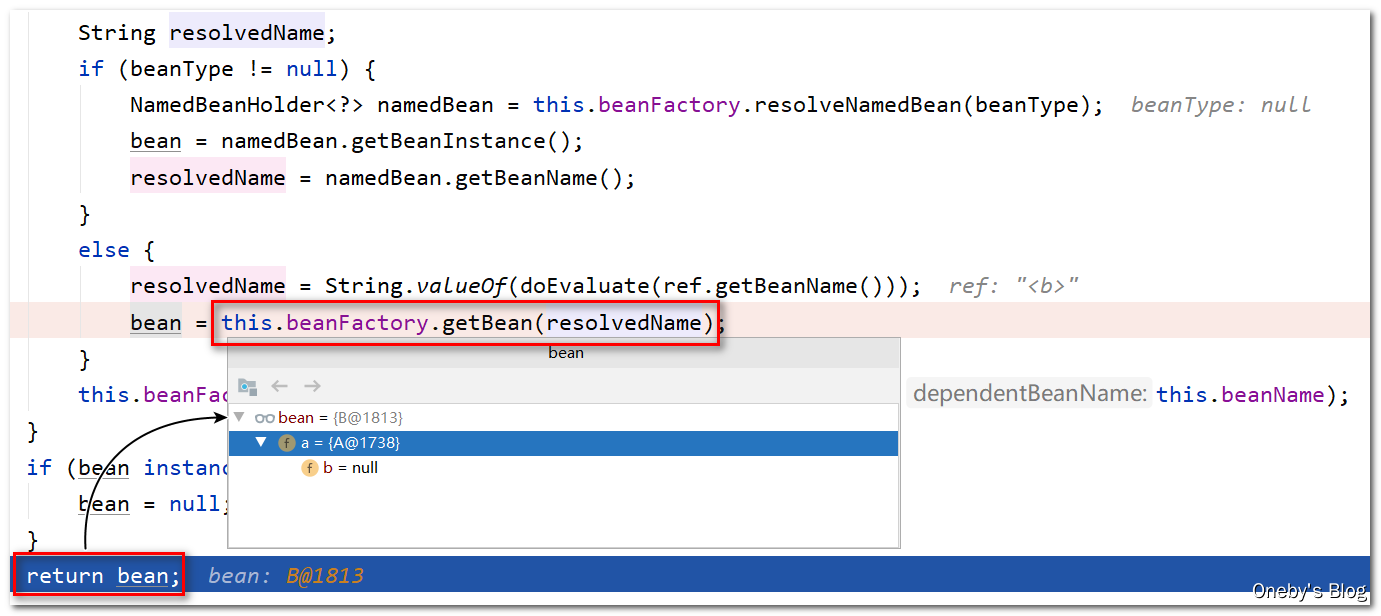
回到 applyPropertyValues(beanName, mbd, bw, pvs) 方法中:
执行完 valueResolver.resolveValueIfNecessary(pv, originalValue) 方法后,将获得属性填充好的 beanB 实例
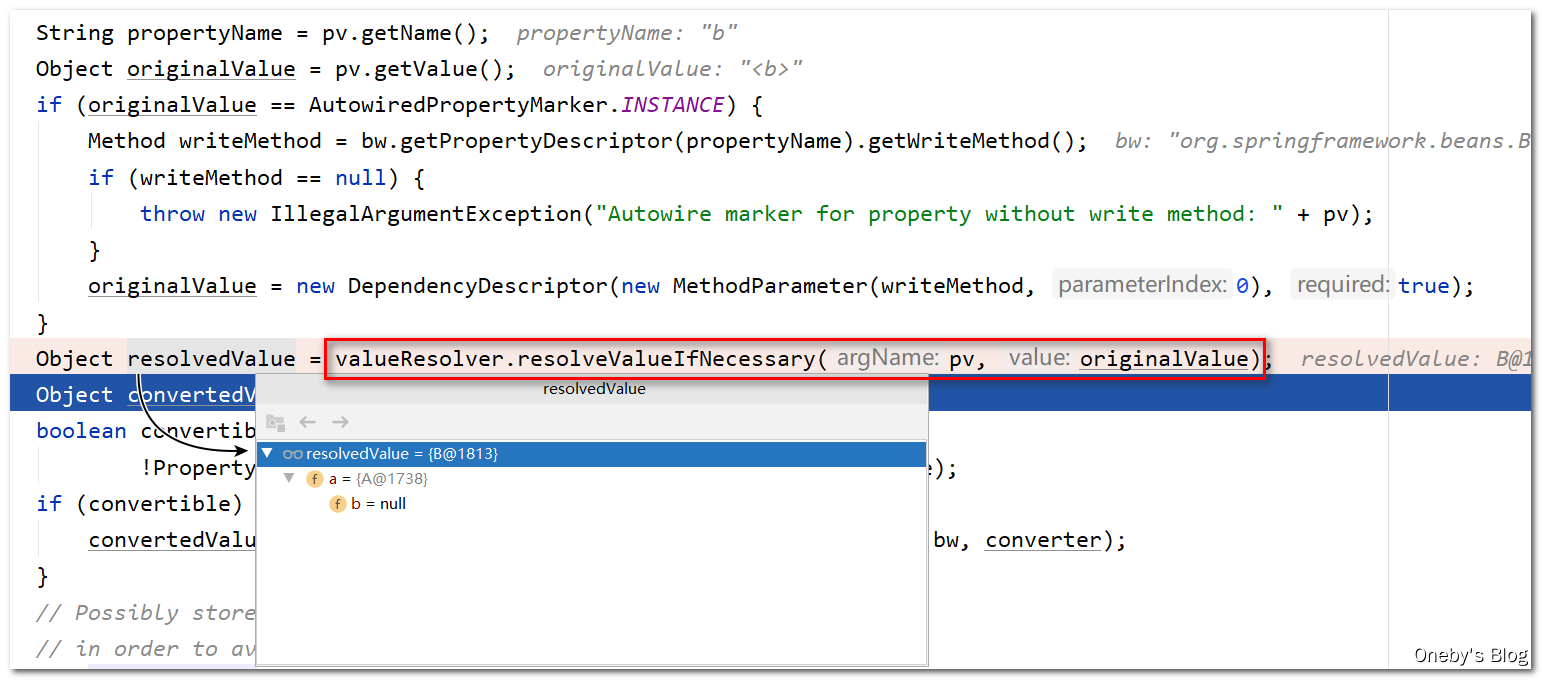
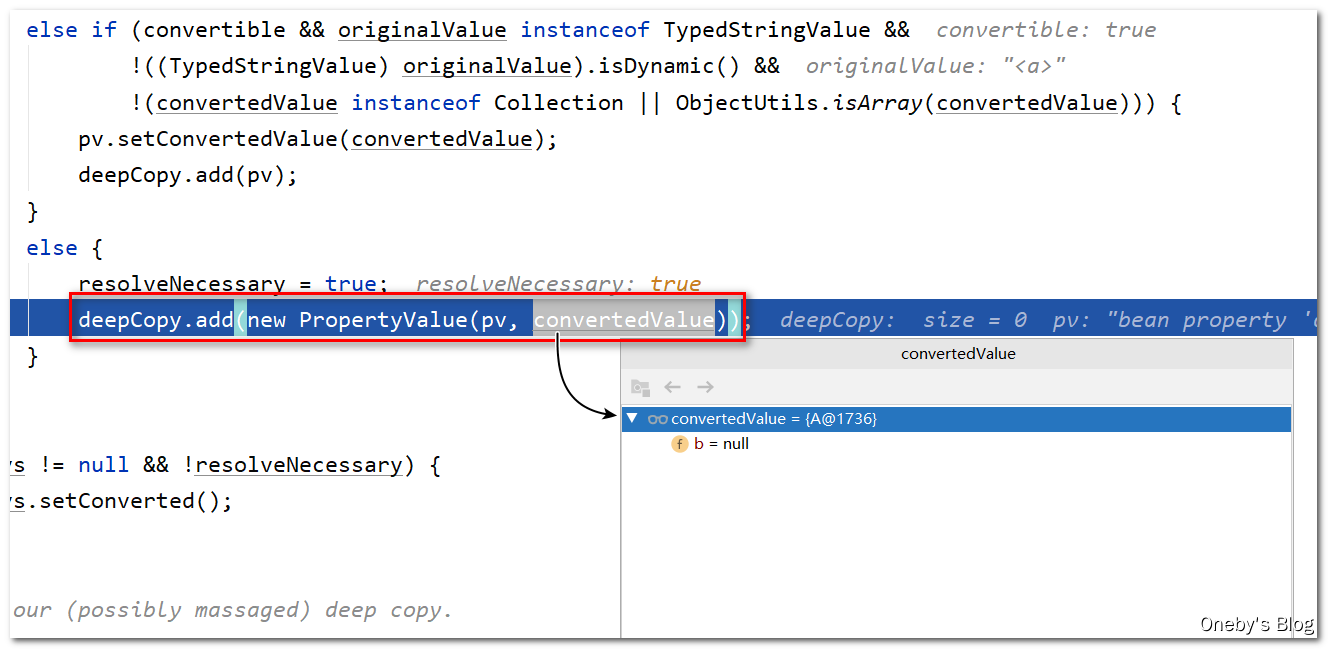
将 b 属性添加至 deepCopy 集合中:
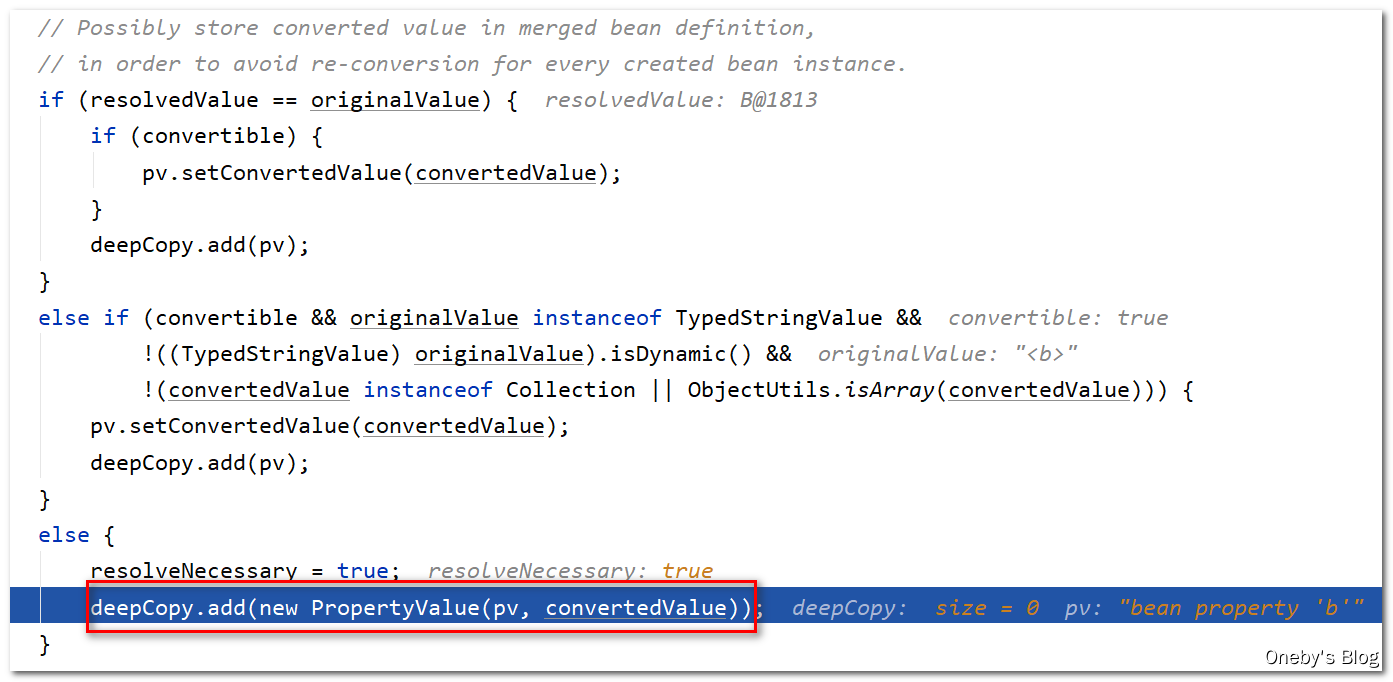
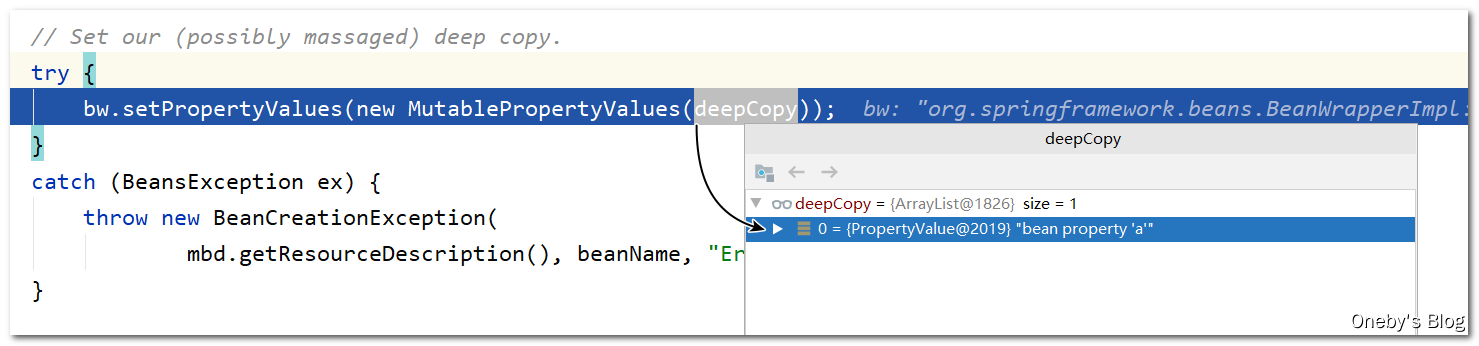
执行 bw.setPropertyValues(new MutablePropertyValues(deepCopy)) 方法对 beanA 的 b 属性进行填充
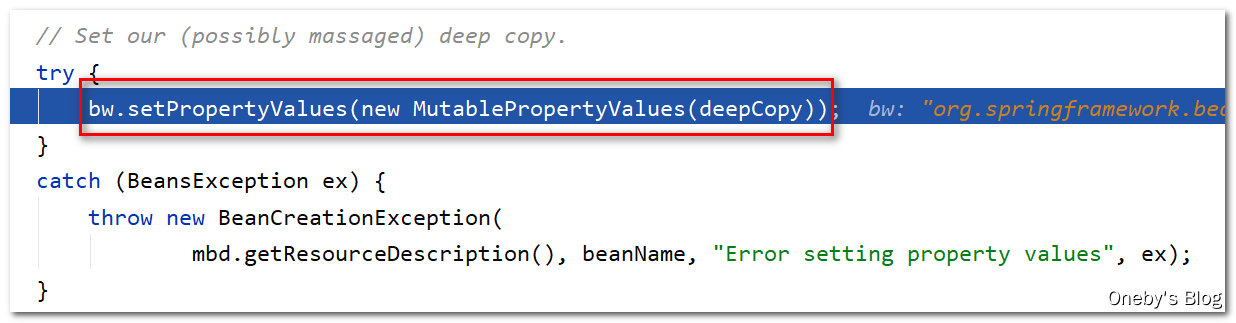
进入 setPropertyValues(pvs, false, false) 方法:
在 bw.setPropertyValues(new MutablePropertyValues(deepCopy)) 方法中调用了 setPropertyValues(pvs, false, false) 方法,在该方法中会对 bean 的每一个属性进行填充(通过 setPropertyValues(pvs, false, false) 方法对属性进行赋值)
回到 applyPropertyValues(beanName, mbd, bw, pvs) 方法中:
此时 bw 中包裹着 beanA,执行 bw.setPropertyValues(new MutablePropertyValues(deepCopy)) 方法会将 deepCopy 中的元素依次赋值给 beanA 的各个属性,此时 beanA 中的 b 属性已经赋值为 beanA,又加上之前 beanB 中的 a 属性已经赋值为 beanA,此时可开启无限套娃模式
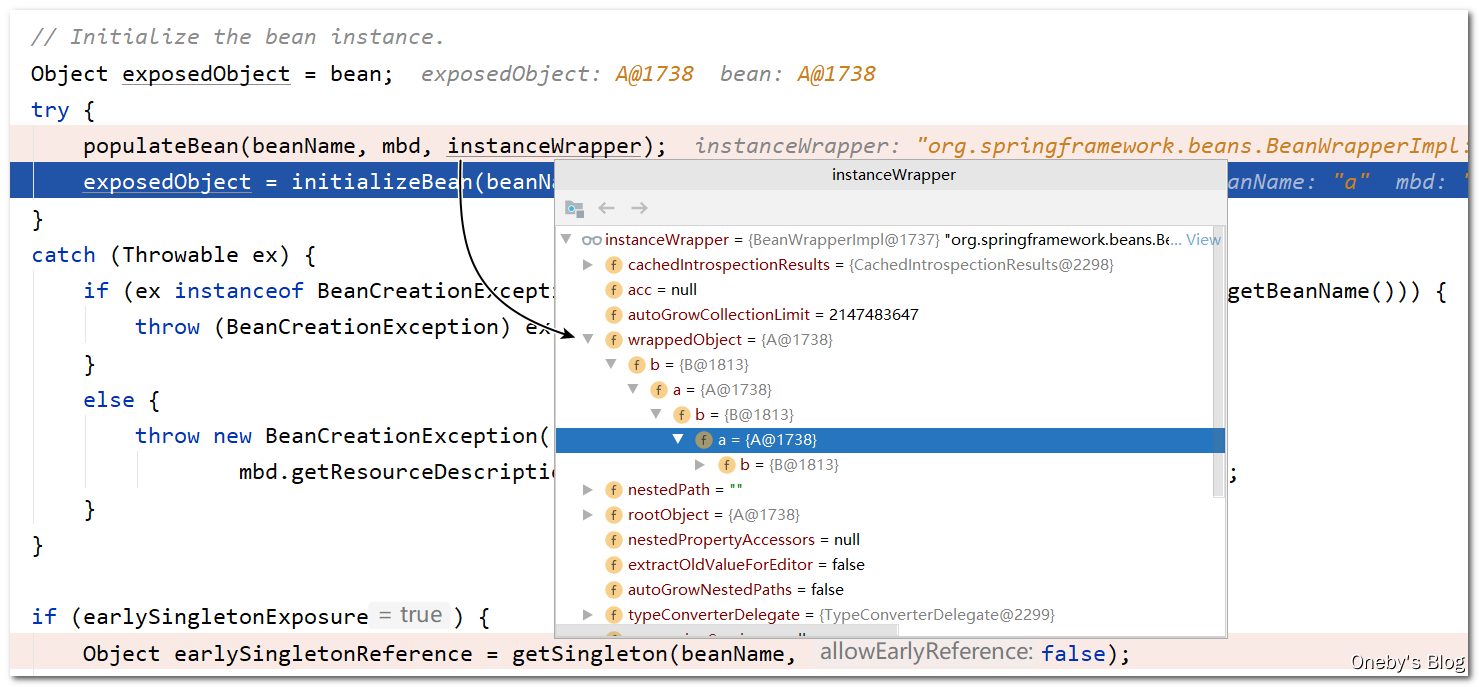
回到 doCreateBean(beanName, mbdToUse, args) 方法中:
执行完 populateBean(beanName, mbd, instanceWrapper) 方法后,可以开启无限套娃模式
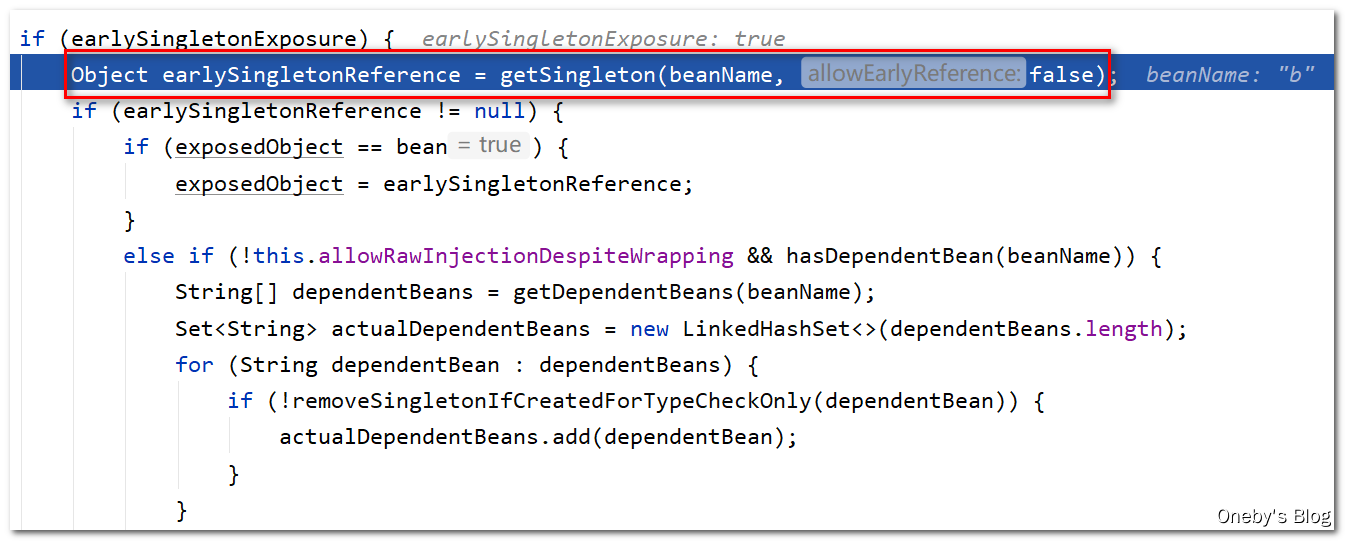
这次执行 getSingleton(beanName, false) 方法能获取到 beanA 吗?答:可以
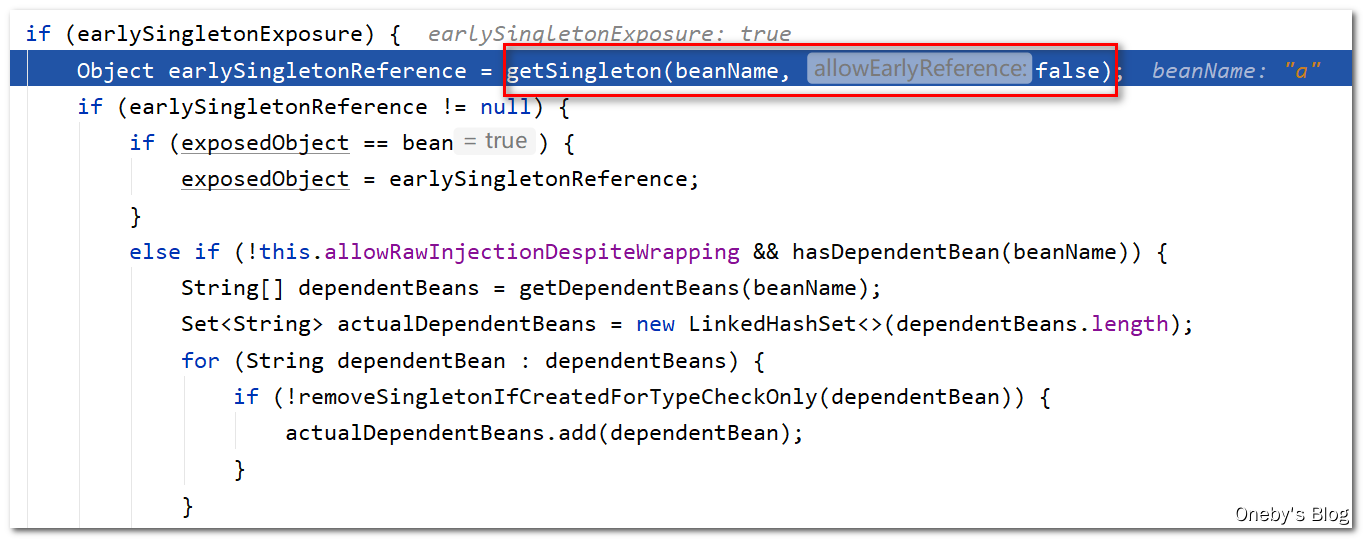
进入 getSingleton(beanName, false) 方法:
之前 beanB 中注入 a 属性时,将 beanA 从三级缓存 singletonFactories 移动到了二级缓存 earlySingletonObjects 中,因此可以从二级缓存 earlySingletonObjects 中获取到 beanA
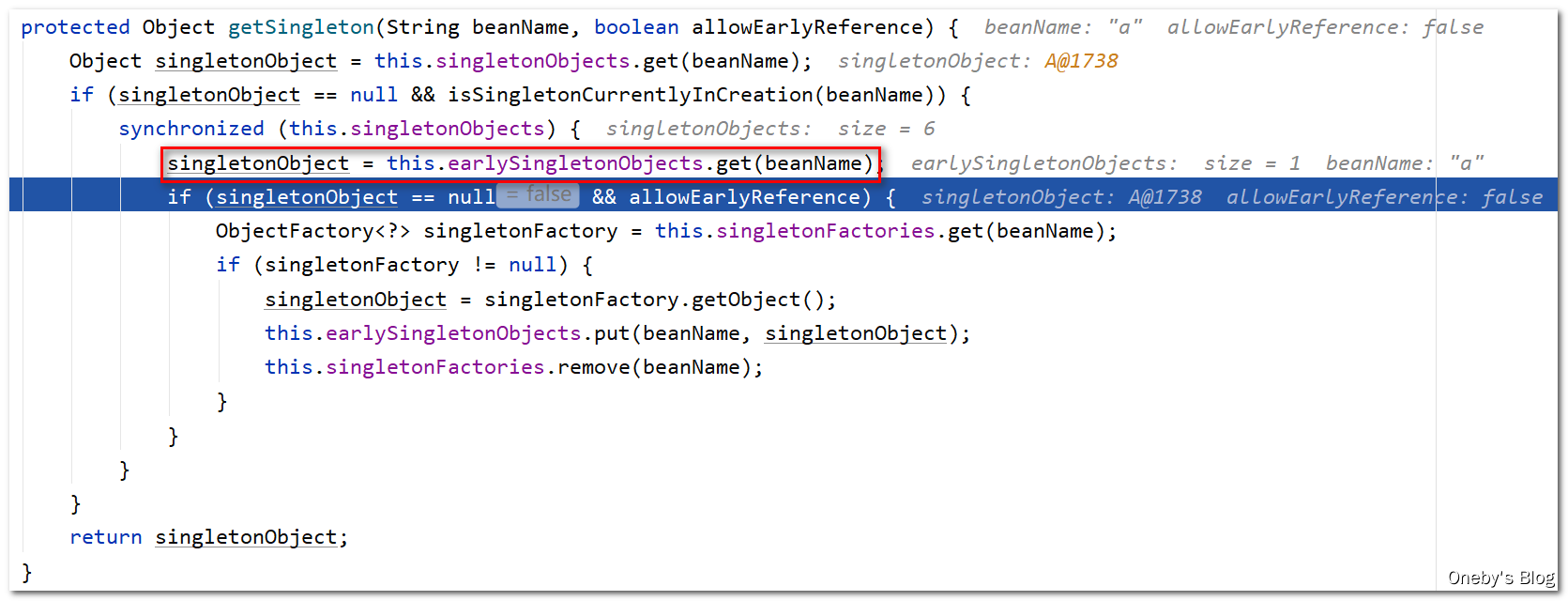
回到 doCreateBean(beanName, mbdToUse, args) 方法中:
最终将获取到的 beanA 返回
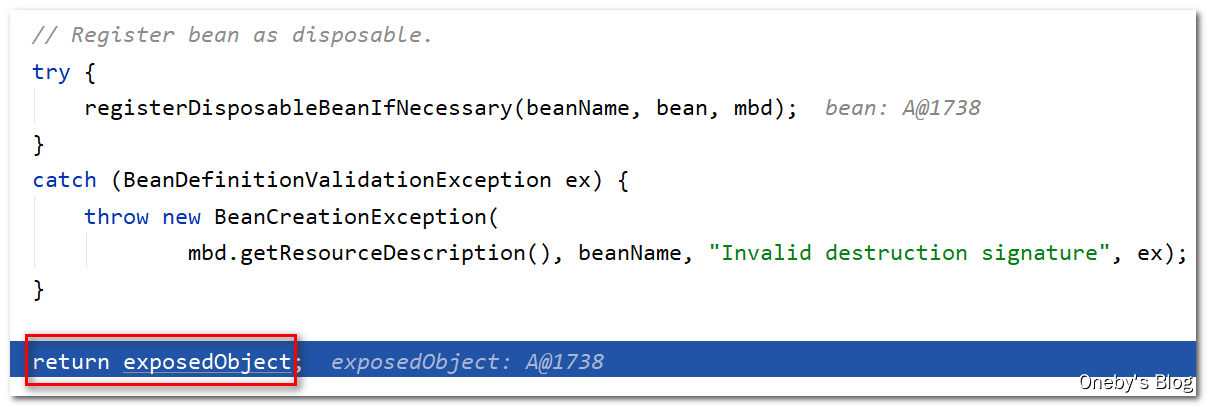
回到 createBean(beanName, mbd, args) 方法中:
执行 doCreateBean(beanName, mbdToUse, args) 方法后得到 beanA 实例,并将此实例返回
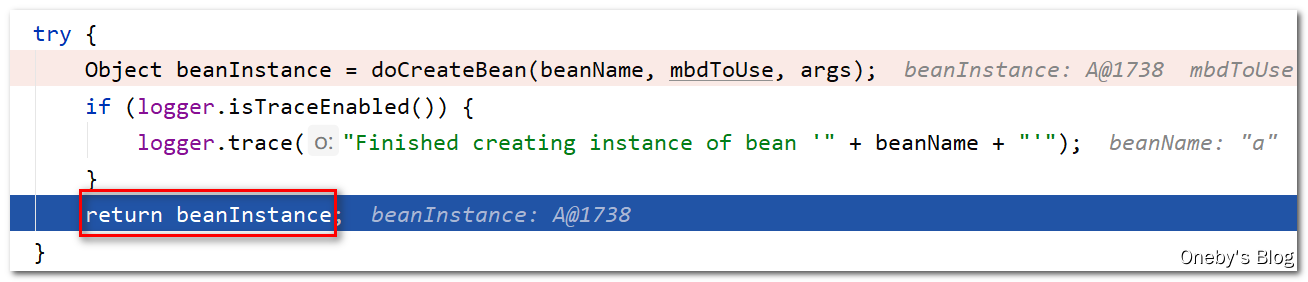
回到 getSingleton(beanName, () -> { ... } 方法:
执行 singletonFactory.getObject() 方法后将获得 beanA 实例,这里的 singletonFactory 是我们传入的 Lambda 表达式(专门用于创建 bean 实例)
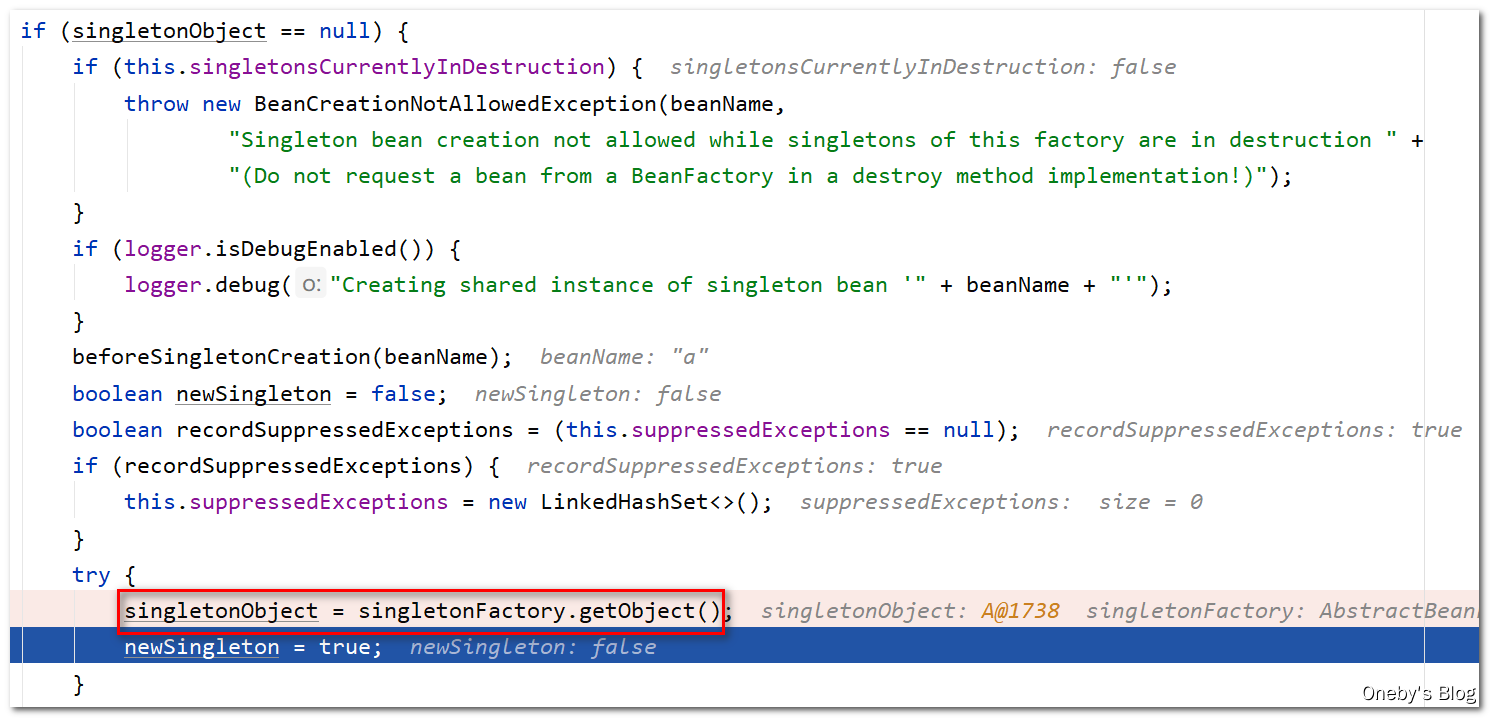
执行 addSingleton(beanName, singletonObject) 方法将 beanA 添加到一级缓存 singletonObjects 中
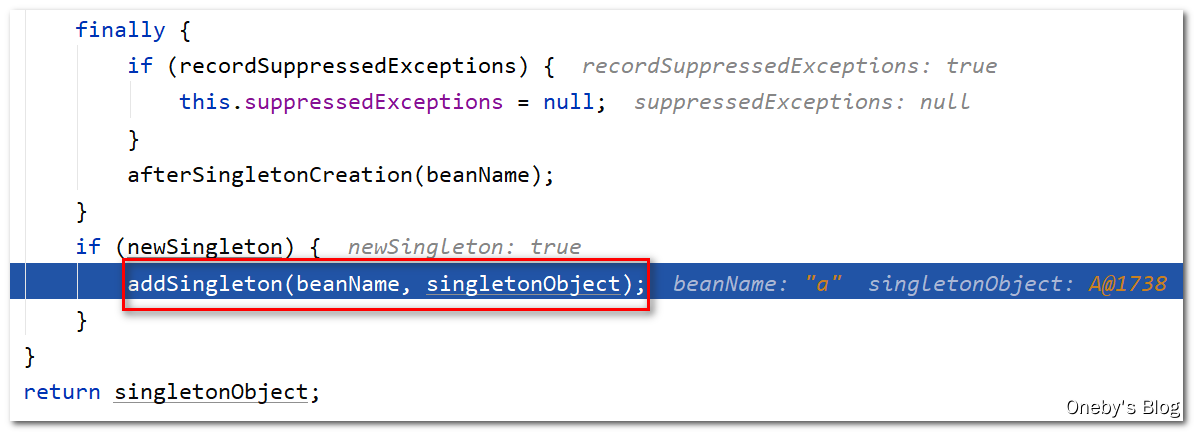
进入 addSingleton(beanName, singletonObject) 方法:
- 将 beanA 放入一级缓存 singletonObjects 中
- 将 beanA 从三级缓存 singletonFactories 中删除(beanA 并不在三级缓存中)
- 将 beanA 从二级缓存 earlySingletonObjects 中删除(beanA 确实在二级缓存中)
- 将 beanA 的 beanName 注册到 registeredSingletons 中(之前添加至三级缓存的时候已经注册过啦~)
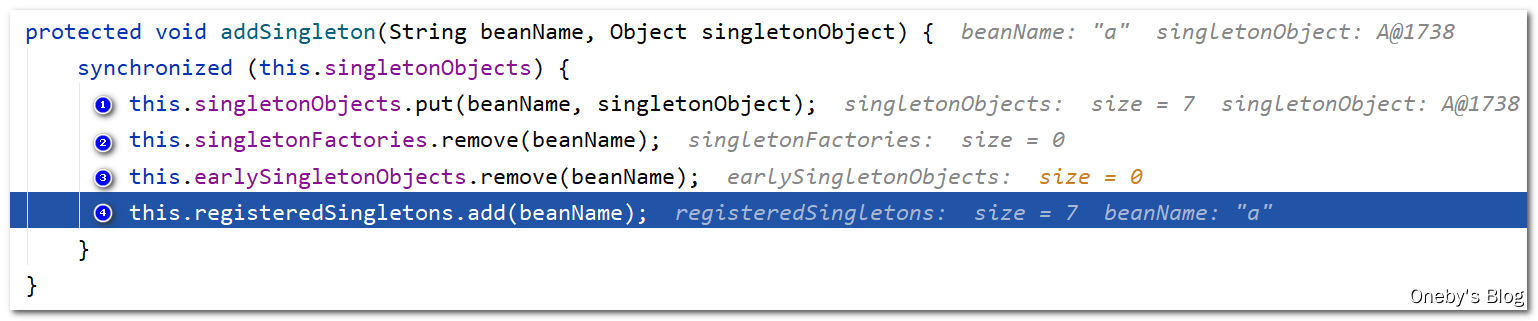
注:
- 此时的第三级、第二级缓存都没有东西了
- 在第一级缓存有两个已经实例化初始化好的成品:beanA与beanB
回到 getSingleton(beanName, () -> { ... } 方法中:
将 beanA 添加至一级缓存 singletonObjects 后,将其返回
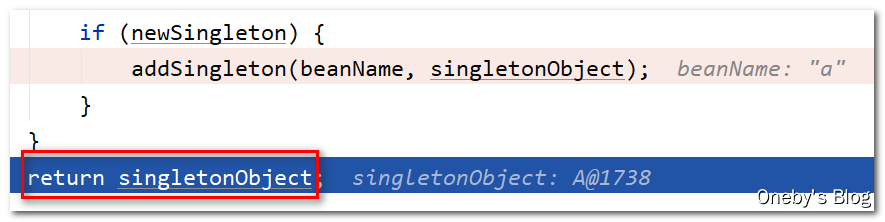
回到 doGetBean(name, null, null, false) 方法中:
执行 getSingleton(beanName, () -> { ... } 方法得到 beanA 实例后,将其返回
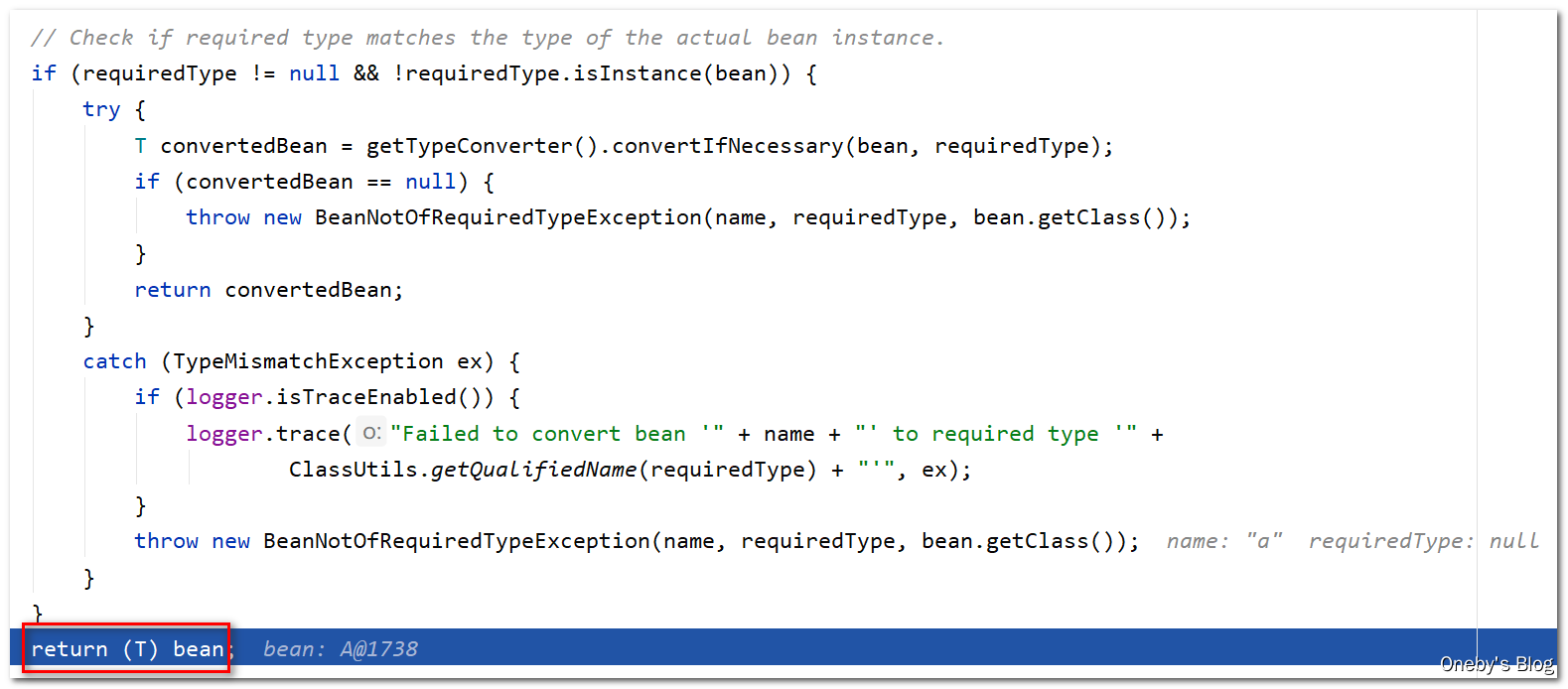
回到 preInstantiateSingletons() 方法中:
终于要结束了。。。执行完 getBean(beanName) 方法后,将得到无限套娃版本的 beanA 和 beanB 实例
6、循环依赖总结
全部 Debug 断点:
导出 Debug 所有断点:点击【View Breakpoints】
Debug 步骤总结:
- 调用
doGetBean()方法,想要获取beanA,于是调用getSingleton()方法从缓存中查找beanA - 在
getSingleton()方法中,从一级缓存中查找,没有,返回null doGetBean()方法中获取到的beanA为null,于是走对应的处理逻辑,调用getSingleton()的重载方法(参数为ObjectFactory的)去获取一个beanA单例- 在
getSingleton()方法中,先将beanA_name添加到一个集合中,用于标记该bean正在创建中。然后回调匿名内部类的creatBean()方法创建beanA对象 - 进入
AbstractAutowireCapableBeanFactory#doCreateBean(),先反射调用构造器创建出beanA的实例,然后判断。是否为单例、是否允许提前暴露引用(对于单例一般为true)**、是否正在创建中〈即是否在第四步的集合中)。判断为true则将beanA添加到【三级缓存】中** - 调用
populateBean()对beanA进行属性填充,此时检测到beanA依赖于beanB,于是开始从一级缓存当中查找beanB - 调用
doGetBean()方法,和上面beanA的过程一样,到一级缓存中查找beanB,没有则创建,然后给beanB填充属性 - 此时beanB依赖于beanA,调用
getSingleton()获取beanA,依次从一级、二级、三级缓存中找,此时从三级缓存中获取到beanA的创建工厂,通过创建工厂获取到singletonObject,此时这个singletonObject指向的就是上面在doCreateBean()方法中实例化的beanA - 这样beanB就获取到了beanA的依赖,于是beanB顺利完成实例化,将beanB从第三级缓存放在第一级缓存当中,并将beanA从三级缓存移动到二级缓存中
- 随后beanA继续他的属性填充工作,此时也获取到了beanB,beanA也随之完成了创建,回到
getsingleton()方法中继续向下执行,将beanA从二级缓存移动到一级缓存中
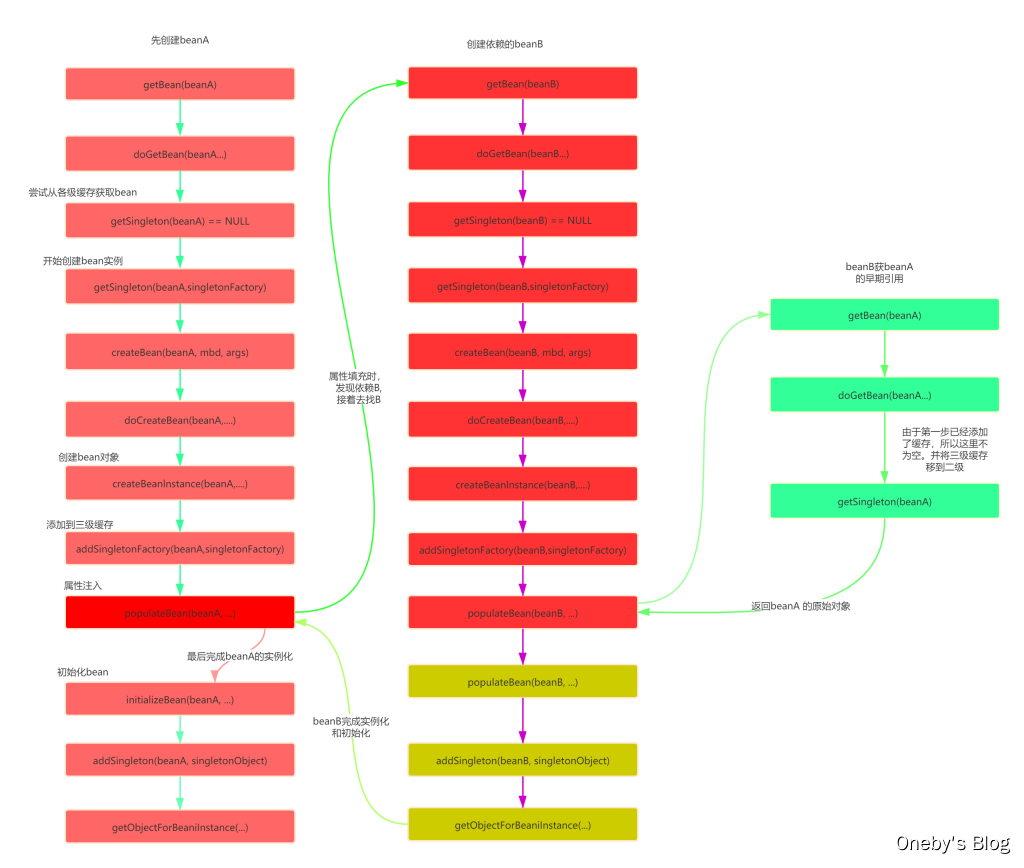
7、三级缓存总结
Spring 创建 Bean 的两大步骤:
- 创建原始bean对象
- 填充对象属性和初始化
每次创建bean之前,我们都会从缓存中查下有没有该bean,因为是单例,只能有一个。当我们创建 beanA的原始对象后,并把它放到三级缓存中,接下来就该填充对象属性了,这时候发现依赖了beanB,接着就又去创建beanB,同样的流程,创建完 beanB填充属性时又发现它依赖了beanA又是同样的流程。
==不同的是==:这时候可以在三级缓存中查到刚放进去的原始对象beanA,所以不需要继续创建,用它注入beanB,完成beanB的创建。既然 beanB创建好了,所以beanA就可以完成填充属性的步骤了,接着执行剩下的逻辑,闭环完成。
Spring解决循环依赖依靠的是Bean的“中间态”这个概念,而这个中间态指的是已经实例化但还没初始化的状态,也即半成品。
实例化的过程又是通过构造器创建的,如果A还没创建好出来怎么可能提前曝光,所以构造器的循环依赖无法解决。
Spring为了解决单例的循环依赖问题,使用了三级缓存:
- 其中一级缓存为单例池〈 singletonObjects),我们的应用中使用的bean对象就是一级缓存中的
- 二级缓存为提前曝光对象( earlySingletonObjects),用来解决对象创建过程中的循环依赖问题
- 三级缓存为提前曝光对象工厂( singletonFactories),用于处理存在 AOP 时的循环依赖问题
假设A、B循环引用,实例化A的时候就将其放入三级缓存中,接着填充属性的时候,发现依赖了B,同样的流程也是实例化后放入三级缓存,接着去填充属性时又发现自己依赖A,这时候从缓存中查找到早期暴露的A,没有AOP代理的话,直接将A的原始对象注入B,完成B的初始化后,进行属性填充和初始化,这时候B完成后,就去完成剩下的A的步骤,如果有AOP代理,就进行AOP处理获取代理后的对象A,注入B,走剩下的流程。
8、Spring循环依赖+AOP源码分析
1、情况一:没有依赖,有 AOP
此时, SimpleBean 对象在 Spring 中是如何创建的呢,我们一起来跟下源码
接下来,我们从 DefaultListableBeanFactory 的 preInstantiateSingletons 方法开始 debug
没有跟进去的方法,或者快速跳过的,我们可以先略过,重点关注跟进去了的方法和停留了的代码,此时有几个属性值中的内容值得我们留意下:

我们接着从 createBean 往下跟
关键代码在 doCreateBean 中,其中有几个关键方法的调用值得大家去跟下:

此时:代理对象的创建是在对象实例化完成,并且初始化也完成之后进行的,是对一个成品对象创建代理对象
所以此种情况下:只用一级缓存就够了,其他两个缓存可以不要
2、情况二:循环依赖,没有AOP
此时循环依赖的两个类是: Circle 和 Loop
对象的创建过程与前面的基本一致,只是多了循环依赖,少了 AOP,所以我们重点关注: populateBean 和 initializeBean 方法
先创建的是 Circle 对象,那么我们就从创建它的 populateBean 开始,再开始之前,我们先看看三级缓存中的数据情况
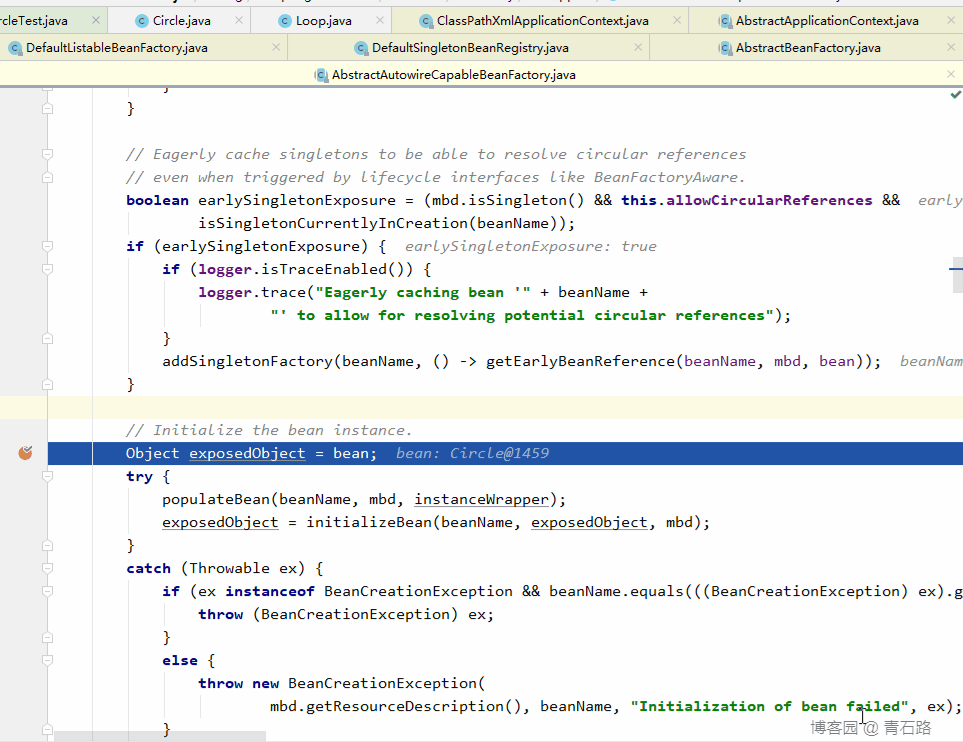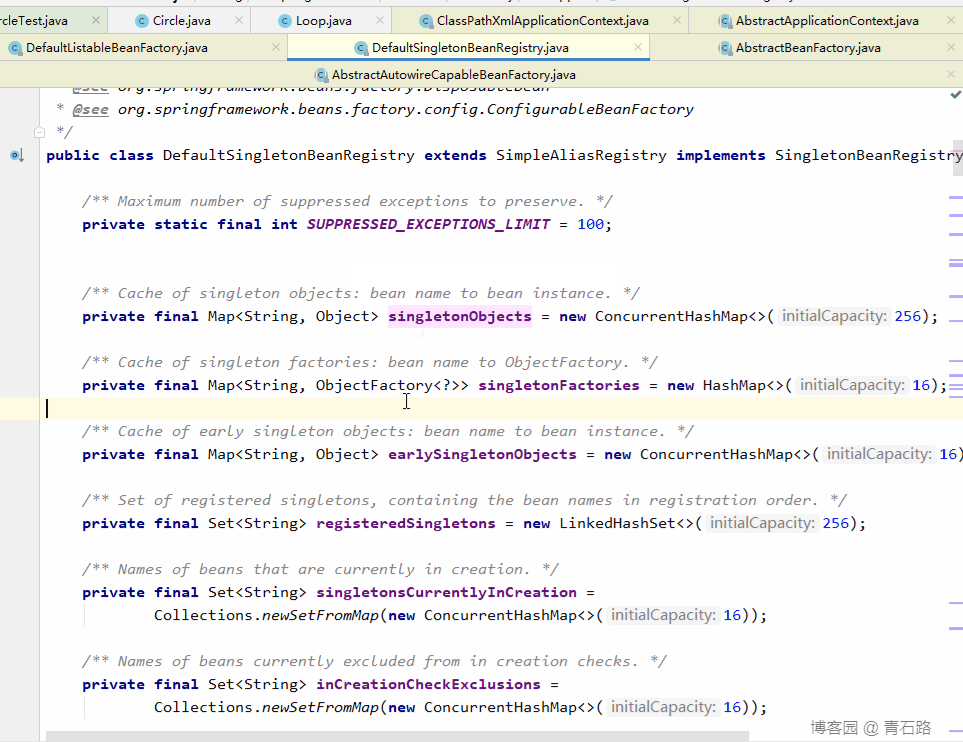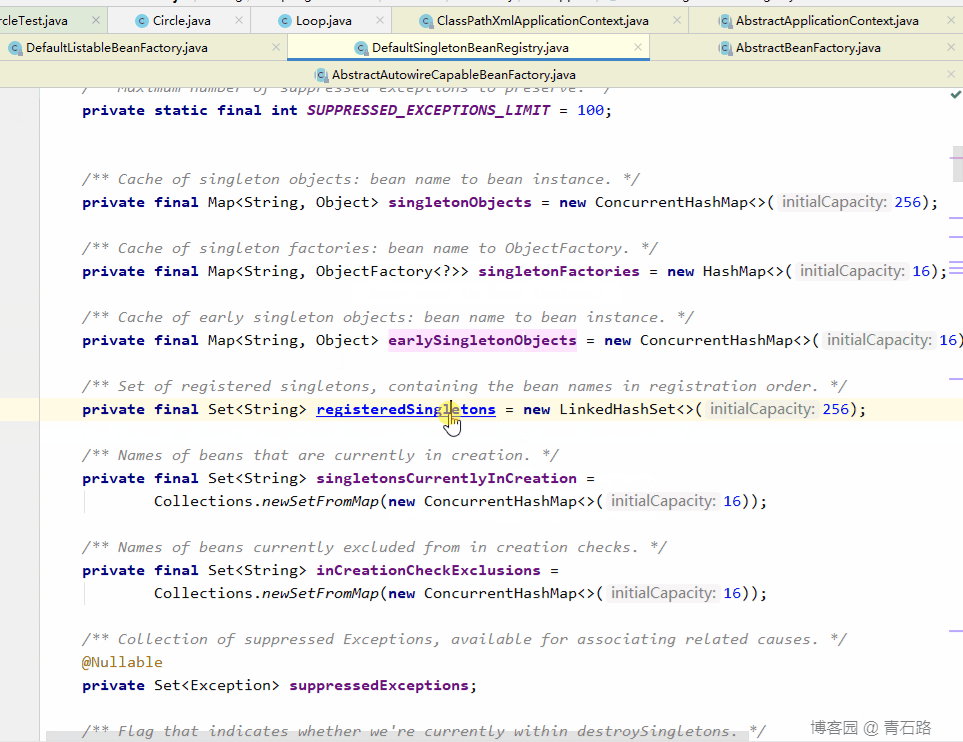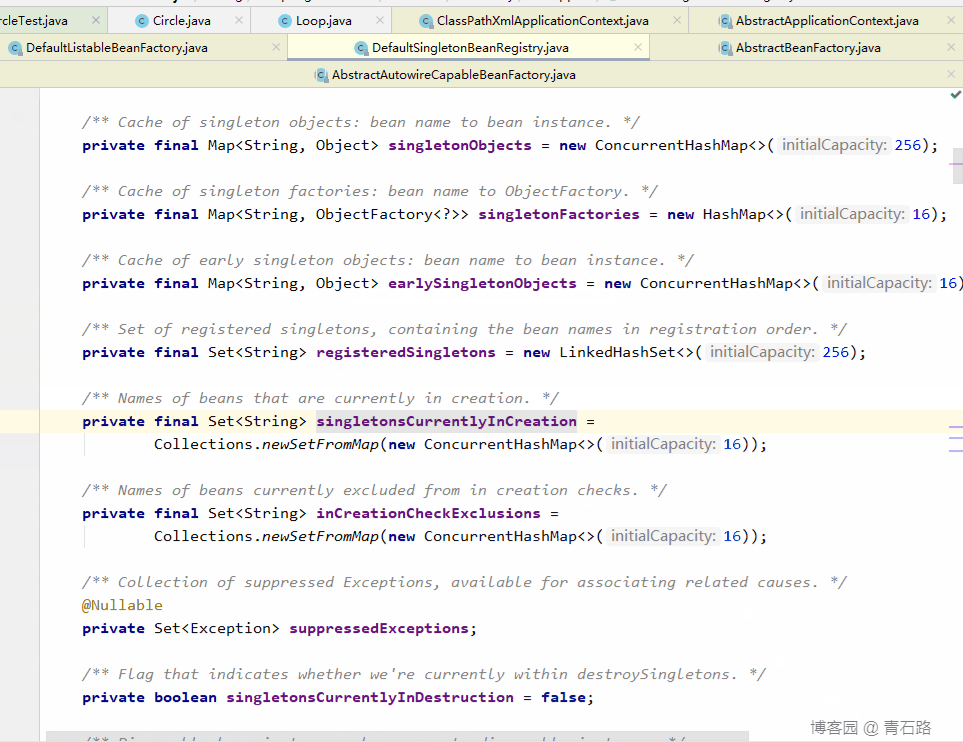

我们开始跟 populateBean ,它完成属性的填充,与循环依赖有关,一定要仔细看,仔细跟
对 circle 对象的属性 loop 进行填充的时候,去 Spring 容器中找 loop 对象,发现没有则进行创建,又来到了熟悉的 createBean
此时三级缓存中的数据没有变化,但是 Set<String> singletonsCurrentlyInCreation 中多了个 loop
相信到这里大家都没有问题,我们继续往下看
loop 实例化完成之后,对其属性 circle 进行填充,去 Spring 中获取 circle 对象,又来到了熟悉的 doGetBean
此时一、二级缓存中都没有 circle、loop ,而三级缓存中有这两个,我们接着往下看,重点来了,仔细看哦
通过 getSingleton 获取 circle 时,三级缓存调用了 getEarlyBeanReference ,但**由于没有 AOP,所以 getEarlyBeanReference 直接返回了普通的半成品 circle**,然后将 半成品 circle 放到了二级缓存,并将其返回,然后填充到了 loop 对象中
此时的 loop 对象就是一个成品对象了;接着将 loop 对象返回,填充到 circle 对象中,如下如所示
我们发现直接将 成品 loop 放到了一级缓存中,二级缓存自始至终都没有过 loop ,三级缓存虽说存了 loop ,但没用到就直接 remove 了
此时缓存中的数据,相信大家都能想到了:

虽说 loop 对象已经填充到了 circle 对象中,但还有一丢丢流程没走完,我们接着往下看
将 成品 circle 放到了一级缓存中,二级缓存中的 circle 没有用到就直接 remove 了,最后各级缓存中的数据相信大家都清楚了,就不展示了
我们回顾下这种情况下各级缓存的存在感,一级缓存存在感十足,二级缓存可以说无存在感,三级缓存有存在感(向 loop 中填充 circle 的时候有用到)
所以此种情况下:可以减少某个缓存,只需要两级缓存就够了
3、情况三:循环依赖 + AOP
比上一种情况多了 AOP,我们来看看对象的创建过程有什么不一样;同样是先创建 Circle ,在创建 Loop
创建过程与上一种情况大体一样,只是有小部分区别,跟源码的时候我会在这些区别上有所停顿,其他的会跳过,大家要仔细看
实例化 Circle ,然后填充 半成品 circle 的属性 loop ,去 Spring 容器中获取 loop 对象,发现没有
则实例化 Loop ,接着填充 半成品 loop 的属性 circle ,去 Spring 容器中获取 circle 对象
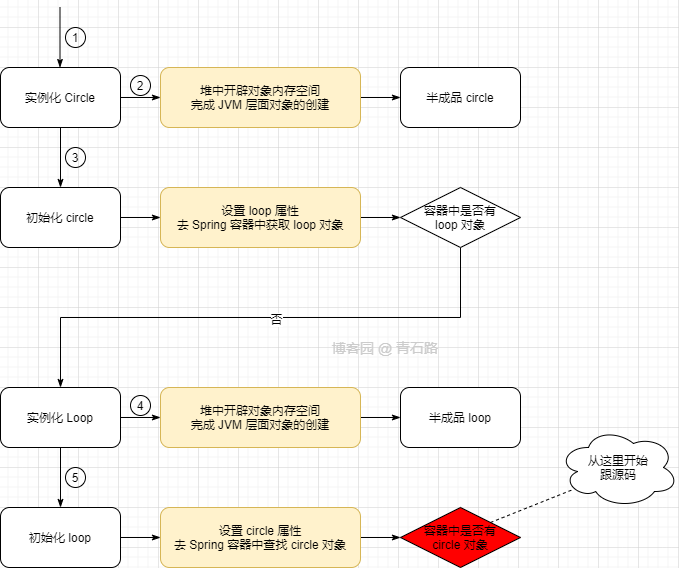
这个过程与前一种情况是一致的,就直接跳过了,我们从上图中的红色步骤开始跟源码,此时三级缓存中的数据如下

我们发现从第三级缓存获取 circle 的时候,调用了 getEarlyBeanReference 创建了 半成品 circle 的代理对象
将 半成品 circle 的代理对象放到了第二级缓存中,并将代理对象返回赋值给了 半成品 loop 的 circle 属性
注意:此时是在进行 loop 的初始化,但却把 半成品 circle 的代理对象提前创建出来了
loop 的初始化还未完成,我们接着往下看,又是一个重点,仔细看
在 initializeBean 方法中完成了 半成品 loop 的初始化,并在最后创建了 loop 成品 的代理对象
loop 代理对象创建完成之后会将其放入到第一级缓存中(移除第三级缓存中的 loop ,第二级缓存自始至终都没有 loop )
然后将 loop 代理对象返回并赋值给 半成品 circle 的属性 loop ,接着进行 半成品 circle 的 initializeBean
因为 circle 的代理对象已经生成过了(在第二级缓存中),所以不用再生成代理对象了;
将第二级缓存中的 circle 代理对象移到第一级缓存中,并返回该代理对象
此时各级缓存中的数据情况如下(普通 circle 、 loop 对象在各自代理对象的 target 中)

我们回顾下这种情况下各级缓存的存在感,一级缓存仍是存在感十足,二级缓存有存在感,三级缓存挺有存在感
第三级缓存提前创建 circle 代理对象,不提前创建则只能给 loop 对象的属性 circle 赋值成 半成品 circle ,==那么 loop 对象中的 circle 对象就无 AOP 增强功能了==
第二级缓存用于存放 circle 代理,用于解决循环依赖;也许在这个示例体现的不够明显,因为依赖比较简单,依赖稍复杂一些,就能感受到了
第一级缓存存放的是对外暴露的对象,可能是代理对象,也可能是普通对象

所以此种情况下:三级缓存一个都不能少
4、情况四:循环依赖 + AOP + 删除第三级缓存
没有依赖,有AOP 这种情况中,我们知道 AOP 代理对象的生成是在成品对象创建完成之后创建的,这也是 Spring 的设计原则,代理对象尽量推迟创建
循环依赖 + AOP 这种情况中, circle 代理对象的生成提前了,因为必须要保证其 AOP 功能,但 loop 代理对象的生成还是遵循的 Spring 的原则
如果我们打破这个原则,将代理对象的创建逻辑提前,那是不是就可以不用三级缓存了,而只用两级缓存了呢?
对 Spring 的源码做了非常小的改动,改动如下:
去除了第三级缓存,并将代理对象的创建逻辑提前,置于实例化之后,初始化之前;我们来看下执行结果:
并没有什么问题。
5、情况五:循环依赖 + AOP + 注解
目前基于 xml 的配置越来越少,而基于注解的配置越来越多,所以了也提供了一个注解的版本供大家去跟源码
代码还是很简单:spring-circle-annotation
跟踪流程与 循环依赖 + AOP 那种情况基本一致,只是属性的填充有了一些区别,具体可查看:Spring 的自动装配 → 骚话 @Autowired 的底层工作原理
6、总结
- 三级缓存各自的作用
- 第一级缓存的是对外暴露的对象,也就是我们应用需要用到的
- 第二级缓存的作用是==为了处理循环依赖的对象创建问题==,里面存的是半成品对象或半成品对象的代理对象
- 第三级缓存的作用==处理存在 AOP + 循环依赖的对象创建问题==,能将==代理对象提前创建==
- Spring 为什么要引入第三级缓存
- 严格来讲,第三级缓存并非缺它不可,因为可以提前创建代理对象
- 提前创建代理对象只是会节省那么一丢丢内存空间,并不会带来性能上的提升,但是会破环 Spring 的设计原则
- Spring 的设计原则是尽可能保证普通对象创建完成之后,再生成其 AOP 代理(尽可能延迟代理对象的生成)
- 所以 Spring 用了第三级缓存,既维持了设计原则,又处理了循环依赖;牺牲那么一丢丢内存空间是愿意接受的
9、循环依赖于三级缓存相关面试解答
1、说下什么是循环依赖
两个或则两个以上的bean对象互相依赖对方,最终形成 闭环 。例如 A 对象依赖 B 对象,B 对象也依赖 A 对象

2、那循环依赖会有什么问题呢
在bean对象的创建过程会产生死循环,类似如下
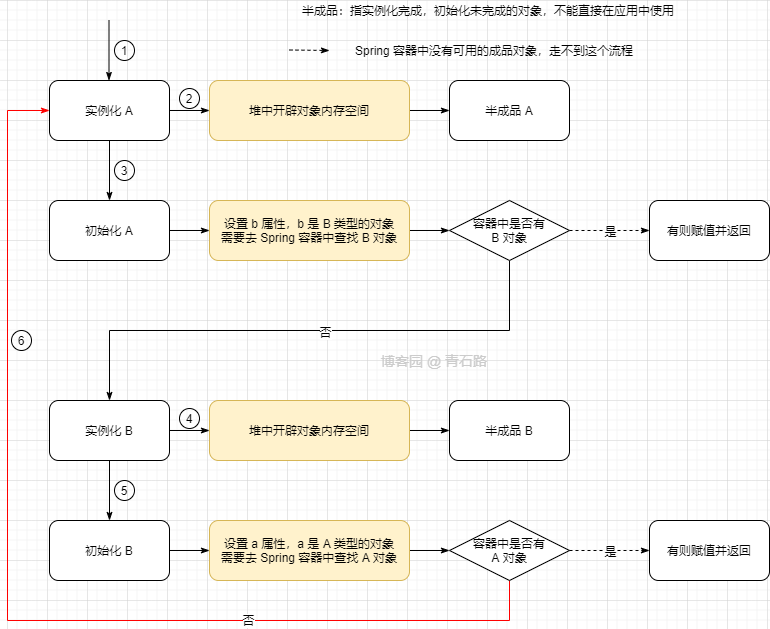
3、那么Spring 是如何解决的呢?
通过三级缓存提前暴露bean对象来解决的
4、三级缓存里面分别存的什么
三级缓存就是三个map对象
- 一级缓存是一个ConcurrentHashMap,容量为256,里面存的是成品对象,实例化和初始化都完成了,我们的应用中使用的对象就是一级缓存中的
- 二级缓存是一个HashMap,容量为16,里面存的是半成品,用来解决对象创建过程中的循环依赖问题
- 三级缓存是一个HashMap,容量为16,里面存的是 ObjectFactory<?> 类型的 lambda 表达式,用于处理存在 AOP 时的循环依赖问题

5、Spring使用三级缓存解决循环依赖的前提是什么?
有两个前提:
bean是单例实例,即scope的属性为singleton
- 因为如果是scope的属性为prototype原型,那么每一次创建的bean对象都是新对象,不会走三级缓存。
bean对象的依赖注入方式不能全是构造器注入的方式
Spring解决循环依赖依靠的是Bean的“中间态”这个概念,而这个中间态指的是已经实例化但还没初始化的状态,也即半成品。
实例化的过程又是通过构造器创建的,如果A还没创建好出来怎么可能提前曝光,所以构造器的循环依赖无法解决
也就是说:
- 构造方法注入的方式,将实例化与初始化并在一起完成,能够快速创建一个可直接使用的对象
- setter 方法注入的方式,是在对象实例化完成之后,再通过反射调用对象的 setter 方法完成属性的赋值。将对象的实例化与初始化分隔开了
那又为什么说不能全是构造器注入的方式
依赖情况 依赖注入方式 循环依赖是否被解决 AB相互依赖(循环依赖) 均采用setter方式注入 是 AB相互依赖(循环依赖) 均采用构造器方式注入 否 AB相互依赖(循环依赖) A注入B的方式为setter,B注入A的方式为构造器 是 AB相互依赖(循环依赖) B注入A的方式为setter,A注入B的方式为构造器 否
为什么在下表中的第三种情况的循环依赖能被解决,而第四种情况不能被解决呢?
Spring在创建Bean时默认会根据自然排序进行创建,所以A会先于B进行创建。
6、为什么要用三级缓存来解决循环依赖问题(只用一级缓存行不行,只用二级缓存行不行)
只用一级缓存也是可以解决的,但是会复杂化整个逻辑
半成品对象是没法直接使用的(存在 NPE 问题),所以 Spring 需要保证在启动的过程中,所有中间产生的半成品对象最终都会变成成品对象。
如果将半成品对象和成品对象都混在一级缓存中,那么为了区分他们,势必会增加一些而外的标记和逻辑处理,这就会导致对象的创建过程变得复杂化了。
将半成品对象与成品对象分开存放,两级缓存各司其职,能够简化对象的创建过程,更简单、直观。
如果 Spring 不引入 AOP,那么两级缓存就够了,但是作为 Spring 的核心之一,AOP 怎能少得了呢?
所以为了处理 AOP代理时的循环依赖,Spring 引入第三级缓存来处理循环依赖时的代理对象的创建。
如果要使用二级缓存解决循环依赖,意味着所有Bean在实例化后就要完成AOP代理,这样违背了Spring设计的原则,Spring在设计之初就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来在Bean生命周期的最后一步来完成AOP代理,而不是在实例化后就立马进行AOP代理。
7、如果将代理对象的创建过程提前,紧随于实例化之后,而在初始化之前,那是不是就可以只用两级缓存了?
可以,没有问题。但是会破坏Spring的设计原则:尽可能保证普通对象创建完成之后,再生成其 AOP 代理(尽可能延迟代理对象的生成)
Linux
1、Linux常用服务类相关命令
1、service (Centos6)
注册在系统中的标准化程序
有方便统一的管理方式(常用的方法)
- service 服务名 start:开启服务
- service 服务名 stop:关闭服务
- service 服务名 restart:重启服务
- service 服务名 reload:重新加载服务
- service 服务名 status:查看当前服务的状态
查看服务的方法:
/etc/init.d/服务名通过chkconfig命令设置自启动
查看服务
1
chkconfig --list | grep xxx
设置服务是否开机自启动
1
chkconfig --level 5 服务名 off

2、systemctl (Centos7)
注册在系统中的标准化程序
有方便统一的管理方式(常用的方法)
- systemctl start 服务名(xxxx.service):开启服务
- systemctl restart 服务名(xxxx.service):重启服务
- systemctl stop 服务名(xxxx.service):关闭服务
- systemctl reload 服务名(xxxx.service):重新加载服务
- systemctl status 服务名(xxxx.service):查看当前服务的状态
查看服务的方法:
/usr/lib/systemd/system查看服务的命令
1
2
3
4
5
6systemctl list-unit-files
# 可以使用grep进行过滤
systemctl list-unit-files | grep xxx
systemctl --type service通过systemctl命令设置自启动
1
2
3
4
5# 开机自启动
systemctl enable service_name
# 开机不自启动
systemctl disable service_name
Git
1、git分支相关命令
创建分支
1
2
3
4
5# 创建分支
git branch <分支名>
# 查看分支
git branch -v <分支名>切换分支
1
2
3
4git checkout <分支名>
# 一步完成:创建分支并切换到该分支(最常用)
git checkout -b <分支名>合并分支
1
2
3
4
5# 先切换到主分支
git checkout master
# 合并分支
git merge <分支名>删除分支
1
2
3
4
5# 先切换到主分支
git checkout master
# 删除分支
git branch -D <分支名>
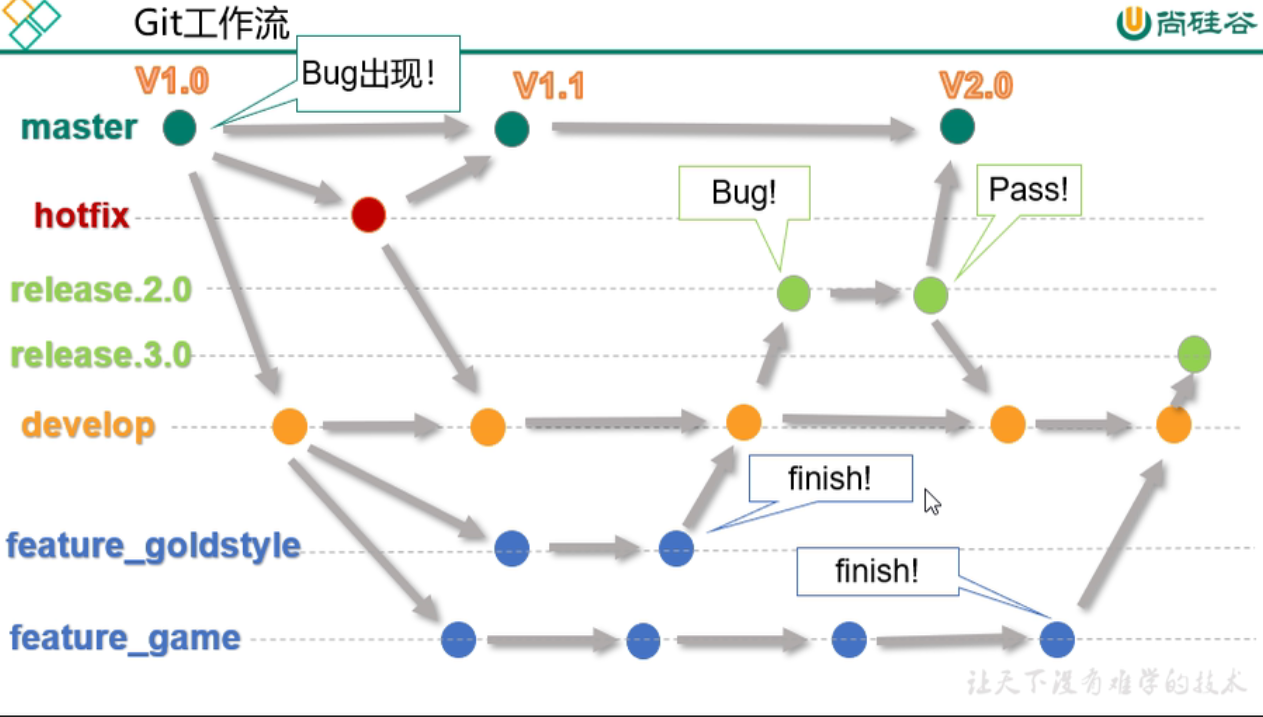
2、请讲一下Git的工作流
- 在master主分支下分出develop开发分支进行开发工作
- master一般是项目经理或者运维人员才能操作的
- 开发人员接触的最多的就是develop分支
- 注意:master分支和develop要保持一致
- 在develop分支下,根据项目的不同模块再分出对应的开发分支
- 如果在master主分支(上线)出现了bug,那么master会分出hotfix分支进行bug的修复工作
- bug修复过后在下线master分支,将hotfix分支合并到master之后在上线
- 同时要将hotfix分支合并到develop分支当中,保证master分支和develop要保持一致,防止将来把develop分支合并到master主分支出现重复的bug
- 当模块的开发工作完成之后,将对应模块的开发分支提交到develop分支当中,并创建release分支查看是否有bug,如果有bug的话进行修复。最终合并到master主分支当中进行上线
3、GitHub的常用词
watch:会持续收到该项目的动态fork:复制某个项目到自己的GitHub仓库star:点赞clone:将项目下载至本地follow:关注你感兴趣的作者,会收到他们的动态
4、in关键字限制搜索范围
公式:
1 | [要搜索的关键字] in name 或description 或readme |
- xxx in:name——项目名包含xxx的
- xxx in:description——项目描述包含xxx的
- xxx in:readme——项目的readme文件中包含xxx的
组合使用:
1 | # 搜索项目名或者readme或者项目描述中包含秒杀的项目 |
5、stars或fork数量关键词去查找
stars的公式:
1 | [要搜索的关键字] stars 通配符[:> 或者 :>=] |
forks的公式:
1 | [要搜索的关键字] forks 通配符[:> 或者 :>=] |
组合使用:
1 | # 查找fork在100到200之间并且stars数在80到100之间的springboot项目 |
6、awesome加强搜索
公式:
1 | awesome 关键字 |
awesome系列一般是用来学习、工具、书籍类相关的项目
使用:搜索优秀的redis相关的项目,包括框架、教程等
1 | awesome redis |
7、高亮显示某一行代码
公式:
1 | # 1行 |
8、项目内搜索
在键盘输入英文t,此时路径会变成xxx/find/master。网页的代码呈现一个树状的结构,方便我们查看源码和相关框架。
9、搜索某个地区内的大佬
公式:
1 | location:地区 language:语言 |
使用:
1 | # 搜索地区在北京的Java方向的大佬 |
Redis
1、redis持久化
Redis提供了2个不同形式的持久化方式。
- RDB (Redis DataBase)
- AOF (Append Of File)
1、RDB
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
备份是如何执行的?
- Redis会单独创建(fork) 一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。
- 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
- RDB的缺点是最后一次持久化后的数据可能丢失。
RDB的优缺点:
- 优点:
- 节省磁盘空间
- 恢复速度快
- 缺点:
- 虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。
- 在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
2、AOF
以日志的形式来记录每个==写==操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据,换言之,Redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
备份是如何执行的?
AOF与RDB类似,都是依靠一个fork子进程和一个缓冲区进行写指令的备份的。而且AOF在进行写指令备份的时候,可以开启重写机制来提高性能
AOF的优缺点:
- 优点:
- 备份机制更稳健,丢失数据概率更低。
- 可读的日志文本,通过操作AOF稳健,可以处理误操作。
- 缺点:
- 恢复备份速度要慢。
- 每次读写都同步的话,有一定的性能压力。
- 存在个别Bug,造成恢复不能。

2、Redis在项目中的使用场景
| 数据类型 | 使用场景 |
|---|---|
| String | 比如说,①我想知道什么时候封锁一个IP地址。 可以使用命令 Incrby记录当前IP访问的次数,达到一定的次数就封锁该IP②设置分布式锁:set key value [Ex seconds] [PX milliseconds] [NX|XX] 参数解释: 1.EX:key在多少秒之后过期 2.PX:key在多少毫秒之后过期 3.NX:当key不存在的时候,才创建key,效果等同于setnx key value 4.XX:当key存在的时候,覆盖key ③商品编号、订单号采用 INCR 命令生成 ④文章阅读量、点赞数和在看数 |
| Hash | redis 中的 hash 类似于 java 中的 Map<String,Map<Object,object>> 数据结构,即以字符串为 key,以 Map 对象为 value①存储用户信息【id,name,age】 hset(key,field,value) hset(userKey,id,101) hset(userKey,name,admin) hset(userKey,age,23) —-修改案例—- hget(userKey,id) hset(userKey,id,102) 为什么不使用String类型来存储 set(userKey,用信息的字符串) get(userKey) 不建议使用 String 类型存储用户信息 ②购物车早期版本,可在小中厂项目中使用 1.新增商品: hset shopcut:uid1024 sid334488 12.新增商品: hset shopcut:uid1024 sid337788 13.增加商品数量2: hincrby shopcut:uid1024 sid337788 24.查看商品总数: hlen shopcut:uid10245.全部选择: hgetall shopcut:uid1024 |
| List | 与其说 list 是个集合,还不如说 list 是个双端队列。 ①实现最新消息的排行,还可以利用List的 push命令,将任务存在list集合中,同时使用另一个命令pop,将任务从集合中取出。Redis—list数据类型来模拟消息队列。【电商中的秒杀就可以采用这种方式来完成一个秒杀活动】 ②微信文章订阅公众号 1.比如我订阅了如下两个公众号,他们发布了两篇文章,文章 ID 分别为 666 和 888,可以通过执行 LPUSH likearticle:onebyId 666 888 命令推送给我2.查看我自己的号订阅的全部文章,类似分页,下面0~10就是一次显示10条: LPUSH likearticle:onebyId 0 10 |
| Set | 特殊之处:可以自动排重。比如说微博中将每个人的好友存在集合(Set)中,这样①求两个人的共通好友的操作。我们只需要求交集即可 ②微信抽奖小程序: 1.如果某个用户点击了立即参与按钮,则执行 sadd key useId 命令将该用户 ID 添加至 set 中2.显示已经有多少人参与了抽奖: SCARD key3.抽奖(从set中任意选取N个中奖人) 3.1.随机抽奖2个人,元素不删除: SRANDMEMBER key 23.2.随机抽奖3个人,元素会删除: SPOP key 3③微信朋友圈点赞: 1.新增点赞: SADD pub:msgID 点赞用户ID1 点赞用户ID22.取消点赞: SREM pub:msgID 点赞用户ID3.展现所有点赞过的用户: SMEMBERS pub:msgID4.点赞用户数统计,就是常见的点赞红色数字: SCARD pub.msgID5.判断某个朋友是否对楼主点赞过: SISMEMBER pub:msgID 用户ID④QQ内推可能认识的人 QQ 内推可能认识的好友: SDIFF 我的好友 Ta的好友 |
| ZSet | 以某一个条件为权重,进行排序。 京东:①商品详情的时候,都会有一个综合排名,还可以按照商品销售量进行排名。 思路:定义商品销售排行榜(sorted set集合),key为goods:sellsort,分数为商品销售数量。 1.商品编号1001的销量是9,商品编号1002的销量是15: ZADD goods:sellsort 9 1001 15 10022.有一个客户又买了2件商品1001,商品编号1001销量加2: ZINCRBY goods:sellsort 2 10013.求商品销量前10名: ZRANGE goods:sellsort 0 10 WITHSCORES②抖音/微博热搜 1.点击视频增加播放量: ZINCRBY hotvcr:20200919 1八佰,ZINCRBY hotvcr:20200919 15 八佰 2 花木兰2.展示当日排行前10条: ZREVRANGE hotvcr:20200919 0 9 WITHSCORES |
3、Redis 6.0.7的bug
Redis突然发布了紧急版本 6.0.8 ,之前消息称 6.0.7 被称作最后一个 6.x 版本,但 Redis 团队表示 6.0.8 版本升级迫切性等级为高:任何将 Redis 6.0.7 与 Sentinel 或 CONFIG REWRITE 命令配合使用的人都会受到影响,应尽快升级。
从官方给出的信息来看,估计是出现了Bug,具体更新的内容如下:
- Bug修复
- CONFIG REWRITE在通过CONFIG设置oom-score-adj-values后,可以通过CONFIG设置或从配置文件中加载,会生成一个损坏的配置文件。将会导致Redis无法启动
- 修正MacOS上redis-cli –pipe的问题。
- 在不存在的密钥上,修复HKEYS/HVALS的RESP3响应。
- 各种小的错误修复
- 新功能
- 当设置为madvise时,移除THP警告。
- 允许在群集中只读副本上使用读命令进行EXEC。
- 在redis-cli-cluster调用命令中增加master/replicas选项。
- 模块化API
- 添加
RedisModule_ThreadSafeContextTryLock。
- 添加
官网地址:
- 官网地址:https://redis.io/
- 中文官网地址:http://www.redis.cn/
查看当前Redis版本的方法:
- 在 Linux 命令行下:在 redis 安装目录下执行
redis-server -v命令 - 在 redis 客户端命令行下:执行
info命令,第二行就是当前启动的Redis的版本
4、Redis 命令大全
直接搜索即可
如果当前不能使用外网或者不能进行线上查看,可以使用Redis自带的help指令:help @关键字
eg:help @String
注意事项:执行 redis 指令可能会出现如下错误:(error) MISCONF Redis is configured to save RDB snapshots, but it is currently not able to persist on disk. Commands that may modify the data set are disabled, because this instance is configured to report errors during writes if RDB snapshotting fails (stop-writes-on-bgsave-error option). Please check the Redis logs for details about the RDB error.
原因分析:究其原因是因为强制把 redis 快照关闭了导致不能持久化的问题,在网上查了一些相关解决方案,通过 stop-writes-on-bgsave-error 值设置为 no 即可避免这种问题。
解决方案一:通过 redis 命令行修改,在 redis 命令行执行 config set stop-writes-on-bgsave-error no 指令
解决方案二:直接修改 redis.conf 配置文件,使用 vim 编辑器打开 redis-server 配置的 redis.conf 文件,然后使用快捷匹配模式:/stop-writes-on-bgsave-error 定位到 stop-writes-on-bgsave-error 字符串所在位置,接着把后面的 yes 设置为 no 即可。
5、Redis的分布式锁
知道分布式锁吗?有哪些实现方案? 你谈谈对redis分布式锁的理解, 删key的时候有什么问题?
单机版的锁与分布式锁:
- JVM层面的加锁,单机版的锁
- 分布式微服务架构,拆分后各个微服务组件为了避免冲突和数据故障而加入的一种锁,分布式的锁
分布式锁的几种实现方式:
- mysql
- zookeeper
- redis
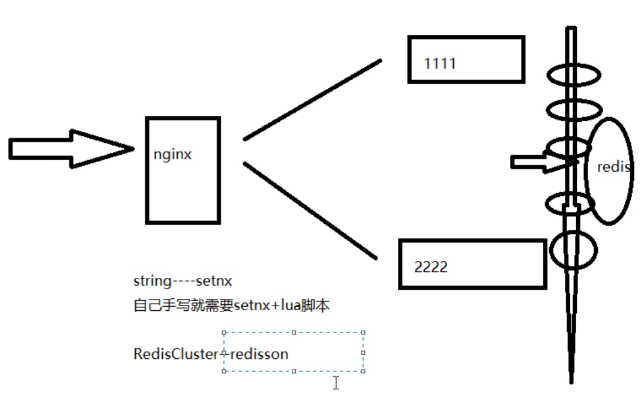
一般的互联网公司,大家都习惯用redis做分布式锁
redis ==》 redlock ==》 redisson
1、分布式锁的常见面试题
- Redis除了拿来做缓存,你还见过基于Redis的什么用法?
- Redis做分布式锁的时候有需要注意的问题?
- 如果是Redis是单点部署的,会带来什么问题? 那你准备怎么解决单点问题呢?
- 集群模式下,比如主从模式,有没有什么问题呢?
- 那你简单的介绍一下Redlock吧? 你简历上写redisson,你谈谈
- Redis分布式锁如何续期?看门狗知道吗?
2、为什么需要分布式锁?分布式锁的最终形成
1、版本1.0:单机版&没加锁
问题:单机版程序没有加锁,在并发测试下数字不对,会出现并发安全问题
解决:加锁,那么问题又来了,加 synchronized 锁还是 ReentrantLock 锁呢?
synchronized:不见不散,等不到锁就会死等ReentrantLock:过时不候,lock.tryLock()提供一个过时时间的参数,时间一到自动放弃锁
如何选择:根据业务需求来选,如果非要抢到锁不可,就使用 synchronized 锁;如果可以暂时放弃锁,等会再来强,就使用 ReentrantLock 锁
2、版本2.0:单机版&加锁
使用 synchronized 锁保证单机版程序在并发下的安全性
注意事项:
- 在单机环境下,可以使用
synchronized锁或Lock锁来实现。 - 但是在分布式系统中,因为竞争的线程可能不在同一个节点上(同一个 jvm 中)即不同线程抢夺的不是同一把锁,所以需要一个让所有进程都能访问到的锁来实现,比如 redis 或者 zookeeper 来构建;
- 不同进程 jvm 层面的锁就不管用了,那么可以利用第三方的一个组件,来获取锁,未获取到锁,则阻塞当前想要运行的线程
3、版本3.0:分布式版&不加分布式锁
分布式部署之后,单机版的锁失效,撤销单机版的锁,并且在微服务之上,挡了一个 nginx 服务器,用于实现负载均衡的功能
在jmeter的压测下出现并发问题
4、版本4.0:分布式版&用redis做分布式锁
Redis具有极高的性能,且其命令对分布式锁支持友好,借助 SET 命令即可实现加锁处理
设置分布式锁:set key value [Ex seconds] [PX milliseconds] [NX|XX]
参数解释:
- EX:key在多少秒之后过期
- PX:key在多少毫秒之后过期
- NX:当key不存在的时候,才创建key,效果等同于setnx key value
- XX:当key存在的时候,覆盖key
代码层面:
使用当前请求的 UUID + 线程名作为分布式锁的 value:
1 | // 当前请求的 UUID + 线程名 |
使用setnx命令的jedis来加分布式锁
1 | // 分布式锁 |
进程抢占分布式锁,如果抢占失败,则返回值为 false;如果抢占成功,则返回值为 true。
最后记得解锁:
1 | // 释放分布式锁 |
5、版本5.0:finally版
上面代码存在的问题:如果代码在执行的过程中出现异常,那么就可能无法释放锁,因此必须要在代码层面加上 finally 代码块,保证锁的释放
1 | try { |
6、版本6.0:过期时间版
上面代码存在的问题:假设部署了微服务 jar 包的服务器挂了,代码层面根本没有走到 finally 这块,也没办法保证解锁。既使之后该服务器重新启动,这个 key 也没有被删除,其他微服务就一直抢不到锁,因此我们需要加入一个过期时间限定的 key
使用setex命令的jedis来加分布式锁的过期时间
1 | // setIfAbsent() 就相当于 setnx,如果不存在就新建锁 |
7、版本7.0:加锁原子版
上面代码存在的问题:加锁与设置过期时间的操作分开了,假设服务器刚刚执行了加锁操作,然后宕机了,也没办法保证解锁。——没能保证加锁与过期时间的原子性
使用setIfAbsent的重载方法来保证原子性:
1 | // setIfAbsent() 就相当于 setnx,如果不存在就新建锁,同时加上过期时间保证原子性 |
8、版本8.0:加UUID防止张冠李戴
上面代码存在的问题:张冠李戴,删除了别人的锁:我们无法保证一个业务的执行时间,有可能是 10s,有可能是 20s,也有可能更长。因为执行业务的时候可能会调用其他服务,我们并不能保证其他服务的调用时间。如果设置的锁过期了,当前业务还正在执行,那么就有可能出现并发问题,并且还有可能出现当前业务执行完成后,释放了其他业务的锁
如下图,假设进程 A 在 T2 时刻设置了一把过期时间为 30s 的锁,在 T5 时刻该锁过期被释放,在 T5 和 T6 期间,Test 这把锁已经失效了,并不能保证进程 A 业务的原子性了。于是进程 B 在 T6 时刻能够获取 Test 这把锁,但是进程 A 在 T7 时刻删除了进程 B 加的锁,进程 B 在 T8 时刻删除锁的时候就蒙蔽了,我 TM 锁呢?
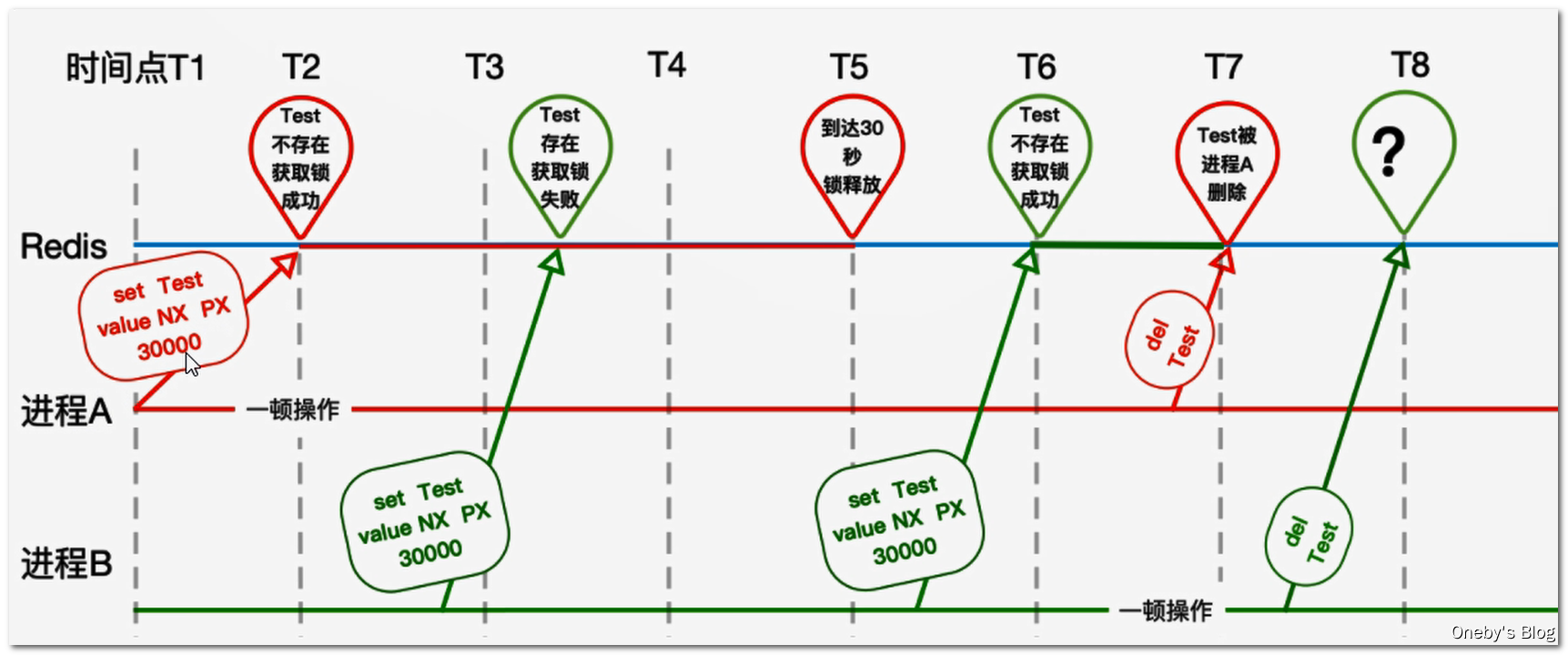
因此可以在解锁之前使用UUID判断当前的锁是不是自己的锁
1 | // 当前请求的 UUID + 线程名 |
9、版本9.0:解锁原子性
上面代码存在的问题:在 finally 代码块中的判断与删除并不是原子操作,假设执行 if 判断的时候,这把锁还是属于当前业务,但是有可能刚执行完 if 判断,这把锁就被其他业务给释放了,还是会出现误删锁的情况
1、版本9.1:解锁原子性——lura脚本保证解锁原子性操作(常用)
redis 可以通过 eval 命令保证代码执行的原子性

代码:
1、**RedisUtils 工具类**:
getJedis() 方法用于从 jedisPool 中获取一个连接块对象
1 | public class RedisUtils { |
2、使用 lua 脚本保证解锁操作的原子性
1 | try { |
2、版本9.2:解锁原子性——Redis事务保证解锁原子性操作
1、事务介绍
- Redis的事务是通过
MULTl,EXEC,DISCARD和WATCH这四个命令来完成。 - Redis的单个命令都是原子性的,所以这里确保事务性的对象是命令集合。
- Redis将命令集合序列化并确保处于同一事务的命令集合连续且不被打断的执行。
- Redis不支持回滚的操作。
2、相关命令
MULTI- 用于标记事务块的开始。
- Redis会将后续的命令逐个放入队列中,然后使用EXEC命令原子化地执行这个命令序列。
- 语法:
MULTI
EXEC- 在一个事务中执行所有先前放入队列的命令,然后恢复正常的连接状态。
- 语法:
EXEC
DISCARD- 清除所有先前在一个事务中放入队列的命令,然后恢复正常的连接状态。
- 语法:
DISCARD
WATCH- 当某个事务需要按条件执行时,就要使用这个命令将给定的键设置为受监控的状态。
- 语法:
WATCH key[key..…] - 注:该命令可以实现redis的乐观锁,不会有ABA问题
UNWATCH- 清除所有先前为一个事务监控的键。
- 语法:
UNWATCH
代码:
开启事务不断监视 REDIS_LOCK_KEY 这把锁有没有被别人动过,如果已经被别人动过了,那么继续重新执行删除操作,否则就解除监视
1 | try { |
10、版本10.0:自动续期版
上面代码存在的问题:我们无法保证一个业务的执行时间,有可能是 10s,有可能是 20s,也有可能更长。因为执行业务的时候可能会调用其他服务,我们并不能保证其他服务的调用时间。如果设置的锁过期了,当前业务还正在执行,那么之前设置的锁就失效了,就有可能出现并发问题。
因此我们需要确保 redisLock 过期时间大于业务执行时间的问题,即面临如何对 Redis 分布式锁进行续期的问题:
redis 与 zookeeper 在 CAP 方面的对比:
- redis:
- redis 异步复制造成的锁丢失, 比如:主节点没来的及把刚刚 set 进来这条数据给从节点,就挂了,那么主节点和从节点的数据就不一致。此时如果集群模式下,就得上 Redisson 来解决
- zookeeper:
- zookeeper 保持强一致性原则,对于集群中所有节点来说,要么同时更新成功,要么失败,因此使用 zookeeper 集群并不存在主从节点数据丢失的问题,但丢失了速度方面的性能
使用 Redisson 实现自动续期功能:
redis 集群环境下,我们自己写的也不OK,直接上 RedLock 之 Redisson 落地实现
代码:
注入 Redisson 对象
在 RedisConfig 配置类中注入 Redisson 对象
1 |
|
2、业务逻辑
直接 redissonLock.lock()、redissonLock.unlock() 完事儿,这尼玛就是 juc 版本的 redis 分布式锁啊
1 | /** |
完善代码,修改可能出现的bug
问题:在超高并发的情况下,可能会抛出如下异常,原因是解锁 lock 的线程并不是当前线程

代码:在释放锁之前加一个判断:还在持有锁的状态,并且是当前线程持有的锁再解锁
1 |
|
11、分布式锁总结
- synchronized 锁:单机版 OK,上 nginx分布式微服务,单机锁就不 OK,
- 分布式锁:取消单机锁,上 redis 分布式锁 SETNX
- 如果出异常的话,可能无法释放锁, 必须要在 finally 代码块中释放锁
- 如果宕机了,部署了微服务代码层面根本没有走到 finally 这块,也没办法保证解锁,因此需要有设置锁的过期时间
- 除了增加过期时间之外,还必须要 SETNX 操作和设置过期时间的操作必须为原子性操作
- 规定只能自己删除自己的锁,你不能把别人的锁删除了,防止张冠李戴,可使用 lua 脚本或者事务
- 判断锁所属业务与删除锁的操作也需要是原子性操作
- redis 集群环境下,我们自己写的也不 OK,直接上 RedLock 之 Redisson 落地实现
3、Redis 删除策略与缓存淘汰策略
1、Redis 缓存淘汰策略相关的面试题
- 生产上你们的redis内存设置多少?
- 如何配置、修改redis的内存大小?
- 如果内存满了你怎么办?
- redis 清理内存的方式?定期删除和惰性删除了解过吗
- redis 的缓存淘汰策略
- redis 的 LRU 淘汰机制了解过吗?可否手写一个 LRU 算法
2、redis 内存满了怎么办
redis 默认内存多少?在哪里查看? 如何设置修改?
1、如何查看 redis 最大占用内存
在 redis.conf 配置文件中有一个,输入 :set nu 显示行号,大约在 859 多行有一个 maxmemory 字段,用预设值 redis 的最大占用内存
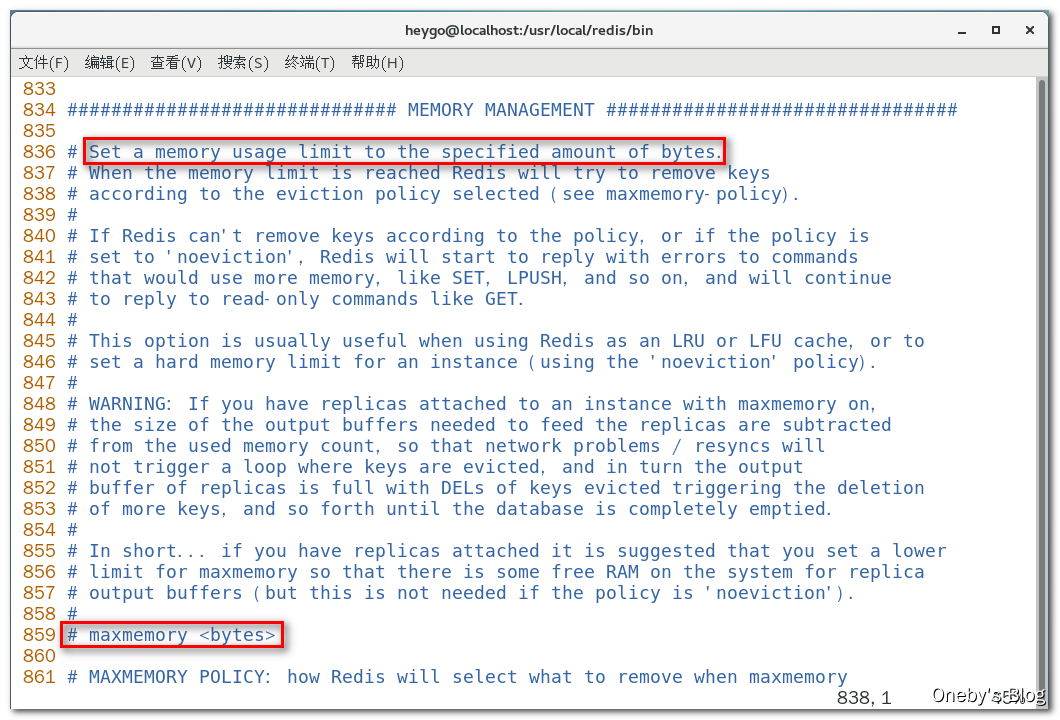
2、redis 会占用物理机器多少内存?
如果不设置最大内存大小或者设置最大内存大小为 0,在 64 位操作系统下不限制内存大小,在32位操作系统下最多使用 3GB 内存
3、一般生产上如何配置 redis 的内存
一般推荐Redis设置内存为最大物理内存的四分之三,也就是 0.75
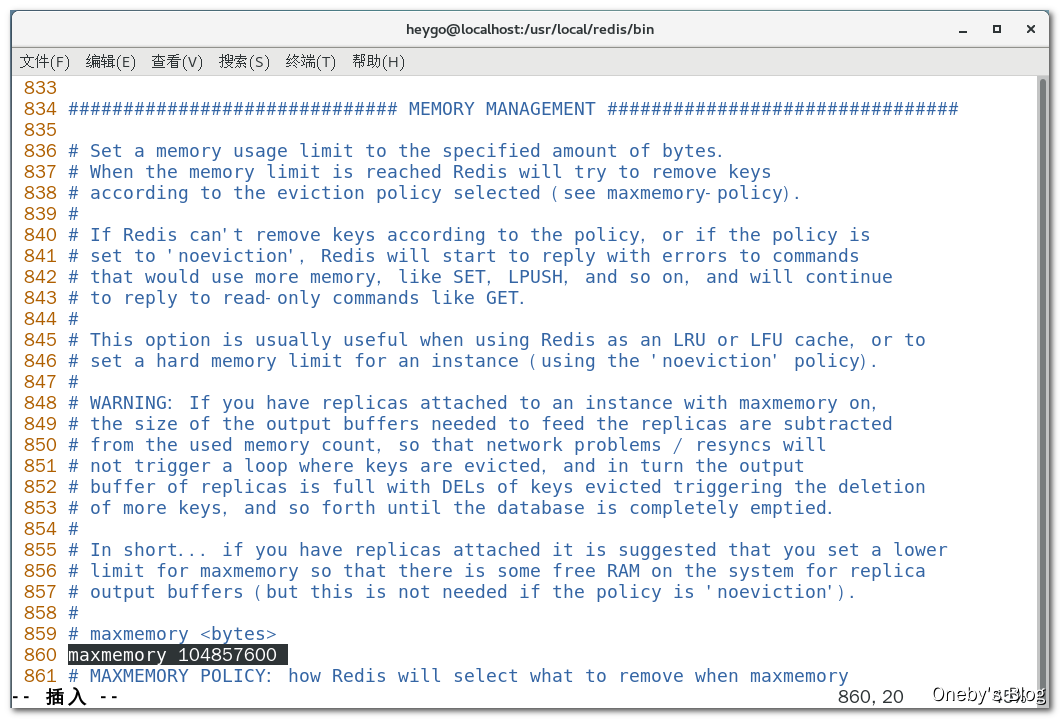
4、如何修改 redis 内存设置
1、通过修改文件配置(永久生效):修改 maxmemory 字段,单位为字节
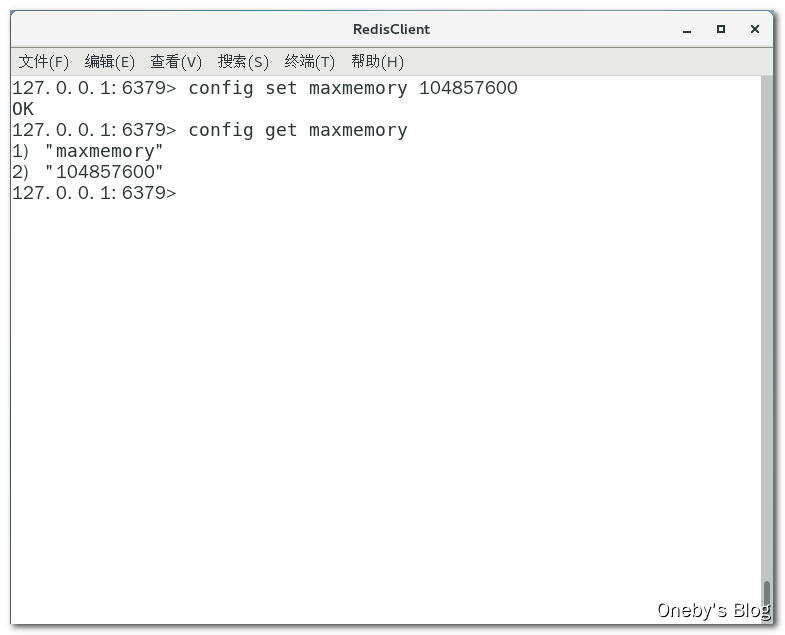
2、通过命令修改(重启失效):config set maxmemory 104857600 设置 redis 最大占用内存为 100MB,config get maxmemory 获取 redis 最大占用内存
5、通过命令查看 redis 内存使用情况?
通过 info 指令info memory可以查看 redis 内存使用情况:used_memory_human 表示实际已经占用的内存,maxmemory 表示 redis 最大占用内存
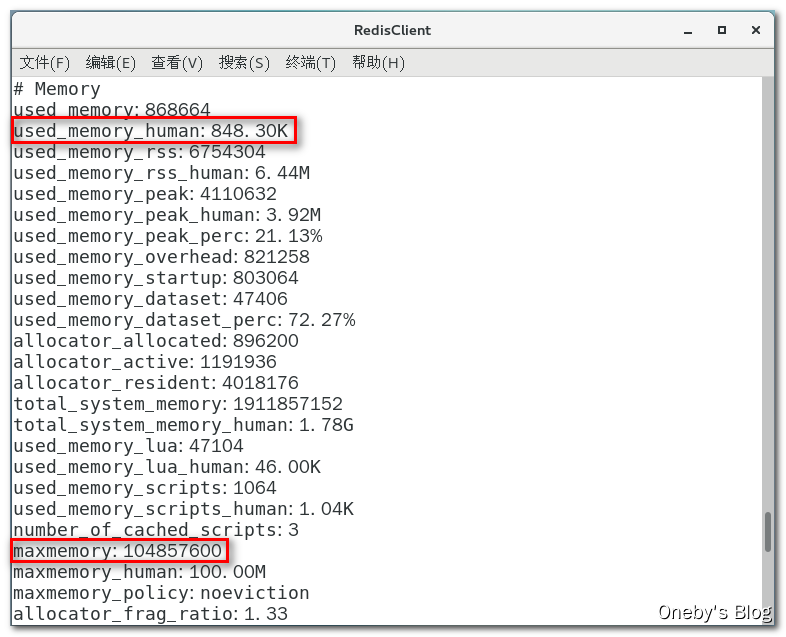
6、如果把 redis 内存打满了会发生什么? 如果 redis 内存使用超出了设置的最大值会怎样?
redis 将会报错:(error) OOM command not allowed when used memory > ‘maxmemory’
如果设置了 maxmemory 的选项,假如 redis 内存使用达到上限,并且 key 都没有加上过期时间,就会导致数据写爆 redis 内存。为了避免类似情况,于是引出下一部分的内存淘汰策略
3、redis 删除策略
redis 如何删除设置了过期时间的 key
1、redis过期键的删除策略
如果一个键是过期的,那它到了过期时间之后是不是马上就从内存中被被删除呢?那么过期后到底什么时候被删除呢?redis 如何操作的呢
通过查看 redis 配置文件可知,默认淘汰策略是【noeviction(Don’t evict anything, just return an error on write operations.)】,如果 redis 内存被写爆了,直接返回 error
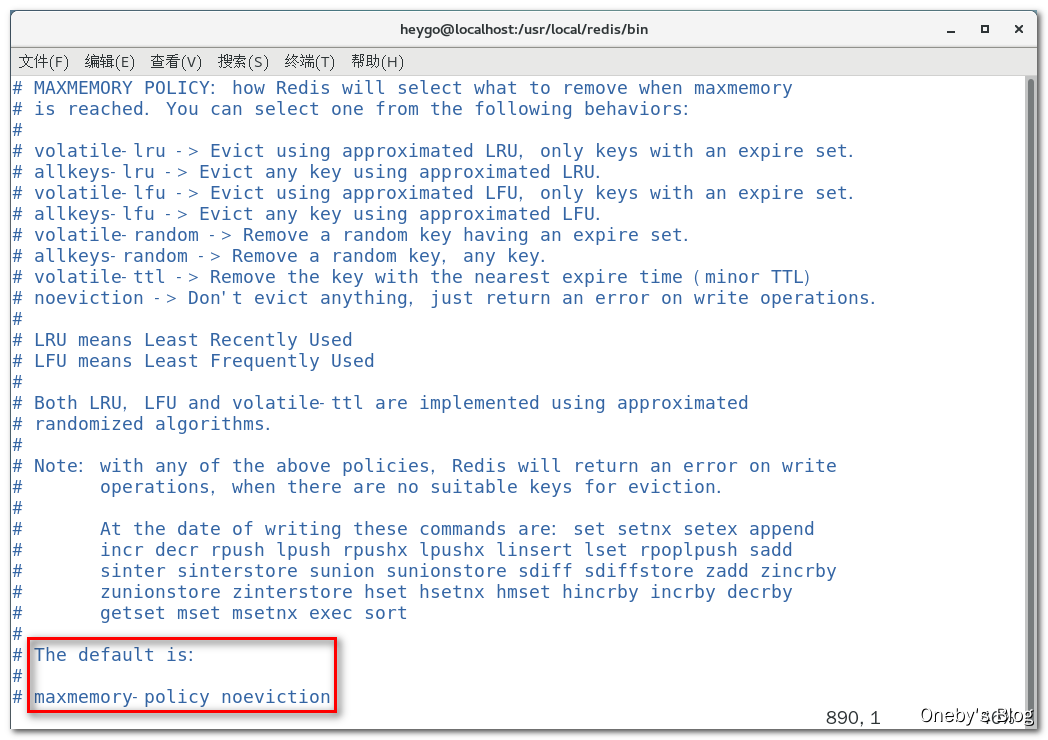
redis 对于过期 key 的三种不同删除策略:
- 立即删除
- 立即删除能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,其所占用的内存也会随之释放。但是立即删除对 CPU 是最不友好的。因为删除操作会占用 CPU 的时间,如果刚好碰上了 CPU 很忙的时候,比如正在做交集或排序等计算的时候,就会给 CPU 造成额外的压力,让 CPU 心累,时时需要删除,忙死
- 这会产生大量的性能消耗,同时也会影响数据的读取操作。
- 总结:定时删除对 CPU 不友好,但对 memory 友好,用处理器性能换取存储空间(拿时间换空间)
- 惰性删除
- 惰性删除的策略刚好和定时删除相反,惰性删除在数据到达过期时间后不做处理,等下次访问该数据时:如果发现未过期,则返回该数据;如果发现已过期,则将其删除,并返回不存在。
- 如果一个键已经过期并且未被访问到,那么这个键仍然保留在数据库中,那么只要这个过期键不被删除,它所占用的内存就不会释放。因此惰性删除策略的缺点是:它对内存是最不友好的。
- 在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行 FLUSHDB),我们甚至可以将这种情况看作是一种内存泄漏——无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的 redis 服务器来说,肯定不是一个好消息
- 总结:惰性删除对 memory 不友好,但对 CPU 友好,用存储空间换取处理器性能(拿空间换时间)
- 定期删除:(折中方案)
- 上面两种删除策略都走极端,因此引出我们的定期删除策略。
- 定期删除策略是前两种策略的折中:定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
- 其做法为:**==周期性轮询== redis 库中的时效性数据,采用==随机抽取==的策略,利用==过期数据占比==的方式控制删除频度。**
- 定期删除的特点:
- CPU 性能占用设置有峰值,检测频度可自定义设置
- 内存压力不是很大,长期占用内存的冷数据会被持续清理
- 总结:周期性抽查存储空间(随机抽查,重点抽查)
- 定期删除的举例:
- redis 默认每间隔 100ms 检查是否有过期的 key,如果有过期 key 则删除。
- 注意:redis 不是每隔100ms 将所有的 key 检查一次而是随机抽取进行检查(如果每隔 100ms,全部 key 进行检查,redis 直接进去ICU)。因此,如果只采用定期删除策略,会导致很多 key 到时间没有删除。
- 定期删除的难点:
- 定期删除策略的难点是确定删除操作执行的时长和频率:redis 不可能时时刻刻遍历所有被设置了生存时间的 key,来检测数据是否已经到达过期时间,然后对它进行删除。
- 如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化成定时删除策略,以至于将 CPU 时间过多地消耗在删除过期键上面。
- 如果删除操作执行得太少,或者执行的时间太短,定期删除策略又会和惰性删除束略一样,出现浪费内存的情况。
- 因此,如果采用定期删除策略的话,服务器必须根据情况,合理地设置删除操作的执行时长和执行频率。
总结:
惰性删除和定期删除都存在数据没有被抽到的情况,如果这些数据已经到了过期时间,没有任何作用,这会导致大量过期的 key 堆积在内存中,导致 redis 内存空间紧张或者很快耗尽
因此必须要有一个更好的兜底方案,接下来引出 redis 内存淘汰策略
4、Redis的缓存淘汰策略
redis 6.0.8 版本的内存淘汰策略有哪些?:
8 种内存淘汰策略
noeviction:不会驱逐任何keyallkeys-lru:对所有key使用LRU算法进行删除volatile-lru:对所有设置了过期时间的key使用LRU算法进行删除allkeys-random:对所有key随机删除volatile-random:对所有设置了过期时间的key随机删除volatile-ttl:删除马上要过期的keyallkeys-lfu:对所有key使用LFU算法进行删除volatile-lfu:对所有设置了过期时间的key使用LFU算法进行删除
总结:
- 2个维度
- 过期键中筛选
- 所有键中筛选
- 4个方面
- lru
- lfu
- random
- ttl、noeviction
如何配置 redis 的内存淘汰策略:
1、通过修改文件配置(永久生效):配置 maxmemory-policy 字段:
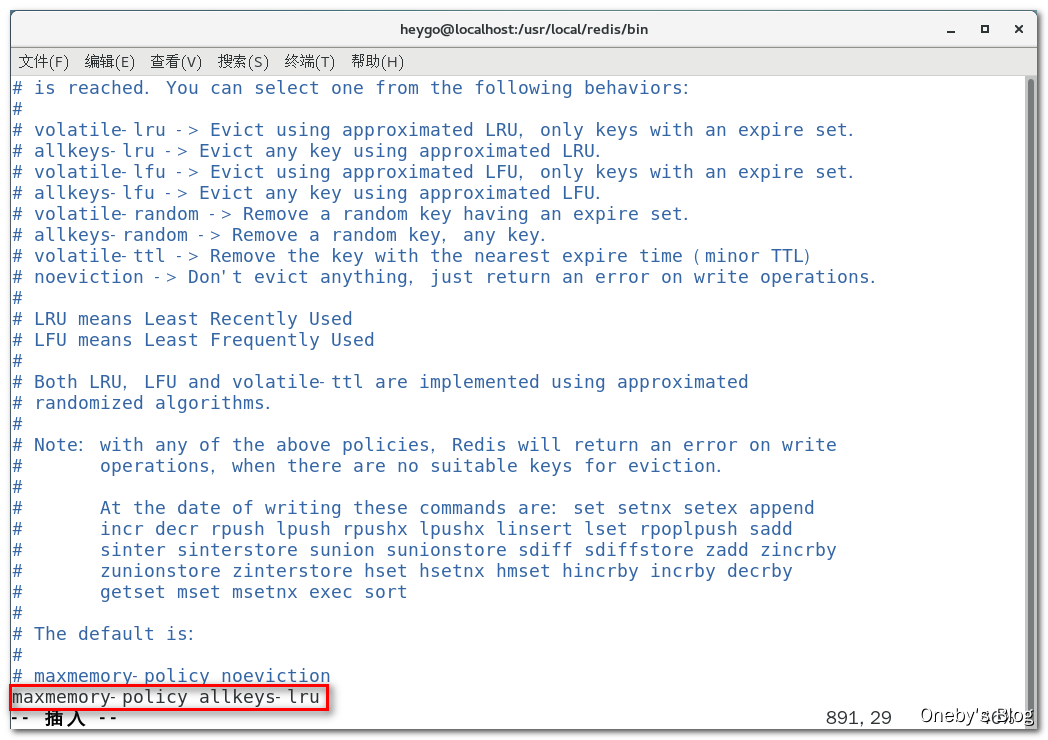
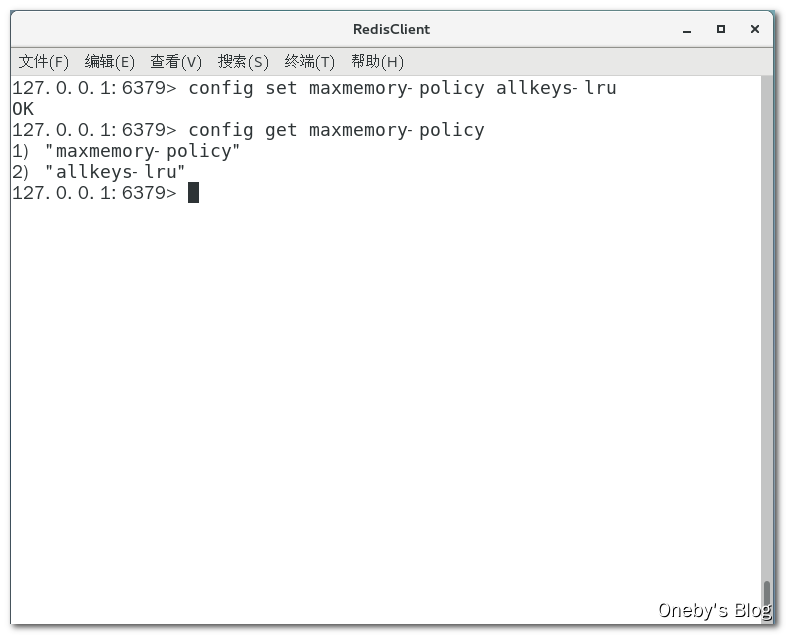
通过命令修改(重启失效):config set maxmemory-policy allkeys-lru 命令设置内存淘汰策略,config get maxmemory-policy 命令获取当前采用的内存淘汰策略
5、redis LRU 算法
1、LRU 算法简介
LRU 是 Least Recently Used 的缩写,即最近最少使用,是一种常用的页面置换算法,每次选择最近最久未使用的页面予以淘汰
2、LRU 算法题来源
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制 。
实现 LRUCache 类:
- LRUCache(int capacity):以正整数作为容量 capacity 初始化 LRU 缓存
- int get(int key):如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
- void put(int key, int value):如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间.
进阶:你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
1 | 输入 |
3、LRU 算法设计思想
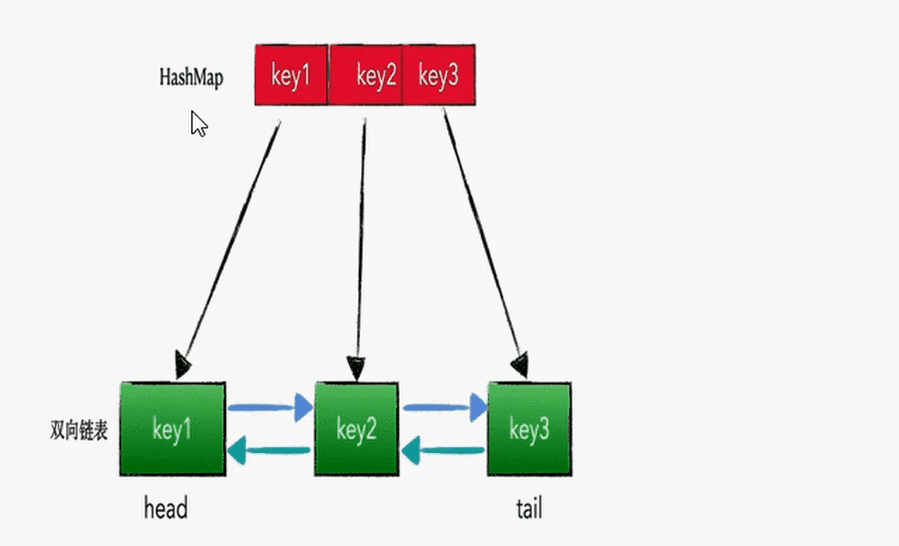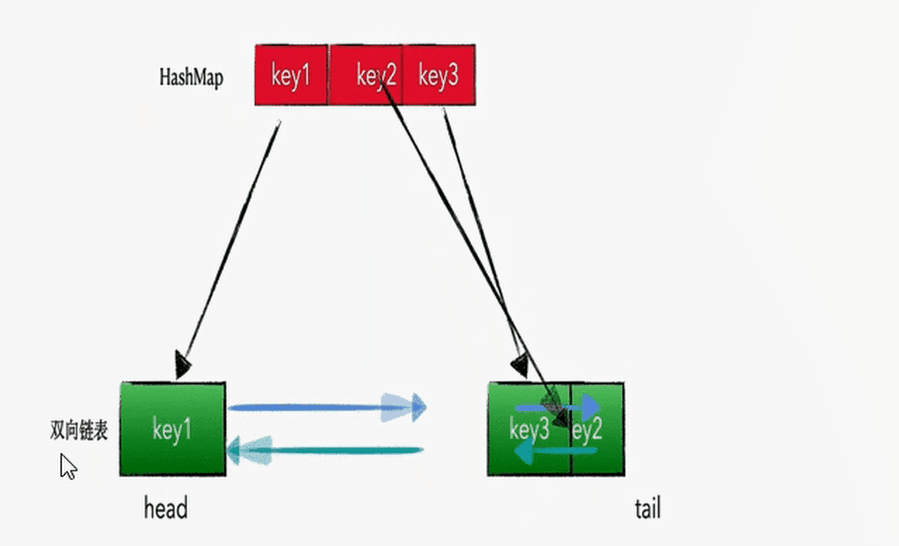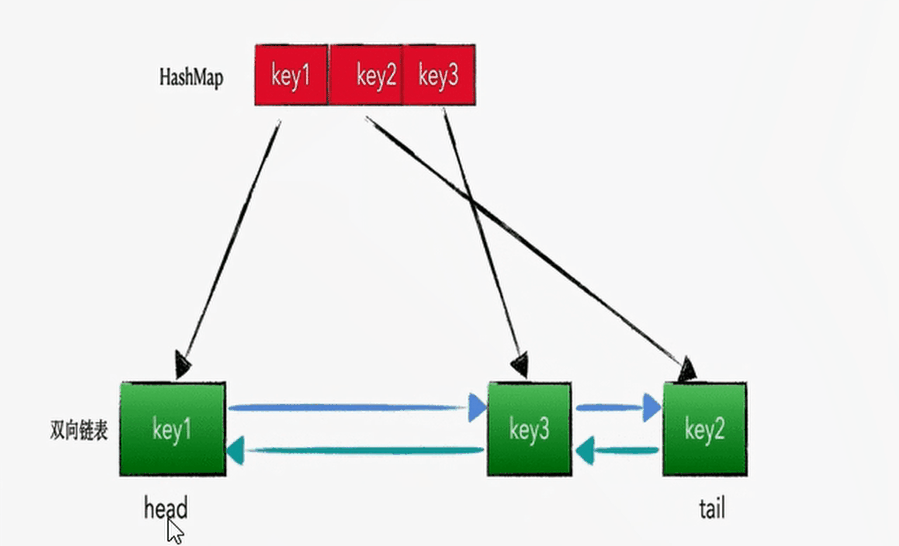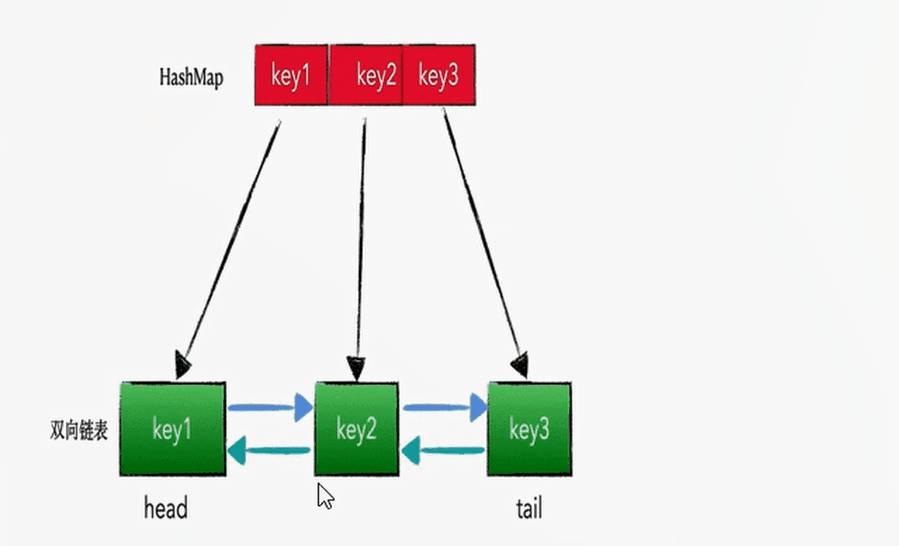
查找和插入的时间复杂度为 O(1),HashMap 没得跑了,但是 HashMap 是无序的集合,怎么样将其改造为有序集合呢?答案就是在各个 Node 节点之间增加 prev 指针和 next 指针,构成双向链表。即:HashMap + 双向链表
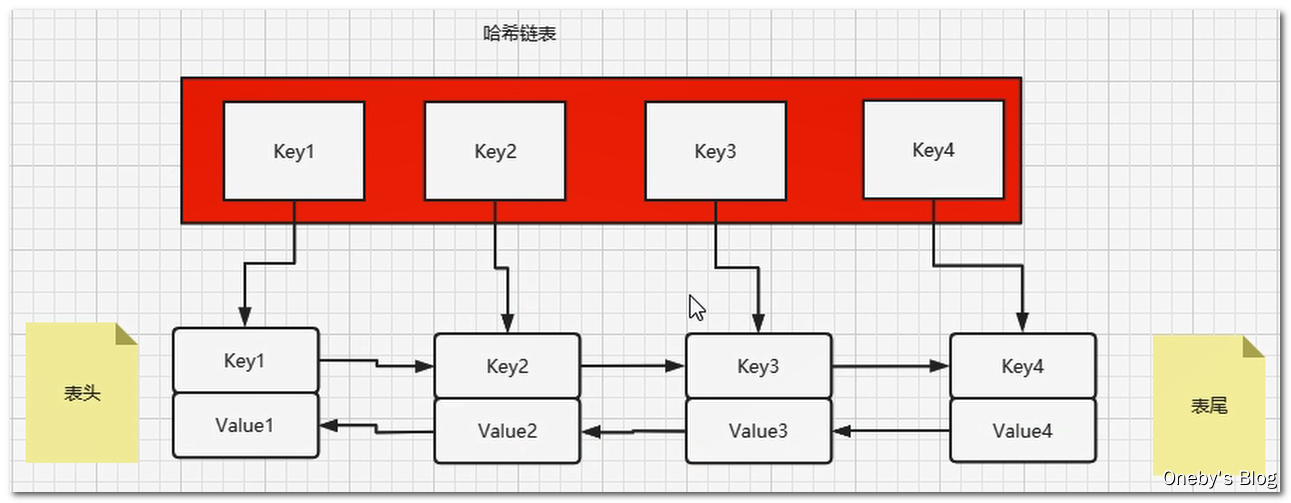
LRU 的算法核心是哈希链表,本质就是 HashMap+DoubleLinkedList 时间复杂度是O(1),哈希表+双向链表的结合体,下面这幅动图完美诠释了 HashMap+DoubleLinkedList 的工作原理:
4、LRU 算法编码实现
1、**借助 JDK 自带的 LinkedHashMap**:
LinkedHashMap 的注释中写明了: LinkedHashMap 非常适合用来构建 LRU 缓存
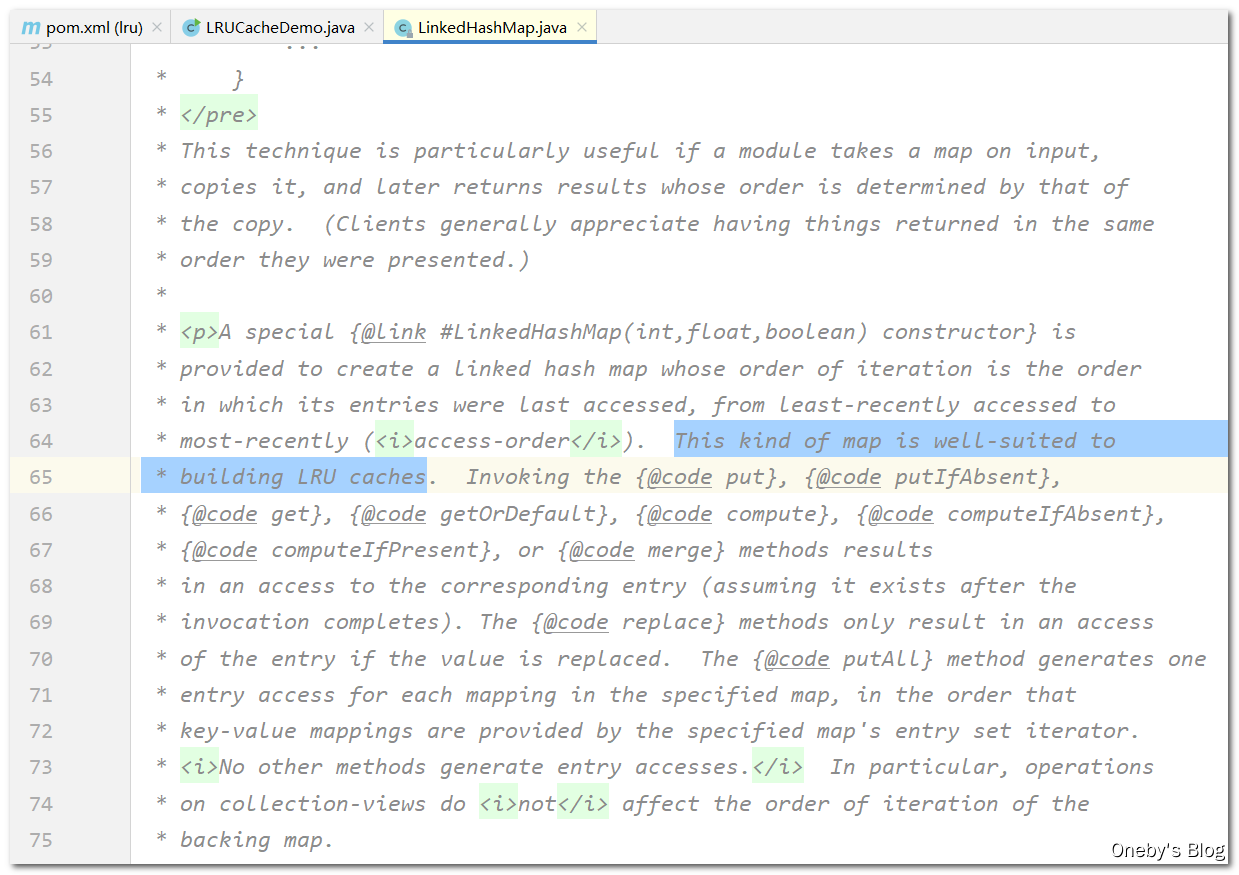
LRU 代码:
通过继承 LinkedHashMap,重写 boolean removeEldestEntry(Map.Entry<K, V> eldest) 方法就行了
1 | public class LRUCacheDemo<K, V> extends LinkedHashMap<K, V> { |
为何要重写 boolean removeEldestEntry(Map.Entry<K, V> eldest) 方法:
先来看看 LinkedHashMap 中的 boolean removeEldestEntry(Map.Entry<K, V> eldest) 方法,直接 return false,缓存爆就爆,反正就是不会删除 EldestEntry
1 | /** |
boolean removeEldestEntry(Map.Entry<K, V> eldest) 方法在 void afterNodeInsertion(boolean evict) 方法中被调用,只有当 boolean removeEldestEntry(Map.Entry<K, V> eldest) 方法返回 true 时,才能够删除 EldestEntry
1 | void afterNodeInsertion(boolean evict) { // possibly remove eldest |
因此我们重写之后的判断条件为:如果 LinkedHashMap 中存储的元素个数已经大于缓存容量 capacity,则返回 true,表示允许删除 EldestEntry;否则返回 false,表示无需删除 EldestEntry
1 | // 用于判断是否需要删除最近最久未使用的节点 |
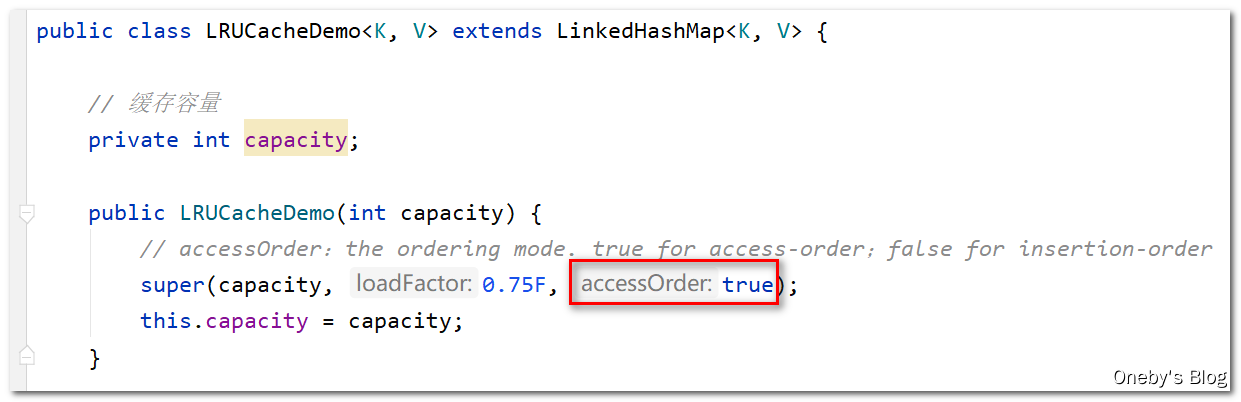
举例说明构造函数中的 accessOrder 的含义:
构造函数中的 accessOrder 字段
在 LRUCacheDemo 的构造方法中,我们调用了 LinkedHashMap 的构造方法,其中有一个字段为 accessOrder
accessOrder = true 和 accessOrder = false 的情况:
- 当
accessOrder = true时,每次使用 key 时(put 或者 get 时),都将 key 对应的数据移动到队尾(右边),表示最近经常使用; - 当
accessOrder = false时,key 的顺序为插入双向链表时的顺序
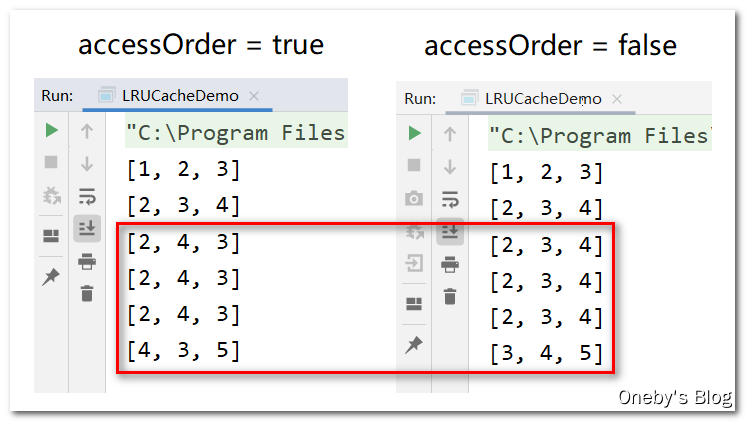
注:false可以说是一种优化,没有去移动相关节点,性能会更好一点
LinkedHashMap 的 put() 方法:
LinkedHashMap 其实没有 put() 方法,LinkedHashMap的put()方法其实就是 HashMap 的 put() 方法,我就奇了怪了,LinkedHashMap 就是 HashMap???其实并不是。。。一起来看一下HashMap的putVal()方法:
1 | /** |
在 putval() 方法的调用了两个方法:afterNodeAccess(e) 方法和 afterNodeInsertion(evict) 方法,这两个方法就是专门针对于 LinkedHashMap 写的方法:在 HashMap 中这些方法均为空实现的方法,没有任何代码逻辑,需要推迟到子类 LinkedHashMap 中去实现,就是模板方法设计模式
1 | // Callbacks to allow LinkedHashMap post-actions |
注释也写了:Callbacks to allow LinkedHashMap post-actions
在 LinkedHashMap 的 void afterNodeAccess(Node<K,V> e) 方法中:如果设置了 accessOrder = true 时,则每次使用 key 时(put 或者 get 时),都将 key 对应的数据移动到队尾(右边),表示这是最近经常使用的节点
1 | void afterNodeAccess(Node<K,V> e) { // move node to last |
在 LinkedHashMap 的 void afterNodeInsertion(boolean evict) 方法中:如果头指针不为空并且当前需要删除老节点,则执行 removeNode(hash(key), key, null, false, true) 方法删除 EldestEntry(若 accessOrder = true 时,EldestEntry 表示最近最少使用的数据,若 accessOrder = false 时,EldestEntry 表示最先插入链表的节点)
1 | void afterNodeInsertion(boolean evict) { // possibly remove eldest |
LinkedHashMap 的 get() 方法:
在 LinkedHashMap 的 get() 方法中:若 accessOrder = true 时,则每次 get(key) 之后都会将 key 对应的数据移动至双向链表的尾部:
1 | public V get(Object key) { |
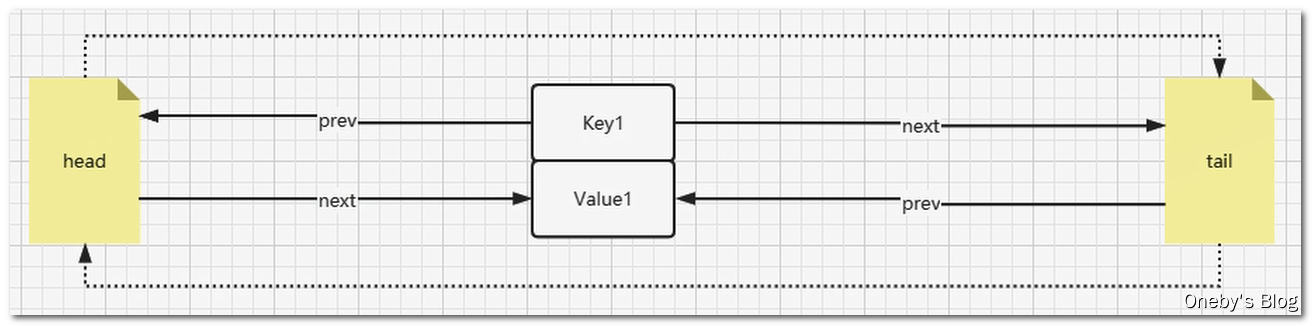
LinkedHashMap 中如何构造双向链表?
Entry<K,V> 继承了 HashMap.Node<K,V>,并且有 Entry<K,V> before, after; 两个字段,这不就是双线链表的标配嘛
1 | /** |
在 LinkedHashMap 中定义了 head 和 tail ,分别指向双向链表的头部和尾部,人家注释中也说了,**head 用于指向双向链表中最老的节点,tail 用于指向最年轻的节点,至于最老和最年轻的定义,就得看 accessOrder 字段的值了:如果 accessOrder = false,那么最老的节点就是最久没有被使用过的节点,最年轻的节点就是最近被刚被使用过的节点;如果 accessOrder = true,那么最老的节点就是链表头部的节点,最年轻的节点就是链表尾部的节点**
1 | /** |
2、完全自己手写
依葫芦画瓢,先定义 Node 类作为数据的承载体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 1.构造一个node节点作为数据载体
class Node<K, V> {
K key;
V value;
Node<K, V> prev;
Node<K, V> next;
public Node() {
this.prev = this.next = null;
}
public Node(K key, V value) {
this.key = key;
this.value = value;
this.prev = this.next = null;
}
}定义双向链表,里面存放的就是 Node 对象,Node 节点之间通过
prev和next指针连接起来1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33// 2.构建一个虚拟的双向链表,,里面存放的就是我们的Node
class DoubleLinkedList<K, V> {
Node<K, V> head;
Node<K, V> tail;
public DoubleLinkedList() {
head = new Node<>();
tail = new Node<>();
head.next = tail;
tail.prev = head;
}
// 3.添加到头(头插法)
public void addHead(Node<K, V> node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
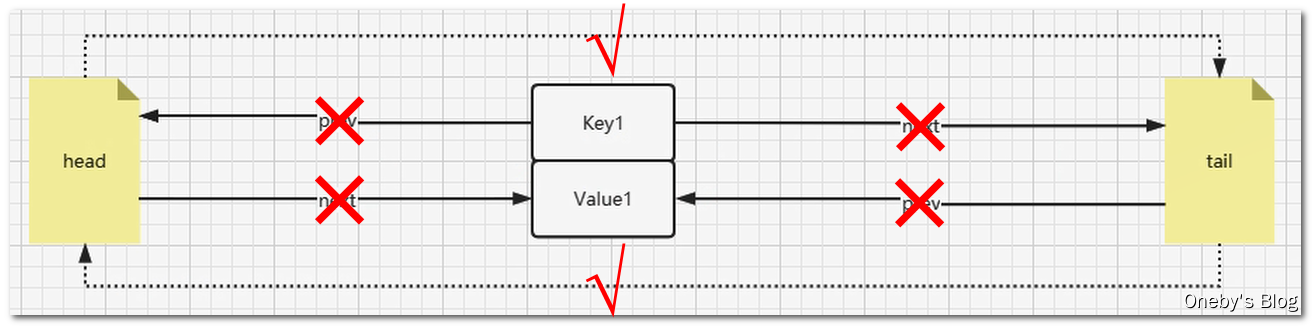
// 4.删除节点
public void removeNode(Node<K, V> node) {
node.next.prev = node.prev;
node.prev.next = node.next;
node.prev = null;
node.next = null;
}
// 5.获得最后一个节点
public Node getLast() {
return tail.prev;
}
}通过
HashMap和DoubleLinkedList构建LinkedHashMap,我们这里可是将最近最常使用的节点放在了双向链表的头部(和LinkedHashMap不同哦)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44private int cacheSize;
Map<Integer, Node<Integer, Integer>> map;
DoubleLinkedList<Integer, Integer> doubleLinkedList;
public LRUCacheDemo(int cacheSize) {
this.cacheSize = cacheSize;//坑位
map = new HashMap<>();//查找
doubleLinkedList = new DoubleLinkedList<>();
}
public int get(int key) {
if (!map.containsKey(key)) {
return -1;
}
Node<Integer, Integer> node = map.get(key);
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
return node.value;
}
public void put(int key, int value) {
if (map.containsKey(key)) { //update
Node<Integer, Integer> node = map.get(key);
node.value = value;
map.put(key, node);
doubleLinkedList.removeNode(node);
doubleLinkedList.addHead(node);
} else {
if (map.size() == cacheSize) //坑位满了
{
Node<Integer, Integer> lastNode = doubleLinkedList.getLast();
map.remove(lastNode.key);
doubleLinkedList.removeNode(lastNode);
}
//新增一个
Node<Integer, Integer> newNode = new Node<>(key, value);
map.put(key, newNode);
doubleLinkedList.addHead(newNode);
}
}测试
LRUCacheDemo1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public static void main(String[] args) {
LRUCacheDemo lruCacheDemo = new LRUCacheDemo(3);
lruCacheDemo.put(1, 1);
lruCacheDemo.put(2, 2);
lruCacheDemo.put(3, 3);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(4, 1);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(3, 1);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(3, 1);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(3, 1);
System.out.println(lruCacheDemo.map.keySet());
lruCacheDemo.put(5, 1);
System.out.println(lruCacheDemo.map.keySet());
}测试结果:我们实现的是
accessOrder = false最近最少使用的数据已经被删除了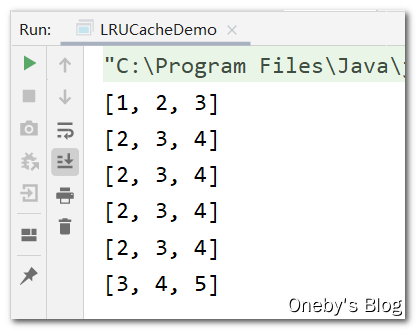
全部代码:
1 | public class LRUCacheDemo { |
图解双向队列:
DoubleLinkedList双向链表的初始化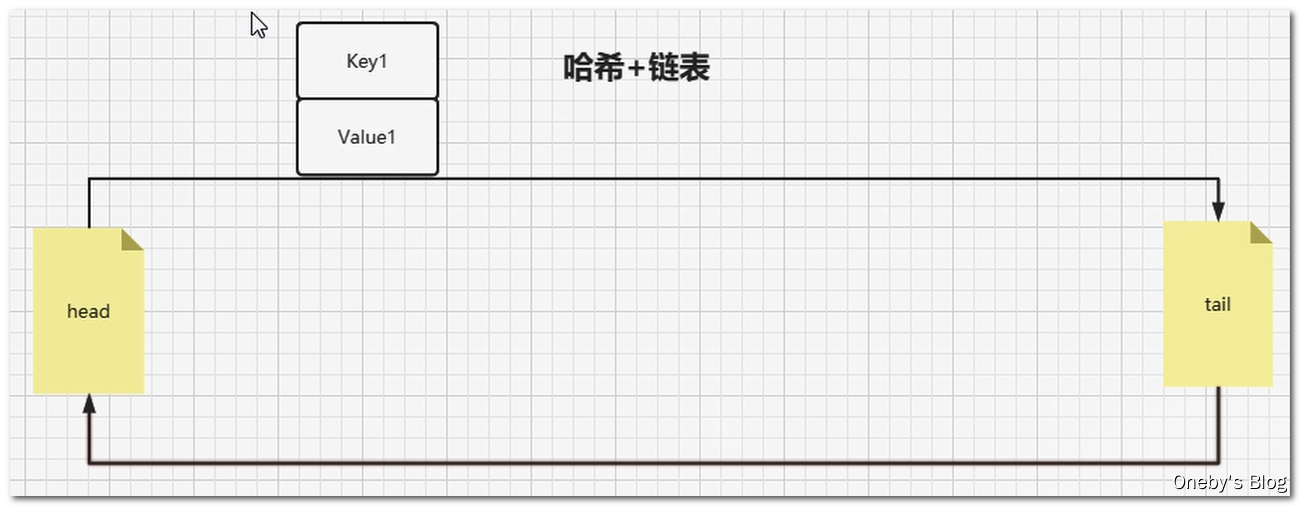
双向链表插入节点
双向链表删除节点
MySql
1、Mysql什么时候建索引,什么时候不能建索引
1、索引是什么?
MySQL官方对索引的定义为:索引(Index)是希切MySQL高效获取数据的数据结构。
可以得到索引的本质:索引是数据结构(大部分索引是B+树)
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上
2、索引的优缺点
优点:
- 类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗
缺点:
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息
- 实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的
3、什么时候建索引,什么时候不能建索引
哪些情况需要创建索引:(从索引的优点去考虑)
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其它表关联的字段,外键关系建立索引
- 单键/组合索引的选择问题,组合索引性价比更高
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组字段
- 分组字段创建索引会比排序字段创建索引的效率更高,因为分组本身就包含了排序,分组是先排序后分组
哪些情况不要创建索引:(从索引的缺点去考虑)
- 表记录太少
- 因为还需要维护一张索引表
- 经常增删改的表或者字段
- 因为索引会降低更新表的速度
- Where条件里用不到的字段不创建索引
- 索引是为了更好更快的查询数据,如果该字段不用来查询数据,就没有必要创建索引
- 过滤性不好的不适合建索引
- 过滤性不好,如:性别
- 过滤性好,如:身份证号
JUC多线程及高并发
1、谈谈你对volatile的理解
1、解答
volatile是Java虚拟机提供的轻量级的同步机制
- 保证可见性
- 不保证原子性
- 禁止指令重排
2、谈谈JMM(Java内存模型)
JMM(Java内存模型,简称JMM)本身是一种抽象的概念并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。
JMM关于同步的规定:
- 线程解锁前,必须把共享变量的值刷新回主内存。
- 线程加锁前,必须读取主内存的最新值到自己的工作内存。
- 加锁解锁是同一把锁。
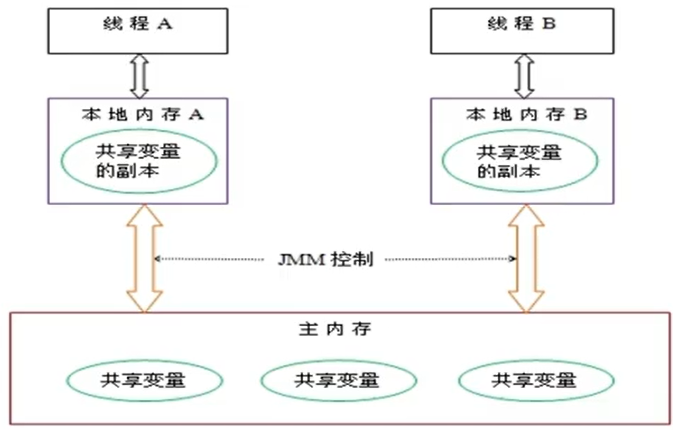
由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),==工作内存是每个线程的私有数据区域==,而Java内存模型中规定所有变量都存储到主内存,==主内存是共享内存区域==,所有线程都可以访问,但线程对变量的操作(读取、复制等)必须在工作内存中进行,首先要将变量从主内存拷贝到自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量,各个线程中的工作内存中存储着主内存中的变量副本拷贝,因此==不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成==,其简要访问过程如下图:
3、解析
1、volatile解决可见性问题
通过前面对JMM的介绍,我们知道:
- 各个线程对主内存中共享变量的操作都是各个线程各自拷贝到自己的工作内存进行操作后再写回主内存中的。
- 这就可能存在一个线程A修改了共享变量X的值但还未写回主内存时,另一个线程B又对准内存中同一个共享变量X进行操作,
- 但此时A线程工作内存中共享变量X对线程B来说并不是可见,这种工作内存与主内存同步存在延迟现象就造成了可见性问题。
可见性问题:
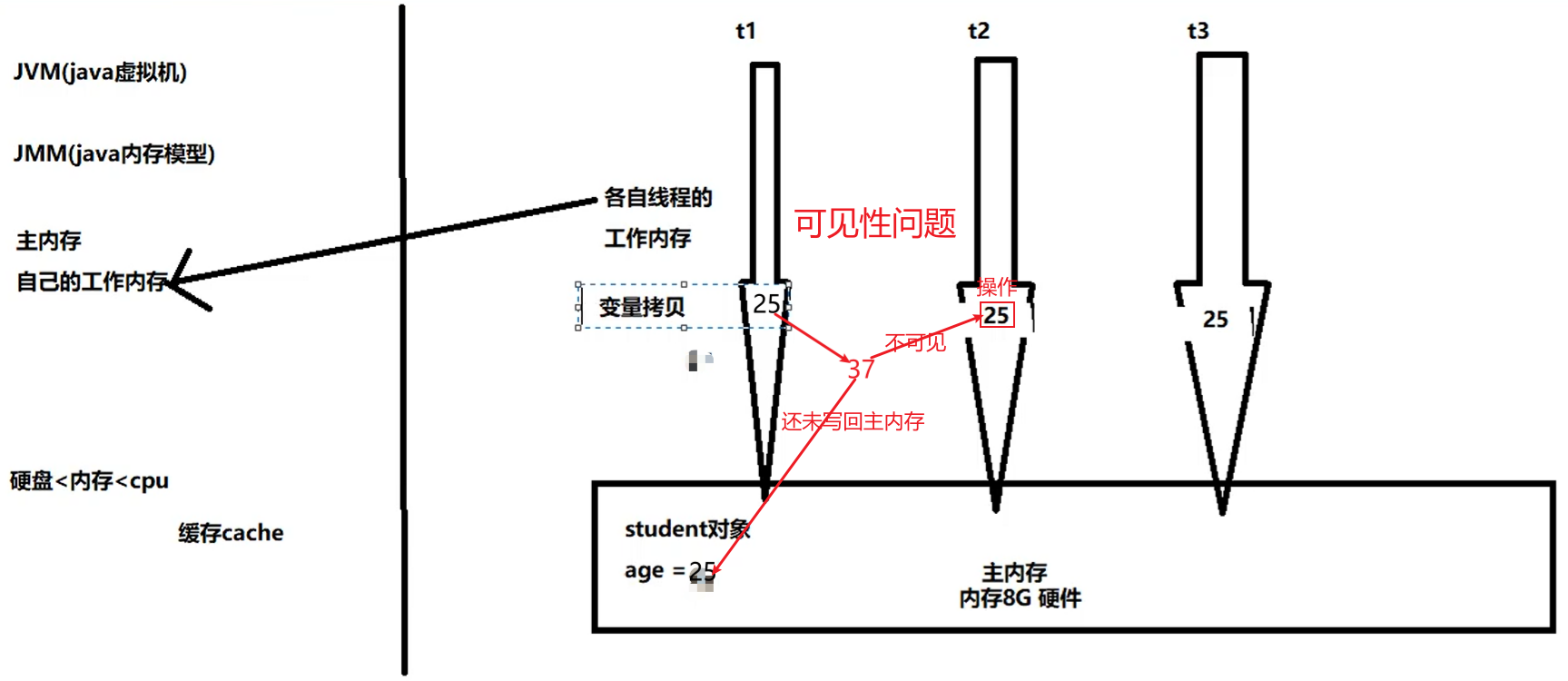
volatile解决可见性问题:
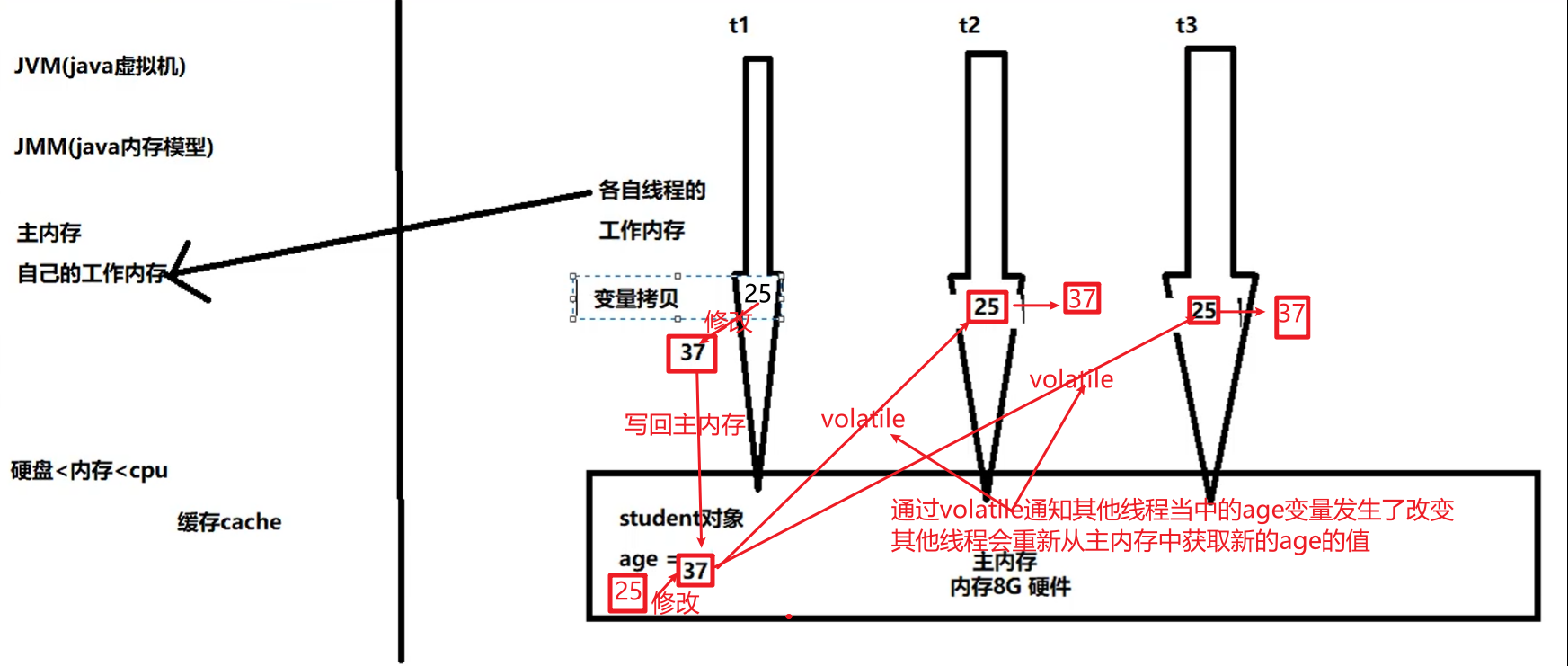
2、volatile不能解决原子性问题
编程代码:20个线程对int类型的变量num进行1000次的自增操作num++,最终得到的num结果小于等于20000
尝试解决:在num前面使用volatile进行修饰,运行发现num结果的依旧小于等于20000
- volatile不能解决原子性问题
为什么volatile不能解决原子性问题?
- volatile解决的是可见性的问题,当一个线程修改自己工作流程的num时,要将num写回主内存当中并对其他线程可见,但是它不能保证
- 从主存获取num数据
- 在自己的工作内存当中将num的值加1
- 在把修改过后的num的值写回主内存
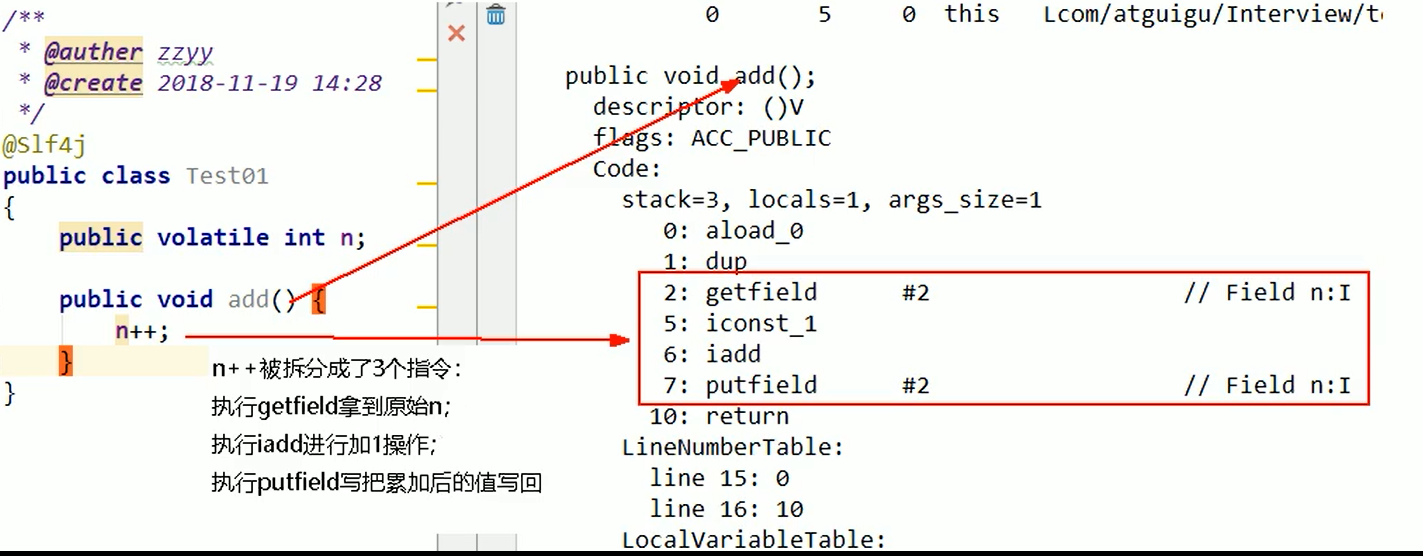
- 以上三个操作是原子性的,所以就有可能出现丢失写值的情况:多个线程把自己修改的num值同时写回主内存,而num只增加了1。就会出现最终num的结果小于等于20000的情况了。
注:num++并不是一个原子操作,它是三个操作。相关的JVM字节码:
那么怎么解决num++的原子性问题
- 方法1:synchronized加锁
- 不推荐,锁的粒度太大
- 方法2:使用原子整形类AutomicInteger的getAndIncrement方法进行自增
- 底层:使用了CAS轻量级锁
3、volatile禁止指令重排序——保证有序性
计算机在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排,一般分以下3种:

单线程环境里面确保程序最终执行结果和代码顺序执行的结果一致。
处理器在进行重排序时必须考虑指令之间的数据依赖性。
多线程环境中线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的,结果无法预测。
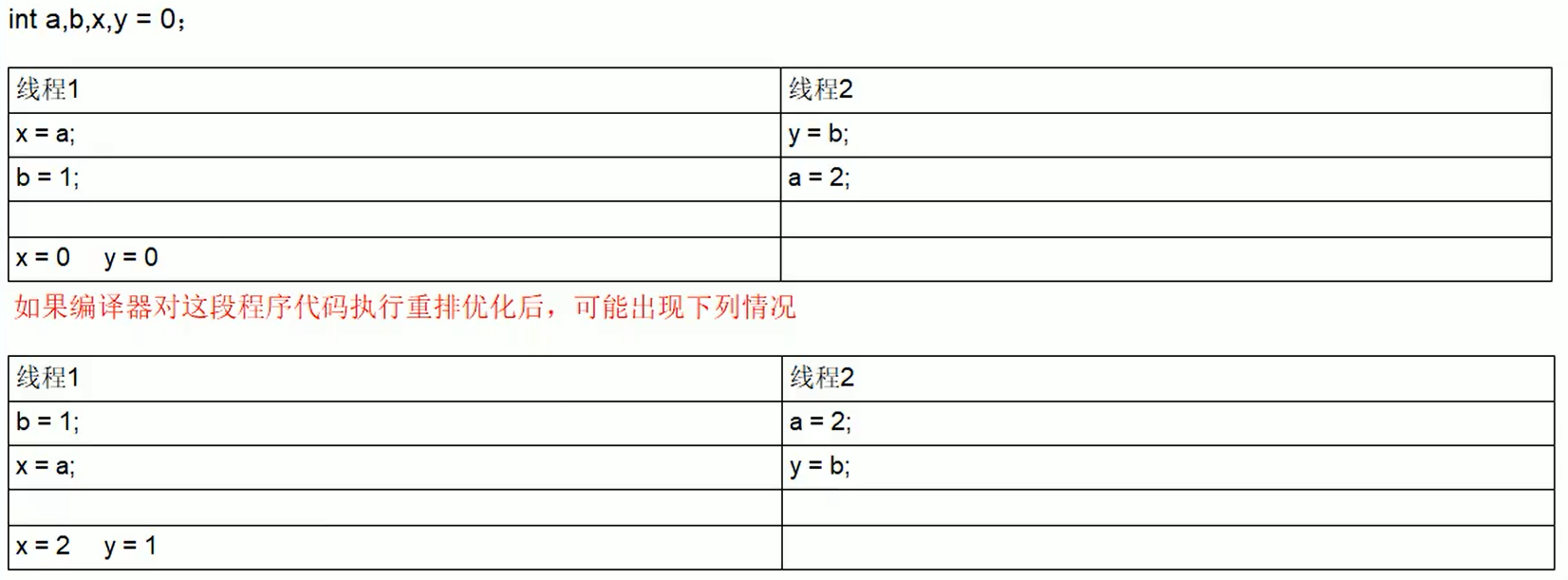
4、volatile底层原理
为什么volatile可以实现可见性与有序性?
先了解一个概念,内存屏障又称内存栅栏(Memory Barrier),是一个CPU指令,它的作用有两个:
- 保证特定操作的执行顺序
- 保证某些变量的内存可见性(利用该特性实现volatile的内存可见性)
内存屏障(Memory Barrier)的分类:
关于Volatile写的内存屏障指令
StoreStore屏障:禁止上面的普通写和下面的volatile写重排序——保证了使用volatile修饰的变量的写是在普通写之后执行的
StoreLoad屏障:防止上面的volatile写和下面可能有的volatile读/写重排序——保证了使用volatile修饰的变量的写是在其他在该volatile变量之后的使用volatile修饰的变量之前执行的
1
2
3
4int a = 10; // 1
volatile int b = 20; // 2
int c = 30; // 3
volatile int d = 40; // 4- 2的volatile可以保证1在2之前执行,2在3/4之前执行
- 4的volatile可以保证1/2/3在4之前执行
关于Volatile读的内存屏障指令
LoadLoad屏障:禁止下面所有普通读操作和上面的volatile读重排序——保证了使用volatile修饰的变量的读是在其他普通变量读的之前执行
LoadStore屏障:禁止下面所有的写操作和上面的volatile读重排序——保证了使用volatile修饰的变量的读是在其他普通变量写的之前执行
1
2
3
4
5
6
7volatile int a = 10;
int b = 20;
int c = 30;
System.out.println(a); // 1
System.out.println(b); // 2
c = 80; // 3- a的volatile保证了1在2/3之前执行
由于编译器和处理器都能执行指令重排优化。如果在指令间插入一条Memory Barrier则告诉编译器和CPU,不管什么指令都不能和这条Memory Barrier指令重新排序,也就是说通过插入内存屏障禁止在内存屏障前后的指令执行重排序优化。——保证有序性
内存屏障另外一个作用是强制刷出各种CPU的缓存数据,因此任何CPU上的线程都能读取到这些数据的最新版本。——保证可见性
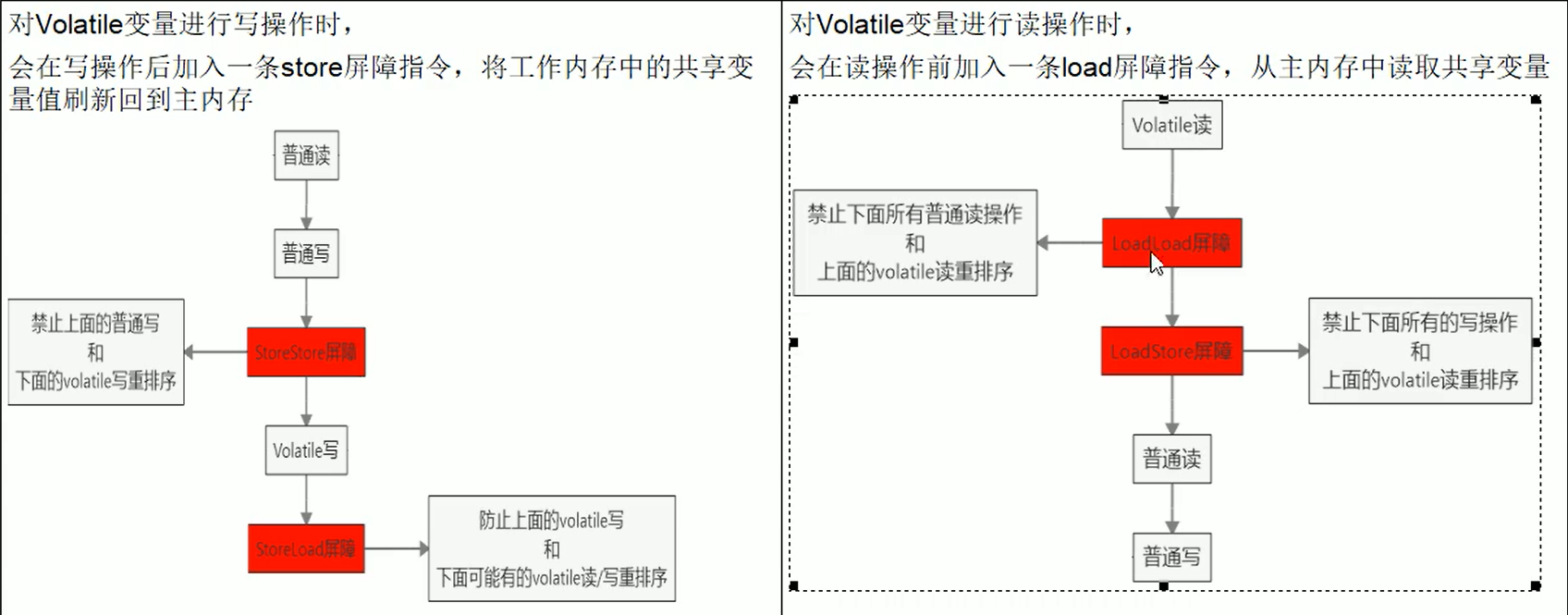
4、保证线程的安全
- 工作内存和主内存同步延迟现象导致的可见性问题:
- 可以使用
synchronized或volatile关键字解决,他们都可以使一个线程修改后的变量立即对其他线程可见。
- 可以使用
- 对于指令重排导致的可见性问题和有序性问题:
- 可以利用volatile关键字解决,因为volatile的另外一个作用就是禁止重排序优化。
4、你在哪些地方用过volatile?
解答:
- 在单例模式Singleton的DCL写法(Double Check Lock双端检索机制)使用过volatile来反正指令的重排序
- 在手写读写锁的缓存的时候
- 在翻阅CAS的底层的JUC源码时经常能看到volatile
为什么单例模式Singleton的DCL写法会出现指令的重排序问题导的线程安全问题?
原因在于对象的创建并不是一个原子操作,对象的操作分为3个步骤,而且步骤之间不存在数据依赖,可以进行指令重排序。
导致某一个线程执行到第一次检测,读取到的instance不为null时,可能会出现两种情况:
- instance的引用对象真的创建成功了(绝大部分都是)
- instance的引用对象可能没有完成初始化(还是可能出现的,出现了就是线程安全问题了)
instance = new SingletonDemo();——创建对象可以分为以下3步完成(伪代码)
- 分配对象内存空间
- memory = allocate();
- 初始化对象
- instance(memory);
- 设置instance指向刚分配的内存地址,此时instance! =null
- instance = memory;
如果JVM依靠的以上的指令进行对象的创建的话,就不会出现线程安全问题了——第一种情况
但是步骤2和步骤3不存在数据依赖关系,而且无论重排前还是重排后程序的执行结果在单线程中并没有改变,因此这种重排优化是允许的。
- 分配对象内存空间
- memory = allocate();
- 设置instance指向刚分配的内存地址,此时instance! =null,但是对象还没有初始化完成!对象里面的实例变量可能还没有赋值等等
- instance = memory;
- 初始化对象
- instance(memory);
因此此时线程得到的instance实例就是有问题的,就出现了线程安全问题——第二种情况
2、CAS你知道吗
1、什么是CAS
CAS的全称是Compare-And-Swap(比较并交换),它是一条CPU并发原语。
它的功能是判断内存某个位置的值是否为预期值,如果是则更改为新的值,这个过程是原子的。
CAS就是一个线程如果想要将当前修改值放进主内存之前需要进行一次比较操作:拿一开始从主内存获取的变量副本与当前主内存当中的该变量的值进行比较。如果一样,则表示在该线程修改该变量的值的这段时间内,没有其他线程动过主内存当中该变量的值(除了出现ABA问题),则可以进行写回操作,并且返回true。否则返回false并且写回失败。
CAS并发原语体现在JAVA语言中就是sun.misc.Unsafe类中的各个方法。调用UnSafe类中CAS方法,JVM会帮我们实现CAS汇编指令。这是一种完全依赖于硬件的功能,通过它实现原子性。再次强调,由于CAS是一种系统原语,原语属于操作系统用语范畴,是由若干指令组成的,用语完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说CAS是一条CPU的原子指令,不会造成所谓的数据不一致性问题。
CAS应用:CAS有3个操作数,内存值V,旧的预期值A,要修改的更新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
为什么说CAS的粒度要比Synchronized低呢?——这就需要从CAS的底层说起
- 因为Synchronized使用了锁,线程的并发性下降了
- 而CAS没有使用锁,底层是使用了自旋锁(自旋锁不是锁,而是一个循环),因此线程的并发性并没有下降
2、CAS的底层
CAS的底层:Unsafe + 自旋锁
- Unsafe保证CAS操作的原子性
- 自旋锁保证CAS操作的成功性
以atomicInteger.getAndIncrement();为例:

假设线程A和线程B两个线程同时执行getAndAddInt操作(分别在不同CPU上)
- AtomicInteger里面的value原始值为3,即主内存中AtomicInteger的value为3,根据JMM模型,线程A和线程B各自持有一份值为3的value的副本分别到各自的工作内存。
- 线程A通过getAndIncrement(var1,var2)拿到value值3,这时线程A被挂起。
- 线程B也通过getAndIncrement(var1,var2)方法获得value值3,此时刚好线程B没有被挂起并执行compareAndSwap方法比较内存值也为3,成功修改内存值为4,线程B打完收工,一切OK。
- 这是线程A恢复运行,执行compareAndSwapInt方法比较,发现手里的值3与内存值4不一致,说明该值已经被其他线程抢先异步修改过了,那A线程本次修改失败,只能重新读取重新来一遍了。
- 线程A重新获取value值,因为变量value被volatile修饰,所以其他线程对它的修改,线程A总是能够看到,线程A继续执行compareAndSwapInt进行比较替换,直到成功。
底层汇编:
Unsafe类中的compareAndSwaplnt,是一个本地方法,该方法的实现位于unsafe.cpp中
1 | UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x)) |
(Atomic::cmpxchg(x,addr,e)) == e
- 先想办法拿到变量value在内存中的地址。
- 通过Atomic::cmpxchg实现比较替换,其中参数x是即将更新的值,参数e是原内存的值。
3、Unsafe
Unsafe是CAS的核心类,由于Java方法无法直接访问底层系统,需要通过本地(native)方法来访问,Unsafe相当于一个后门,基于该类可以直接操作特定内存的数据。Unsafe类存在于sun.misc包中,其内部方法操作可以像C的指针一样直接操作内存,因为Java中CAS操作的执行依赖于Unsafe类的方法。
注意Unsafe类中的所有方法都是native修饰的,也就是说Unsafe类中的方法都直接调用操作系统底层资源执行相应任务。
其中:
- 变量valueOffset,表示该变量在内存中的偏移地址,因为Unsafe就是根据内存偏移地址获取数据的。
- 变量value用volatile修饰,保证了多线程之间的内存可见性。
4、CAS的缺点是什么?原子类Atomiclnteger的ABA问题谈谈?原子更新引用知道吗?
- 循环时间长开销大
- 只能保证一个共享变量的原子操作
- ABA问题
1、ABA问题
因为CAS需要在操作值的时候,检查值有没有发生变化,比如没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时则会发现它的值没有发生变化,但是实际上却变化了。
ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加1,那么A->B->A就会变成1A->2B->3A。
从Java 1.5开始,JDK的Atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法的作用是首先检查当前引用是否等于预期引用,并且检查当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
2、循环时间长开销大
自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令,那么效率会有一定的提升。
pause指令有两个作用:
- 第一,它可以延迟流水线执行命令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零;
- 第二,它可以避免在退出循环的时候因内存顺序冲突(Memory Order Violation)而引起CPU流水线被清空(CPU Pipeline Flush),从而提高CPU的执行效率。
3、只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁。
还有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量i = 2,j = a,合并一下ij = 2a,然后用CAS来操作ij。
从Java 1.5开始,JDK提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行CAS操作。
3、我们知道ArrayList是线程不安全,请编写一个不安全的案例并给出解决方案
ArrayList的add操作在多线程下是不安全的,会出现ConcurrentModificationException异常——并发修改异常
解决方法:
- 使用Vector集合代替ArrayList集合
- Vector的底层方法,如add方法加了synchronized锁,粒度大,并发性低,不推荐
- 使用Collections.synchronizedList集合包装ArrayList集合
- 底层也是加了synchronized锁,粒度大,并发性低,不推荐
- 使用JUC的CopyOnWriteArrayList集合代替ArrayList集合
- 推荐
JUC的CopyOnWriteArrayList集合:——解决ArrayList多线程不安全问题
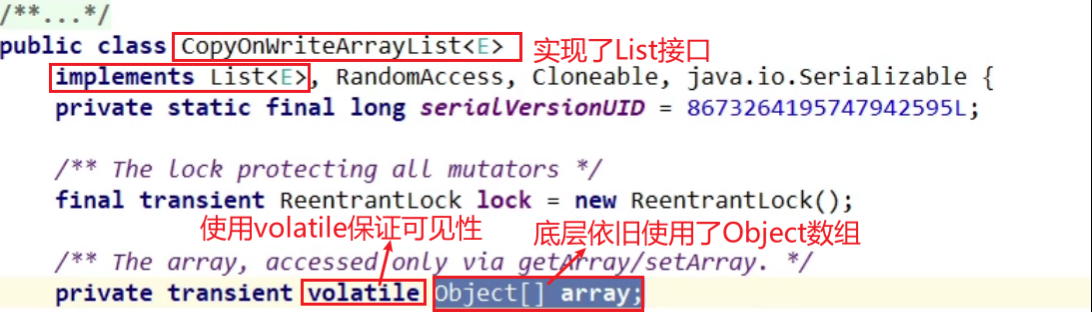
CopyOnWriteArrayList集合的add方法实现:
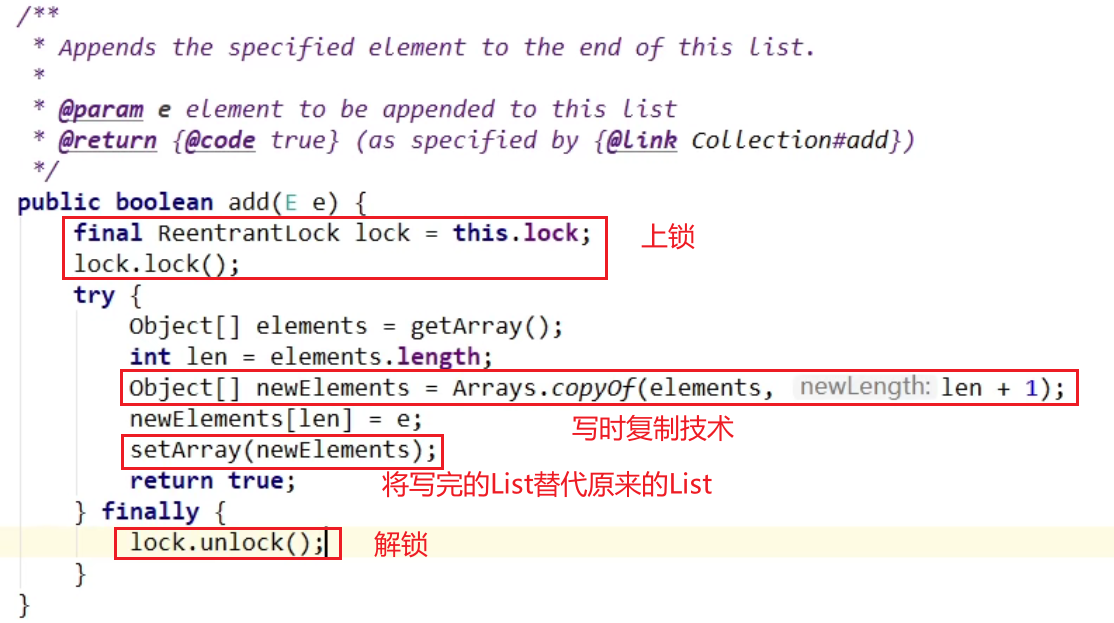
写时复制技术:
- CopyOnWrite容器即写时复制的容器。
- 往一个容器添加元素的时候,不直接往当前容器Object[]添加,而是先将当前object[]进行Copy,复制出一个新的容器Object[] newElements,然后新的容器Object[] newElements里添加元素,
- 添加完元素之后,再将原容器的引用指向新的容器:setArray(newElements);
- 这样做的好处是可以对copyonwrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。
- 所以copyonwrite容器也是一种读写分离的思想,读和写不同的容器。
JUC的CopyOnWriteArraySet集合:——解决HashSet多线程不安全问题
- 底层使用了上面的CopyOnWriteArrayList集合
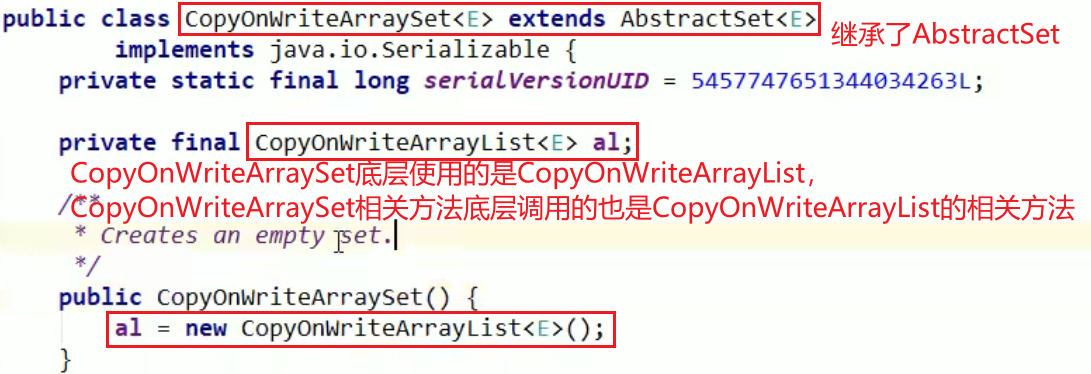
注:
- HashSet的底层是一个容量为18,负载因子为0.75的HashMap
- HashSet集合add的值是底层HashMap的key(不可重复)
- 底层HashMap的value是PRESENT——一个Object类型的常量
- CopyOnWriteArraySet的底层是一个CopyOnWriteArrayList
JUC的ConcurrentHashMap集合:——解决HashMap多线程不安全问题
注意:
- ConcurrentHashMap集合在JDK1.7与JDK1.8的底层实现不一样
ConcurrentHashMap JDK1.7:使用分段锁机制实现;ConcurrentHashMap JDK1.8:则使用数组+链表+红黑树数据结构和CAS原子操作实现;
- HashMap集合在JDK1.7与JDK1.8的底层实现也略微有一点差别
- JDK1.7的HashMap在多线程的环境下,扩容的过程中可能会出现并发死链问题
- 出现原因:JDK1.7的HashMap在添加元素是使用的是头插法
- JDK1.8的HashMap使用尾插法解决了并发死链问题
- 但是两种HashMap都不能解决在多线程的环境下出现ConCurrentModificationException问题
- JDK1.7的HashMap在多线程的环境下,扩容的过程中可能会出现并发死链问题
4、公平锁/非公平锁/可重入锁/递归锁/自旋锁谈谈你的理解?请手写一个自旋锁
1、公平锁和非公平锁
1、是什么
- 公平锁:是指多个线程按照申请锁的顺序来获取锁,类似排队打饭,先来后到。
- 非公平锁:是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。在高并发的情况下,有可能会造成优先级反转或者饥饿现象。
2、两者区别
公平锁/非公平锁:并发包中ReentrantLock的创建可以指定构造函数的boolean类型来得到公平锁或非公平锁,默认是非公平锁。
关于两者区别:
- 公平锁:Threads acquire a fair lock in the order in which they requested it.
- 公平锁,就是很公平,在并发情况下,每个线程在获取锁时会查看此锁维护的等待队列,如果为空,或者当前线程是等待队列的第一个,就占有锁,否则就会加入到等待队列中,以后会按照FIFO的规则从队列中取到自己。
- 非公平锁:非公平锁比较粗鲁,上来就直接尝试占有锁,如果尝试失败,就再采取类似公平锁那种方式。
3、ReentrantLock 与 Synchronized
Java ReentrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。非公平锁的优点在于吞吐量比公平锁大。
对于Synchronized而言,也是一种非公平锁。
2、可重入锁(又名递归锁)
可重入锁(也就是递归锁):指的是同一个线程外层函数获得锁之后,内层递归函数仍然能获取该锁的代码,在同一线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。
也就是说:线程可以进入任何一个它已经拥有的锁所有同步着的代码块。
- ReentrantLock/Synchronized就是一个典型的可重入锁
- 可重入锁最大的作用是避免死锁
- ReentrantLock可以获取多把的锁,但是需要配对进行解锁,否则会出现死锁问题
3、独占锁/共享锁
独占锁:指该锁一次只能被一个线程所持有。
- 对
ReentrantLock和Synchronized而言都是独占锁。
- 对
共享锁:指该锁可被多个线程所持有。
- 对
ReentrantReadWriteLock,其读锁是共享锁,其写锁是独占锁。读锁的共享锁可保证并发读是非常高效的,- 读写,写读,写写的过程是互斥的。
- 读读是共享的
- 对
4、自旋锁
自旋锁:是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁。
这样的好处是减少线程上下切换的消耗,缺点是循环会消耗CPU。
自己实现自旋锁:
1 | import java.util.concurrent.TimeUnit; |
5、synchronized和lock有什么区别?用新的lock有什么好处?你举例说说
- 原始构成
- synchronized是关键字,属于JVM层面,monitorenter(底层是通过monitor对象来完成,其实wait/notify等方法也依赖于monitor对象,只有在同步块或者方法中才能调用wait/notify等方法)
- Lock是具体类(java.util.concurrent.locks.lock)是api层面的锁。
- 使用方法
- synchronized不需要用户去手动释放锁,当synchronized代码执行完后系统会自动让线程释放对锁的占用。
- ReentrantLock则需要用户去手动释放锁,若没有主动释放锁,就有可能导致出现死锁现象。
- 需要lock()和unlock()方法配合try/finally语句块来完成。
- 等待是否可中断
- synchronized不可中断,除非抛出异常或者正常运行完成。
- ReentrantLock可中断
- 设置超时方法:tryLock(long timeout,TimeUnit unit);
- lockInterruptibly()放代码块中,调用interrupt()方法可中断。
- 加锁是否公平
- synchronized非公平锁
- ReentrantLock两者都可以,默认非公平锁,构造方法可以传入boolean值,true为公平锁,false为非公平锁。
- 锁绑定多个条件Condition
- synchronized没有Condition,进行唤醒时要不就是随机唤醒一个沉睡的线程,要不就是唤醒全部沉睡的线程
- ReentrantLock用来实现分组唤醒需要唤醒的线程,可以精确唤醒,而不是像synchronized要么随机唤醒一个要么唤醒全部线程。
5、CountDownLatch/CyclicBarrier/Semaphore
1、CountDownLatch——做减法
- 让一些线程阻塞直到另一个线程完成一系列操作后才被唤醒
- CountDownLatch主要有两个方法,当一个或多个线程调用await方法时,调用线程会被阻塞。其他线程调用countDown方法会将计数器减1(调用CountDown方法的线程不会阻塞),当计数器的值变为0时,因调用await方法被阻塞的线程会被唤醒,继续执行。
- 鲜明的例子:秦灭六国,统一中原(减法)
枚举与CountDownLatch实现对应线程的调用
CountDownLatch例子:
1 | import java.util.concurrent.CountDownLatch; |
国家枚举:
1 | public enum CountryEnum { |
2、CyclicBarrier——做加法
- CyslicBarrier的字面意思是可循环(Cyclic)使用的屏障(Barrier)。
- 它要做的事情是,让一组线程到达屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会打开门,所有被屏障拦截的线程才会继续干活,线程进入屏障通过CyclicBarrier的await()方法。
- 鲜明的例子:集七颗龙珠召唤神龙(加法)
3、Semaphore——伸缩(加减法)
- 信号量主要用于两个目的,一个是用于多个共享资源的互斥使用,另一个用于并发线程数的控制。
- 主要的方法:acquire()方法做减法,release()做加法,放在try/finally块当中执行
- 鲜明的例子:争抢车位
6、阻塞队列知道吗
1、队列+阻塞队列
阻塞队列,首先它是一个队列,而一个阻塞队列在数据结构中所起的作用大致是:线程1往阻塞队列中添加元素,而线程2从阻塞队列中移除元素。
- 当阻塞队列是空时,从队列中获取元素的操作将被阻塞。
- 当阻塞队列是满时,往队列里添加元素的操作将被阻塞。
- 试图从空的阻塞队列中获取元素的线程将会被阻塞,直到其他的线程往空的队列插入新的元素
- 同样,试图从已满的阻塞队列中添加元素的线程同样也会被阻塞,直到其他的线程从队列中移除一个或者多个元素或者完全清空队列后使队列重新变得空闲起来并后续新增
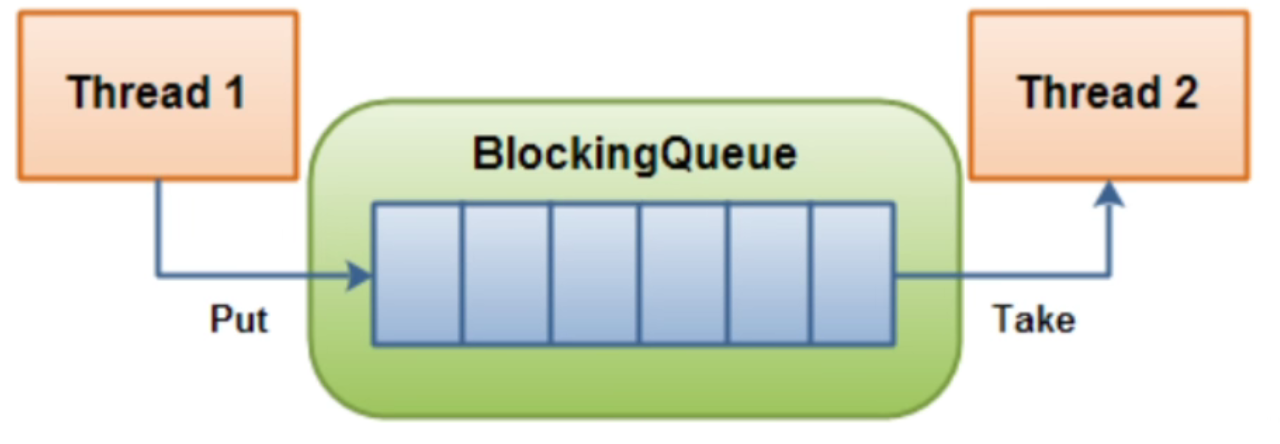
2、为什么用?有什么好处?
在多线程领域:所谓阻塞,在某些情况下会挂起线程(即阻塞),一旦满足条件,被挂起的线程又会自动被唤醒。
为什么需要BlockingQueue?
好处是我们不需要关心什么时候需要阻塞线程,什么时候需要唤醒线程,因为这一切BlockingQueue都给你包办了。
在concurrent包发布之前,在多线程环境下,我们每个程序员都必须去自己控制这些细节,尤其还要兼顾效率和线程安全,而这会给程序带来不小的复杂度。
3、架构梳理+种类分析
BlockingQueue和list都是Collections的接口。常用的BlockingQueue的实现类有
ArrayBlockingQueue**:由数组结构组成的有界**阻塞队列,此队列按FIFO(先进先出)原则对元素进行排序LinkedBlockingQueue**:由链表结构组成的有界**(但大小默认值为Integer.MAX_VALUE)阻塞队列,此队列按FIFO(先进先出)原则对元素进行排序,吞吐量通常要高于ArrayBlockingQueue。但是它要慎用,LinkedBlockingQueue虽然说是一个有界的阻塞队列,但是它的默认容量是Integer.MAX_VALUE——2147483647(21亿多,与无界差不了多少)SynchronousQueue**:一个不存储元素的阻塞队列,也即单个元素的队列**。每一个put操作必须要等待一个take操作,否则不能继续添加元素,反之亦然。- SynchronousQueue没有容量。
- 与其他BlockingQueue不同,SynchronousQueue是一个不存储元素的BlockingQueue。
- 吞吐量通常要高于LinkedBlockingQueue
PriorityBlockingQueue:支持优先级排序的无界阻塞队列。DelayQueue:使用优先级队列实现的延迟无界阻塞队列。LinkedTransferQueue:由链表结构组成的无界阻塞队列。LinkedBlockingDeque:由链表结构组成的双向阻塞队列。
4、BlockingQueue的核心方法
| 方法类型 | 抛出异常 | 特殊值 | 阻塞 | 超时 |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除 | remove() | poll() | take() | poll(time,unit) |
| 检查 | element() | peek() | 不可用 | 不可用 |
- 抛出异常
- 当阻塞队列满时,再往队列里add插入元素会抛
IllegalStateException Queue Full - 当阻塞队列空时,再往队列里remove移除元素会抛
NoSuchElementException
- 当阻塞队列满时,再往队列里add插入元素会抛
- 特殊值
- 插入方法,成功true失败false
- 移除方法,成功返回出队列的元素,队列里面没有就返回null
- 一直阻塞
- 当阻塞队列满时,生产者线程继续往队列里put元素,队列会一直阻塞生产线程直到put数据or响应中断退出
- 当阻塞队列空时,消费者线程试图从队列里take元素,队列会一直阻塞消费者线程直到队列可用
- 超时退出
- 当阻塞队列满时,队列会阻塞线程一定的时间,超过限时后生产者线程会退出,返回false
5、阻塞队列用在哪里
- 生产者消费者模式
- 传统版
- 使用的是RentranLock与Condition的await与signalAll返回
- 注意虚假唤醒问题
- 阻塞队列版
- 在资源类当中添加阻塞队列和相关和生产与消费的方法,通过offer与poll的进行超时调用
- 传统版
- 线程池
- 消息中间件的底层使用的就是阻塞队列
7、使用FutureTask 与 Callable的几个注意事项
1、使用FutureTask的注意事项
- 多个线程抢FutureTask,FutureTask只会执行一次
- 如果想要执行多次FutureTask,需要新建新的FutureTask对象给线程使用
- futureTask的get的方法可以获取运行futureTask的线程的运行结果,建议将该方法放在最后使用。
- 因为该方法需要得到Callable结果的计算结果,放在前面可能会导致当前线程出现阻塞等待Callable的结果的获取之后才能往下运行
- 如果不得不先获取futureTask的结果,可以使用idDone方法,以自旋锁的方式获取
2、Java有了Runnable接口,为什么还需要Callable接口?
先看看两者的源码:
Runnable.java
1 | // JDK1.0开始 |
Callable.java
1 | // JDK1.5开始 |
由他们本身的接口定义我们就能够看出它们的区别:
- callable的核心是call方法,允许返回值,runnable的核心是run方法,没有返回值
- call方法可以抛出异常,但是run方法不行
- 因为runnable是java1.0就有了,所以他不存在返回值,后期在java1.5进行了优化,就出现了callable,就有了返回值和抛异常
- 因此Callable接口实现类中run()方法允许将异常向上抛出,也可以直接在内部处理(try…catch)
- 而Runnable接口实现类中run()方法的异常必须在内部处理掉,不能向上抛出
- callable和runnable都可以应用于executors。而thread类只支持runnable
- runnable对象实例可以作为线程池方法
execute()的入口参数来执行任务; - callable对象实例可以作为线程池的
submit()方法入口参数来执行任务; - 运行Callable任务可拿到一个Future对象, Future表示异步计算的结果。它提供了检查计算是否完成的方法,以等待计算的完成,并检索计算的结果。 通过Future对象可了解任务执行情况,可取消任务的执行,还可获取任务执行的结果。
- Callable接口支持通过FutureTask异步返回执行结果,此时需要调用FutureTask.get()方法实现,此方法会阻塞线程直到获取“将来”的结果,当不调用此方法时,主线程不会阻塞。
8、线程池用过吗?ThreadPoolExecutor谈谈你的理解?
1、为什么用线程池?——线程池的优势
线程池主要是控制运行线程的数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
主要特点是:线程复用、控制最大并发数、管理线程。
- 第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
2、线程池如何使用?
1、架构说明
Java中的线程池是通过Executor框架实现的,该框架中用到了Executor,Executors,ExecutorService,ThreadPoolExecutor这几个类。
2、编码实现
- Executors.newScheduledThreadPool()
- java8新出:Executors.newWorkStealingPool(int)——使用所有可用处理器作为目标并行度,创建一个窃取线程的池。
- 使用目前机器上可用的处理器作为它的并行级别
- **Executors.newFixedThreadPool(int)**:一池固定线程数,执行长期的任务,性能好很多
- **Executors.newSingleThreadExecutor()**:一池一线程,一个任务一个任务执行的场景
- **Executors.newCachedThreadPool()**:一池多线程(可扩容),适用与执行很多短期异步的小程序或者负载较轻的服务器
1、Executors.newFixedThreadPool(int)
1 | /** |
主要特点:
- 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
- newFixedThreadPool创建的线程池corePoolSize和maximumPoolSize值是相等的,它使用的LinkedBlockingQueue。
2、Executors.newSingleThreadExecutor()
1 | /** |
主要特点:
- 创建一个单线程化的线程池,它只会唯一的工作线程来执行任务,保证所有任务按照指定顺序执行。
- newSingleThread将corePoolSize和maximumPoolSize都设置为1,它使用的是LinkedBlockingQueue。
3、Executors.newCachedThreadPool()
1 | /** |
主要特点:
- 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
- newCachedThreadPool将corePoolSize设置为0,将maximumPoolSize设置为Integer.MAX_VALUE,使用的SynchronousQueue,也就是说来了任务就创建线程运行,当线程空闲超过60秒,就销毁线程。
3、ThreadPoolExcutor
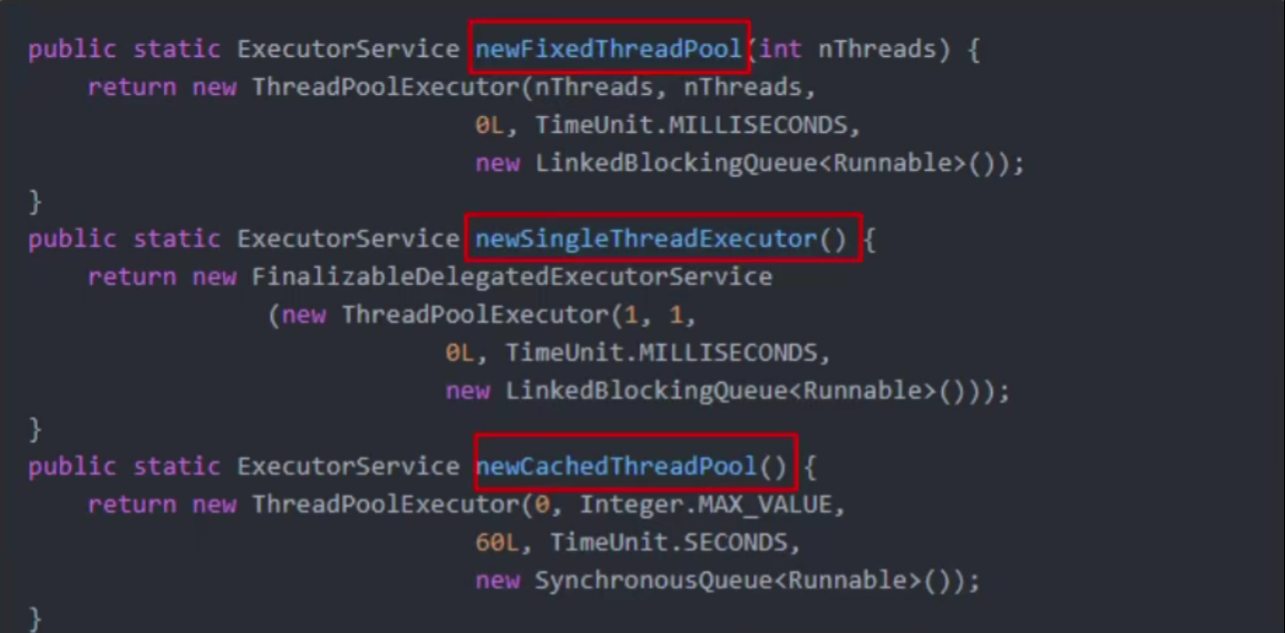
以上线程池的底层都是使用了ThreadPoolExcutor的构造方法,只是传入的参数有差别。这也是我们自定义线程池的方法
3、线程池的几个重要参数介绍
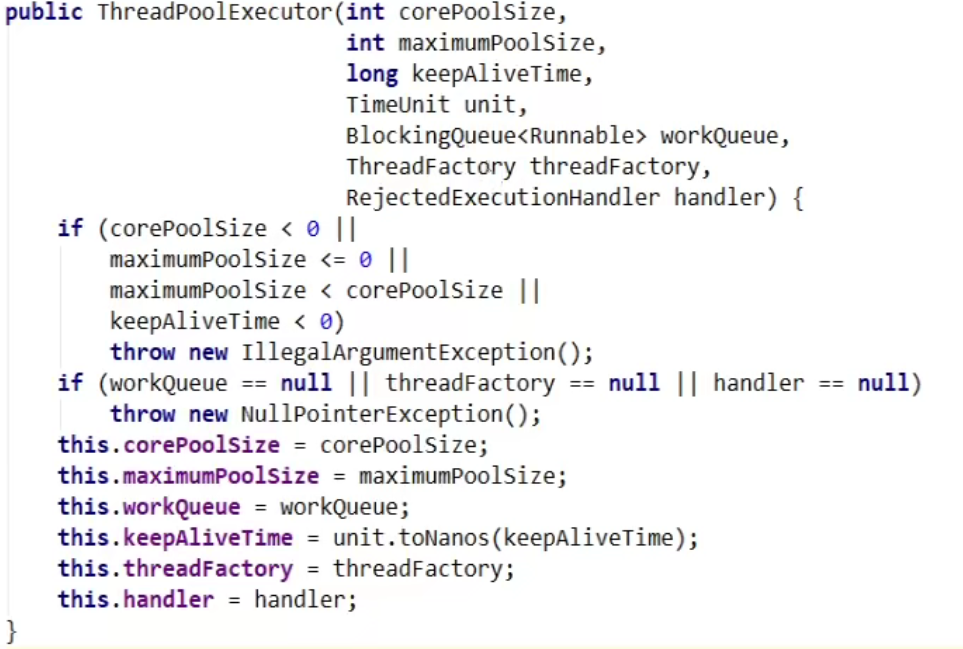
corePoolSize:线程池中的常驻核心线程数- 在创建线程池后,当有请求任务来之后,就会安排池中的线程去执行请求任务,近似理解为今日当值线程。
- 当线程池中的线程数目到达corePoolSize后,就会把到达的任务放到缓存队列当中。
maximumPoolSize:线程池能够容纳同时执行的最大线程数,此值必须大于等于1.keepAliveTime:多余的空闲线程的存活时间。- 当前线程池数量超过corePoolSize时,当空闲时间达到keepAliveTime值时,多余空闲线程会被销毁直到只剩下corePoolSize个线程为止。
- 默认情况下:只有当线程池中的线程数大于corePoolSize时keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize。
unit:keepAliveTime的单位workQueue:任务队列,被提交但尚未被执行的任务。threadFactory:表示生成线程池中工作线程的线程工厂,用于创建线程一般用默认的即可。- 也可以直接cv默认的,然后定义一下线程名字,出问题了好排错
handler:拒绝策略,表示当队列满了并且工作线程大于等于线程池的最大线程数,当有新的任务到来时采用的策略。
为什么在ThreadPoolExecutor的底层构造函数有七种参数,而线程池的创建却只有5个?剩下的那两个参数是什么?有什么作用?
答:
在线程池的创建当中使用的参数是前五个,剩下的那两个参数:
一个是生成线程池当中的线程的线程工厂,一般用默认的线程工厂进行工作线程的创建,因此提取出来在底层进行赋值,
最后一个参数是拒绝策略,作用是当队列满了并且工作线程大于等于线程池的最大线程数,当有新的任务到来时采用的策略。以上三个线程池的拒绝策略都是一样的——丢弃任务,并抛出拒绝执行 RejectedExecutionException 异常信息(线程池默认的拒绝策略)。因此也提取出来在底层进行赋值。

4、说说线程池的底层工作原理?
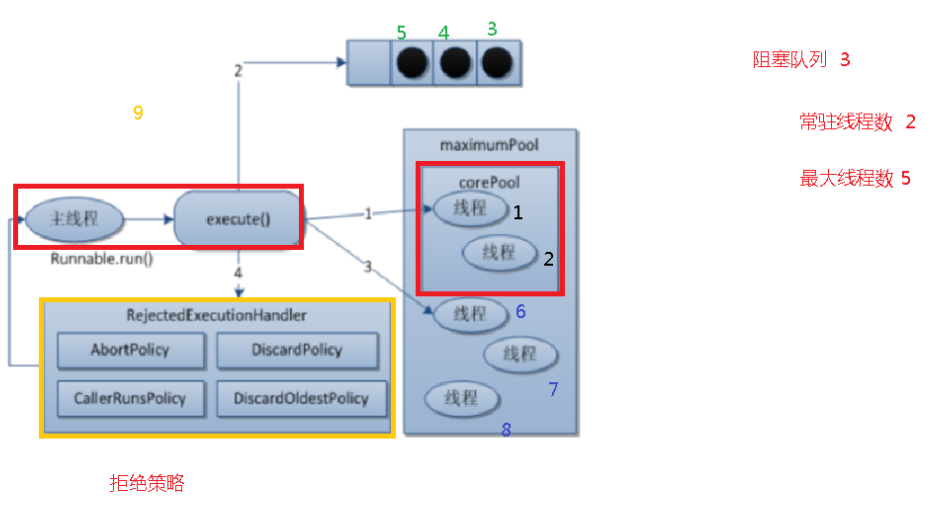
在创建了线程池后,线程池中的线程数为零,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。
当调用 execute()方法添加一个请求任务时,线程池会做出如下判断:
- 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
- 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入workQueue 队列;
- 如果这个时候队列满了且正在运行的线程数量还小于maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务(救急);
- 如果队列满了且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会启动饱和拒绝策略来执行。
当一个线程完成任务时,它会从队列中取下一个任务来执行
当一个线程无事可做超过一定的时间(keepAliveTime)时,线程会判断:
- 如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。
- 所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
9、线程池用过吗?生产上你是如何设置合理参数?
1、线程池的拒绝策略你谈谈?JDK内置的拒绝策略有哪些?
答:
线程池中,有三个重要的参数,决定影响了拒绝策略:corePoolSize - 核心线程数,也即最小的线程数。workQueue - 阻塞队列 。 maximumPoolSize -最大线程数。
当提交任务数大于 corePoolSize 的时候,会优先将任务放到 workQueue 阻塞队列中。当阻塞队列饱和后,会扩充线程池中线程数,直到达到maximumPoolSize 最大线程数配置。此时,再多余的任务,则会触发线程池的拒绝策略了。
总结起来,也就是一句话,当提交的任务数大于(workQueue.size() + maximumPoolSize ),就会触发线程池的拒绝策略。
四种拒绝策略:
CallerRunsPolicy:当触发拒绝策略,只要线程池没有关闭的话,则使用调用线程直接运行任务。一般并发比较小,性能要求不高,不允许失败。但是,由于调用者自己运行任务,如果任务提交速度过快,可能导致程序阻塞,性能效率上必然的损失较大;AbortPolicy:丢弃任务,并抛出拒绝执行 RejectedExecutionException 异常信息。线程池默认的拒绝策略。必须处理好抛出的异常,否则会打断当前的执行流程,影响后续的任务执行。DiscardPolicy:直接丢弃,其他啥都没有;DiscardOldestPolicy:当触发拒绝策略,只要线程池没有关闭的话,丢弃阻塞队列 workQueue 中最老的一个任务,并将新任务加入
除了线程池给的四种拒绝策略的实现,其他著名框架也提供了拒绝策略实现:
Dubbo的实现:在抛出RejectedExecutionException异常之前会记录日志,并 dump 线程栈信息,方便定位问题Netty的实现:创建一个新线程来执行任务ActiveMQ的实现:带超时等待(60s)尝试放入队列,类似我们之前自定义的拒绝策略PinPoint的实现:它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略
以上内置拒绝策略均实现了RejectedExecutionHandler接口(函数式接口)。
2、你在工作中单一的/固定数的/可变的单重创建线程池的方法,你用哪个多?
答:一个都不用,我们生产上只能使用自定义的
Executors中JDK已经给你提供了,为什么不用?

3、合理配置线程池你是如何考虑的?
- CPU密集型
- CPU密集的意思是该任务需要大量的运算,而没有阻塞,CPU一直全速运行。
- CPU密集型任务配置尽可能少的线程数量:一般公式为:CPU核数+1个线程的线程的线程池。
- IO密集型
- 第一种:由于IO密集型任务线程并不是一直执行任务,则应配置尽可能多的线程,如*CPU核数 * 2*
- 第二种:IO密集型,即该任务需要大量的IO,即大量的阻塞。
- 在单线程上运行IO密集型的任务会导致浪费大量的CPU运算能力浪费在等待。
- 所以IO密集型任务中使用多线程可以大大的加速程序运行,即使在单核CPU上,这种加速主要就是利用了被浪费掉的阻塞时间。
- IO密集型时,大部分线程都阻塞,故需要多配置线程数:参考公式:CPU核数/1-阻塞系数 阻塞系数在0.8-0.9之间。(一般乐观就设置为0.9)
- 混合型
- CPU密集型的任务与IO密集型任务的执行时间差别较小,拆分为两个线程池;否则没有必要拆分。
10、死锁编程及定位分析
答:
- 死锁是指两个或者两个以上的进程在执行过程中,因抢夺资源而造成的一种互相等待的现象,若无外力干涉它们将都无法推进下去,如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性也就很低,否则就会因争夺有限的资源而陷入死锁。
- 产生死锁的主要原因:
- 系统资源不足
- 进程运行推进的顺序不合适
- 资源分配不当
- 解决
- jps命令定位进程号
- jstack找到死锁查看
- 在服务器上可以用jatack 拉取出项目的内存日志 看线程的情况 可以看出死锁
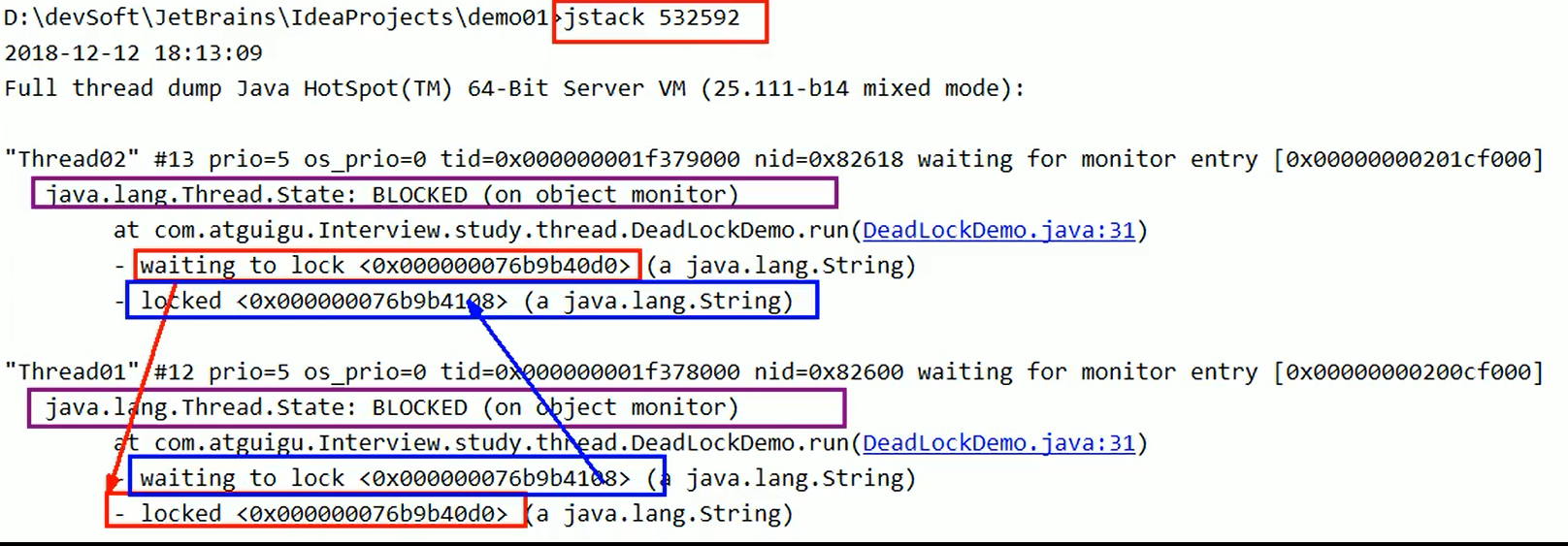
11、Java里面锁请谈谈你的理解,能说多少说多少
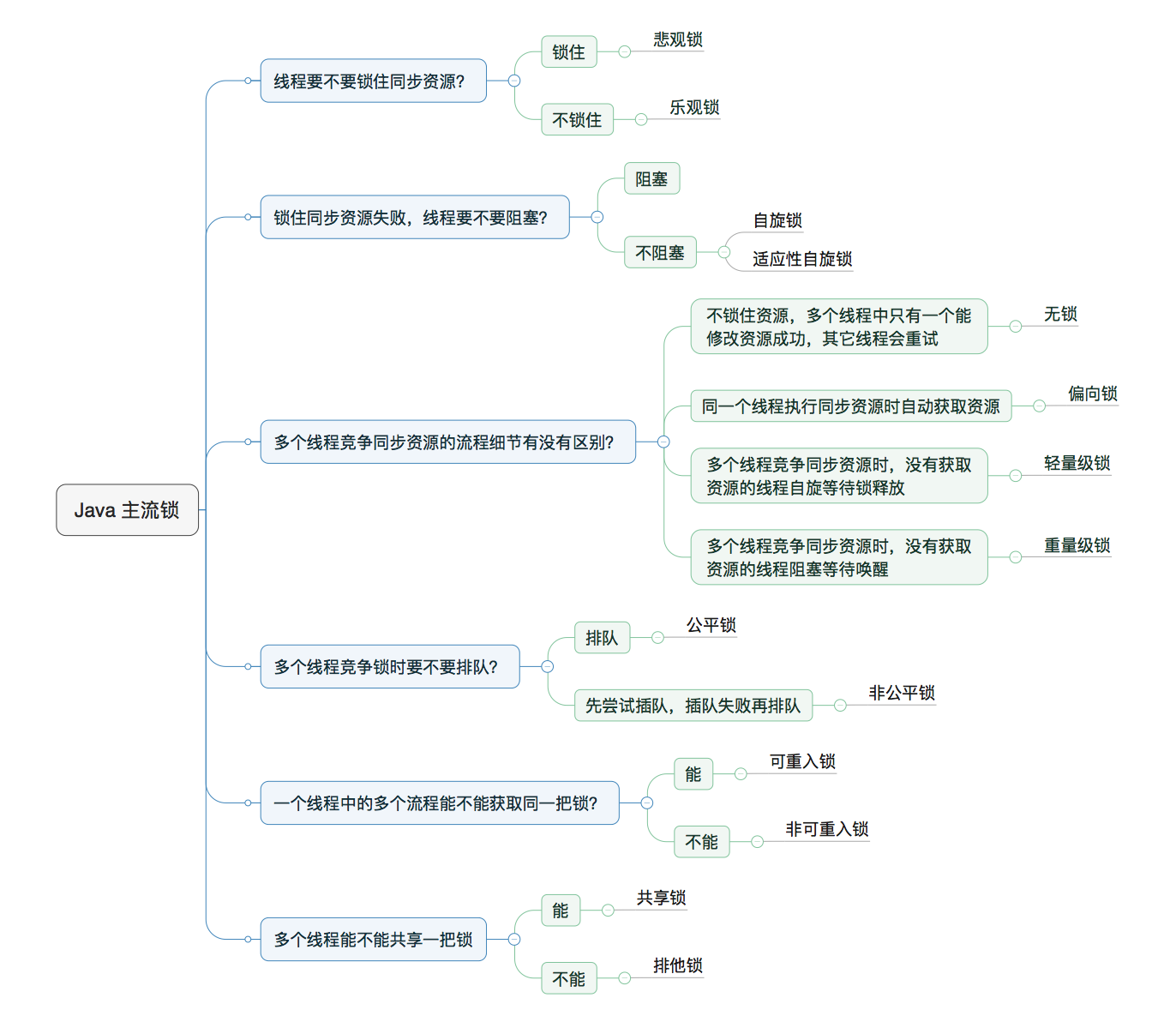
公平锁与非公平锁
- 公平锁:多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
- 优点:所有的线程都能得到资源,不会饿死在队列中。
- 缺点:吞吐量会下降很多,队列里面除了第一个线程,其他的线程都会阻塞,cpu唤醒阻塞线程的开销会很大。
- 非公平锁:多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。
- 优点:可以减少CPU唤醒线程的开销,整体的吞吐效率会高点,CPU也不必取唤醒所有线程,会减少唤起线程的数量。
- 缺点:可能导致队列中间的线程一直获取不到锁或者长时间获取不到锁,导致饿死。
- 公平锁:多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
可重入锁与不可重入锁
- 可重入锁:可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者class),不会因为之前已经获取过还没释放而阻塞。
- synchronized的重入的实现机理:
- 每个锁对象拥有一个锁计数器和一个指向持有该锁的线程的指针。
- 当执行monitorenter时,如果目标对象的计数器为零,那么说明它没有被其他线程所持有,Java虚拟机会将该锁对象的持有线程设置为当前线程,并且将其计数器加1。
- 在目标锁对象的计数器不为零的情况下,如果锁对象的持有线程是当前线程,那么Java虚拟机可以将其计数器加1,否则需要等待,直至持有线程释放该锁。
- 当执行monitorexit时,Java虚拟机则需将锁对象的计数器减1。计数器为零代表锁已被释放。
- synchronized的重入的实现机理:
- 不可重入锁:如果是不可重入锁的话,第一个锁没有解锁就不能操作第二个锁的内容
- 可重入锁:可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者class),不会因为之前已经获取过还没释放而阻塞。
死锁
- 两个或多个进程在运行过程中,因争夺资源而造成的一种相互等待的现象,当进程处于这种相互等待的状态时,若无外力作用,它们都将无法再向前推进。
活锁
- 活锁出现在两个线程互相改变对方的结束条件,最后谁也无法结束
乐观锁与悲观锁
- 悲观锁:当要对数据库中的一条数据进行修改的时候,为了避免同时被其他人修改,最好的办法就是直接对该数据进行加锁以防止并发。
- 悲观锁主要分为共享锁和排他锁:
- 共享锁【shared locks】又称为读锁,简称 S 锁。顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
- 排他锁【exclusive locks】又称为写锁,简称 X 锁。顾名思义,排他锁就是不能与其他锁并存,如果一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁。获取排他锁的事务可以对数据行读取和修改。
- 乐观锁:不会刻意使用数据库本身的锁机制,而是依据数据本身来保证数据的正确性。乐观锁的实现有CAS与版本号控制这两种方式
自旋锁与自适应自旋锁
- 自旋锁:在如今多处理器环境下,完全可以让另一个没有获取到锁的线程在门外等待一会(自旋),但==不放弃CPU的执行时间==。等待持有锁的线程是否很快就会释放锁。为了让线程等待,我们只需要让线程执行一个忙循环(自旋),这便是自旋锁由来的原因。
- 自适应自旋锁:自旋的时间不再固定了,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定的。
无锁、偏向锁、轻量级锁与重量级锁
- 无锁
- 无锁没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。
- 无锁的特点就是修改操作在循环内进行,线程会不断的尝试修改共享资源。如果没有冲突就修改成功并退出,否则就会继续循环尝试。如果有多个线程修改同一个值,必定会有一个线程能修改成功,而其他修改失败的线程会不断重试直到修改成功。上面我们介绍的CAS原理及应用即是无锁的实现。无锁无法全面代替有锁,但无锁在某些场合下的性能是非常高的。
- 偏向锁
- 偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁,降低获取锁的代价。
- 在大多数情况下,锁总是由同一线程多次获得,不存在多线程竞争,所以出现了偏向锁。其目标就是在只有一个线程执行同步代码块时能够提高性能。
- 当一个线程访问同步代码块并获取锁时,会在Mark Word里存储锁偏向的线程ID。在线程进入和退出同步块时不再通过CAS操作来加锁和解锁,而是检测Mark Word里是否存储着指向当前线程的偏向锁。引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令即可。
- 偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,线程不会主动释放偏向锁。偏向锁的撤销,需要等待全局安全点(在这个时间点上没有字节码正在执行),它会首先暂停拥有偏向锁的线程,判断锁对象是否处于被锁定状态。撤销偏向锁后恢复到无锁(标志位为“01”)或轻量级锁(标志位为“00”)的状态。
- 偏向锁在JDK 6及以后的JVM里是默认启用的。可以通过JVM参数关闭偏向锁:-XX:-UseBiasedLocking=false,关闭之后程序默认会进入轻量级锁状态。
- 轻量级锁
- 是指当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。
- 在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,然后拷贝对象头中的Mark Word复制到锁记录中。
- 拷贝成功后,虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,并将Lock Record里的owner指针指向对象的Mark Word。
- 如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为“00”,表示此对象处于轻量级锁定状态。
- 如果轻量级锁的更新操作失败了,虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行,否则说明多个线程竞争锁。
- 若当前只有一个等待线程,则该线程通过自旋进行等待。但是当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁。
- 重量级锁
- 升级为重量级锁时,锁标志的状态值变为“10”,此时Mark Word中存储的是指向重量级锁的指针,此时等待锁的线程都会进入阻塞状态。
- 无锁
饥饿问题
- 一个线程由于优先级太低,始终得不到 CPU 调度执行,也不能够结束
表锁与行锁
表锁:当一个线程在给一张表进行数据操作的时候,会将整一张表都锁起来。在它操作完成之前,其他线程不能对这张表的所有数据进行操作。
表锁:意向锁
表锁,其实也可以叫意向锁,表明“某个事务正在某些行持有了锁、或该事务准备去持有锁”。
意向锁产生的主要目的是为了处理行锁和表锁之间的冲突:
- 事务在请求S锁和X锁前,需要先获得对应的IS、IX锁,
- 在为数据行加共享 / 排他锁之前,InooDB 会先获取该数据行所在在数据表的对应意向锁。
- 意向共享锁(IS锁):事务在请求S锁前,要先获得IS锁
- 意向排他锁(IX锁):事务在请求X锁前,要先获得IX锁
行锁:一个线程在对一张表的某一行数据进行操作的时候,会将那一行数据锁起来,在它操作完成之前,其他线程不能对这一行数据进行操作,但是对原这张表的其他行数据进行操作是允许的。
- 行锁:记录锁(Record Locks)
- mysql的行锁是通过索引加载的,即行锁是加在索引响应的行上的,要是对应的SQL语句没有走索引,则会全表扫描.
- 行锁:间隙锁(Gap Locks)
- 区间锁,仅仅锁住一个索引区间(开区间,不包括双端端点)。
- 在索引记录之间的间隙中加锁,或者是在某一条索引记录之前或者之后加锁,==并不包括该索引记录本==身。比如在 1、2、3中,间隙锁的可能值有 (∞, 1),(1, 2),(2, ∞),
- 间隙锁可用于防止幻读,保证索引间的不会被插入数据
- 行锁:临键锁(Next-Key Locks)
- record lock + gap lock,左开右闭区间。
- 默认情况下,innodb使用next-key locks来锁定记录。
- 但当查询的索引含有唯一属性的时候,Next-Key Lock 会进行优化,将其降级为Record Lock,即仅锁住索引本身,不是范围。
- Next-Key Lock在不同的场景中会退化成记录锁或间隙锁
- 行锁:记录锁(Record Locks)
关于锁的优化:
- 锁消除
- 锁消除时指虚拟机即时编译器再运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除。锁消除的主要判定依据来源于逃逸分析的数据支持。
- 意思就是:JVM会判断在一段程序中的同步明显不会逃逸出去从而被其他线程访问到,那JVM就把它们当作栈上数据对待,认为这些数据时线程独有的,不需要加同步。此时就会进行锁消除。
- 当然在实际开发中,我们很清楚的知道那些地方时线程独有的,不需要加同步锁,但是在Java API中有很多方法都是加了同步的,那么此时JVM会判断这段代码是否需要加锁。如果数据并不会逃逸,则会进行锁消除。(eg:StringBuffer到StringBulider的转换)
- 锁粗化
- 如果存在连串的一系列操作都对同一个对象反复加锁和解锁,甚至加锁操作时出现在循环体中的,那即使没有线程竞争,频繁地进行互斥同步操作也会导致不必要地性能操作。JVM会检测到这样一连串地操作都是对同一个对象加锁,那么JVM会将加锁同步地范围扩展(粗化)到整个一系列操作的外部,使整个一连串地append()操作只需要加锁一次就可以了。
- 锁升级/锁膨胀
- 如果在尝试加轻量级锁的过程中,CAS 操作无法成功,这时一种情况就是有其它线程为此对象加上了轻量级锁(有竞争),这时需要进行锁膨胀,将轻量级锁变为重量级锁。

12、关于LockSupport的面试题
1、为什么可以先唤醒线程后阻塞线程?
因为unpark获得了一个凭证,之后再调用park方法,就可以名正言顺的凭证消费,故不会阻塞
2、为什么唤醒两个后阻塞两次。但是最终结果还会阻塞线程?
因为凭证的数量最多为1,连续调用两个unpark和调用一次unpark效果一样,只会增加一个凭证;而调用两次park却需要消费两个凭证,凭证不够,故会阻塞。
13、关于AQS
1、AQS 是什么
字面意思:AQS(AbstractQueuedSynchronizer):抽象的队列同步器
一般我们说的 AQS 指的是 java.util.concurrent.locks 包下的 AbstractQueuedSynchronizer,但其实还有另外三种抽象队列同步器:AbstractOwnableSynchronizer、AbstractQueuedLongSynchronizer 和 AbstractQueuedSynchronizer
技术翻译:AQS 是用来构建锁或者其它同步器组件的重量级基础框架及整个JUC体系的基石, 通过内置的FIFO队列来完成资源获取线程的排队工作,并通过一个int类变量(state)表示持有锁的状态
CLH:Craig、Landin and Hagersten 队列,是一个双向链表,AQS中的队列是CLH变体的虚拟FIFO双向队列
2、AQS 是 JUC 的基石
和AQS有关的并发编程类:
进一步理解锁和同步器的关系:
锁:面向锁的使用者。定义了程序员和锁交互的使用层API,隐藏了实现细节,你调用即可,可以理解为用户层面的 API。同步器:面向锁的实现者。比如Java并发大神Douglee,提出统一规范并简化了锁的实现,屏蔽了同步状态管理、阻塞线程排队和通知、唤醒机制等,Java 中有那么多的锁,就能简化锁的实现。
3、AQS 能干嘛
AQS:加锁会导致阻塞
有阻塞就需要排队,实现排队必然需要有某种形式的队列来进行管理
抢到资源的线程直接使用办理业务,抢占不到资源的线程的必然涉及一种排队等候机制,抢占资源失败的线程继续去等待(类似办理窗口都满了,暂时没有受理窗口的顾客只能去候客区排队等候),仍然保留获取锁的可能且获取锁流程仍在继续(候客区的顾客也在等着叫号,轮到了再去受理窗口办理业务)。
既然说到了排队等候机制,那么就一定会有某种队列形成,这样的队列是什么数据结构呢?如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是CLH队列的变体实现的,将暂时获取不到锁的线程加入到队列中,这个队列就是AQS的抽象表现。它将请求共享资源的线程封装成队列的结点(Node) ,通过CAS、自旋以及LockSuport.park()的方式,维护state变量的状态,使并发达到同步的效果。
4、AQS 初步认识
1、AQS初识
官网解释:

有阻塞就需要排队,实现排队必然需要队列:
- AQS使用一个volatile的int类型的成员变量来表示同步状态,通过内置的 FIFO队列来完成资源获取的排队工作将每条要去抢占资源的线程封装成 一个Node节点来实现锁的分配,通过CAS完成对State值的修改。
- Node 节点是啥?
- 答:你有见过 HashMap 的 Node 节点吗?JDK 用 static class Node<K,V> implements Map.Entry<K,V> 来封装我们传入的 KV 键值对。
- 这里也是一样的道理,JDK 使用 Node 来封装(管理)Thread
- 可以将 Node 和 Thread 类比于候客区的椅子和等待用餐的顾客

2、AQS内部体系架构
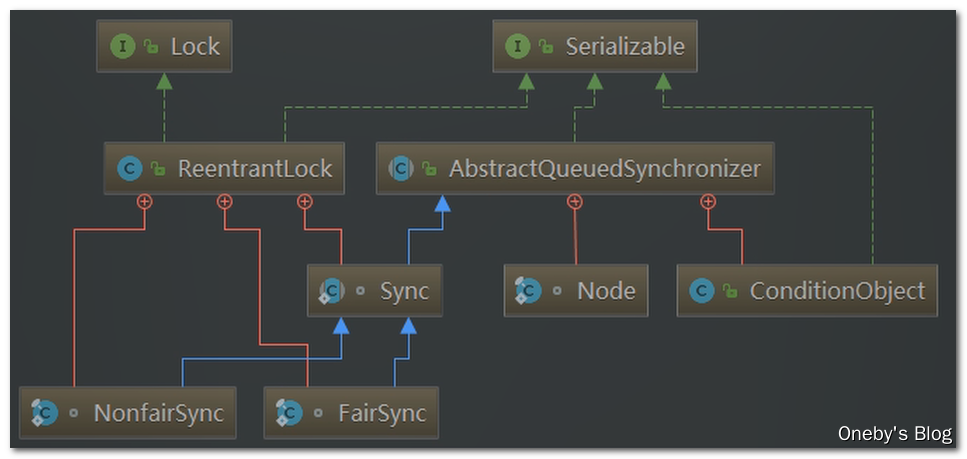
AQS的int变量
1
2
3
4/**
* The synchronization state.
*/
private volatile int state;AQS的同步状态State成员变量,类似于银行办理业务的受理窗口状态:零就是没人,自由状态可以办理;大于等于1,有人占用窗口,需要等待
AQS的CLH队列
CLH队列(三个大牛的名字组成),原是一个双向链表,被AQS修改为一个双向队列,类似于银行侯客区的等待顾客
内部类Node(Node类在AQS类内部)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35/**
* Status field, taking on only the values:
* SIGNAL: The successor of this node is (or will soon be)
* blocked (via park), so the current node must
* unpark its successor when it releases or
* cancels. To avoid races, acquire methods must
* first indicate they need a signal,
* then retry the atomic acquire, and then,
* on failure, block.
* CANCELLED: This node is cancelled due to timeout or interrupt.
* Nodes never leave this state. In particular,
* a thread with cancelled node never again blocks.
* CONDITION: This node is currently on a condition queue.
* It will not be used as a sync queue node
* until transferred, at which time the status
* will be set to 0. (Use of this value here has
* nothing to do with the other uses of the
* field, but simplifies mechanics.)
* PROPAGATE: A releaseShared should be propagated to other
* nodes. This is set (for head node only) in
* doReleaseShared to ensure propagation
* continues, even if other operations have
* since intervened.
* 0: None of the above
*
* The values are arranged numerically to simplify use.
* Non-negative values mean that a node doesn't need to
* signal. So, most code doesn't need to check for particular
* values, just for sign.
*
* The field is initialized to 0 for normal sync nodes, and
* CONDITION for condition nodes. It is modified using CAS
* (or when possible, unconditional volatile writes).
*/
volatile int waitStatus;Node的等待状态waitState成员变量,类似于等候区其它顾客(其它线程)的等待状态,队列中每个排队的个体就是一个Node
Node类的内部结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29static final class Node{
//共享
static final Node SHARED = new Node();
//独占
static final Node EXCLUSIVE = null;
//线程被取消了
static final int CANCELLED = 1;
//后继线程需要唤醒
static final int SIGNAL = -1;
//等待condition唤醒
static final int CONDITION = -2;
//共享式同步状态获取将会无条件地传播下去
static final int PROPAGATE = -3;
// 初始为e,状态是上面的几种
volatile int waitStatus;
// 前置节点
volatile Node prev;
// 后继节点
volatile Node next;
// ...
3、总结
有阻塞就需要排队,实现排队必然需要队列
- AQS就是通过state 变量 + CLH双端 Node 队列(头尾指针)实现
- Node就是通过waitStatus + 前后指针 实现
Node当中的属性说明:
两种模式:
| 模式 | 含义 |
|---|---|
| SHARED | 表示线程以共享的模式等待锁 |
| EXCLUSIVE | 表示线程正在以独占的方式等待锁 |
六个属性:
| 方法和属性值 | 含义 |
|---|---|
| waitStatus | 当前节点在队列当中的状态 |
| thread | 表示处于该节点的线程 |
| prev | 前驱指针 |
| next | 后继指针 |
| predecessor | 返回前驱节点,没有的话抛npe |
| nextWaiter | 指向下一个处于CONDITION状态的节点 |
waitStatus的五种取值:
| 枚举 | 含义 |
|---|---|
| 0 | 当一个Node被初始化的时候的默认值 |
| CANCELLED | 为1,表示线程获取锁的请求已经取消了 |
| CONDITION | 为-2,表示节点在等待队列当中,节点线程等待唤醒 |
| PROPAGATE | 为-3,当前线程处于SHARED情况下,该字段才会使用。共享式同步状态获取将会无条件地传播下去 |
| SIGNAL | 为-1,表示线程已经准备好了,就等资源释放了 |
4、AQS底层是怎么排队的?
通过调用 LockSupport.pork() 来进行排队
5、AQS的源码解读(通过ReentrantLock为突破口)
1、加锁
只要涉及到加锁,底层会调用NonfairSync的lock()方法来进行加锁。(以ReentrantLock的非公平锁为例)
1 | final void lock() { |
- 如果当前资源锁的状态为0,则表示当前没有线程占有锁
- 使用CAS将锁状态从0设置为1,并将当前线程设置为占有此锁
- CAS设置失败表示当前已经有线程占用该锁,进入acquire()方法
而AQS的acquire()方法是一个模板方法,如果子类没有重写该方法就会抛出异常。
而子类的重写肯定会调用如下三个方法进行锁的抢夺与线程阻塞:
1 | public final void acquire(int arg) { |
tryAcquire():试图获取锁
首先再次获取当前资源的锁的状态——因为此时可能出现此时占用锁的线程已经释放锁的情况
- 如果当前资源锁的状态为0,则表示当前没有线程占有锁——证明之前占用锁的线程已经释放了锁
- 使用CAS将锁状态从0设置为1,并将当前线程设置为占有此锁
- 返回true,由于前面的
!取反之后为false,退出if块
如果当前锁的状态不等于0,表示当前有线程占有锁,则判断当前占用锁的线程是不是当前线程
- 如果是当前线程,表示此时正是锁的重入
- 增加重入的次数,并将其设置进锁的状态status当中
- 返回true,由于前面的
!取反之后为false,退出if块
如果不是以上两种情况,返回false。由于前面的
!取反之后为true,继续执行addWaiter()方法。注:公平锁与非公平锁的区别就是在第一个if判断中:公平锁的最前面有!hasQueuePredecessors()方法判断当前的CLH等待队列中是否有等待的线程,而非公平锁没有该方法。
hasQueuePredecessors()方法如何能体现公平锁与非公平锁的区别?
- 当一个新的线程来抢占锁,如果当前的CLH等待队列中有等待的线程,那么直接返回true,在
!取反为false直接退出if块,不进行之后锁的CAS抢占。tryAcquire()方法直接返回false - 之后由addWaiter()方法添加进CLH等待队列——体现了公平
- 如果没有hasQueuePredecessors()方法,那么新来的线程会与等待队列中头结点的下一个线程(正在被唤醒的线程)一同争抢锁
- 当前等待队列中头结点的下一个线程有可能争抢失败继续进入等待队列的最尾部继续等待唤醒,有可能导致饥饿现象——体现了非公平
- 当一个新的线程来抢占锁,如果当前的CLH等待队列中有等待的线程,那么直接返回true,在
addWaiter():将当前线程封装成一个节点Node加入CLH等待队列
- 将当前的线程包装成一个节点Node,此时Node的属性为
- Thread:当前线程
- mode:Node.EXCLUSIVE(独占模式)
- waitStatus:0
- prev/next:null
- CLH等待队列的尾节点赋值pred——一开始肯定为null,后面为tail指向的节点
- 判断尾结点是否为null——一开始肯定为null,不进入if块,执行下面的enq(node)入队方法
- 不为null的话,将当前节点(也就是线程的节点)的prev指针指向尾节点
- 使用CAS将CLH等待队列的尾节点从尾节点指向当前节点(线程节点)
- 将尾节点的next指针指向当前节点(线程节点)
- 返回当前节点(线程节点)——此时当前节点(线程节点)的属性
- Thread:当前线程
- mode:Node.EXCLUSIVE(独占模式)
- waitStatus:0
- prev:尾节点
- next:null
- 如果尾节点为null的话,进入enq(node)入队方法:enq(node)方法是一个自旋锁for(;;)
- CLH等待队列的尾节点赋值t
- 如果当前尾结点为null的话,就要进行一些初始化操作——一开始肯定为null
- 使用CAS创建一个哨兵节点(空节点),并且将CLH等待队列的头结点与尾结点都指向该哨兵节点
- 结束f块继续进入自旋
- 如果当前尾结点不为null的话——初始化操作之后的尾结点就不为null了
- 将当前节点当前节点(线程节点)的prev指向尾节点
- 使用CAS将CLH等待队列的尾节点从尾节点指向当前节点(线程节点)
- 将尾节点的next指针指向当前节点(线程节点)
- 返回尾结点
注:
- 第一个进入CLH等待队列的线程执行路线:1 ==》 2 ==》 4 ==》 5
- 后面进入CLH等待队列的线程执行路线:1 ==》 2 ==》 3
- 将当前的线程包装成一个节点Node,此时Node的属性为
acquireQueued(final Node node, int arg):将当前节点的前驱节点的waitStatus状态修改为SINGAL(-1)——acquireQueued)方法也是一个自旋锁for(;;)
设置一个失败的标志变量failed为true,目的是为了下面finally块当中线程的取消做准备
try块
设置一个中断的标志变量interrupted为false
自旋:
获取当前节点(线程节点)的前驱节点
如果当前节点(线程节点)的前驱节点为头结点并且当前节点(线程节点)试图获取锁成功——当前节点(线程节点)依旧没有放弃获取锁(或者被唤醒之后试图获取锁),注意此时是头结点的下一个线程结点
- 将当前节点(线程节点)设置为CLH等待队列的头结点——此时的当前节点(线程节点)已经抢到了锁
- 将前哨兵节点的next指向null——此时的前哨兵节点就没有任何的引用指向,慢慢地就会被GC回收掉,此时的当前节点(线程节点)的就是最新的哨兵节点
- 将失败的标志变量failed修改为false
- 返回中断的标志变量interrupted为false
判断当前节点试图获取锁失败之后是否应该被park挂起shouldParkAfterFailedAcquire(p, node)方法——别忘了acquireQueued方法是一个自旋方法,即shouldParkAfterFailedAcquire(p, node)方法会被多次执行直至线程被挂起或者抢到锁
- 获取前驱节点的waitStatus
- 如果前驱节点的waitStatus是SINGAL(-1)——负责唤醒它的下一个线程,返回true
- 如果前驱节点的waitStatus大于0,即CANCELLED(1)——表示前驱节点要被取消了
- 使用自旋锁的方式当前节点的prev节点修改为前驱节点的prev
- 前驱节点的前驱节点的next指向当前节点
- 返回false
- 否则,使用CAS将前驱节点的waitStatus从ws修改为SINGAL
- 返回false
返回false之后继续进行acquireQueued方法的自旋,继续试图去抢夺锁,失败之后继续进入shouldParkAfterFailedAcquire()方法
此时前驱节点的waitStatus为SINGAL(-1),返回true。继续执行parkCheckInterrupt()方法
执行parkCheckInterrupt()方法将线程进行park挂起
- 调用LockSupport的park方法将当前线程挂起,等待抢占锁的节点的unpark进行唤醒
finally块
- 如果失败的标志变量failed为true
- 取消当前节点
- 如果失败的标志变量failed为true
以上6个方法的相关源码:
tryAcquire():试图获取锁
1 | // 非公平锁实现 |
addWaiter():将当前线程封装成一个节点Node加入CLH等待队列
1 | private Node addWaiter(Node mode) { |
enq():构建CLH等待队列,将当前节点加入CLH等待队列
1 | private Node enq(final Node node) { |
acquireQueued(final Node node, int arg):将当前节点的前驱节点的waitStatus状态修改为SINGAL(-1)
1 | final boolean acquireQueued(final Node node, int arg) { |
shouldParkAfterFailedAcquire(p, node):判断当前节点在获取锁失败之后是否应该挂起
1 | private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { |
parkAndCheckInterrupt():挂起线程
1 | private final boolean parkAndCheckInterrupt() { |
流程图:
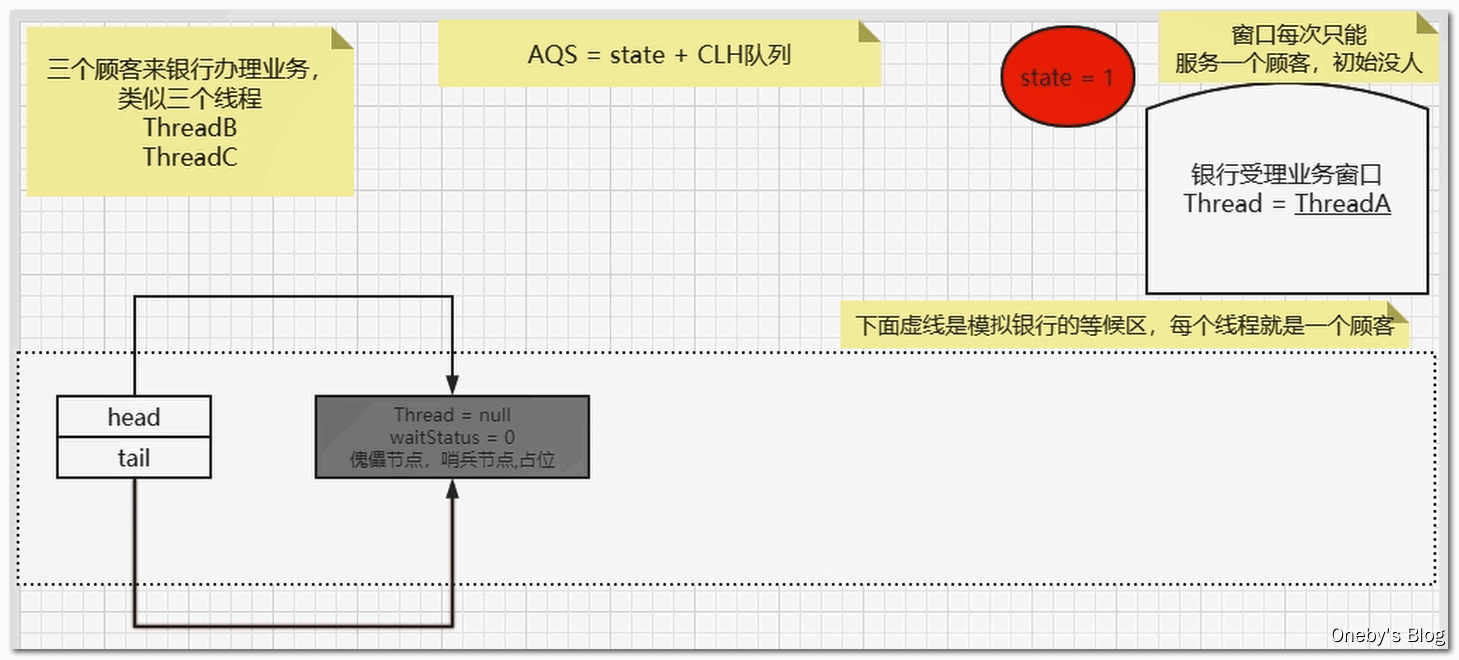
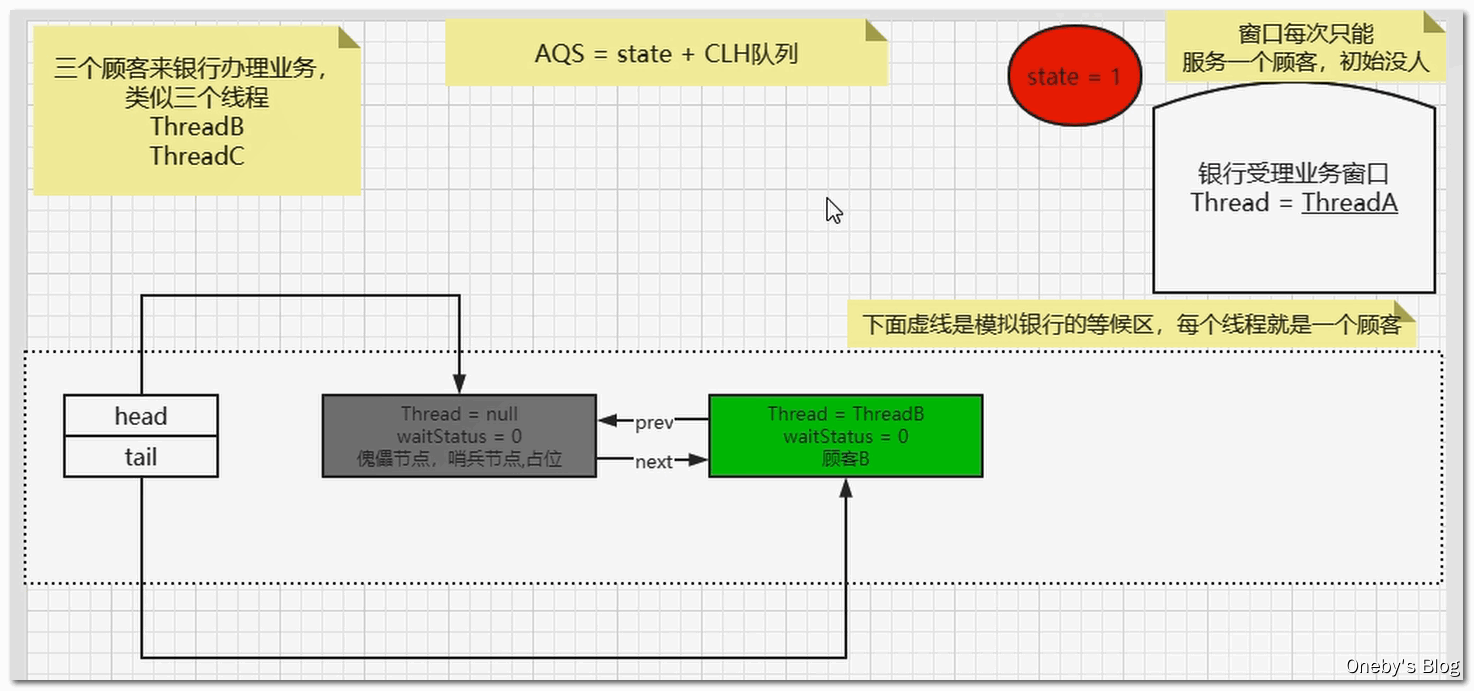
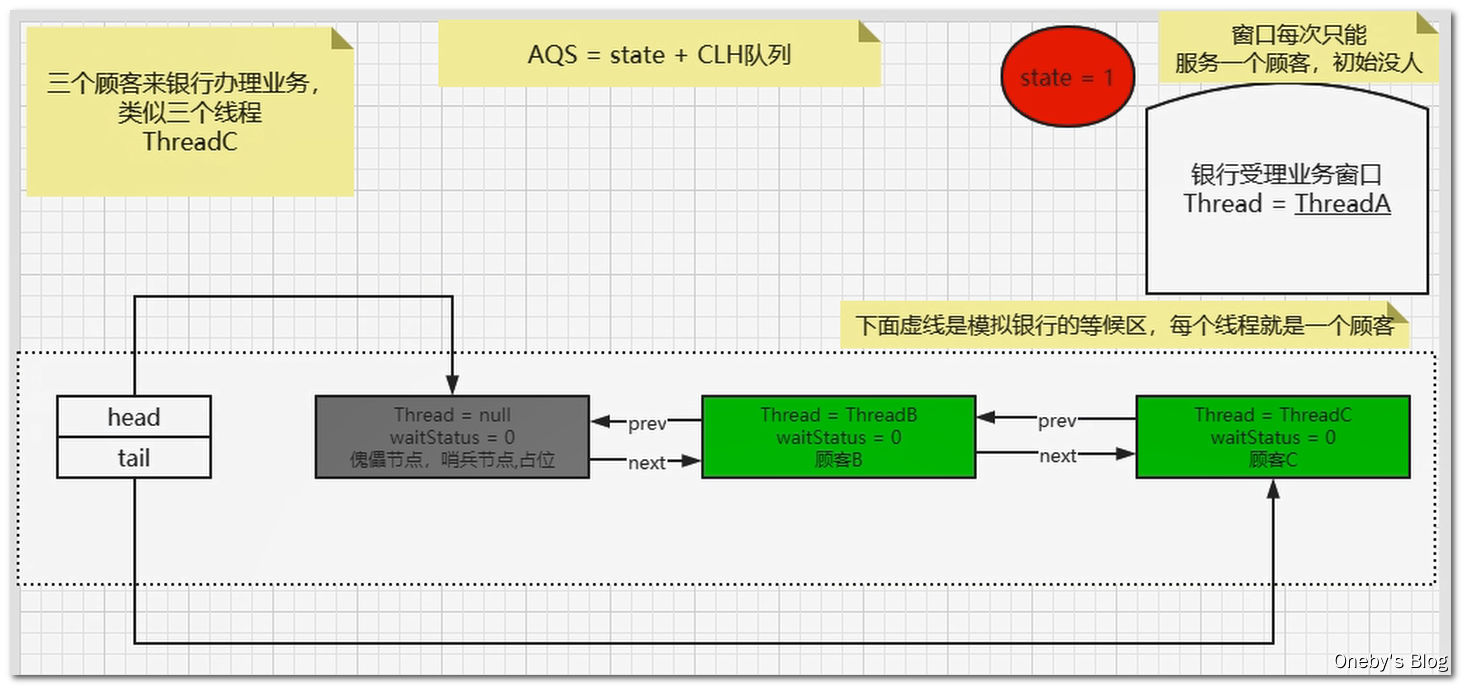
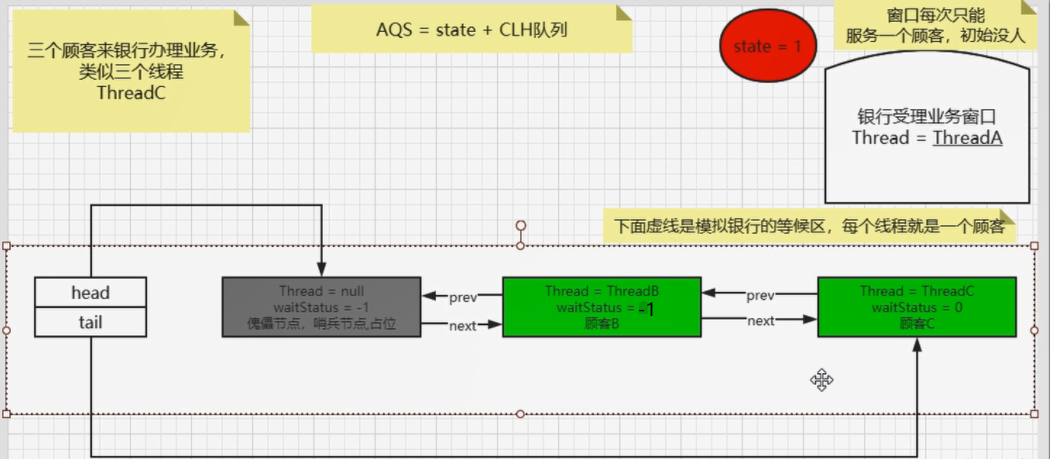
2、解锁
ReentrantLock调用unLock进行解锁,unlock() 方法底层调用了 sync.release(1) 方法
1 | public final boolean release(int arg) { |
以上主要是两个方法:
- tryRelease():试图释放锁
- unparkSuccessor():唤醒CLH等待队列哨兵节点之后的第一个线程节点
tryRelease():试图释放锁
1 | protected final boolean tryRelease(int releases) { |
unparkSuccessor():唤醒CLH等待队列哨兵节点之后的第一个线程节点
1 | private void unparkSuccessor(Node node) { |
流程图:
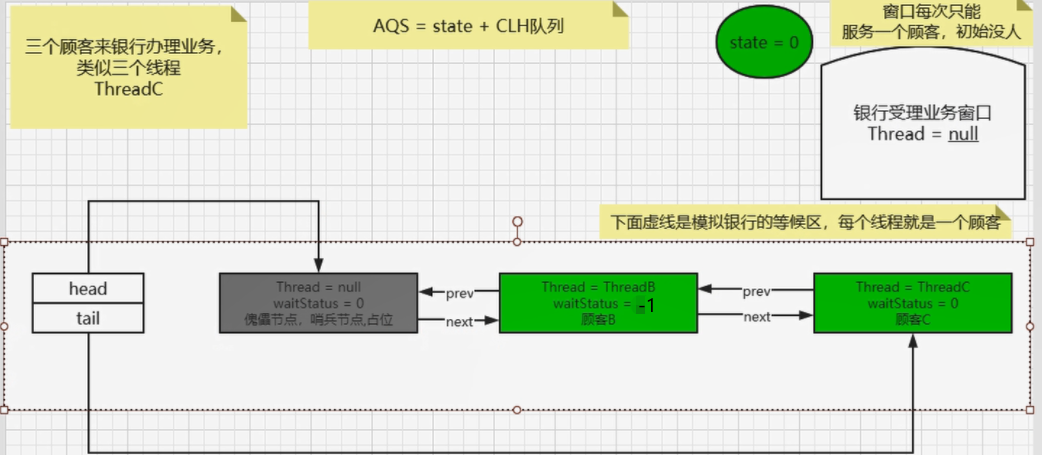
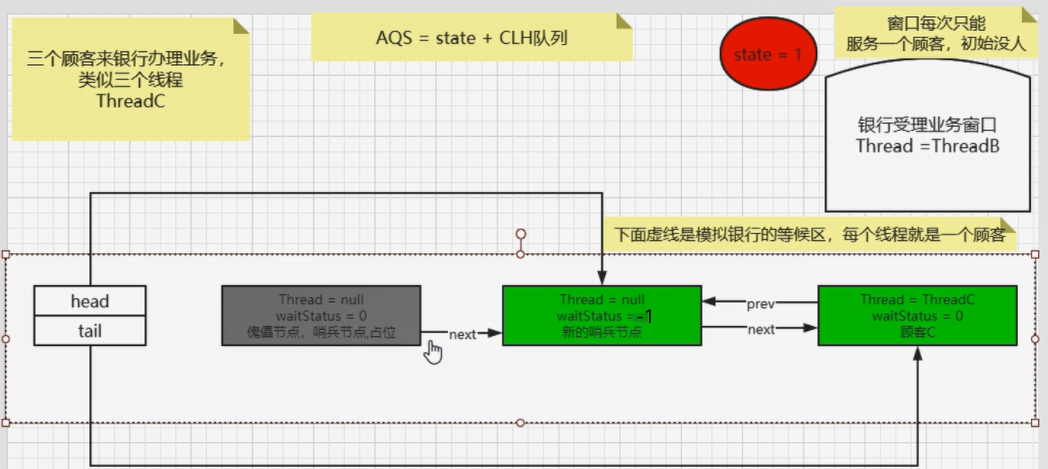
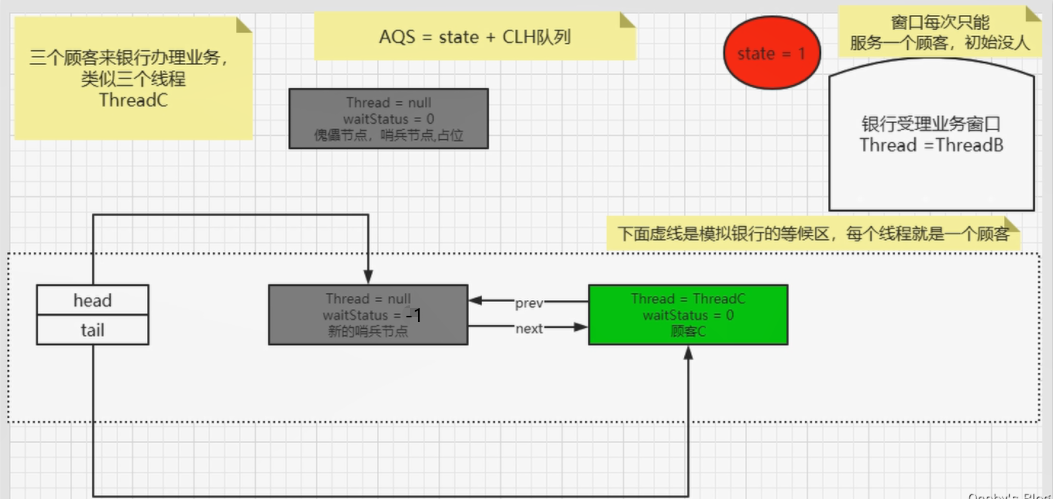
3、AQS 的面试考点
第一个考点:我相信你应该看过源码了,那么AQS里面有个变量叫State,它的值有几种?
答:3个状态:没占用是0,占用了是1,大于1是可重入锁
第二个考点:如果锁正在被占用,AB两个线程进来了以后,请问这个时候CLH等待队列当中总共有多少个Node节点?
答:答案是3个,分别是哨兵节点、nodeA、nodeB
第三个考点:在占有锁的线程释放锁的过程中,此时CLH等待队列中的头节点的下一个节点被取消了,此时占有锁的线程唤醒的是CLH队列当中的哪一个挂起线程?
答:唤醒的是CLH等待队列当中从尾到头数的第一个符合唤醒条件的线程。唤醒条件:
- 线程不为空
- 线程的waitStatus小于等于0
JVM
1、JVM垃圾回收机制,GC发生在JVM哪部分,有几种GC,它们的算法是什么
GC发生在JVM哪部分?有几种GC?
- GC发生在堆与方法区中
- 次数上频繁收集Young区(新生代)——Minor GC
- 次数上较少收集Old区(老年代)——Major GC
- 基本不动Perm方法区
关于 Full GC 与 major GC 的区别
- 部分收集(Partial GC):指目标不是完整收集整个java堆的垃圾收集,其中又分为:
- 新生代收集(Minor GC/Young GC):指目标只是新生代的垃圾收集。
- 老年代收集(Major GC/Old GC):指目标只是老年代的垃圾收集。目前只有CMS收集器会有单独收集老年代的行为。
- 注意:”Major GC”这个说法现在有点混淆,在不同资料上常有不同所指,需按上下文区分到底是指老年代的收集还是整堆收集
- 混合收集(Mixed GC):指目标是收集整个新生代以及部分老年代的垃圾收集。目前只有G1收集器会有这种行为
- 整堆收集(Full GC):收集整个java堆和方法区的垃圾收集
垃圾收集的算法是什么
- 引用计数法
- 计数该对象有多少个引用,如果计数的值不为0,则代表该对象存在引用,不对它进行垃圾回收
- 这种方法存在循环引用问题,JVM没有采用该方法
- 复制算法(Copying)
- 该算法常在JVM回收新生代Young GC使用
- 从跟集合(GC Root)开始,通过可达性分析算法Tracing从From中找到存活对象,拷贝到To区中;
- 之后From、To区交换身份下次内存分配依旧是从From区开始
- 优点:
- 没有标记和清除的过程,效率高
- 没有内存碎片,可以利用bump-the-pointer(碰撞指针)实现快速分配内存
- 缺点:
- 需要双倍的空间
- 标记清除算法(Mark-Sweep)
- 标记(Mark):
- 从根集合(GC Root)开始扫描,对存活的对象进行标记
- 清除(Sweep):
- 扫描整个内存空间,回收未被标记的对象,使用free-list记录可用区域
- 优点:
- 不需要额外的空间
- 缺点:
- 两次扫描,耗时严重
- 会产生内存碎片
- 标记(Mark):
- 标记压缩算法(Mark-Compact):
- 标记(Mark):
- 从根集合(GC Root)开始扫描,对存活的对象进行标记
- 压缩(Compact):
- 再次扫描,并往一端滑动存活对象
- 在整理压缩阶段,不在对标记的对象做回收,而是通过所有存活对象都向一端移动,然后直接消除边界以外的内存
- 优点:
- 没有内存碎片,可以利用bump-the-pointer(碰撞指针)实现快速分配内存
- 缺点:
- 需要移动对象的成本
- 标记(Mark):
- 标记清除压缩算法(Mark-Sweep-Compact):
- 老年代一般都是使用由标记清除或者是标记清除与标记整理的混合实现进行垃圾回收
- 就是将以上的标记清除算法和标记压缩算法混合实现
2、JVM内存结构
3、关于类加载子系统常问的问题
1、类加载器有哪些?
JVM支持两种类型的类加载器,分别为引导类加载器( Bootstrap ClassLoader)**和自定义类加载器(User-Defined ClassLoader)** 。
引导类加载器( Bootstrap ClassLoader):
- 本身不是使用java语言编写,而是使用C与C++进行编写
自定义类加载器(User-Defined ClassLoader)
使用java语言编写
派生于抽象类ClassLoader。所以扩展类加载器(Extinction Class Loader)与系统类加载器(System Class Loader)都属于自定义类加载器
其中sun.misc.Launcher它是一个java虚拟机的入口应用
无论类加载器的类型如何划分,在程序中我们最常见的类加载器始终只有3个:
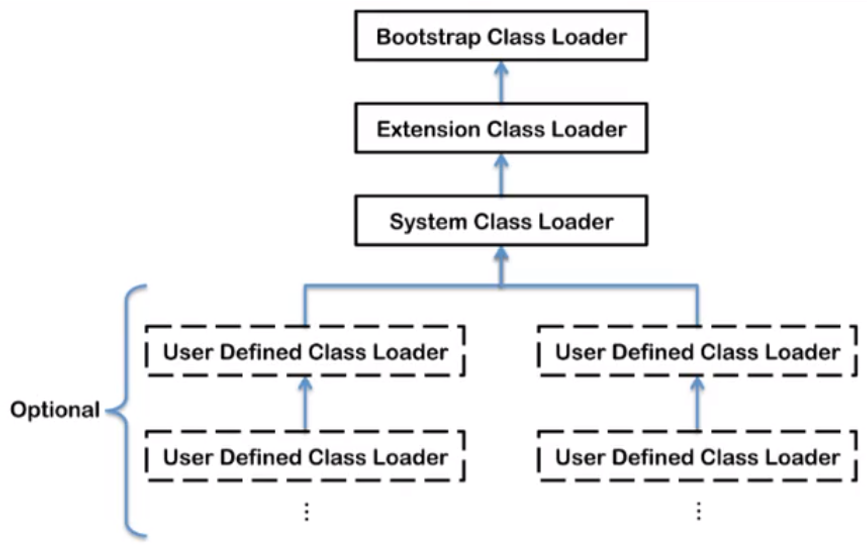
这里的四者之间的关系是包含关系。不是上层下层,也不是子父类的继承关系。
对于引导类加载器(Bootstrap Class Loader)、扩展类加载器(Extension Class Loader)与系统类加载器(System Class Loader)三者的关系:
- 系统类加载器(System Class Loader)的上层就是扩展类加载器(Extension Class Loader):对于用户自定义类来说:默认使用系统类加载器进行加载
- 扩展类加载器(Extension Class Loader)的上层是引导类加载器(Bootstrap Class Loader)
- 引导类加载器(Bootstrap Class Loader)是最高层的类加载器:Java的核心类库都是使用引导类加载器进行加载的。并且我们获取不到引导类加载器。因为引导类加载器并不是所以java语言进行编写的。
2、双亲委派机制
3、沙箱安全机制
4、GC Roots的作用域
1、什么是垃圾
- 内存中已经不再被使用到的空间就是垃圾
- 即没有被引用的对象
2、要进行垃圾回收,如何判断一个对象是否可以被回收?——两种算法
1、引用计数法
Java中,引用和对象是有关联的。如果要操作对象则必须引用进行。
因此,简单的办法是通过引用计数来判断一个对象是否可以回收。简单的说,给对象中添加一个引用计数,每当有一个引用失效时,计数器值减1.
任何时刻计数器值为0的对象就是不可能再被利用的,那么这个对象就是可回收对象。
那么为什么主流的Java虚拟机里面都没有选择这种算法呢?主要的原因是它很难解决对象之间==相互循环引用==的问题。
2、枚举根节点做可达性分析(根搜索路径算法)
为了解决引用计数法的循环引用问题,Java使用了可达性分析的方法。
所谓“GC Roots”或者tracing GC的“根集合”就是==一组==必须活跃的引用。
基本思路就是通过一系列名为“GC Roots”的对象作为起点,从这个被称为GC Roots的对象开始向下搜索,如果一个对象到GC Roots没有任何引用链相连时,则说明此对象不可用。即给定一个集合的引用作为根出发,通过引用关系遍历对象图,能被遍历到的(可达性的)对象就被判定为存活,没有被遍历到的就被判断为死亡。
3、Java中可以作为GC Roots的对象
- 虚拟机栈(栈帧中的局部变量区,也叫做局部变量表)中引用的对象。
- 比如:各个线程被调用的方法中使用到的参数、局部变量等。
- 方法区中的类静态属性引用的对象。
- 比如:Java类的引用类型静态变量
- 方法区中常量引用的对象
- 比如:字符串常量池(String Table)里的引用
- 本地方法栈中JNI(Native方法)引用的对象。
- 所有被同步锁synchronized持有的对象
- Java虚拟机内部的引用。
- 反映java虛拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
5、你说你做过JVM调优和参数配置,请问如何查看JVM系统默认值
1、JVM的参数类型
- 标配参数
- -version
- -help
- java -showversion
- x参数(了解)
- -Xint:解释执行
- -Xcomp:第一次使用就编译成本地代码
- -Xmixed:混合模式
- xx参数(重点)
- Boolean类型
- 公式:-XX:+或者-某个属性值
- +表示开启
- -表示关闭
- 是否打印GC收集细节
- -XX:-PrintGCDetails:不打印GC收集细节
- -XX:+PrintGCDetails:打印GC收集细节
- 是否使用串行垃圾回收器
- -XX:-UseSerialGC:不使用串行垃圾回收器
- -XX:+UseSerialGC:使用串行垃圾回收器
- 公式:-XX:+或者-某个属性值
- KV设值类型
- 公式:-XX:属性key=属性值value
- -XX:MetaspaceSize=128m
- -XX:MaxTenuringThreadhold=15
- 公式:-XX:属性key=属性值value
- Boolean类型
jinfo举例,如何查看当前运行程序的配置:
先使用jps查看需要的java进程的进程id,然后使用jinfo查看当前运行程序的配置
2、-Xms和-Xmx是属于哪一种参数类型?
- -Xms:等价于-XX:InitialHeapSize——用来设置初始堆的大小
- -Xmx:等价于-XX:MaxHeapSize——用来设置最大的对的大小
因此这两个参数属于xx参数的类型
3、怎么不使用VM参数,使用java代码的方式查看当前进程的内存总量等等信息
1 | // 查看当前java虚拟机中的内存总量 |
4、盘点家底查看JVM默认值
1、查看当前java虚拟机的初始默认值
-XX:+PrintFlagsInitial
公式:
- java -XX:+PrintFlagsInitial -version
- java -XX:+PrintFlagsInitial
2、查看当前java虚拟机修改更新之后的值
-XX:+PrintFlagsFinal
公式:
- java -XX:+PrintFlagsFinal -version
- java -XX:+PrintFlags
3、查看在VM当中设置的参数值
-XX:+PrintCommandLineFlags
公式:
- java -XX:+PrintCommandLineFlags -version
对于上面命令查看到的默认值的相关说明
- 如果当前默认值是true或者false,表示当前的属性是Boolean类型
- 如果当前默认值是具体的值,表示当前的属性是KV设值类型
=表示当前值没有被修改更新过:=表示当前默认值因虚拟机启动时进行了修改或者人为修改更新过
6、你平时工作用过的JVM常用基本配置参数有哪些?
1、常用参数
1、-Xms
- 初始大小内存,默认为物理内存的1/64
- 等价于
-XX:InitialHeapSize——初始化堆的大小
2、-Xmx
- 最大分配内存,默认为物理内存的1/4
- 等价于
-XX:MaxHeapSize——最大堆内存大小
3、-Xss
- 设置单个线程栈的大小,一般默认为512k~1024k
- 等价于
-XX:ThreadStackSize——当前线程栈的大小
如果使用jinfo去查看-Xss的初始默认值,发现:

-XX:ThreadStackSize的默认值是0,而不是512k或者1024k?
- 这里的0代表的是JVM已经设置好的初始值
这个初始值在不同的平台有不同的取值:

在64位的Linux系统一般为1024KB
在Windows系统的话则取决于当前的虚拟内存
4、-Xmn
- 设置年轻代的大小
5、-XX:MetaspaceSize
设置元空间大小
- 元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:**==元空间并不在虚拟机中,使用的是本地内存==**
- 因此,默认情况下,元空间的大小受本地内存限制。类的元数据放入本地内存,字符串池和类的静态变量放入java堆中,这样可以加载多少类的元数据就不在由
MaxPermSize控制,而由系统的实际可用空间来控制。
元空间并不在虚拟机中,使用的是本地内存。本地内存的空间一般比虚拟机大,但是为什么在本地空间充足的情况下,依旧会出现元空间的OOM?
使用jinfo去查看MetaspaceSize的默认初始值时,发现:
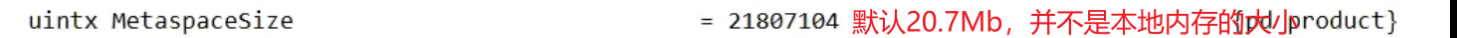
元空间的大小并不是如我们所想那样是本地内存的大小,这个初始值的大小与当前虚拟机的核数有关
所以在生产环境下,会适当的调高元空间的默认初始值。使其不会轻易出现OOM。
经典的VM参数设置:(这里指的是经常使用的,具体还是的由具体的业务决定)
1
-Xms128m -Xmx4096m -Xss1024k -XX:MetaspaceSize=512m -XX:+PrintCommandLineFlags -XX:+PrintGCDetails
6、-XX:PrintGCDetails
- 输出详细的GC收集日志信息
1、MinorGC(或 young GC 或 YGC)日志
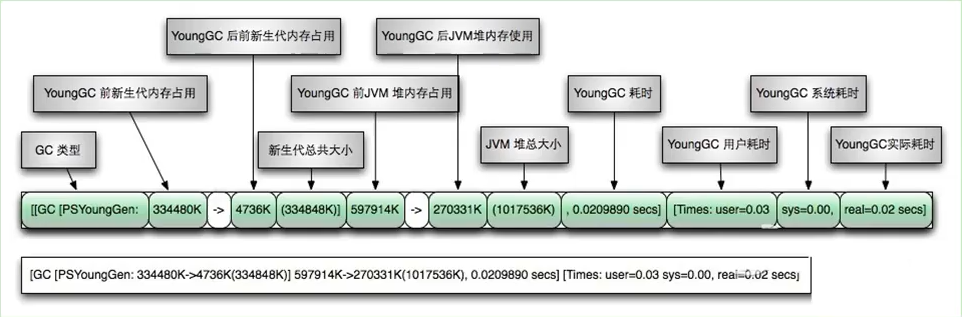
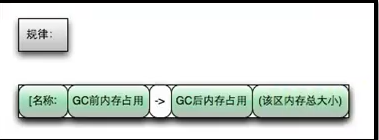
2、Full GC 日志
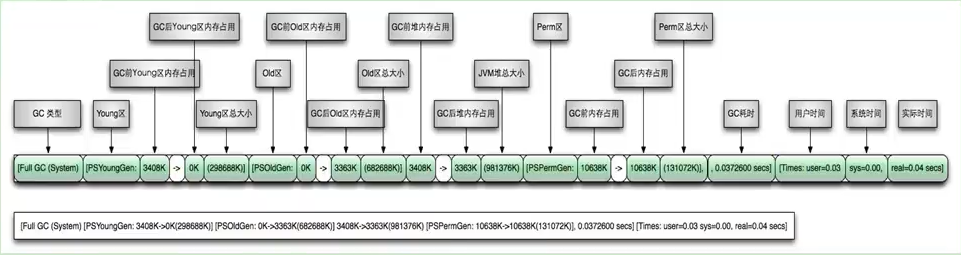
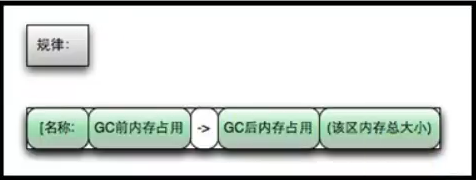
7、-XX:SurvivorRatio
- 设置新生代中Eden和S0/S1空间的比例
- 默认为:-XX:SurvivorRatio=8——即Eden:S0:S1 = 8:1:1
- 假如设置-XX:SurvivorRatio=4——即Eden:S0:S1 = 4:1:1
- SurvivorRatio值就是设置Eden区的比例占多少,S0/S1相同
8、-XX:NewRatio
- 配置年轻代与老年代在堆结构的占比
- 默认为:-XX:NewRatio=2——新生代占1,老年代占2。年轻代占整一个堆的1/3
- 假如设置-XX:NewRatio=4——新生代占1,老年代占4。年轻代占整一个堆的1/5
- NewRatio值就是设置老年代的占比,剩下的1给新生代
9、-XX:MaxTenuringThreshold
- 设置垃圾最大年龄
使用jinfo查看默认进入老年代的年龄

-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。
如果设置为0的话,则年轻代对象不经过Survivor区,直接进入老年代。对于老年代比较多的应用,可以提高效率。
如果将此值设置为一个较大值,这年轻代对象会在Survivor区进行多次复制,这样可以增加对象在年轻代的存活时间,增加在年轻代即被回收的概论
在JDk1.8之前,一般会将这个值设置为31,使更多的对象在年轻代就被回收掉,不让对象轻易进入老年代。以此来减少Full GC的次数。
这种方法在JDK1.8之后就不能实现了。因为在JDK1.8的环境下,如果设置的设置大于15的话,会报一个
Error:Could not create the Java Virtual Machine
7、强引用、软引用、弱引用、虚引用分别是什么?
1、整体架构
2、强引用(默认支持模式)——StrongReference
当内存不足,JVM开始垃圾回收,对于强引用的对象,就算是出现了OOM也不会对该对象进行回收,死都不收。
强引用是最常见的普通对象引用,只要还有引用指向一个对象,就能表明对象还“活着”,垃圾收集器不会碰到这种对象。在Java中最常见的就是强引用,把一个对象赋给一个引用变量,这个引用变量就是一个强引用。当一个对象被强引用变量引用时,它处于可达状态,它是不可能被垃圾机制回收的,即使该对象以后永远都不能被用到,JVM也不会回收。因此强引用是造成Java内存泄露的主要原因之一。
对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显示地将相应(强)引用赋值为null,一般认为就是可以被垃圾收集的了(当然具体回收时还要看垃圾收集策略)。
3、软引用——SoftReference
软引用是一种相对强化了一些的引用,需要用java.lang.ref.SoftReference类来实现,可以让对象豁免一次垃圾收集。
对于只有软引用的对象来说:
- 当系统内存充足时,它不会被回收
- 当系统内存不足时,它会被回收
软引用通常用在对内存敏感的程序中,比如高速缓存就有用到软引用,内存够用的时候就保留,不够用就回收。
4、弱引用——WeakReference
弱引用需要用java.lang.ref.WeakReference类来实现,它比软引用的生存期更短。
对于软引用对象来说,只要垃圾回收机制一运行,不管JVM的内存空间是否足够,都会回收该对象占用的内存。
5、软引用和弱引用的使用场景
假如有一个应用需要读取大量的本地图片:
- 如果每次读取图片都从硬盘读取则会严重影响性能。
- 如果一次性全部加载到内存中有可能造成内存泄露。
此时使用软引用可以解决这个问题。
设计思路:用一个HashMap来保存图片的路径和相应图片对象关联的软引用之间的映射关系,在内存不足时,JVM会自动回收这些缓存图片对象所占用的空间,从而有效地避免OOM的问题。
1 | Map<String,SoftReference<Bitmap>> imageCache = new HashMap<String,SoftReference<Bitmap>>(); |
你知道所引用的话,能谈谈weakHashMap吗?
weakHashMap的key都是弱引用对象,如果发生了垃圾回收并且在finally块中不能复活的话,被回收的key会被移除出Map。

6、虚引用——PhantomReference
虚引用需要java.lang.refPhantonReference类来实现。
顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。
如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收,它不能单独使用也不能通过它访问对象,虚引用必须和队列(ReferenceQueue)联合使用。
虚引用的主要作用是跟踪对象被垃圾回收的状态。仅仅是提供了一种确保对象被finalize以后,做某些事情的机制。
PhantomReference的get方法总是返回null,因此无法访问对应的引用对象。其意义在于说明一个对象那个已经进入finalization阶段,可以被gc回收,用来实现比finalization机制更灵活的回收操作。
换句话说,设置虚引用关联的唯一目的,就是在这个对象被收集器回收的时候收到一个系统通知或者后续添加进一步的处理。
Java技术允许使用finalize()方法在垃圾收集器将对象从内存中清楚之前做必要的清理工作。
引用队列
在对象被回收前需要被引用队列保存一下。

7、GCRoots和四大引用小总结
java提供了4种引用类型,在垃圾回收的时候,都有自己各自的特点。
- ReferenceQueue是用来配合引用工作的,没有ReferenceQueue一样可以运行。
- 创建引用的时候可以指定关联的队列,当GC释放对象内存的时候,会将引用加入到引用队列,如果程序发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动
- 这相当于是一种通知机制。
- 当关联的引用队列中有数据的时候,意味着引用指向的堆内存中的对象被回收。通过这种方式,JVM允许我们在对象被销毁后,做一些我们自己想做的事情。
8、请谈谈你对OOM的认识?
1、java.lang.StackOverFlowError
java.lang.StackOverFlowError——栈溢出异常
一般的线程栈的大小也只有512Kb或者1024Kb,当递归的深度太深或者出现不合理的递归时,容易出现以上异常
这里说的”异常”并不是说StackOverFlowError是一个异常,StackOverFlowError不是异常而是错误。只是平时大家习以为常说是异常,其实StackOverFlowError是一个Error错误。
2、java.lang.OutOfMemoryError:Java heap space
java.lang.OutOfMemoryError:Java heap space——堆空间溢出异常
若当前的堆空间不满足创建对象的大小,就会出现Java heap space——堆空间溢出异常
同理,Java heap space也不是异常,而是一个Error错误。
3、java.lang.OutOfMemoryError:GC overhead limit exceeded——GC时间过长异常
GC回收时间长时会抛出OutOfMemoryError。过长的定义是,超过98%的时间用来做GC并且回收了不到2%的堆内存,连续多次GC都只回收了不到2%的极端情况下才会抛出。
假设不抛出GC overhead limit错误会发生什么情况呢?
- 那就是GC清理的这么点内存很快会再次填满,迫使GC再次执行,这样就形成恶性循环,CPU使用率一直是100%,而GC缺没有任何成果。
同理,GC overhead limit exceeded也不是异常,而是一个Error错误。
4、java.lang.OutOfMemoryError:Direct buffer memory——本地内存溢出异常
导致原因:
- 写NIO程序经常使用ByteBuffer来读取或者写入数据,这是一种基于通道(Channel)与缓冲区(Buffer)的I/O方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。
- 这样能在一些场景中显著提高性能,因为避免了在java堆和Native堆中来回复制数据。
- ByteBuffer.allocate(capability)第一种方式是分配JVM堆内存,属于GC管辖范围,由于需要拷贝所以速度相对较慢。
- ByteBuffer.allocateDirect(capability)第一种方式是分配OS本地内存,不属于GC管辖范围,由于不需要内存拷贝,所以速度相对较快。
- 但如果不断分配内存,堆内存很少使用,那么JVM就不需要执行GC,DirectByteBuffer对象们就不会被回收,这时候堆内存充足,但本地内存可能已经使用光了,再次尝试分配本地内存就会出现OutOfMemoryError,那程序就直接崩溃了。
同理,也不是异常,而是一个Error错误。
5、java.langOutOfMemoryError:Metaspace
使用java -XX:+PrintFlagsInitial命令查看本机的初始化参数:-XX:Metaspacesize为218103768(大约为20.8M)
Java 8及以后的版本使用Metaspace来代替永久代
Metaspace是方法区在HotSpot中的实现,它与永久代最大的区别在于:Metaspace并不在虚拟机内存中,而是使用本地内存,也就是说在Java8中,class metadata(the virtual machines internal presentation of Java class),被存储在叫做Metaspace的native memory
Metaspace存放了以下信息:
- 虚拟机加载的类信息
- 常量池
- 静态变量
- 即时编译后的代码
6、java.lang.OutOfMemoryError:unable to create new native thread——无法创建本地线程异常
高并发请求服务器时,经常出现如下异常:java.lang.OutOfMemoryError:unbale to create new native thread
准确的说该native thread异常与对应的平台有关。
导致原因:
- 应用创建了太多线程,一个应用进程创建多个线程,超过系统承载极限。
- 服务器并不允许应用程序创建那么多线程,linux系统默认允许单个进程可以创建的线程数是1024个,如果应用创建超过这个数量,就会报java.lang.OutOfMemoryError:unable to create new native thread
解决办法:
- 想办法降低应用程序创建线程的数量,分析应用是否真的需要创建那么多线程,如果不是,改代码将线程数降到最低。
- 对于有的应用,确实需要创建多个线程,远超过linux系统默认的1024个线程的限制,可以通过修改linux服务器配置,扩大linux默认限制。
1、非root用户登录linux系统测试
查看最大线程数量命令:
1 | ulimit -u |
2、服务器级别调参调优
扩大服务器线程数:
1 | vim/etc/security/limits.d/90-nproc.conf |
9、GC回收算法和垃圾收集器的关系?分别是什么请你谈谈
1、GC回收算法
GC算法是内存回收的方法论,垃圾收集器就是算法落地实现。常见的GC算法有:
- 引用计数
- 复制算法
- 标记清除算法
- 标记整理算法(标记压缩算法)
因为目前为止还没有完美的收集器出现,更加没有万能的收集器,知识针对具体应用最合适的收集器,进行分代收集。
2、4种主要垃圾收集器
- 串行垃圾回收器(Serial):它为单线程环境设计且只使用一个线程进行垃圾回收,会暂停所有的用户线程。所以不适合服务器环境。
- 并行垃圾回收器(Parallel):多个垃圾收集线程并行工作,此时用户线程是暂停的,适用于科学计算/大数据处理平台处理等弱交互场景。
- 并发垃圾回收器(CMS):用户线程和垃圾收集线程同时执行(不一定是并行,可能交替执行),不需要停顿用户线程,使用对响应时间有要求的场景。
- GI垃圾回收器:G1垃圾回收器将堆内存分割成不同的区域然后并发的对其进行垃圾回收。
3、串行(Serial) VS 并行(Parallel)
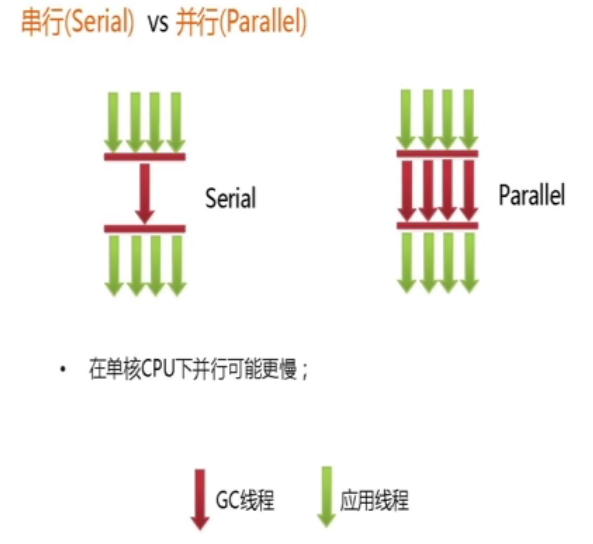
注:不管是串行还是并行,都存在STW问题。只是并行的STW时间比串行的要短很多。
4、STW(Stop-the-World) VS 并发(Concurrent)
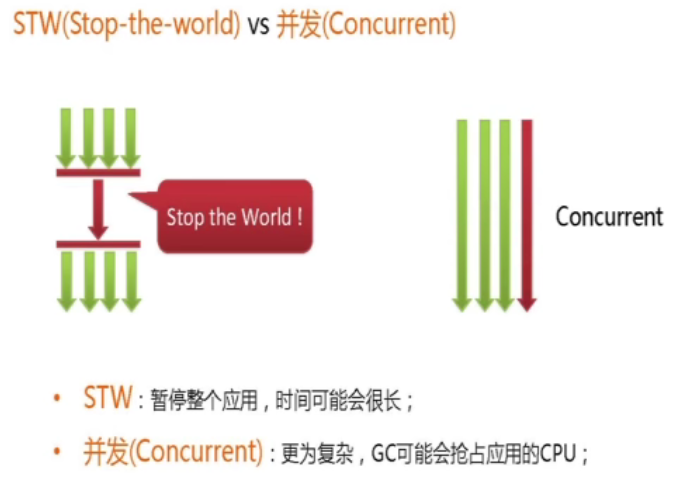
并发使得在进行垃圾收集时也可以执行工作线程。
10、怎么查看服务器默认的垃圾收集器是哪个?生产上你是如何配置垃圾收集器的?谈谈你的理解?
1、怎么查看默认的垃圾收集器是哪个?
使用JVM参数:
1 | java -XX:+PrintCommandLineFlags -version |
2、默认的垃圾收集器有哪些?
Java的GC回收的类型主要有以下七种:
- UseSerialGC:串行垃圾回收器——新生代
- UseParallelGC:并行垃圾回收器——新生代
- UseConcMarkSweepGC(CMS):并发垃圾回收器——老年代
- UseParNewGC——新生代并行垃圾回收器
- UseParallelOldGC——老年代并行垃圾回收器
- UseG1GC——G1垃圾回收器——整堆
相关的源码:
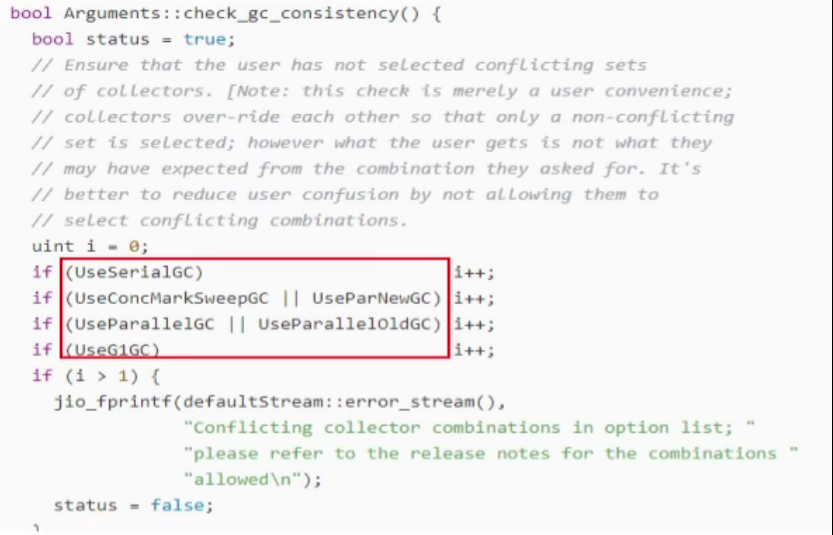
垃圾收集器的组合关系:
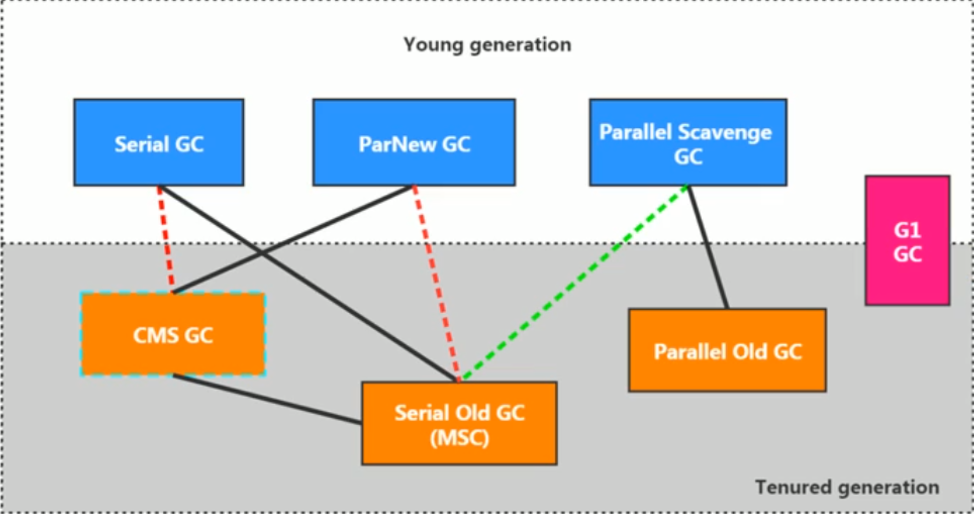
两个收集器间有连线,表明它们可以搭配使用:
Serial/Serial Old、Serial/CMS、ParNew/Serial Old、ParNew/CMS、Parallel Scavenge/Serial Old、Parallel Scavenge/Parallel Old、G1;
其中Serial Old作为CMS出现”Concurrent Mode Failure” 失败的后备预案。
(红色虚线)由于维护和兼容性测试的成本,在JDK 8时将Serial+CMS、ParNew+Serial Old这两个组合声明为废弃(JEP 173),并在JDK 9中完全取消了这些组合的支持(JEP214) ,即:移除。
(绿色虚线)JDK 14中:弃用Parallel Scavenge和Serial Old GC组合(JEP366)
(青色虚线)JDK 14中:删除CMS垃圾回收器 (JEP 363)
Java不同版本的默认垃圾回收器组合:
| 版本 | Young | Old |
|---|---|---|
| JDK6 | PSScavenge(Parallel Scavenge) | PSMarkSweep (Parallel Scavenge) |
| JDK7 | PSScavenge(Parallel Scavenge) | PSParallelCompact(Parallel Old) |
| JDK8 | PSScavenge(Parallel Scavenge) | PSParallelCompact(Parallel Old) |
| JDK9 | G1 | G1 |
3、垃圾收集器详解
1、部分参数预先说明
- DefNew——Default New Generation
- Tenured——Old
- ParNew——Parallel New Generation
- PSYoungGen——Parallel Scavenge
- ParOldGen——Parallel Old Generation
2、Server/Client模式分别是什么意思
- 使用范围:只需要掌握Server模式即可,Client模式基本不会用。
- 操作系统:
- 32位操作系统,不论硬件如何都默认使用Client的JVM模式。
- 32位操作系统,2G内存同时有2个CPU以上用Server模式,低于该配置还是Client模式。
- 64位only server模式
3、新生代
1、串行GC(Serial)/(Serial Copying)
串行收集器:Serial收集器。一个单线程的收集器,在进行垃圾收集时候,必须暂停其他所有的工作线程知道它收集结束。
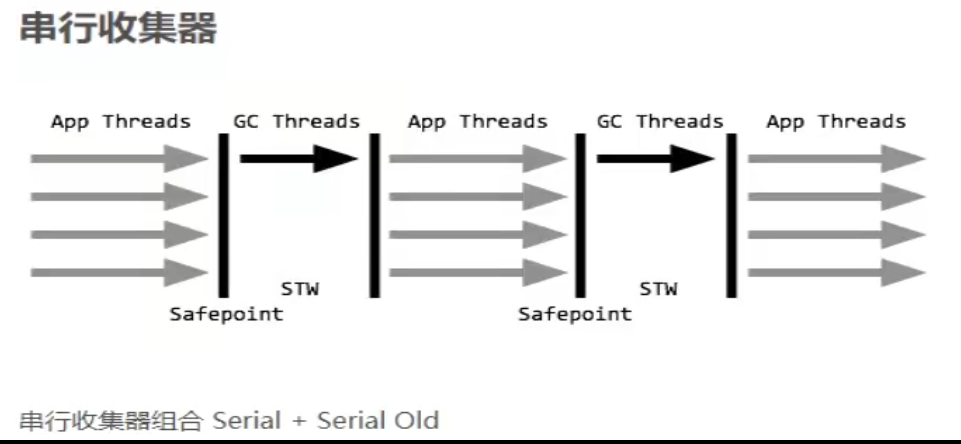
串行收集器是最古老,最稳定以及效率高的收集器,只使用一个线程去回收但其在进行垃圾收集过程中可能会产生较长的停顿(Stor-the-World状态)。虽然在收集垃圾过程中需要暂停所有其他的工作线程,但是它简单高效,对于限定单个CPU环境来说,没有线程交互的开销可以获得最高的单线程垃圾收集效率,因此Serial垃圾收集器依然是java虚拟机运行在Client模式下默认的新生代垃圾收集器。
对应JVM参数是:**-XX:+UseSerialGC**
开启后会使用:Serial(Young区用)+ Serial Old(Old区用)的收集器组合。
表示:新生代、老年代都会使用串行回收收集器,新生代使用复制算法,老年代使用标记-整理算法。
2、并行GC(ParNew)
ParNew(并行)收集器。一句话:使用多线程进行垃圾回收,在垃圾收集时,会Stop-the-World暂停其他所有的工作线程直到它收集结束,时间较串行垃圾收集器来说要短。
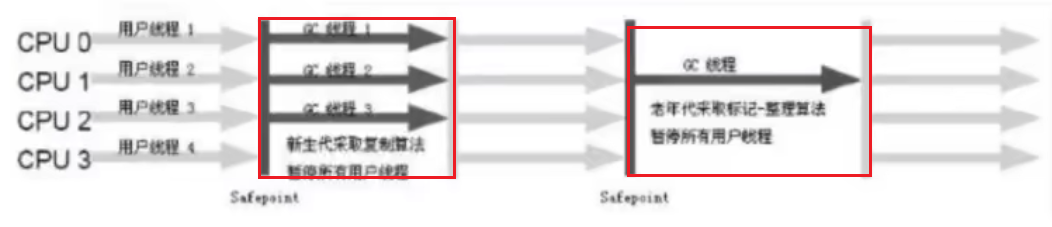
ParNew收集器其实就是Serial收集器新生代的并行多线程版本,最常见的应用场景是配合老年代的CMS GC工作,其余的行为和Serial收集器完全一样,ParNew垃圾收集器在垃圾收集过程中同样也要暂停所有其他的工作线程。它是很多java虚拟机运行在Server模式下新生代的默认垃圾收集器。
常用对应JVM参数:**-XX:+UseParNewGC 启用ParNew收集器,只影响新生代的收集,不影响老年代。**
开启上述参数后,会使用:ParNew(Young区用)+ Serial Old的收集器组合,新生代使用复制算法,老年代采用标记-整理算法。
但是,ParNew + Tenured这样的搭配,java8已经不在推荐
Java HotSpot(TM) 64-Bit Server VM warning:
Using the ParNew young collector with the Serial old collecto is deprecated and will likely be removed in a future release
备注:关于新生代并行线程数的设置:
1 | -XX:ParallelGCThreads |
限制线程数量,默认开启和CPU数目相同的线程数。
3、并行回收GC(Parallel)/(Parallel Scavenge)
Parallel Scavenge收集器类似ParNew也是一个新生代垃圾收集器,使用复制算法,也是一个并行的多线程的垃圾收集器,俗称吞吐量有限收集器。一句话:串行收集器在新生代和老年代的并行化。
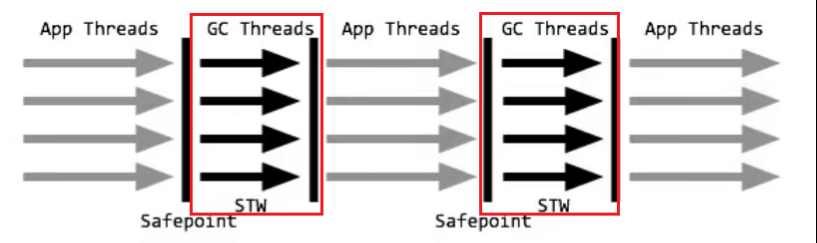
它重点关注的是:
- 可控制的吞吐量(Thoughput=运行用户代码时间/(运行用户代码时间+垃圾收集时间),也即比如程序运行100分钟,垃圾收集时间1分钟,吞吐量就是99%)。
- 高吞吐量意味着高效利用CPU的时间,它多用于在后台运算而不需要太多交互的任务。
- 自适应调节策略也是ParallelScavenge收集器与ParNew收集器的一个重要区别。
- 自使用调节策略:虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间(-XX:MaxGCPauseMillis)或最大的吞吐量。
常用JVM参数:**-XX:+UseParallelGC或-XX:+UseParallelOldGC(可互相激活)**使用Parallel Scanvenge收集器
备注:关于新生代与老年代并行线程数的设置:
1 | -XX:ParallelGCThreads=[数字N] |
表示启动多少个GC线程:
- 当CPU > 8:N = 5/8
- 当CPU < 8:N = CPU实际个数
4、老年代
1、串行GC(Serial Old)/(Serial MSC)
Serial Old是Serial垃圾收集器老年代版本,它同样是个单线程的收集器,使用标记-整理算法,这个收集器也主要是运行在Client默认的java虚拟机默认的老年代垃圾收集器。
在Server模式下,主要有两个用途(了解,版本已经到8及以后):
- 在JDK1.5之前版本中与新生代的Parallel Scavenge收集器搭配使用。 (Parallel Scavenge + Serial Old )
- 作为老年代版中使用CMS收集器的后备垃圾收集方案。
注:理论了解即可,实际中java8已经被优化掉了,没有了。
如果在java8的VM配置相关参数启动Serial Old垃圾收集器,会发生:

2、并行GC(Parallel Old)/(Parallel MSC)
Parallel Old收集器是Parallel Scavenge的老年代版本,使用多线程的标记-整理算法,Parallel Old收集器在JDK1.6才开始提供。
JVM常用参数:**-XX:+UseParallel Old** 使用Parallel Old收集器,设置该参数后,新生代Parallel+老年代Parallel Old
3、并发标记清除GC(CMS)
CMS收集器(Concurrent Mark Sweep:并发标记清除)是一种以获取==最短回收停顿时间==为目标的收集器。
适合应用在互联网站或者B/S系统的服务器上,这类应用尤其重视服务器的响应速度,希望系统停顿时间最短。
CMS非常适合堆内存大、CPU核数多的服务器端应用,也是G1出现之前大型应用的首选收集器。
Concurrent Mark Sweep并发标记清除,并发收集低停顿,并发指的是与用户线程一起执行。
开启该收集器的JVM参数:**-XX:+UseConcMarkSweepGC** 开启该参数后会自动将-XX:+UseParNewGC打开
开启该参数后,使用ParNew(Young区用)+CMS(Old区用)+Serial Old的收集器组合,Serial Old将作为CMS出错的后备收集器。
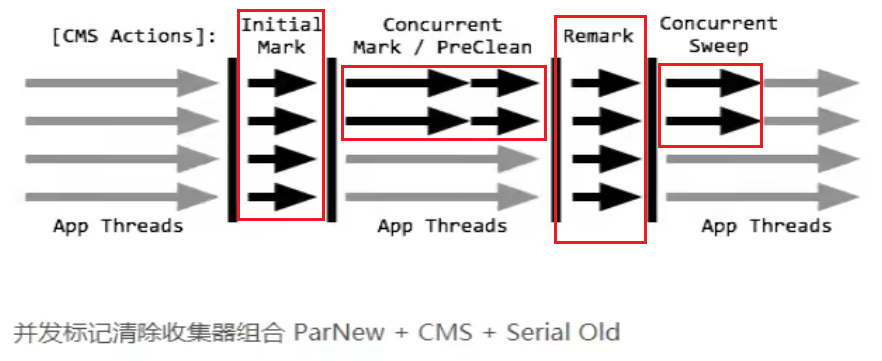
CMS垃圾收集的过程:
- 初始标记(CMS initial mark)
- 只是标记一下GC Roots能直接关联的对象,速度很快,仍然需要暂停所有的工作线程。
- 并发标记(CMS concurrent mark)和用户线程一起
- 进行GC Roots跟踪的过程,和用户线程一起工作,不需要暂停工作线程。主要标记过程,标记全部对象。
- 重新标记(CMS remark)
- 为了修正在并发标记期间,因用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,仍然需要暂停所有的工作线程。
- 由于并发标记时,用户线程依然运行,因此在正式清理前,再做修正。
- 并发清除(CMS concurrent sweep)和用户线程一起
- 清除GC Roots不可达对象,和用户线程一起工作,不需要暂停工作线程。基于标记结果,直接清理对象。
- 由于耗时最长的并发标记和并发清除过程中,垃圾收集线程可以和用户现在一起并发工作,所以总体上来看CMS收集器的内存回收和用户线程是一起并发执行。
CMS也存在STW,发生在第一步:初始标记和第三步:重新标记。时间很短。
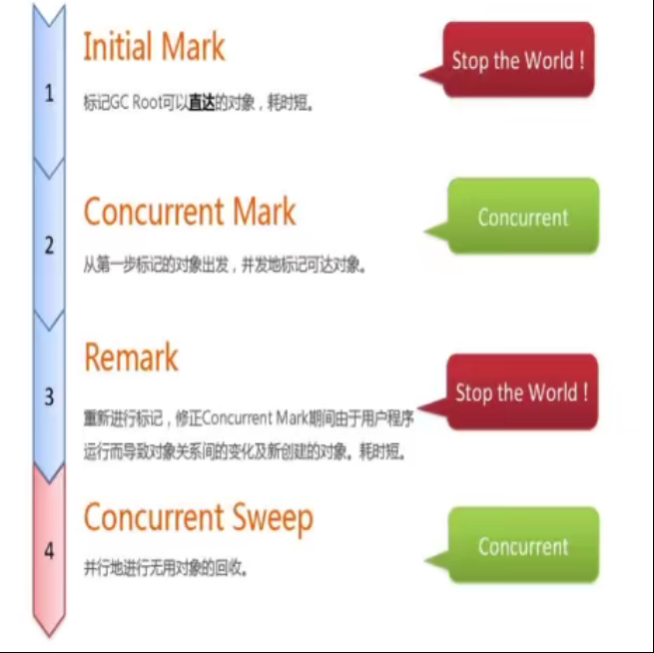
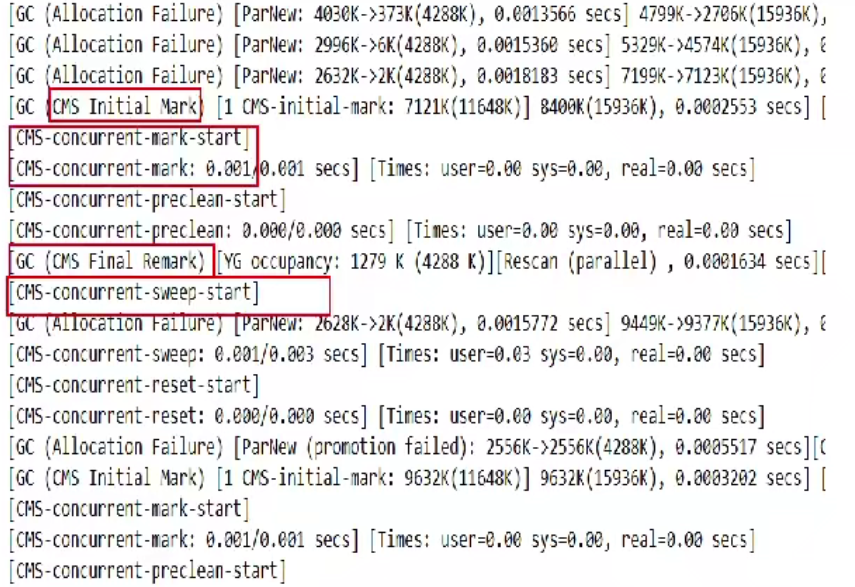
CMS的优缺点:
- 优点:
- 并发收集低停顿
- 缺点
- 并发执行,对CPU资源压力大
- 由于并发进行,CMS在收集与应用线程会同时增加对堆内存的占用,也就是说,CMS必须要在老年代堆内存用尽之前完成垃圾回收,否则CMS回收失败时,将触发担保机制,串行老年代收集器会以STW的方式进行一次GC,从而造成较大停顿时间。
- 采用的标记清除算法会导致大量碎片
- 标记清除算法无法整理空间碎片,老年代空间会随着应用时长被逐步耗尽,最后将不得不通过担保机制对堆内存进行压缩。CMS也提供了参数
-XX:CMSFullGCsBeForeCompaction(默认0,即每次都进行内存整理)来指定多少次CMS收集之后,进行一次压缩的Full GC。
- 标记清除算法无法整理空间碎片,老年代空间会随着应用时长被逐步耗尽,最后将不得不通过担保机制对堆内存进行压缩。CMS也提供了参数
- 并发执行,对CPU资源压力大
4、如何选择垃圾收集器
组合的选择:
单CPU或小内存,单机程序——使用串行垃圾回收器
1
-XX:+UseSerialGC
多CPU,需要最大吞吐量,如后台计算型应用——使用并行垃圾回收器
1
2
3-XX:+UseParallelGC
// 或(相互激活)
-XX:+UseParallelOldGC多CPU,追求低停顿时间,需要快速响应如互联网应用——CMS垃圾回收器
1
2-XX:+UseConcMarkSweepGC
-XX:+ParNewGC
5、垃圾收集器总结
| 参数 | 新生代垃圾收集器 | 新生代算法 | 老年代垃圾收集器 | 老年代算法 |
|---|---|---|---|---|
| -XX:+UseSerialGC | SerialGC | 复制 | SerialOldGC | 标记-整理 |
| -XX:+UseParNewGC | ParNew | 复制 | SerialOldGC | 标记-整理 |
| -XX:+UseParallelGC/+XX:+UsePallallelOldGC | Parallel[Scavenge] | 复制 | Parallel Old | 标记-整理 |
| -XX:+UseConcMarkSweepGC | ParNew | 复制 | CMS + SerialOld的收集器组合(Serial Old作为CMS出错的后备收集器) | 标记-清除 |
| -XX:+UseG1GC | G1整体上采用标记-整理算法 | 局部是通过复制算法,不会产生内存碎片 |
11、G1垃圾收集器
1、以前收集器特点
- 年轻代和老年代是各自独立且连续的内存块
- 年轻代收集使用单eden+S0+S1进行复制算法
- 老年代收集必须扫描整个老年代区域
- 都是以尽可能少而快速地执行GC为设计原则。
2、G1是什么?
CMS垃圾收集器虽然减少了暂停应用程序的运行时间,但是它还是存在着内存碎片问题。于是,为了去除内存碎片问题,同时又保留CMS垃圾收集器低暂停时间的优点,JAVA7发布了一个新的垃圾收集器——G1垃圾收集器。
G1是在2012年才在jdk1.7u4中可用。oracle官方计划在jdk9中将G1变成默认的垃圾收集器以替代CMS。它是一款面向服务端应用的收集器,主要应用在多CPU和大内存服务器环境下,极大的减少垃圾收集的停顿时间,全面提升服务器的性能,逐步替换java8以前的CMS收集器。
主要改变是Eden,Survivor和Tenured等内存区域不再是连续的了,而是变成了一个个大小一样的region,每个region从1M到32M不等。一个region有可能属于Eden,Survivor或者Tenured内存区域。
G1(Garbage-First)收集器,是一款面向服务端应用的收集器,应用在多处理器和大容量内存环境中,在实现高吞吐量的同时,尽可能的满足垃圾收集暂停时间的要求。另外还具有以下特性:
- 像CMS收集器一样,能与应用程序线程并发执行。
- 整理空间空间更快
- 需要更多的时间来预测GC停顿时间
- 不希望牺牲大量的吞吐性能
- 不需要更大的Java Heap
G1收集器的设计目标是取代CMS收集器,它同CMS相比,在以下方面表现的更出色:
- G1是一个有整理内存过程的垃圾收集器,不会产生很多内存碎片。
- G1的Stop The World(STW)更可控,G1在停顿时间上添加了预测机制,用户可以指定期望停顿时间。
3、G1的特点
- G1能充分利用多CPU、多核环境硬件优势,尽量缩短STW。
- G1 整体上采用标记-整理算法,局部是通过复制算法,不会产生内存碎片。
- 宏观上看G1之中不再区分年轻代和老年代。**把内存划分成多个独立的子区域(Region)**,可以近似理解为一个围棋的棋盘。
- G1收集器里面讲整个的内存区都混合在一起了,但其本身依然在小范围内要进行年轻代和老年代的区分,保留了新生代和老年代,但它们不再是物理隔离的,而是一部分Region的集合且不需要Region是连续的,也就是说依然会采用不同的GC方式来处理不同的区域。
- G1 虽然也是分代收集器,但整个内存分区不存在物理上的年轻代与老年代的区别,也不需要完全独立的survivor(to space)堆做复制准备。G1只有逻辑上的分代概念,或者说每个分区都可能随G1的运行在不同代之间前后切换。
4、底层原理
1、Region区域化垃圾收集器
区域化内存划片Region,整体编为一系列不连续的内存区域,避免了全内存的GC操作。
核心思想是将整个堆内存区域分成大小相同的子区域(Region),在JVM启动时会自动设置这些子区域的大小。
在堆的使用上,G1并不要求对象的存储一定是物理上连续的只要逻辑上连续即可,每个分区也不会固定地为某个代服务,可以按需在年轻代和老年代之间切换。启动时可以通过参数-XX:G1HeapRegionSize=n可指定分区大小(1MB-32MB,且必须是2的幂),默认将整个堆划分为2048个分区。大小范围在1MB-32MB,最多能设置2048个区域。也即能够支持的最大内存为:32MB * 2048 = 65536MB = 64G内存。
G1将新生代、老年代的物理空间取消了。
最大好处是化整为零,避免全内存扫描,只需要按照区域来进行扫描即可。
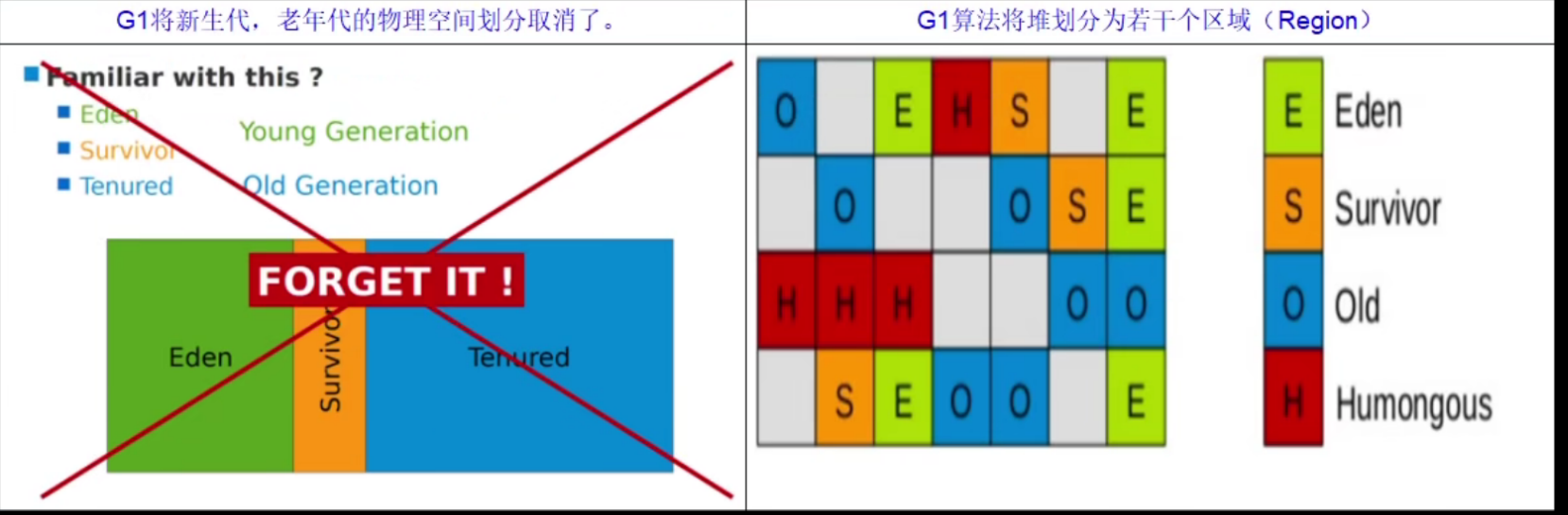
G1算法将堆划分为若干个区域(Region),它仍然属于分代收集器
这些Region的一部分包含新生代,新生代的垃圾收集依然采用暂停所有应用线程的方式,将存活对象拷贝到老年代或者Survivor空间。
这些Region的一部分包含老年代,G1收集器通过将对象从一个区域复制到另一个区域,完成了清理工作。这就意味着,在正常的处理过程中,G1完成了堆的压缩(至少是部分堆的压缩),这样也就不会有CMS内存碎片问题的存在了。
在G1中,还有一种特殊的区域,叫Humongous(巨大的)区域。如果一个对象占用的空间超过了分区容量的50%以上,G1收集器就认为这是一个巨型对象。这些巨型对象默认直接会被分配在老年代,但是如果它是一个短期存在的巨型对象,就会对垃圾收集器造成负面影响。
为了解决这个问题,G1划分了一个Humongous区,它用来专门存放巨型对象。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC——所以说要尽量避免创建大对象。
2、回收步骤
G1收集器下的Young GC
针对Eden区进行收集,Eden区耗尽后会被触发,主要是小区域收集+形成连续的内存块,避免内存碎片。
- Eden区的数据移动到新的Survivor区,部分数据晋升到Old区。
- Survivor区的数据移动到新的Survivor区,部分数据晋升到Old区。
- 最后Eden区收集干净了,GC结束,用户的应用程序继续执行。
3、4步过程
- 初始标记:只标记GC Roots能直接关联到的对象
- 并发标记:进行GC Roots Tracing的过程
- 最终标记:修正并发标记期间,因程序运行导致标记发生变化的那一部分对象
- 筛选回收:根据时间来进行价值最大化的回收。
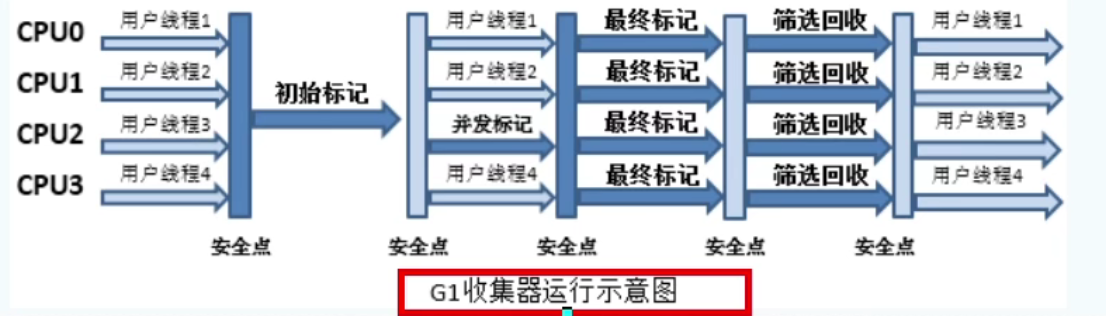
5、常用配置参数(了解)
开发人员仅仅声明一下参数即可。
三步归纳:开始G1 + 设置最大内存 + 设置最大停顿时间
- -XX:+UseG1GC——使用G1垃圾回收器
- -Xmx32g——设置最大内存
- -XX:MaxGCPauseMillis=100——设置最大停顿时间
注:-XX:MaxGCPauseMillis=n:最大GC停顿时间单位毫秒,这是个软目标,JVM将尽可能(但不保证)停顿小于这个时间。
1、-XX:+UseG1GC——常用
使用G1垃圾回收器
2、-XX:G1HeapRegionSize=n——常用
设置的G1区域的大小。值是2的幂,范围是1MB到32MB。目标是根据最小的Java堆大小划分出约2048个区域。
3、-XX:MaxGCPauseMillis=n——常用
最大GC停顿时间,这是个软目标,JVM将尽可能(但不保证)停顿小于这个时间。
4、-XX:InitiatingHeapOccupancyPercent=n——默认
堆占用了多少的时候就触发GC,默认为45
5、-XX:ConcGCThreads=n——默认
并发GC使用的线程数。
6、-XX:G1ReservePercent=n——默认
设置作为空闲的预留内存百分比,以降低目标空间溢出的风险,默认值是10%
6、和CMS相比的优势
两个优势:
- G1不会产生内存碎片
- G1可以精确控制停顿。该收集器是把整个堆(新生代、老生代)划分成多个固定大小的区域,每次根据允许停顿时间去收集垃圾最多的区域。
7、在将要上线的项目中配置JVM参数
在有包的路径下,运行jar命令,公式如下:
1 | java -server [JVM的各种参数] -jar jar/war包的名字 |
12、生产环境服务器变慢,诊断思路和性能评估谈谈?
1、整机:top
主要关注的几个参数:
- lad average:三个负载值,分别代表系统在1、5、15内的负载情况。
- 如果三个负载值的平均值超过0.6或者0.7,说明当前系统的负载比较大,需要进行优化
- %CPU:CPU占比
- %MEM:内存占比
1 | # 系统性能命令的精简版 |
2、CPU:vmstat
1、vmstat:查看CPU(包含不限于)
1 | vmstat -n 2 3 |

一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数单位是秒,第二个参数是采样的次数。
-procs
- r:运行等待CPU时间片的进程数,原则上1核的CPU运行队列不要超过2,整个系统的运行队列不能超过总核数的2倍,否则代表系统压力过大。
- b:等待资源的进程数,比如正在等待磁盘I/O、网络I/O等。
-cpu
- us:用户进程消耗CPU时间百分比,us值高,用户进程小号CPU时间多,如果长期大于50%,优化程序;
- sy:内核进程消耗的CPU百分比;
- us + sy参考值为80%,如果us + sy大于80%,说明可能存在CPU不足
- id:处于空闲的CPU百分比
- wa:系统等待IO的CPU时间百分比
- st:来自于一个虚拟机偷取的CPU时间的百分比
2、vmstat:查看额外
查看所有cpu核信息:
1 | mpstat -P ALL 2 |
每个进程使用cpu的用量分解信息:
1 | pidstat -u1 -p 进程编号 |
3、内存:free
1、应用程序可用内存数
1 | free |
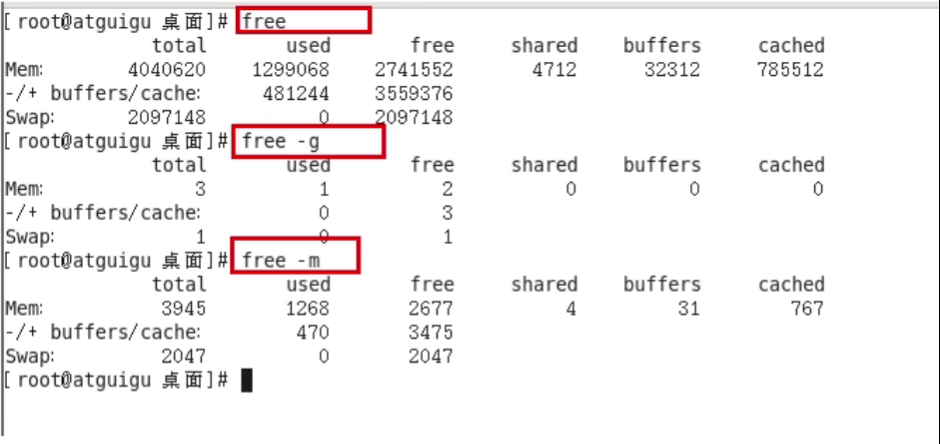
经验:
- 应用程序可用内存/系统物理内存>70%内存充足。
- 应用程序可用内存/系统物理内存<20%内存不足,需要增加内存。
- 20%<应用程序可用内存/系统物理内存<70%内训基本够用
2、查看额外
1 | pidstat -p 进程号 -r 采样间隔秒数 |
4、硬盘:df
查看磁盘剩余空间数:
1 | df -h |
5、磁盘IO:iostat
磁盘I/O性能评估:
1 | iostat -xdk 2 3 |
磁盘块设备发布:
- rkB/s:每秒读取数据量kB
- wkB/s:每秒写入数据量kB
- svctm I/O:请求的平均等待时间,单位毫秒
- await I/O:请求的拼接等待杰斯安,单位毫秒;值越小,性能越好
- util:疫苗中有百分几的时间用于I/O操作。接近100%时,表示磁盘带宽跑满,需要优化程序或者增加硬盘
rkB/s、wkB/s根据系统应用不同会有不同的值,但有规律遵循:长期、超大数据读写,肯定不正常,需要优化程序读取。
svctm的值与await的值很接近,表示几乎没有I/O等待,磁盘性能好,
如果await的值远高于svctm的值,则表示I/O队列等待太长,需要优化程序或者更换磁盘。
查看额外:
1 | pidstat -d 采样间隔秒数 -p 进程号 |
6、网络IO:ifstat
默认本地没有,下载ifstat:
1 | wget http://gael.roualland.free.fr/ifstat/ifstat-1.1.tar.gz |
查看网络IO:
13、假设生产环境出现CPU占用过高,请谈谈你的分析思路和定位
需要结合Linux和JDK命令一块分析
案例步骤:
- 先用top命令找出CPU占比最高的
- ps -ef或者jps进一步定位,得知是一个怎么样的一个后台程序惹事
- 定位到具体线程或者代码
- ps -mp pid -o THREAD,tid,time
- -m:显示所有的线程
- -p pid进程使用cpu的时间
- -o该参数后是用户自定义格式
- ps -mp pid -o THREAD,tid,time
- 将需要的线程ID转换为16进制格式(英文小写格式)
- printf “%x\n”有问题的线程ID
- jstack 进程ID | grep(16进制线程ID小写英文) -A60
- -A60指的是打印出前60行
14、对于JDK自带的JVM监控和性能分析工具用过哪些?一般你是怎么用的?
1、概览
2、性能监控工具
- jps
- jinfo
- jmap
- jstat
- jstack
Elasticsearch
1、Elasticsearch 和 solr 的区别
背景:
- 它们都是基于Lucene搜索服务器基础之上开发,一款优秀的,高性能的企业级搜索服务器。
- 高性能是因为他们都是基于分词技术构建的倒排索引的方式进行查询
- 开发语言:java语言开发
- 诞生时间:
- Solr :2004年诞生。
- Es:2010年诞生。
- Es 比Solr更新,因此Es的功能越强大
区别:
- 当实时建立索引的时候,solr会产生io阻塞,而es则不会,es查询性能要高于solr。
- 在不断动态添加数据的时候,solr的检索效率会变的低下,而es则没有什么变化。
- Solr利用zookeeper进行分布式管理,而es自身带有分布式系统管理功能。
- Solr一般都要部署到web服务器上,比如tomcat。启动tomcat的时候需要配置tomcat与solr的关联。
- Solr 的本质是一个动态web项目
- Solr支持更多的格式数据[xml,json,csv等],而es仅支持json文件格式。
- Solr是传统搜索应用的有力解决方案,但是es更适用于新兴的实时搜索应用。
- 单纯的对已有数据进行检索的时候,solr效率更好,高于es。
- 如果是对实时建立索引的数据,而且需要不断动态添加数据,使用es会更好
- 现在的互联网数据基本上都是不断动态变化的,因此Es运用得比solr更多
- Solr官网提供的功能更多,而es本身更注重于核心功能,高级功能多有第三方插件。
关于solr与Es的集群:
SolrCloud:集群图:
Elasticsearch:集群图
面试相关
1、单点登陆的实现
单点登录:一处登录多处使用!
- 如:使用浏览器在网页当中登陆京东账号,打开另外有关京东的网页,发现已经是登陆的状态了
单点登陆的前提:单点登录多使用在分布式系统中
- 也不是说普通的web项目不能使用单点登陆,只能说是没有必要
实现思路流程图:
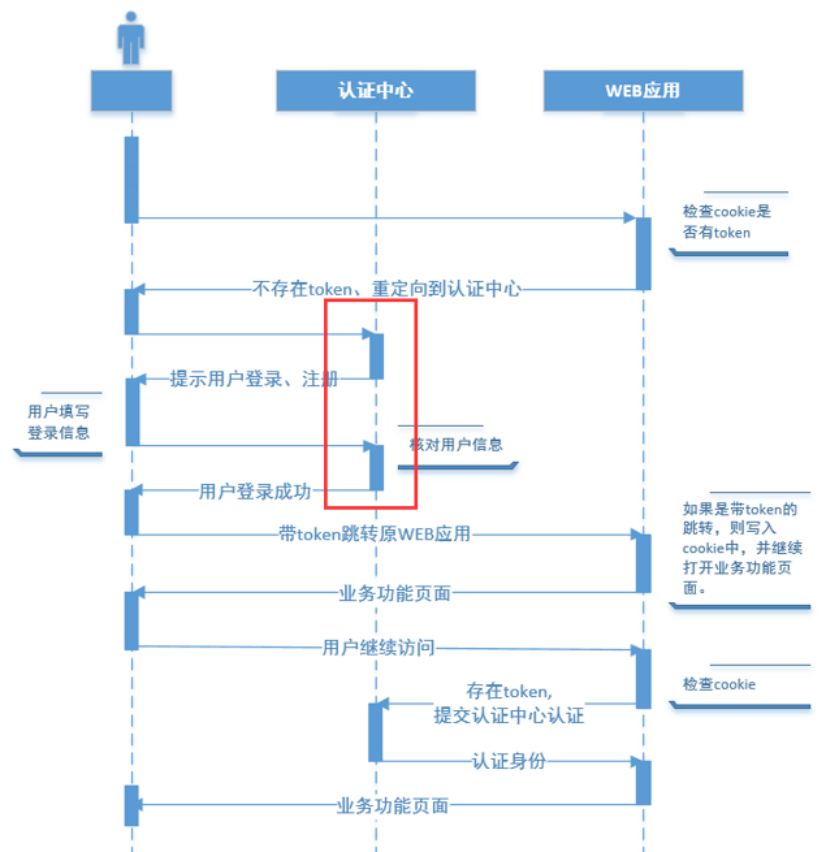
注意:这里的单点登陆是基于cookie的,是将token放入到cookie中的。如果浏览器禁用cookie的话,那么就无法实现单点登陆功能,甚至还会登陆失败。
2、购物车的实现
分析:
购物车:
- 购物车跟用户的关系?
- 一个用户必须对应一个购物车【一个用户不管买多少商品,都会存在属于自己的购物车中。】
- 单点登录一定在购物车之前。
- 跟购物车有关的操作有哪些?
- 添加购物车
- 用户未登录状态
- 添加到什么地方?未登录将数据保存到什么地方?
- Redis — 京东
- Cookie — 自己开发项目的时候【如果浏览器禁用cookie,就只能使用Redis了】
- 添加到什么地方?未登录将数据保存到什么地方?
- 用户登录状态
- Redis 缓存中 【读写速度快】
- Hash :hset(key,field,value)
- Key:user:userId:cart
- Hset(key,skuId,value);
- Hash :hset(key,field,value)
- 存在数据库中【oracle,mysql】
- Redis 缓存中 【读写速度快】
- 用户未登录状态
- 展示购物车
- 未登录状态展示
- 直接从cookie 中取得数据展示即可
- 登录状态
- 用户一旦登录:必须显示数据库【redis】+ cookie 中的购物车的数据
- Cookie 中有三条记录
- Redis中有五条记录
- 真正展示的时候应该是八条记录
- 用户一旦登录:必须显示数据库【redis】+ cookie 中的购物车的数据
- 未登录状态展示
- 添加购物车
消息队列
1、消息队列在项目中的使用
背景:在分布式系统中是如何处理高并发的。
由于在高并发的环境下,来不及同步处理用户发送的请求,则会导致请求发生阻塞。比如说,大量的insert,update之类的请求同时到达数据库MYSQL,直接导致了无数的行锁表锁的产生,甚至会导致请求堆积很多。从而触发 too many connections 错误。使用消息队列可以解决【异步通信】
异步
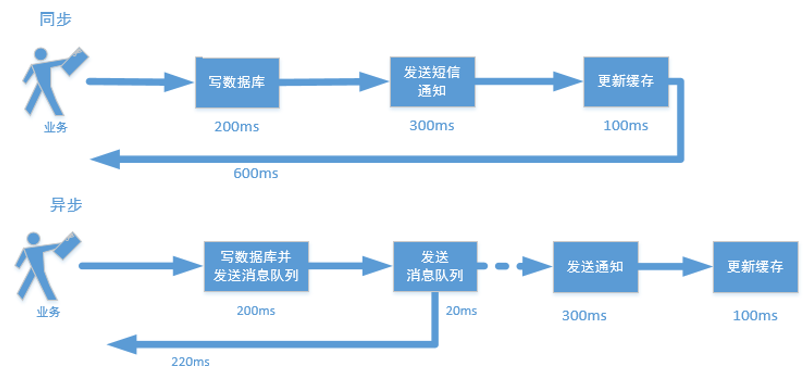
并行
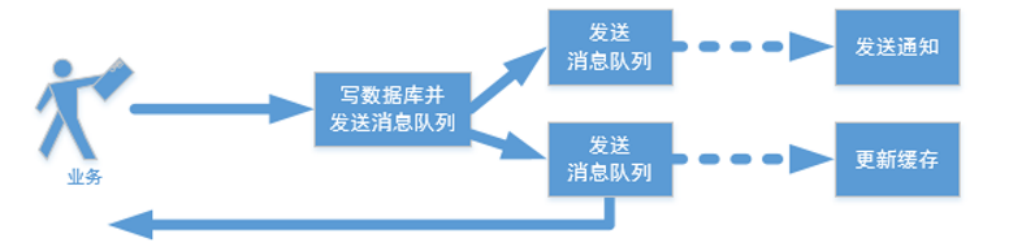
排队(起到削峰填谷的作用)
消息队列在电商的使用场景:
消息队列的弊端:
- 消息的不确定性:使用延迟队列,轮询技术来解决该问题即可!